1. Introduction
Evolutionary algorithms (EAs) are a family of randomized search heuristics inspired from biological evolution, and many empirical studies demonstrate that crossovers that combine genes of two parents to generate new offspring could be helpful to the convergence of EAs [
1,
2,
3]. Meanwhile, theoretical results on runtime analysis validate the promising function of crossover in EAs [
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15], whereas there are also some cases that crossover cannot be helpful [
16,
17].
By exchanging components of target vectors with donor vectors, differential evolution (DE) algorithms implement crossover operations in a different way. Numerical results show that continuous DE algorithms can achieve competitive performance on a large variety of complicated problems [
18,
19,
20,
21], and its competitiveness is to great extent attributed to the employed crossover operations [
22]. However, the binary differential evolution (BDE) algorithm [
23], which simulates the working mechanism of continuous DE, is not as competitive as its continuous counterpart. Analysis of the working principle indicates that the mutation and update strategies result in poor convergence of BDE [
24], but there were no theoretical results reported on how crossover influences the performance of discrete-coded DE algorithms.
This paper is dedicated to investigating the influence of binomial crossover by introducing it to the (
)EA, excluding the impacts of population and mutation strategies of DE. Although the expected hitting time/runtime is popularly investigated in the theoretical study of randomized search heuristics (RSHs), there is a gap between runtime analysis and practice because their optimization time to reach an optimum is uncertain and could be even infinite in continuous optimization [
25]. Due to this reason, optimization time is seldom used in computer simulation for evaluating the performance of EAs, and their performance is evaluated after running finite generations by solution quality such as the mean and median of the fitness value or approximation error [
26]. In theory, solution quality can be measured for a given iteration budget by the expected fitness value [
27] or approximation error [
28,
29], which contributes to the analysis framework named fixed-budget analysis (FBA). An FBA on immune-inspired hypermutations led to theoretical results that are very different from those of runtime analysis but consistent with the empirical results, which demonstrates that the perspective of fixed-budget computations provides valuable information and additional insights for the performance of randomized search heuristics [
30].
Accordingly, we evaluate the solution quality of an EA after running finite generations by the expected approximation error and the error tail probability. The former measures the fitness gap between a solution and optimum, and the latter is the probability distribution of the error over error levels, which measures the probability of finding the optimum. An EA is said to outperform another if, for the former EA, its error and tail probability are smaller. Furthermore, an EA is said to asymptotically outperform another if, for the former EA, its error and tail probability are smaller after a sufficiently large number of generations.
The research question of this paper is whether the binomial crossover operator can help reduce the approximation error of EA. As a pioneering work on this topic, we investigate a
that performs the binomial crossover on an individual and an offspring generated by mutation, and compare a
without crossover and its variant
on two classical problems, OneMax and Deceptive. By splitting the objective space into error levels, the analysis is performed based on the Markov chain models [
31,
32]. Given the two EAs, the comparison of their performance is drawn from the comparison of their transition probabilities, which are estimated by investigating the bits preferred by evolutionary operations. Under some conditions,
with binomial crossover outperforms
on OneMax, but not on Deceptive; however, by adding an adaptive parameter mechanism arising from theoretical results,
with binomial crossover outperforms
on Deceptive too.
This work presents the first study on how binomial crossover influences the expected runtime and tail probability of randomized search heuristics. Meanwhile, we also propose a feasible routine to get adaptive parameter settings of EAs from theoretical results. The rest of this paper is organized as follows.
Section 2 reviews related theoretical work. Preliminary contents for our theoretical analysis are presented in
Section 3. Then, the influence of the binomial crossover on transition probabilities is investigated in
Section 4.
Section 5 conducts an analysis of the asymptotic performance of EAs. To reveal how binomial crossover works on the performance of EAs for consecutive iterations, the OneMax problem and the Deceptive problem are investigated in
Section 6 and
Section 7, respectively. Finally,
Section 8 presents the conclusions and discussions.
3. Preliminaries
3.1. Problems
Considering a maximization problem
denote its optimal solution by
and optimal objective value by
. The quality of a solution
is evaluated by its approximation error
. The error
takes finite values, called error levels:
where
L is a non-negative integer.
is called
at the level i if
,
. The collection of solutions at level
i is denoted by
.
We investigate the optimization problem in the form
where
. Error levels of (
1) take only
values. Two instances, the uni-modal OneMax problem and the multi-modal Deceptive problem, are considered in this paper.
For the OneMax problem, both exploration and exploitation are helpful to the convergence of EAs to the optimum, because exploration accelerates the convergence process and exploitation refines the precision of approximation solutions. However, for the Deceptive problem, local exploitation leads to convergence to the local optimum, but it in turn increases the difficulty to jump to the global optimum. That is, exploitation hinders convergence to the global optimum of the Deceptive problem, thus, the performance of EAs is dominantly influenced by their exploration ability.
