
Detection and Prediction of Chipping in Wafer Grinding Based on Dicing Signal


Abstract
:1. Introduction
2. Related Work
2.1. Literature Review
2.2. Dimensionality Reduction
2.3. BLSTM Model
3. Method
3.1. Dimensionality Reduction of a Parameter Vector
3.2. Chipping Prediction Model
3.3. Implementation Procedure
- (1)
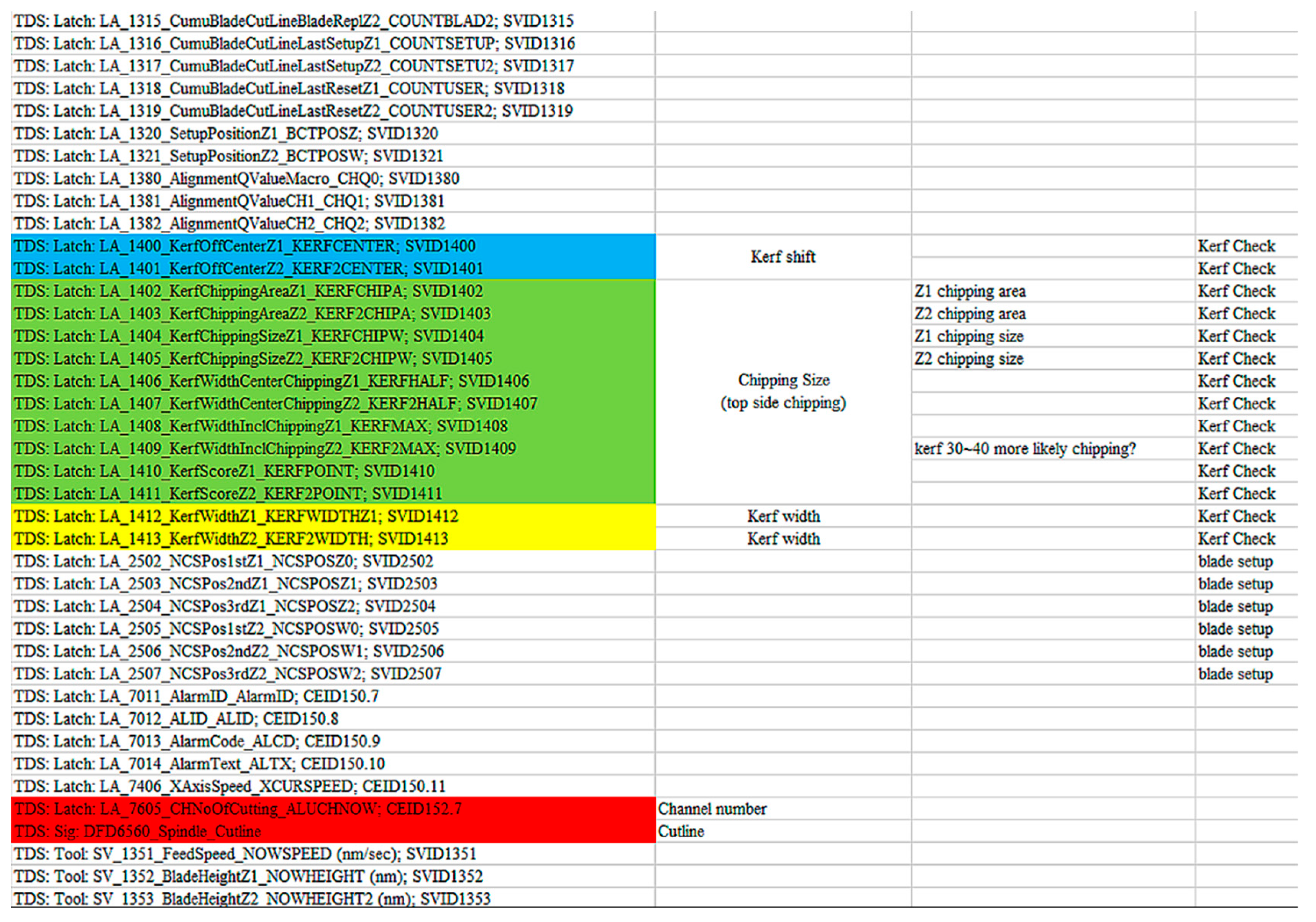
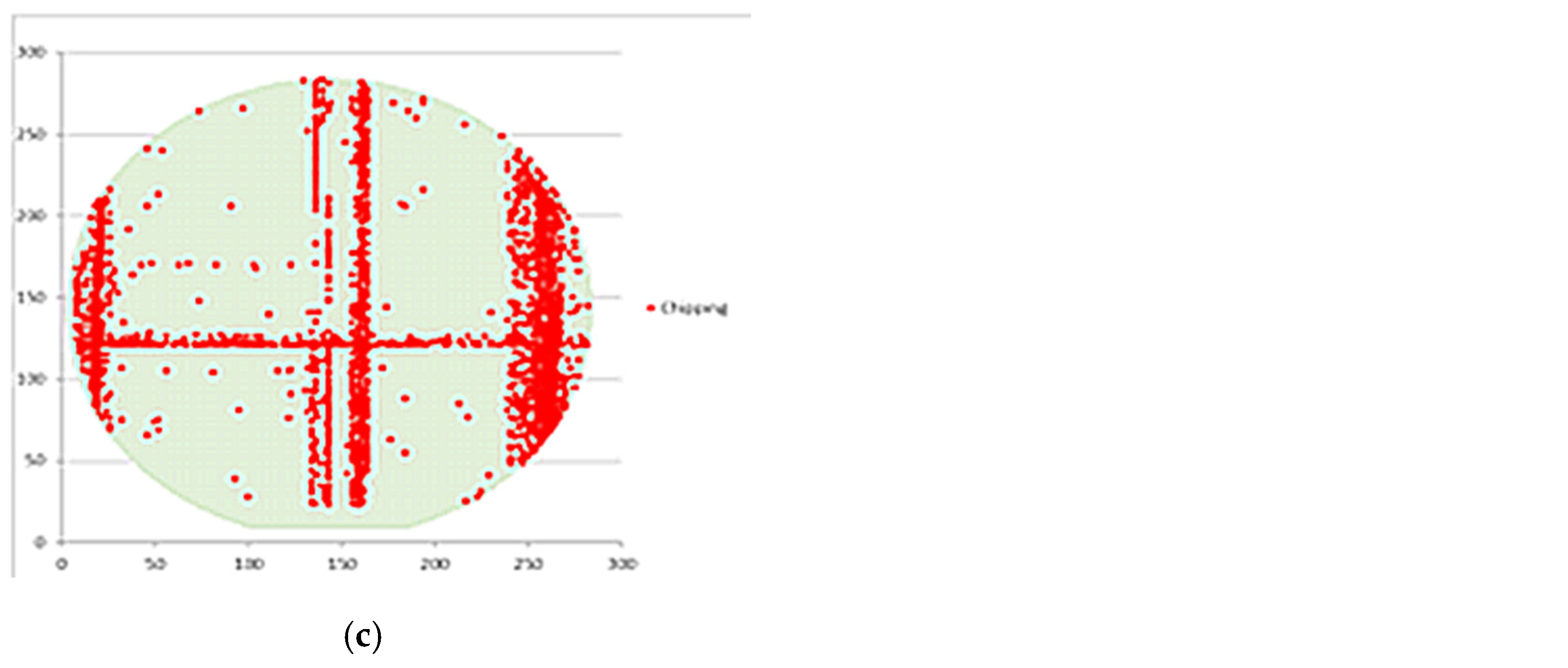
