


Entropy-Randomized Clustering

Abstract
:1. Introduction
2. An Indicator of Data Matrices
3. Randomized Binary Clustering
4. Entropy-Optimal Distribution
5. Parametrical Problems (18)–(20)
5.1. Randomized Binary Clustering Algorithms
5.1.1. Algorithm with a Given Cluster Size s
- 1.
- Calculating the numerical characteristics of the data matrix
- 2.
- Forming the matrix ensemble
- (a)
- Forming the correspondence table
- (b)
- Constructing the matrices
- (c)
- Calculating the elements of the distance matrices in (15):
- (d)
- Calculating the indicator of the matrix :
- 3.
- Determining the Lagrange multipliers and for the finite-dimensional problem
- (a)
- Specifying the initial values for the Lagrange multipliers:
- (b)
- (c)
- Determining the optimal probability distribution:
- (d)
- Determining the most probable cluster :
- (e)
- Determining the cluster :
5.1.2. Algorithm with an Unknown Cluster Size
- 1.
- Applying step 1 of
- 2.
- Organizing a loop with respect to the cluster size
- (a)
- Applying step 2 of
- (b)
- Applying step 3 of
- (c)
- Putting into the memory.
- (d)
- Calculating the conditionally maximum value of the entropy:
- (e)
- Putting in the memory.
- (f)
- If , then returning to Step 2a.
- (g)
- Determining the maximum element of the array :
- (h)
- Extracting the probability distribution
- (i)
- Executing Steps 3d and 3e of :
6. Functional Problems (18)–(20)
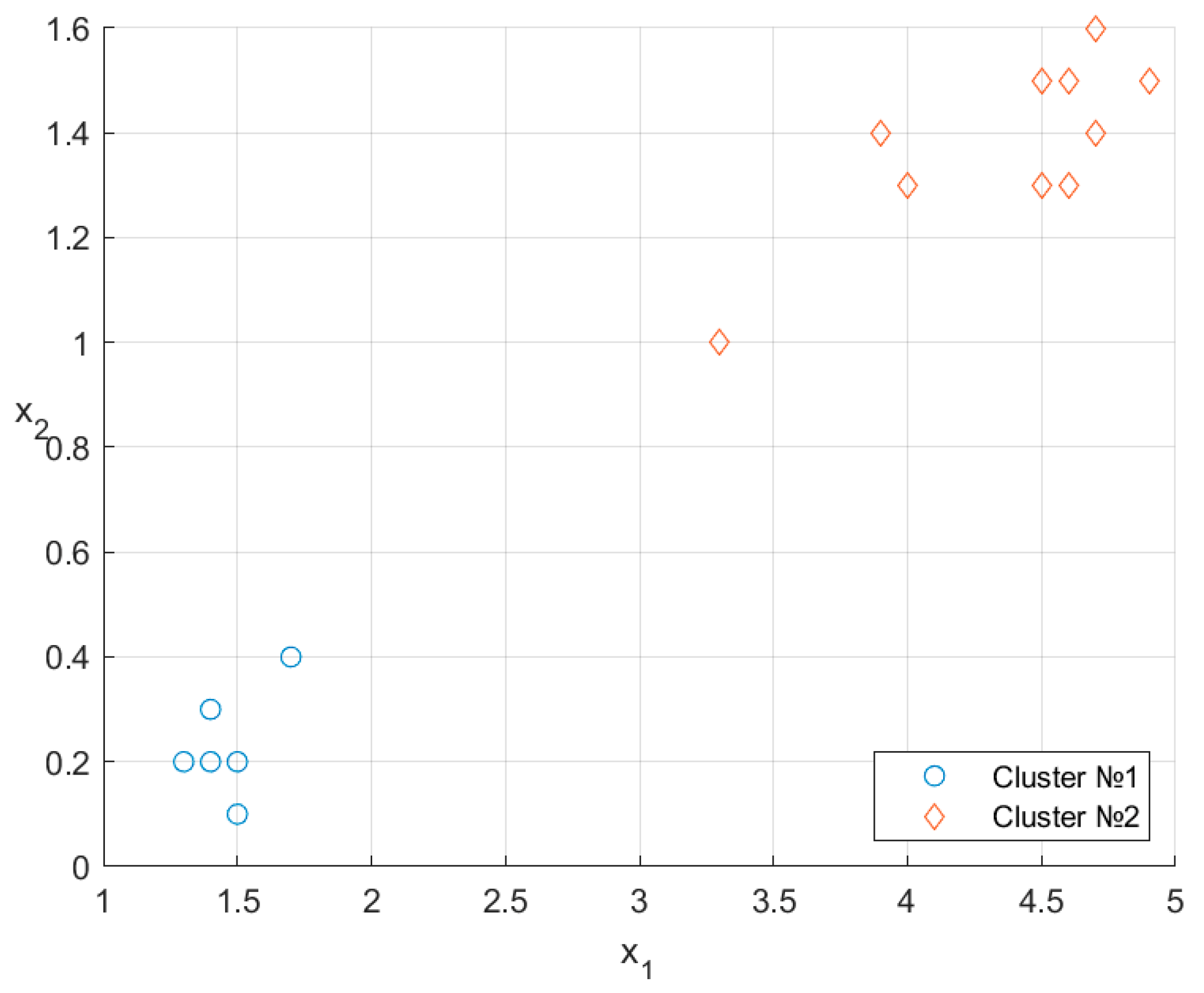
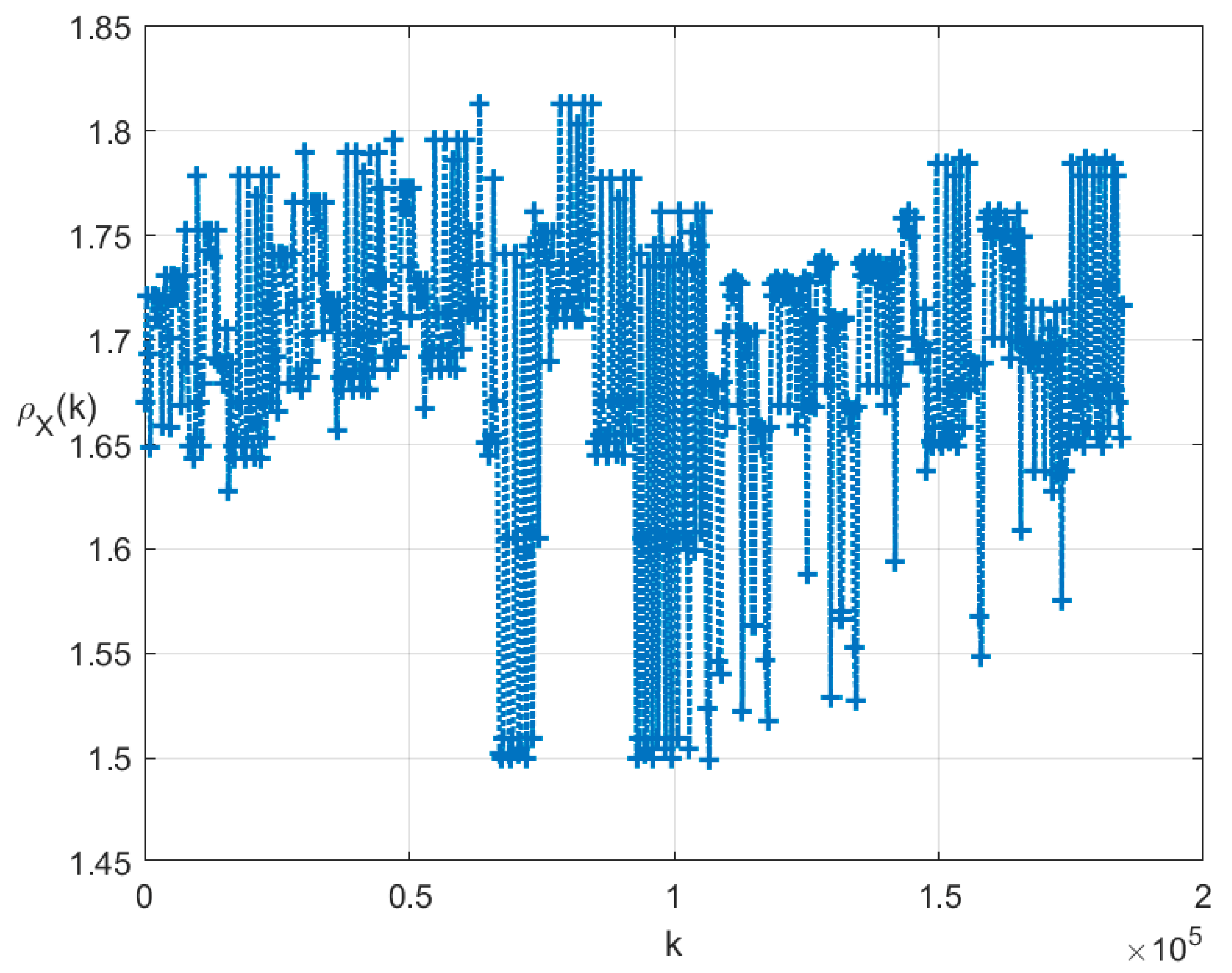
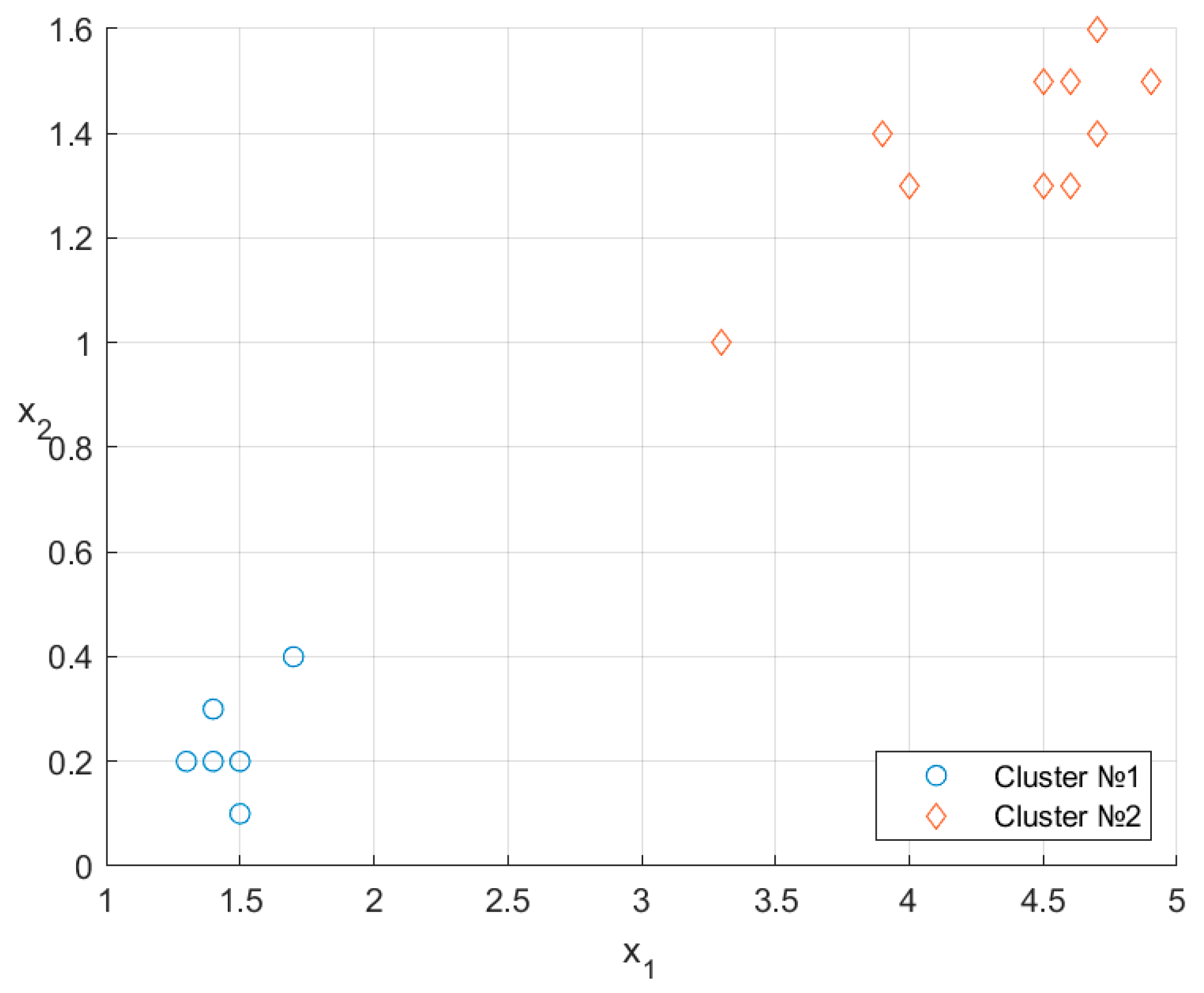
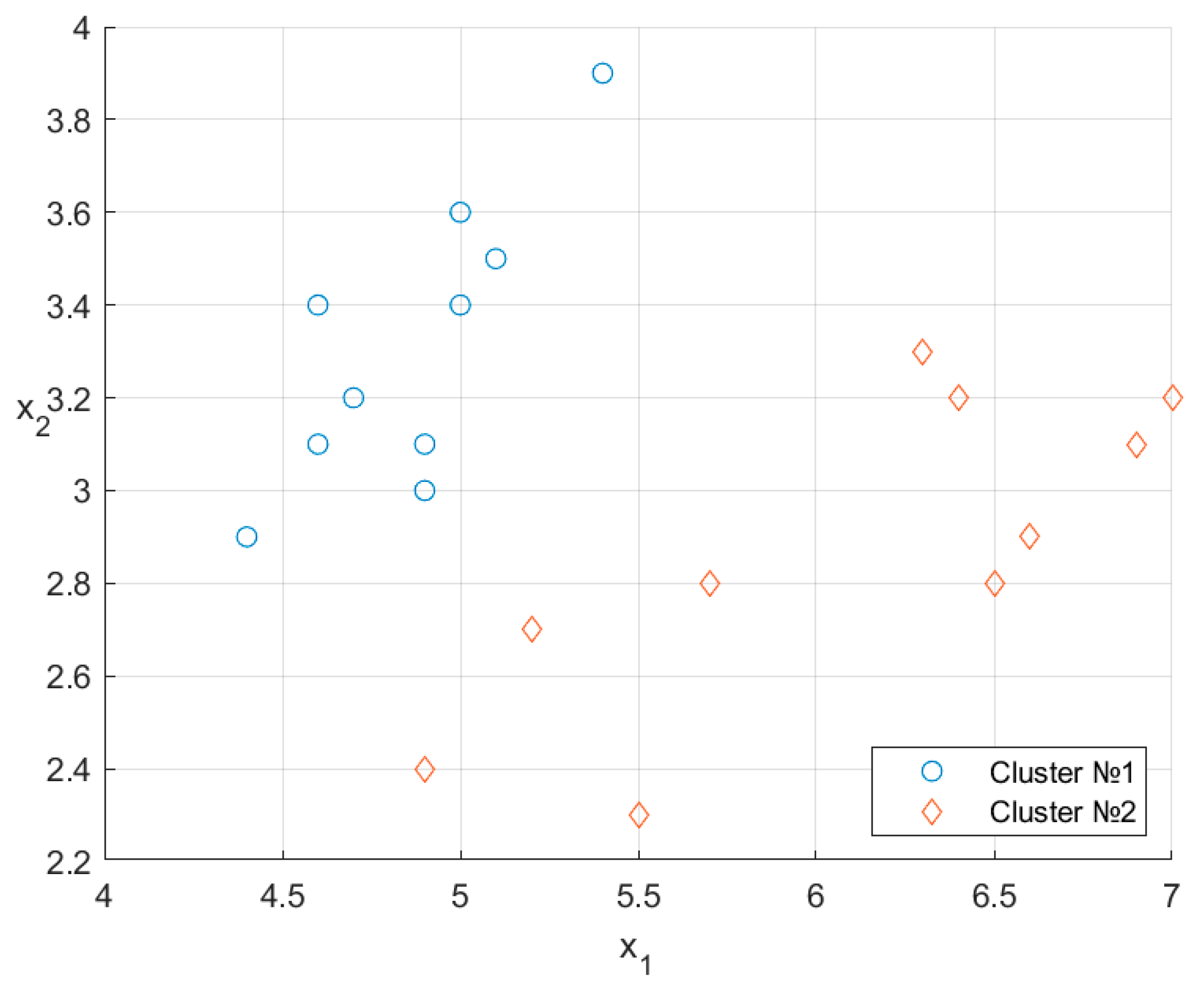
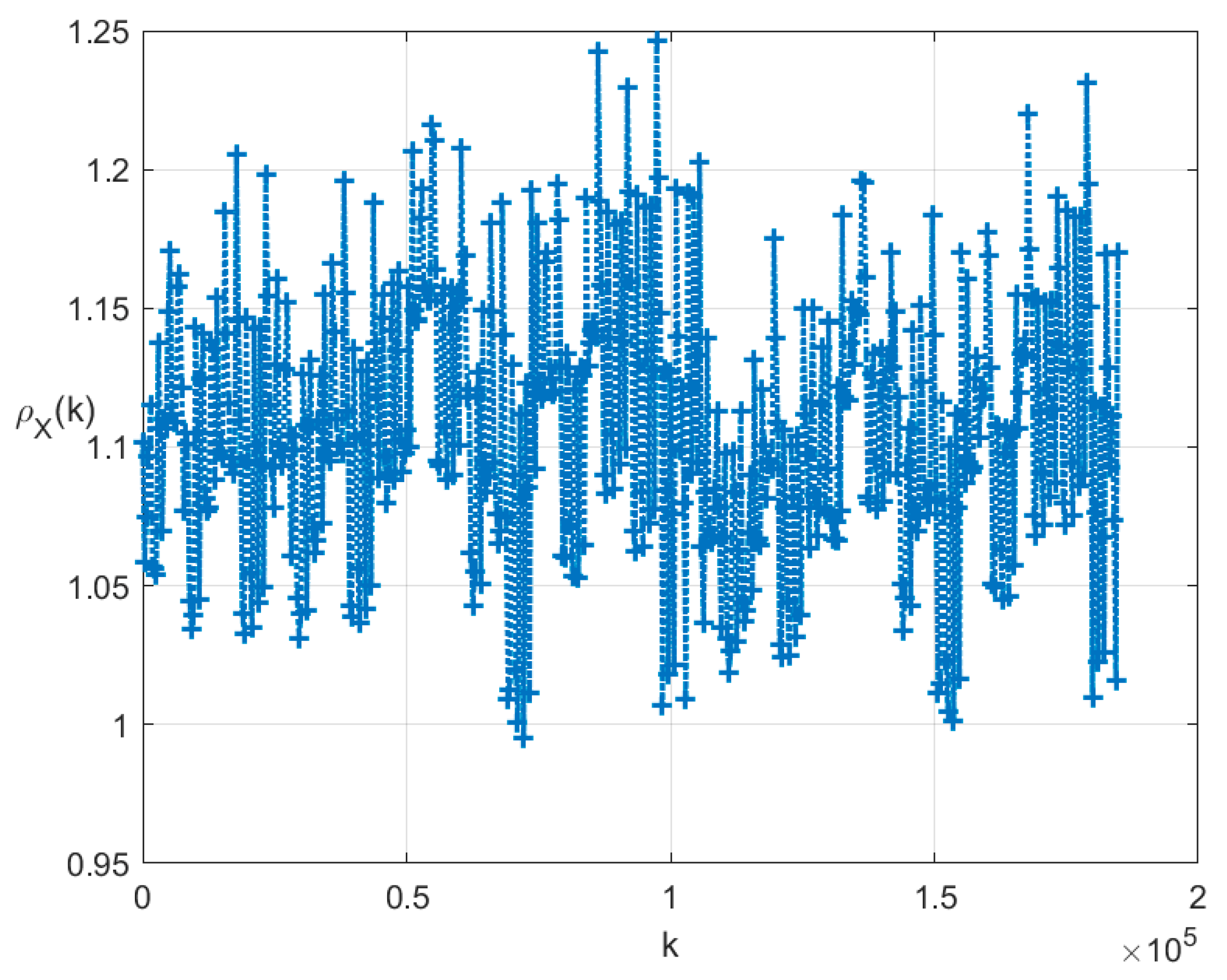
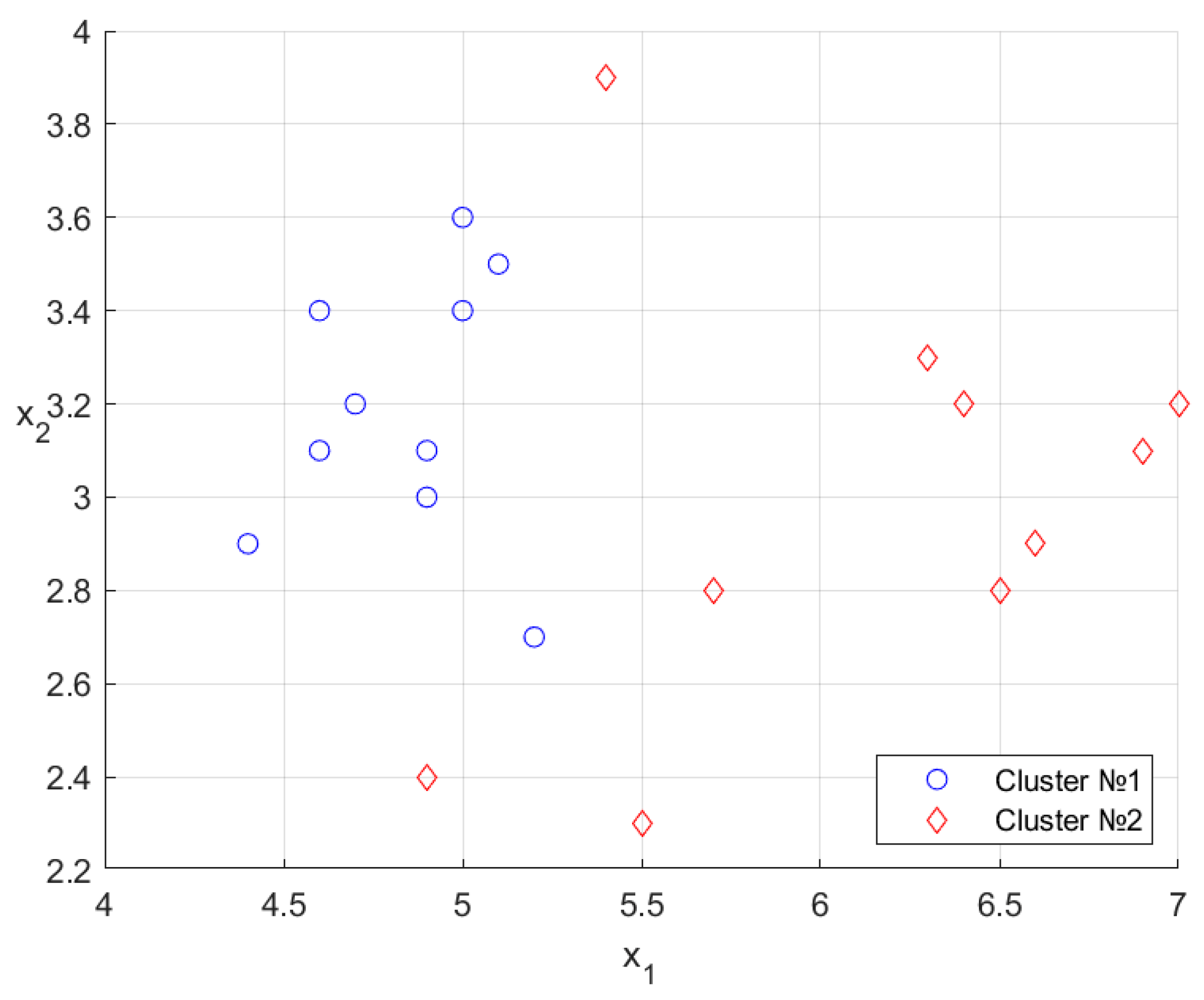
7. Illustrative Examples
8. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mandel, I.D. Klasternyi Analiz (Cluster Analysis); Finansy i Statistika: Moscow, Russia, 1988. [Google Scholar]
- Zagoruiko, N.G. Kognitivnyi Analiz Dannykh (Cognitive Data Analysis); GEO: Novosibirsk, Russia, 2012. [Google Scholar]
