


ConvFaceNeXt: Lightweight Networks for Face Recognition



Abstract
:1. Introduction
- We propose a family of lightweight face recognition models known generally as ConvFaceNeXt. The proposed models have three major components, namely the stem partition, the bottleneck partition and the embedding partition. With different combinations of downsampling approaches in the stem partition and the bottleneck partition, four models of ConvFaceNeXt are proposed. These downsampling approaches differ in kernel size for convolutional operation. Specifically, the patchify approach involving a non-overlapping patch is introduced in addition to the typical overlapping approach. All of the ConvFaceNeXt models are lightweight yet still able to achieve comparable or better performance.
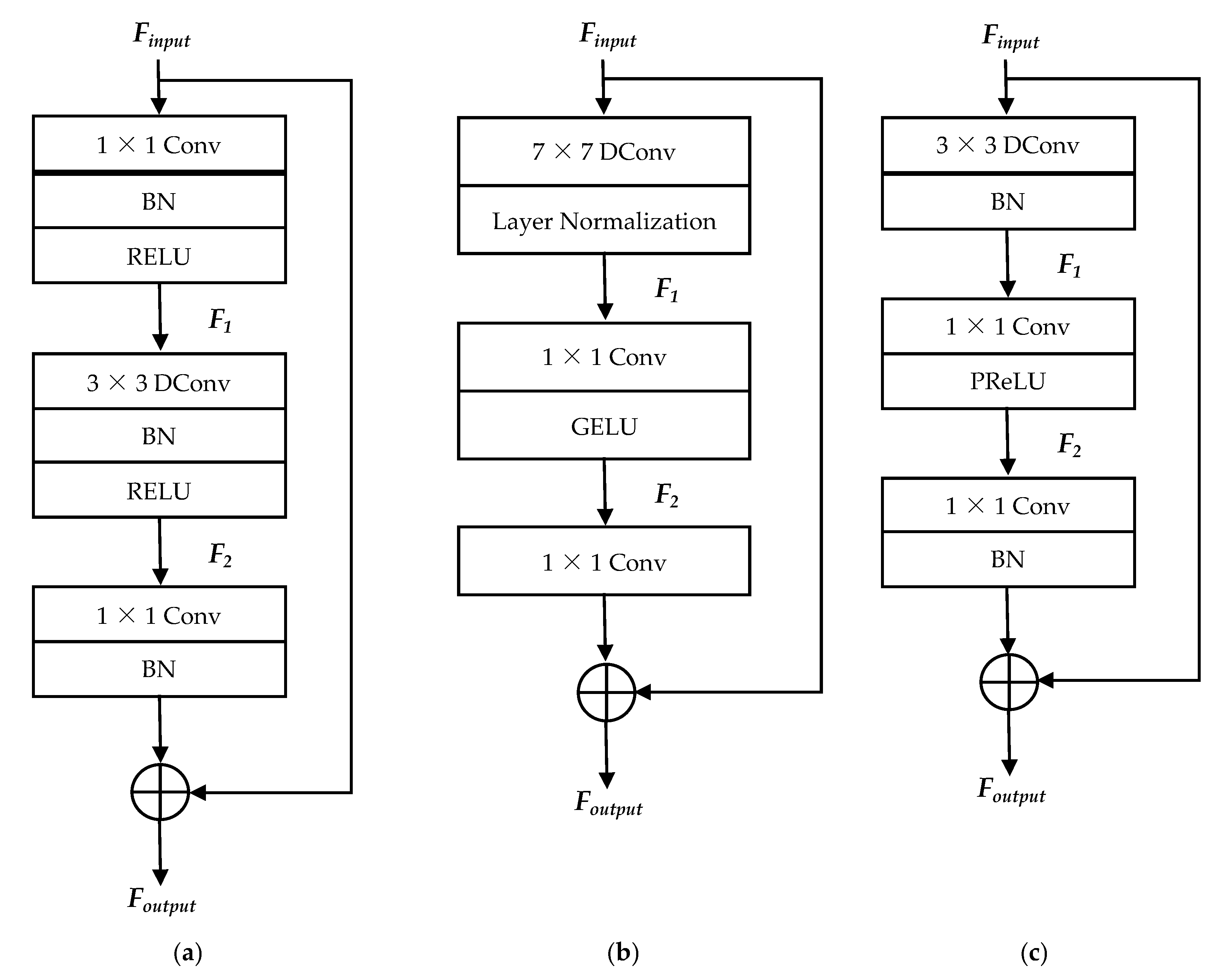
- We improve and enhance the existing ConvNeXt block for face recognition tasks. Hence, a new structure known as an enhanced ConvNeXt (ECN) block is proposed. Given the same input tensor and expansion factor, the ECN block has significantly lower FLOPs and parameter counts compared with the inverted residual block and ConvNeXt block. These advantages are mainly due to the arrangement of depthwise convolution in the first layer of the ECN block as well as the smaller kernel size. Multiple ECN blocks are stacked repeatedly in the bottleneck partition to form the core part of ConvFaceNeXt.
- We capture more comprehensive and richer face features with less information loss. This is accomplished by aggregating the blocks with the same output dimension for the three respective stages in the bottleneck partition. The aggregation process ensures information correlation for all the generated features within the same stage. In addition, the impact of the vanishing gradient problem can be minimised because the high-level and low-level features of each stage are linked through aggregation. Thus, ConvFaceNeXt models are resistant to information loss, as more feature details can be preserved.
