
Framework for Classroom Student Grading with Open-Ended Questions: A Text-Mining Approach

 ,
,  and
and 
Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
3.1. Available Data
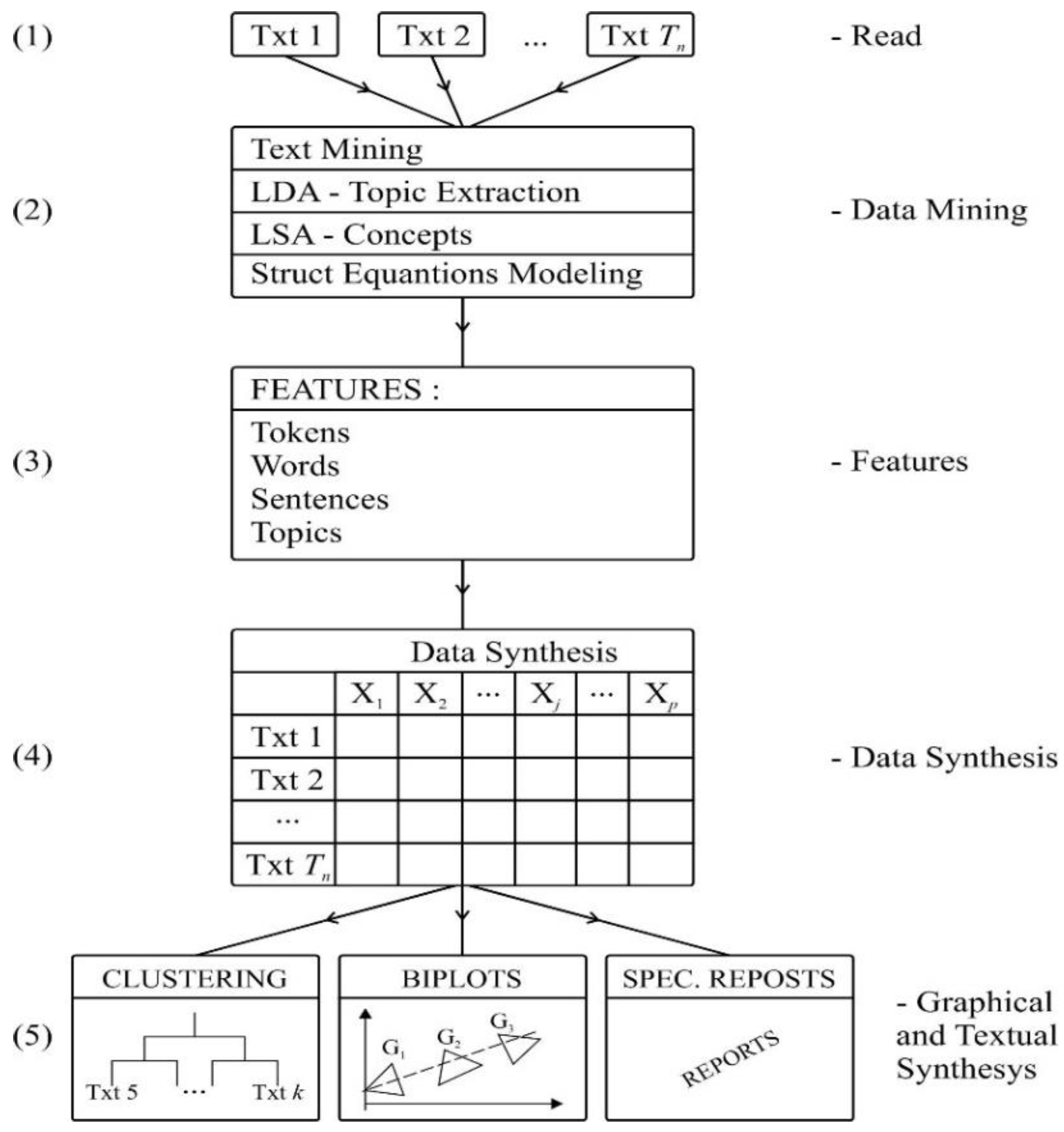
3.2. Methods: General View
- (1)
- Reading texts. Textual data sets containing the students’ answers are read. Generally, these texts are stored as separate text files (one file per text/student answer) forming a corpus, or the whole set of texts is stored as a sheet of an EXCEL book, one row per student/text, with an entire text stored in a single cell.
- (2)
- Textual data-mining tasks are performed with R packages—such as QuanteDa, LDA, LSA, PLS-PM and SemPLS (Ahadi et al., 2022) [38]. This analysis aims to obtain relevant information about students’ use of language in text construction. For example, token extraction (words, forms, sentences, pairs of words and their frequencies). Estimating topics subjacent to text construction is also considered using the LDA package (Chang, 2015) [39]. A theoretical model relating latent students’ skills in text and content construction with students’ competence in the subject matter is modelled using path modelling.
- (3)
- This step leads to the characterisation of each text by a set of feature values resulting from the previous text-mining analysis. Specific features are used to create partial reports to be used when a deeper analysis is necessary—to break ties, for example—and in the construction of global graphical and numeric synthesis.
- (4)
- Current Data Synthesis (CDS)—As a result of previous steps, a synthesis table data set is built. Its rows correspond to students/texts, and its columns represent relevant features used to construct multivariant graphical displays helping teachers in the decision process.
- (5)
- Graphical and Textual Synthesis—The main outputs from the system are biplots and classification trees involving texts and other supplementary information about students—such as results obtained in previous tests or other observational annotations. Thus, it is believed that a teacher must combine, closely supported by the framework, his/her previous knowledge about students, specific domain knowledge and teaching experience with scoring.
