
Resource Allocation in V2X Communications Based on Multi-Agent Reinforcement Learning with Attention Mechanism

Abstract
:1. Introduction
1.1. Related Work
1.2. Contribution and Organization
- Due to the mobility of vehicular users, it is not easy to obtain CSI accurately. We propose the framework of MARL to adapt to the changing environment and use only partial CSI for wireless resource allocation to ensure the high rate of V2I links and low latency of V2V links.
- To make each agent more effective in acquiring the state information of other agents in the environment and to establish collaborative relationships, we propose an algorithm of multi-agent deep reinforcement learning with attention mechanism (AMARL) to enhance the sense of collaboration among agents. It also enables agents to obtain more useful information, reduce the signaling overhead, and allocate resources more clearly.
- Experimental results demonstrate that, compared to other baseline schemes, the proposed AMARL-based algorithm can satisfy the requirement of low latency for V2V links and significantly increase the total rate of V2I links. It also has better adaptability to environmental changes.
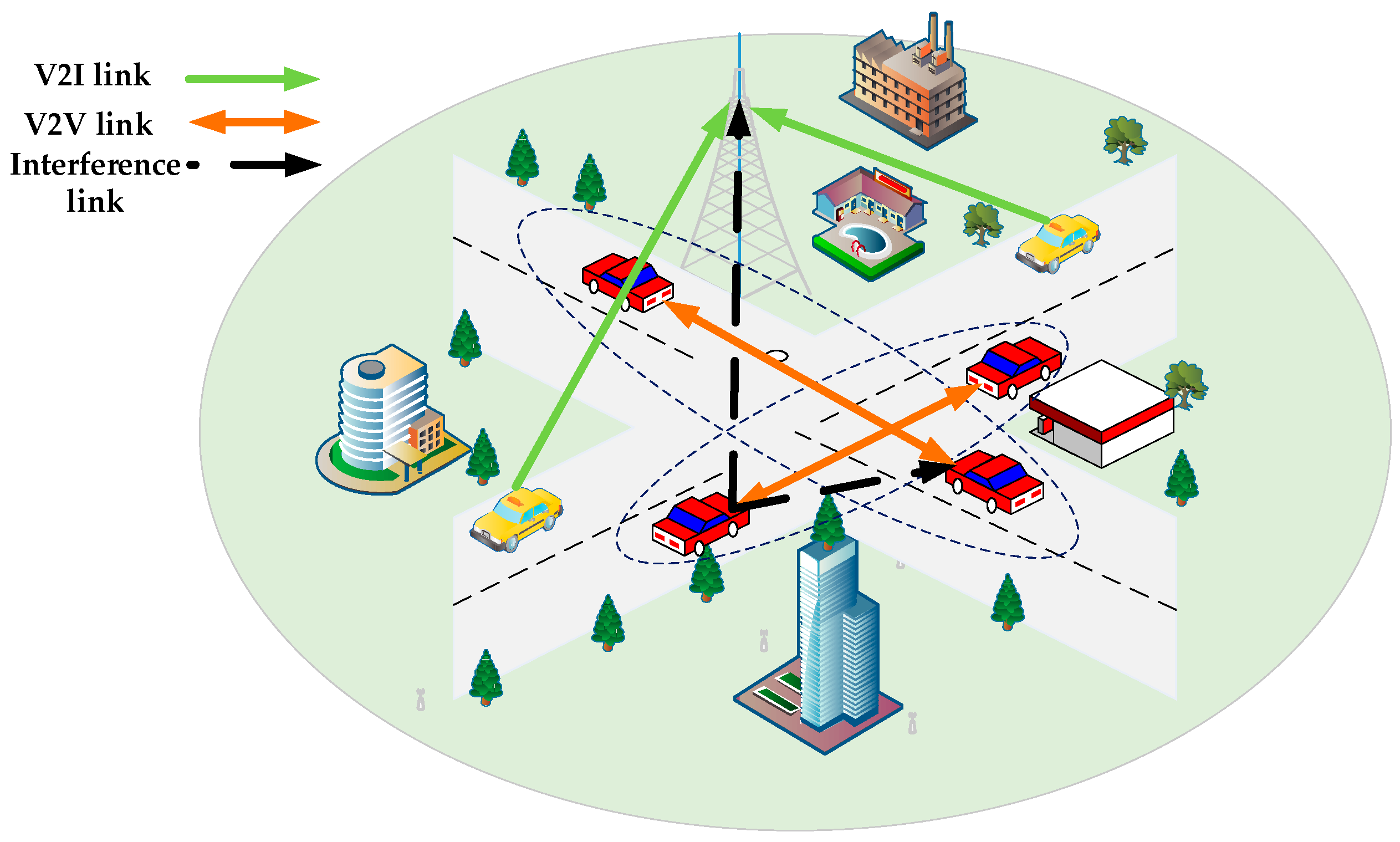
2. System Model
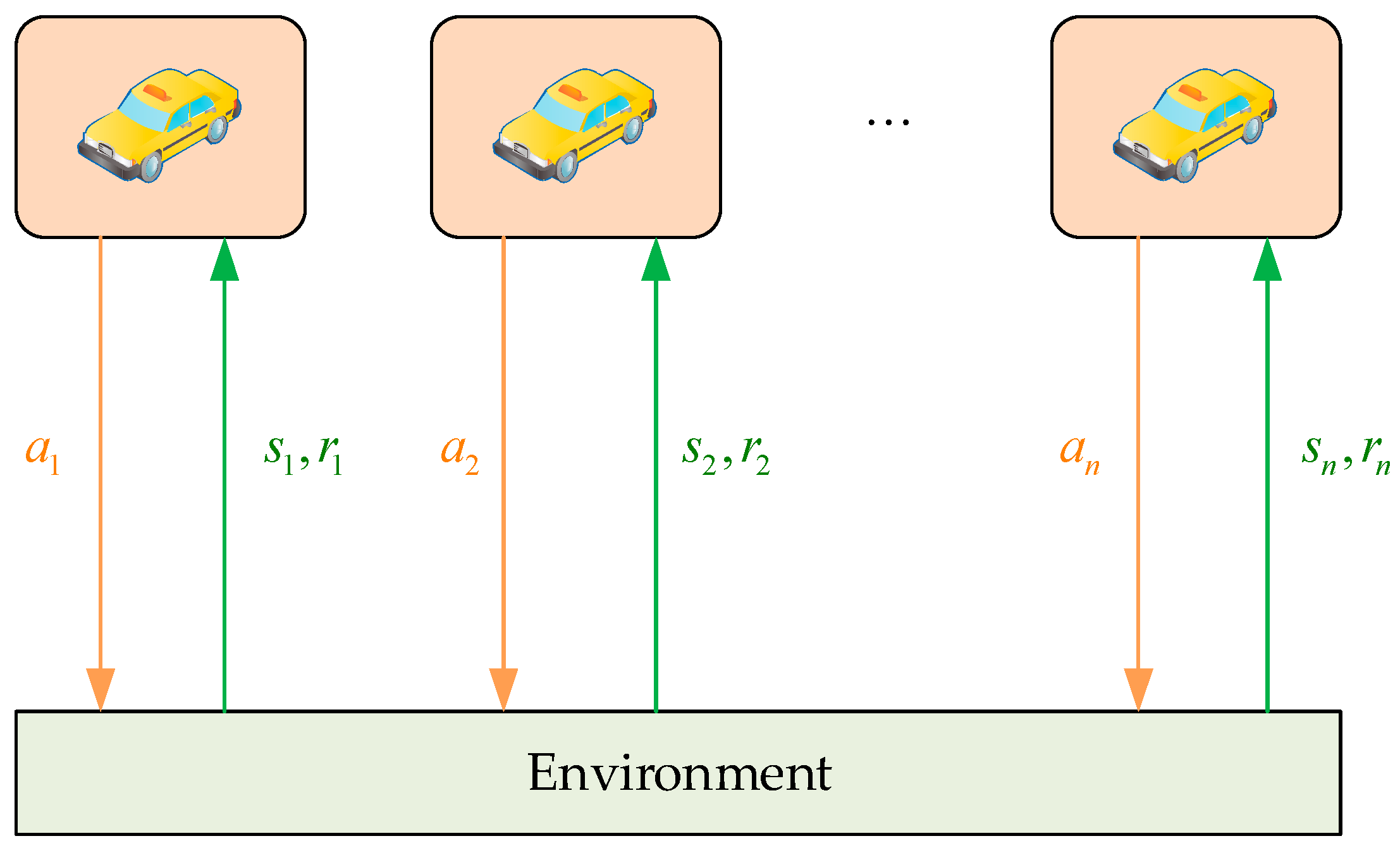
3. Resource Allocation Based on Multi-Agent Reinforcement Learning with Attention Mechanism Algorithm
3.1. Design of Three Elements
3.1.1. Observation Space
3.1.2. Action Space
3.1.3. Rewards Function
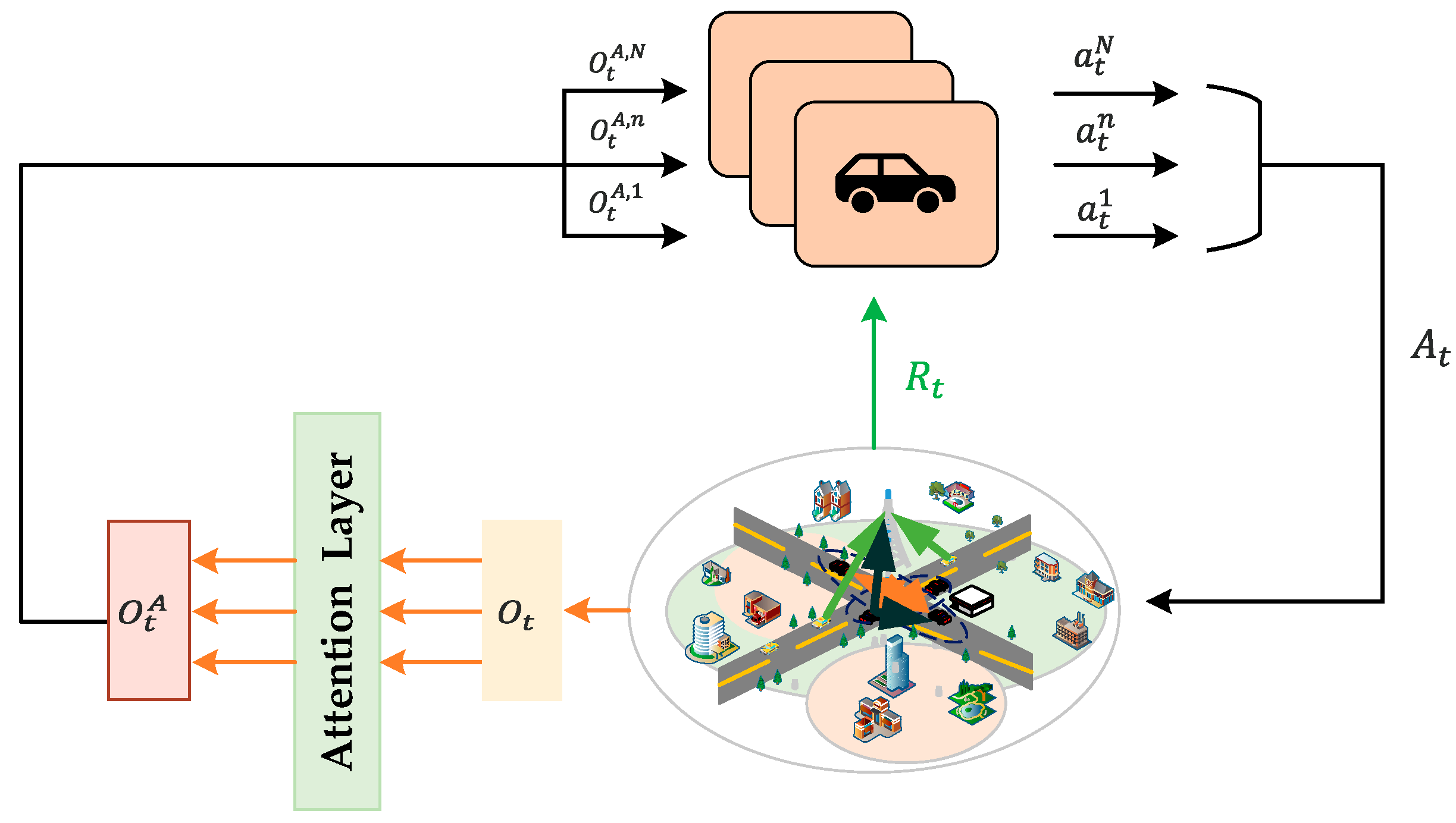
3.2. Algorithmic Framework
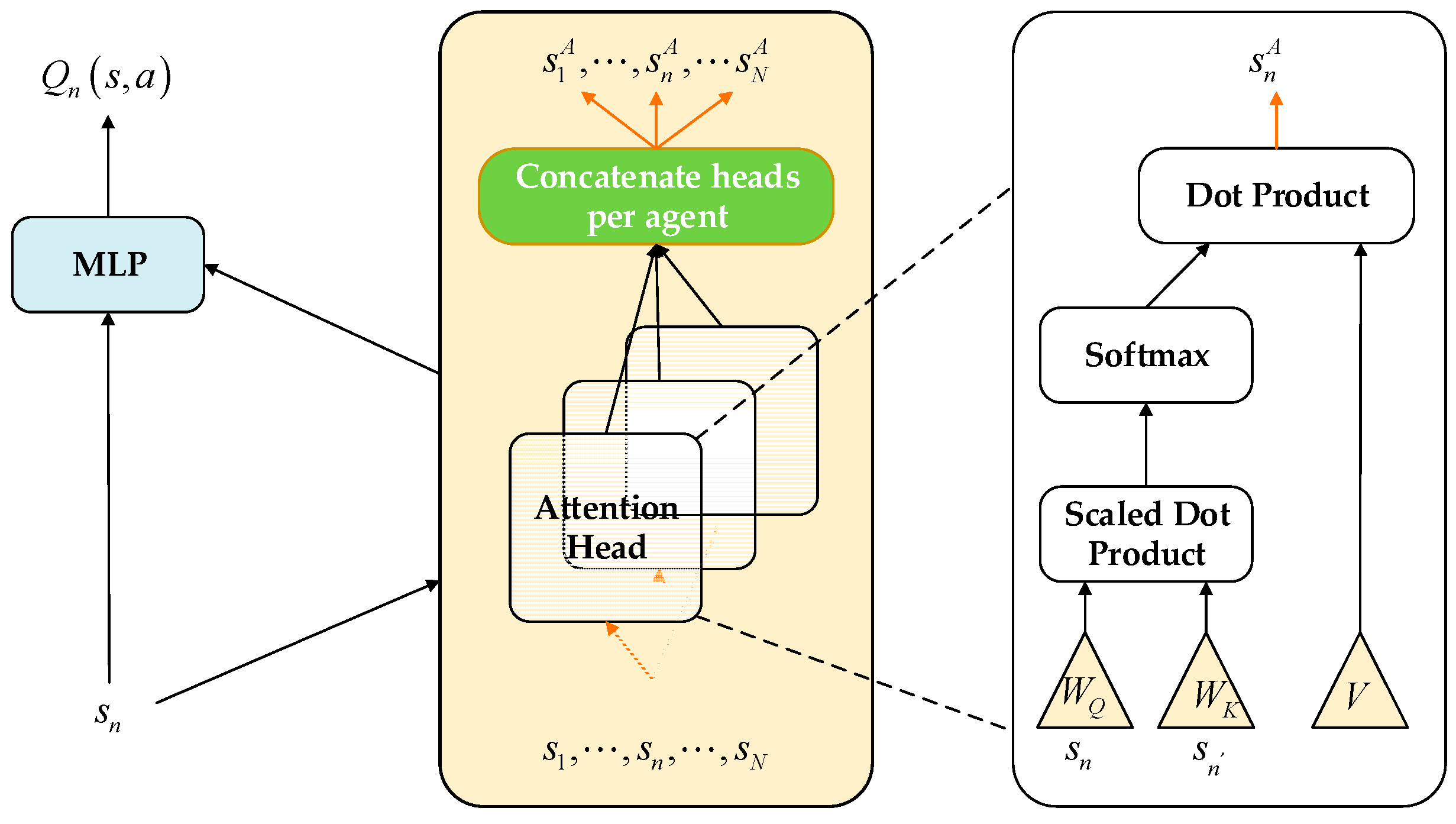
3.2.1. Overview of Attentional Mechanism
3.2.2. Multi-Agent Reinforcement Learning
3.2.3. AMARL Algorithm
- (1)
- Collecting training data:
- (2)
- Updating parameters:
| Algorithm 1 Training Process |
| 1: Input: V2X environment simulator, Attention network model, DQN model, payload size, and maximum tolerant latency 2: Output: AMARL network’s weight 3: Initialize: experience replay array, the parameters of DQN and target DQN 4: for each episode do 5: Update environment; 6: Reset remaining payload and remaining time ; 7: for each step do 8: Observed state of all V2V agents: ; 9: Through the attention network: ; 10: for each V2V agent do 11: Based on add select action according to the ϵ-greed policy; 12: end for 13: All agents take actions and gain shared reward ; 14: Update environment; 15: for each V2V agent do 16: Gain the next moment of observation: ; 17: Store in the experience replay array; 18: end for 19: end for 20: for each V2V agent do 21: Sample a mini-batch experiences from experience replay array ; 22: Update DQN parameter according to (25); 23: Update the target DQN every steps: ; 24: end for 25: end for |
| Algorithm 2 Testing Process |
| 1: Input: V2X environment simulator, AMARL network model 2: Output: All V2V agents actions 3: Start: Load AMARL network model, Start V2X environment simulator 4: for each episode do 5: Update environment; 6: Reset remaining payload and remaining time ; 7: for each step do 8: Observed state of all V2V agents: ; 9: Through the attention network: ; 10: for each V2V agent do 11: Compile the state observation space and select the action with the maximum Q value based on the trained Q network; 12: end for 13: end for 14: end for |
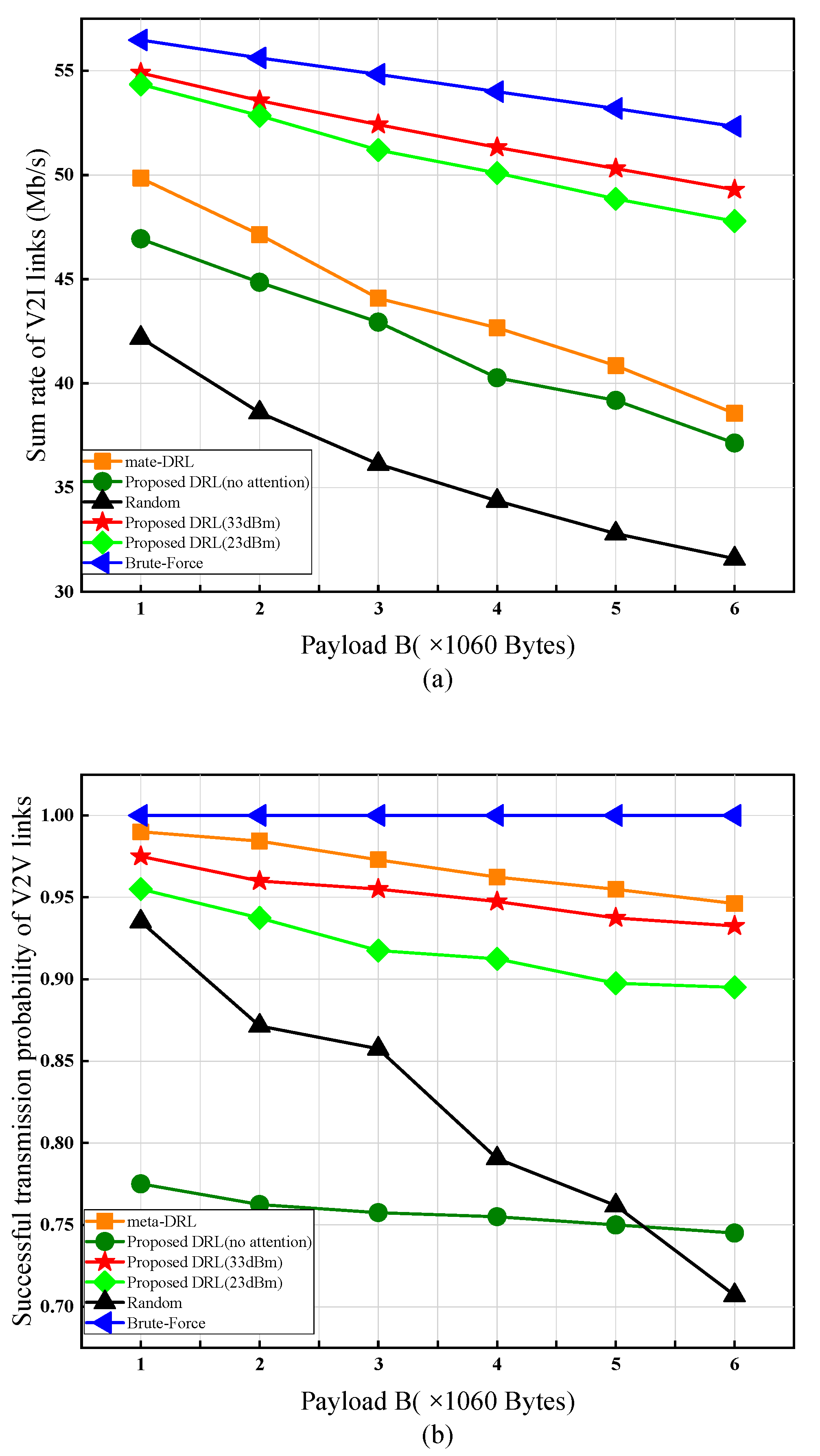
4. Simulation Results
- (1)
- Meta-reinforcement learning [27]: In this scheme, DQN is used to solve the problem of spectrum allocation, deep deterministic policy gradient (DDPG) is used to solve the problem of continuous power allocation, and meta-learning is introduced to make the agent adapt to the changes in the environment.
- (2)
- Proposed RL (no attention): This scheme does not incorporate an attention mechanism, and the agent will obtain the state information of other agents without any difference and then allocate wireless resources.
- (3)
- Brute-Force: This scheme is implemented in a centralized manner and requires accurate CSI. It focuses only on improving the performance of V2Vs, ignoring the need for V2I links, and performs an exhaustive search of the action space of all V2V pairs to maximize V2Vs and rates.
- (4)
- Random: randomizes spectrum and power allocation.