2. Related Works
3. Proposed Approach
3.1. Preliminaries
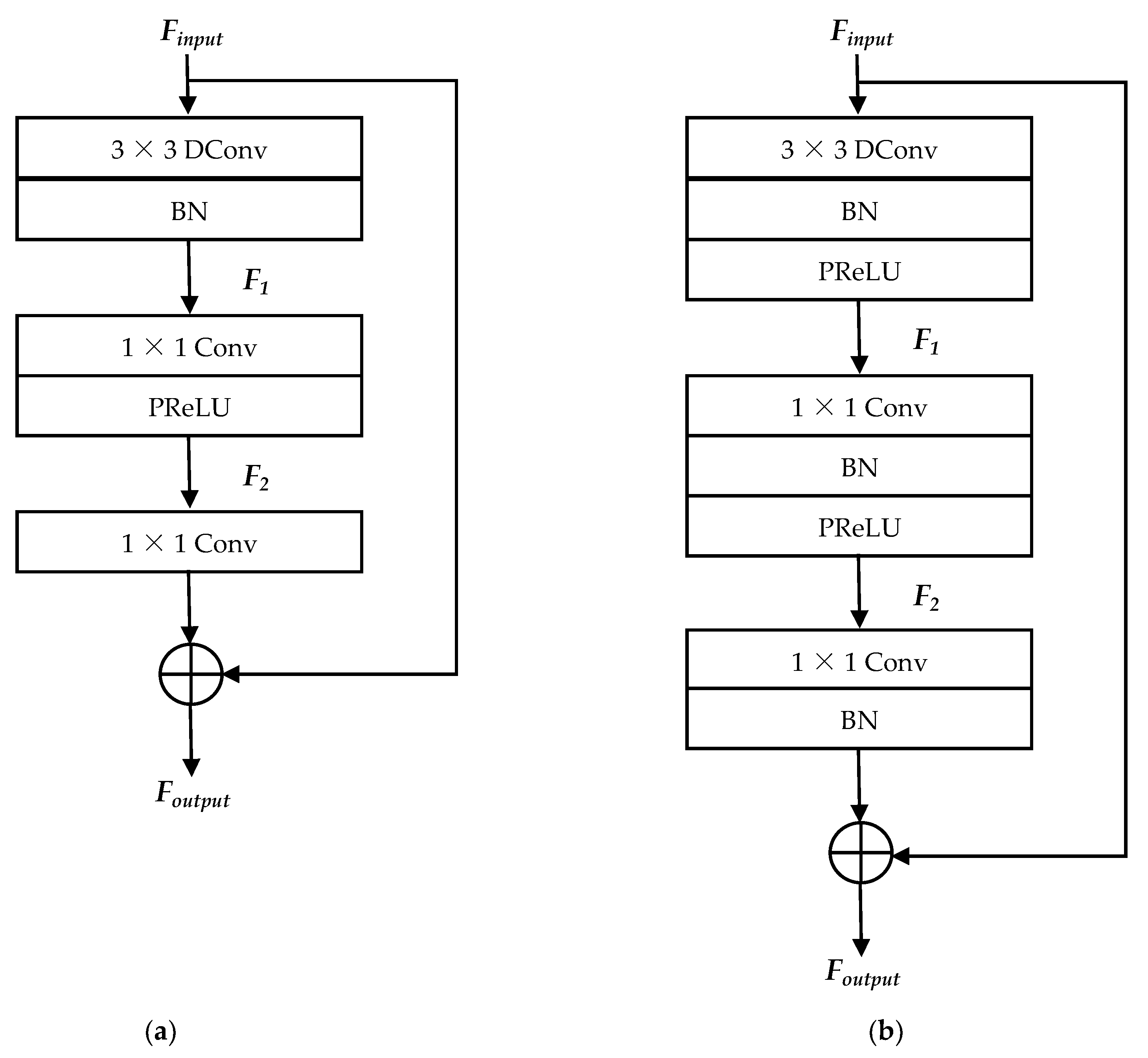
3.2. Enhanced ConvNeXt Block for the Lightweight Model
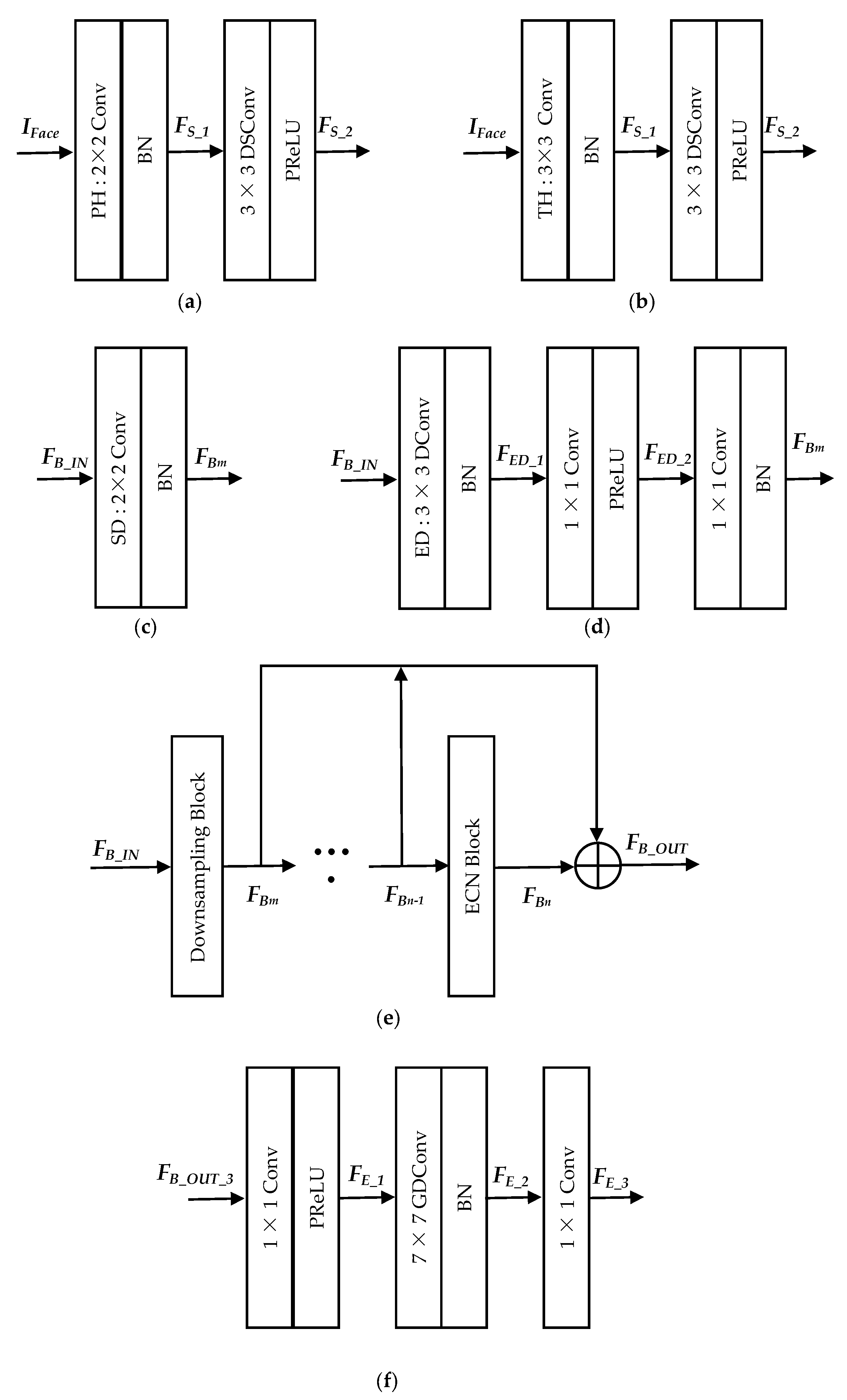
3.3. ConvFaceNeXt Architecture
3.3.1. Stem Partition
3.3.2. Bottleneck Partition
3.3.3. Embedding Partition
4. Experiments and Analysis
4.1. Dataset
- The Labeled Faces in the Wild (LFW) [41] dataset consists of 13,233 face images from 5749 identities. The majority of the face images are frontal or near-frontal. The verification evaluation comprises 6000 pairs of face images, which includes 3000 positive face pairs and 3000 negative face pairs.
- Cross-Age LFW (CALFW) [42] is the revised version of LFW, where 3000 positive face pairs are obtained from the same individual with a notable age gap, whereas the remaining 3000 negative face pairs are from different individuals of the same gender and race.
- Cross-Pose LFW (CPLFW) [43] is derived from LFW with intra-class pose variation for the 3000 positive face pairs while ensuring the same gender and race attributes for the other 3000 negative face pairs.