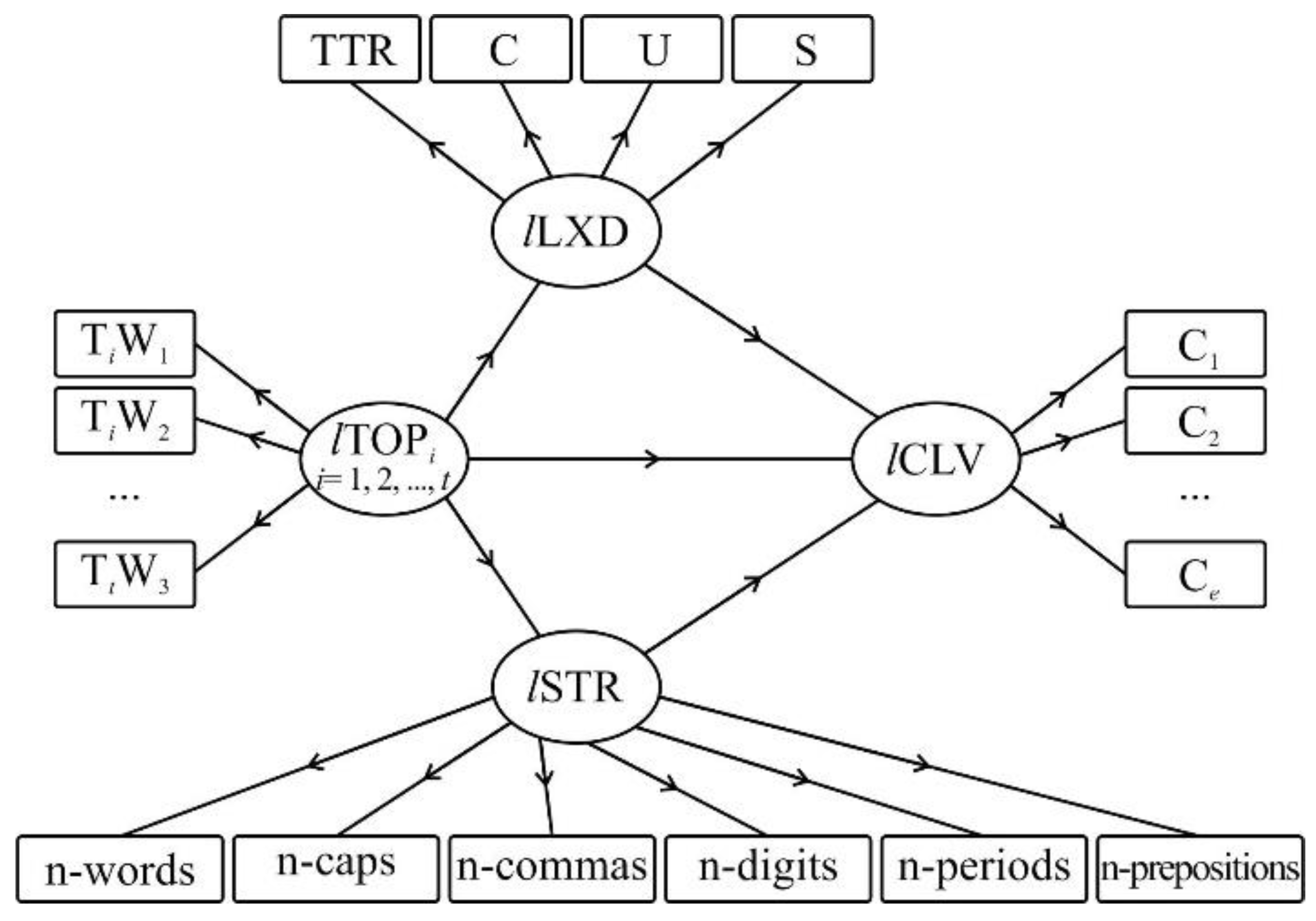
3.3. Model Formulation Using Structural Equations Modelling (SEM)
3.4. Methods: Text Mining Summarising of Data Sets
3.5. Methods: Graphical Methods
4. Results of Data Analysis
4.1. PLS Path Model Estimation Using PLS
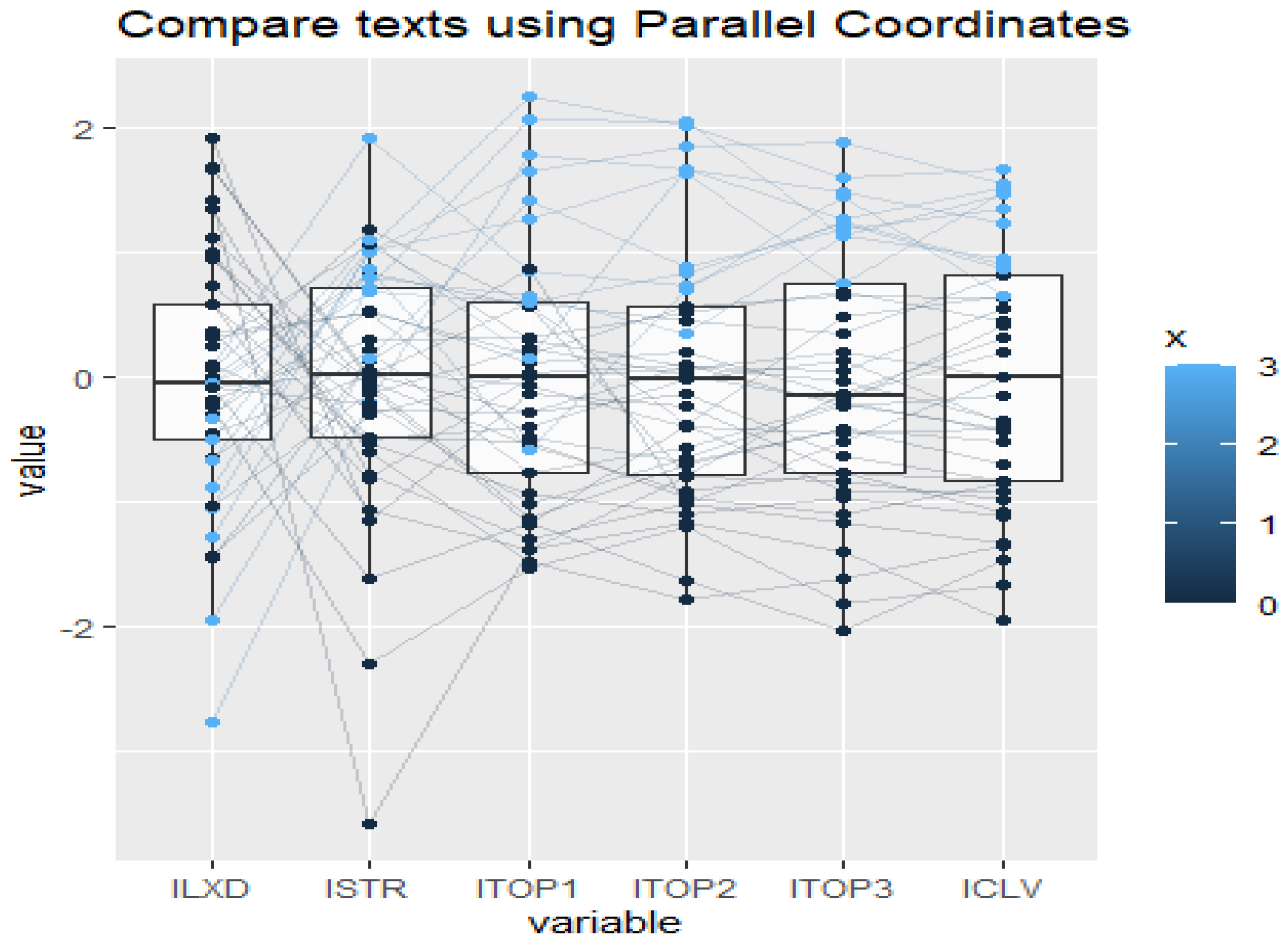
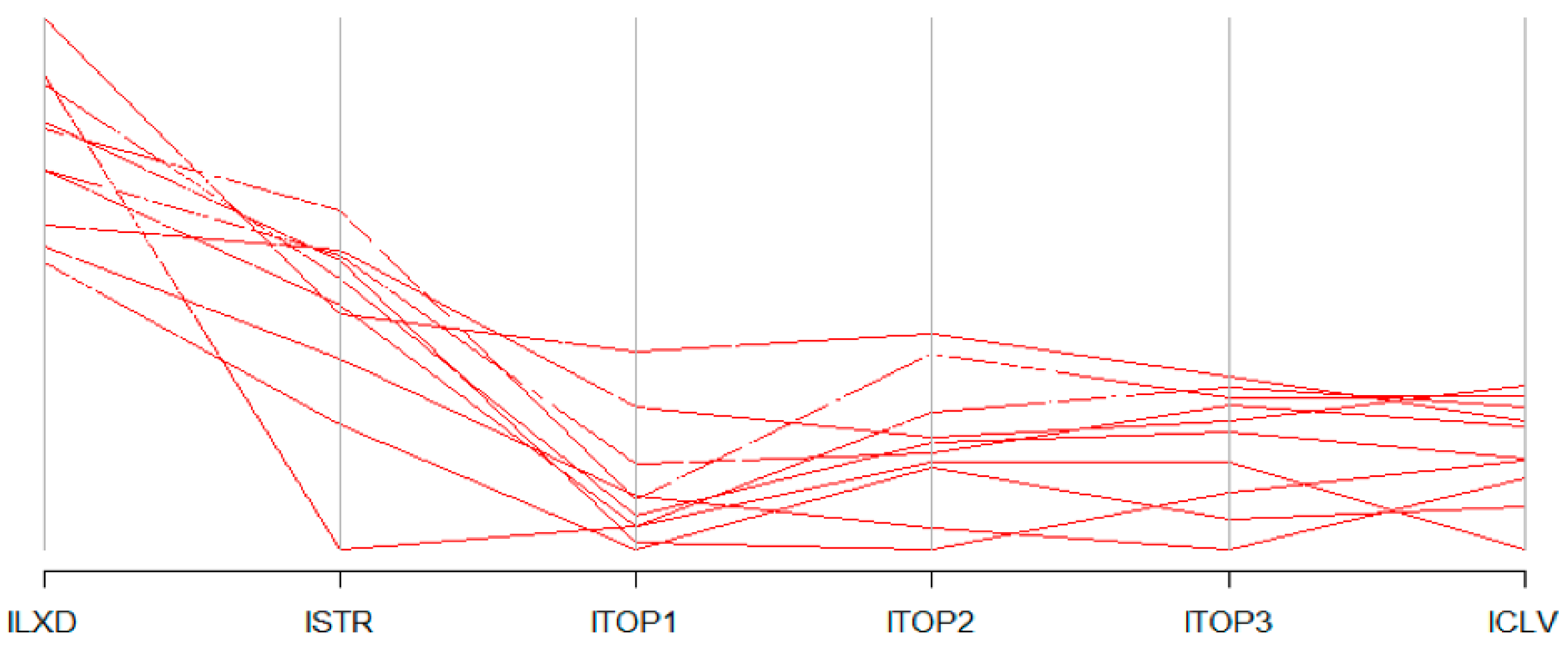
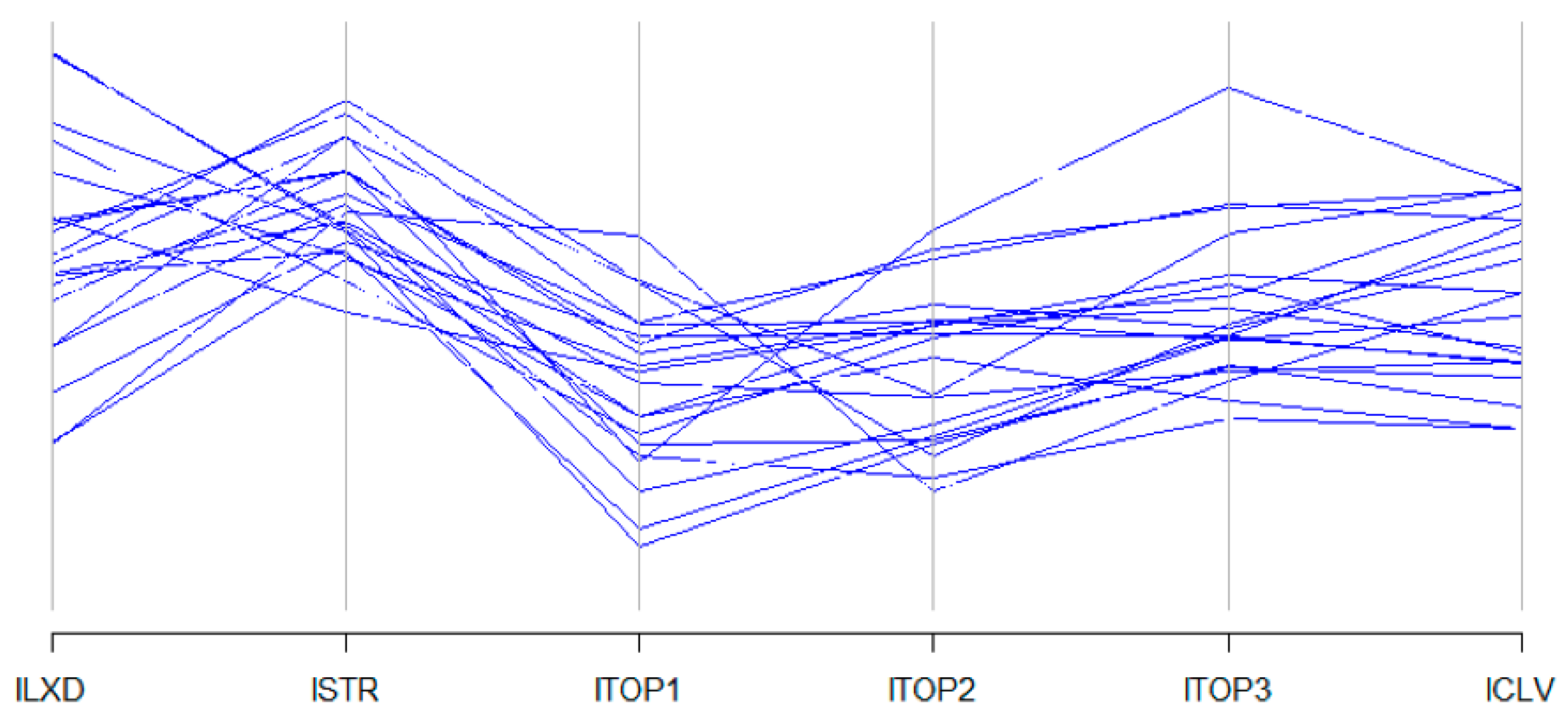
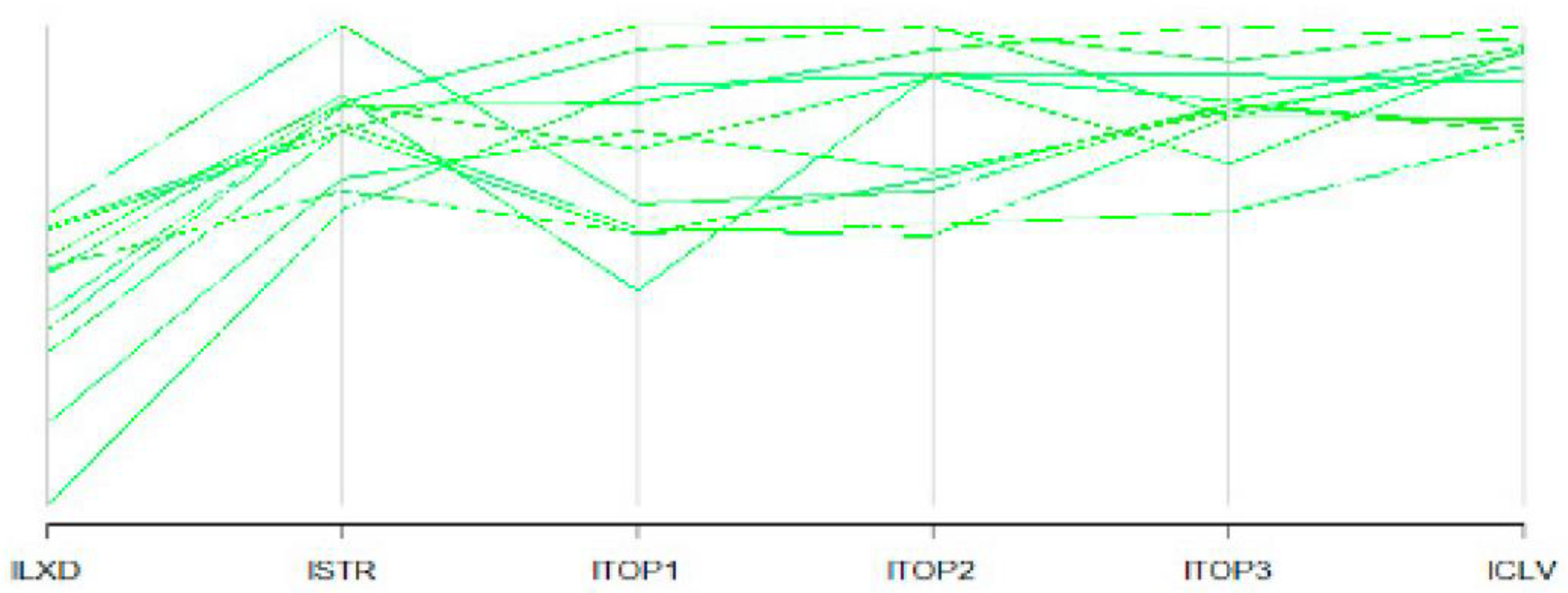
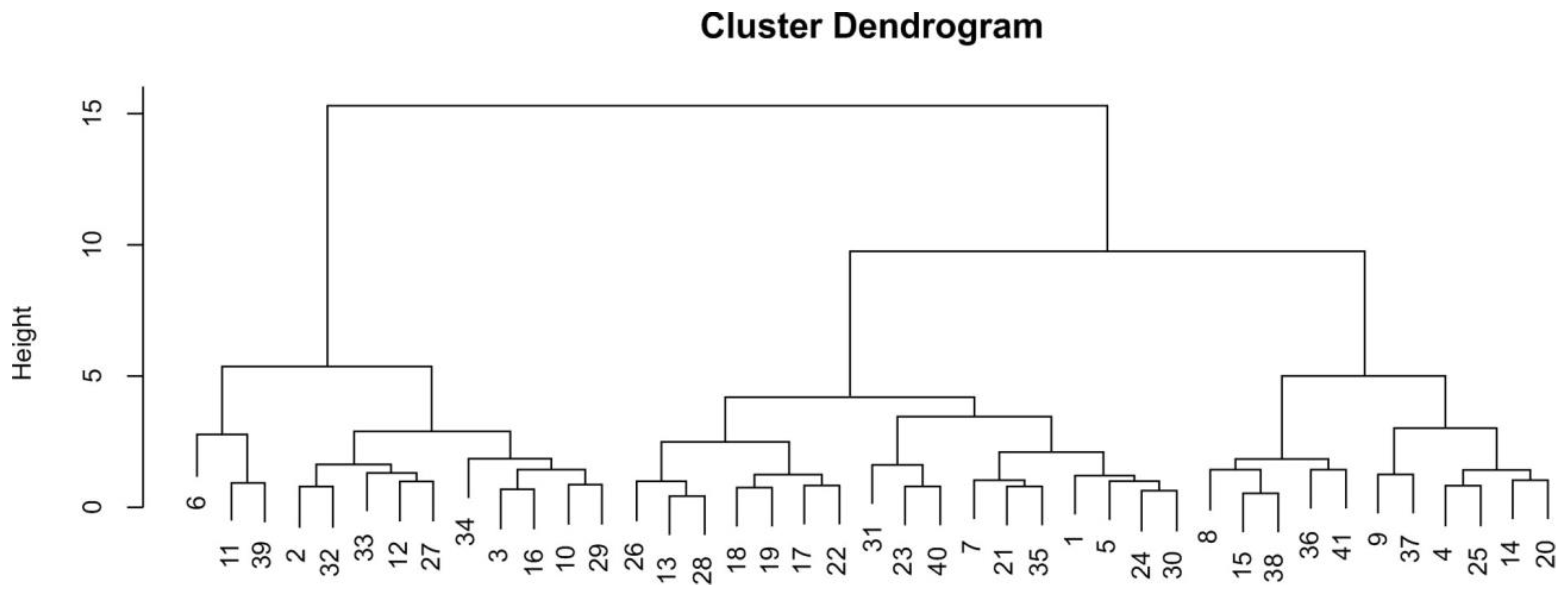
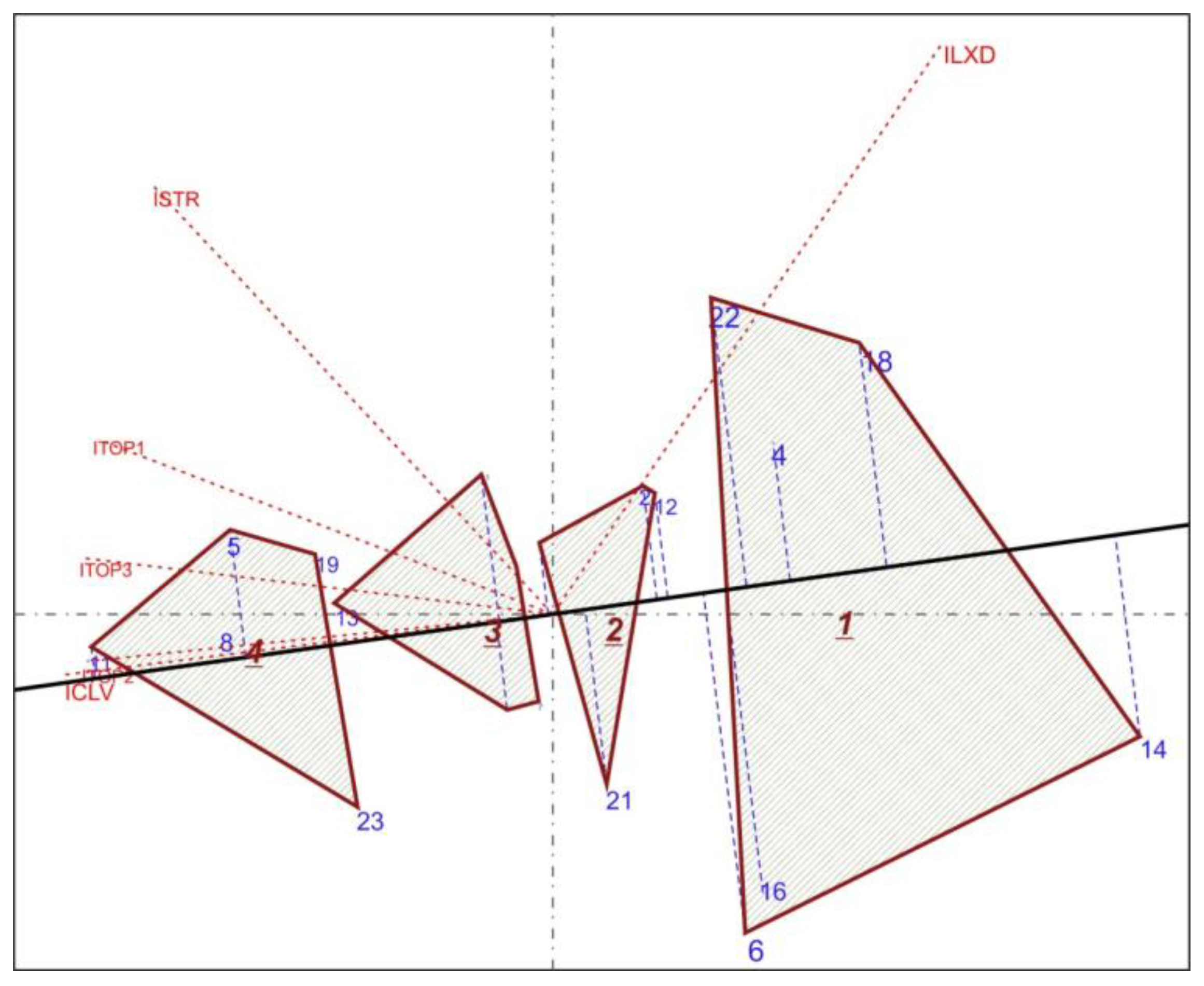
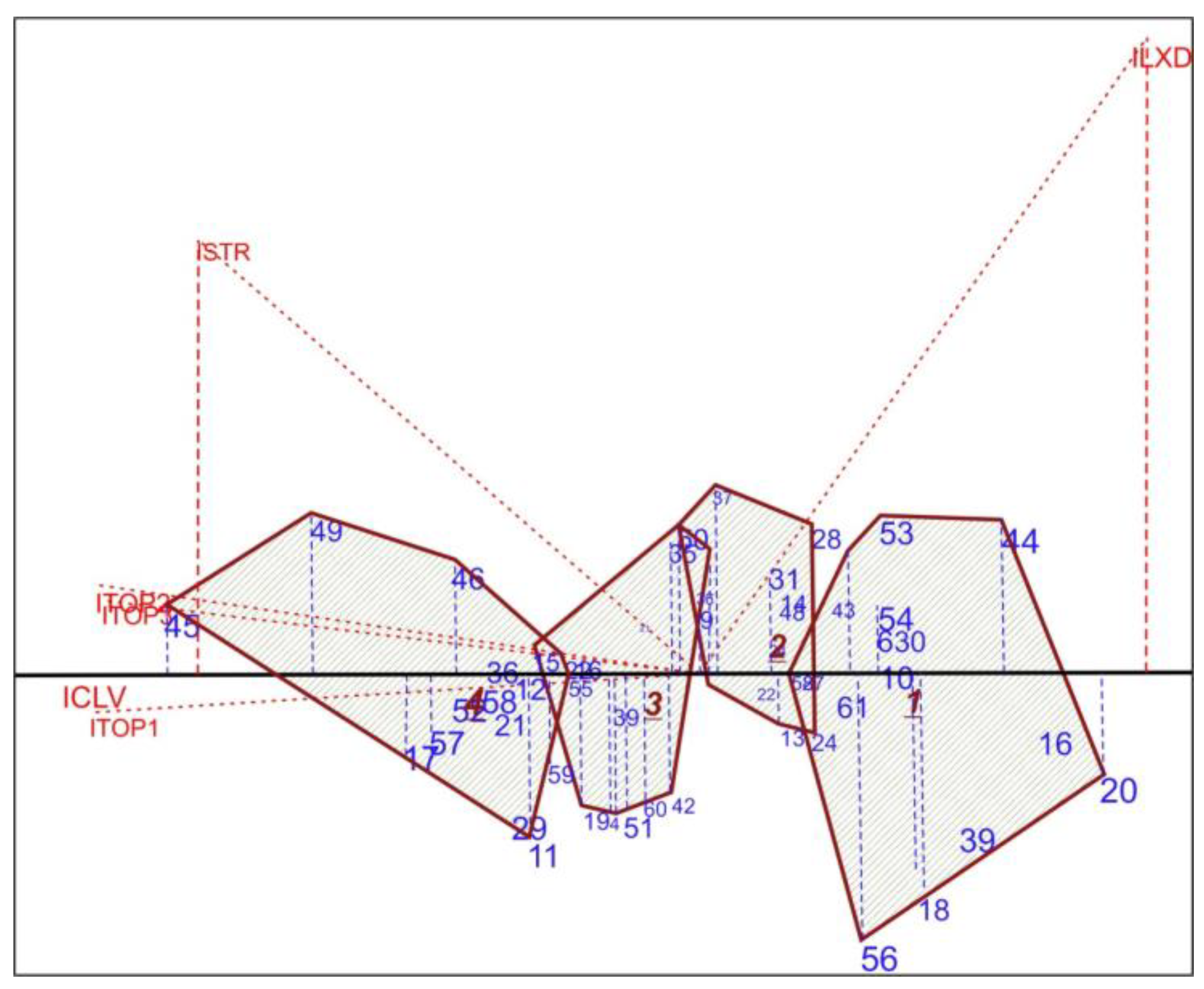
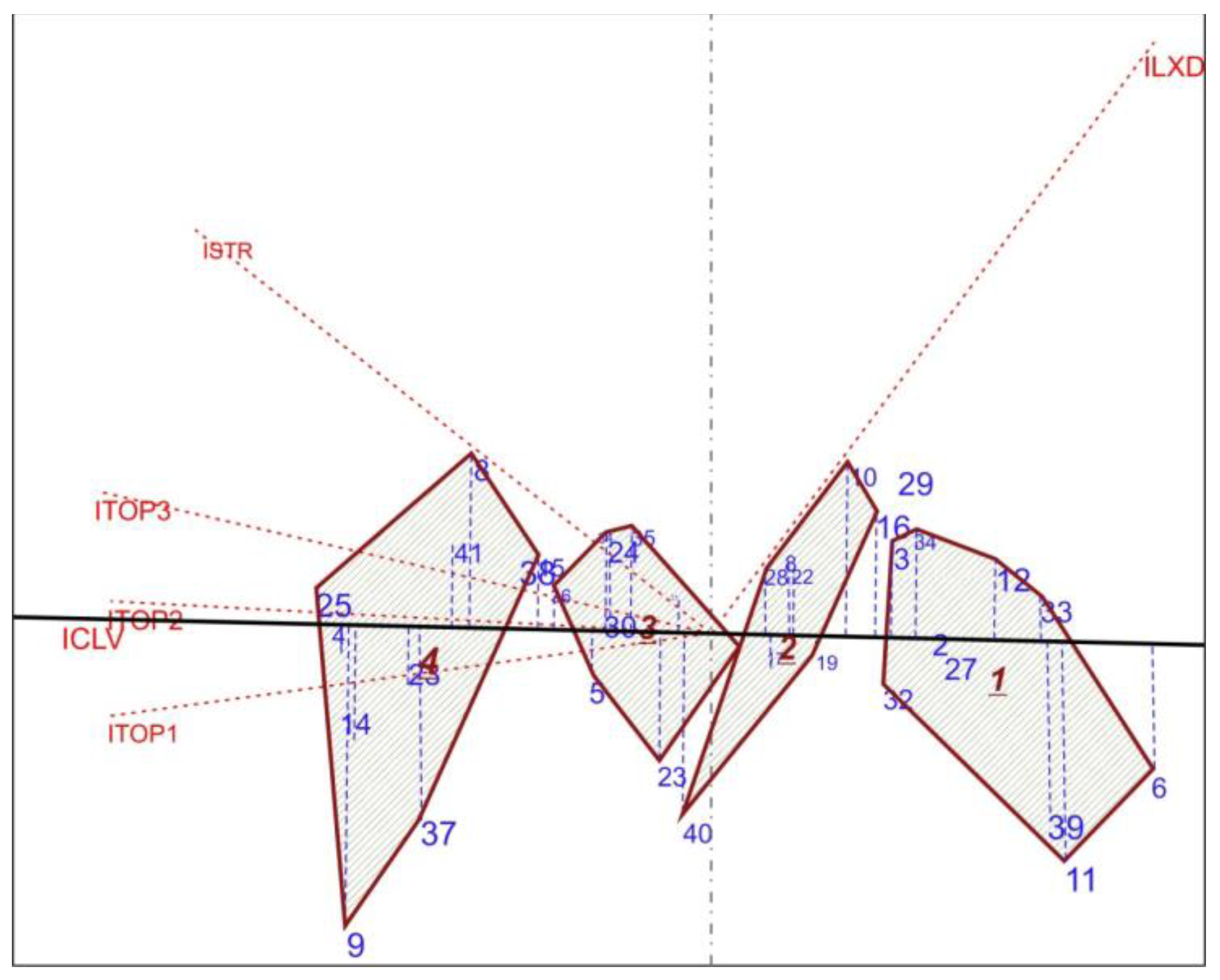
4.2. Text Comparisons Using Biplots
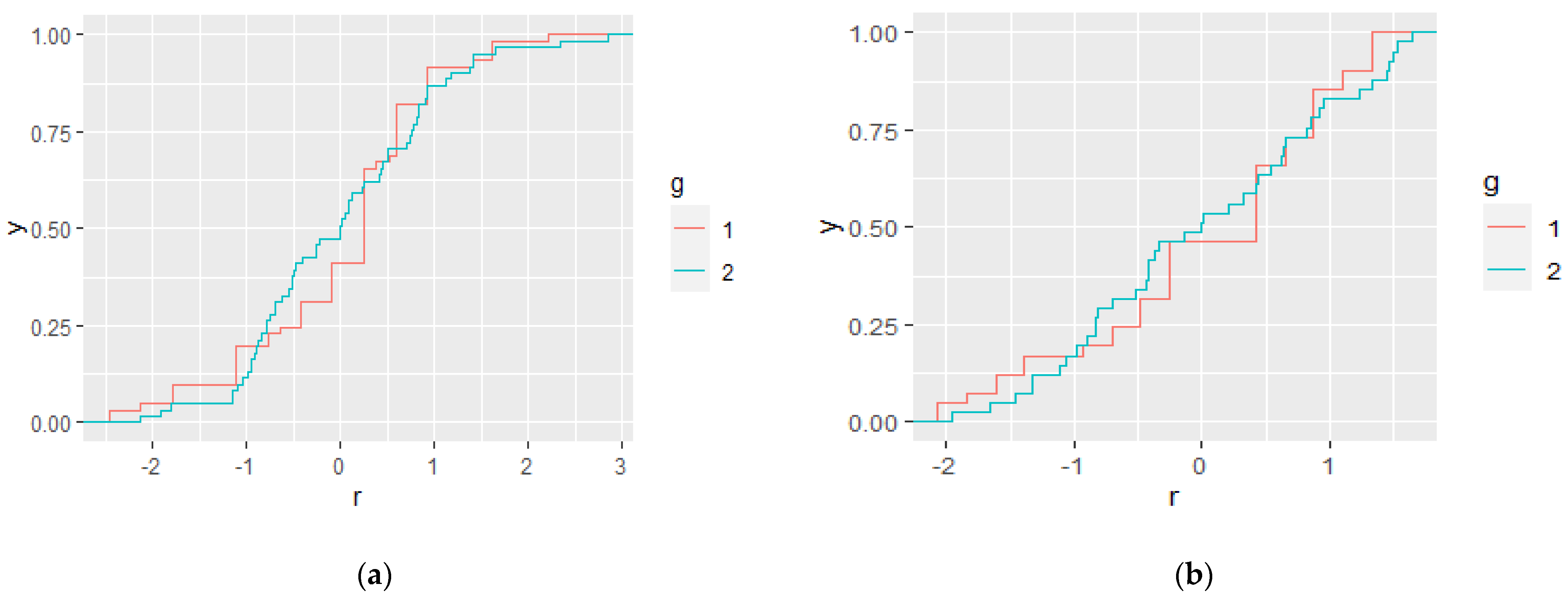
5. Reliability and Validity Issues
6. Discussion
7. Conclusions and the Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Livingston, S.A. Constructed-Response Test Questions: Why We Use Them; How We Score Them. RD Connect. 2009, 11. [Google Scholar]
- McClellan, C. Constructed-Response Scoring—Doing It Right. RD Connect. 2010, 13, 1–7. [Google Scholar]
