
A Heterogeneous Federated Transfer Learning Approach with Extreme Aggregation and Speed





Abstract
:1. Introduction
- In terms of FL challenges and more specifically “expansive commutation” related to the number of transmitted messages and the size of the transmitted information of the training models, these models follow different lossy compression schemes to reduce the size of the model architecture in terms of the number of bits. However, these models, being DL networks, have a serious disadvantage of being large models with multiple parameters;
- As these models are trained with gradient descent algorithms which are iterative algorithms and are subject to a higher level of computational costs during training, the training process will be very expansive and time consuming when it acts to rebuild the feature map, and will also take time when it comes to aggregation;
- In terms of “system heterogeneity”, another disadvantage of the FL algorithm is that when it comes to model aggregation based on averaging methods, the averaging rules do not take into account that the resulting weights associated with different data can have different scales. In this context, the result will end up in favor of the edge model that has the largest scale;
- Generally speaking, in terms of “statistical heterogeneity”, the discussed models follow aggregations of DL networks that share the same architectures. This requires, in case of classification, for example, that the number of output neurons must be the same. This means that we should have the same number of classes in this case. However, in real applications, peripheral devices can be used to monitor a different number of classes with different types depending on the purpose of the monitoring process. At this point, we cannot deny the fact that similar deep network architectures will not handle the actual application of non-IID data in terms of class count.
