1. Introduction
Let us suppose we have two independent random samples
and
, which are drawn from two normal distributions,
and
, respectively. The Behrens–Fisher problem occurs when testing the equality of the two means
and
based on random samples like these without the assumption that the two variances,
and
, are equal. [
1] showed that a uniformly most powerful test does not exist in this case, and the Behrens–Fisher problem remains one of the unsolved problems of statistics. Many different approaches have been tried to solve this problem. Among those approaches are the fiducial approach proposed by [
2,
3], which somehow opened the way to the Bayesian approach proposed by [
4,
5], based on setting independent and locally uniform prior distributions for
. The frequentist approach proposed by [
6,
7] uses Student’s
t distribution with
degrees of freedom as the approximate distribution of the Behrens–Fisher statistic.
In this paper, we will obtain the exact and near-exact distributions, both the probability density function and cumulative distribution function, of the Behrens–Fisher statistic,
under
, where
and
for
, in the form of mixtures of Student’s
t distributions multiplied by constants. Particularly for the case when both sample sizes are odd, the exact distribution will be derived in a finite closed form without any unsolved integrals or infinite sums by using the GIG (generalized integer gamma) distribution in [
8], which is the distribution of the sum of independent gamma variables with integer shape parameters and nonequal rate parameters. For the other cases, that is, when both sample sizes are even or one of them is even and the other one is odd, the near-exact distribution will be obtained by approximating the exact distribution using a finite mixture of GIG distributions to obtain a more manageable cumulative distribution function. Such exact and near-exact distributions include
and
as unknown parameters, which have to be estimated, based on the observed samples, being then the
p-values obtained from these exact or near-exact distributions with estimated parameters. The results will be compared with Welch’s
t-test, one of the most widely used solutions to the problem, through Monte-Carlo simulations for relatively small sample sizes. We will see that the tests based on the exact or near-exact distribution show some advantage in terms of being able to obtain higher power than Welch’s
t-test, especially when sample sizes are small and unbalanced and variances are also unbalanced.
This paper is organized as follows:
Section 2 presents the exact distribution when both sample sizes are odd;
Section 3 provides the near-exact distribution when one sample size is even and the other one odd, and
Section 4 presents the exact near-exact distribution of the test statistic when both sample sizes are even. Numerical studies are provided in
Section 5 to compare the exact and the near-exact distribution approaches with Welch’s
t-test, and concluding remarks are presented in
Section 6.
2. The Exact Distribution of the Behrens–Fisher Statistic
for Odd-Numbered Sample Sizes
In this section, we present the exact distribution of the Behrens–Fisher statistic in (
1), when both
and
are odd. Since
where
is the sum of two independent gamma variables, each of which follows the distributions
and
, where
indicates a gamma distribution with shape parameter
and rate parameter
.
Now, we can divide the problem into two cases: one is the case of
, and the other is the case
. When
follows a GIG distribution of depth 2 with shape parameters
and rate parameters
, which are different. Notice that
and
are both integers because of odd-numbered sample sizes. The probability density function for this distribution is
where
are given by (11)–(13) in [
8]. In this case,
and
for
.
As a matter of fact, this probability density function can be rewritten as
which is a finite mixture of integer gamma distributions in [
9]. Now that we have obtained the exact distribution of
W, we can easily get the joint distribution of
W and
, under
.
Y follows a normal distribution
under
, and so, given the independence of
W and
Y, the joint probability density function of these two random variables is
where
and
is the probability density function of a standard normal distribution.
Since we want to derive the distribution of
, we need to go further and obtain the joint distribution of
and
from
by a simple change of variables. From this process, we obtain
for
and
and
where
yields the probability density function of a
random variable, with
denoting a Student’s
t distribution with
degrees of freedom.
Hence,
is a mixture of probability density functions of
random variables
, with weights
. Given that the probability density function of Student’s
t variable with
n degrees of freedom is given by
for
, the probability density function of
, under
, can be rewritten as
for
.
