
Complex Color Space Segmentation to Classify Objects in Urban Environments
 , , and
, , and
Abstract
:1. Introduction
2. Related Works
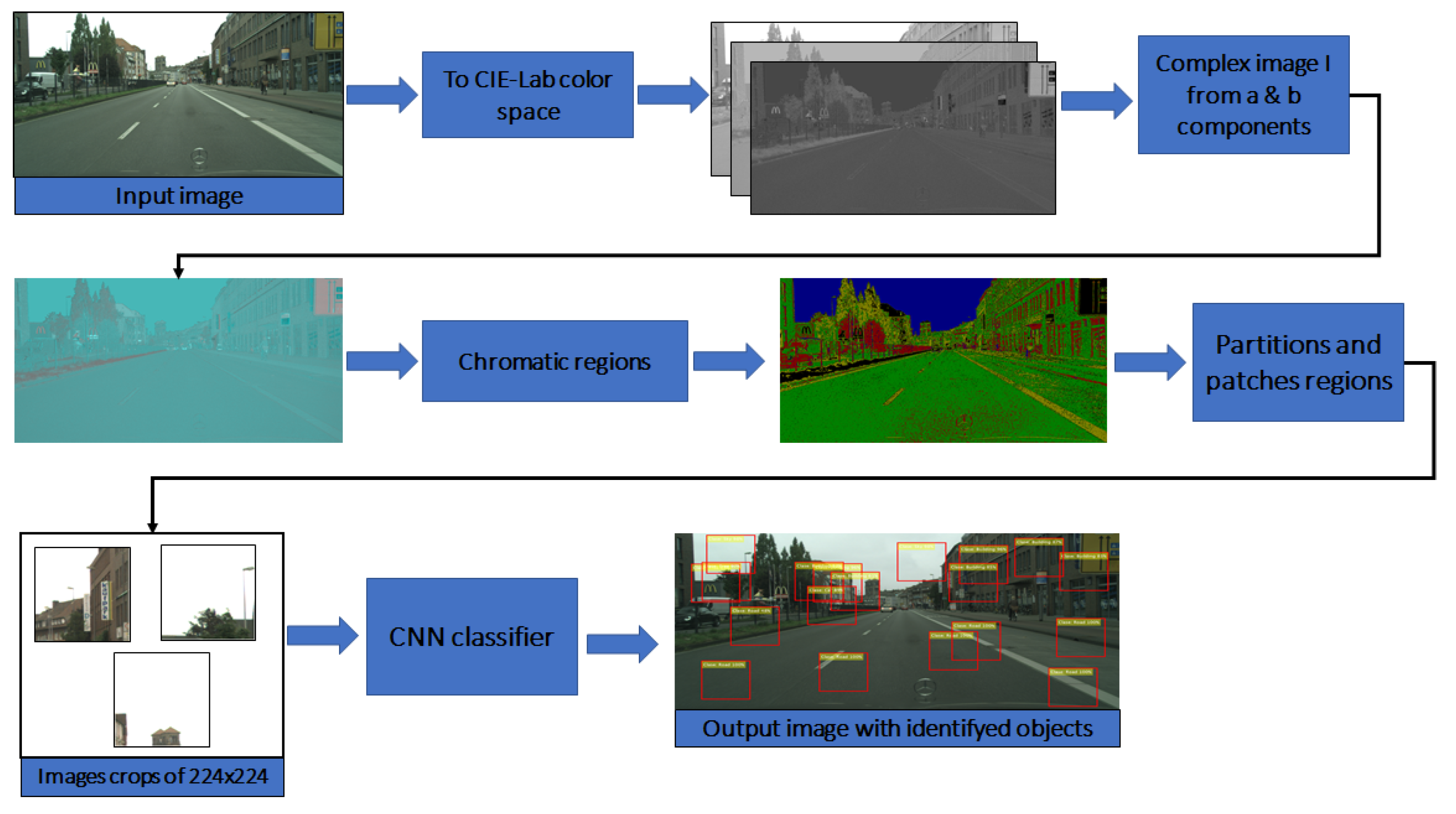
3. Image Segmentation Approach
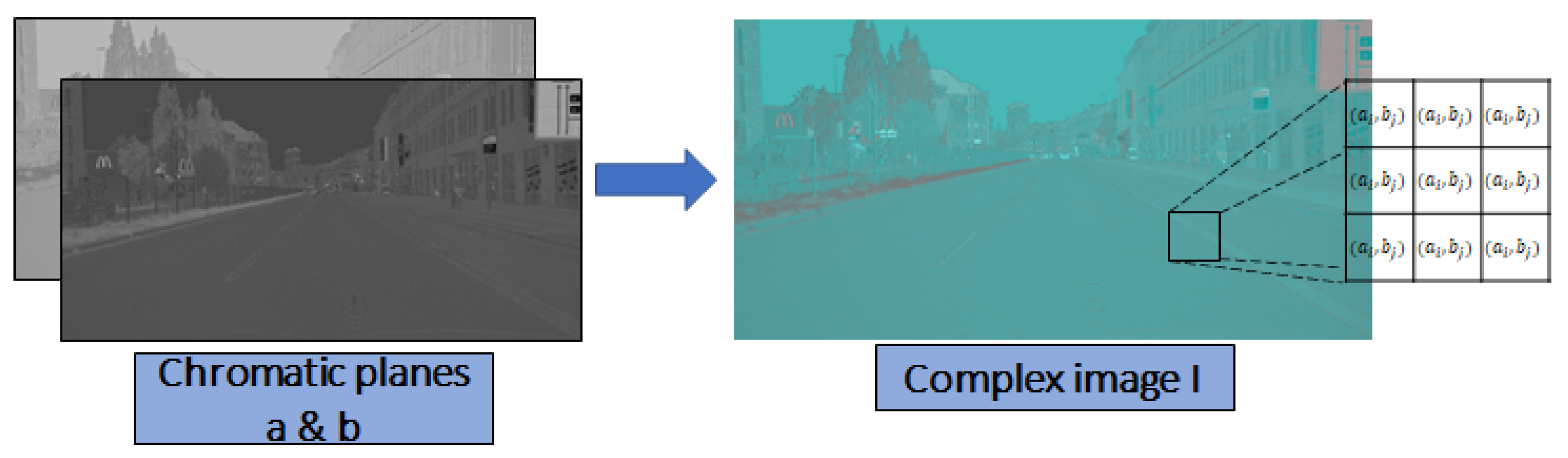
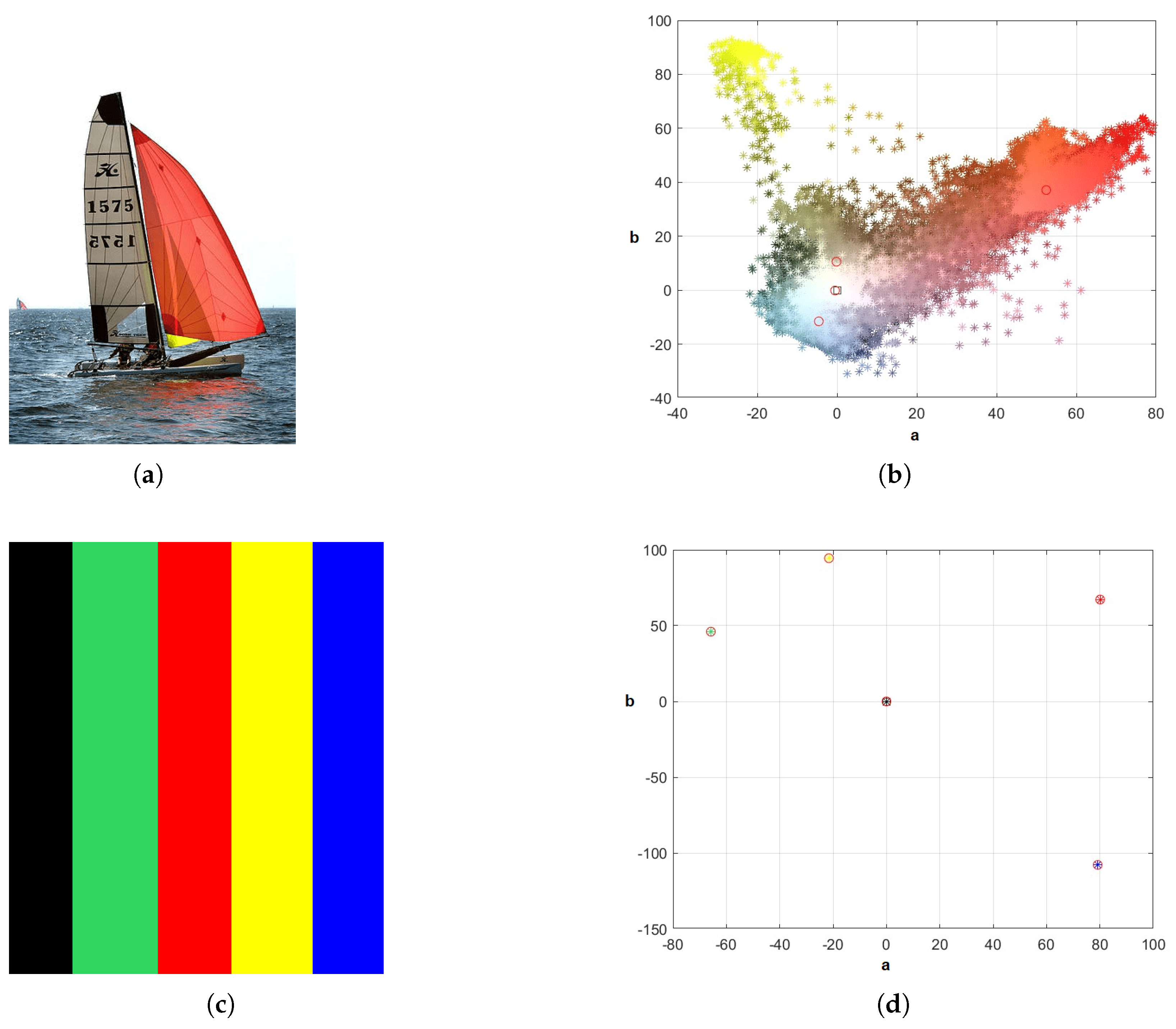
3.1. Image in the Complex Space
3.2. Chromatic Map
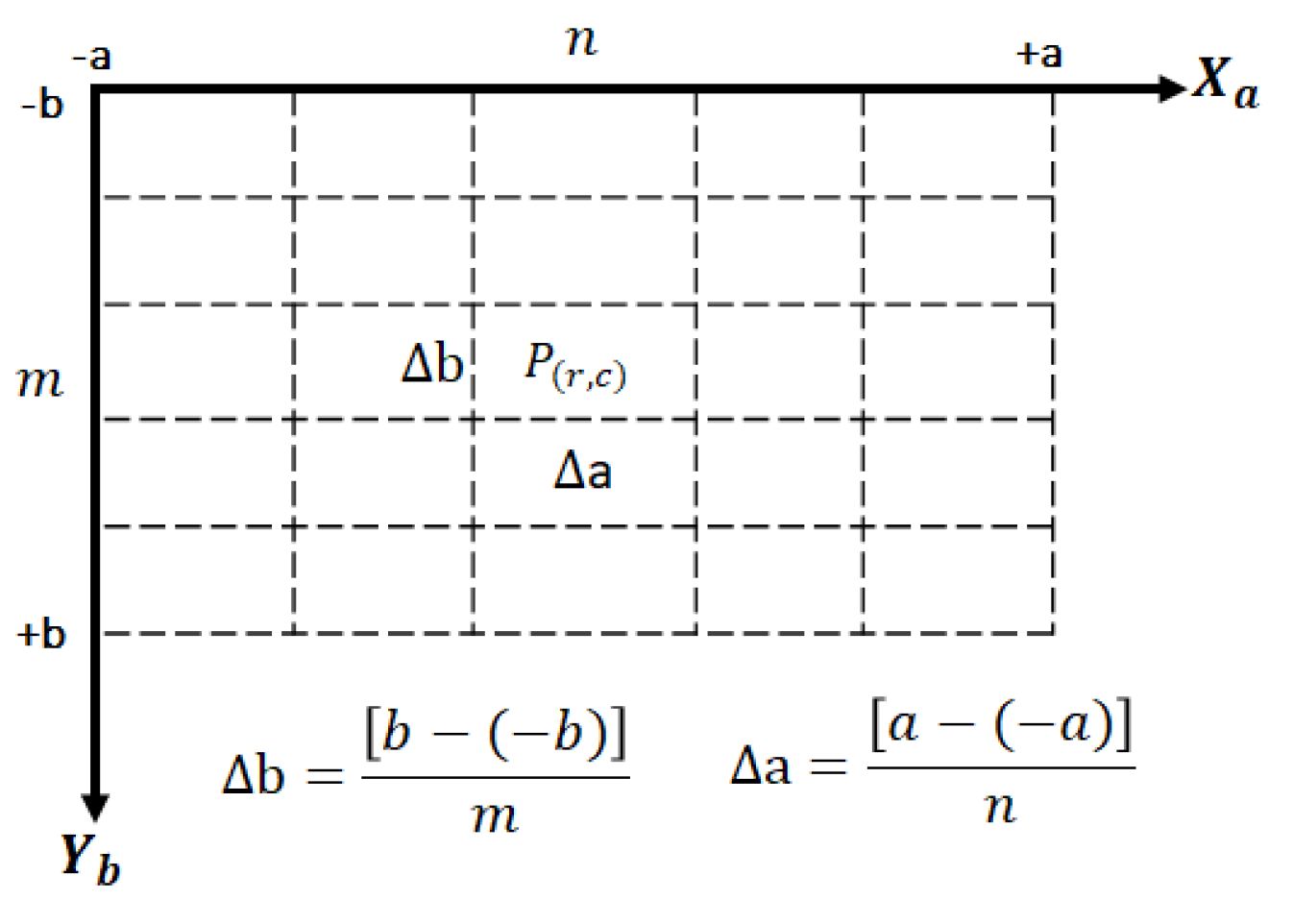
3.3. Segmentation Approach
| Algorithm 1 Segmentation method |
|
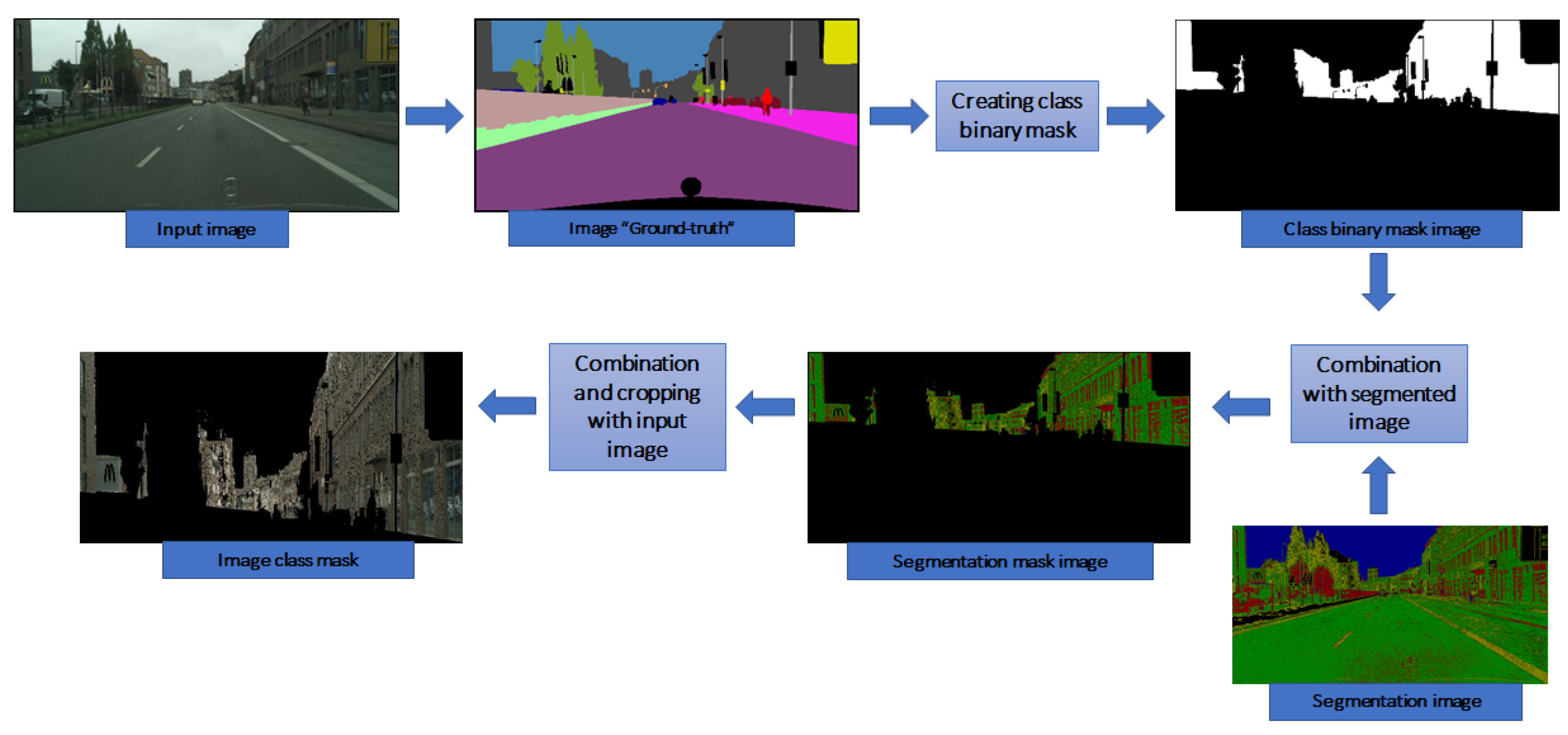
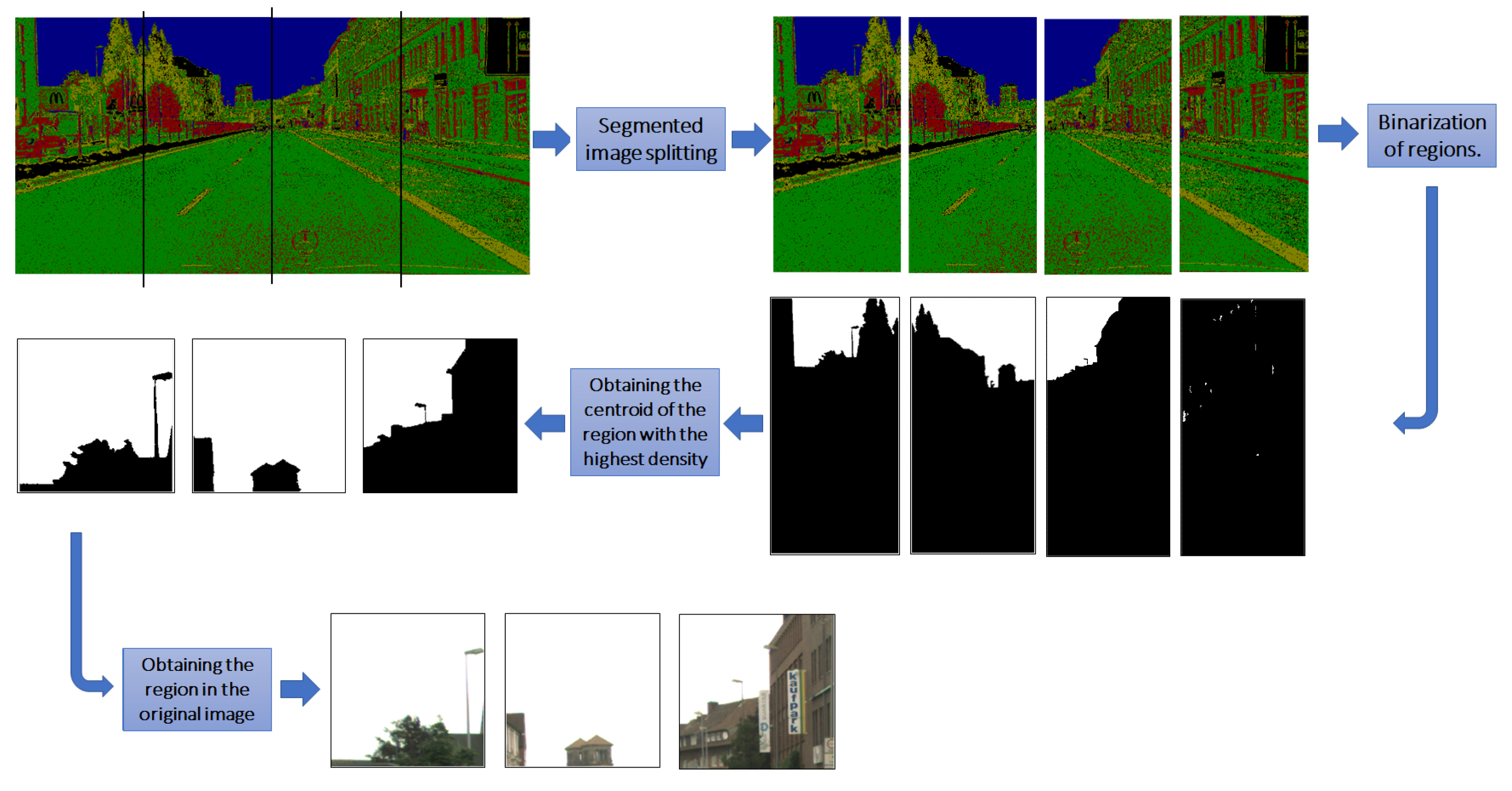
4. Results
4.1. Experimental Results
4.2. Segmentation Performance
- The percentage of pixel relationship by a class must be at least similar to ground-truth.
- Reject block sizes on where the number of void images is higher than 10%.
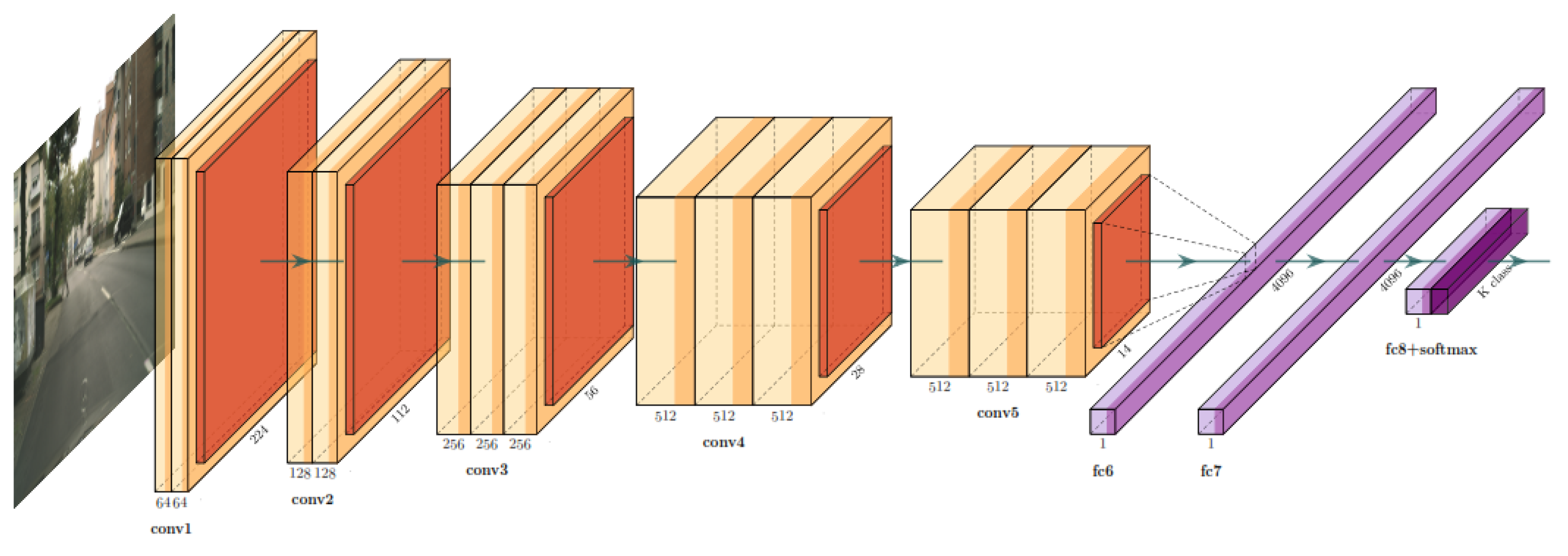
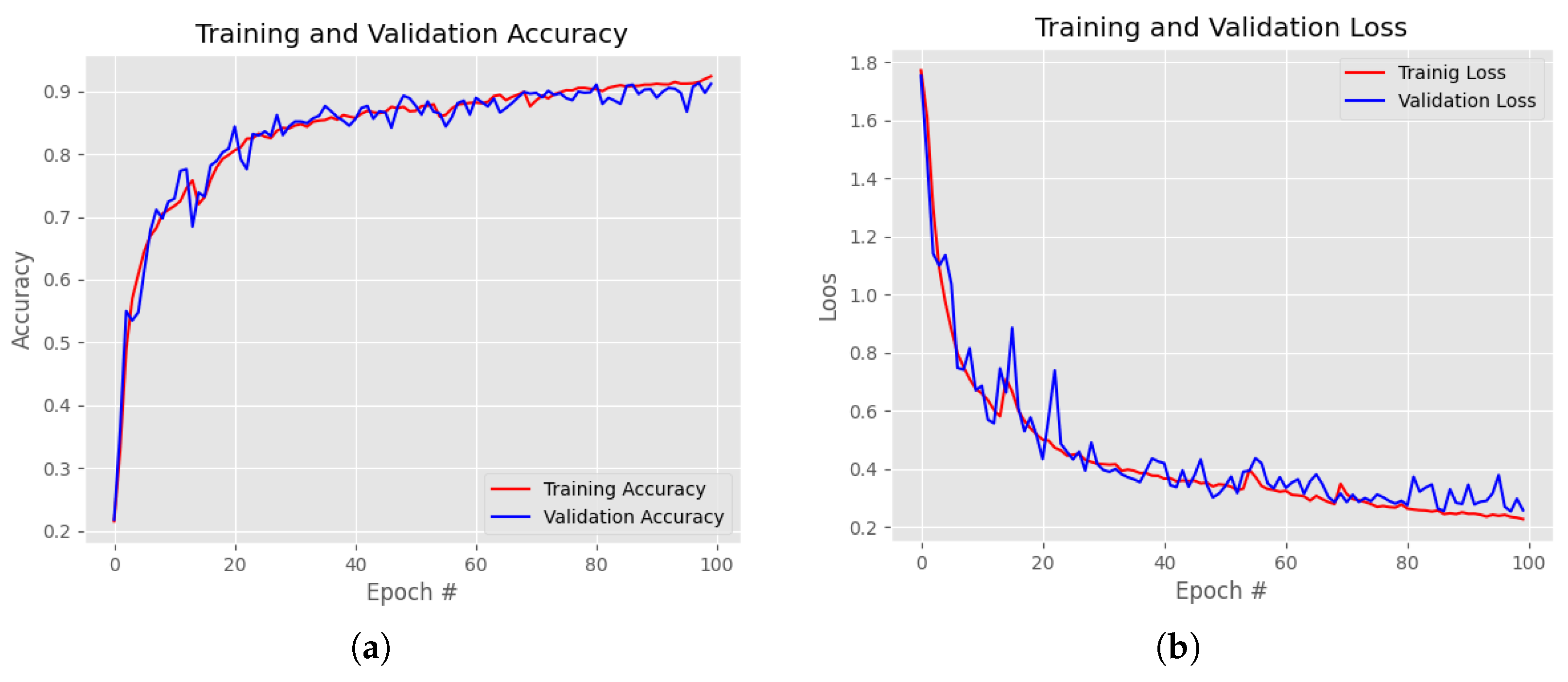
4.3. Cnn Architecture
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A Survey of Autonomous Driving: Common Practices and Emerging Technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Narkhede, P.R.; Gokhale, A.V. Color image segmentation using edge detection and seeded region growing approach for CIELab and HSV color spaces. In Proceedings of the 2015 International Conference on Industrial Instrumentation and Control (ICIC), Pune, India, 28–30 May 2015. [Google Scholar] [CrossRef]