- In the context of “privacy concerns”, these models have adopted several encryption techniques to protect the privacy of the models and efficiently remedy cyber threats.
- There is a big issue concerning data selection when validating these learning models. The MNIST dataset, which is generally designed for the purpose of image recognition and not specifically intended for FL, is widely used in these studies. This is truly a problem that makes results obtained in this work not fully supported by the obtained conclusions in terms of real application. Therefore, to meter the splitting process followed in this case the model will not address issues of FL related to both statistical and system heterogeneity.
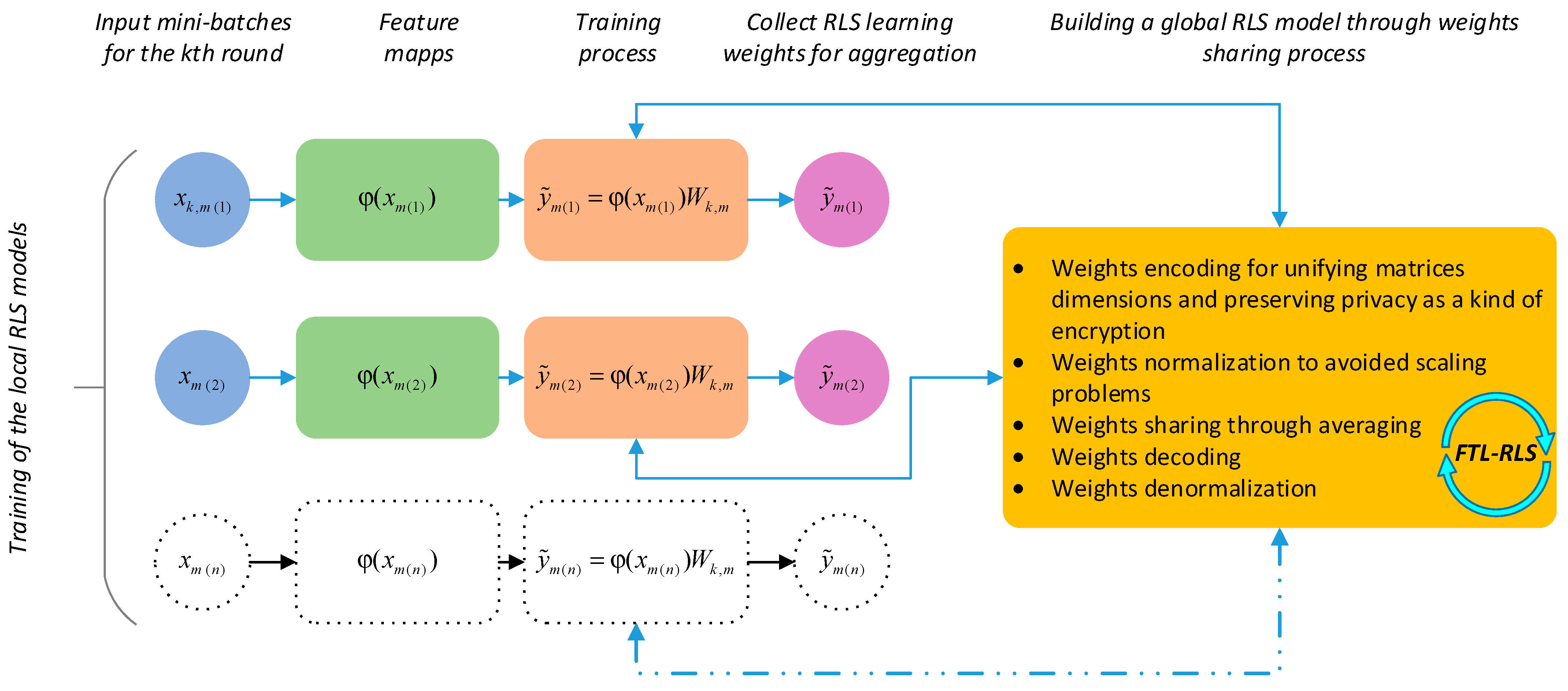
- Federated networks include a massive number of devices (i.e., millions). This situation definitely slows down communication due to limited resources like bandwidth, energy, and power. As a result, communication methods must iteratively send small messages or model updates as part of the training process, reducing both the number of communications and the size of the messages transmitted each round (see [1], page 52, section “expansive communication”). To overcome the problem of large packets of messages transmission (i.e., expansive communication), the recursive least squares (RLS) method is involved in this work. RLS offers a fast and accurate small scale-based linear programming allowing both the approximation and generalization depending only on a single matrix of weights and not the multiple weighting and nonlinear abstraction processes as with deep networks.
- RLS depends on the Sherman-Morison-Woodbury (SMW) demonstration to perform anon-iterative model updates requiring very small computational resources compared to gradient decent algorithms.
- To solve the problem related to weight scales (i.e., statistical heterogeneity), a specific weight scaling and rescaling process has been involved before and after collaborative training.
