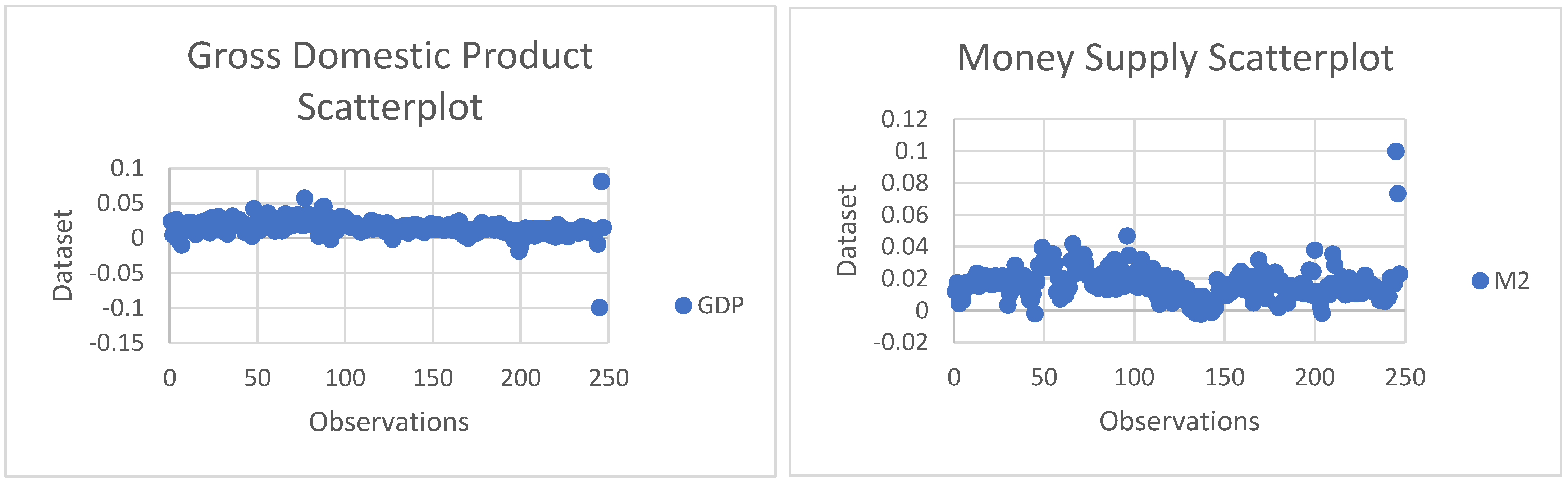
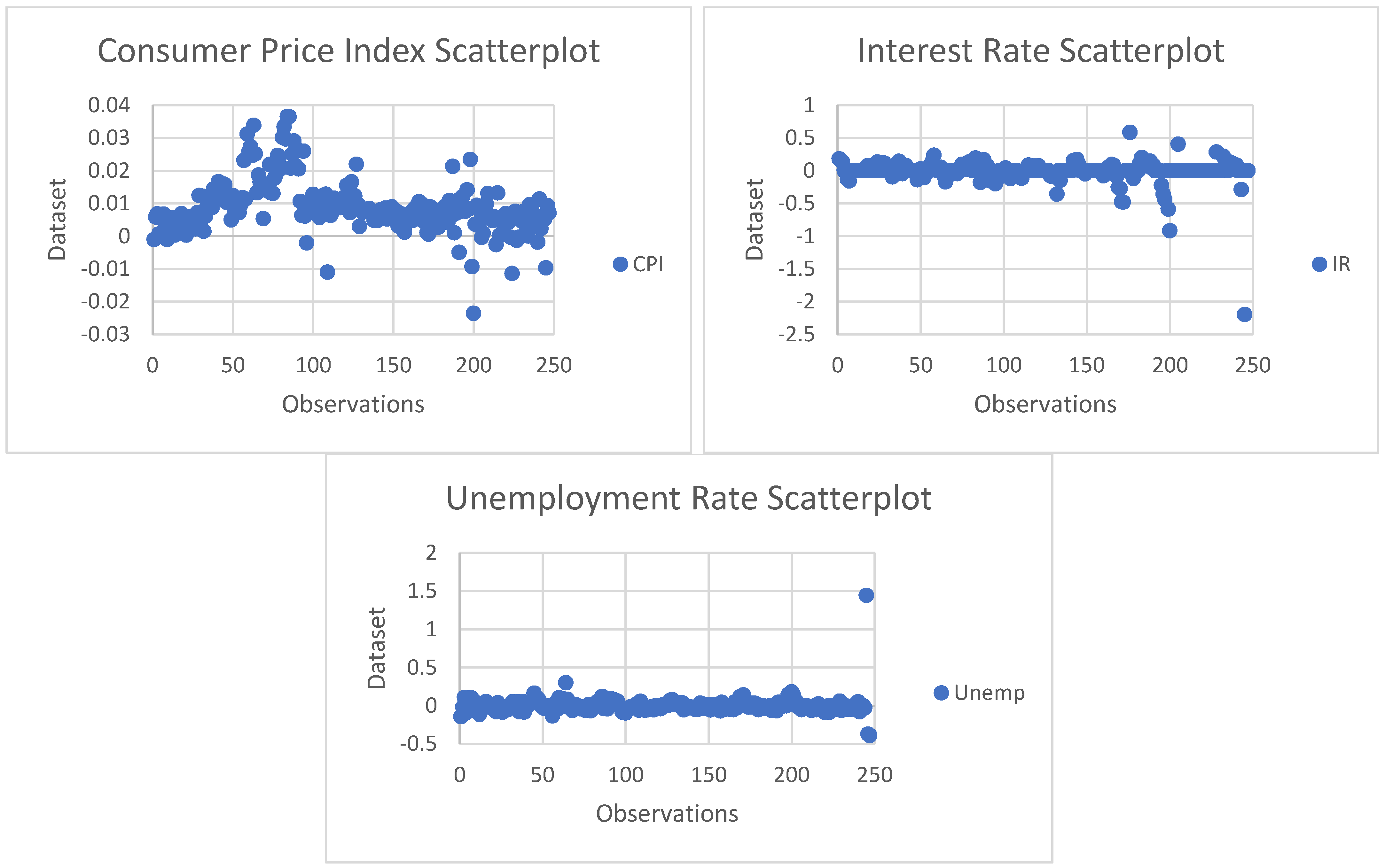
The software utilized in these analyses were R and Microsoft Excel. The dataset comprises 254 observations; however, it is worth stating that the last observation is sacrificed due to the normalization techniques applied and four used as lagged values of the VAR model, which leaves the total sample with 250 observations. Furthermore, the range calculation indicates high variability in the dataset, which can also be confirmed by the large standard deviation in the cases of GDP, M2, and CPI. That is, the data is more spread out around the mean; however, as for Interest Rate and the Unemployment Rate, there is less variability, and the data is more clustered around its mean. In addition, it is pivotal to state that the data does not suffer from skewness or kurtosis as the acceptable range for skewness is ±2, and for kurtosis ±3, according to [
30].