- Xu, Y.; Shen, B.; Zhao, M.; Luo, S. An Adaptive Robot Soccer Image Segmentation Based on HSI Color Space and Histogram Analysis. J. Comput. 2019, 30, 290–303. [Google Scholar]
- Smith, A.R. Color gamut transform pairs. In Proceedings of the SIGGRAPH ’78, Atlanta, GA, USA, 23–25 August 1978. [Google Scholar]
- Cheng, H.D.; Jiang, X.H.; Sun, Y.; Wang, J. Color Image Segmentation: Advances and Prospects. Pattern Recognit. 2001, 34, 2259–2281. [Google Scholar] [CrossRef]
- Bansal, S.; Aggarwal, D. Color image segmentation using CIELab color space using ant colony optimization. Int. J. Comput. Appl. Citeseer 2011, 29, 28–34. [Google Scholar] [CrossRef]
- Spiegel, M.R.; Seymour Lipschutz, J.J.S.; Spellman, D. Complex Variables: With an Introduction to Conformal Mapping and Its Applications, 2nd ed.; Schaum’s Outlines Series; McGraw-Hill: New York, NY, USA, 2009. [Google Scholar]
- Fujiyoshi, H.; Hirakawa, T.; Yamashita, T. Deep learning-based image recognition for autonomous driving. IATSS Res. 2019, 43, 244–252. [Google Scholar] [CrossRef]