3.2. Evolutionary Algorithms
For the sake of analysis on binomial crossover excluding the influence of population and mutation, the presented in Algorithm 1 is taken as the baseline algorithm in our study. Its candidate solutions are generated by the bitwise mutation with probability . The binomial crossover is appended to , getting which is illustrated in Algorithm 2. The first performs bitwise mutation with probability , and then applies binomial crossover with rate to generate a candidate solution for selection.
The EAs investigated in this paper can be modeled as homogeneous Markov chains [
31,
32]. Given the error vector
and the initial distribution
the transition matrix of
and
for the optimization problem (
1) can be written in the form
where
| Algorithm 1 |
- 1:
counter ; - 2:
randomly generate a solution ; - 3:
while the stopping criterion is not satisfied do - 4:
generate the mutant by bitwise mutation:
- 5:
if then - 6:
; - 7:
else - 8:
; - 9:
end if - 10:
; - 11:
end while
|
| Algorithm 2 |
- 1:
counter ; - 2:
randomly generate a solution ; - 3:
while the stopping criterion is not satisfied do - 4:
Generate the mutant by bitwise mutation:
- 5:
set ; - 6:
generate the offspring by performing binomial crossover on :
- 7:
if then - 8:
; - 9:
else - 10:
; - 11:
end if - 12:
; - 13:
end while
|
Recalling that the solutions are updated by the elitist selection, we know
is an upper triangular matrix that can be partitioned as
where
represents the probabilities to transfer from non-optimal statuses to the optimal status, and
is the transition submatrix depicting the transitions between non-optimal statuses.
3.3. Transition Probabilities
Transition probabilities can be confirmed by considering generation of a candidate with , which is achieved if “l preferred bits” of are changed. If there are multiple solutions that are better than , there could be multiple choices for both the number l and the location of “l preferred bits”.
Example 1. For the OneMax problem, equals to the amount of ‘0’-bits in . Denoting and , we know replaces if and only if . Then, to generate a candidate replacing , “l preferred bits” can be confirmed as follows.
If , “l preferred bits” consist of ‘1’-bits and ‘0’-bits, where l is an even number that is not greater than .
While , “l preferred bits” could be combinations of ‘0’-bits and k ‘1’-bits (), where . Here, k is not greater than i, because could not be greater than j, the number of ‘0’-bits in . Meanwhile, k does not exceed , the number of ‘1’-bits in .
If an EA flips each bit with an identical probability, the probability of flipping l bits are related to l and independent of their locations. Denoting the probability of flipping l bits by , we can confirm the connection between the transition probability and .
As presented in Example 1, transition from level
j to level
i (
) results from flips of
‘0’-bits and
k ‘1’-bits. Then, transition probabilities for OneMax are confirmed as
where
,
.
According to definition of the Deceptive problem, we get the following map from
to
.
Transition from level j to level i () is attributed to one of the following cases.
If , the amount of ‘1’-bits decreases from to . This transition results from a change of ‘1’-bits and k ‘0’-bits, where ;
if , all of ‘0’-bits are flipped, and all of its ‘1’-bits keep unchanged.
Accordingly, transition probabilities for Deceptive are confirmed as
where
.
3.4. Performance Metrics
To evaluate the performance of EAs, we propose two metrics for a given iteration budget, the expected approximation error (EAE) and the tail probability (TP) of EAs for t consecutive iterations.
Definition 1. Let be the individual sequence of an individual-based EA.
- (1)
The expected approximation error (EAE) after t consecutive iterations is - (2)
Given , the tail probability (TP) of the approximation error that is greater than or equal to is defined as
EAE is the fitness gap between a solution and the optimum. It measures solution quality after running t generations. TP is the probability distribution of a found solution over non-optimal levels where . The sum of TP is the probability of not finding the optimum.
Given two EAs
and
, if both EAE and TP of Algorithm
are smaller than those of Algorithm
for any iteration budget, we say Algorithm
outperforms Algorithm
on problem (
1).
Definition 2. Let and be two EAs applied to problem (1). - 1.
Algorithm outperforms , denoted by , if it holds that
, ;
, , .
- 2.
Algorithm asymptotically outperforms on problem (1), denoted by , if it holds that
The asymptotic outperformance is weaker than the outperformance.
4. Comparison of Transition Probabilities of Two EAs
In this section, we compare transition probabilities of and . According to the connection between and , a comparison of transition probabilities can be conducted by considering the probabilities of flipping “l preferred bits”.