- Zagoruiko, N.G.; Barakhnin, V.B.; Borisova, I.A.; Tkachev, D.A. Clusterization of Text Documents from the Database of Publications Using FRiS-Tax Algorithm. Comput. Technol. 2013, 18, 62–74. [Google Scholar]
- Jain, A.; Murty, M.; Flynn, P. Data Clustering: A Review. ACM Comput. Surv. 1990, 31, 264–323. [Google Scholar] [CrossRef]
- Vorontsov, K.V. Lektsii po Algoritmam Klasterizatsii i Mnogomernomu Shkalirovaniyu (Lectures on Clustering Algorithms and Multidimensional Scaling); Moscow State University: Moscow, Russia, 2007. [Google Scholar]
- Lescovec, J.; Rajaraman, A.; Ullman, J. Mining of Massive Datasets; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Deerwester, S.; Dumias, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by Latent Semantic Analysis. J. Am. Soc. Inf. Sci. 1999, 41, 391–407. [Google Scholar] [CrossRef]
- Zamir, O.E. Clustering Web Documents: A Phrase-Based Method for Grouping Search Engine Results. Ph.D. Thesis, The Univeristy of Washington, Seattle, WA, USA, 1999. [Google Scholar]
- Cao, G.; Song, D.; Bruza, P. Suffix-Tree Clustering on Post-retrieval Documents Information; The Univeristy of Queensland: Brisbane, QLD, Australia, 2003. [Google Scholar]
- Huang, D.; Wang, C.D.; Lai, J.H.; Kwoh, C.K. Toward multidiversified ensemble clustering of high-dimensional data: From subspaces to metrics and beyond. IEEE Trans. Cybern. 2021. [Google Scholar] [CrossRef] [PubMed]
- Khan, I.; Luo, Z.; Shaikh, A.K.; Hedjam, R. Ensemble clustering using extended fuzzy k-means for cancer data analysis. Expert Syst. Appl. 2021, 172, 114622. [Google Scholar] [CrossRef]
- Jain, A.; Dubs, R. Clustering Methods and Algorithms; Prentice-Hall: Hoboken, NJ, USA, 1988. [Google Scholar]
- Pal, N.R.; Biswas, J. Cluster Validation Using Graph Theoretic Concept. Pattern Recognit. 1997, 30, 847–857. [Google Scholar] [CrossRef]
- Halkidi, M.; Batistakis, Y.; Vazirgiannis, M. On Clustering Validation Techniques. J. Intell. Inf. Syst. 2001, 17, 107–145. [Google Scholar] [CrossRef]
