2.3.1. Execution Time Model
This subsection proposes the study of the implementation details for the case of linear control structures, where controllers will be modeled as infinite-impulse response (IIR) and finite-impulse response (FIR) filters. Starting from [
10], a set of implementation aspects which are treated for state-space realizations will be considered in a unified manner for the case of transfer matrices in this paper. Additionally, this section also analyzes the 2DOF extension. The duration for each operation involved in the control structure can significantly impact the regulator implementability.
The necessary mathematical operations to fully implement an LTI-based control law must be formally defined. Besides the LTI-control law, the classical saturation and anti-windup nonlinearities will be considered, which are usually related to said LTI laws. The unary and binary mathematical operators defined in
Table 1 and gathered in the operations alphabet
, are considered with real operands and must be accounted for into a microprocessor-based environment.
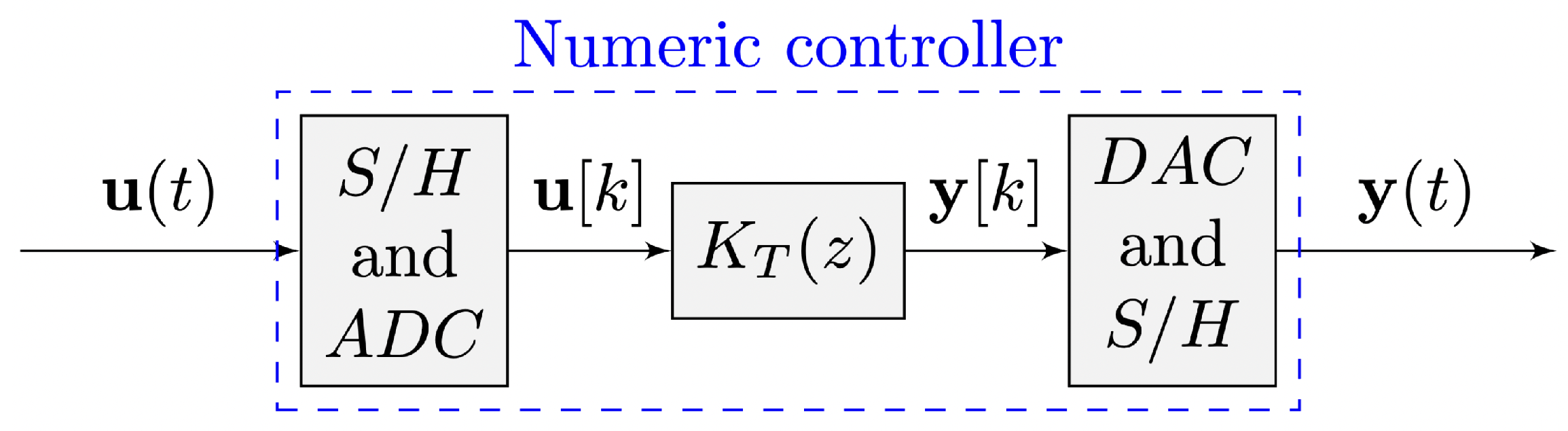
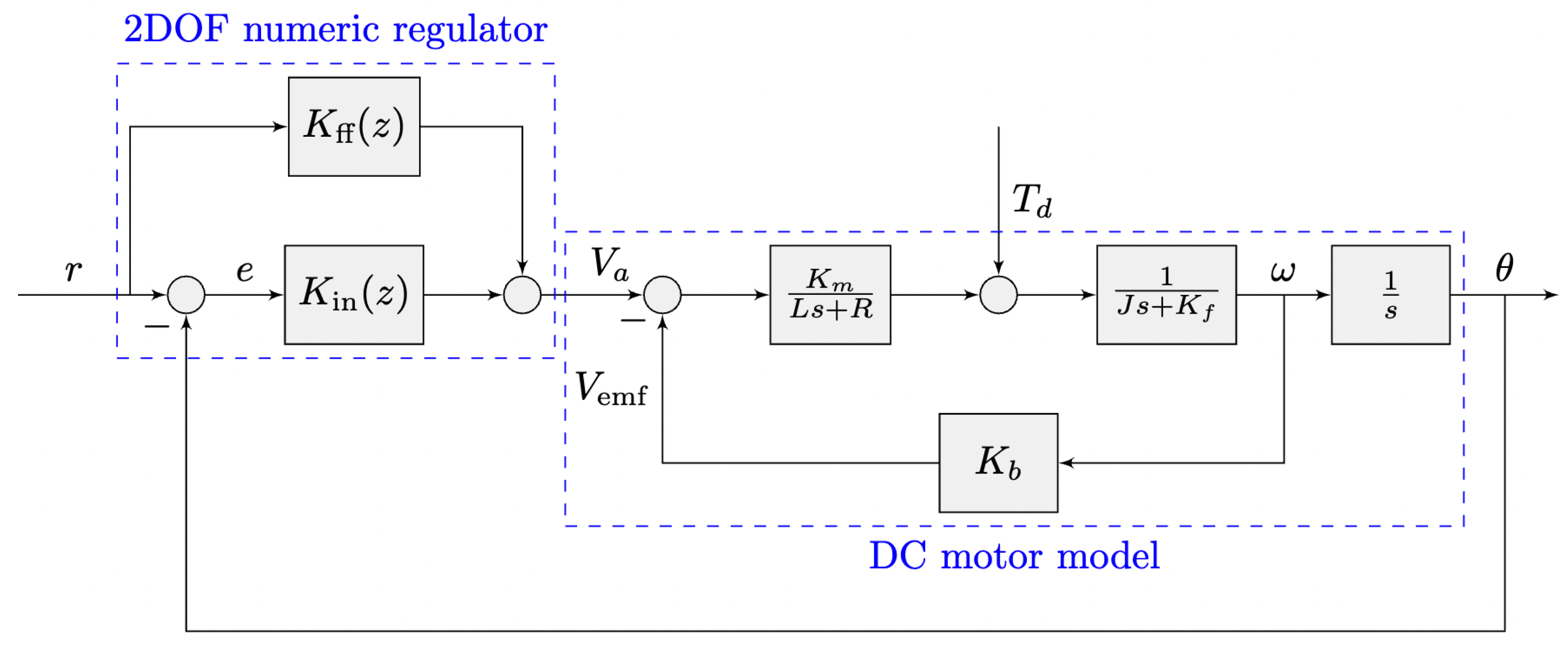
As such, the process of computing a command signal
as in
Figure 1 implies a finite and formal computational finite sequence
, where all terms are mathematical operations as in
Table 1, i.e.,
,
, where
N depends on the structure of the controller
. Moreover, in order to additionally specify a set of practical hardware specifications and constraints
and to uniformly describe the problem, the finite sequence can be now extended to a full sequence
:
Starting from an array
of operations as (
25), we follow with a general-purpose instruction set model. Assume a Random-Access Machine (RAM) computational model as in [
23], with deterministic operations. RAM machines have practical counterparts, materialized through RISC machines. Reconfigurable RISC machines specialized on certain problems have been proposed in [
31]. Additionally, there is the approach of multiply and accumulate (MAC) instructions supported in digital signal processors (DSP) [
32]. Depending on the supported computer architectures of the RCP framework, relevant are also Single Instruction stream/Multiple instruction Pipelining (SIMP) [
33] constructions with respect to single-processor architectures, or Single Instruction/Multiple Data (SIMD) features, which allow the practical parallelization of addition and multiplication operations for several sets of operands.