- The CFP [44] dataset contains 7000 face images from 500 identities, where each identity has 10 frontal and 4 profile face images. There are 3500 positive face pairs and 3500 negative face pairs. The evaluations are conducted based on two protocols, namely frontal-frontal (CFP-FF) and frontal-profile (CFP-FP).
- AgeDB [45] includes 16,488 face images of 568 identities used for age-invariant face verification. This dataset contains 3000 positive and 3000 negative face pairs. There are four face verification protocols, each with different age gaps of 5, 10, 20 and 30. AgeDB-30, with the largest age gap, was used for evaluation since it is harder compared with the other three protocols.
- VGGFace2 [7] comprises 3.31 million face images from 9131 individuals. The VGGFace2 dataset is split into two parts, where the training dataset has 8631 individuals while the evaluation set has only 500 individuals. Two evaluation protocols are available, which include evaluation over the pose and age variations. VGG2-FP, which emphasizes pose variation, was chosen as the benchmark to evaluate 2500 positive and 2500 negative face pairs.
- IARPA Janus Benchmarks (IJB) [46,47] set a new phase in unconstrained face recognition with several series of datasets. These datasets are more challenging, with further unconstrained face samples under significant pose, illumination and image quality variations. In contrast to other image-to-image or video-to-video datasets, each IJB is a template-based dataset with both still images and video frames. The IJB-B [46] dataset consists of 1845 individuals. This dataset has 21,798 still images in addition to 55,026 frames from 7011 videos. The 1:1 baseline verification of the IJB-B dataset is based on 10,270 genuine comparisons and 8 million imposter comparisons. On the other hand, there are 3531 individuals for the IJB-C [47] dataset. This dataset comprises 31,334 still images alongside 117,542 frames from 11,779 videos. The 1:1 baseline verification consists of 19,557 genuine comparisons and 15,638,932 imposter comparisons.
4.2. Experimental Settings
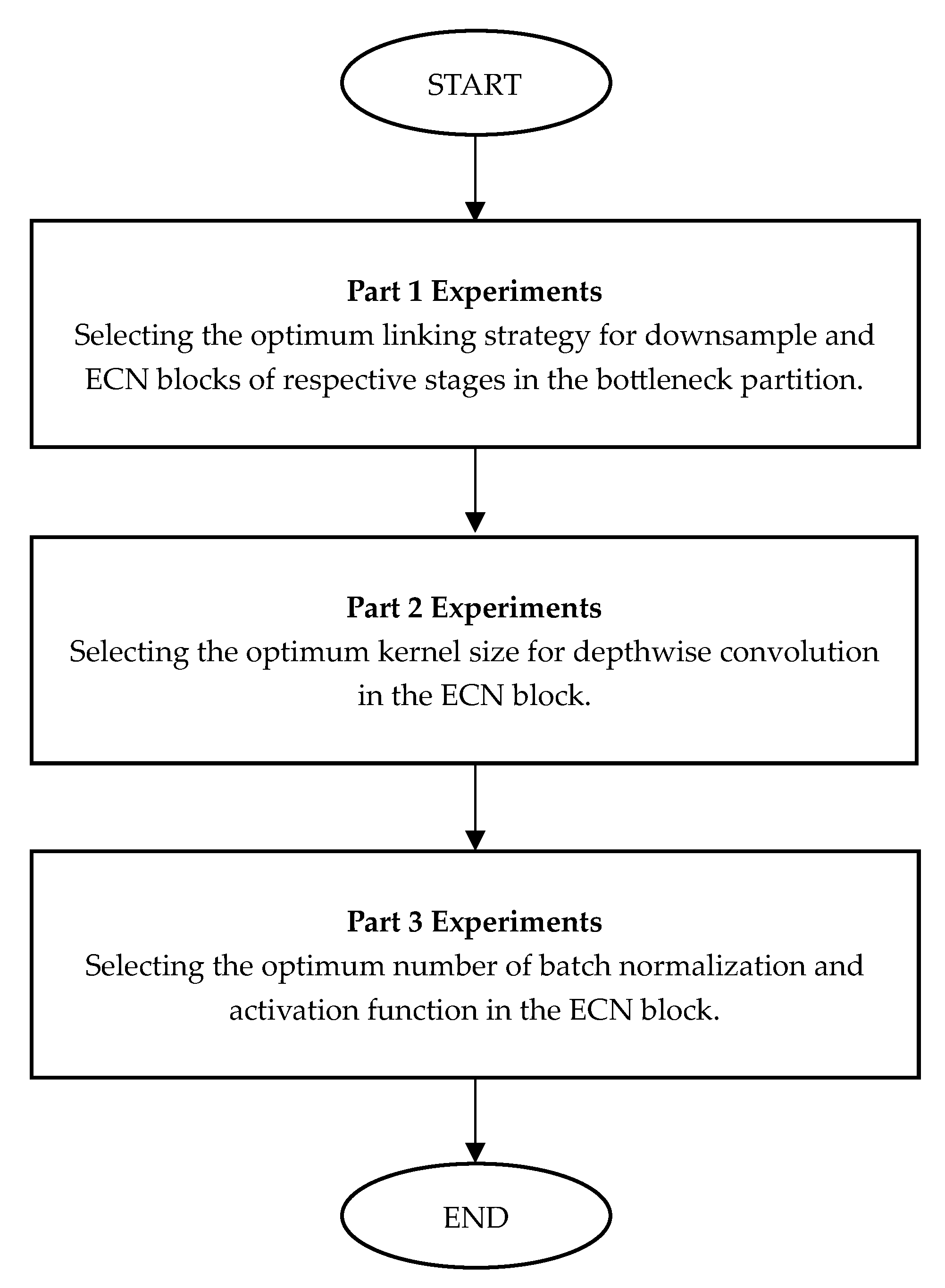
4.3. Ablation Studies
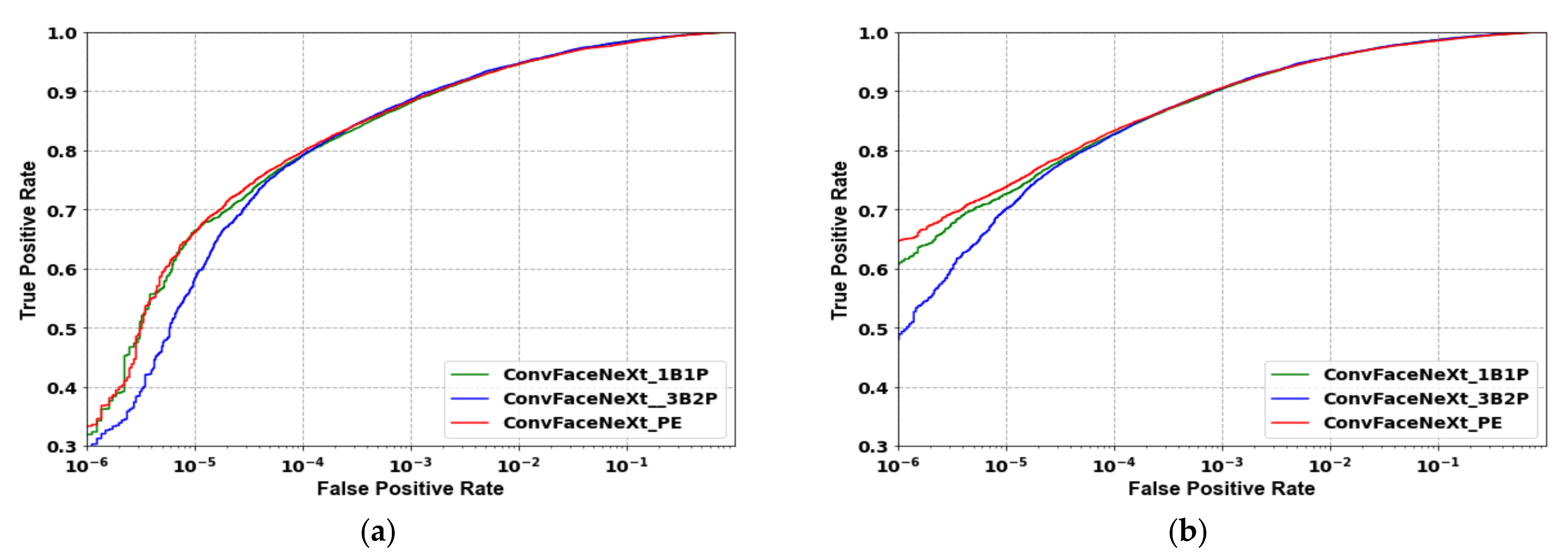
4.3.1. Effect of Different Linking Strategies
4.3.2. Effect of Different Kernel Sizes
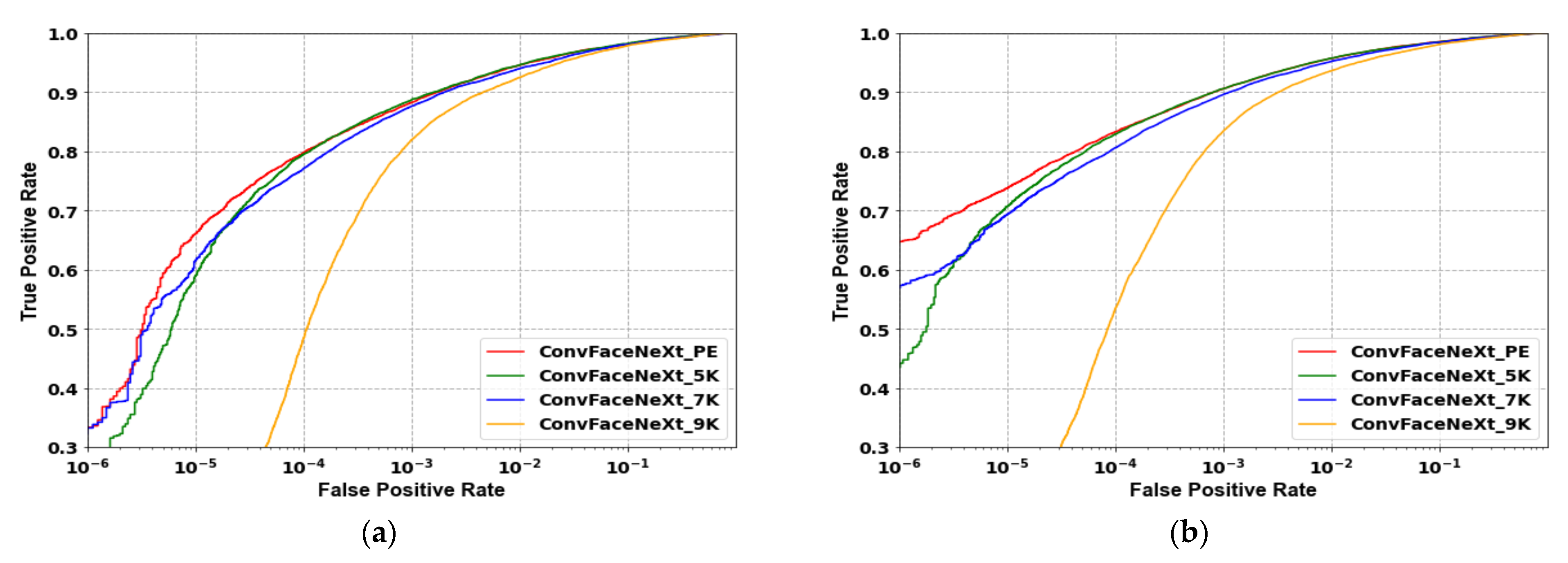
4.3.3. Effect on Different Numbers of Batch Normalisations and Activation Functions
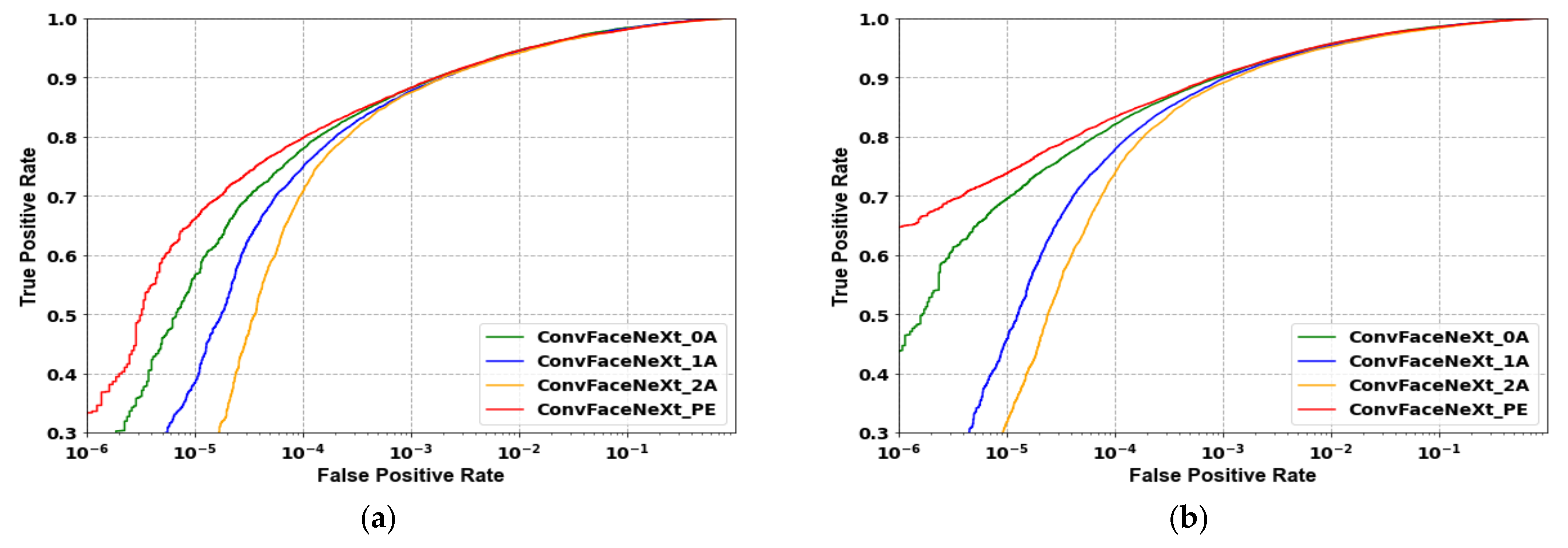
4.4. Quantitative Analysis
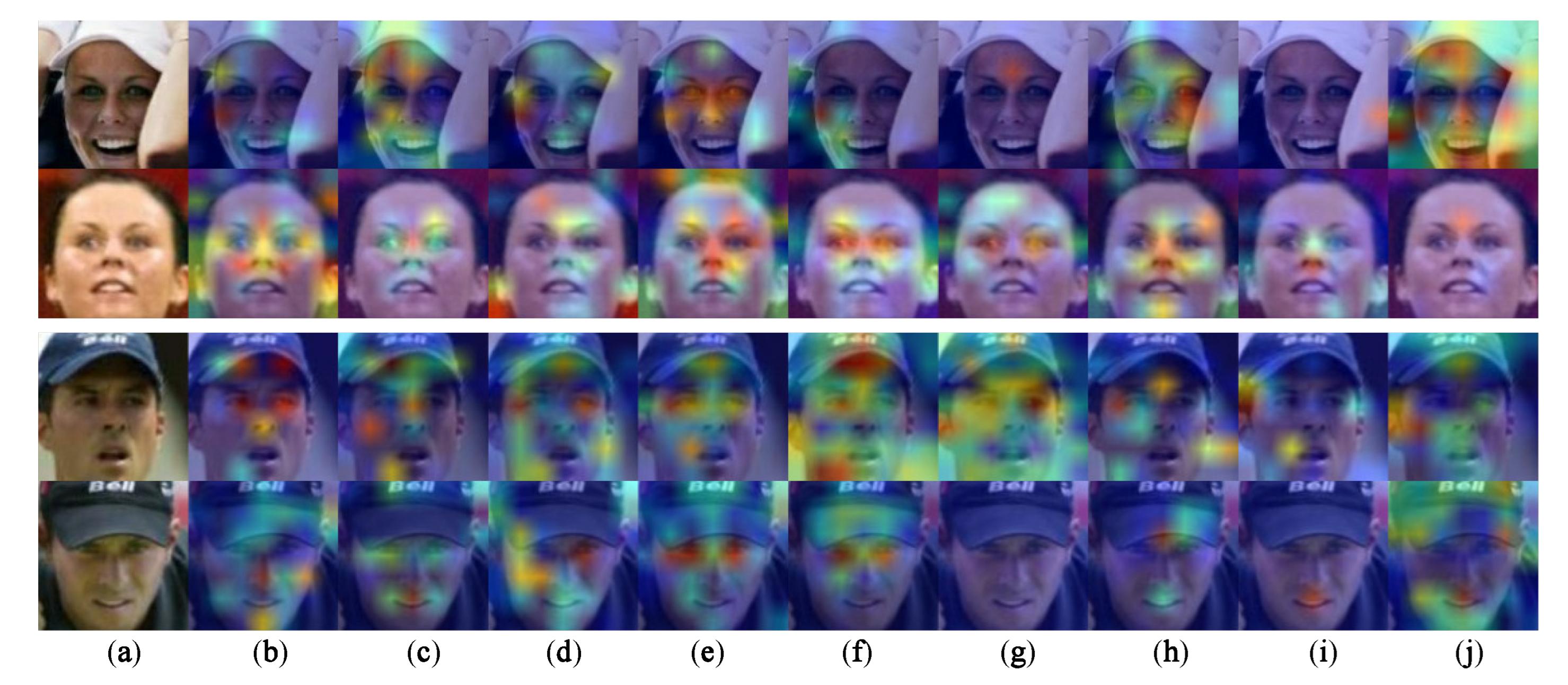
