
Robustness Enhancement of Neural Networks via Architecture Search with Multi-Objective Evolutionary Optimization



Abstract
:1. Introduction
- (1)
- We propose a novel robustness-enhanced method of neural networks based on architecture search with multi-objective optimization on the robustness and accuracy.
- (2)
- We analyze the effectiveness of different surrogate models and select the best one to accelerate the performance evaluation of networks in the architecture search algorithm.
- (3)
- We utilize the CLEVER (Cross Lipschitz Extreme Value for nEtwork Robustness) [19] score, which is an attack-independent metric, to evaluate the network robustness, so that the optimized neural network can defend against various adversarial attack approaches.
- (4)
- We conduct extensive experiments on real-world datasets to evaluate the effectiveness of REASON.
2. Related Work
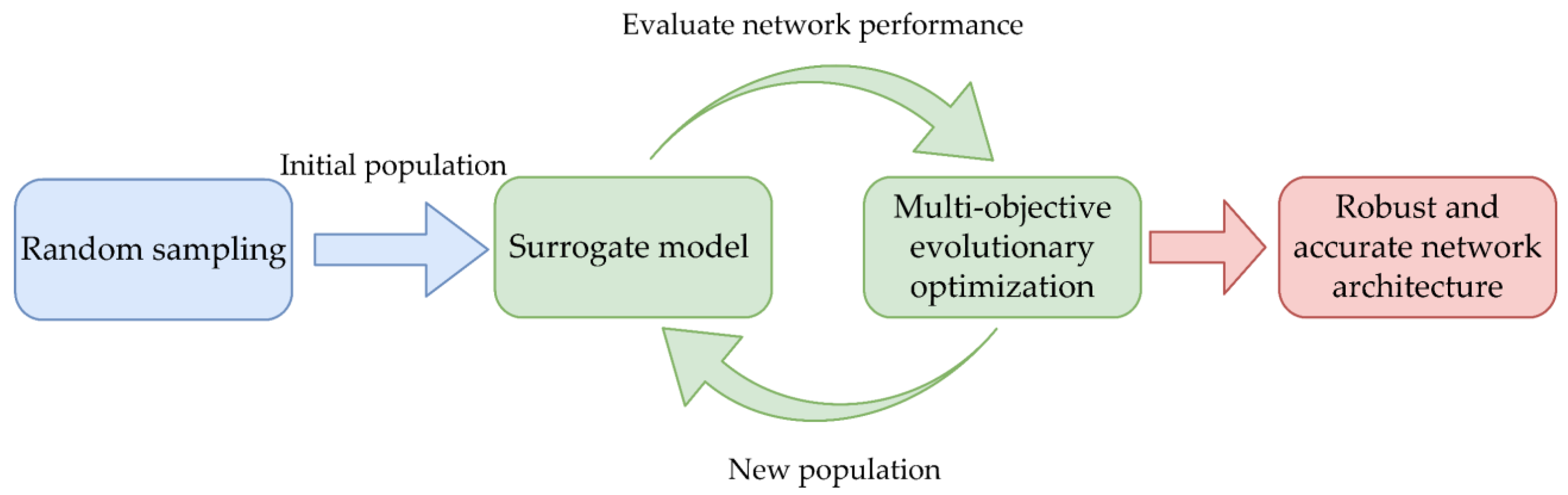
3. Framework of Robustness Enhancement in Neural Networks
3.1. Multi-Objective Search Trade off
3.2. Network Evaluation Cost
3.3. Robustness Evaluation Method
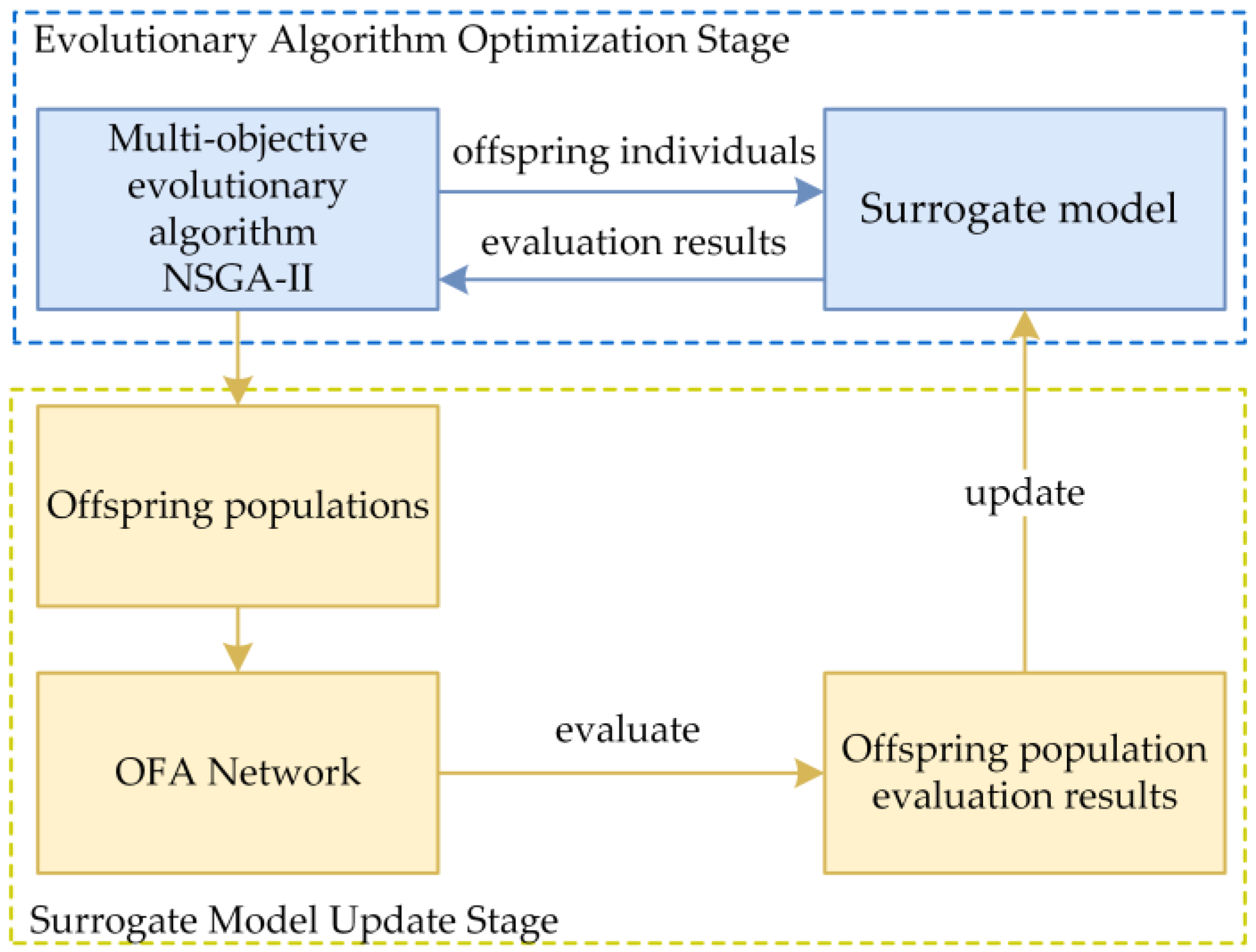
3.4. Robust Architecture Search Algorithm
| Algorithm 1. Robust architecture search algorithm |
| Given: : the number of random samples; : the number of iterations of multi-objective search; : the population set with empty initial value; : the subpopulation generated in each iteration of multi-objective search, with a size of ; : the search space of neural network architecture; : the individual network architecture; : the OFA network; : the function for evaluating the accuracy of network with weights : the function for evaluating the robustness in network