- Li, H.; Cai, Z.; Graesser, A.C. Computerized summary scoring: Crowdsourcing-based latent semantic analysis. Behav. Res. Methods 2018, 50, 2144–2161. [Google Scholar] [CrossRef] [Green Version]
- Wiliam, D.; Lee, C.; Harrison, C.; Black, P. Teachers developing assessment for learning: Impact on student achievement. Assess. Educ. Princ. Policy Pract. 2004, 11, 49–65. [Google Scholar] [CrossRef]
- Feinerer, I.; Hornik, K.; Meyer, D. Text Mining Infrastructure in R. J. Stat. Softw. 2008, 25, 1–54. [Google Scholar] [CrossRef] [Green Version]
- Lebart, L.; Salem, A.; Berry, L. (Eds.) Exploring Textual Data; Springer: Heidelberg, The Netherlands, 1998; Volume 4. [Google Scholar] [CrossRef]
- Süzen, N.; Gorban, A.N.; Levesley, J.; Mirkes, E.M. Automatic short answer grading and feedback using text mining methods. Procedia Comput. Sci. 2020, 169, 726–743. [Google Scholar] [CrossRef]
- Landauer, T.K. Automatic Essay Assessment. Assess. Educ. Princ. Policy Pract. 2003, 10, 295–308. [Google Scholar] [CrossRef]
- Landauer, T.K.; Dumais, S.T. A solution to Plato’s problem: The latent semantic analysis theory of acquisition, induction, and representation of knowledge. Psychol. Rev. 1997, 104, 211–240. [Google Scholar] [CrossRef]