Definition 1. The hardware constraints and specification set encompasses metadata which imply extra operations or different approaches to the standard operations performed on the controller signals and implementation-specific information, with various outcomes on the total execution time, frequently found in practice being:
reading reference signals and plant measurements , all input signal reading steps may imply preprocessing constraints in terms of sensor delays, impulse counters or data type conversions—this equates to adding steps;
scaling operations for the input and output signals imposed by the operating point used for plant linearization: and , which equates to augmenting the sequence set with items;
input and output signals scaling operations, i.e., and , useful especially for sensor/adapter signals, and extend the operations with ;
starting from the variable base word length L of the microcontroller arithmetic registers which allows operations to be executed in a single clock tick, each variable’s type and size should be adequately adapted for , etc., which complicates the adding and multiplication routines with additional steps;
controller gain-scheduling verifications and updates based on the value of the input signal , leading to extra ;
underflow and overflow checks for involved signals, implying saturations ;
availability of Direct Memory Access (DMA) modules, MAC instructions, circular buffers in opposition to linear buffering, or output bypassing, which has the advantage of discarding operations.
Such specifications will be quantified by scaling factors to the base duration of the RISC machine model operations. Depending on the significance of the alternative instruction, could be less than, equal to, or greater than one, respectively.
Therefore, a set of instructions
can be manually designed or automatically deduced. For manual modeling, the control engineer needs to find this set for each control law, while for automatic mode, an RCP tool can already deduce this set. Such an RCP tool generally deals with the code generation for different environments. Now, the sequence of operations generator procedures can be seen as a functional:
To implement the mathematical operations
from
Table 1, the atomic assembly instructions
from
Table 2 will represent the starting point. It covers the basic arithmetical operations required in linear systems, with the additivity and homogeneity properties, conditional jumps for saturations and the anti-windup of integrator terms, forced and imposed delays through data acquisition hardware and access to memory devices. Each arbitrary atomic assembly operation will be denoted by
a, as part of the formal set
all the equivalent assembly instructions supported by
for the implementation of
, with the RISC machine assumption that each instruction takes a fixed clock tick value
> 0. The number of ways in obtaining the resulting assembly instructions is not unique and it further depends on the structure of
. A straightforward example to illustrate this phenomenon is when the regulator coefficients are stored contiguously in the memory in comparison to arbitrary and uncorrelated memory registers. The execution time implications are obtained through different pointer operations. To conclude, a new mathematical operator analogous to (
26), tasked with the generation of a computer-equivalent set of instructions given by the functional
is:
which results in an infinite sequence of atomic software instructions, but with a finite number of them being different to
NOP, located at the start of the sequence, which implement the linear controller formula:
The difference between the sets
and
is that
contains abstract mathematical operations
, and each such operation
will be practically implemented using equivalent
steps,
, as in the mapping:
the number of atomic operations different from
NOP being
.
The importance of the previously defined sequences and functionals, i.e.,
,
,
and
, respectively, and the implications of estimating the number of assembly operations in a tight manner was insisted upon in the base paper [
10].
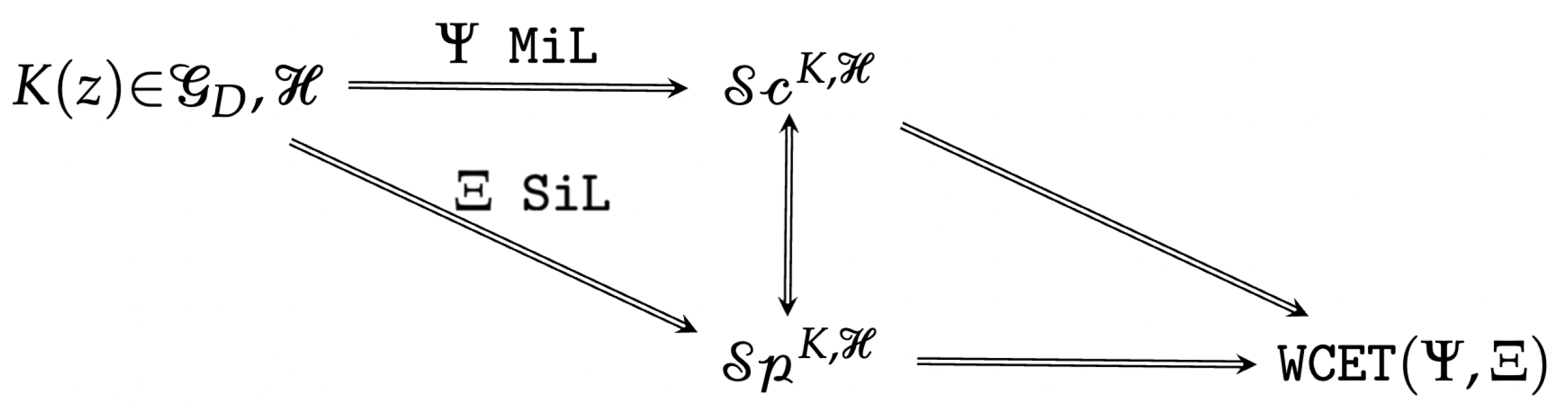
Figure 3 gathers them and illustrates their connections in an RCP context. The mapping from
to the set
is usually performed for Model-in-the-Loop (MiL) simulations through an application
, while the mapping
is made through Software-in-the-Loop (SiL) testing using an application
. The master RCP program, with access to both
and
, can subsequently perform a worst-case execution time analysis on the implementation of the digital regulator
in the production hardware context
.