4.1. Impact of Payload Size on Network Performance
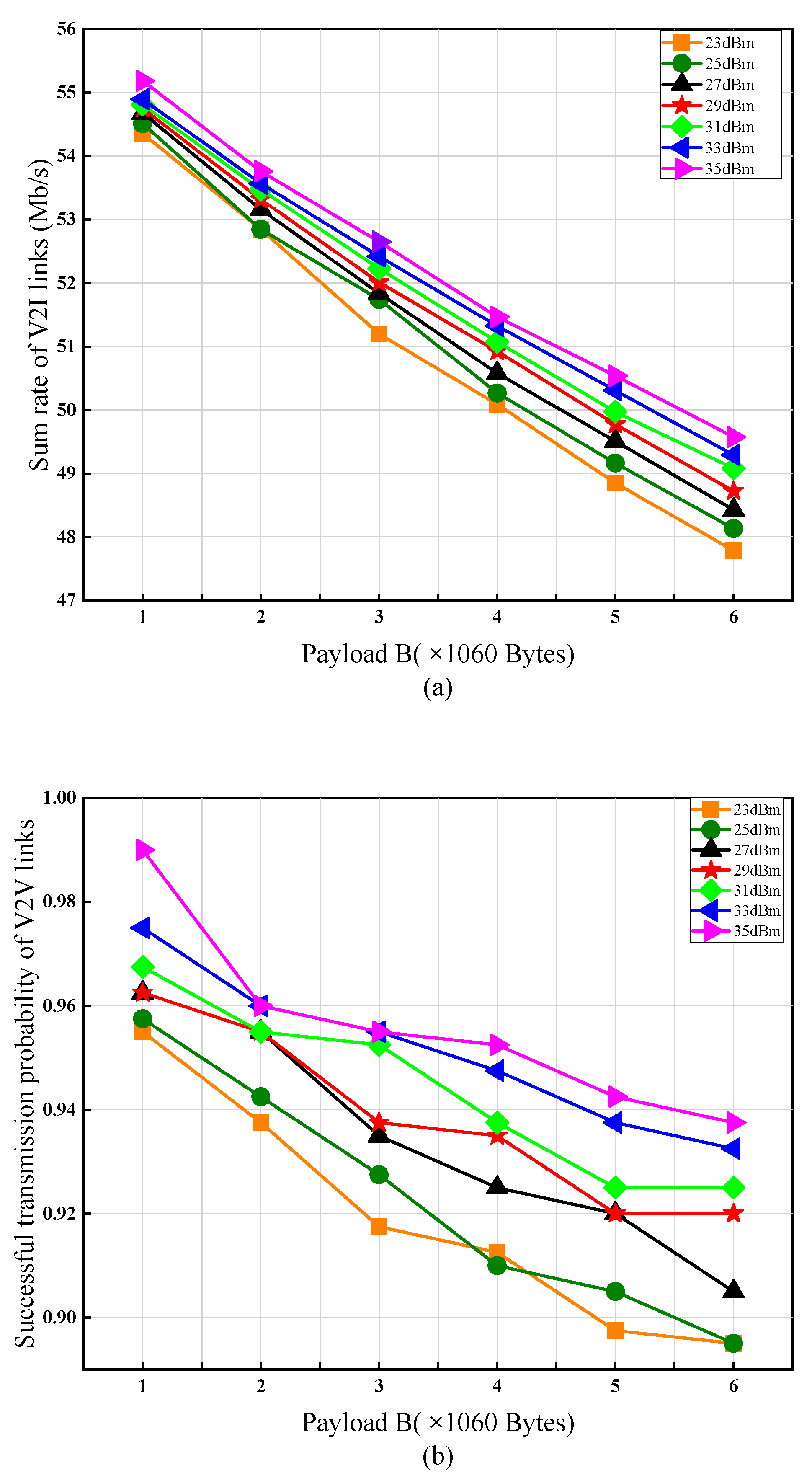
4.2. Impact of V2V Links Transmission Power on Network Performance
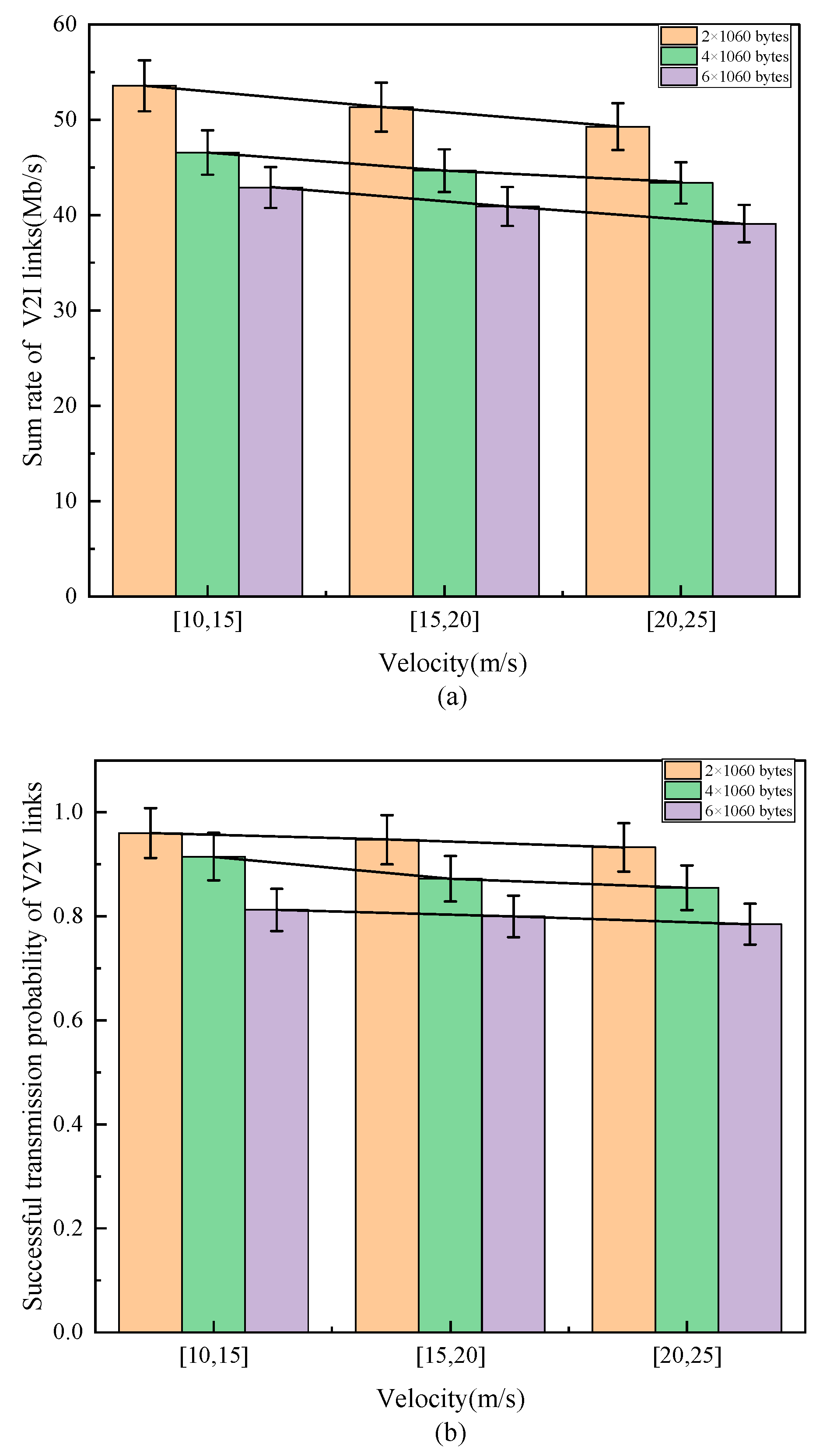
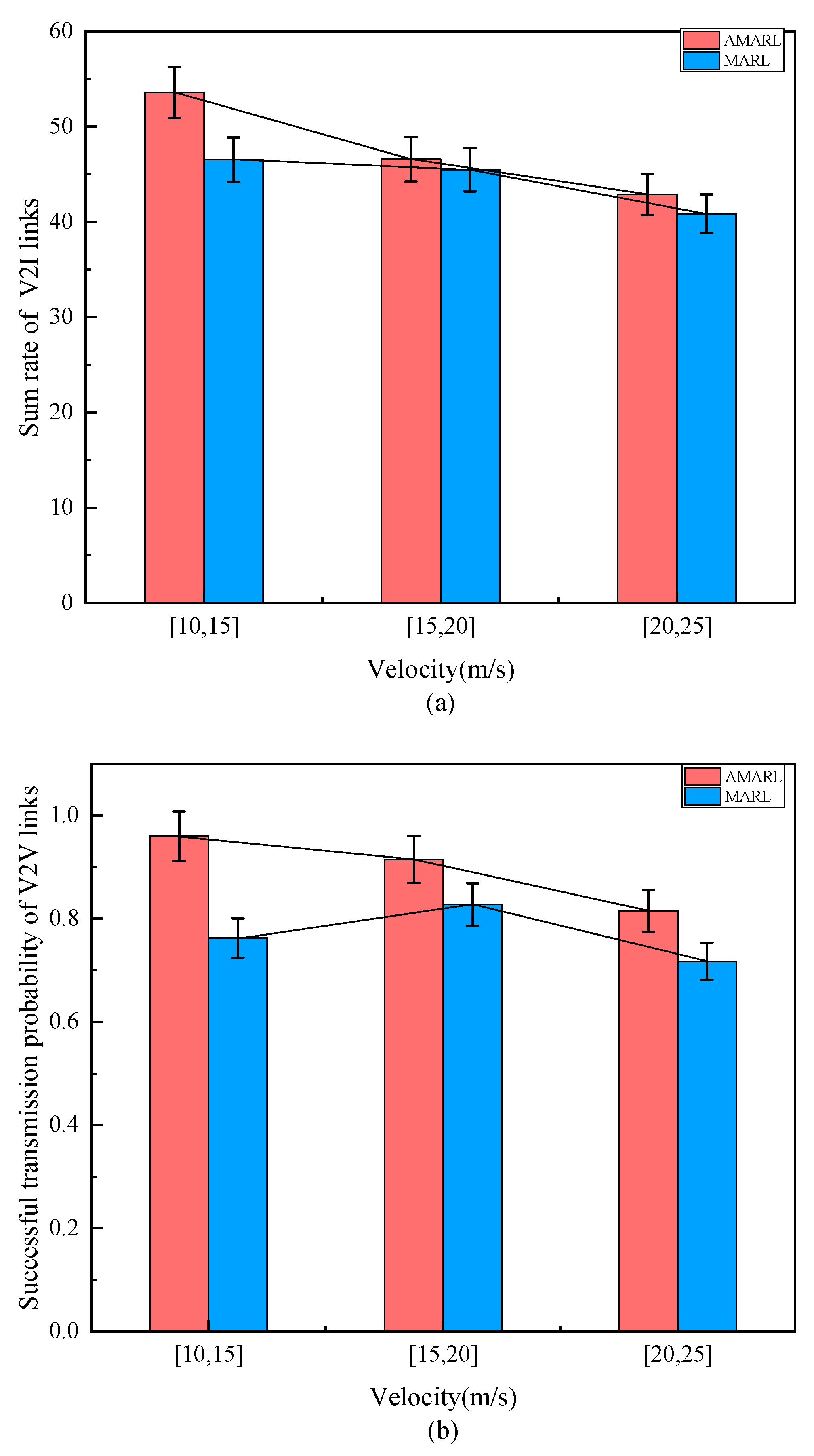
4.3. Impact of Vehicle Velocity on Network Performance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ko, S.-W.; Chae, H.; Han, K.; Lee, S.; Seo, D.-W.; Huang, K. V2X-Based Vehicular Positioning: Opportunities, Challenges, and Future Directions. IEEE Wirel. Commun. 2021, 28, 144–151. [Google Scholar] [CrossRef]
- Rahim, N.A.; Liu, Z.; Lee, H.; Khyam, M.O.; He, J.; Pesch, D.; Moessner, K.; Saad, W.; Poor, H.V. 6G for Vehicle-to-Everything (V2X) Communications: Enabling Technologies, Challenges, and Opportunities. Proc. IEEE 2022, 110, 712–734. [Google Scholar] [CrossRef]
- Pervez, F.; Yang, C.; Zhao, L. Dynamic Resource Management to Enhance Video Streaming Experience in a C-V2X Network. In Proceedings of the 2020 IEEE 92nd Vehicular Technology Conference (VTC2020-Fall), online, 18 November–16 December 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Coll-Perales, B.; Schulte-Tigges, J.; Rondinone, M.; Gozalvez, J.; Reke, M.; Matheis, D.; Walter, T. Prototyping