4.1. Probabilities of Flipping Preferred Bits
Denote probabilities of
and
to flip “
l preferred bits” by
and
, respectively. By (
5), we know
Since the mutation and the binomial crossover in Algorithm 2 are mutually independent, we can get the probability by considering the crossover first. When flipping “
l preferred bits” by
, there are
(
) bits of
set as
by (
7), the probability of which is
If only “
l preferred bits” are flipped, we know,
Note that
degrades to
when
, and
becomes the random search while
. Thus, we assume that
,
, and
are located in
. A fair comparison of transition probabilities is investigated by considering the identical parameter setting
Then, we know
, and Equation (
14) implies
Subtracting (
13) from (
16), we have
From the fact that , we conclude that is greater than if and only if . That is, the introduction of the binomial crossover in leads to the enhancement of the exploration ability of . We get the following theorem for the case that .
Theorem 1. While , it holds for all that
Proof. The result can be obtained directly from Equation (
17) by setting
. □
For the popular setting where the mutation probability of (1+1)EA is set as , the introduction of binomial crossover does increase the ability to generate new candidate solutions. Then, we investigate how this improvement contributes to change of transition probabilities.
4.2. Comparison of Transition Probabilities
To validate that algorithm is more efficient than algorithm , it is assumed that the probability of to transfer to promising statuses could be not smaller than that of .
Definition 3. Let and be two EAs with an identical initialization mechanism. and are the transition matrices of and , respectively. It is said that dominates, denoted by , if it holds that
- 1.
;
- 2.
.
Denote the transition probabilities of and by and , respectively. For the OneMax problem and Deceptive problem, we get the relation of transition dominance on the premise that .
Theorem 2. For and , denote their transition matrices by and , respectively. On the condition that , it holds for problem (1) that . Proof. Denote the collection of all solutions at level
k by
,
. We prove the result by considering the transition probability
Since the function values of solutions are merely related to the number of ‘1’-bits, the probability to generate a solution by performing mutation on depends on the Hamming distance . Given , is partitioned as where , and L is a positive integer that is smaller than or equal to n.
Accordingly, the probability to transfer from level
j to
i is confirmed as
where
is the size of
,
the probability to flip “
l preferred bits”. Then,
Since
, Theorem 1 implies that
Combining it with (
18) and () we know
Then, we get the result by Definition 2. □
Example 2 (Comparison of transition probabilities for the OneMax problem).
Let . By (8), we havewhere . Since , Theorem 1 implies that and by (21) and () we have Example 3 (Comparison of transition probabilities for the Deceptive problem).
Let . Equation (10) implies thatwhere . Similar to the analysis of Example 2, we get the conclusion that .
The results demonstrate that when , the introduction of binomial crossover leads to transition dominance of over . In the following section, we would like to answer if transition dominance leads to outperformance of over .
5. Analysis of Asymptotic Performance
In this section, we will prove that
asymptotically outperforms
using the average convergence rate [
25,
32].
Definition 4. The average convergence rate (ACR) of an EA for t generation is Lemma 1 ([
32], Theorem 1).
Let be the transition submatrix associated with a convergent EA. Under random initialization (i.e., the EA may start at any initial state with a positive probability), it holdswhere is the spectral radius of .
Lemma 1 presents the asymptotic characteristics of the ACR, by which we get the result on the asymptotic performance of EAs.
Proposition 1. If , there exists such that
- 1.
, ;
- 2.
, .
Proof. By Lemma 1, we know
, there exists
such that
From the fact that the transition submatrix
of an RSH is upper triangular, we conclude
While
, it holds
Then, Equation (
28) implies that
Applying it to (
27) for
, we have
which proves the first conclusion.
Noting that the tail probability
can be taken as the expected approximation error of an optimization problem with an error vector
by (
29) we have
The second conclusion is proven. □
By Definition 2 and Proposition 1, we get the following theorem for comparing the asymptotic performance of and .
Theorem 3. If , the asymptotically outperforms on problem (1). Proof. The proof can be completed by applying Theorem 2 and Proposition 1. □
On condition that
, Theorem 3 indicates that after sufficiently many number of iterations,
can performs better on problem (
1) than
. A further question is whether
outperforms
for
. We answer the question in next sections.
6. Comparison of the Two EAs on OneMax
In this section, we show that the outperformance introduced by binomial crossover can be obtained for the uni-modal OneMax problem based on the following lemma [
29].
Lemma 2 ([
29], Theorem 3).
Letwhere , . If transition matrices and satisfy For the EAs investigated in this study, conditions (
30)–() are satisfied thanks to the monotonicity of transition probabilities.
Lemma 3. When (), and are monotonously decreasing in l.