4.5. Qualitative Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Taskiran, M.; Kahraman, N.; Erdem, C.E. Face Recognition: Past, Present and Future (A Review). Digit. Signal Process. 2020, 106, 102809. [Google Scholar] [CrossRef]
- Ranjan, R.; Sankaranarayanan, S.; Bansal, A.; Bodla, N.; Chen, J.C.; Patel, V.M.; Castillo, C.D.; Chellappa, R. Deep Learning for Understanding Faces: Machines May Be Just as Good, or Better, than Humans. IEEE Signal Process. Mag. 2018, 35, 66–83. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, J.; Hu, J.; Wang, Z.; Chen, J.; Hu, J. Multi-View Cosine Similarity Learning with Application to Face Verification. Mathematics 2022, 10, 1800. [Google Scholar] [CrossRef]
- Hoo, S.C.; Ibrahim, H. Biometric-based Attendance Tracking System for Education Sectors: A Literature Survey on Hardware Requireemnts. J. Sens. 2019, 2019, 7410478. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.A.; Wolf, L. Deepface: Closing the Gap to Human-Level Performance in Face Verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1701–1708. [Google Scholar]
- Cao, Q.; Shen, L.; Xie, W.; Parkhi, O.M.; Zisserman, A. VGGFace2: A Dataset for Recognising Faces across Pose and Age. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 67–74. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef] [Green Version]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 122–138. [Google Scholar]
- Chen, S.; Liu, Y.; Gao, X.; Han, Z. MobileFaceNets: Efficient CNNs for Accurate Real-Time Face Verification on Mobile Devices. In Biometric Recognition. CCBR 2018; Springer: Cham, Switzerland, 2018; pp. 428–438. [Google Scholar]
- Martindez-Díaz, Y.; Luevano, L.S.; Mendez-Vazquez, H.; Nicolas-Diaz, M.; Chang, L.; Gonzalez-Mendoza, M. ShuffleFaceNet: A Lightweight Face Architecture for Efficient and Highly-Accurate Face Recognition. In Proceedings of the 2019 IEEE/CVF International Conference on Computer VisionWorkshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 2721–2728. [Google Scholar]
- Martínez-Díaz, Y.; Nicolás-Díaz, M.; Méndez-Vázquez, H.; Luevano, L.S.; Chang, L.; Gonzalez-Mendoza, M.; Sucar, L.E. Benchmarking Lightweight Face Architectures on Specific Face Recognition Scenarios. Artif. Intell. Rev. 2021, 54, 6201–6244. [Google Scholar] [CrossRef]
- Cai, H.; Zhu, L.; Han, S. ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware. In Proceedings of the 2019 7th International Conference on Learning Representation (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Liu, W.; Zhou, L.; Chen, J. Face Recognition Based on Lightweight Convolutional Neural Networks. Information 2021, 12, 191. [Google Scholar] [CrossRef]