with weights ; : the surrogate predictor of accuracy; : the surrogate predictor of robustness; : the multi-objective search algorithm for generating offspring based on the population set through two surrogate predictor of and . Output: Pareto solutions of robust architecture search 1. 2. while do 3. randomly sample individual network from 4. get weights of by inheriting from 5. 6. 7. 8. 9. end while 10. while do |
| 11. fit based on 12. fit based on 13. 14. for each in do 15. get weights of by inheriting from 16. 17. 18. 19. end for 20. j 21. end while 22. return Non-Dominated-Sort() |
4. Experiments
4.1. Experimental Parameter Settings
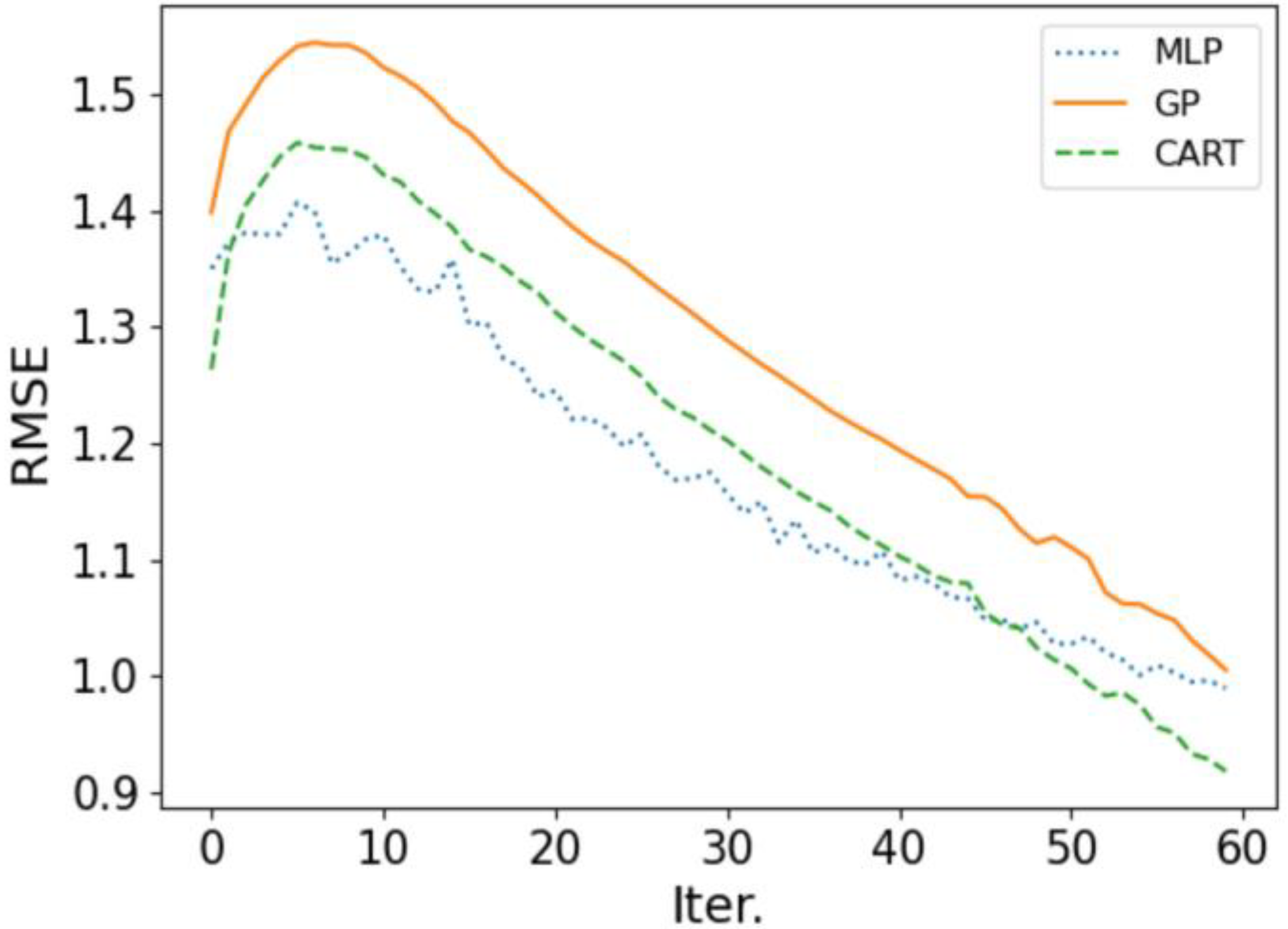
4.2. Surrogate Model Performance Analysis
4.2.1. Comparison of Root Mean Square Error
4.2.2. Comparison of Correlation Coefficient
4.3. Robustness Evaluation Effectiveness Analysis
4.3.1. Randomness Analysis
4.3.2. Coefficient Analysis
4.4. Architecture Search Results Analysis
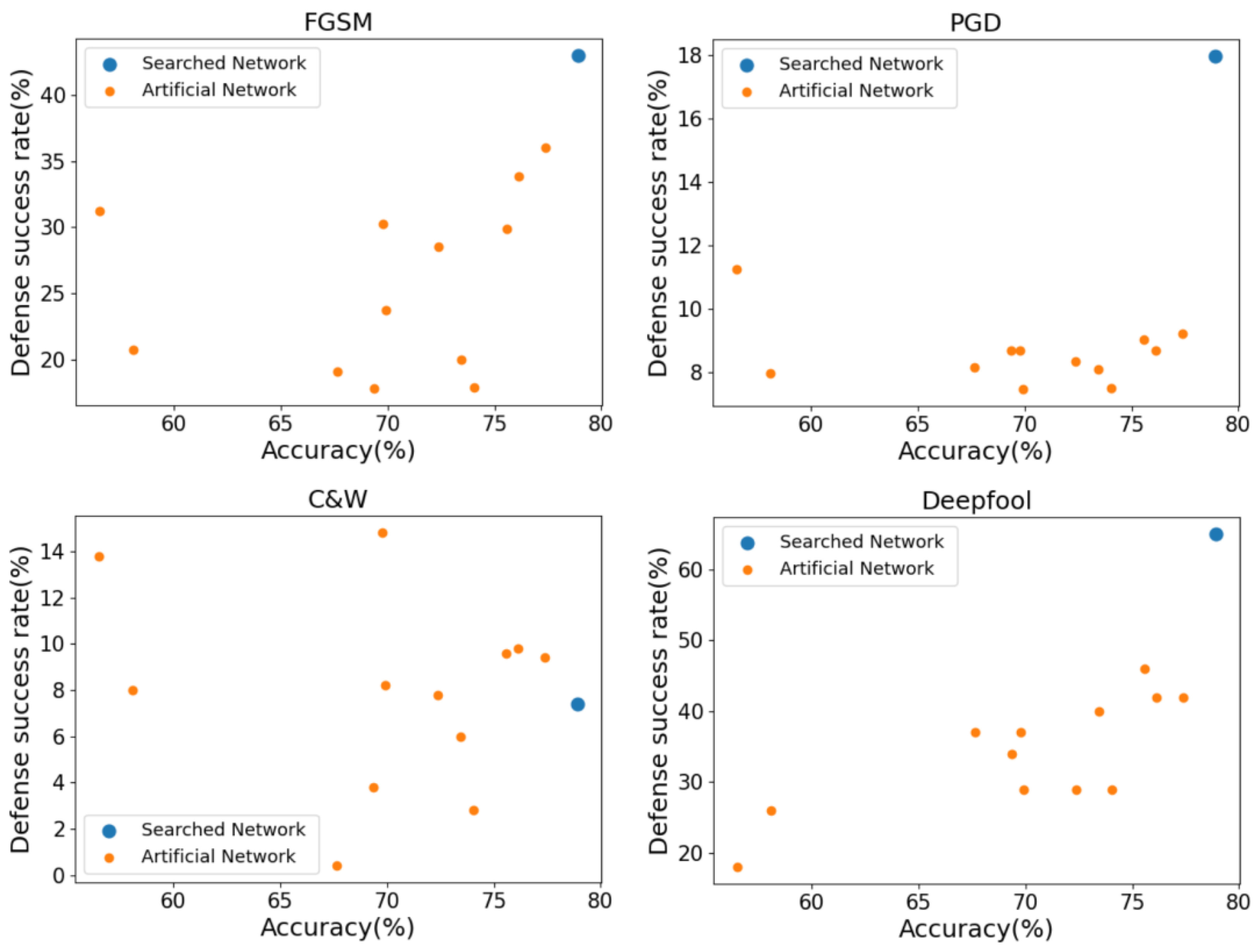
4.4.1. Comparison with Artificially Designed Networks
4.4.2. Comparison with Other Robust Architecture Search Algorithms
4.4.3. Comparison with Search Algorithm Using Attack-Dependent Robustness Metric
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Eykholt, K.; Evtimov, I.; Fernandes, E.; Li, B.; Rahmati, A.; Xiao, C.; Song, D. Robust physical-world attacks on deep learning visual classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1625–1634. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Wang, J. Adversarial Examples in Physical World. In Proceedings of the International Joint Conference on Artificial Intelligence, Virtual, 19–26 August 2021; pp. 4925–4926. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Gu, S.; Rigazio, L. Towards deep neural network architectures robust to adversarial examples. arXiv 2014, arXiv:1412.5068. [Google Scholar]