Proof. When
, Equations (
13) and (
14) imply that
all of which are not greater than 1 when
. Thus,
and
are monotonously decreasing in
l. □
Lemma 4. For the OneMax problem, and are decreasing in j.
Proof. We validate the monotonicity of for , and that of can be confirmed in a similar way.
Let
. By (
21) we know
where
. Moreover, (
33) implies that
and we know
From (
35)–(
38) we conclude that
Similarly, we can validate that
In conclusion, and are monotonously decreasing in j. □
Theorem 4. On condition that , it holds for the OneMax problem that Proof. Given the initial distribution
and transition matrix
, the level distribution at iteration
t is confirmed by
By premultiplying (
39) with
and
, respectively, we get
Meanwhile, by Theorem 2 we have
and Lemma 4 implies
Then, (
42)–(
44) validate satisfaction of conditions (
30)–(), and by Lemma 2 we know
Then, we get the conclusion by Definition 2. □
The above theorem demonstrates that the dominance of transition matrices introduced by the binomial crossover operator leads to the outperformance of on the uni-modal problem OneMax.
7. Comparison of the Two EAs on Deceptive
In this section, we show that the outperformance of over may not always hold on Deceptive. Then, we propose an adaptive strategy of parameter setting arising from the theoretical analysis, with which performs better in terms of tail probability.
7.1. Numerical Demonstration for Inconsistency between the Transition Dominance and the Algorithm Outperformance
For the Deceptive problem, we first present a counterexample to show even if the transition matrix of an EA dominates another EA, we cannot conclude that the former EA outperforms the latter.
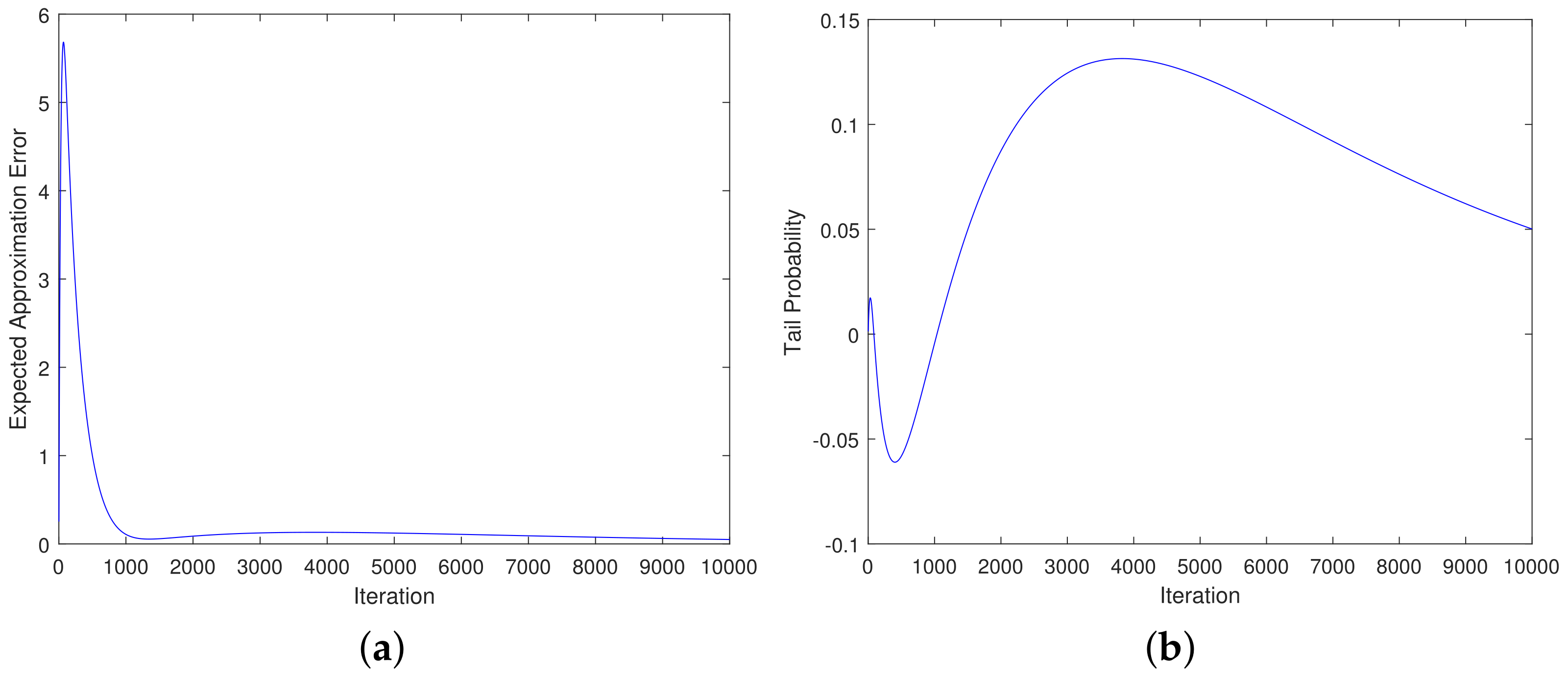
Example 4. We construct two artificial Markov chains as the models of two EAs. Let and be two EAs starting with an identical initial distribution and the respective transition matrices are Obviously, it holds . Through computer simulation, we get the curve of EAE difference of the two EAs in Figure 1a and the curve of TPs difference between the two EAs in Figure 1b. From Figure 1b, it is clear that does not always outperform because the difference of TPs is negative at the early stage of the iteration process but later positive. Now we turn to discuss and on Deceptive. We demonstrate may not outperform over all generations although the transition matrix of dominates that of .
