1. Introduction
The language of native speakers often contains wordings with varying degrees of semantic decomposition. The most overt are idioms, such as, e.g., it is a piece of cake meaning ‘easy’ or to be under the weather meaning ‘to feel ill’, but even more frequent and relevant to language proficiency of a speaker or machine are lexically restricted binary word co-occurrences, in which one of the two syntactically bound lexical items restricts the selection of the other item. Consider a statement in an CNN sports commentary from 9 July 2022:
Having taken an early lead, Rybakina almost gave up her advantage soon after, needing to fend off multiple break points before eventually taking a two-game lead in the set.
Already, this short statement contains three of such co-occurrences: take [a] lead, give up advantage, and fend off [a] break point, with lead, advantage, and break point restricting the selection of take, give up, and fend off respectively. While for an English native speaker, these co-occurrences may appear to involve no idiosyncrasy, one can clearly recognize it from the multilingual angle. Thus, in German, instead of the literal nehmen, one would use gehen ‘go’ to translate take in take [a] lead: in Führung gehen, lit. ‘to go into lead’. In Spanish, give up in co-occurrence with ventaja ‘advantage’ will be translated as ceder ‘cede’: ceder [una] ventaja, and in French fend off will be translated in the context of breakpoint as repousser ‘repell’: repousser [un] point de rupture. In contrast, in the context of walk, take would be translated into German as machen ‘make’: einen Spaziergang machen, lit. ‘make a walk’, in the context of rights, give up would be translated into Spanish as renunciar ‘renounce’: renunciar a sus derechos, lit.‘renounce to one’s rights’, and in the context of competition, fend off would be translated into French as contrer: contrer la concurrence. Note that at the same time lead, advantage, break point, walk, rights, and competition will always be translated literally.
Lexically resticted word co-occurrences are of extremely high relevance to second language learners [
1,
2,
3,
4,
5,
6] and many Natural Language Processing (NLP) applications, including, e.g., natural language generation [
7,
8], machine translation [
9], semantic role labeling [
10] and word sense disambiguation [
11]. Thus, language learners must memorize them by heart and master even fine-grained semantic differences between them (as Mel’čuk and Wanner [
12] show, while a certain semantic feature-based analogy (or, in other words, generalization) in the formation of such co-occurrences is possible, even for co-occurrences with emotion nouns, which are considered to be very homogeneous, major divergences prevail). For instance, a language learner should know the difference between
lodge [
a]
complaint and
voice [
a]
complaint or between
receive [
a]
compensation and
have [
a]
compensation. Automatic text generation appears more natural if it uses idiosyncratic word co-occurrences (compare, e.g.,
John walks every morning on the beach vs.
John takes a walk on the beach every morning); semantic role labeling needs to capture in
take a walk that John is not the recipient of the walk, but rather the actor, and machine translation from English to German needs to translate
take in co-occurrence with
walk as
machen ‘make’ and not as
nehmen ‘take’. Language models as commonly used in modern NLP partially capture such co-occurrences, but it has been shown that even if downstream applications use state-of-the-art language models, they benefit from additional information on restricted lexical co-occurrence; see, e.g., the experiments of Maru et al. on Word Sense Disambiguation [
11], in which they use explicit lists of semantically labeled lexical co-occurrences. Therefore, it is surprising that so far, the automatic acquisition and semantic labeling of lexically resticted co-occurrences has not been given close attention in mainstream research on distributional semantics. Most of the work focused on a mere identification of statistically significant lexical co-occurrences in text corpora; see, among others, [
7,
13,
14,
15]. This is insufficient. Firstly, not all statistically significant word co-occurrences are, in fact, lexically restricted, and, secondly, as illustrated above, in order to be of real use, their semantics must be also known.
In a series of experiments, Wanner et al. (see, for instance, [
16,
17,
18,
19]) work with precompiled lists of co-occurrences, which they classify with respect to the fine-grained semantic typology of
lexical functions (LFs) [
20]. In another work [
21], they go one step further by identifying instances from precompiled co-occurrence lists in text corpora and using then their sentential contexts as additional information for classification. Most recently, Espinosa-Anke et al. [
22] use in their graph transformer-based model, in addition to the sentential context, the syntactic dependencies between the elements of the co-occurrences and thus take into account lexicographic studies [
20] that identify syntactic dependency as one of the prominent characteristics of the individual semantic categories of the co-occurrences. However, another crucial feature of lexically restricted co-occurrences remained so far unconsidered in NLP: between its elements, not only a syntactic but also a semantic dependency holds (although Espinosa-Anke et al. explicitly point out the existence of a semantic dependency between the elements in lexically restricted word co-occurrences, they do not model it in explicit terms: the elements that form the co-occurrence are identified separately using the BIO-tagging strategy [
23]).