- Landauer, T.K.; Laham, D.; Rehder, B.; Schreiner, M.E. How Well Can Passage Meaning be Derived without Using Word Order? In A Comparison of Latent Semantic Analysis and Humans, Proceedings of the 19th Annual Conference of the Cognitive Science Society; Shafto, M.G., Langley, P., Eds.; Lawrence Erlbaum Associates: Mahwah, NJ, USA, 1997; pp. 412–417. Available online: http://lsa.colorado.edu/papers/cogsci97.pdf (accessed on 25 October 2022).
- Landauer, T.K.; McNamara, D.S.; Dennis, S.; Kintsch, W. (Eds.) Handbook of Latent Semantic Analysis; Psychology Press: Hove, UK, 2007. [Google Scholar] [CrossRef]
- Shermis, M.D.; Shneyderman, A.; Attali, Y. How important is content in the ratings of essay assessments? Assess. Educ. Princ. Policy Pract. 2008, 15, 91–105. [Google Scholar] [CrossRef]
- Ke, Z.; Ng, V. Automated Essay Scoring: A Survey of the State of the Art. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 6300–6308. [Google Scholar] [CrossRef]
- Perin, D.; Lauterbach, M. Assessing Text-Based Writing of Low-Skilled College Students. Int. J. Artif. Intell. Educ. 2018, 28, 56–78. [Google Scholar] [CrossRef]
- Page, E.B. The Imminence of Grading Essays by Computer. Phi Delta Kappan 1966, 47, 238–243. Available online: https://www.jstor.org/stable/20371545 (accessed on 25 October 2022).
- Page, E.B. Statistical and linguistic strategies in the computer grading of essays. In Proceedings of the 1967 Conference on Computational Linguistics, Stroudsburg, PA, USA, 23–25 August 1967; pp. 1–13. [Google Scholar] [CrossRef] [Green Version]
- Page, E.B. The Use of the Computer in Analyzing Student Essays. Int. Rev. Educ. 1968, 14, 210–225. Available online: https://www.jstor.org/stable/3442515 (accessed on 25 October 2022). [CrossRef]
- Page, E.B. Project Essay Grade: PEG. In Automated Essay Scoring: A Cross-disciplinary Perspective; Shermis, M.D., Burstein, J.C., Eds.; Lawrence Erlbaum Associates: Mahwah, NJ, USA, 2002; pp. 43–54. [Google Scholar]