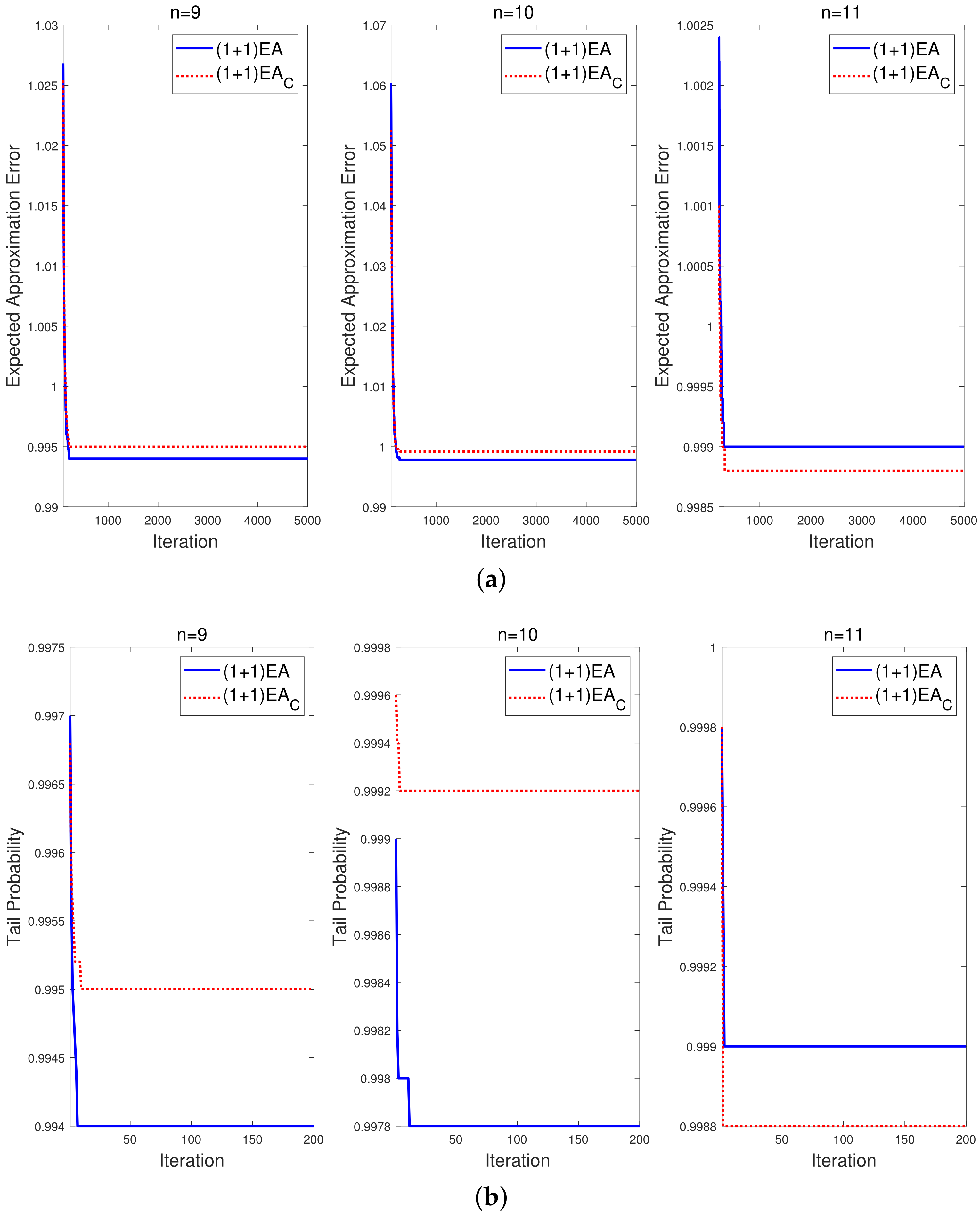
Example 5. In and , set . For , let , . The numerical simulation results of EAEs and TPs for 5000 independent runs are depicted in Figure 2. It is shown that when , both EAEs and TPs of could be smaller than those of . This indicates that the dominance of the transition matrix does not always guarantee the outperformance of the corresponding algorithm. With , although the binomial crossover leads to transition dominance of over , the enhancement of exploitation plays a governing role in the iteration process. Thus, the imbalance of exploration and exploitation leads to poor performance of at some stage of the iteration process. As shown in the previous two examples, the outperformance of cannot be drawn from the dominance of transition matrices.