- Xu, H.; Gao, Y.; Yu, F.; Darrell, T. End-To-End Learning of Driving Models From Large-Scale Video Datasets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Dal Mutto, C.; Zanuttigh, P.; Cortelazzo, G.M. Fusion of geometry and color information for scene segmentation. IEEE J. Sel. Top. Signal Process. 2012, 6, 505–521. [Google Scholar] [CrossRef]
- Pagnutti, G.; Zanuttigh, P. Joint segmentation of color and depth data based on splitting and merging driven by surface fitting. Image Vis. Comput. 2018, 70, 21–31. [Google Scholar] [CrossRef] [Green Version]
- Karimpouli, S.; Tahmasebi, P. Segmentation of digital rock images using deep convolutional autoencoder networks. Comput. Geosci. 2019, 126, 142–150. [Google Scholar] [CrossRef]
- Rochan, M.; Rahman, S.; Bruce, N.D.; Wang, Y. Weakly supervised object localization and segmentation in videos. Image Vis. Comput. 2016, 56, 1–12. [Google Scholar] [CrossRef]
- Zhou, D.; Frémont, V.; Quost, B.; Dai, Y.; Li, H. Moving object detection and segmentation in urban environments from a moving platform. Image Vis. Comput. 2017, 68, 76–87. [Google Scholar] [CrossRef]
- Xie, J.; Kiefel, M.; Sun, M.T.; Geiger, A. Semantic Instance Annotation of Street Scenes by 3D to 2D Label Transfer. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Kaushik, R.; Kumar, S. Image Segmentation Using Convolutional Neural Network. Int. J. Sci. Technol. Res. 2019, 8, 667–675. [Google Scholar]