- Ross, A.; Doshi-Velez, F. Improving the adversarial robustness and interpretability of deep neural networks by regularizing their input gradients. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018; p. 1. [Google Scholar]
- Guo, M.; Yang, Y.; Xu, R.; Liu, Z.; Lin, D. When nas meets robustness: In search of robust architectures against adversarial attacks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 631–640. [Google Scholar]
- Kotyan, S.; Vargas, D.V. Towards evolving robust neural architectures to defend from adversarial attacks. In Proceedings of the 2020 Genetic and Evolutionary Computation Conference Companion, Cancun, Mexico, 8–12 July 2020; pp. 135–136. [Google Scholar]
- Geraeinejad, V.; Sinaei, S.; Modarressi, M.; Daneshtalab, M. RoCo-NAS: Robust and Compact Neural Architecture Search. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Dong, M.; Li, Y.; Wang, Y.; Xu, C. Adversarially robust neural architectures. arXiv 2020, arXiv:2009.00902. [Google Scholar]
- Mok, J.; Na, B.; Choe, H.; Yoon, S. AdvRush: Searching for Adversarially Robust Neural Architectures. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 12322–12332. [Google Scholar]
- Hosseini, R.; Yang, X.; Xie, P. Dsrna: Differentiable search of robust neural architectures. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6196–6205. [Google Scholar]
- Liu, H.; Simonyan, K.; Yang, Y. DARTS: Differentiable architecture search. arXiv 2018, arXiv:1806.09055. [Google Scholar]