- Han, J.; Kamber, M.; Pei, J. Data Mining Concept and Techniques; Morgan Kaufmann Publishers: Burlington, MA, USA, 2012. [Google Scholar]
- Popkov, Y.S. Randomization and Entropy in Machine Learning and Data Processing. Dokl. Math. 2022, 105, 135–157. [Google Scholar] [CrossRef]
- Popkov, Y.S.; Dubnov, Y.A.; Popkov, A.Y. Introduction to the Theory of Randomized Machine Learning. In Learning Systems: From Theory to Practice; Sgurev, V., Piuri, V., Jotsov, V., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 199–220. [Google Scholar] [CrossRef]
- Popkov, Y.S. Macrosystems Theory and Its Applications (Lecture Notes in Control and Information Sciences Vol 203); Springer: Berlin, Germany, 1995. [Google Scholar]
- Popkov, Y.S. Multiplicative Methods for Entropy Programming Problems and their Applications. In Proceedings of the 2010 IEEE International Conference on Industrial Engineering and Engineering Management, Xiamen, China, 29–31 October 2010; pp. 1358–1362. [Google Scholar] [CrossRef]
- Polyak, B.T. Introduction to Optimization; Optimization Software: New York, NY, USA, 1987. [Google Scholar]
- Joffe, A.D.; Tihomirov, A.M. Teoriya Ekstremalnykh Zadach (Theory of Extreme Problems); Nauka: Moscow, Russia, 1974. [Google Scholar]
- Tihomirov, V.M.; Alekseev, V.N.; Fomin, S.V. Optimal Control; Nauka: Moscow, Russia, 1979. [Google Scholar]
- Popkov, Y.; Popkov, A. New methods of entropy-robust estimation for randomized models under limited data. Entropy 2014, 16, 675–698. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Type | ||
|---|---|---|---|
| 1 | 4.5 | 1.5 | 2 |
| 2 | 4.6 | 1.5 | 2 |
| 3 | 4.7 | 1.4 | 2 |
| 4 | 1.7 | 0.4 | 1 |
| 5 | 1.3 | 0.2 | 1 |
| 6 | 1.4 | 0.3 | 1 |
| 7 | 1.5 | 0.2 | 1 |
| 8 | 3.9 | 1.4 | 2 |
| 9 | 4.5 | 1.3 | 2 |
| 10 | 4.6 | 1.3 | 2 |
| 11 | 1.4 | 0.2 | 1 |
| 12 | 4.7 | 1.6 | 2 |
| 13 | 4.0 | 1.3 | 2 |
| 14 | 1.4 | 0.2 | 1 |
| 15 | 1.4 | 0.2 | 1 |
| 16 | 1.5 | 0.2 | 1 |