- To overcome the problem related to model architecture (i.e., system heterogeneity), a specific mapping process in a sort of feature encoding is designed to unify weights matrix sizes before the collaborative training process.
- To circumvent the problem of providing more-appropriate data, a specific dataset is generated in this context, addressing all above FL issues in an attempt to provide coherent conclusions.
- Due to the algorithmic simplicity of the FTR-RLS method and characteristics of the generated dataset, simulations conduction is feasible on ordinary available commercial computers with quad-core microprocessors without any need for higher computing environments.
- To overcome the problem related to the privacy of the FL model itself (i.e., privacy concerns) FTR-RLS involves a weights encoding process through transpose matrix design as a sort of encryption. This leads to the addition of some difficulty/delay in extracting information from real learning weights through attack experiments.
2. Materials and Methods
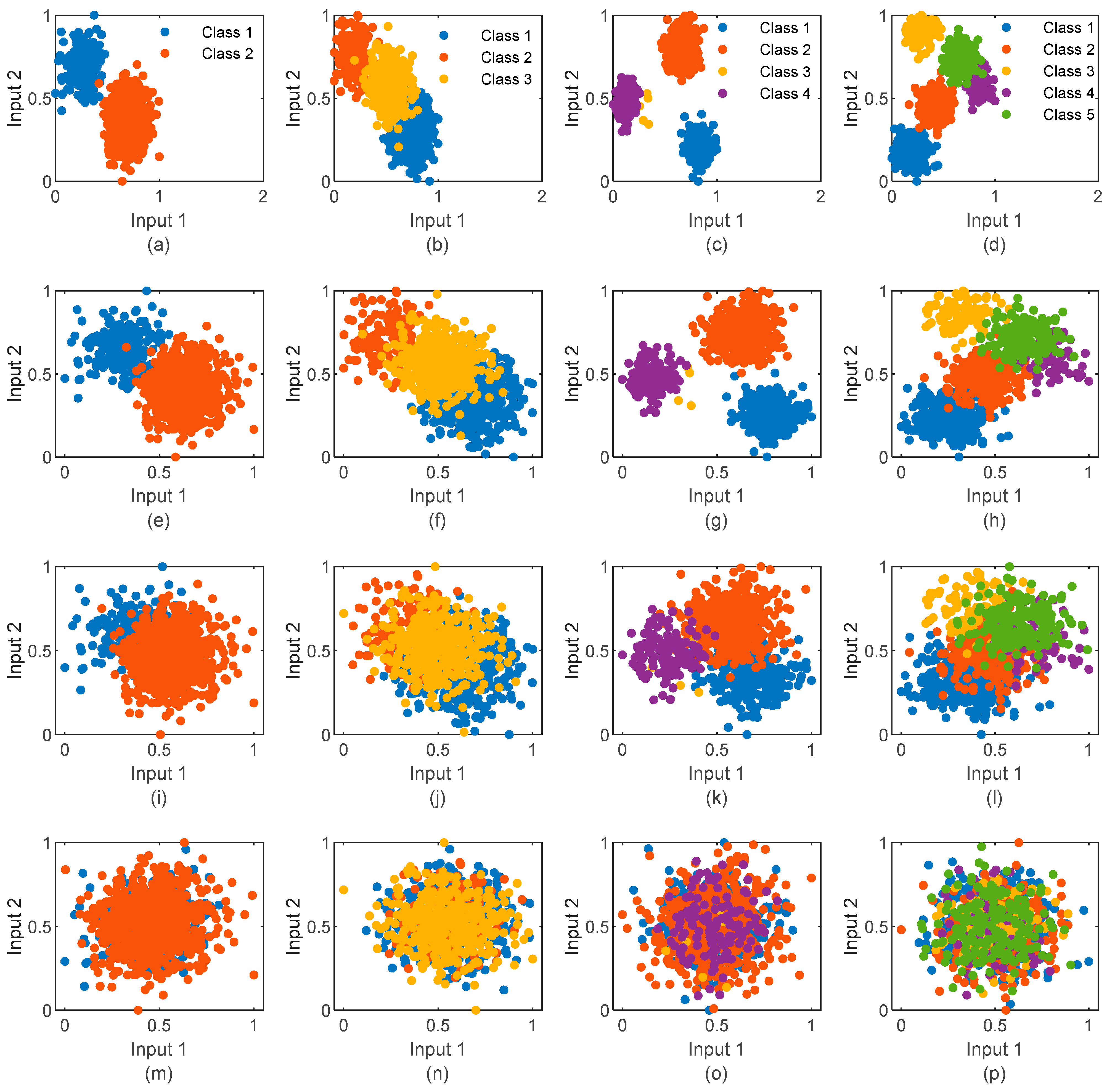
2.1. Dataset Generation
- To emulate real conditions of data complexity related to statistical heterogeneity, and are used as the main parameters to generate a different version of data complexity levels in terms of cardinality. This process was also adopted to make sure that data will be applicable for both conventional small-scale machine learning algorithms and DL.
- To respond to a real problem of systems heterogeneity, the generated dataset contains four levels of complexity: S01, S02, S03 and S04. At each level, four subsets are generated independently for four particular clients, C01, C02, C03 and C04. The subsets generated for each client are independent of each other in terms of distributions, observation scales, class numbers and class proportions.