- Wang, Z.; Zhang, Q.; Ong, Y.S.; Yao, S.; Liu, H.; Luo, J. Choose appropriate subproblems for collaborative modeling in expensive multiobjective optimization. IEEE Trans. Cybern. 2021. [Google Scholar] [CrossRef]
- Leung, M.F.; Wang, J. A collaborative neurodynamic approach to multiobjective optimization. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5738–5748. [Google Scholar] [CrossRef] [PubMed]
- Gunantara, N. A review of multi-objective optimization: Methods and its applications. Cogent Eng. 2018, 5, 1502242. [Google Scholar] [CrossRef]
- Marler, R.T.; Arora, J.S. Survey of multi-objective optimization methods for engineering. Struct. Multidiscip. Optim. 2004, 26, 369–395. [Google Scholar] [CrossRef]
- Weng, T.W.; Zhang, H.; Chen, P.Y.; Yi, J.; Su, D.; Gao, Y.; Daniel, L. Evaluating the robustness of neural networks: An extreme value theory approach. arXiv 2018, arXiv:1801.10578. [Google Scholar]
- Xie, G.; Wang, J.; Yu, G.; Zheng, F.; Jin, Y. Tiny adversarial mulit-objective oneshot neural architecture search. arXiv 2021, arXiv:2103.00363. [Google Scholar]
- Yue, Z.; Lin, B.; Huang, X.; Zhang, Y. Effective, efficient and robust neural architecture search. arXiv 2020, arXiv:2011.09820. [Google Scholar]
- Chen, H.; Zhang, B.; Xue, S.; Gong, X.; Liu, H.; Ji, R.; Doermann, D. Anti-bandit neural architecture search for model defense. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 70–85. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T.A.M.T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Cai, H.; Zhu, L.; Han, S. Proxylessnas: Direct neural architecture search on target task and hardware. arXiv 2018, arXiv:1812.00332. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. Mnasnet: Platform-aware neural architecture search for mobile. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2820–2828. [Google Scholar]