- Boutros, F.; Damer, N.; Fang, M.; Kirchbuchner, F.; Kuijper, A. MixFaceNets: Extremely Efficient Face Recognition Networks. In Proceedings of the 2021 International IEEE Joint Conference on Biometrics (IJCB), Shenzhen, China, 4–7 August 2021. [Google Scholar]
- Tan, M.; Le, Q.V. MixConv: Mixed Depthwise Convolutional Kernels. In Proceedings of the 2019 30th British Machine Vision Conference (BMVC), Cardiff, UK, 9–12 September 2019. [Google Scholar]
- Zhang, P.; Zhao, F.; Liu, P.; Li, M. Efficient Lightweight Attention Network for Face Recognition. IEEE Access 2022, 10, 31740–31750. [Google Scholar] [CrossRef]
- Boutros, F.; Siebke, P.; Klemt, M.; Damer, N.; Kirchbuchner, F.; Kuijper, A. PocketNet: Extreme Lightweight Face Recognition Network Using Neural Architecture Search and Multistep Knowledge Distillation. IEEE Access 2022, 10, 46823–46833. [Google Scholar] [CrossRef]
- Liu, H.; Simonyan, K.; Yang, Y. DARTS: Differentiable Architecture Search. In Proceedings of the 2019 7th International Conference on Learning Representation (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. arXiv 2022, arXiv:2201.03545. [Google Scholar]
- Mondal, M.; Das, B.; Roy, S.D.; Singh, P.; Lall, B.; Joshi, S.D. Adaptive CNN Filter Pruning Using Global Importance Metric. Comput. Vis. Image Underst. 2022, 222, 103511. [Google Scholar] [CrossRef]
- Hupont, I.; Tolan, S.; Gunes, H.; Gómez, E. The Landscape of Facial Processing Applications in The Context of The European AI Act and The Development of Trustworthy Systems. Sci. Rep. 2022, 12, 10688. [Google Scholar] [CrossRef] [PubMed]
- Boutros, F. Efficient and High Performing Biometrics: Towards Enabling Recognition in Embedded Domains. Ph.D. Thesis, Technical University of Darmstadt, Darmstadt, Germany, June 2022. [Google Scholar]
- Minaee, S.; Liang, X.; Yan, S. Modern Augmented Reality: Applications, Trends, and Future Directions. arXiv 2022, arXiv:2202.09450. [Google Scholar]
- Shah, S.W.; Kanhere, S.S. Recent Trends in User Authentication—A Survey. IEEE Access 2019, 7, 112505–112519. [Google Scholar] [CrossRef]
- Brown, D. Mobile Attendance based on Face Detection and Recognition using OpenVINO. In Proceedings of the 2021 International Conference on Artificial Intelligence and Smart Systems (ICAIS), Coimbatore, India, 25–27 March 2021. [Google Scholar]