2.2. Federated Transfer Learning Recursive Least Squares
| Algorithm 1. RLS algorithm. |
| Inputs: Outputs: % Initialization: ; ; % Recursive learning phase For ; ; ; ; End (For) |
| Algorithm 2. FTL-RLS algorithm. |
| Inputs: Outputs: For % Initialization: % Activate parallel computing pool forclients for local training If ; ; End (If) % Recursive learning phase For ; ; ; ; % Encoding with the transpose ; End (For) % Start federated training process % Normalization of weights matrices ; % Deactivate parallel computing pool and work on normal CPU mode % Initiate collaborative training(aggregation) ; % Activate parallel computing pool for clients weights processing % Demoralization of weights matrices ; % Decode with inverse of the transpose and model update weights ; % Deactivate parallel computing pool and work on CPU mode End (For) |
3. Results and Discussion
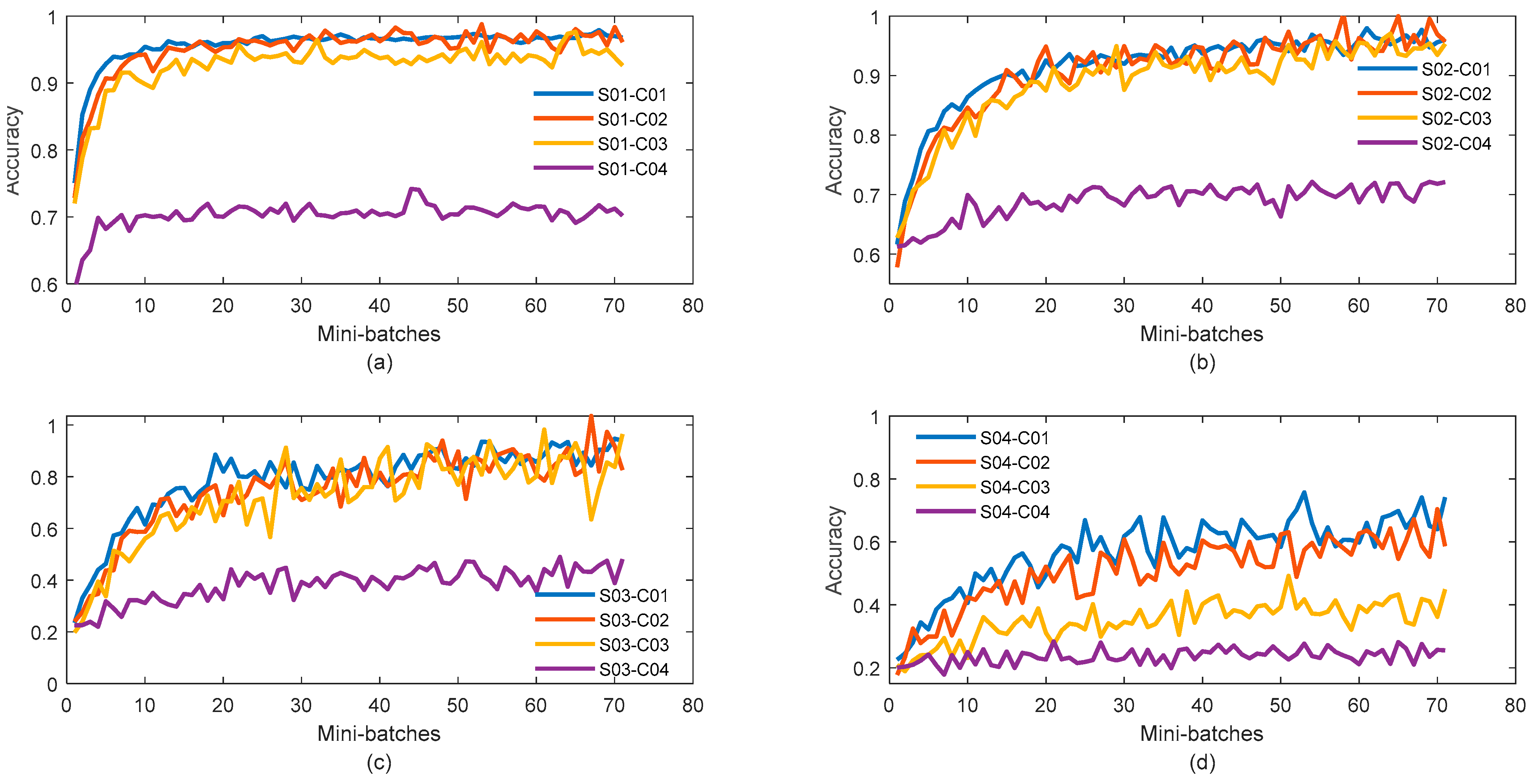
- FTR-RLS performs well at S01 for the different clients, especially C01 and C02 when data classes are only two and three, respectively. When the number of classes gets bigger the training process becomes difficult;
- For the other subsets of S02,S03, and S04, the more the complex the data are, the weaker the training becomes. In this context, we are noticing deterioration in FTR-RLS in terms of convergence speed and accuracy. This means that the model is getting slower when reaching its optimal accuracy, which is also reduced due to data complexity and the increased number of classes;
- By the increase of data complexity, we observe more fluctuation in curves of classification accuracy behavior as a sort of noise. This fluctuation reflects the instability of the training process as a reaction to higher levels of cardinality.