- Page, E.B.; Poggio, J.P.; Keith, T.Z. Computer Analysis of Student Essays: Finding Trait Differences in Student Profile. In Proceedings of the Annual Meeting of the American Educational Research Association, Chicago, IL, USA, 21–26 April 2022. [Google Scholar]
- Deerwester, S.; Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by latent semantic analysis. J. Am. Soc. Inf. Sci. 1990, 41, 391–407. [Google Scholar] [CrossRef]
- Dikli, S. Automated Essay Scoring. Turk. Online J. Distance Educ. 2006, 7, 49–62. [Google Scholar]
- Bellegarda, J.R. Latent Semantic Mapping: Principles & Applications; Springer International Publishing: New York, NY, USA, 2007. [Google Scholar] [CrossRef]
- Pereira, L.A.P.d.M.A. Contribuição Para A Formulação De Uma Metodologia De Ensino E Avaliação Baseada na Análise Estatística de Textos em Português; Faculdade de Ciências Sociais e Humanas, Universidade Nova de Lisboa: Lisboa, Portugal, 2013; Available online: http://hdl.handle.net/10362/12100 (accessed on 25 October 2022).
- Kerkhof, R.G. Natural Language Processing for Scoring Open-Ended Questions: A Systematic Review. Available online: http://essay.utwente.nl/82090/ (accessed on 25 October 2022).