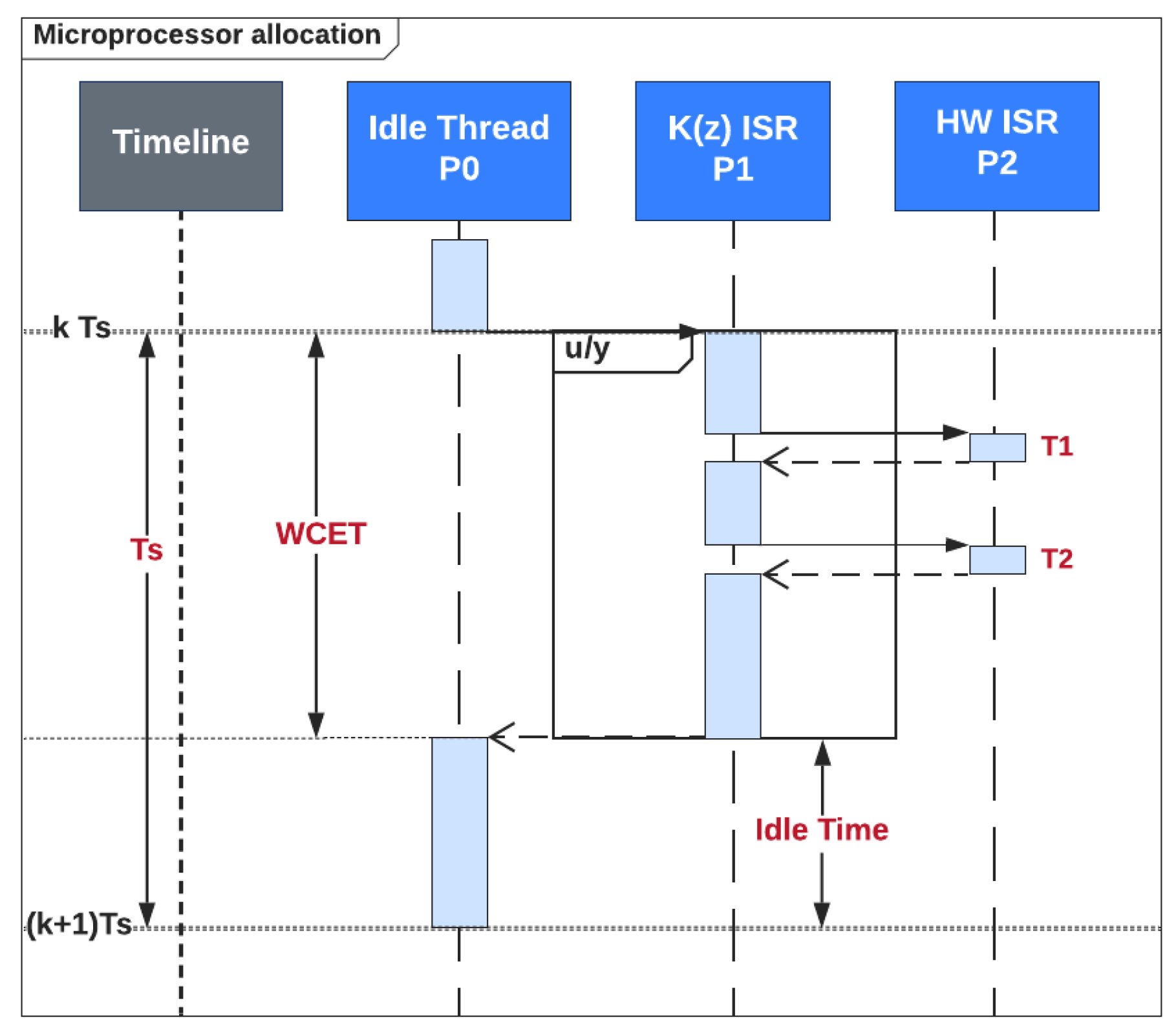
Figure 4 presents the sequence diagram with the timing constraints of the discrete-time controller
K with respect to other software threads from the microcontroller, with an illustration of the WCET of the controller interrupt service routine (ISR) thread. The main result of the section is gathered in the following theorem.
Theorem 1. Given a numerical control law given by , along with a microcontroller specification set and a code-generation procedure given by a pair of MiL and SiL , the worst-case execution time estimation can be computed by the following formula:where represents the number of atomic assembly operations as in (28), and accounts the context switching operations for the other software threads. Additionally, the exact bounds from depend on all other software entities running on the same microprocessor and are not correlated with the input dimension m or the output dimension p of the numerical controller. Proof. According to the schematic representation from
Figure 3, starting from the control law
and the specification set
, the set
can be obtained via the MiL operator
, resulting in
. However, in order to measure each
, the set of atomic operations must be attached via the SiL operator
:
, each such atomic operation requiring exactly
, leading to:
where
is the time necessary to execute an operation or a set of operations.
Additionally, a second term
accumulates ISR switching and stack-handling operations handled by the scheduler, bounded by a processor-dependent constant
, which can be modeled as
. As such, the worst-case execution time can now be written as:
which concludes the proof. □
Observation 1. All possible delays caused by context switching to preemptive ISRs belonging to measurement data processing, with the cost of , are included in the input processing step and do not remain unaccounted for in the execution time model of Theorem (30). Two additional performance qualifiers can be employed to globally assess the controller ISR implementation impact on the scheduling algorithm of the processor.