and Evaluation of Infrastructure-Assisted Transition of Control for Cooperative Automated Vehicles. IEEE Trans. Intell. Transp. Syst. 2022, 23, 6720–6736. [Google Scholar] [CrossRef]
- Eiermann, L.; Wirthmuller, F.; Massow, K.; Breuel, G.; Radusch, I. Driver Assistance for Safe and Comfortable On-Ramp Merging Using Environment Models Extended through V2X Communication and Role-Based Behavior Predictions. In Proceedings of the 2020 IEEE 16th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 3–5 September 2020; pp. 263–270. [Google Scholar] [CrossRef]
- Zhou, H.; Xu, W.; Chen, J.; Wang, W. Evolutionary V2X Technologies Toward the Internet of Vehicles: Challenges and Opportunities. Proc. IEEE 2020, 108, 308–323. [Google Scholar] [CrossRef]
- Jiang, D.; Taliwal, V.; Meier, A.; Holfelder, W.; Herrtwich, R. Design of 5.9 ghz dsrc-based vehicular safety communication. IEEE Wirel. Commun. 2006, 13, 36–43. [Google Scholar] [CrossRef]
- 3GPP TR 21.914; Digital Cellular Telecommunications System (Phase2+) (GSM); Universal Mobile Telecommunications System (UMTS); LTE; 5G.; Version 14.0.0 Release 14. ETSI: Valbonne, France, 2018.