- Liu, S.; Zeng, S.; Li, S. Evaluating Text Coherence at Sentence and Paragraph Levels. arXiv 2020, arXiv:2006.03221. [Google Scholar]
- Pietsch, A.-S.; Lessmann, S. Topic modeling for analyzing open-ended survey responses. J. Bus. Anal. 2018, 1, 93–116. [Google Scholar] [CrossRef] [Green Version]
- Roberts, M.E.; Stewart, B.M.; Tingley, D.; Lucas, C.; Leder-Luis, J.; Gadarian, S.K.; Albertson, B.; Rand, D.G. Structural Topic Models for Open-Ended Survey Responses. Am. J. Political Sci. 2014, 58, 1064–1082. [Google Scholar] [CrossRef] [Green Version]
- Benoit, K.; Watanabe, K.; Wang, H.; Nulty, P.; Obeng, A.; Müller, S.; Matsuo, A. Quanteda: An R package for the quantitative analysis of textual data. J. Open Source Softw. 2018, 3, 774. [Google Scholar] [CrossRef] [Green Version]
- Burrows, S.; Gurevych, I.; Stein, B. The Eras and Trends of Automatic Short Answer Grading. Int. J. Artif. Intell. Educ. 2015, 25, 60–117. [Google Scholar] [CrossRef] [Green Version]
- Galhardi, L.B.; Brancher, J.D. Machine Learning Approach for Automatic Short Answer Grading: A Systematic Review; Springer: Berlin/Heidelberg, Germany, 2018; pp. 380–391. [Google Scholar] [CrossRef]
- Paalman, J.; Mullick, S.; Zervanou, K.; Zhang, Y. Term Based Semantic Clusters for Very Short Text Classification. In Proceedings of the Natural Language Processing in a Deep Learning World; 2019; pp. 878–887. [Google Scholar] [CrossRef]
- Poulimenou, S.; Stamou, S.; Papavlasopoulos, S.; Poulos, M. Short Text Coherence Hypothesis. J. Quant. Linguist. 2016, 23, 191–210. [Google Scholar] [CrossRef]
- Zhang, L.; Huang, Y.; Yang, X.; Yu, S.; Zhuang, F. An automatic short-answer grading model for semi-open-ended questions. Interact. Learn. Environ. 2019, 30, 177–190. [Google Scholar] [CrossRef]
- Williamson, D.M.; Xi, X.; Breyer, F.J. A Framework for Evaluation and Use of Automated Scoring. Educ. Meas. Issues Pract. 2012, 31, 2–13. [Google Scholar] [CrossRef]
- Feathers, T. Flawed Algorithms Are Grading Millions of Students’ Essays. Available online: https://www.vice.com/en/article/pa7dj9/flawed-algorithms-are-grading-millions-of-students-essays (accessed on 20 August 2019).
- Lott-Lavigna, R. A-Level Students to Receive Their Predicted Grades in Government U-Turn. Available online: https://www.vice.com/en/article/y3ze87/a-level-students-to-receive-their-predicted-grades-in-government-u-turn (accessed on 17 August 2020).
- Rico-Juan, J.R.; Gallego, A.-J.; Valero-Mas, J.J.; Calvo-Zaragoza, J. Statistical semi-supervised system for grading multiple peer-reviewed open-ended works. Comput. Educ. 2018, 126, 264–282. [Google Scholar] [CrossRef]
- Ahadi, A.; Singh, A.; Bower, M.; Garrett, M. Text Mining in Education—A Bibliometrics-Based Systematic Review. Educ. Sci. 2022, 12, 210. [Google Scholar] [CrossRef]
- Chang, J. Lda: Collapsed Gibbs Sampling Methods for Topic Models (1.4.2). CRAN Repository. 2015. Available online: https://cran.r-project.org/package=lda (accessed on 25 October 2022).
- Olson, G.A.; Faigley, L.; Chomsky, N. Language, Politics, and Composition: A Conversation with Noam Chomsky. J. Adv. Compos. 1991, 11, 1–35. Available online: https://www.jstor.org/stable/20865759 (accessed on 25 October 2022).
- Michalke, M. Korpus: Text Analysis With Emphasis on Pos Tagging, Readability And Lexical Diversity (0.13-8). Available online: https://cran.r-project.org/package=koRpus (accessed on 25 October 2022).
- Kearney, M.W.; Hvitfeldt, E. Textfeatures: Extracts Features from Text (0.3.3). Available online: https://cran.r-project.org/package=textfeatures (accessed on 25 October 2022).
- Sanchez, G. PLS Path Modeling with R. 2013. Available online: https://www.gastonsanchez.com/PLS_Path_Modeling_with_R.pdf (accessed on 25 October 2022).
- Sarstedt, M.; Hair, J.F.; Cheah, J.-H.; Becker, J.-M.; Ringle, C.M. How to Specify, Estimate, and Validate Higher-Order Constructs in PLS-SEM. Australas. Mark. J. 2019, 27, 197–211. [Google Scholar] [CrossRef]
- Schloerke, B.; Cook, D.; Larmarange, J.; Briatte, F.; Marbach, M.; Thoen, E.; Elberg, A.; Toomet, O.; Crowley, J.; Hofmann, H.; et al. GGally: Extension to “ggplot2” (2.0.0). Available online: https://cran.r-project.org/package=GGally (accessed on 25 October 2022).
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S; Springer: New York, NY, USA, 2002. [Google Scholar] [CrossRef]
- Wegman, E.J. Hyperdimensional Data Analysis Using Parallel Coordinates. J. Am. Stat. Assoc. 1990, 85, 664. [Google Scholar] [CrossRef]
- Wickham, H. Tidy Data. J. Stat. Softw. 2014, 59. Available online: http://www.jstatsoft.org/ (accessed on 25 October 2022). [CrossRef]
- Ripley, B. Tree: Classification and Regression Trees (1.0-40). 2019. Available online: https://cran.r-project.org/package=tree (accessed on 25 October 2022).
- Gabriel, K.R. The biplot graphic display of matrices with application to principal component analysis. Biometrika 1971, 58, 453–467. [Google Scholar] [CrossRef]
- Galindo-Villardón, M.P. Una alternativa de representación simultánea: HJ-Biplot. Qüestiió Quad. D’estadística I Investig. Oper. 1986, 10, 13–23. Available online: http://hdl.handle.net/2099/4523 (accessed on 25 October 2022).