Then, the cumulative distribution function of
would also be a mixture of cumulative distribution functions of
with weights
. For Student’s
t distribution with even degrees of freedom, the cumulative distribution function is given by
for
, which is obtained by applying
and
from [
10], where
denotes a Gaussian hypergeometric function.
Thus, the cumulative distribution function of
, under
, can be expressed as
for
.
The distribution of
is much simpler when
Since the rate parameters of the two independent gamma variables,
and
, are, in this case, equal,
W simply follows the gamma distribution
. Therefore, in this case,
. This means that the probability density function and cumulative distribution function of
are the same as those of Student’s
distribution with
degrees of freedom. The probability density function for this distribution is written as
for
.
Additionally, as
is an even number when sample sizes are odd-numbered, the cumulative distribution function can be written as
for
.
3. The Exact and Near-Exact Distribution of the Behrens–Fisher Statistic
for Even-Numbered Sample Sizes
In this section, we present the exact distribution of when sample sizes are both even. The exact distribution consists of an infinite series, but we provide a near-exact distribution based on a finite mixture of GIG distributions, which yields an approximation to the exact distribution.
3.1. The Exact Distribution
Unlike the case where both sample sizes are odd, does not follow a GIG distribution when both sample sizes are even. This is so because the shape parameters for and are not integers when sample sizes are even. However, we can use the Kummer confluent hypergeometric function to obtain the exact distribution of W for this case.
Given the integral definition of the Kummer confluent hypergeometric function, the probability density function of
W, which is the sum of two independent gamma variables with shape parameters
and rate parameters
can be expressed as
for
.
Since
the probability density function of
W can be further written as
for
, which is the probability density function of an infinite mixture of gamma distributions with weights
. Now, using a similar approach to the one used in
Section 2 for the case of odd-numbered sample sizes, we can obtain the exact probability density function of
under
in the form of an infinite mixture of probability density functions of
distributions, with weights
, for
. The probability density function of
may be then stated as follows:
for
.
Regarding the exact cumulative distribution function of
, under
, this cumulative distribution function would also be an infinite mixture of cumulative distribution functions of
distributions, with weights
, for
. It can be written as
for
, where
,
, by applying the expression for
obtained in
Section 2.
As the exact cumulative distribution function of is expressed as an infinite sum when , it is not much of a manageable cumulative distribution function. In order to obtain numerical values of this cumulative distribution function in a reasonable amount of time, use of an integer upper bound for the summation in i is required. However, the number of terms required in order to obtain a small enough truncation error is often very large. Hence, a near-exact distribution of with a manageable cumulative distribution function needs to be obtained for the case where so that quantiles and p-values can be computed in a faster and more practical way.
3.2. Near-Exact Distribution
In order to obtain a near-exact distribution for , based on a finite mixture, we will first obtain a near-exact distribution for W and then derive the distribution of from this distribution of W.
Let
, and let
. Then, the exact characteristic function of
W is given by
where
is the imaginary number with
. Since
is the characteristic function of the sum of two independent gamma variables
and
, we can make use of the probability density function of
W expressed as an infinite mixture of probability density functions of gamma distributions obtained in
Section 3.1 to write
where
. This leads to
Now, for a given integer
, we propose to approximate
by
where
are determined in such a way that satisfies
with
. This approximate characteristic function
is, in fact, the characteristic function of a finite mixture (with weights
) of
GIG distributions of depth 2 with integer shape parameters
and rate parameters
and
, the first
moments of which are the same as those of
W.
Hence, a finite mixture of probability density functions of
GIG distributions with weights
for
will then be a near-exact probability density function of
W. As the GIG distribution itself is a finite mixture of gamma distributions, as shown in
Section 2, this probability density function can be written as
for
, where
for
and
are defined in the same way as
in
Section 2, except here we use
instead of
.
From this near-exact probability density function of
W, using the same logic as before just like in
Section 2 and
Section 3.1, we can obtain a near-exact probability density function of
in the form of a finite mixture of probability density function
of
with weights
. Thus, the near-exact probability density function under
is given as follows:
for
. Naturally, the corresponding near-exact cumulative distribution function of
would be a finite mixture of cumulative distribution function
of
with weights
, which can be written as
for
, by applying
obtained in
Section 2.