- Ye, X.Y.; Hong, D.S.; Chen, H.H.; Hsiao, P.Y.; Fu, L.C. A two-stage real-time YOLOv2-based road marking detector with lightweight spatial transformation-invariant classification. Image Vis. Comput. 2020, 102, 103978. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning Deconvolution Network for Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rehman, S.; Ajmal, H.; Farooq, U.; Ain, Q.U.; Riaz, F.; Hassan, A. Convolutional neural network based image segmentation: A review. In Proceedings of the Pattern Recognition and Tracking XXIX, Orlando, FL, USA, 15–19 April 2018. [Google Scholar] [CrossRef]
- Li, Q.; Shen, L.; Guo, S.; Lai, Z. Wavelet integrated CNNs for noise-robust image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7245–7254. [Google Scholar]
- Yuan, L.; Hou, Q.; Jiang, Z.; Feng, J.; Yan, S. Volo: Vision outlooker for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.H.; Liu, Y.; Zhan, X.; Cheng, M.M. P2T: Pyramid pooling transformer for scene understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Churchill, R.V.; Brown, J.W. Variable Compleja y Aplicaciones, 5th ed.; McGraw-Hill-Interamericana: Madrid, Spain, 1996. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Brostow, G.J.; Fauqueur, J.; Cipolla, R. Semantic object classes in video: A high-definition ground truth database. Pattern Recognit. Lett. 2009, 30, 88–97. [Google Scholar] [CrossRef]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in Perception for Autonomous Driving: Waymo Open Dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2446–2454. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A multimodal dataset for autonomous driving. In Proceedings of the CVPR, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. JMLR. Org 2014, 15, 1929–1958. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| -Axis Blocks | Cityscape Image | CamVid Image | ||||||
|---|---|---|---|---|---|---|---|---|
| -Axis Blocks | -Axis Blocks | |||||||
| 4 | 8 | 16 | 32 | 4 | 8 | 16 | 32 | |
| 4 | 3 | 4 | 7 | 11 | 2 | 4 | 6 | 9 |
| 8 | 4 | 4 | 7 | 11 | 4 | 4 | 5 | 9 |
| 16 | 6 | 6 | 7 | 13 | 6 | 6 | 6 | 10 |
| 32 | 12 | 11 | 12 | 12 | 11 | 11 | 10 | 13 |
| Class | -Axis Blocks | -Axis Blocks | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Pixel Ratio | Void Images | Pixel Ratio | Void Images | Pixel Ratio | Void Images | Pixel Ratio | Void Images | ||
| Building | 4 | 464 | 227 | 28 | 14 | ||||