- Shaukat, Z.; Akhtar, F.; Fang, J.; Ali, S.; Azeem, M. Cloud based Face Recognition for Google Glass. In Proceedings of the 2018 International Conference on Computing and Artificial Intelligence (ICCAI), Chengdu, China, 12–14 March 2018. [Google Scholar]
- Deng, J.; Guo, J.; Zhang, D.; Deng, Y.; Lu, X.; Shi, S. Lightweight Face Recognition Challenge. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Deng, J.; Guo, J.; Yang, J.; Xue, N.; Cotsia, I.; Zafeiriou, S.P. ArcFace: Additive Angular Margin Loss for Deep Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5962–5979. [Google Scholar] [CrossRef]
- Xiao, J.; Jiang, G.; Liu, H. A Lightweight Face Recognition Model based on MobileFaceNet for Limited Computation Environment. EAI Endorsed Trans. Internet Things 2022, 7. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolu-tional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Jia, W.; Ren, Q.; Zhao, Y.; Li, S.; Min, H.; Chen, Y. EEPNet: An Efficient and Effective Convolutional Neural Network for Palmprint Recognition. Pattern Recognit Lett. 2022, 159, 140–149. [Google Scholar] [CrossRef]
- Bansal, A.; Nanduri, A.; Castillo, C.D.; Ranjan, R.; Chellappa, R. UMDFaces: An Annotated Face Dataset for Training Deep Networks. In Proceedings of the IEEE International Joint Conference on Biometrics (IJCB), Denver, CO, USA, 1–4 October 2017; pp. 464–473. [Google Scholar] [CrossRef] [Green Version]
- Yi, D.; Lei, Z.; Liao, S.; Li, S. Learning Face Representation from Scratch. arXiv 2014, arXiv:1411.7923. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition. In Proceedings of the BMVC 2015—British Machine Vision Conference, Swansea, UK, 7–10 September 2015. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Zhang, P.; Xiong, H.; Zhao, J. Face.EvoLVe: A Cross-Platform Library for High-Performance Face Analytics. Neurocomputing 2022, 494, 443–445. [Google Scholar] [CrossRef]
- Huang, G.B.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments. In Proceedings of the Workshop on Faces in ‘Real-Life’ Images: Detection, Alignment, and Recognition, Marseille, France, 12–18 October 2008. [Google Scholar]
- Zheng, T.; Deng, W.; Hu, J. Cross-Age LFW: A Database for Studying Cross-Age Face Recognition in Unconstrained Environments. arXiv 2017, arXiv:1708.08197. [Google Scholar] [CrossRef]
- Zheng, T.; Deng, W. Cross-Pose LFW: A Database for Studying Cross-Pose Face Recognition in Unconstrained Environments; Technical Report; Beijing University of Posts and Telecommunications: Beijing, China, 2018; Available online: http://www.whdeng.cn/CPLFW/Cross-Pose-LFW.pdf (accessed on 5 January 2022).