4. One of the Sample Sizes Is Even and the Other Is Odd
The exact distribution of the Behrens–Fisher statistic
for this case is given by the same expressions used in
Section 3.1. Just like the case of even-numbered sample sizes, the exact cumulative distribution function is not that manageable for usage when
in this case, too. Hence there is a need to obtain a near-exact distribution of
with a manageable cumulative distribution function for faster and more practical computation of quantiles and
-values.
As we did in
Section 3.2, we will first obtain a near-exact distribution for
W, and then we will derive the near-exact distribution for
from the distribution of
W. Let, without any loss of generality,
be even and
be odd. Additionally, let
, which is equivalent to
, and let
. Then, for
and
as defined in (
2) and (
3), the exact characteristic function of
W can be written as
where
is the characteristic function of a GIG distribution of depth 2 with integer shape parameters
and
and rate parameters
and
, while
is the characteristic function of a
distribution. Now, for a given
, we propose to approximate
by
where
are determined in such a way that
with
.
The characteristic function is the characteristic function of a finite mixture of distributions, which are distributions . The first moments of this mixture are the same as those of .
We should note that the weights
do not depend on
. The
h-th non-central moment of
and of the mixture of
distributions are, respectively, given by
which means
are determined in such a way that satisfies
for
, definitely not depending on
.
By using
instead of
, we can then approximate
with
which is the characteristic function of a finite mixture of
distributions of depth 3 with shape parameters
and rate parameters
.
Thus, a finite mixture of
probability density functions
s of
distributions of depth 3 with weights
can be a near-exact probability density function of
W. As GIG distribution itself is a finite mixture of gamma distributions, this near-exact probability density function of
W is written as
where
and
are given by (11)–(13) in [
8] using
and
, which are
where
and
. From this near-exact probability density function of
W, using the same logic as before, we can once again obtain a near-exact probability density function of
in the form of a finite mixture of probability density functions of
distributions, with weights
. The near-exact probability density function of
, under
, is thus given by
for
.
Hence, the corresponding near-exact cumulative distribution function of
, under
, is also a finite mixture of cumulative distribution functions of
, with weights
, which can be written as
for
by applying
obtained in
Section 2.
5. Comparison of the Exact or Near-Exact Distribution and Welch’s t Test
When it is plausible to assume that
, that is, that
, we can make use of the exact and near-exact distribution of
to solve the Behrens–Fisher problem. The exact cumulative distribution function of
will be used for computation of
p-values when both sample sizes are odd, while the near-exact cumulative distribution functions obtained in
Section 3 and
Section 4 will be used for computing
p-values when both sample sizes are even or when one of the sample sizes is even and the other is odd. Because the cumulative distribution functions of
include the unknown parameters
and
, these will be estimated by the sample variances
.
We will compare the exact or near-exact distributions and Welch’s
t-test by their actual sizes and powers for testing
versus
. For
, since the hypothesis is for the right-tailed test, the corresponding
p-value is computed from
in (
4) or
in (
5) or (
6), depending on the parity of the sample sizes, according to the derivations in the previous sections, and with
estimated by
. We used different type I error rates
and we conducted Monte Carlo experiments under a range of different sets of parameters.
Simulations were conducted for variance and sample size pairs that correspond to
For
, we covered the cases where
satisfies
with
corresponding to the null hypothesis
.
For each combination of parameters, the number of replications was 50,000, and in each subsection, we provide two scenarios: one in which sample sizes were balanced, and another one where they were unbalanced. For each generated sample, we computed
for
50,000 and then obtained the type I error under
and the power under
from
where
is the indicator function and the
p-value
is computed using
in (
4) for the case of both odd sample sizes or
in (
5) or (
6) when at least one of the sample sizes is even.
All computations were done with the software R, version 4.1.0.