| 17 | 1.5 | 0.1 | 1 |
| 18 | 4.9 | 1.5 | 2 |
| 19 | 3.3 | 1.0 | 2 |
| 20 | 1.4 | 0.2 | 1 |
| No. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 0.1 | 0.22 | 3.01 | 3.45 | 3.32 | 3.27 | 3.36 | 3.36 | 3.36 |
| 2 | 0.1 | 0 | 0.14 | 3.1 | 3.55 | 3.42 | 3.36 | 3.45 | 3.45 | 3.45 |
| 3 | 0.22 | 0.14 | 0 | 3.16 | 3.61 | 3.48 | 3.42 | 3.51 | 3.51 | 3.51 |
| 4 | 3.01 | 3.1 | 3.16 | 0 | 0.45 | 0.32 | 0.28 | 0.36 | 0.36 | 0.36 |
| 5 | 3.45 | 3.55 | 3.61 | 0.45 | 0 | 0.14 | 0.2 | 0.1 | 0.1 | 0.1 |
| 6 | 3.32 | 3.42 | 3.48 | 0.32 | 0.14 | 0 | 0.14 | 0.1 | 0.1 | 0.1 |
| 7 | 3.27 | 3.36 | 3.42 | 0.28 | 0.2 | 0.14 | 0 | 0.1 | 0.1 | 0.1 |
| 8 | 3.36 | 3.45 | 3.51 | 0.36 | 0.1 | 0.1 | 0.1 | 0 | 0 | 0 |
| 9 | 3.36 | 3.45 | 3.51 | 0.36 | 0.1 | 0.1 | 0.1 | 0 | 0 | 0 |
| 10 | 3.36 | 3.45 | 3.51 | 0.36 | 0.1 | 0.1 | 0.1 | 0 | 0 | 0 |
| No. | Type | ||
|---|---|---|---|
| 1 | 6.4 | 3.2 | 2 |
| 2 | 6.5 | 2.8 | 2 |
| 3 | 7.0 | 3.2 | 2 |
| 4 | 5.4 | 3.9 | 1 |
| 5 | 4.7 | 3.2 | 1 |
| 6 | 4.6 | 3.4 | 1 |
