
Classification in High Dimension Using the Ledoit–Wolf Shrinkage Method



Abstract
:1. Introduction
2. Materials and Methods
2.1. Ledoit and Wolf Shrinkage Estimators
2.2. Improved Linear Discriminant Rules
2.3. Properties of the Improved Discriminant Rule
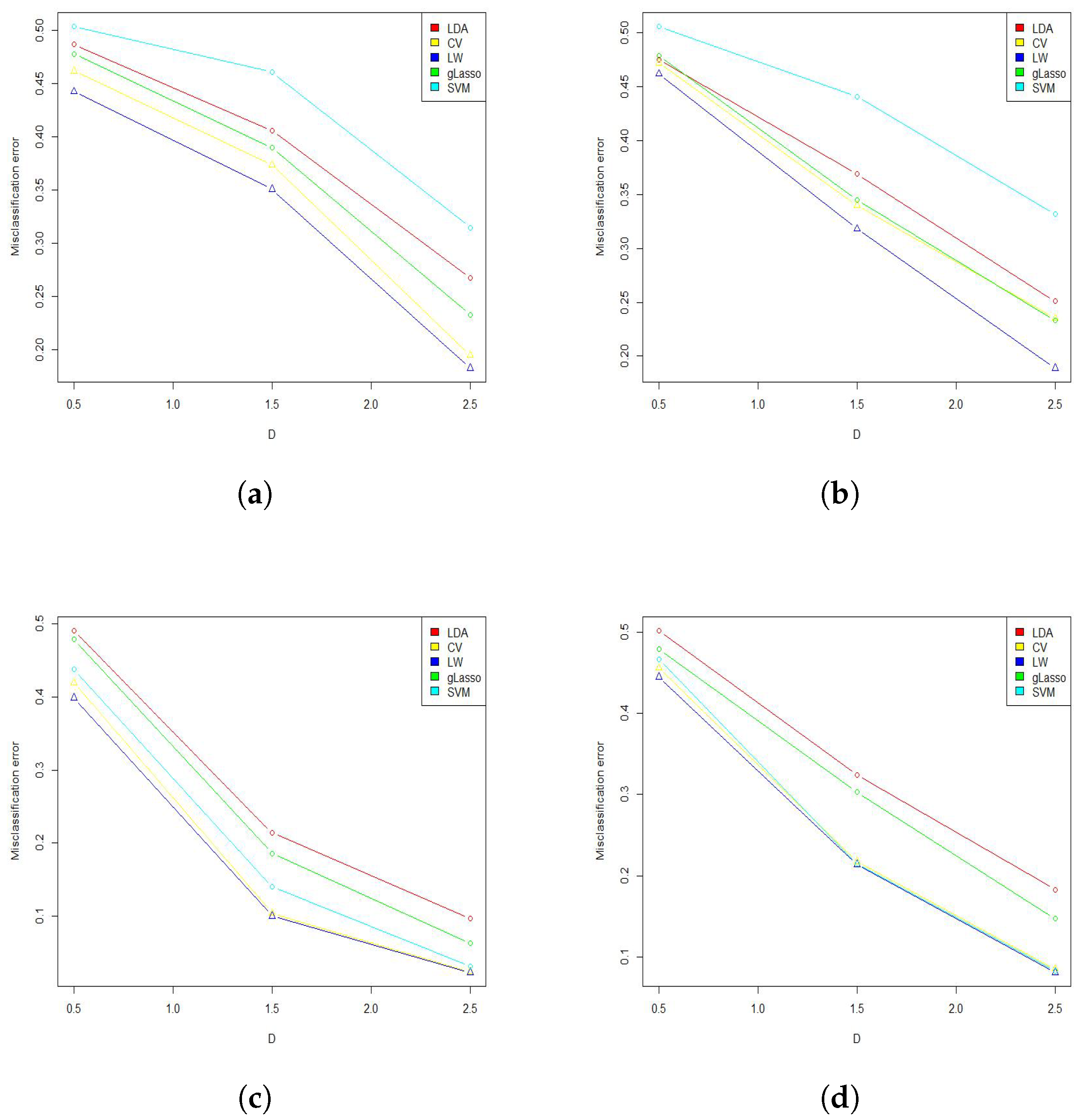
3. Numerical Studies
3.1. Simulation Study
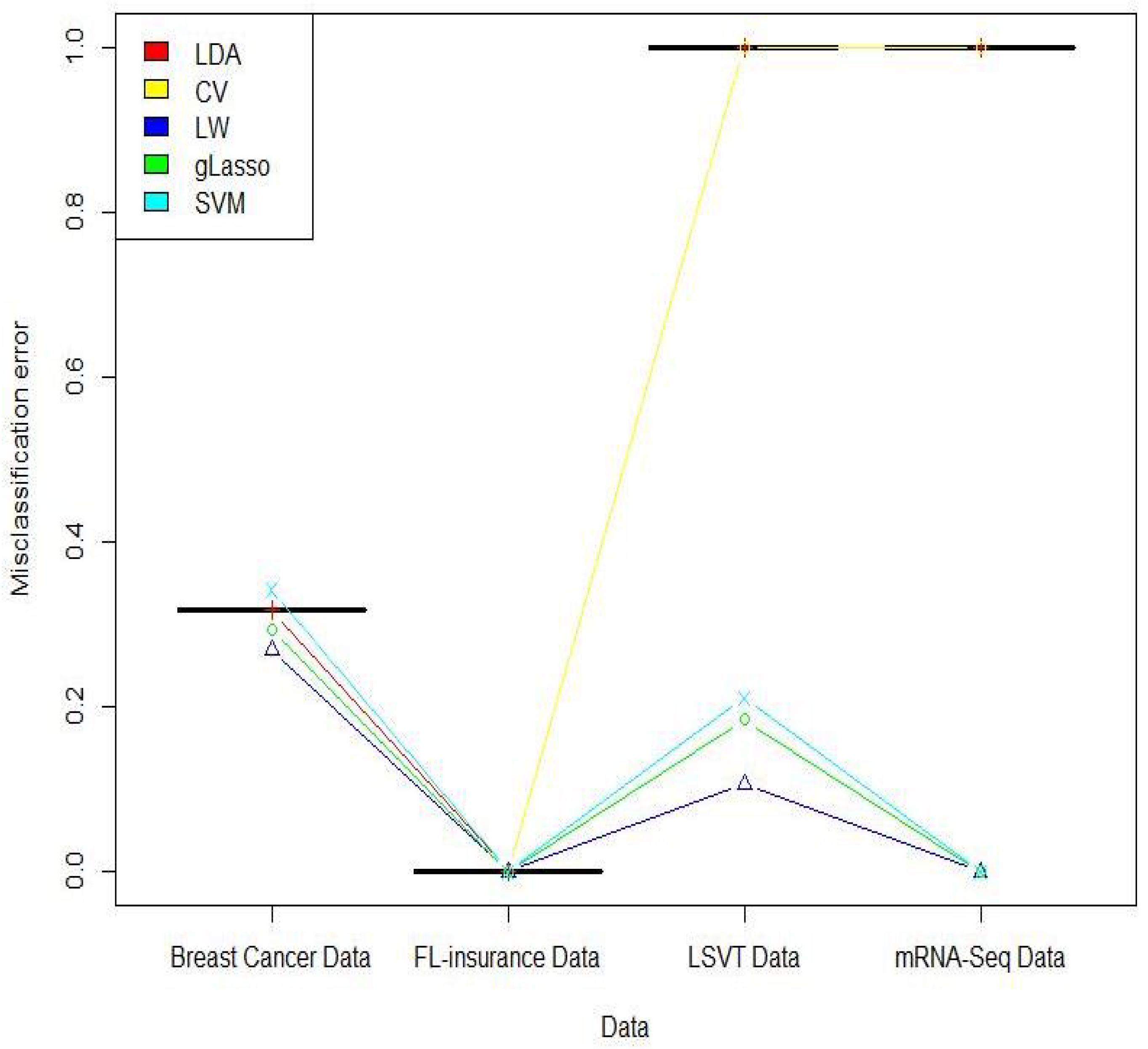
3.2. Real Data Analyses
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Clemmensen, L.; Hastie, T.; Witten, D.; Ersbøll, B. Sparse discriminant analysis. Technometrics 2011, 53, 406–413. [Google Scholar] [CrossRef] [Green Version]
- Peck, R.; Van Ness, J. The use of shrinkage estimators in linear discriminant analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1982, 5, 530–537. [Google Scholar] [CrossRef] [PubMed]
- Srivastava, M.S. Multivariate theory for analyzing high dimensional data. J. Jpn. Stat. Soc. 2007, 37, 53–86. [Google Scholar] [CrossRef] [Green Version]
- Dempster, A.P. Covariance selection. Biometrics 1972, 28, 157–175. [Google Scholar] [CrossRef]
- Meinshausen, N.; Bühlmann, P. High-dimensional graphs and variable selection with the lasso. Ann. Stat. 2006, 34, 1436–1462. [Google Scholar] [CrossRef] [Green Version]
- Banerjee, O.; El Ghaoui, L.; d’Aspremont, A. Model selection through sparse maximum likelihood estimation for multivariate Gaussian or binary data. J. Mach. Learn. Res. 2008, 9, 485–516. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. Sparse inverse covariance estimation with the graphical lasso. Biostatistics 2008, 9, 432–441. [Google Scholar] [CrossRef] [Green Version]
- Bickel, P.J.; Levina, E. Covariance regularization by thresholding. Ann. Stat. 2008, 36, 2577–2604. [Google Scholar] [CrossRef]