In view of the continuous significant advances shown by semantic relation extraction techniques (
http://nlpprogress.com/english/relationship_extraction.html, accessed on 15 July 2022), our goal is to explore whether the extension of a graph transformer-based model for the identification and classification of lexically restricted co-occurrences by a state-of-the-art semantic relation extraction network can contribute to an increase of the performance. Our exploration is motivated by the fact that (i) current approaches still struggle with correctly classifying some less frequent categories of lexically restricted word co-occurrences, and (ii) especially semantically similar categories are systematically confused, which is detrimental in particular for such applications as second language learning. Semantic relation techniques are a promising means to remedy this problem.
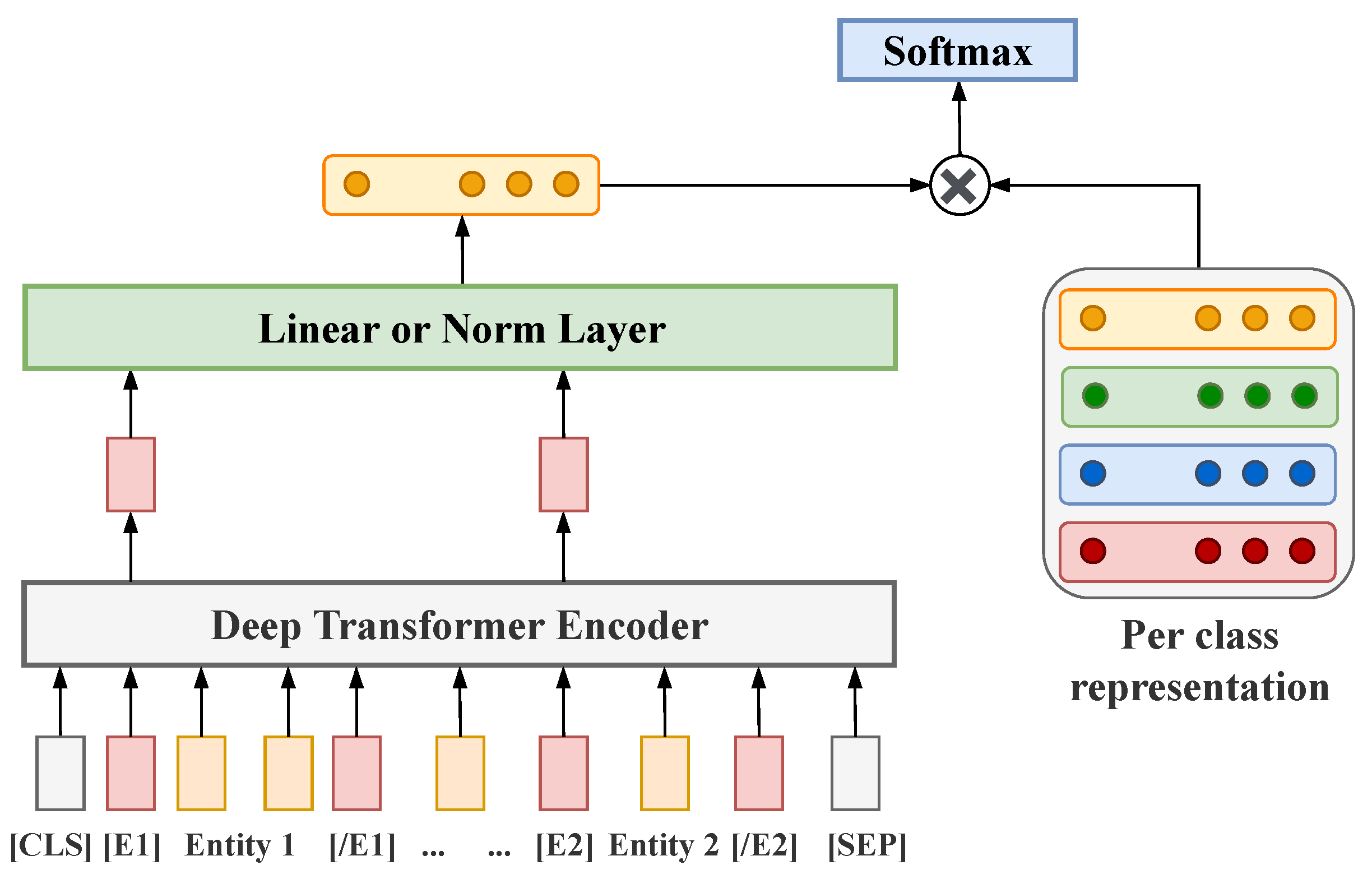
To this end, we design an LF relation–extraction model that is inspired by [
24] and carry out with this model two kinds of experiments. In the first experiment, we tackle a classical classification task to assess the stand-alone performance of the adapted model and thus its suitability to form part of an extended graph transformer-based model. Given a dataset with lexically restricted co-occurrences in their sentential contexts, we classify the co-occurrences with respect to the LF typology. In the second experiment, we use the output of the identification stage of the model of Espinosa-Anke et al. [
22] and feed it as input to an LF relation extraction network. Our experiments show that relation extraction indeed helps to increase the quality of lexically restricted word co-occurrence identification and classification. In particular, relation extraction ensures a better distinction between some of the categories of co-occurrences, which are notoriously confused by other state-of-the-art techniques. On the other hand, the quality increase is limited—which allows for some conclusions with respect to an implicit representation of semantic relation information by graph transformers.
The contributions of our work can thus be summarized as follows:
We adapt a generic relation extraction framework to the problem of lexically restricted word co-occurrence classification.
We show that neural relation extraction techniques that have not been used for the classification of lexically restricted word co-occurrences so far are a suitable means to account for the relational nature of such co-occurrences and can compete in their performance with, e.g., the most recent BIO tagging technique. This means that if the goal is to simultaneously identify and classify lexically restricted and semantic relations, relation extraction techniques can be successfully used.