- Wu, B.; Dai, X.; Zhang, P.; Wang, Y.; Sun, F.; Wu, Y.; Keutzer, K. Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10734–10742. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Adam, H. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 1314–1324. [Google Scholar]
- Chu, X.; Zhang, B.; Xu, R. Fairnas: Rethinking evaluation fairness of weight sharing neural architecture search. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 12239–12248. [Google Scholar]
- Dong, J.D.; Cheng, A.C.; Juan, D.C.; Wei, W.; Sun, M. Dpp-net: Device-aware progressive search for pareto-optimal neural architectures. In Proceedings of the European Conference on Computer Vision (ECCV), Munchen, Germany, 8–14 September 2018; pp. 517–531. [Google Scholar]
- Cai, H.; Gan, C.; Wang, T.; Zhang, Z.; Han, S. Once-for-all: Train one network and specialize it for efficient deployment. arXiv 2019, arXiv:1908.09791. [Google Scholar]
- Zhang, H.; Weng, T.W.; Chen, P.Y.; Hsieh, C.J.; Daniel, L. Efficient neural network robustness certification with general activation functions. Adv. Neural Inf. Process. Syst. 2018, 31, 4939–4948. [Google Scholar]
- Weng, L.; Zhang, H.; Chen, H.; Song, Z.; Hsieh, C.J.; Daniel, L.; Dhillon, I. Towards fast computation of certified robustness for relu networks. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5276–5285. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 770–778. [Google Scholar]
- Available online: https://image-net.org/ (accessed on 20 May 2021).