Definition 2. The processor usage level qualifier relative to a fixed sampling period of a discrete-time regulator , described in a relative manner, is defined by: Definition 3. The processor idle time qualifier with respect to a fixed sampling period of a discrete-time regulator , described in absolute units, is defined by: 2.3.2. Modeling Duration of Finite and Infinite-Impulse Response Topologies
Denote by
a MIMO regulator with
m inputs and
p outputs, thus fully described by the expressions of
transfer functions
:
Each element of the transfer matrix
, i.e.,
, can be modeled as an infinite-impulse response (IIR) filter or as a finite-impulse response (FIR) filter. The case where
is modeled as a state-space representation is treated in the base conference paper [
10], namely in Algorithm 1 and Table I, respectively.
For an arbitrary discrete-time IIR transfer function
of order
n, define
as the pair:
Using this notation, the transfer function
can be written using a series of second-order sections and an additional first-order component, if necessary, as:
with the terms from each triplet
not all null,
known as a first-order section, and each
, with
being denoted in the literature as a second-order section (SOS).
Remark 4. Second-order sections are usually described with an additional gain term multiplied separately to the output of the transfer function as: To not further complicate the notations, we will not explicitly write this gain term for every second-order section, but it will be implicitly considered in the implementation and execution time analysis.
There are multiple approaches of implementing digital biquadratic filters, a good example being the description from the monograph [
34].