We demonstrate that the neural relation extraction techniques distinguish better between notoriously confused categories of lexically restricted word co-occurrences than the state-of-the-art techniques. This can be of high relevance to applications that focus on these categories.
Our contrastive analysis of the BIO tagging technique, which receives as input syntactic dependency information only, and the proposed relation extraction technique suggests that the graph transformers used in the BIO tagging technique already capture the category-specific semantics of the lexically restricted word co-occurrences. This outcome contributes to the research on the types of knowledge captured by neural models.
The remainder of the article is structured as follows. The next section (
Section 2) contains some background on lexically restricted co-occurrences. In
Section 3, we provide an overview of the state of the art of the research on the identification and classification of such co-occurrences.
Section 4 introduces the Graph-Trased transformer model (Gr2C-Tr) of Espinosa-Anke et al. [
22] and its extension by a relation extraction network.
Section 5 describes the experiments that have been carried out and their results, which are discussed in
Section 6.
Section 7, finally, draws the conclusions from our experiments and outlines some lines of relevant future work.
2. Background on Lexically Restricted Word Co-Occurrences
In lexicology and lexicography, lexically restricted word co-occurrences have been studied under the heading of
collocations [
25,
26,
27,
28]. The item that restricts the selection of the other item is referred to as the
base and the restricted item is the
collocate. Note, however, that the original notion of collocation as introduced by J.R. Firth [
29] is broader: it merely implies
statistically significant word co-occurrence. In other words, any combination of words that appear together sufficiently often are considered to be collocations, among them, e.g.,
doctor–
hospital,
hospital–
pandemic, or
pandemic–
mask. As can be observed, in these examples, no lexical restriction is imposed by one of the lexical items on the other item, i.e., there is no base and no collocate. Most of the work on automatic word co-occurrence identification is based on this notion of collocation (see
Section 3 below). Obviously, this is not to say that both notions are disjoint. On the contrary, lexically restricted co-occurrences will often (although by far not always) be statistically significant; see, e.g.,
strong tea,
contagious disease, or
come [
to]
power.