- For each algorithm in general classification accuracies express significant decrease in performances when moving from client C01 to C02. This explains that the number of classes affects the predictions of training models.
- For each algorithm, moving from different levels of data complexity resembled by distance between classes also has a significant impact in performances reduction of performances of learning algorithm.
- The different subsets of C04’s low classification results explain that it is the most challenging part in the generated data.
- It is undeniable that CNN and LSTM could achieve more classification accuracy which is in this case better than FTL-RLS. However, we cannot deny that blackbox models used in this case are strengthened by many default features such as regularization, parameter selection through grid search, adaptive learning optimizers, etc., while FTL-RLS has only basic rules of learning. In this context, the performance of FTL-RLS compared to these algorithms is comparable, which explains its strength in keeping classification performances under FL.
- CNN achieves better results than LSTM owing to its known capabilities in pattern separation through mapping-based local receptive fields.
- ANN and RLS provide almost the same results in this case.
- One of the important FTL-RLS features is “computational time” and “algorithmic simplicity”, related to both “algorithmic architecture” itself (number of instructions) and the “non-iterative” nature of the RLS algorithm. In this context, the training time of FTL-RLS (i.e., s) clarifies that the algorithm performances are way too far better and the algorithmic architecture can be easily constructed and implemented in low computational costly hardware unlike ANN, LSTM and CNN.
- Shared parameter sizes (i.e., weights, biases, etc.) of learning algorithms show that the FTL-RLS encoding process reduces messages sizes with more than compared to ANN, LSTM, CNN and fair comparison.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, Q.; Liu, Y.; Cheng, Y.; Kang, Y.; Chen, T.; Yu, H. Federated Learning. Synth. Lect. Artif. Intell. Mach. Learn. 2019, 13, 1–207. [Google Scholar] [CrossRef]
- Li, L.; Fan, Y.; Tse, M.; Lin, K.-Y. A review of applications in federated learning. Comput. Ind. Eng. 2020, 149, 106854. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated Machine Learning. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Nilsson, A.; Smith, S.; Ulm, G.; Gustavsson, E.; Jirstrand, M. A performance evaluation of federated learning algorithms. DIDL 2018-Proc. 2nd Work. Distrib. Infrastructures Deep Learn. Part Middlew. 2018, 2018, 3286559. [Google Scholar] [CrossRef]
- Liu, B.; Ding, Z. A consensus-based decentralized training algorithm for deep neural networks with communication compression. Neurocomputing 2021, 440, 287–296. [Google Scholar] [CrossRef]
- Deng, L. The MNIST Database of Handwritten Digit Images for Machine Learning Research [Best of the Web]. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Fang, C.; Guo, Y.; Hu, Y.; Ma, B.; Feng, L.; Yin, A. Privacy-preserving and communication-efficient federated learning in Internet of Things. Comput. Secur. 2021, 103, 102199. [Google Scholar] [CrossRef]
- Shakespeare, W. The Complete Works of William Shakespeare. 2020. Available online: http://www.gutenberg.org/ebooks/100 (accessed on 3 September 2022).
- Asad, M.; Moustafa, A.; Ito, T. FedOpt: Towards communication efficiency and privacy preservation in federated learning. Appl. Sci. 2020, 10, 2864. [Google Scholar] [CrossRef]
- Chen, Z.; Liao, W.; Hua, K.; Lu, C.; Yu, W. Towards asynchronous federated learning for heterogeneous edge-powered internet of things. Digit. Commun. Netw. 2021, 7, 317–326. [Google Scholar] [CrossRef]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Cohen, G.; Afshar, S.; Tapson, J.; van Schaik, A. EMNIST: An extension of MNIST to handwritten letters. arXiv 2017, arXiv:1702.05373. [Google Scholar]
- Abdellatif, A.A.; Mhaisen, N.; Mohamed, A.; Erbad, A.; Guizani, M.; Dawy, Z.; Nasreddine, W. Communication-efficient hierarchical federated learning for IoT heterogeneous systems with imbalanced data. Future Gener. Comput. Syst. 2022, 128, 406–419. [Google Scholar] [CrossRef]
- ECG. Heartbeat Categorization Dataset: Segmented and Preprocessed ECG Signals for Heartbeat Classification. 2018. Available online: https://www.kaggle.com/datasets/shayanfazeli/heartbeat (accessed on 28 July 2022).