| 8 | 212 | 162 | 20 | 14 | |||||
| 16 | 15 | 16 | 14 | 14 | |||||
| 32 | 14 | 14 | 14 | 14 | |||||
| Pedestrian | 4 | 486 | 267 | 75 | 61 | ||||
| 8 | 249 | 202 | 68 | 61 | |||||
| 16 | 62 | 63 | 61 | 61 | |||||
| 32 | 62 | 61 | 61 | 61 | |||||
| Road | 4 | 457 | 214 | 14 | 0 | ||||
| 8 | 202 | 150 | 7 | 0 | |||||
| 16 | 1 | 2 | 0 | 0 | |||||
| 32 | 0 | 0 | 0 | 0 | |||||
| Class | -Axis Blocks | -Axis Blocks | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Pixel Ratio | Void Images | Pixel Ratio | Void Images | Pixel Ratio | Void Images | Pixel Ratio | Void Images | ||
| Building | 4 | 130 | 73 | 4 | 4 | ||||
| 8 | 45 | 47 | 4 | 4 | |||||
| 16 | 4 | 4 | 4 | 4 | |||||
| 32 | 4 | 4 | 4 | 4 | |||||
| Pedestrian | 4 | 139 | 94 | 38 | 38 | ||||
| 8 | 71 | 73 | 38 | 38 | |||||
| 16 | 38 | 38 | 38 | 38 | |||||
| 32 | 38 | 38 | 38 | 38 | |||||
| Road | 4 | 128 | 71 | 2 | 2 | ||||
| 8 | 43 | 45 | 2 | 2 | |||||
| 16 | 2 | 2 | 2 | 2 | |||||
| 32 | 2 | 2 | 2 | 2 | |||||
| Architecture | Image Size (in Pixels) | ||
|---|---|---|---|
| SmallVGG | |||
| VGG16-Modified | |||
| ResNet150 | |||
| Dataset | Execution Time (in Seconds) | |
|---|---|---|
| Per Image | Total No. of Images Per Dataset | |
| CamVid | ||
| Cityscape | ||