- 3GPP TR 21.915; Study on New Radio (NR) Access Technology; Version 1.1.0 Release 15. ETSI: Valbonne, France, 2018.
- TS 23.287; Architecture Enhancements for 5G System (5GS) to Support Vehicle-To-Everything (V2X) Services, 3GPP, V16.4.0 (Release 16). ETSI: Valbonne, France, 2020.
- Gyawali, S.; Xu, S.; Qian, Y.; Hu, R.Q. Challenges and Solutions for Cellular Based V2X Communications. IEEE Commun. Surv. Tutor. 2021, 23, 222–255. [Google Scholar] [CrossRef]
- Guo, C.; Liang, L.; Li, G.Y. Resource Allocation for Vehicular Communications with Low Latency and High Reliability. IEEE Trans. Wirel. Commun. 2019, 18, 3887–3902. [Google Scholar] [CrossRef]
- Guo, C.; Liang, L.; Li, G.Y. Resource Allocation for Low-Latency Vehicular Communications: An Effective Capacity Perspective. IEEE J. Sel. Areas Commun. 2019, 37, 905–917. [Google Scholar] [CrossRef]
- Abbas, F.; Fan, P.; Khan, Z. A Novel Low-Latency V2V Resource Allocation Scheme Based on Cellular V2X Communications. IEEE Trans. Intell. Transp. Syst. 2019, 20, 2185–2197. [Google Scholar] [CrossRef]
- Zhang, M.; Dou, Y.; Chong, P.H.J.; Chan, H.C.B.; Seet, B.-C. Fuzzy Logic-Based Resource Allocation Algorithm for V2X Communications in 5G Cellular Networks. IEEE J. Sel. Areas Commun. 2021, 39, 2501–2513. [Google Scholar] [CrossRef]
- Chen, C.; Wang, B.; Zhang, R. Interference Hypergraph-Based Resource Allocation (IHG-RA) for NOMA-Integrated V2X Networks. IEEE Internet Things J. 2019, 6, 161–170. [Google Scholar] [CrossRef]
- Liang, L.; Xie, S.; Li, G.Y.; Ding, Z.; Yu, X. Graph-Based Resource Sharing in Vehicular Communication. IEEE Trans. Wirel. Commun. 2018, 17, 4579–4592. [Google Scholar] [CrossRef]
- Zappone, A.; Di Renzo, M.; Debbah, M. Wireless Networks Design in the Era of Deep Learning: Model-Based, AI-Based, or Both? IEEE Trans. Commun. 2019, 67, 7331–7376. [Google Scholar] [CrossRef]
- Wang, J.; Jiang, C.; Zhang, H.; Ren, Y.; Chen, K.-C.; Hanzo, L. Thirty Years of Machine Learning: The Road to Pareto-Optimal Wireless Networks. IEEE Commun. Surv. Tutorials 2020, 22, 1472–1514. [Google Scholar] [CrossRef]
- Wang, L.; Ye, H.; Liang, L.; Li, G.Y. Learn to Compress CSI and Allocate Resources in Vehicular Networks. IEEE Trans. Commun. 2020, 68, 3640–3653. [Google Scholar] [CrossRef]
- Zhang, X.; Peng, M.; Yan, S.; Sun, Y. Deep-Reinforcement-Learning-Based Mode Selection and Resource Allocation for Cellular V2X Communications. IEEE Internet Things J. 2020, 7, 6380–6391. [Google Scholar] [CrossRef]
- Chen, X.; Wu, C.; Chen, T.; Zhang, H.; Liu, Z.; Zhang, Y.; Bennis, M. Age of Information Aware Radio Resource Management in Vehicular Networks: A Proactive Deep Reinforcement Learning Perspective. IEEE Trans. Wirel. Commun. 2020, 19, 2268–2281. [Google Scholar] [CrossRef]
- Fu, J.; Qin, X.; Huang, Y.; Tang, L.; Liu, Y. Deep Reinforcement Learning-Based Resource Allocation for Cellular Vehicular Network Mode 3 with Underlay Approach. Sensors 2022, 22, 1874. [Google Scholar] [CrossRef]
- Liang, L.; Ye, H.; Li, G.Y. Spectrum Sharing in Vehicular Networks Based on Multi-Agent Reinforcement Learning. IEEE J. Sel. Areas Commun. 2019, 37, 2282–2292. [Google Scholar] [CrossRef]
- Foerster, J.; Nardelli, N.; Farquhar, G.; Afouras, T.; Torr, P.H.S.; Kohli, P.; Whiteson, S. Stabilising Experience Replay for Deep Multi-Agent Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 1146–1155. [Google Scholar]
- Wang, R.; Jiang, X.; Zhou, Y.; Li, Z.; Wu, D.; Tang, T.; Fedotov, A.; Badenko, V. Multi-agent reinforcement learning for edge information sharing in vehicular networks. Digit. Commun. Netw. 2022, 8, 267–277. [Google Scholar] [CrossRef]
- Yuan, Y.; Zheng, G.; Wong, K.-K.; Ben Letaief, K. Meta-Reinforcement Learning Based Resource Allocation for Dynamic V2X Communications. IEEE Trans. Veh. Technol. 2021, 70, 8964–8977. [Google Scholar] [CrossRef]
- Gündoğan, A.; Gürsu, H.M.; Pauli, V.; Kellerer, W. Distributed resource allocation with multi-agent deep reinforcement learning for 5G-V2V communication. In Proceedings of the Twenty-First International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing, Online, 11–14 October 2020; pp. 357–362. [Google Scholar]
- He, Z.; Wang, L.; Ye, H.; Li, G.Y.; Juang, B.-H.F. Resource Allocation based on Graph Neural Networks in Vehicular Communications. In Proceedings of the GLOBECOM 2020—2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–5. [Google Scholar] [CrossRef]
- He, Y.; Wang, Y.; Yu, F.R.; Lin, Q.; Li, J.; Leung, V.C.M. Efficient Resource Allocation for Multi-Beam Satellite-Terrestrial Vehicular Networks: A Multi-Agent Actor-Critic Method With Attention Mechanism. IEEE Trans. Intell. Transp. Syst. 2022, 23, 2727–2738. [Google Scholar] [CrossRef]
- Iqbal, S.; Sha, F. Actor-Attention-Critic for Multi-Agent Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 2961–2970. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Advances in Neural Information Processing Systems 30 (NIPS 2017); Long Beach, CA, USA, 4–9 December 2017.