- Kendall, M.G. A new measure of rank correlation. Biometrika 1938, 30, 81–93. [Google Scholar] [CrossRef]
- Sedgwick, P. Spearman’s rank correlation coefficient. BMJ 2014, 349, g7327. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munchen, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 22–24 May 2017; pp. 39–57. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Chen, X.; Hsieh, C.J. Stabilizing differentiable architecture search via perturbation-based regularization. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 1554–1565. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spearman’s Rank Correlation Coefficient | Kendall’s Rank Correlation Coefficient |
|---|---|
| 0.9003 | 0.7208 |
| Network | Accuracy | FGSM | PGD | C&W | Deepfool |
|---|---|---|---|---|---|
| Searched Network | 78.908 | 43.118 | 18.272 | 7.4 | 65.0 |
| AlexNet | 56.522 | 31.224 | 11.254 | 13.8 | 18.0 |
| VGG13 | 69.928 | 23.746 | 7.456 | 8.2 | 29.0 |
| VGG19 | 72.376 | 28.528 | 8.33 | 7.8 | 29.0 |
| ResNet50 | 76.13 | 33.856 | 8.67 | 9.8 | 42.0 |
| ResNet101 | 77.374 | 36.016 | 9.198 | 9.4 | 42.0 |
| SqueezeNet | 58.092 | 20.73 | 7.966 | 8.0 | 26.0 |
| DenseNet169 | 75.6 | 29.902 | 9.026 | 9.6 | 46.0 |
| GoogLeNet | 69.778 | 30.264 | 8.68 | 14.8 | 37.0 |
| ShuffleNetV2 | 69.362 | 17.792 | 8.69 | 3.8 | 34.0 |
| MobileNetV3_small | 67.668 | 19.056 | 8.16 | 0.4 | 37.0 |
| MobileNetV3_large | 74.042 | 17.892 | 7.5 | 2.8 | 29.0 |
| MnasNet | 73.456 | 19.99 | 8.09 | 6.0 | 40.0 |
| Search Algorithms | Accuracy | FGSM | PGD |
|---|---|---|---|
| REASON | 73.066 | 62.458 | 59.93 |
| RobNet-large | 61.26 | 39.74 | 37.14 |
| SDARTS-ADV | 74.85 | 48.09 | 46.54 |
| PC-DARTS-ADV | 75.73 | 48.25 | 46.59 |
| DSRNA-CB | 75.84 | 50.89 | 45.39 |
| DSRNA-Jacobian | 75.88 | 48.69 | 43.79 |
| Metrics | Accuracy | FGSM | PGD | C&W | Deepfool |
|---|---|---|---|---|---|
| Attack-Dependent | 78.732 | 43.012 | 18.054 | 7.6 | 63.8 |
| CLEVER Score | 78.908 | 43.118 | 18.272 | 7.6 | 65.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Huang, H.; Zuo, X.; Zhao, X. Robustness Enhancement of Neural Networks via Architecture Search with Multi-Objective Evolutionary Optimization. Mathematics 2022, 10, 2724. https://doi.org/10.3390/math10152724
Chen H, Huang H, Zuo X, Zhao X. Robustness Enhancement of Neural Networks via Architecture Search with Multi-Objective Evolutionary Optimization. Mathematics. 2022; 10(15):2724. https://doi.org/10.3390/math10152724
Chicago/Turabian StyleChen, Haojie, Hai Huang, Xingquan Zuo, and Xinchao Zhao. 2022. "Robustness Enhancement of Neural Networks via Architecture Search with Multi-Objective Evolutionary Optimization" Mathematics 10, no. 15: 2724. https://doi.org/10.3390/math10152724
APA StyleChen, H., Huang, H., Zuo, X., & Zhao, X. (2022). Robustness Enhancement of Neural Networks via Architecture Search with Multi-Objective Evolutionary Optimization. Mathematics, 10(15), 2724. https://doi.org/10.3390/math10152724