In contrast to the mainstream research in NLP, we use the notion of collocation as introduced in lexicology/lexicography. As already mentioned above, this notion implies that between the base and the collocate of a concrete co-occurrence, a specific semantic relation, which is expressed by the collocate, and a specific syntactic dependency hold. Based on this relation and dependency, collocations can be typified. For instance, take a walk, give a lecture, make a proposal belong to the same type: take, give, and make express the same semantic relation with their respective base (namely ‘perform’ or ‘carry out’), and all of them take their respective base as a direct object. The same applies to thunderous applause, heavy storm, high temperature: here, thunderous, heavy, and high all express the relation ‘intense’.
The most fine-grained semantically-oriented typology of collocations available to date is the typology of lexical functions (LFs) [
20]. An LF is defined as a function
that delivers for a base
B a set of synonymous collocates that express the meaning of
f. LFs are assigned Latin abbreviations as labels; cf., e.g., “Oper1” (“operare” ‘perform’): Oper1(
walk) = {
take,
do,
have}; “Magn” (“magnum” ‘big’/‘intense’): Magn(
applause) = {
thunderous,
deafening,
loud, …}. But each LF can also be considered as a specific lexico-semantic relation between the base and the collocate of a collocation in question [
30].
Table 1 displays the subset of the relations we experiment with along with their corresponding LF names and illustrative examples.
5. Experiments
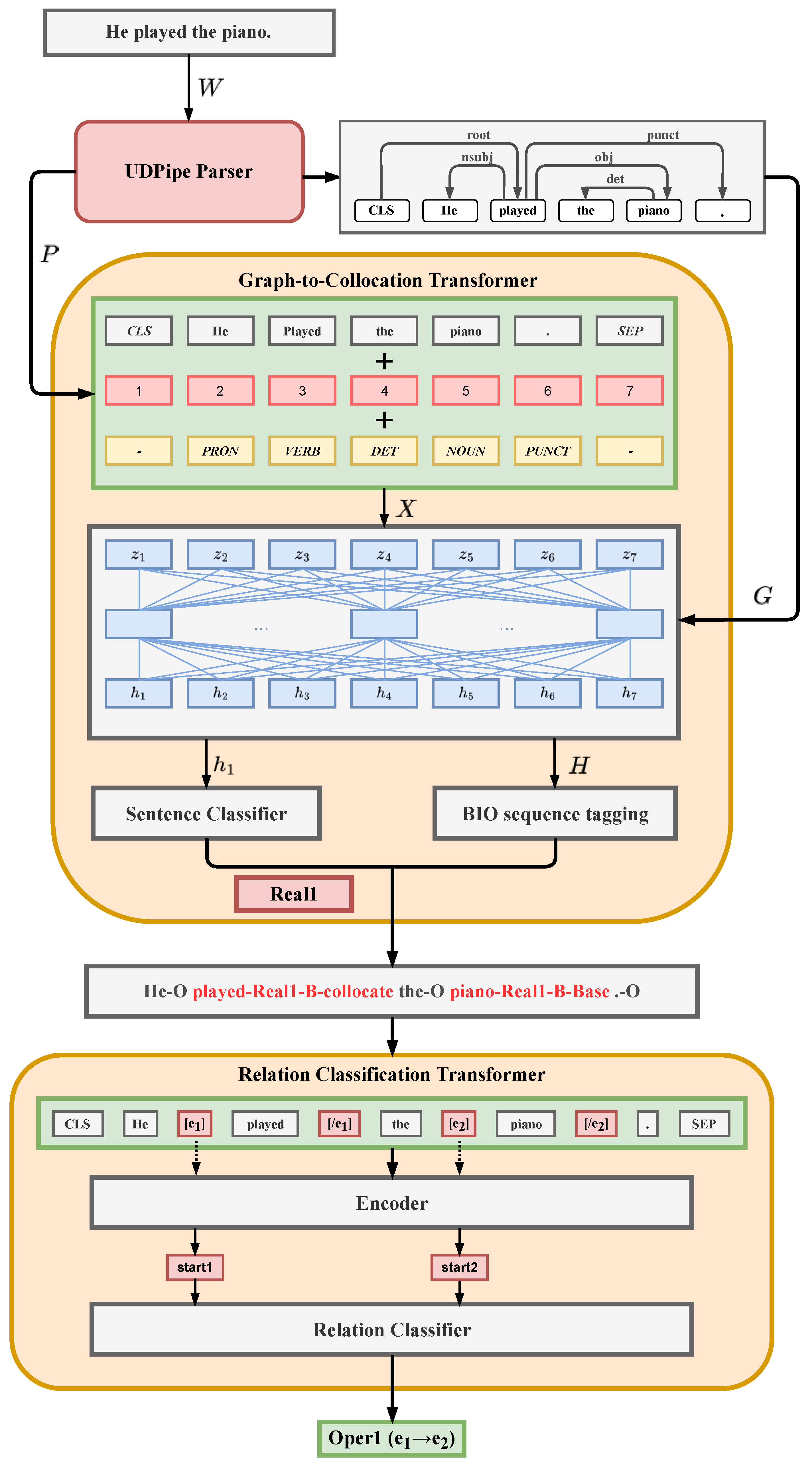
Extending the original G2C-Tr model by a dedicated relation-based collocation classification described above, we obtain a reinforced model architecture depicted in
Figure 1, with two transformers dedicated specifically to collocation extraction and classification, respectively. In the follow-up experiments, we assess to what extent this extension leads to an improvement of the performance of the overall model.