These variables have been extensively explored over the years, and with different research approaches, many theories have evolved. Among those is the relationship between expansionary monetary policy and GDP growth. When working with a macroeconomic dataset, it is common to come across non-stationary data (A dataset is considered stationary when its mean and variance are constant over time [
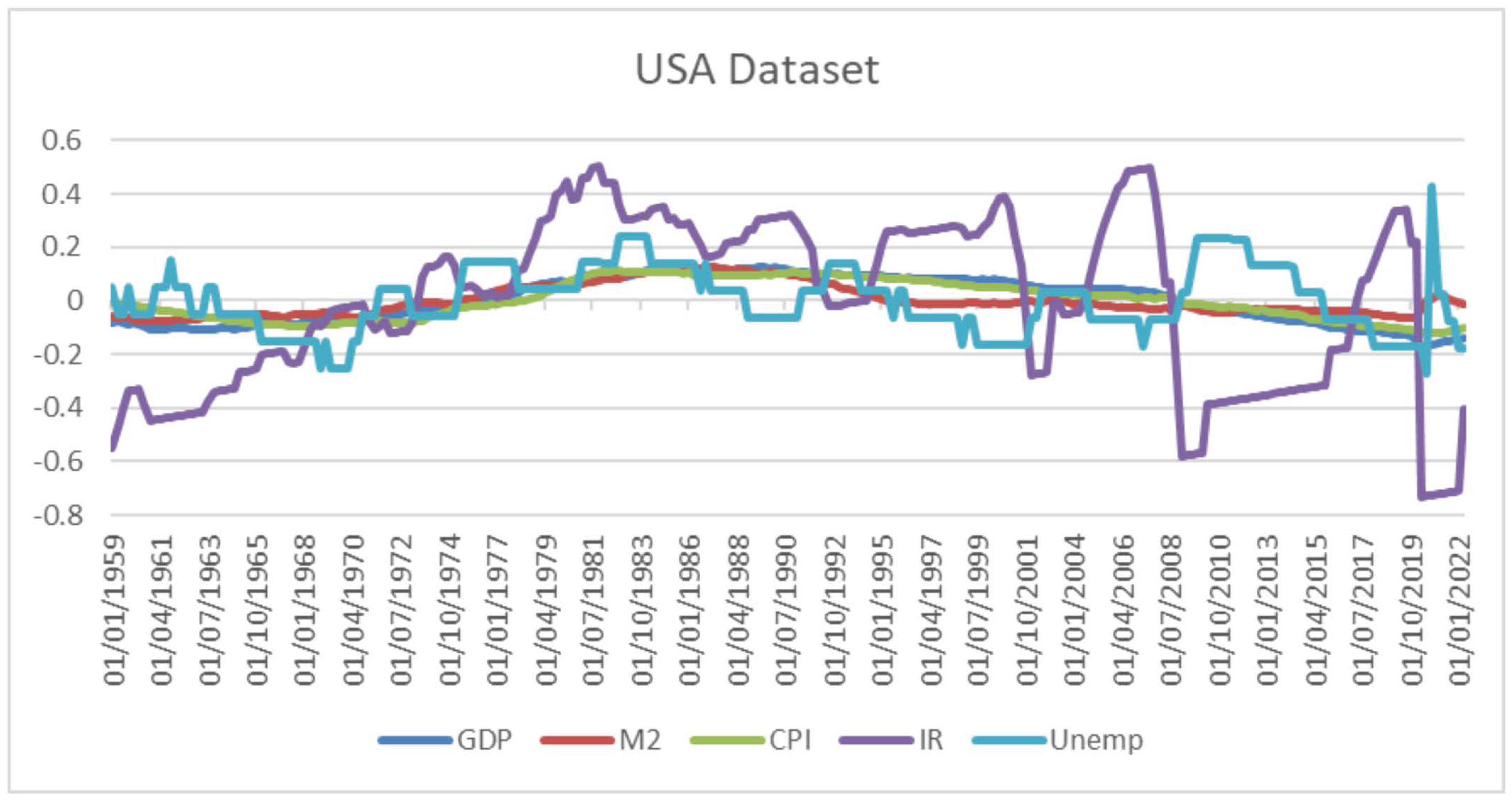
31]), especially when the analysis involves variables such as Growth Domestic Product (GDP), Money Supply (M2), and Consumer Price Index (CPI). Because these variables are not volatile, they usually have an upward or downward trend in an extensive dataset, which must be corrected before any econometric analysis to avoid spurious output and, therefore, misleading interpretation. Hence, the solution to transform non-stationary data to stationary is to take the log of the variables to normalize them and then apply a lagged differencing methodology:
The basic econometric models are separated into two or more variables, a dependent variable called and one independent variable called . Thus, the model tests the capability of to affect but not the opposite; therefore, in this model, is classified as exogenous while is endogenous.
Vector Autoregressive (VAR) Model
The paper has been constructed based on the Vector Autoregressive (VAR) model that [
32] advocated as an alternative for regular econometric models that consist of the assumption of
causing
. Therefore, VAR is a theory-free method that allows the dataset to speak for itself with no prior assumptions made. The model proposed by VAR is a regression model for multivariate time series data when there is more than one dependent variable since all variables within the model can affect each other. In such a case, there might be a mutual relationship between all variables in the model, taking into account a lagged period, which can be any. So, all variables are considered endogenous. Hence, if we convert this into a mathematical equation, then we have (6) and (7), as similarly observed in [
31,
33,
34].