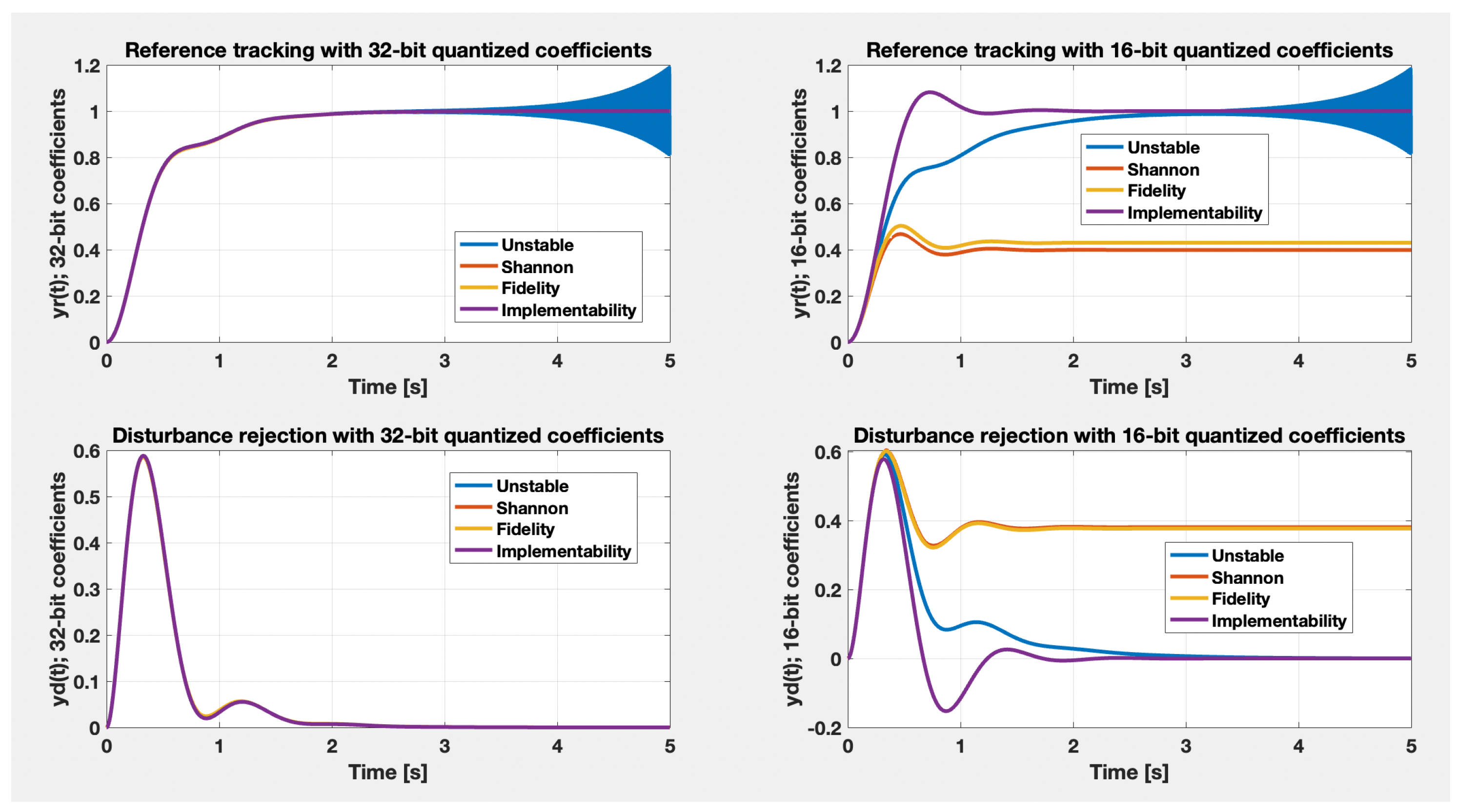
Table 3 exposes the four usual topologies, which principally implement the same input-output transfer function, but with important differences regarding numerical stability when selecting fixed-point or floating-point implementations. These configurations are referred to as the canonical forms: Direct Form I, Direct Form II, Transposed Form I, Transposed Form II, which differ in the numerical properties of their implementations and in the number of necessary delay elements. As observed in the third column of the table, all biquad topologies are based on four additions, five multiplications, and a different number of load/store operations, depending on the definition of the internal state variables. Such implementation details are relevant when studying particularized structures, such as in the situations treated in [
35,
36].