In this section, we present the datasets that we used, the setup of the experiments, including the details of the training and the combination of the pre-trained models selected for each transformer block in
Figure 1, and the results of the experiments.
5.1. Datasets
In order to be able to compare the performance of the extended model that we propose with the performance of the original G2C-Tr model [
22], we use the same English, French, and Spanish datasets compiled from the 2019 Wikipedia dumps using the lists of LF instances of Fisas et al. [
67] as seed lists. The dumps are preprocessed (removing metadata and markups) and parsed with the UDPipe2.5 (
https://ufal.mff.cuni.cz/udpipe, accessed on 1 July 2022). From the parsed dumps, for each LF instance encountered in the lists of LF instances, sentences that contain this instance (with one of its valid dependency patterns) are extracted. Only those sentences are selected in which the lemmas of the base and collocate elements have the same PoS as specified in the list of LF instances compiled in [
67]. In order to further minimize the number of the remaining erroneous samples in which the base and the collocate items do not form a collocation (as, e.g., in
Conceding defeat, Cavaco Silva said he wished his rival “much success in meeting his duties for the good of all Portuguese”, where between
success and
meet an indirect dependency relation holds and the two words
meet and
success form, in principle, a collocation, but not in this sentence), an additional manual validation has been performed. For each LF and each syntactic dependency pattern between the base and the collocate elements of this LF, three sentences from the preliminary dataset are randomly picked. In case the base and the collocate elements did not form an instance of this LF, all sentences with the considered dependency pattern between the base and collocate elements were removed from the dataset (for this purpose, an expanded list of expected syntactic dependencies between the base and the collocate elements is used, namely, ‘acl’, ‘acl:relcl’, ‘advcl’, ‘advmod’, ‘amod’, ‘case’, ‘compound’, ‘conj’, ‘csubj’, ‘nmod’, ‘nsubj’, ‘nsubj:pass’, ‘obj’, ‘obl’, ‘obl:npmod’, and ‘xcomp’). This allowed us to take into account mistakes of the parser while not excluding correct examples with wrongly assigned dependencies).
Table 2 displays the counts of the individual LF instances in the obtained English, French, and Spanish corpora.
The corpora are annotated with respect to the LF taxonomy and the sentence LF labels in terms of BI labels of the BIO sequence annotation schema for both elements of the instance, the base and the collocate (‘B-<LF>b’ and ‘I-<LF>b’ for the base, ‘B-<LF>c’, ‘I-<LF>c’ for the collocate, and ‘O’ for other tokens); see
Figure 1 for an illustration. The BIO annotation has the advantage that it facilitates a convenient labeling of multi-word elements, and the separate annotation of the base and collocate elements allows for flawless annotation of cases where the base and the collocate elements are not adjacent. As a sentence label, the most frequent LF in a sentence and the first one in case of a draw is chosen.
For training of the relation classification transformer, we created an additional dataset, where we introduced entity markers into the input sequences ( for the base and for the collocate), such that the <LF> tag indicates the default order of the base and the collocate (e.g., in “Oper1(,)”, which is a verb–object construction, the verbal collocate precedes the base). In case one sentence contains several collocations, we use each of them for an individual training example by copying the sentence and introducing entity markers only for a single collocation at once. Thus, the number of examples is equal to the number of annotated collocations in our corpora. We did not introduce negative examples of any special “not-a-collocation” class to ensure that the transformer in extension cannot “cancel” a collocation extracted by the base G2C-Tr model but can only refine the lexical function assignment.