5.1. Odd n1 and n2
In
Table 1 and
Table 2, we present the power values for the exact distribution and Welch’s test, represented, respectively, by E and W. We considered for
and
the sets of values indicated above.
We may see that when sample sizes are unbalanced, as in
Table 2, the exact distribution gives larger values of power than Welch’s
t-test, namely for larger values of
and smaller values of
, while they tend to give similar results when the two sample sizes are homogeneous, still with the exact distribution giving larger power values when the variances are unbalanced. Namely, for the case of
and
and
, the near-exact distribution shows a gain of over 30% in power in relation to Welch’s
t-test for
.
5.2. Even and
Table 3 and
Table 4 provide numerical results for type I error rates and powers for Welch’s
t-test and near-exact distributions that use
for cases where both sample sizes are even. In these tables, the near-exact distributions and Welch’s test are, respectively, denoted by NE and W.
Similar to the case of odd sample sizes, we see that the differences in power between the near-exact distribution and Welch’s
t-test are quite slim when the sample sizes are equal, as shown in
Table 3, although with a tendency for the near-exact distributions to exhibit larger powers when variances are unbalanced, while in the unbalanced case
shown in
Table 4 the power displayed by the near-exact distributions is quite larger, particularly if the variances are also unbalanced. Namely, for the case
and
, the near-exact distribution shows a gain of over 20% in power.
5.3. Is Even and Is Odd
Table 5 displays the case of similar sample sizes, and it shows that once again, the near-exact distribution and Welch’s test are fairly similar to each other in terms of Type I error rates and values of power. On the other hand,
Table 6 presents the results for the unbalanced sample size case, and it shows that the near-exact distribution and Welch’s test can control well the type I error rates, but that the near-exact distribution can obtain larger powers than Welch’s test. In particular, when
and
, the near-exact distribution shows a gain of almost 30% in power in relation to Welch’s
t-test for
. The near-exact distributions and Welch’s test are, respectively, denoted by NE and W in these tables.
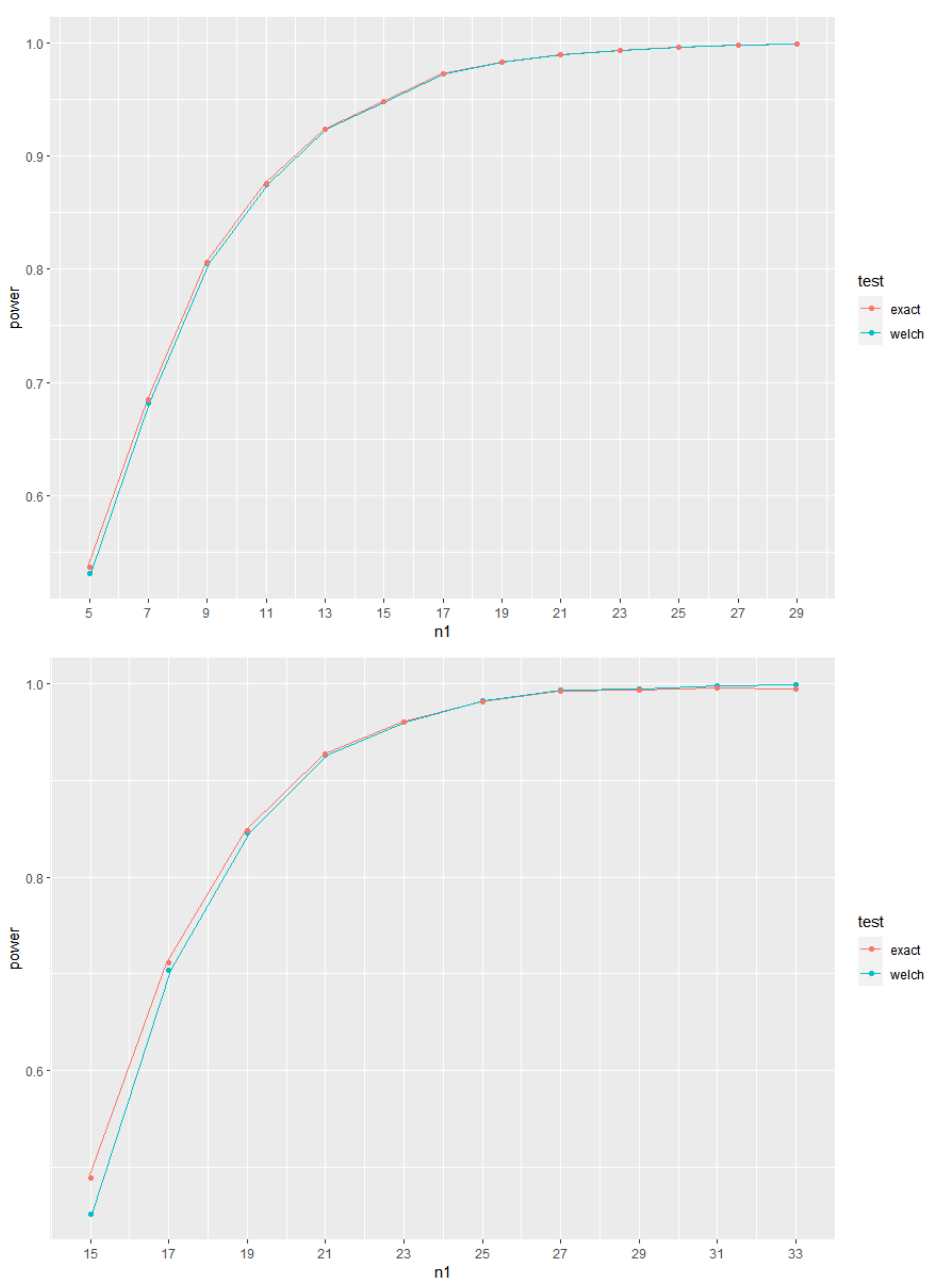
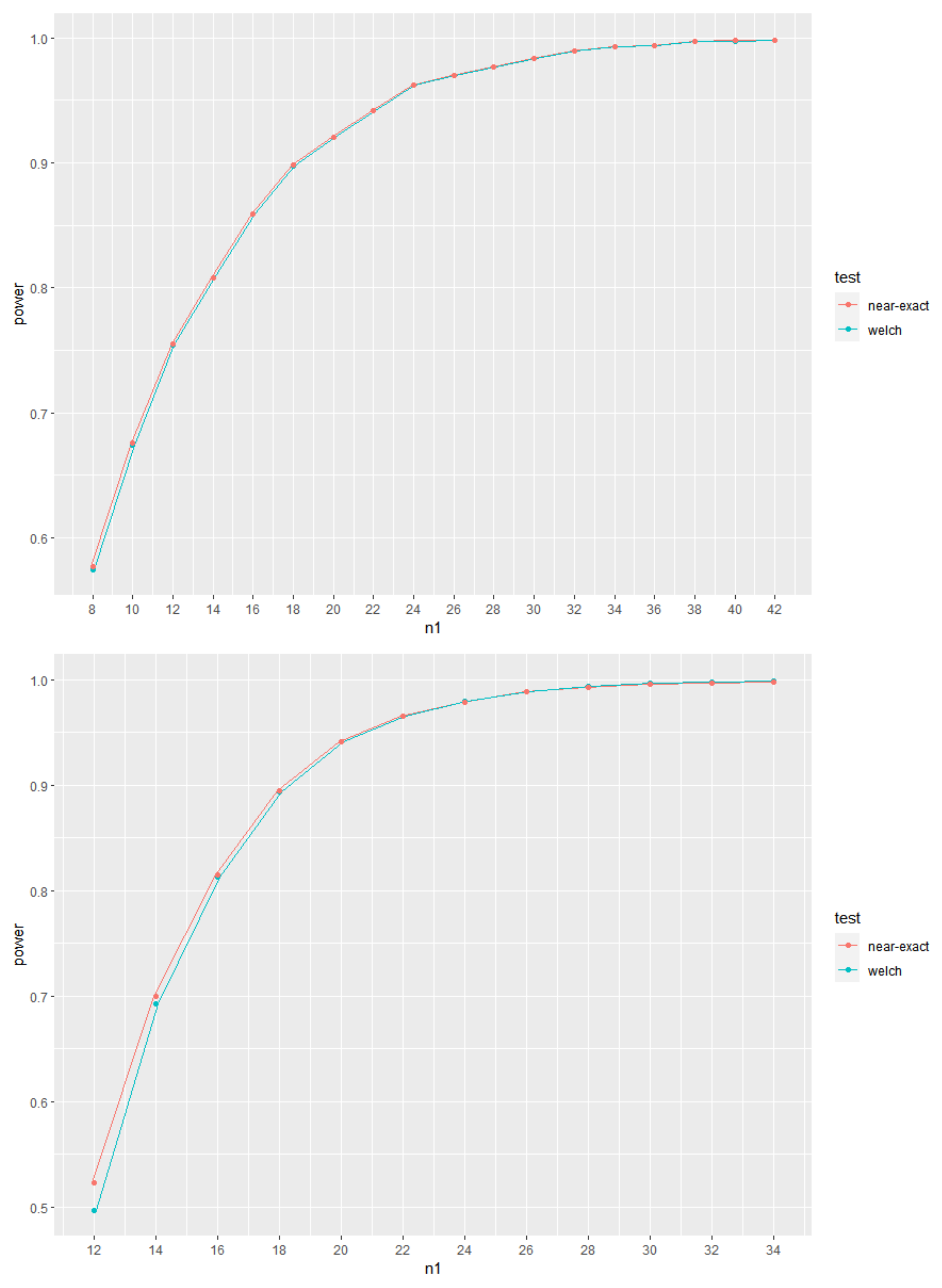
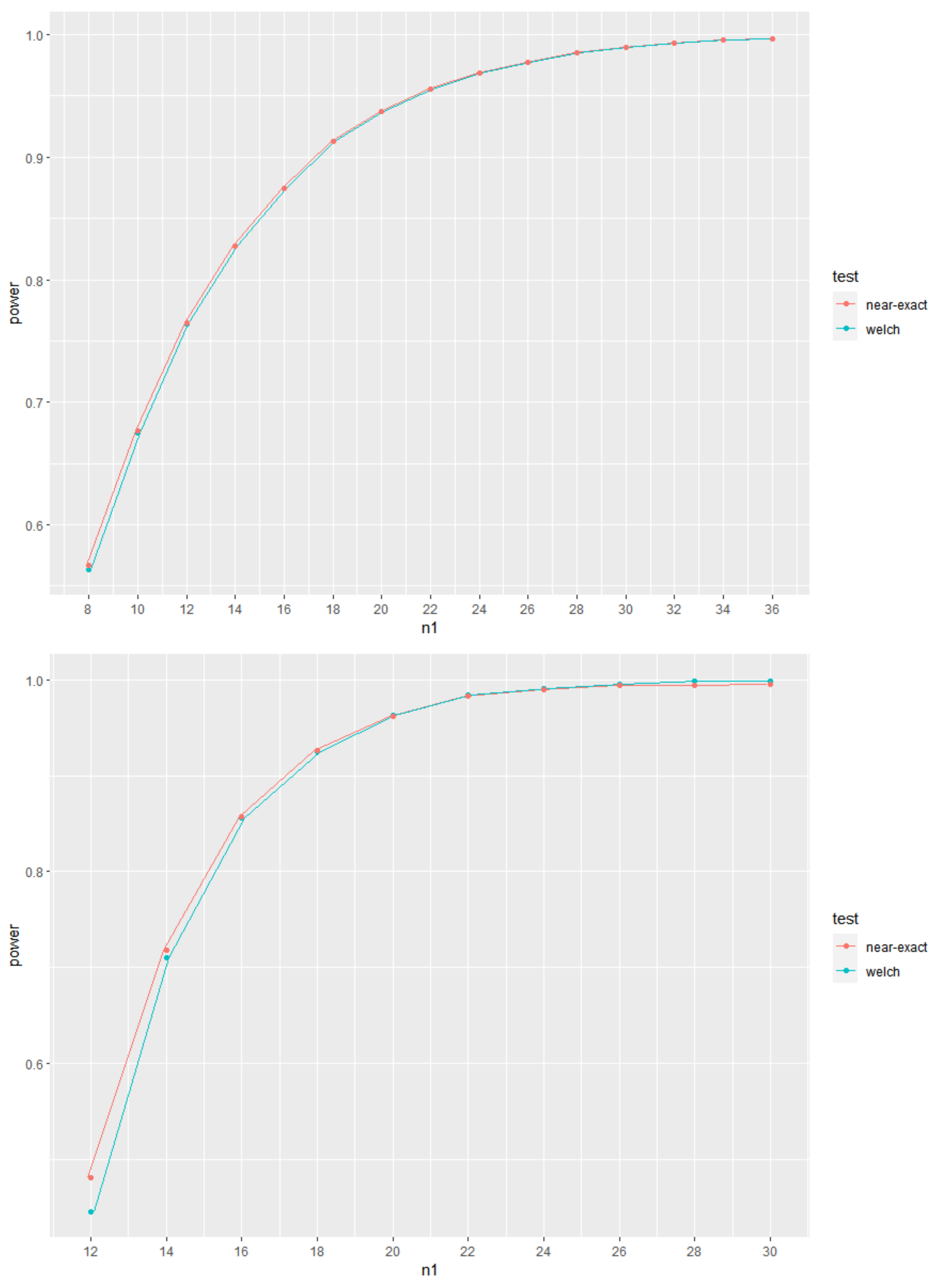
5.4. Brief Study of Power Evolution for Increasing Sample Sizes