- Cai, T.T.; Zhang, L. High dimensional linear discriminant analysis: Optimality, adaptive algorithm and missing data. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2019, 89, 675–705. [Google Scholar]
- Rothman, A.J.; Levina, E.; Zhu, J. Generalized thresholding of large covariance matrices. J. Am. Stat. Assoc. 2009, 104, 177–186. [Google Scholar] [CrossRef]
- Bien, J.; Tibshirani, R. Sparse estimation of a covariance matrix. Biometrika 2011, 98, 807–820. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fan, J.; Liao, Y.; Liu, H. An overview of the estimation of large covariance and precision matrices. Econom. J. 2016, 19, C1–C32. [Google Scholar] [CrossRef]
- Stein, C.; James, W. Estimation with quadratic loss. In Proceedings of the Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 20–30 June 1961; Volume 1, pp. 361–379. [Google Scholar]
- Efron, B. Biased versus unbiased estimation. Adv. Math. 1975, 16, 259–277. [Google Scholar] [CrossRef] [Green Version]
- Efron, B.; Morris, C. Data analysis using Stein’s estimator and its generalizations. J. Am. Stat. Assoc. 1975, 70, 311–319. [Google Scholar] [CrossRef]
- Efron, B.; Morris, C. Multivariate empirical Bayes and estimation of covariance matrices. Ann. Stat. 1976, 4, 22–32. [Google Scholar] [CrossRef]
- Di Pillo, P.J. The application of bias to discriminant analysis. Commun. Stat. Theory Methods 1976, 5, 843–854. [Google Scholar] [CrossRef]
- Campbell, N.A. Shrunken estimators in discriminant and canonical variate analysis. J. R. Stat. Soc. Ser. (Appl. Stat.) 1980, 29, 5–14. [Google Scholar] [CrossRef]
- Mkhadri, A. Shrinkage parameter for the modified linear discriminant analysis. Pattern Recognit. Lett. 1995, 16, 267–275. [Google Scholar] [CrossRef] [Green Version]