The fitness landscape of Deceptive confirms that global convergence of EAs on Deceptive is principally attributed to the direct transition from level j to level 0, quantified by the transition probability . By investigating the impact of binomial crossover on the transition probability , we arrive at an adaptive strategy for the regulation of the mutation rate and the crossover rate, by which performance of both and are enhanced.
7.2. Comparisons on the Probabilities to Transfer from Non-Optimal Statuses to the Optimal Status
A comparison between
and
is performed by investigating their monotonicity. Substituting (
13) and (
14) into (
23) and (
24), respectively, we have
We first investigate the maximum values of to get the ideal performance of on the Deceptive problem.
Theorem 5. gets its maximum values .
Proof. While
,
gets its maximum value
□
Influence of the binomial crossover on is investigated on condition that . By regulating , we compare with the maximum value of .
Theorem 6. On condition that , the following results hold.
- 1.
.
- 2.
If , ; otherwise, .
- 3.
, if ; otherwise, .
- 4.
if , ; otherwise, .
Proof. Note that degrades to when . Then, if the maximum value of is obtained by setting , we have ; otherwise, it holds .
- (1)
For the case that
, Equation () implies
Obviously,
is monotonously increasing in
. It gets the maximum value while
. Then, by (
45) we get
.
- (2)
While
, by () we have
If , is monotonously increasing in , and gets its maximum value while . For this case, we know .
While
,
gets its maximum value
by setting
Then, we have .
- (3)
For the case that
, we denote
where
While , both and are increasing in . For this case, gets its maximum value when , and we have .
If
,
gets its maximum value when
, and
gets its maximum value when
. Then,
get its maximum value
at some
Accordingly, we know .
If
,
gets its maximum value when
, and
is monotonously increasing in
. Then,
get its maximum value
at some
and we know
.
- (4)
While
, Equation () implies that
Denoting
we can confirm the sign of
by considering
While
,
is monotonously decreasing in
, and its minimum value is
The maximum value of
is
- (a)
If
, we have
Thus, , and is increasing in . For this case, get its maximum value when , and we have .
- (b)
If
,
gets the maximum value
when
Thus, .
- (c)
If , , and then, is decreasing in . Then, its maximum value is obtained by setting , and we know .
While
,
is increasing in
, and its maximum value is
Then, is monotonously decreasing in , and its maximum value is obtained by setting . Accordingly, we know .
In summary, while ; otherwise, .
□
Theorems 5 and 6 present the “best” settings to maximize the transition probabilities from non-optimal statuses to the optimal level, by which we get a parameter adaptive strategy that greatly enhances the exploration of compared EAs.
7.3. Parameter Adaptive Strategy to Enhance Exploration of EAs
Since the level index j is equal to the Hamming distance between and , improvement of level index j is bounded by reduction of the Hamming distance obtained by replacing with . Then, while the local exploitation leads to a transition from level j to a non-optimal level i, the practically adaptive strategy of parameters can be obtained according to the Hamming distance between and .
When
is located at the solution
at status
j, Equation (
47) implies that the “best” setting of mutation rate is
. Once it transfers to solution
at status
, the “best” setting changes to
. Then, the difference of “best” settings is
, bounded from above by
. Accordingly, the mutation rate of
can be updated to
For
, the parameter
is adapted using the strategy consistent to that of
to focus on influence of
. That is,
Since demonstrates different monotonicity for varied levels, one cannot get an identical strategy for the adaptive setting of . As a compromise, we would like to consider the case that , which is obtained by random initialization with overwhelming probability.
According to the proof of Theorem 6, we know
should be set as great as possible for the case
; while
,
is located in intervals whose boundary values are
and
, given by (
49) and (
50), respectively. Then, while
is updated by (
52), the update strategy of
can be confirmed to satisfy that
Accordingly, the adaptive setting of
could be
where
is updated by (
52).