5.2. Setup of the Experiments
For the experiments, the obtained datasets were split into training, development, and test subsets in proportion 80–10–10 in terms of LF-wise unique instances, such that all occurrence samples of a single LF instance appear only in one of the subsets. Sentences with several collocations that belonged to different splits are dropped. Since collocations have different frequencies in the corpus, not each split leads to the same proportion in terms of overall number of samples. Therefore, for each LF, we additionally distributed collocations to ensure an approximate 80–10–10 split not only in terms of the number of LF instances in general but also in terms of the number of instances per LF.
In order to be able to clearly distinguish the contribution of our extension to the final figures, to run the experiments, we used the same versions of Transformers for the G2C-Tr model as in [
22]: BERT-large (
https://huggingface.co/bert-large-uncased, accessed on 1 July 2022) for English, XLM-RoBERTa-base (
https://huggingface.co/xlm-roberta-base, accessed on 1 July 2022) for Spanish and French, and considered models trained with and without information about PoS tags.
As for the relation classification, we used different monolingual RoBERTa large and XLM-RoBERTa large-based models for English (
https://huggingface.co/roberta-large, accessed on 1 July 2022), Spanish (
https://huggingface.co/xlm-roberta-large, accessed on 1 July 2022), and French (
https://huggingface.co/camembert/camembert-large, accessed on 1 July 2022). About 20% of the development set has been used for the evaluation of intermediate checkpoints during the training phase, and the three best checkpoints were evaluated on the entire development set in order to select the model to be used for the G2C-Tr extension. The batch size was of 16; the models were trained for 10 epochs (about 169,000 steps for English, 90,000 steps for Spanish, and 83,000 steps for French). Since, in contrast to the G2C-Tr base model, which may predict base without collocate and vise versa, our model extracts only complete collocations, we also removed unpaired B-I tags from the outcome of the base model and re-evaluated it to make the scores for both models comparable.
5.3. Results of the Experiments
In what follows, we first present the performance of the relation classification model with respect to the individual LFs and then show the results of the evaluation of the entire model, i.e., the extended G2C-Tr model.
Table 3,
Table 4 and
Table 5 provide precision (P), recall (R), and F1-scores (F1) achieved on the training, development and test set, respectively, per LF for each considered language (with ‘I’ as correctly identified instances of LF
f, ‘A’ as all instances identified as instances of
f, and ‘B’ as all instances of
f in the test set, precision is defined as P = ∣I ∩ A
A∣, recall as R = ∣A ∩ B
B∣ and F1 as the harmonic mean of P and R: F1 = 2PR ∖ (P + R)). Within each LF, examples were split into two groups depending on the order of collocation parts in a sentence, i.e., when the collocate precedes the base (
) and when the base precedes the collocate (
). The columns “#” show the number of examples in each group, with the total size of a set at the bottom.
Table 6 reports the average F1-scores of (i) the original G2C-Tr model, i.e., for separate identification of the base and collocate elements across all LFs, without that both elements must have been identified; (ii) the original G2C-Tr model, but limited to cases when both elements are identified; (iii) the G2C-Tr model extended by the relation extraction layer. We provide the results for these three constellations because the first was used in [
22] to report on the performance of the G2C-Tr model, while the second and third allow for a direct comparison between the original G2C-Tr model and the relation extraction-extended model. Configurations with an access to PoS embeddings (“G2C+PoS”) and without PoS embeddings (“G2C-PoS”) are assessed.