- Schomer, D.L.; Da Silva, F.L. Niedermeyer’s Electroencephalography: Basic Principles, Clinical Applications, and Related Fields; Lippincott Williams & Wilkins: Philadelphia, PA, USA, 2012. [Google Scholar]
- Feng, S.; Li, B.; Yu, H.; Liu, Y.; Fellow, Q.Y. Semi-Supervised Federated Heterogeneous Transfer Learning. Knowledge-Based Syst. 2015, 14, 109384. [Google Scholar] [CrossRef]
- IMDB Dataset. Available online: https://drive.google.com/file/d/0B8yp1gOBCztyN0JaMDVoeXhHWm8/edit?resourcekey=0-y9_nzlfIi3jTOoMJ0xzahw (accessed on 28 July 2022).
- Van Breukelen, M.; Duin, R.P.W.; Tax, D.M.J.; Den Hartog, J.E. Handwritten digit recognition by combined classifiers. Kybernetika 1998, 34, 381–386. [Google Scholar]
- ALLAML Dataset. Available online: https://jundongl.github.io/scikit-feature/datasets.html (accessed on 28 July 2022).
- Palihawadana, C.; Wiratunga, N.; Wijekoon, A.; Kalutarage, H. FedSim: Similarity guided model aggregation for Federated Learning. Neurocomputing 2022, 483, 432–445. [Google Scholar] [CrossRef]
- Wijekoon, A.; Wiratunga, N.; Cooper, K.; Bach, K. Learning to recognise exercises in the self-management of low back pain. In Proceedings of the Thirty-Third International Flairs Conference, Miami Beach, PA, USA, 7–20 May 2020. [Google Scholar]
- Goodreads Datasets. Available online: https://sites.google.com/eng.ucsd.edu/ucsdbookgraph (accessed on 30 July 2022).
- Hu, L.; Yan, H.; Li, L.; Pan, Z.; Liu, X.; Zhang, Z. MHAT: An efficient model-heterogenous aggregation training scheme for federated learning. Inf. Sci. 2021, 560, 493–503. [Google Scholar] [CrossRef]
- Li, S.; Lv, L.; Li, X.; Ding, Z. Mobile app start-up prediction based on federated learning and attributed heterogeneous network embedding. Future Internet 2021, 13, 256. [Google Scholar] [CrossRef]
- Wahab, O.A.; Rjoub, G.; Bentahar, J.; Cohen, R. Federated against the cold: A trust-based federated learning approach to counter the cold start problem in recommendation systems. Inf. Sci. 2022, 601, 189–206. [Google Scholar] [CrossRef]
- MovieLens. Available online: https://grouplens.org/datasets/movielens/1m (accessed on 30 July 2022).
- Epinions. Available online: http://www.epinions.com (accessed on 30 July 2022).