- Sengupta, S.; Chen, J.C.; Castillo, C.; Patel, V.M.; Chellappa, R.; Jacobs, D.W. Frontal to Profile Face Verification in the Wild. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–9 March 2016; pp. 1–9. [Google Scholar] [CrossRef]
- Moschoglou, S.; Papaioannou, A.; Sagonas, C.; Deng, J.; Kotsia, I.; Zafeiriou, S. AgeDB: The First Manually Collected, In-the-Wild Age Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 June 2017; pp. 51–59. [Google Scholar] [CrossRef] [Green Version]
- Whitelam, C.; Taborsky, E.; Blanton, A.; Maze, B.; Adams, J.; Miller, T.; Kalka, N.; Jain, A.K.; Duncan, J.A.; Allen, K.; et al. IARPA Janus Benchmark-B Face Dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 June 2017; pp. 592–600. [Google Scholar] [CrossRef]
- Maze, B.; Adams, J.; Duncan, J.A.; Kalka, N.; Miller, T.; Otto, C.; Jain, A.K.; Niggel, W.T.; Anderson, J.; Cheney, J.; et al. IARPA Janus Benchmark-C: Face Dataset and Protocol. In Proceedings of the 2018 International Conference on Biometrics (ICB), Queensland, Australia, 20–23 February 2018; pp. 158–165. [Google Scholar] [CrossRef]
- Russell, S.; Norvig, P. Artifcial Intelligence: A Modern Approach, 4th Global ed.; Pearson Education Limited: London, UK, 2022. [Google Scholar]
- Wang, Z.; Bai, Y.; Zhou, Y.; Xie, C. Can CNNs Be More Robust Than Transformers? arXiv 2022, arXiv:2206.03452. [Google Scholar] [CrossRef]
- Wang, H.; Wang, Y.; Zhou, Z.; Ji, X.; Gong, D.; Zhou, J.; Li, Z.; Liu, W. CosFace: Large Margin Cosine Loss for Deep Face Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 5265–5274. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef] [Green Version]
- Zhao, J.; Han, J.; Shao, L. Unconstrained Face Recognition Using a Set-to-Set Distance Measure on Deep Learned Features. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 2679–2689. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Guo, G. LS-CNN: Characterizing Local Patches at Multiple Scales for Face Recognition. IEEE Trans. Inf. Forensics Secur. 2019, 15, 1640–1653. [Google Scholar] [CrossRef]
- Boutros, F.; Damer, N.; Kirchbuchner, F.; Kuijper, A. ElasticFace: Elastic Margin Loss for Deep Face Recogni-tion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–20 June 2022; pp. 1577–1586. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Dimension | Operator | Output Dimension |
|---|---|---|
| DConv, BN | ||
| Conv, PReLU | ||
| Conv, BN |
| ConvFaceNeXt Family Member | Stem Partition | Bottleneck Partition | ||||
|---|---|---|---|---|---|---|
| Patchify Head Configuration | Typical Head Configuration | Separate Downsampling Configuration | ECN Downsampling Configuration | ECN Blocks | Embedding Partition | |
| ConvFace- NeXt_PS | √ | √ | Same ECN | Same embedding | ||
| ConvFace- NeXt_PE | √ | √ | block design | partition design | ||
| ConvFace- NeXt_TS | √ | √ | for all four | for all four | ||
| ConvFace- NeXt_TE | √ | √ | family members | family members | ||
| Input Dimension | Operator | Output Dimension | t | s |
|---|---|---|---|---|
| Stem Partition | ||||
| Stem Cell | - | 2 | ||
| DSConv, PReLU | - | 1 | ||
| Bottleneck Partition | ||||
| Stage One: | ||||
| Downsampling block 1 | 2 * | 2 | ||
| ECN blocks 2–5 | 2 | 1 | ||
| Stage Two: | ||||
| Downsampling block 6 | 4 * | 2 | ||
| ECN blocks 7–13 | 2 | 1 | ||
| Stage Three: | ||||
| Downsampling block 14 | 4 * | 2 | ||
| ECN blocks 15 and 16 | 2 | 1 | ||
| Embedding Partition | ||||
| Conv, PReLU | - | 1 | ||
| linear GDConv, BN | - | 1 | ||
| linear Conv | - | 1 | ||
| Model | Param. (M) | FLOPs (M) | LFW | CALFW | CPLFW | CFP-FF | CFF-FP | AgeDB-30 | VGG2-FP | Average |
|---|---|---|---|---|---|---|---|---|---|---|
| ConvFace NeXt_0A | 1.05 | 404.57 | 98.98 | 93.08 | 85.33 | 98.94 | 86.44 | 92.68 | 88.28 | 91.96 |
| ConvFace NeXt_1A | 1.05 | 404.57 | 99.02 | 93.00 | 85.12 | 98.90 | 86.40 | 92.37 | 88.76 | 91.94 |
| ConvFace NeXt_2A | 1.05 | 404.57 | 99.12 | 92.78 | 85.45 | 98.84 | 86.63 | 93.05 | 88.88 | 92.11 |
| ConvFace NeXt_PE | 1.05 | 404.57 | 99.10 | 93.32 | 85.45 | 98.87 | 87.40 | 92.95 | 88.92 | 92.29 |
| Model | IJB-B | IJB-C | ||||
|---|---|---|---|---|---|---|
| FAR | FAR | FAR | FAR | FAR | FAR | |
| = | = | = | = | = | = | |
| ConvFace NeXt_0A | 56.40 | 77.87 | 88.26 | 69.47 | 82.03 | 90.22 |
| ConvFace NeXt_1A | 38.39 | 74.78 | 87.72 | 45.68 | 77.75 | 89.75 |
| ConvFace NeXt_2A | 20.16 | 70.69 | 87.44 | 31.68 | 73.65 | 89.08 |
| ConvFace NeXt_PE | 66.11 | 79.77 | 88.22 | 73.75 | 83.27 | 90.56 |
| Model | Param. (M) | FLOPs (M) | LFW | CALFW | CPLFW | CFP-FF | CFF-FP | AgeDB-30 | VGG2-FP | Average |
|---|---|---|---|---|---|---|---|---|---|---|
| ConvFace NeXt_PE | 1.05 | 404.57 | 99.10 | 93.32 | 85.45 | 98.87 | 87.40 | 92.95 | 88.92 | 92.29 |
| ConvFace NeXt_5K | 1.08 | 419.22 | 98.97 | 93.53 | 86.22 | 98.91 | 89.59 | 92.67 | 90.00 | 92.84 |
| ConvFace NeXt_7K | 1.12 | 441.19 | 98.97 | 93.15 | 85.37 | 98.80 | 89.44 | 92.87 | 89.08 | 92.53 |
| ConvFace NeXt_9K | 1.17 | 470.50 | 98.77 | 92.67 | 84.40 | 98.63 | 88.80 | 91.73 | 89.16 | 92.02 |
| Model | IJB-B | IJB-C | ||||
|---|---|---|---|---|---|---|
| FAR | FAR | FAR | FAR | FAR | FAR | |
| = | = | = | = | = | = | |
| ConvFace NeXt_PE | 66.11 | 79.77 | 88.22 | 73.75 | 83.27 | 90.56 |