- Gonzalez-Martin, M.; Sepulcre, M.; Molina-Masegosa, R.; Gozalvez, J. Analytical Models of the Performance of C-V2X Mode 4 Vehicular Communications. IEEE Trans. Veh. Technol. 2018, 68, 1155–1166. [Google Scholar] [CrossRef]
- Nguyen, H.-H.; Hwang, W.-J. Distributed Scheduling and Discrete Power Control for Energy Efficiency in Multi-Cell Networks. IEEE Commun. Lett. 2015, 19, 2198–2201. [Google Scholar] [CrossRef]
- Otterlo, M.; Wiering, M. Reinforcement Learning and Markov Decision Processes. In Reinforcement Learning; Springer: Berlin/Heidelberg, Germany, 2012; pp. 3–42. [Google Scholar]
- Watkins, C.J.C.H. Learning from Delayed Rewards. Ph.D. Thesis, King’s College, London, UK, 1989. [Google Scholar]
- Tokic, M.; Palm, G. Value-difference based exploration: Adaptive control between epsilon-greedy and softmax. In Annual Conference on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2011; pp. 335–346. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Technical Specification Group Radio Access Network. Study LTE-Based V2X Services; (Release 14), Document 3GPP TR 36.885 V14.0.0, 3rd Generation Partnership Project, June 2016. Available online: https://portal.3gpp.org/desktopmodules/Specifications/SpecificationDetails.aspx?specificationId=2934 (accessed on 1 September 2022).
- Kyösti, P.; Meinilä, J.; Hentila, L.; Zhao, X.; Jämsä, T.; Schneider, C.; Narandzic, M.; Milojevic, M.; Hong, A.; Ylitalo, J.; et al. IST-4-027756 WINNER II D1.1.2 v1.2 WINNER II channel models. Inf. Soc. Technol. 2008, 11, 1–82. [Google Scholar]
- Zeng, Y.; Xu, X. Toward Environment-Aware 6G Communications via Channel Knowledge Map. IEEE Wirel. Commun. 2021, 28, 84–91. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Definition |
|---|---|
| Set of V2I links and V2V links | |
| Numbers of V2I links and V2V links | |
| - V2I link to BS | |
| - V2V link | |
| -- V2V link | |
| -- V2V link | |
| -- V2V link | |
| -- V2I link | |
| - V2I link | |
| - V2V link | |
| Noise power and bandwidth | |
| -- V2V link | |
| The coherence time of the channel | |
| Reward function | |
| Q-network of the n- V2V link | |
| Parameter of the Q-network | |
| Target Q-network of n- V2V link | |
| Mini-batch of experiences | |
| Exploration rate | |
| Discount factor |
| Parameters | Values |
|---|---|
| Carrier frequency | 2 GHz |
| Sub-channel bandwidth | 1 MHz |
| BS antenna height | 25 m |
| BS antenna gain | 8 dBi |
| BS receiver noise figure | 5 dB |
| Vehicle antenna height | 1.5 m |
| Vehicle receiver gain | 3 dBi |
| Vehicle receiver noise figure | 9 dB |
| Vehicle speed | [10, 15] m/s |
| V2I transmission power | 35 dBm |
| V2V Maximum transmission power | 33 dBm |
| −114 dBm | |
| Maximum tolerant latency of V2V links | 100 ms |
| V2V payload size B | ,6] × 1060 bytes |
| Number of V2I links | 4 |
| Number of V2V links | 4 |
| 0.9 | |
| {0.1, 0.9, 1.0} | |
| 5 |
| Parameters | V2I Link | V2V Link |
|---|---|---|
| Path loss model | in km | LOS in WINNER + B1 Manhattan [40] |
| Shadowing distribute | Log-normal | Log-normal |
| Shadowing standard deviation | 8 dB | 3 dB |
| Decorrelation distance | 50 m | 10 m |
| Fast fading | Rayleigh fading | Rayleigh fading |
| Fast fading updata | Every 1 ms | Every 1 ms |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, Y.; Huang, Y.; Tang, L.; Qin, X.; Jia, Z. Resource Allocation in V2X Communications Based on Multi-Agent Reinforcement Learning with Attention Mechanism. Mathematics 2022, 10, 3415. https://doi.org/10.3390/math10193415
Ding Y, Huang Y, Tang L, Qin X, Jia Z. Resource Allocation in V2X Communications Based on Multi-Agent Reinforcement Learning with Attention Mechanism. Mathematics. 2022; 10(19):3415. https://doi.org/10.3390/math10193415
Chicago/Turabian StyleDing, Yuanfeng, Yan Huang, Li Tang, Xizhong Qin, and Zhenhong Jia. 2022. "Resource Allocation in V2X Communications Based on Multi-Agent Reinforcement Learning with Attention Mechanism" Mathematics 10, no. 19: 3415. https://doi.org/10.3390/math10193415
APA StyleDing, Y., Huang, Y., Tang, L., Qin, X., & Jia, Z. (2022). Resource Allocation in V2X Communications Based on Multi-Agent Reinforcement Learning with Attention Mechanism. Mathematics, 10(19), 3415. https://doi.org/10.3390/math10193415