- Wang, F.; Zhu, H.; Lu, R.; Zheng, Y.; Li, H. A privacy-preserving and non-interactive federated learning scheme for regression training with gradient descent. Inf. Sci. 2021, 552, 183–200. [Google Scholar] [CrossRef]
- Chen, Y.; Luo, F.; Li, T.; Xiang, T.; Liu, Z.; Li, J. A training-integrity privacy-preserving federated learning scheme with trusted execution environment. Inf. Sci. 2020, 522, 69–79. [Google Scholar] [CrossRef]
- Berghout, T.; Benbouzid, M.; Muyeen, S.M. Machine Learning for Cybersecurity in Smart Grids: A Comprehensive Review-based Study on Methods, Solutions, and Prospects. Int. J. Crit. Infrastruct. Prot. 2022, 38, 100547. [Google Scholar] [CrossRef]
- Berghout, T.; Benbouzid, M. A Systematic Guide for Predicting Remaining Useful Life with Machine Learning. Electronics 2022, 11, 1125. [Google Scholar] [CrossRef]
- Berghout, T.; Benbouzid, M. EL-NAHL: Exploring labels autoencoding in augmented hidden layers of feedforward neural networks for cybersecurity in smart grids. Reliab. Eng. Syst. Saf. 2022, 226, 108680. [Google Scholar] [CrossRef]
- Fachada, N.; Rosa, A.C. generateData—A 2D data generator. Softw. Impacts 2020, 4, 100017. [Google Scholar] [CrossRef]
- Berghout, T.; Mouss, L.; Kadri, O.; Saïdi, L.; Benbouzid, M. Aircraft Engines Remaining Useful Life Prediction with an Improved Online Sequential Extreme Learning Machine. Appl. Sci. 2020, 10, 1062. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FL Challenges | Ref | Dataset | Algorithm | Main Contributions in FL Besides Model Aggregation |
|---|---|---|---|---|
| Expensive communication | [5] | MNIST [6] | FedAvg variants | Using consensus algorithm to make the training of the global model able to adapt to: (i) a heavy communication load and (ii) to avoid communication blocking problems that can be caused by standard FL algorithms such as FedAvg or FSVRG |
| [7] | MNIST [6] and comprehensive work of William Shakespeare [8] | Using a bi-directional compression where computationless compression operators are employed to quantify gradients on both global and local model frameworks | ||
| [9] | MNIST [6] | Using a sparse coding algorithm for efficient communication with additive holomorphic encryption including a differential privacy to prevent data leakage | ||
| Systems heterogeneity | [10] | MNIST dataset [6], fashion-MNIST dataset [11], and EMNIST dataset [12] | Using an iterative node selection algorithm for efficient management of the FL learning tasks by taking into account the non-synchronization of the delivered messages | |
| [13] | Heartbeat dataset [14] and the Seizure dataset [15] | Using hierarchical FL in heterogeneous systems by introducing an optimized solution for user assignment and resource allocation by paying attention to variants based on gradient descent while taking unbalanced data into account | ||
| [16] | IMDB [17], Handwritten [18] and ALLAML [19] datasets | Using a semi-supervised FL for heterogeneous transfer learning to take advantage of unlabeled non-overlapping samples and to help reduce overfitting | ||
| Statistical heterogeneity | [20] | MNIST [6], Fed-MEx [21], and Fed-Goodreads [22] | Using similarity between clients to model their relationships by involving clients similar gradients to provide better coverage | |
| [23] | MNIST dataset [6] | Using MHAT for local model problems containing various network architectures while KD techniques are investigated for information extraction and global model update | ||
| [24] | LiveLab dataset | Using a mobile application startup prediction model based on FL | ||
| Privacy concerns | [25] | MovieLens [26] and Epinions [27] datasets | Using a trust-based mechanism and extensive reinforcement learning for potential recommender planning and candidate selection. | |