| ConvFace NeXt_5K | 58.95 | 79.46 | 88.66 | 70.71 | 82.89 | 90.58 |
| ConvFace NeXt_7K | 61.59 | 77.06 | 87.60 | 69.32 | 80.60 | 89.58 |
| ConvFace NeXt_9K | 5.52 | 48.42 | 81.92 | 11.27 | 53.30 | 83.35 |
| Model | Param. (M) | FLOPs (M) | LFW | CALFW | CPLFW | CFP-FF | CFF-FP | AgeDB-30 | VGG2-FP | Average |
|---|---|---|---|---|---|---|---|---|---|---|
| ConvFace NeXt_1B1P | 1.04 | 404.57 | 98.98 | 93.05 | 85.40 | 98.73 | 88.23 | 92.23 | 88.66 | 92.18 |
| ConvFace NeXt_PE | 1.05 | 404.57 | 99.10 | 93.32 | 85.45 | 98.87 | 87.40 | 92.95 | 88.92 | 92.29 |
| ConvFace NeXt_3B2P | 1.07 | 405.48 | 99.10 | 93.08 | 85.43 | 98.87 | 88.81 | 92.98 | 89.46 | 92.53 |
| Model | IJB-B | IJB-C | ||||
|---|---|---|---|---|---|---|
| FAR | FAR | FAR | FAR | FAR | FAR | |
| = | = | = | = | = | = | |
| ConvFace NeXt_1B1P | 66.36 | 79.06 | 88.05 | 72.57 | 82.78 | 90.32 |
| ConvFace NeXt_PE | 66.11 | 79.77 | 88.22 | 73.75 | 83.27 | 90.56 |
| ConvFace NeXt_3B2P | 58.28 | 79.16 | 88.62 | 70.09 | 82.65 | 90.45 |
| Model | Param. | FLOPs | Model | LFW | CA | CP | CFP | CFF | AgeDB | VGG2 | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|
| (M) | (M) | Size (MB) | LFW | LFW | -FF | -FP | -30 | -FP | |||
| MobileFace Net | 1.03 | 473.15 | 4.50 | 99.03 | 93.18 | 85.52 | 98.91 | 87.51 | 93.35 | 88.40 | 92.27 |
| ShuffleFace Net | 1.46 | 278.47 | 6.59 | 98.87 | 93.13 | 84.47 | 98.84 | 86.44 | 92.33 | 87.08 | 91.59 |
| ShuffleFace Net | 2.70 | 581.35 | 11.45 | 99.03 | 93.23 | 85.28 | 99.03 | 87.97 | 92.18 | 88.20 | 92.13 |
| MobileFace NetV1 | 3.43 | 1145.89 | 13.70 | 99.02 | 93.50 | 85.38 | 98.96 | 87.64 | 92.95 | 88.14 | 92.23 |
| Proxyless Face NAS | 3.01 | 873.95 | 12.40 | 98.82 | 92.63 | 84.32 | 98.76 | 86.13 | 92.23 | 87.66 | 91.51 |
| ConvFace NeXt_PS | 0.96 | 390.13 | 4.11 | 99.30 | 93.35 | 85.63 | 98.96 | 88.14 | 92.88 | 89.38 | 92.52 |
| ConvFace NeXt_PE | 1.05 | 404.57 | 4.49 | 99.10 | 93.32 | 85.45 | 98.87 | 87.40 | 92.95 | 88.92 | 92.29 |
| ConvFace NeXt_TS | 0.96 | 396.15 | 4.12 | 99.17 | 93.35 | 85.23 | 98.94 | 88.71 | 93.03 | 88.82 | 92.46 |
| ConvFace NeXt_TE | 1.05 | 410.59 | 4.49 | 99.05 | 93.42 | 85.58 | 99.07 | 88.21 | 93.15 | 89.36 | 92.55 |
| Model | IJB-B | IJB-C | ||||
|---|---|---|---|---|---|---|
| FAR | FAR | FAR | FAR | FAR | FAR | |
| = | = | = | = | = | = | |
| MobileFace Net | 38.53 | 73.92 | 87.74 | 55.10 | 78.17 | 89.79 |
| ShuffleFace Net 1× | 64.41 | 77.96 | 87.92 | 71.49 | 81.62 | 90.00 |
| ShuffleFace Net 1.5× | 63.54 | 78.17 | 87.69 | 70.06 | 81.36 | 89.88 |
| MobileFace NetV1 | 66.15 | 79.25 | 88.41 | 72.24 | 82.66 | 90.55 |
| Proxyless Face NAS | 53.33 | 75.79 | 86.87 | 63.18 | 78.66 | 88.90 |
| ConvFace NeXt_PS | 65.49 | 80.04 | 88.56 | 73.72 | 83.36 | 90.82 |
| ConvFace NeXt_PE | 66.11 | 79.77 | 88.22 | 73.75 | 83.27 | 90.56 |
| ConvFace NeXt_TS | 67.45 | 80.93 | 88.75 | 75.11 | 84.21 | 91.01 |
| ConvFace NeXt_TE | 66.29 | 80.61 | 88.99 | 74.85 | 83.79 | 90.95 |
| Method | Training Dataset, Number of Face Images | Loss Function | Param. (M) | FLOPs (M) | LFW Accuracy |
|---|---|---|---|---|---|
| Human-Individual [32] | - | - | - | - | 97.27 |
| MobileFaceNet [11] | CASIA, 0.49 M | ArcFace | 0.99 | - | 99.28 |
| MobileFaceNet [11] | Cleaned MS-Celeb-1M, 3.8 M | ArcFace | 0.99 | - | 99.55 |
| ShuffleFaceNet [12] | MS1M-RetinaFace, 5.1 M | ArcFace | 1.4 | 275.8 | 99.45 |
| ShuffleFaceNet [12] | MS1M-RetinaFace, 5.1 M | ArcFace | 2.6 | 577.5 | 99.67 |
| MobileFaceNetV1 [13] | MS1M-RetinaFace, 5.1 M | CosFace | 3.4 | 1100 | 99.40 |
| ProxylessFaceNAS [13] | MS1M-RetinaFace, 5.1 M | CosFace | 3.2 | 900 | 99.20 |
| LCNN (DSE_LSE) [15] | MS1M-ArcFace, 5.8 M | ArcFace | 1.35 | - | 99.40 |
| LCNN (Distill_DSE_LSE [15] | MS1M-ArcFace, 5.8 M | ArcFace | 1.35 | - | 99.67 |
| MixFaceNet-S [16] | MS1M-ArcFace, 5.8 M | ArcFace | 3.07 | 451.7 | 99.60 |
| ShuffleMixFaceNet-S [16] | MS1M-ArcFace, 5.8 M | ArcFace | 3.07 | 451.7 | 99.58 |
| ELANet [18] | MS1M-RetinaFace, 5.1 M | ArcFace | 1.61 | 550 | 99.68 |
| PocketNetS-128 [19] | MS1M-ArcFace, 5.8 M | ArcFace | 0.92 | 558.11 | 99.58 |
| PocketNetM-128 [19] | MS1M-ArcFace, 5.8 M | ArcFace | 1.68 | 1099.02 | 99.65 |
| LFR [33] | CASIA, 0.49M | ArcFace | - | - | 98.52 |
| ConvFace NeXt_PS | UMD, 0.37 M | ArcFace | 0.96 | 390.13 | 99.30 |
| ConvFace NeXt_PE | UMD, 0.37 M | ArcFace | 1.05 | 404.57 | 99.10 |
| ConvFace NeXt_TS | UMD, 0.37 M | ArcFace | 0.96 | 396.15 | 99.17 |
| ConvFace NeXt_TE | UMD, 0.37 M | ArcFace | 1.05 | 410.59 | 99.05 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hoo, S.C.; Ibrahim, H.; Suandi, S.A. ConvFaceNeXt: Lightweight Networks for Face Recognition. Mathematics 2022, 10, 3592. https://doi.org/10.3390/math10193592
Hoo SC, Ibrahim H, Suandi SA. ConvFaceNeXt: Lightweight Networks for Face Recognition. Mathematics. 2022; 10(19):3592. https://doi.org/10.3390/math10193592
Chicago/Turabian StyleHoo, Seng Chun, Haidi Ibrahim, and Shahrel Azmin Suandi. 2022. "ConvFaceNeXt: Lightweight Networks for Face Recognition" Mathematics 10, no. 19: 3592. https://doi.org/10.3390/math10193592
APA StyleHoo, S. C., Ibrahim, H., & Suandi, S. A. (2022). ConvFaceNeXt: Lightweight Networks for Face Recognition. Mathematics, 10(19), 3592. https://doi.org/10.3390/math10193592