| 7 | 4.6 | 3.1 | 1 |
| 8 | 5.2 | 2.7 | 2 |
| 9 | 5.7 | 2.8 | 2 |
| 10 | 6.6 | 2.9 | 2 |
| 11 | 5.1 | 3.5 | 1 |
| 12 | 6.3 | 3.3 | 2 |
| 13 | 5.5 | 2.3 | 2 |
| 14 | 4.4 | 2.9 | 1 |
| 15 | 4.9 | 3.0 | 1 |
| 16 | 5.0 | 3.4 | 1 |
| 17 | 4.9 | 3.1 | 1 |
| 18 | 6.9 | 3.1 | 2 |
| 19 | 4.9 | 2.4 | 2 |
| 20 | 5.0 | 3.6 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Popkov, Y.S.; Dubnov, Y.A.; Popkov, A.Y. Entropy-Randomized Clustering. Mathematics 2022, 10, 3710. https://doi.org/10.3390/math10193710
Popkov YS, Dubnov YA, Popkov AY. Entropy-Randomized Clustering. Mathematics. 2022; 10(19):3710. https://doi.org/10.3390/math10193710
Chicago/Turabian StylePopkov, Yuri S., Yuri A. Dubnov, and Alexey Yu. Popkov. 2022. "Entropy-Randomized Clustering" Mathematics 10, no. 19: 3710. https://doi.org/10.3390/math10193710
APA StylePopkov, Y. S., Dubnov, Y. A., & Popkov, A. Y. (2022). Entropy-Randomized Clustering. Mathematics, 10(19), 3710. https://doi.org/10.3390/math10193710