- Monecke, A.; Leisch, F. Sempls: Structural Equation Modeling Using Partial Least Squares. J. Stat. Softw. 2012, 48, 1–32. [Google Scholar] [CrossRef] [Green Version]
- Vairinhos, V.M. Desarrollo de un Sistema de Minería de Datos Basado en los Métodos de Biplot. Ph.D. Tesis, Universidad de Salamanca, Salamanca, Spain, 2003. [Google Scholar]
- Grover, S.; Pea, R.; Cooper, S. Designing for deeper learning in a blended computer science course for middle school students. Comput. Sci. Educ. 2015, 25, 199–237. [Google Scholar] [CrossRef]
- Yeung, W.C. Embracing individual differences: Overview of classroom and curricular strategies with reference to the Hong Kong English language curriculum and assessment guide. Hong Kong Teach. Cent. J. 2018, 17, 125–144. [Google Scholar]
- Munroe, L. The open-ended approach framework. Eur. J. Educ. Res. 2015, 4, 97–104. [Google Scholar] [CrossRef]
- Hamit, O. A qualitative study of school climate according to teachers’ perceptions. Eurasian J. Educ. Res. 2018, 18, 81–98. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set Name | Corpus | Level | Use | Subject Matter | Context | Date |
|---|---|---|---|---|---|---|
| Data Set 1 | 61 texts | Sec (12th year) | Summative | Portuguese Literature | Official Examinations | 2008 |
| Data Set 2 | 24 texts | Sec (12th year) | Formative | Sociology | In the class | 2017 |
| Data Set 3 | 41 texts | University | Formative | Economy | In the class | 2020 |
| Feature | Frequency | Rank | Docfreq | |
|---|---|---|---|---|
| 1 | economy | 205 | 1 | 38 |
| 2 | is | 160 | 2 | 33 |
| 3 | definition | 129 | 3 | 27 |
| 4 | science | 108 | 4 | 37 |
| 5 | object | 74 | 5 | 30 |
| 6 | study | 71 | 6 | 32 |
| 7 | social | 60 | 7 | 27 |
| 8 | to be | 56 | 8 | 24 |
| 9 | human | 55 | 9 | 25 |
| 10 | production | 54 | 10 | 28 |
| Text | Types | Tokens | Sentences | |
|---|---|---|---|---|
| 6 | text6 | 51 | 72 | 1 |
| 11 | text11 | 54 | 77 | 2 |
| 27 | text27 | 68 | 105 | 5 |
| 39 | text39 | 70 | 110 | 4 |
| 33 | text33 | 84 | 129 | 5 |
| 12 | text12 | 85 | 134 | 4 |
| 23 | text23 | 87 | 173 | 7 |
| 9 | text9 | 89 | 222 | 5 |
| 26 | text26 | 98 | 167 | 3 |
| 40 | text40 | 100 | 199 | 8 |
| Measurement Model (Figure 2) | Data Set 1 | Data Set 2 | Data Set 3 | |
|---|---|---|---|---|
| TOP 1 ® | T1W1 | 0.911 | 0.928 | 0.855 |
| TOP 1 ® | T1W2 | 0.676 | ns (0.01) | 0.801 |
| TOP 1 ® | T1W3 | 0.571 | 0.779 | 0.729 |
| TOP 2 ® | T2W1 | 0.940 | 0.863 | 0.894 |
| TOP 2 ® | T2W2 | 0.922 | 0.912 | 0.820 |
| TOP 2 ® | T2W3 | 0.597 | ns (0.01) | 0.647 |
| TOP 3 ® | T3W1 | 0.924 | 0.949 | 0.885 |
| TOP 3 ® | T3W2 | 0.784 | 0.571 | 0.768 |
| TOP 3 ® | T3W3 | 0.642 | 0.685 | 0.582 |
| LXD ® | C | 0.995 | 0.995 | 0.998 |
| LXD ® | S | ns (0.01) | 0.875 | 0.967 |
| LXD ® | TTR | 0.972 | 0.958 | 0.972 |
| LXD ® | U | 0.915 | 0.932 | 0.978 |
| STR ® | ncaps | 0.86 | 0.856 | 0.840 |
| STR ® | ncomm | 0.832 | 0.854 | 0.851 |
| STR ® | ndig | 0.788 | 0.427 | ns (0.01) |
| STR ® | nperiod | 0.948 | 0.852 | 0.664 |
| STR ® | nprop | ns (0.01) | 0.380 | 0.548 |
| STR ® | nwords | 0.938 | 0.944 | 0.793 |
| CLV ® | C2 | ns (0.01) | −0.670 | −0.578 |
| CLV ® | C3 | 0.806 | 0.768 | 0.739 |
| CLV ® | C4 | 0.970 | 0.944 | 0.949 |
| CLV ® | C5 | 0.970 | 0.878 | 0.939 |
| CLV ® | C6 | 0.959 | 0.922 | 0.937 |
| Structural Model (Figure 2) | ||||
| TOP 1 ® | LXD | ns | −0.596 | −0.690 |
| TOP 2 ® | LXD | ns | ns | 0.059 |
| TOP 3 ® | LXD | ns | ns | Ns |
| TOP 1 ® | STR | ns | 0.276 | Ns |
| TOP 2 ® | STR | ns | ns | 0.355 |
| TOP 3 ® | STR | ns | 1.088 | Ns |
| TOP 1 ® | CLV | ns | 0.242 | 0.294 |
| TOP 2 ® | CLV | 0.493 | ns | 0.301 |
| TOP 3 ® | CLV | ns | 0.411 | 0.191 |
| LXD ® | CLV | −0.226 | −0.183 | −0.165 |
| STR ® | CLV | ns | 0.182 | 0.166 |
| Performance Measures (Figure 2) | Data Set 1 | Data Set 2 | Data Set 3 | |
|---|---|---|---|---|
| R2 | TOP 1 (3) | ¾¾ | ¾¾ | ¾¾ |
| TOP 2 (3) | ¾¾ | ¾¾ | ¾¾ | |
| TOP 3 (3) | ¾¾ | ¾¾ | ¾¾ | |
| LXD (4) | 0.51 | 0.41 | 1.43 | |
| STR (6) | 0.55 | 0.63 | 0.51 | |
| CLV (5) | 0.98 | 0.96 | 0.98 | |
| GOLDSTEIN | TOP 1 (3) | 0.77 | 0.76 | 0.84 |
| TOP 2 (3) | 0.87 | 0.76 | 0.83 | |
| TOP 3 (3) | 0.83 | 0.79 | 0.79 | |
| LXD (4) | 0.92 | 0.97 | 0.99 | |
| STR (6) | 0.91 | 0.88 | 0.84 | |
| CLV (5) | 0.89 | 0.86 | 0.86 | |
| COMMUNALITY | TOP 1 (3) | 0.54 | 0.54 | 0.63 |
| TOP 2 (3) | 0.70 | 0.56 | 0.63 | |
| TOP 3 (3) | 0.63 | 0.57 | 0.57 | |
| LXD (4) | 0.75 | 0.89 | 0.96 | |
| STR (6) | 0.66 | 0.57 | 0.96 | |
| CLV (5) | 0.75 | 0.68 | 0.71 | |
| REDUNDANCY | TOP 1 (3) | ¾¾ | ¾¾ | ¾¾ |
| TOP 2 (3) | ¾¾ | ¾¾ | ¾¾ | |
| TOP 3 (3) | ¾¾ | ¾¾ | ¾¾ | |
| LXD (4) | 0.38 | 0.41 | 0.41 | |
| STR (6) | 0.36 | 0.63 | 0.24 | |
| CLV (5) | 0.74 | 0.96 | 0.69 | |
| GOODNESS of FIT | AVG R2 | 0.68 | 0.67 | 0.64 |
| AVG COMM | 0.68 | 0.64 | 0.66 | |
| GOF | 0.68 | 0.65 | 0.65 |
| OFFICIAL | HIR | ICLV | ||
|---|---|---|---|---|
| OFFICIAL | Pearson Correlation | 1 | 0.462 ** | 0.345 ** |
| Sig. (2-tailed) | 0.000 | 0.007 | ||
| N | 61 | 61 | 61 | |
| HIR | Pearson Correlation | 1 | 0.433 ** | |
| Sig. (2-tailed) | 0.000 | |||
| N | 61 | 61 | ||
| ICLV | Pearson Correlation | 1 | ||
| Sig. (2-tailed) | ||||
| N | 61 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vairinhos, V.M.; Pereira, L.A.; Matos, F.; Nunes, H.; Patino, C.; Galindo-Villardón, P. Framework for Classroom Student Grading with Open-Ended Questions: A Text-Mining Approach. Mathematics 2022, 10, 4152. https://doi.org/10.3390/math10214152
Vairinhos VM, Pereira LA, Matos F, Nunes H, Patino C, Galindo-Villardón P. Framework for Classroom Student Grading with Open-Ended Questions: A Text-Mining Approach. Mathematics. 2022; 10(21):4152. https://doi.org/10.3390/math10214152
Chicago/Turabian StyleVairinhos, Valter Martins, Luís Agonia Pereira, Florinda Matos, Helena Nunes, Carmen Patino, and Purificación Galindo-Villardón. 2022. "Framework for Classroom Student Grading with Open-Ended Questions: A Text-Mining Approach" Mathematics 10, no. 21: 4152. https://doi.org/10.3390/math10214152
APA StyleVairinhos, V. M., Pereira, L. A., Matos, F., Nunes, H., Patino, C., & Galindo-Villardón, P. (2022). Framework for Classroom Student Grading with Open-Ended Questions: A Text-Mining Approach. Mathematics, 10(21), 4152. https://doi.org/10.3390/math10214152