With the aim of showing the evolution of the values of power for increasing sample sizes, the plots of power curves for increasing values of the sample sizes are shown in
Figure 1,
Figure 2 and
Figure 3, for given
,
,
and
. As expected, it is clear that the power curves are increasing with increasing values of the sample sizes.
Figure 1,
Figure 2 and
Figure 3 represent, respectively, cases of
,
and
. It is also clear from these Figures that, also as expected, although the use of the exact or near-exact distributions lead to an increase in the values of power, the power values from Welch’s test approach asymptotically those obtained when using the exact or near-exact distributions for increasing sample sizes. In
Figure 1,
Figure 2 and
Figure 3, we use
and present the values of
and
in each figure. In addition, the corresponding values of
are also presented.
6. Conclusions
Over the years since the Behrens–Fisher problem was first introduced, many different solutions have been presented for the problem. In this paper, we propose another approach for the Behrens–Fisher problem that is based on a version of the exact distribution and near-exact distributions for its statistic, which are based on GIG (generalized integer gamma) distributions. Overall, the differences between the sizes of the near-exact distribution and Welch’s t-test are negligible, while the use of the exact or near-exact distributions provide powers that are larger than those provided by Welch’s t-test, mainly for the cases where the sample sizes and/or the variances are unbalanced, and namely when smaller sample sizes are associated with larger variances. The results thus show that, mainly for the cases of unbalanced sample sizes and/or unbalanced variances, the use of Welch’s t-test leads to some loss in power compared with the use of the exact or near-exact distributions developed, thus advising towards the use of these latter ones.
The computation of the exact or near-exact distributions poses absolutely no problems, even for large sample sizes, with the computation times remaining in the hundredths of a second for sample sizes in the order of a few hundreds.
In order to decide which distribution to use, the user may want to test the hypothesis
. We may note that, given the definition of
and
in (
3), testing that hypothesis is indeed equivalent to testinf the hypothesis
which may tested in as much the same way we run a test of equality of two variances based on two independent samples.







{kind=link}
{kind=link}
{kind=link}