The VAR model, however, works based on two assumptions:
and are stationary, also known as A(0), and there is a constant mean and variance over time (t);
The error terms and are not correlated since it is random.
The issue with the equation above is that the
and
equations are separate. The objective is to have an interrelation between both equations. This is why all endogenous variables are kept to the left side of the equation, whilst the exogenous variables are kept to the right. The solution for this is to algebraically transform the equations into a reduced form, as observed in Equations (8) and (9) below:
Once the equations are aligned, we can convert them into a matrix:
We can simplify the matrices as follows:
where:
We then have
representing the
and
, Φ
t representing the vector of variables (
), λ
1 the constant,
is the lagged variable, and
as the error term. Because
is supposed to be on the right side of the equation, we then multiply both sides of the equation by the inverse matrix of
, and we get:
Thus, we finally obtain the reduced form of the equation, and we can simplify once more by renaming the terms:
where:
Ι is the unit matrix and
is a constant as
and λ are constants matrices defined as Ω
1. We can simplify Equation (14) as:
where:
The VAR model explained above assumes two endogenous variables,
and
, that are now
but there is no limit to that, and the more variables added, more equations are expected. It is also important to note that in this VAR model Ordinary Least Squares (OLS) will be used to estimate the coefficients of the matrices as similarly done by Feldstein and Stock [
4]. Moreover, it is pivotal to test the VAR model stability, which is done by identifying the root of the Ω matrix. Thus, if the root is less than 1 in absolute value then the system is stable. What is interesting to note is that in case of violation of assumptions 1 and 2, the model would provide a spurious but convincing output, e.g., a high coefficient of determination (R
2) as well as statistically significant values (The coefficient of determination, also known as R squared (R
2), measures, in percentage, the variability of the dependent variable in relation to changes in the independent variable). Therefore, to avoid this before applying the model, the researcher must perform a stationarity test. In this case, the model is the unit root test (The unit root test is used to determine whether a time series is stationary. A dataset is considered stationary if changes in the variable do not change the format of the distribution). This is also referred to as the augmented Dickey–Fuller test proposed by Dickey and Fuller [
35], which is appropriate for time series with more than one lag length, say i = 1, as mathematically described below.
If we subtract
from both sides of the equation, we then have:
where
is the first difference operator. Thus, the unit root hypothesis is as follows:
H0: means that there is a unit root, = 1 − Ω = 0.
H1: means no unit root,=
Calculating the t-statistics, which has a particular distribution called (DF) we get the estimated value of δ. Thus,
< DF critical value then rejects H0, and if
> DF critical value, then there is no evidence to reject H0. Once the VAR model has been applied, the Granger causality test is performed to measure the causal effect among the variables being analyzed. This is important as Y
t may affect X
t in a future period, e.g., Money Supply may impact GDP growth but not necessarily straight after an increase or vice versa, or perhaps a decrease in GDP may increase the Unemployment Rate but not in the long run [
36]. However, it is pivotal to mention that running the VAR model, we first need to find the optimal lag length, which is the minimum value of the following lag length criterion: AIC, SIC, HQ, and FPE (Akaike Information Criterion (AIC), Schwarz Information Criterion (SIC), Hannan-Quinn (HQ), and Final Prediction Error (FPE) are information criteria used by statisticians to identify the optimal lag length). We then regress the Y
t alone, and the objective is to test how accurate the autoregression can be without any additional variable; otherwise, there is no need to add another variable to help predict Y
t.
Hence, if the autoregression equation above is not accurate enough to predict the future value, we then incorporate more variables, e.g., X
t.
We then test the coefficients individually using a t-test and then collectively with an F-test used when we want to test multiple coefficients. Where H0: = 0, which means that Xt does not Granger cause Yt. Conversely, if H1: is not 0 we can assume that Xt Granger causes Yt.