| Dataset | Number of Patches Generated | Execution Time (in Seconds) | |
|---|---|---|---|
| Per Image | Total No. of Images on Dataset | ||
| CamVid | 11,660 | ||
| Cityscape | 2883 | ||
| Work | Methodology | Dataset | Accuracy |
|---|---|---|---|
| YOLOv3 [35] YOLOv4 [36] | An integrated CNN’s used for feature extraction and object classification in real-time. | ImageNet | 93.8% 94.8% Top-5 accuracy rate |
| VOLO [25] | A new architecture that implements a novel outlook attention operation that dynamically conducts the local feature aggregation mechanism in a sliding window manner across the input image. | ImageNet | 87.1% Top-1 accuracy rate |
| SPPNet [37] | Strategy of spatial pyramid pooling to construct a network structure called SPP-net for image classification. | Caltech101 | 93.42% |
| Our approach | Selection of region chromatic based on complex numbers with CNN to object detection. | Cityscapes and Camvid | 94% for 6 classes |
| Classification Learner | Patches Sizes (in Pixels) | ||
|---|---|---|---|
| Quadratic SVM | 78.10% | 78.30% | 78.90% |
| Cubic SVM | 78.50% | 79.10% | 80.10% |
| Fine Gaussian SVM | 67.30% | 70.20% | 74.10% |
| Medium Gaussian SVM | 77.80% | 77.80% | 77.40% |
| Bagged Trees | 79.20% | 79.40% | 79.80% |