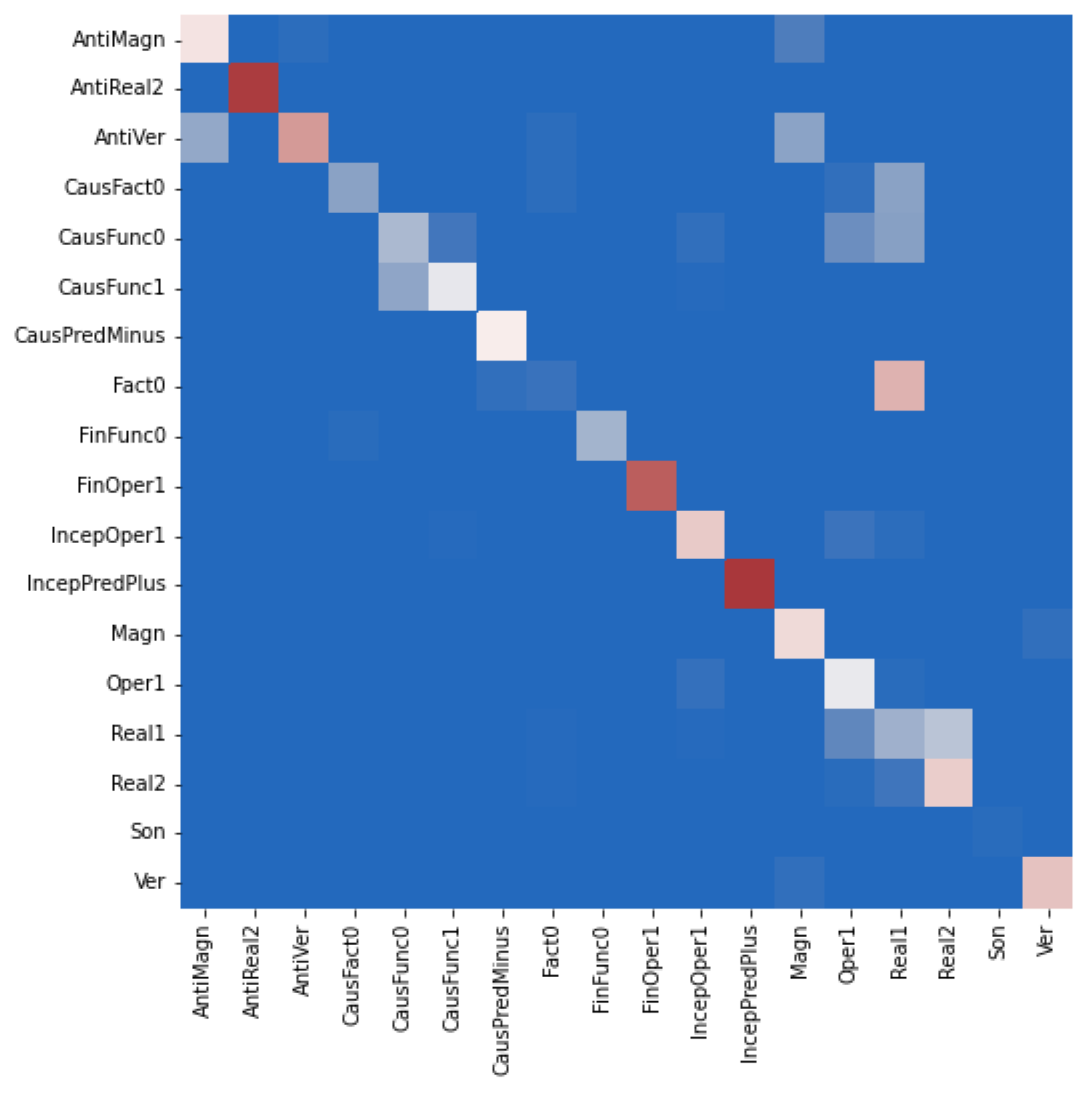
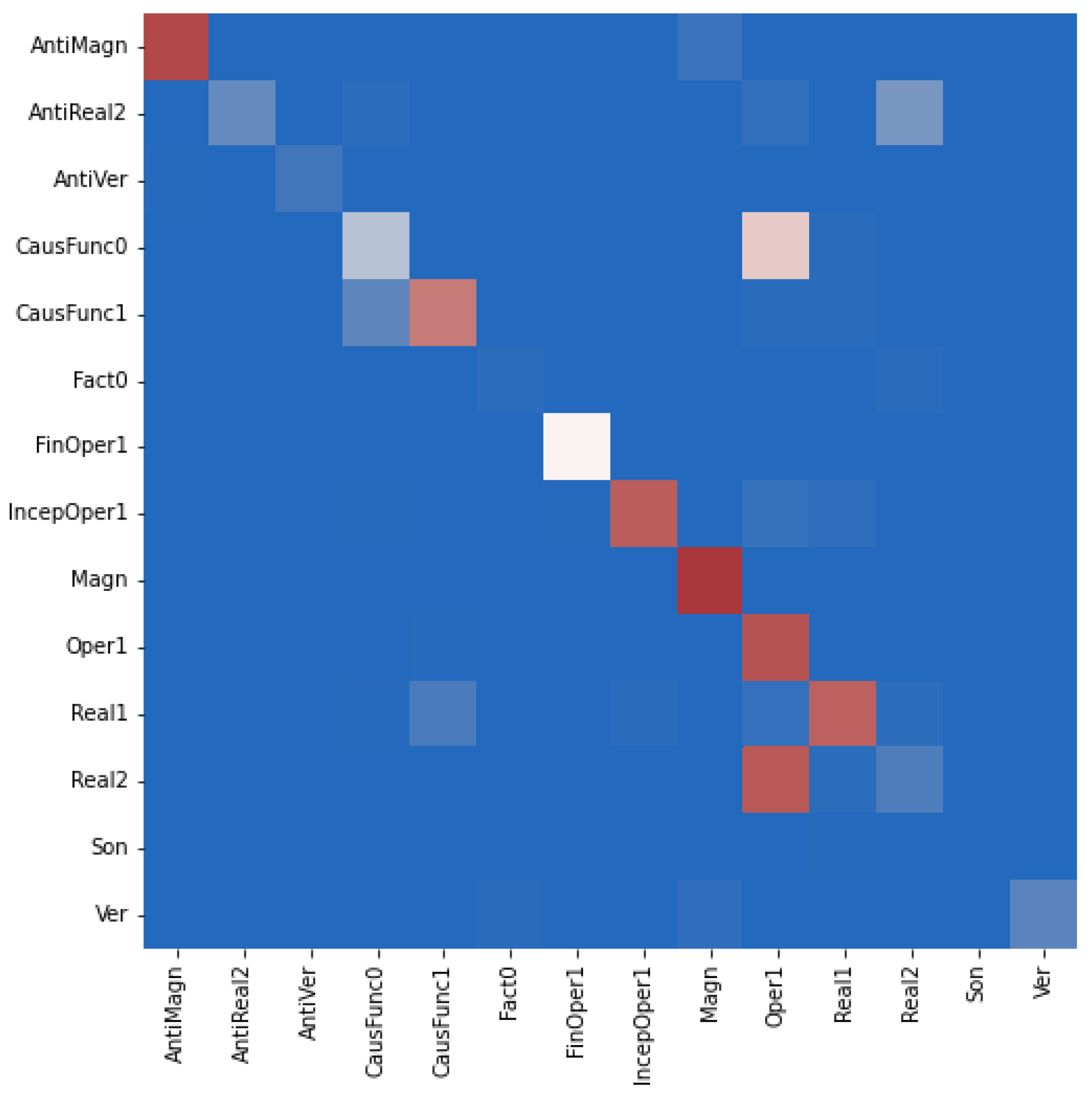
Figure 3,
Figure 4 and
Figure 5 display the corresponding confusion matrices for the test set.
7. Conclusions and Future Work
Following the fact that between the elements of a collocation, i.e., a lexically restricted word co-occurrence, both a syntactic and a semantic dependency holds, we explored to what extent the addition of an explicit semantic relation extraction layer to a graph transformer model, which operates on syntactic dependencies, improves the overall performance of the identification and classification of collocations with respect to the LF taxonomy. Our experiments have shown that the Transformer is already able to capture the semantic relations and that although the additional relation extraction layer helps to somewhat improve the performance, this improvement is limited. It is also to be noted that the semantic relation extraction layer still does not fully solve the problem of the confusion of the instances of syntactically and/or semantically similar LFs, although an improvement compared to the original G2C-Tr model can be observed.
Along with these valuable newly gained insights, the presented work reveals some limitations. In particular to be mentioned is the fact that so far, the relation extraction model has been applied only to the task of classification of lexically restricted word co-occurrences. In our future work, we want to explore the potential of a relation extraction-based model for the joint identification and classification of LF instances.Furthermore, in our study, we did not pursue the question on how the exploitation of the information on syntactic sentence structures would influence the quality of the classification of LF instances with the canonical vs. non-canonical order of their elements. Finally, a more thorough linguistic analysis of the confusion matrices would certainly contribute to a better understanding and thus also to the solution of the classification of LF instances. It should be also clear to the reader that the number of different instances of certain LFs which are available so far for the training and fine-tuning of ML models is very limited. This restricts the potential of currently explored models (including the one presented in this work). To advance significantly, either novel models must be researched, which are able to learn (as humans do) on a few training data only, or substantially larger datasets need to be compiled.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}