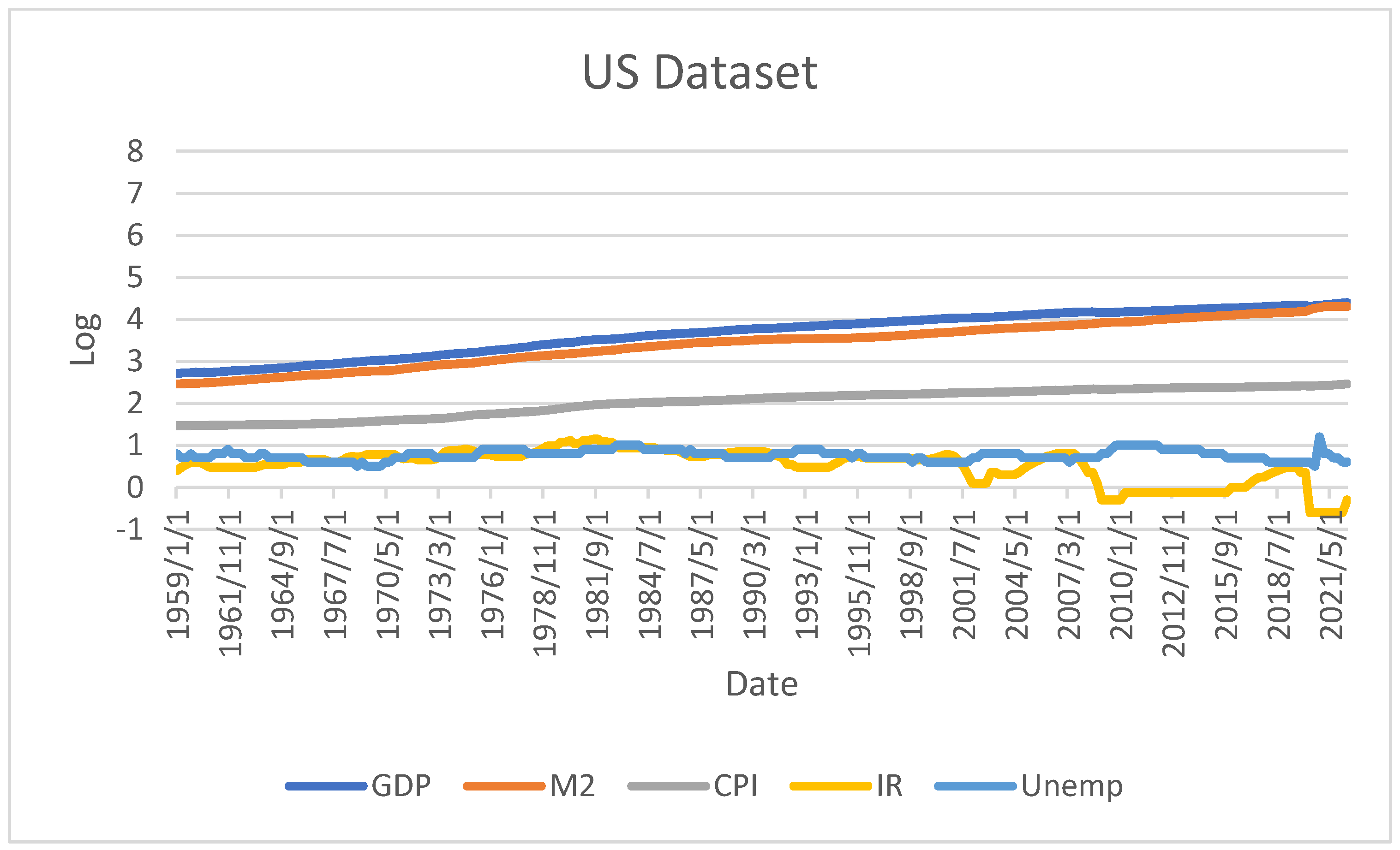
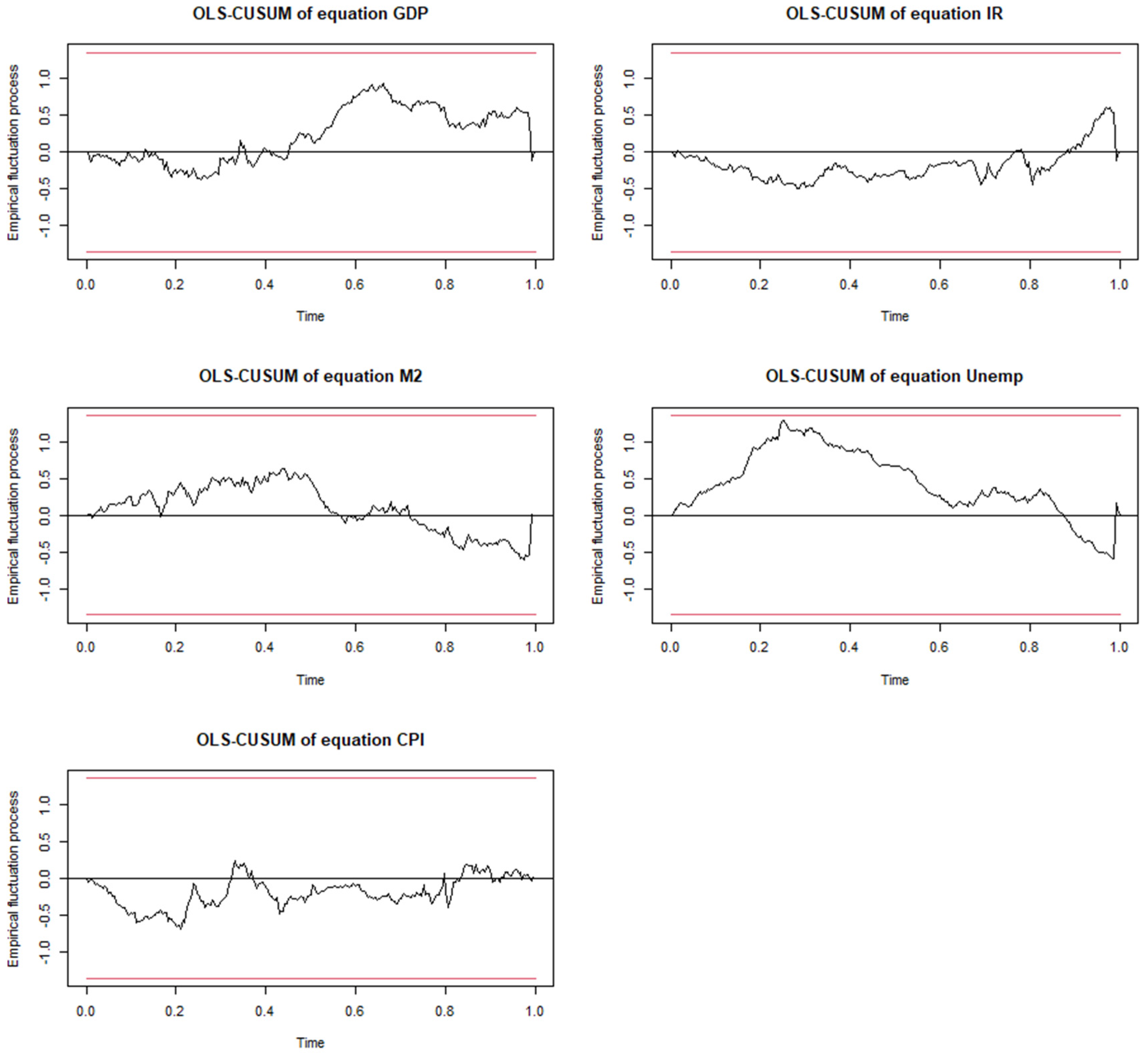
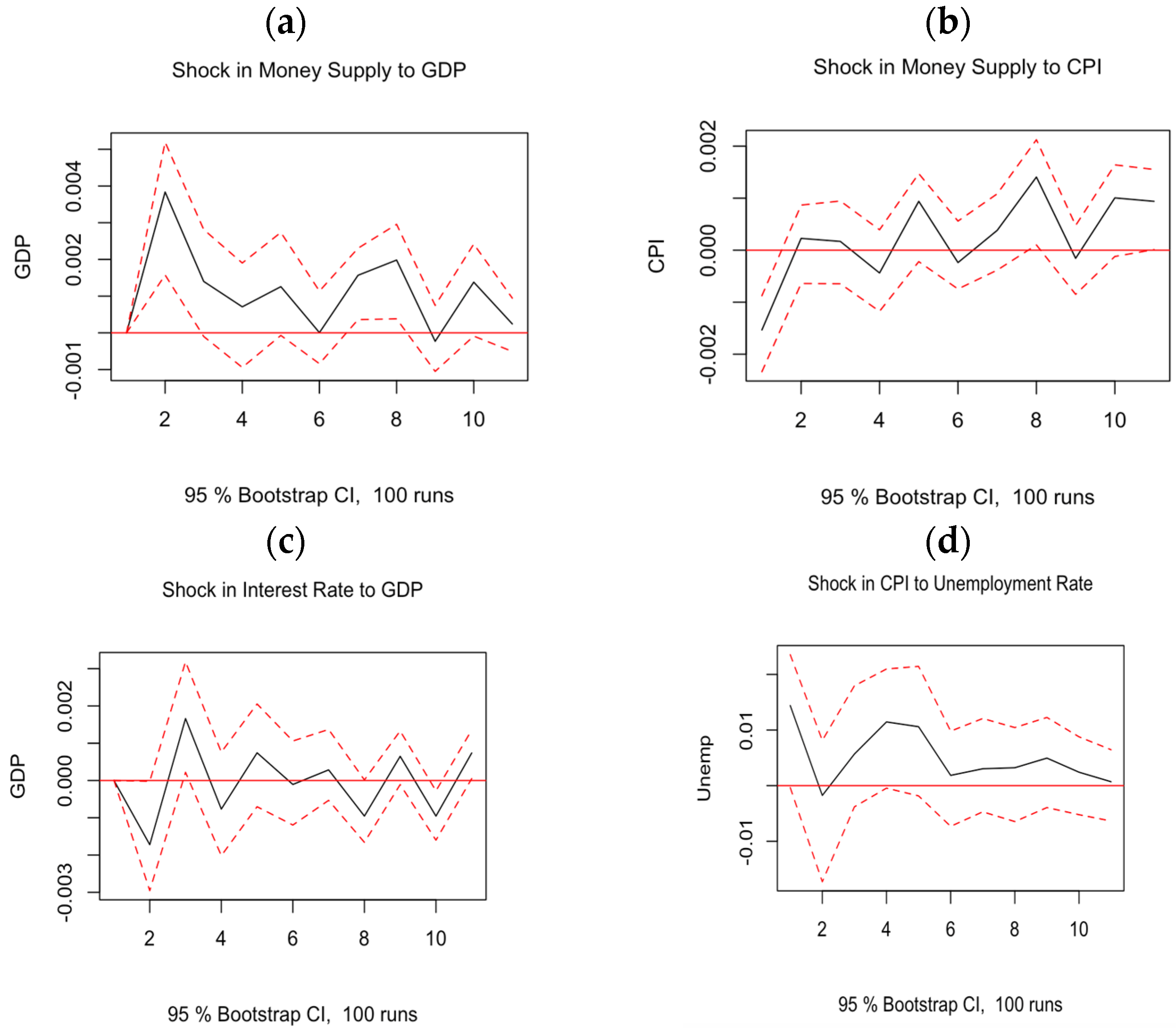
The VAR model is composed of 5 endogenous variables. Gross Domestic Product, Money Supply, Consumer Price Index, Interest Rate, and Unemployment Rate. This is Y = Ln(GDP), Ln(M2), Ln(CPI), Ln(IR), and Ln(Unemp), respectively. Where Ln is their logarithm to a constant base e. This approach shall allow us to conduct an impulse response analysis, which shows the impact of one standard deviation shock in one of the variables concerning another, e.g., one standard deviation change in M2 may cause a short- or long-term impact on GDP. Similarly, one standard deviation change in Interest Rate (IR) may affect the Unemployment Rate up or down.
In the following Section, we explore and expose the procedures and outcomes of the tests performed that support the conclusion in
Section 4.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}