| Narrow Neural Network | 72.90% | 74.20% | 76.20% |
| Medium Neural Network | 74.60% | 76.60% | 78.70% |
| Bilayered Neural Network | 72.90% | 74.20% | 77.00% |
| Trilayered Neural Network | 73.70% | 74.60% | 76.10% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cardenas-Cornejo, J.-J.; Ibarra-Manzano, M.-A.; Razo-Medina, D.-A.; Almanza-Ojeda, D.-L. Complex Color Space Segmentation to Classify Objects in Urban Environments. Mathematics 2022, 10, 3752. https://doi.org/10.3390/math10203752
Cardenas-Cornejo J-J, Ibarra-Manzano M-A, Razo-Medina D-A, Almanza-Ojeda D-L. Complex Color Space Segmentation to Classify Objects in Urban Environments. Mathematics. 2022; 10(20):3752. https://doi.org/10.3390/math10203752
Chicago/Turabian StyleCardenas-Cornejo, Juan-Jose, Mario-Alberto Ibarra-Manzano, Daniel-Alberto Razo-Medina, and Dora-Luz Almanza-Ojeda. 2022. "Complex Color Space Segmentation to Classify Objects in Urban Environments" Mathematics 10, no. 20: 3752. https://doi.org/10.3390/math10203752
APA StyleCardenas-Cornejo, J. -J., Ibarra-Manzano, M. -A., Razo-Medina, D. -A., & Almanza-Ojeda, D. -L. (2022). Complex Color Space Segmentation to Classify Objects in Urban Environments. Mathematics, 10(20), 3752. https://doi.org/10.3390/math10203752