By incorporating the adaptive strategy (
51) to
, we compare the performance of its adaptive variant with the adaptive
that regulates its mutation rate and crossover rate by (
52) and (
53), respectively. For 13–20 dimensional Deceptive problems, numerical simulation of the tail probability is implemented by 10,000 independent runs. The initial value of
is set as
. To investigate the sensitivity of the adaptive strategy on initial values of
, the mutation rate
in
is initialized with values
,
and
, and the corresponding variants are denoted by
,
and
, respectively.
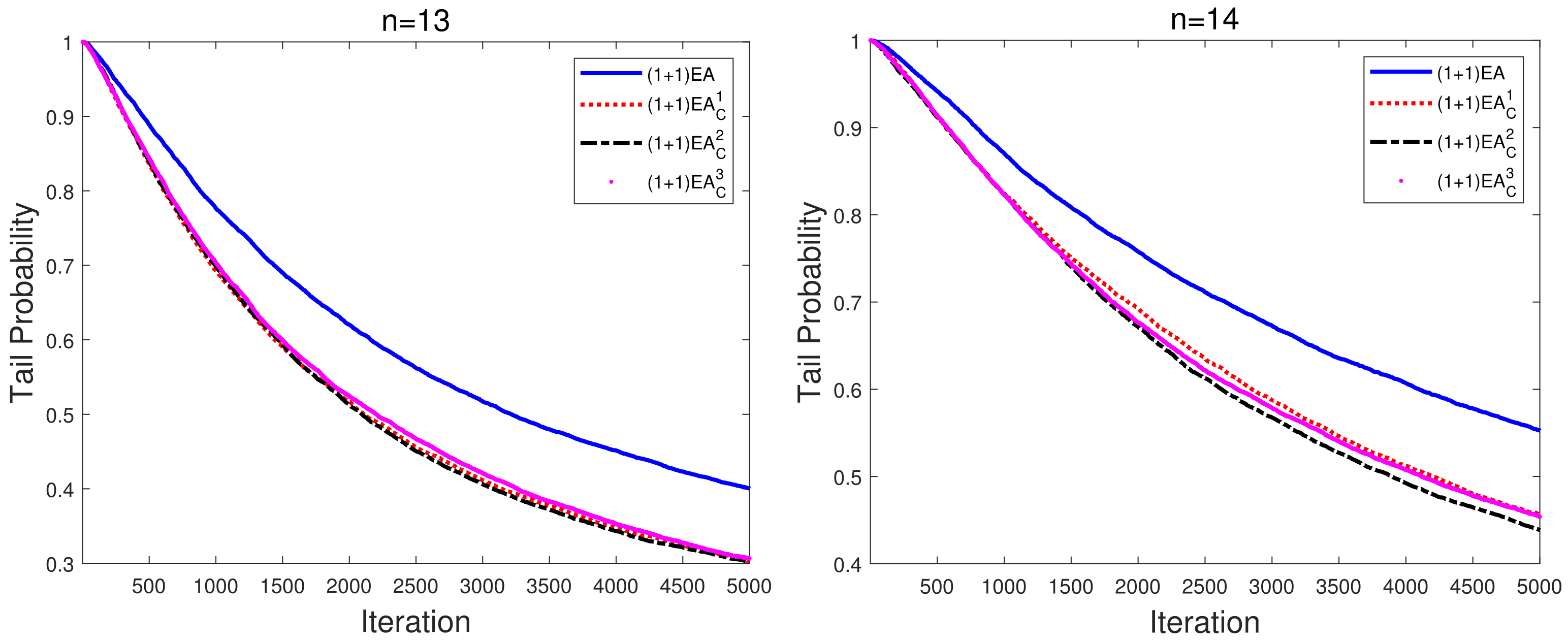
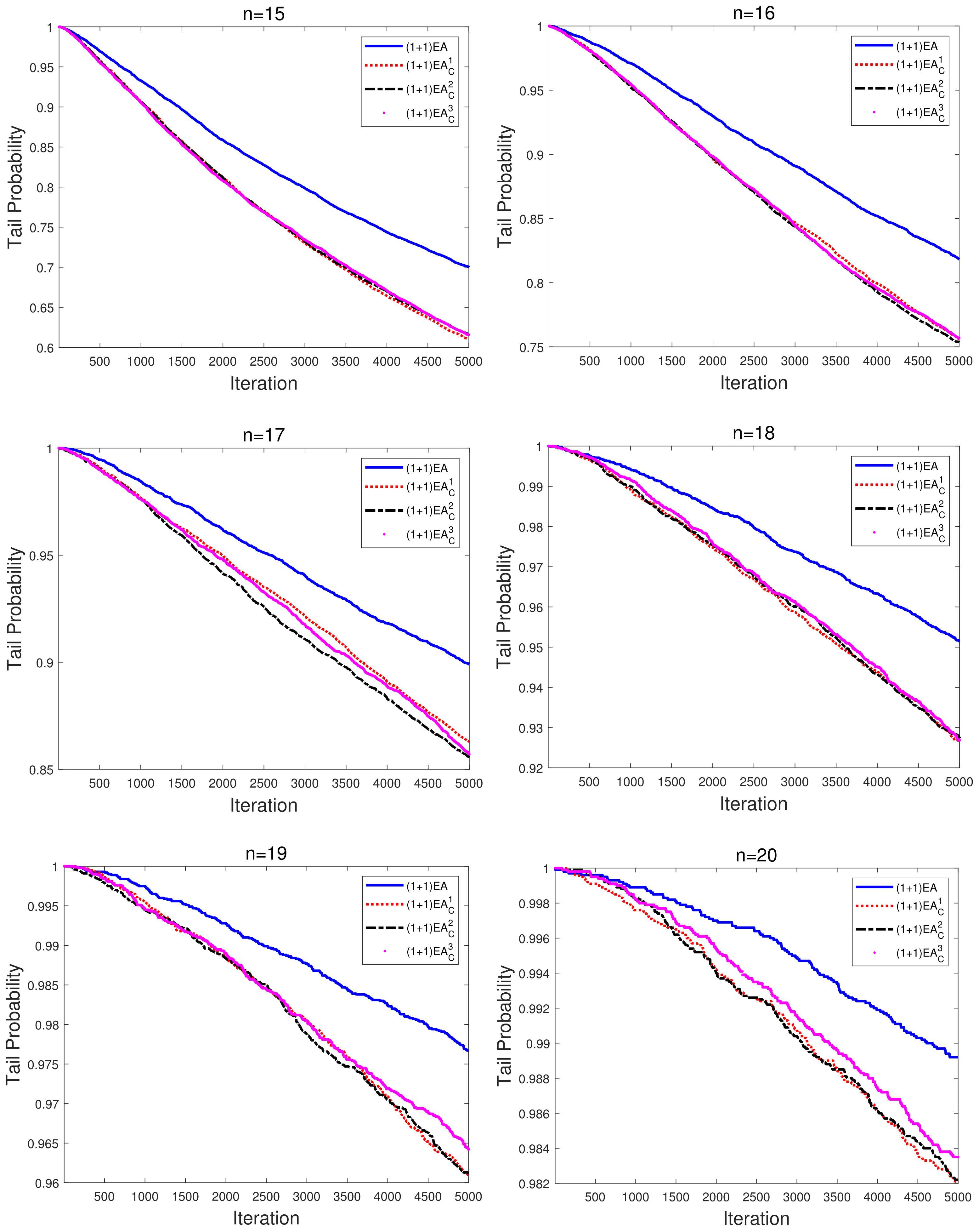
The converging curves of averaged TPs are illustrated in
Figure 3. Compared to the EAs with fixed parameters during the evolution process, the performance of the adaptive EAs on Deceptive has been significantly improved. Furthermore, we also note that the converging curves of adaptive
are not sensitive to the initial mutation rate. Although transition dominance does not necessarily lead to outperformance of
over
, the proposed adaptive strategy can greatly enhance global exploration of
to a large extent, and consequently, we get the improved adaptive
that is not sensitive to initial mutation rates.
8. Conclusions and Discussions
Under the framework of fixed-budget analysis, we conduct a pioneering analysis of the influence of binomial crossover on the approximation error of EAs. The performance of EAs after running finite generations is measured by two metrics: the expected value of the approximation error and the error tail probability, by which we make a case study by comparing the performance of and with binomial crossover.
Starting from the comparison of the probability of flipping “l preferred bits”, it is proven that under proper conditions, incorporation of binomial crossover leads to the dominance of transition probabilities, that is, the probability of transferring to any promising status is improved. Accordingly, the asymptotic performance of is superior to that of .
It is found that the dominance of transition probability guarantees that outperforms on OneMax in terms of both expected approximation error and tail probability. However, this dominance does lead to the outperformance on Deceptive. This means that using binomial crossover may improve the performance on some problems but not on other problems.
For Deceptive, an adaptive strategy of parameter setting is proposed based on the monotonicity analysis of transition probabilities. Numerical simulations demonstrate that it can significantly improve the exploration ability of both and , and superiority of binomial crossover is further strengthened by the adaptive strategy. Thus, a problem-specific adaptive strategy is helpful for improving the performance of EAs.
Our future work will focus on a further study for the adaptive setting of crossover rate in population-based EAs on more complex problems, as well as the development of adaptive EAs improved by the introduction of binomial crossover.




{kind=link}
{kind=link}
{kind=link}
{kind=link}