- Choi, Y.-G.; Lim, J.; Roy, A.; Park, J. Fixed support positive-definite modification of covariance matrix estimators via linear shrinkage. J. Multivar. Anal. 2019, 171, 234–249. [Google Scholar] [CrossRef] [Green Version]
- Bickel, P.J.; Levina, E. Regularized estimation of large covariance matrices. Ann. Stat. 2008, 36, 199–227. [Google Scholar] [CrossRef]
- Khare, K.; Rajaratnam, B. Wishart distributions for decomposable covariance graph models. Ann. Stat. 2011, 39, 514–555. [Google Scholar] [CrossRef] [Green Version]
- Cai, T.; Zhou, H. Minimax estimation of large covariance matrices under ℓ1-norm. Stat. Sin. 2012, 22, 1319–1349. [Google Scholar]
- Maurya, A. A well-conditioned and sparse estimation of covariance and inverse covariance matrices using a joint penalty. J. Mach. Learn. Res. 2016, 17, 4457–4484. [Google Scholar]
- Ledoit, O.; Wolf, M. A well-conditioned estimator for large-dimensional covariance matrices. J. Multivar. Anal. 2004, 88, 365–411. [Google Scholar] [CrossRef]
- Wang, C.; Pan, G.; Tong, T.; Zhu, L. Shrinkage estimation of large dimensional precision matrix using random matrix theory. Stat. Sin. 2015, 25, 993–1008. [Google Scholar] [CrossRef] [Green Version]
- Hong, Y.; Kim, C. Recent developments in high dimensional covariance estimation and its related issues, a review. J. Korean Stat. Soc. 2018, 47, 239–247. [Google Scholar] [CrossRef]
- Le, K.T.; Chaux, C.; Richard, F.; Guedj, E. An adapted linear discriminant analysis with variable selection for the classification in high-dimension, and an application to medical data. Comput. Stat. Data Anal. 2020, 152, 107031. [Google Scholar] [CrossRef]