The ISR model for IIR controller structures is based on the pseudocode exposed in Algorithm 1. hlBased on the specifications for
, each line of the pseudocode will have a set of mandatory mathematical operations, along with optional operations, which will be accounted for in the execution time analysis model through different constant weights.
| Algorithm 1 Infinite-impulse response (IIR) filter interrupt service routine (ISR) |
- Input:
as in ( 35), topology as in Table 3- Output:
Execution time profiler for routine iirFiltIsr - 1:
Construct software structures , – according to ( 37) and Table 3- 2:
Initialize delays involved in second-order sections to zero - 3:
procedureiirFiltIsr(,) - 4:
Read and scale from input device - 5:
← - 6:
for to do - 7:
← ▷ The output from becomes input to - 8:
end for - 9:
- 10:
- 11:
Scale and write to output device - 12:
end procedure - 13:
functioncall(H, topology) ▷ First or second-order section call method for IIR filter - 14:
Read input - 15:
Shift input delays , - 16:
Compute according to input topology as in Table 3- 17:
Shift output delays , - 18:
Scale by second-order section gain g - 19:
return - 20:
end function
|
In ref. [
10], an analysis has been performed on the simplified case of a
nth order IIR SISO transfer function in a series connection, described as:
which, by design, it can implicitly include a delay
by forcing the first
coefficients
to zero. Such a transfer function has its corresponding difference equation as:
A further particularization on the structure of
is to consider the expression of a FIR filter topology, which, by design, discards the previous output delays. The present command signal
will, as such, depend only on an array of delays, i.e., delay tap of inputs
, modeled as:
Four typical canonical forms are distinguished for FIR-type filters, namely the Direct Form (DF), Direct Form Transposed (DFT), Symmetric and Antisymmetric [
34], respectively, with their definitions exposed in
Table 4. The main difference between DF and DFT is that for the former, the delay word lengths are that of the input signals
, while for the latter, the delays have the word length of the accumulator variable. The Symmetric and Antisymmetric cases make use of the linear phase of the filter through the regularity of the first
coefficients as the symmetrical or antisymmetrical equivalents of the latter half of the coefficients. As mentioned in the third column of the table, this has a significant impact on the necessary multiplications and load operations involved in the implementation of
. Algorithm 2 emphasizes the corresponding SISO FIR filter ISR routine starting from the mathematical basis of Equation (
41) and information from
Table 4.
Corollary 1. Given a MIMO transfer matrix as in (35), where each component , can be described as an IIR filter of form (37), with second-order sections as in Table 3 or a FIR filter of form (41), with difference equations as in Table 4, the WCET can be computed as:with coefficients accounting for the hardware specifications set from Definition 1, each assembly operation set determined individually by the RCP application, given the microprocessor tick , and depends only on the other higher-priority software threads. | Algorithm 2 Finite-impulse response (FIR) filter interrupt service routine (ISR) |
- Input:
as in ( 41), topology as in Table 4- Output:
Execution time profiler for routine firFiltIsr - 1:
Construct software structure with N coefficients and a Nth order delay tap - 2:
Initialize Nth-order input delay tap to zero - 3:
procedurefirFiltIsr(N,H) - 4:
Read and scale from input device - 5:
← - 6:
Shift input delay tap - 7:
▷ According to column 2 of Table 4 - 8:
- 9:
Scale and write to output device - 10:
end procedure
|
The proof immediately follows based on Theorem 1 by replacing the general-purpose sequence with its corresponding sum of subsystems from the full MIMO regulator and their definitions.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}