| [28] | / | Using VANE to perform aggregation without disclosing private information without any interaction between clients | ||
| [29] | MNIST dataset [6] | Using a privacy-preserving FL with DL processes based on the trusted execution environment (TEE) |
| Parameter | Description |
|---|---|
| Mean of the radians of clusters which are originally drawn from a normal distribution | |
| Standard deviation of cluster angle | |
| Number of clusters | |
| Average distance between classes centers within X axis | |
| Average distance between classes centers within Y axis | |
| Mean of length of which originally are drawn from normal distribution | |
| Standard deviation of clusters lengths | |
| Clusters fatness which is the standard deviation of the distance between each point and the projection line | |
| Number of observations in the generated data |
| Client→ | C01 | C02 | ||||||||||||||||
| Subset↓ | ||||||||||||||||||
| S01 | 2 | 30 | 30 | 2 | 2 | 10 | 1000 | 3 | 30 | 30 | 2 | 2 | 10 | 1000 | ||||
| S02 | 2 | 20 | 20 | 2 | 2 | 10 | 1000 | 3 | 20 | 20 | 2 | 2 | 10 | 1000 | ||||
| S03 | 2 | 10 | 10 | 2 | 2 | 10 | 1000 | 3 | 10 | 10 | 2 | 2 | 10 | 1000 | ||||
| S04 | 2 | 0 | 0 | 2 | 2 | 10 | 1000 | 3 | 0 | 0 | 2 | 2 | 10 | 1000 | ||||
| Client→ | C03 | C04 | ||||||||||||||||
| Subset↓ | ||||||||||||||||||
| S01 | 4 | 30 | 30 | 2 | 2 | 10 | 1000 | 5 | 30 | 30 | 2 | 2 | 10 | 1000 | ||||
| S02 | 4 | 20 | 20 | 2 | 2 | 10 | 1000 | 5 | 20 | 20 | 2 | 2 | 10 | 1000 | ||||
| S03 | 4 | 10 | 10 | 2 | 2 | 10 | 1000 | 5 | 10 | 10 | 2 | 2 | 10 | 1000 | ||||
| S04 | 4 | 0 | 0 | 2 | 2 | 10 | 1000 | 5 | 0 | 0 | 2 | 2 | 10 | 1000 | ||||
| Algorithm | Subset | Shared Parameters Sizes (Bytes) | Training Time (Seconds) | ||||
|---|---|---|---|---|---|---|---|
| C01 | C02 | C03 | C04 | ||||
| FTR-RLS | S01 | 0.978 | 0.993 | 0.985 | 0.731 | Size of encoded weights | |
| S02 | 0.973 | 0.954 | 0.978 | 0.725 | |||
| S03 | 0.978 | 0.960 | 0.932 | 0.504 | |||
| S04 | 0.764 | 0.486 | 0.582 | 0.320 | |||
| Mean | 0.8027 | ||||||
| ANN (FedAvg) | S01 | 0.977 | 0.993 | 0.970 | 0.734 | Weights and biases of inputs, hidden layers and output layers: | 45.63 |
| S02 | 0.977 | 0.958 | 0.980 | 0.728 | |||
| S03 | 0.972 | 0.954 | 0.936 | 0.500 | |||
| S04 | 0.711 | 0.452 | 0.542 | 0.298 | |||
| Mean | 0.7926 | ||||||
| LSTM (FedAvg) | S01 | 0.999 | 0.997 | 0.992 | 0.730 | Weights and biases of inputs, hidden layers and output layers: | 108.22 |
| S02 | 0.995 | 0.979 | 0.993 | 0.721 | |||
| S03 | 0.999 | 0.975 | 0.999 | 0.741 | |||
| S04 | 0.773 | 0.428 | 0.585 | 0.329 | |||
| Mean | 0.8272 | ||||||
| CNN (FedAvg) | S01 | 1.000 | 1.000 | 0.995 | 0.732 | Weights and biases of local fields, convolutional layers, pooling layers, and output layers, etc.: | 122.36 |
| S02 | 1.050 | 1.034 | 1.048 | 0.761 | |||
| S03 | 0.997 | 0.973 | 0.997 | 0.740 | |||
| S04 | 0.842 | 0.466 | 0.637 | 0.358 | |||
| Mean | 0.8519 | ||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Berghout, T.; Bentrcia, T.; Ferrag, M.A.; Benbouzid, M. A Heterogeneous Federated Transfer Learning Approach with Extreme Aggregation and Speed. Mathematics 2022, 10, 3528. https://doi.org/10.3390/math10193528
Berghout T, Bentrcia T, Ferrag MA, Benbouzid M. A Heterogeneous Federated Transfer Learning Approach with Extreme Aggregation and Speed. Mathematics. 2022; 10(19):3528. https://doi.org/10.3390/math10193528
Chicago/Turabian StyleBerghout, Tarek, Toufik Bentrcia, Mohamed Amine Ferrag, and Mohamed Benbouzid. 2022. "A Heterogeneous Federated Transfer Learning Approach with Extreme Aggregation and Speed" Mathematics 10, no. 19: 3528. https://doi.org/10.3390/math10193528
APA StyleBerghout, T., Bentrcia, T., Ferrag, M. A., & Benbouzid, M. (2022). A Heterogeneous Federated Transfer Learning Approach with Extreme Aggregation and Speed. Mathematics, 10(19), 3528. https://doi.org/10.3390/math10193528