- Srivastava, M.S. Some tests concerning the covariance matrix in high dimensional data. J. Jpn. Stat. Soc. 2005, 35, 251–272. [Google Scholar] [CrossRef] [Green Version]
- Ledoit, O.; Wolf, M. Nonlinear shrinkage estimation of large-dimensional covariance matrices. Ann. Stat. 2012, 40, 1024–1060. [Google Scholar] [CrossRef]
- Friedman, J.H. Regularized discriminant analysis. J. Am. Stat. Assoc. 1989, 88, 165–175. [Google Scholar] [CrossRef]
- Wu, Y.; Qin, Y.; Zhu, M. Quadratic discriminant analysis for high-dimensional data. Stat. Sin. 2019, 29, 939–960. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| LDA | CV | LW | gLasso | SVM | ||
|---|---|---|---|---|---|---|
| a | ||||||
| Data1 | www.UCIMachineLearning.com | ||
| Data2 | www.Kaggle.com | ||
| Data3 | www.UCIMachineLearning.com | ||
| Data4 | www.UCIMachineLearning.com | ||
| LDA | CV | SVM | gLasso | LW | |
|---|---|---|---|---|---|
| Data1 | |||||
| Data2 | |||||
| Data3 | a | ||||
| Data4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lotfi, R.; Shahsavani, D.; Arashi, M. Classification in High Dimension Using the Ledoit–Wolf Shrinkage Method. Mathematics 2022, 10, 4069. https://doi.org/10.3390/math10214069
Lotfi R, Shahsavani D, Arashi M. Classification in High Dimension Using the Ledoit–Wolf Shrinkage Method. Mathematics. 2022; 10(21):4069. https://doi.org/10.3390/math10214069
Chicago/Turabian StyleLotfi, Rasoul, Davood Shahsavani, and Mohammad Arashi. 2022. "Classification in High Dimension Using the Ledoit–Wolf Shrinkage Method" Mathematics 10, no. 21: 4069. https://doi.org/10.3390/math10214069
APA StyleLotfi, R., Shahsavani, D., & Arashi, M. (2022). Classification in High Dimension Using the Ledoit–Wolf Shrinkage Method. Mathematics, 10(21), 4069. https://doi.org/10.3390/math10214069