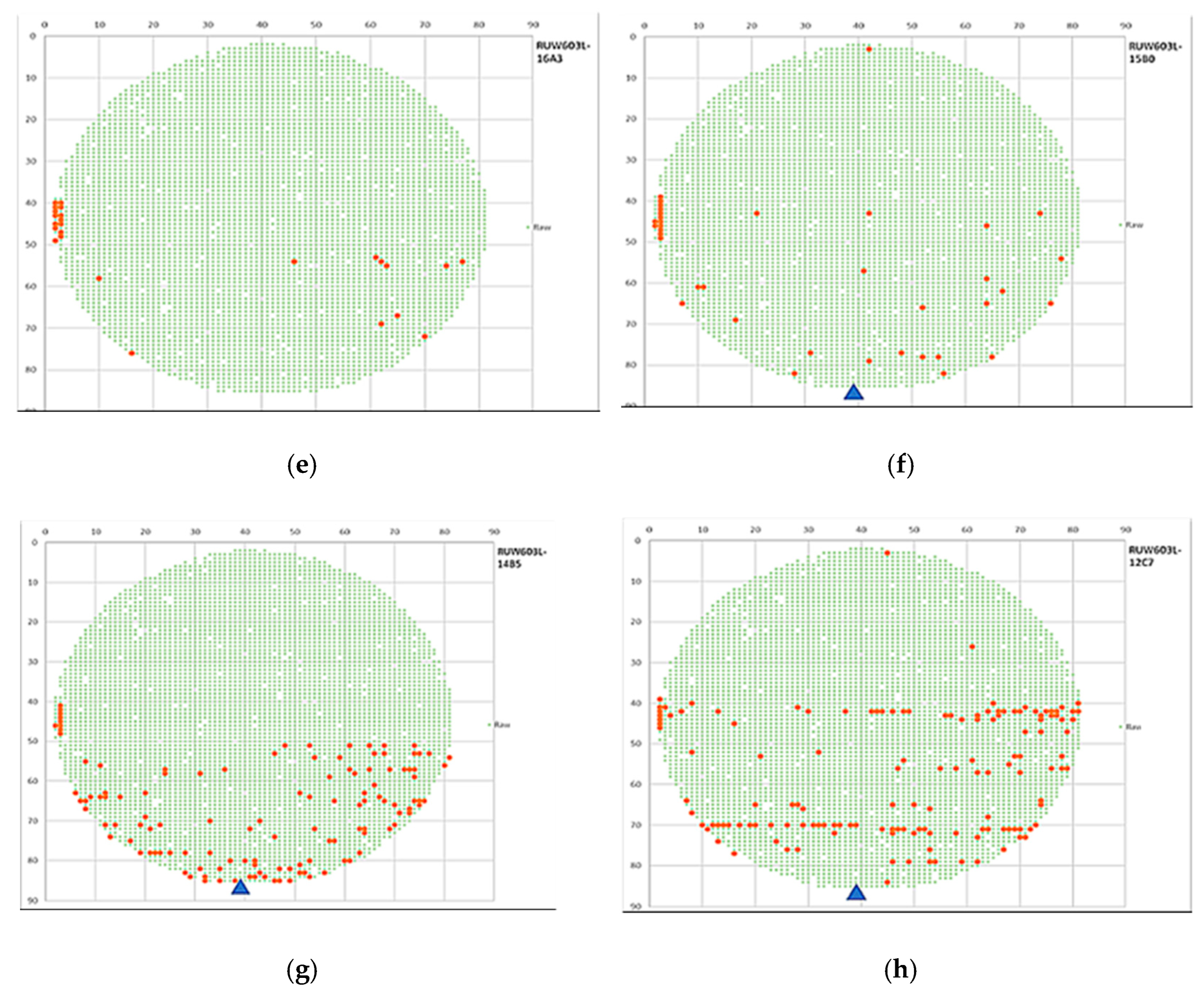
- We collect the wafer grinding-related data provided by a fab in Taiwan; the data table shows the coordinates of the chipping positions out of 112 different wafers. Each chipping position denotes a point marked by orange, as shown in Figure 8. In Figure 9, the coordinates of each cutting position with two color yellow backgrounds correspond to a specific blade number, cutline, and channel number.
- (2)
- We installed the Python programming execution environment of Anaconda3 on Windows 10. Moreover, installing relevant data analysis packages such as Pandas, Numpy, Scikit-learn, Tensorflow, and Keras is still necessary. In addition, Python programming requires setting up packages such as Matplotlib and Pyplot for drawing visual graphics.
- (3)
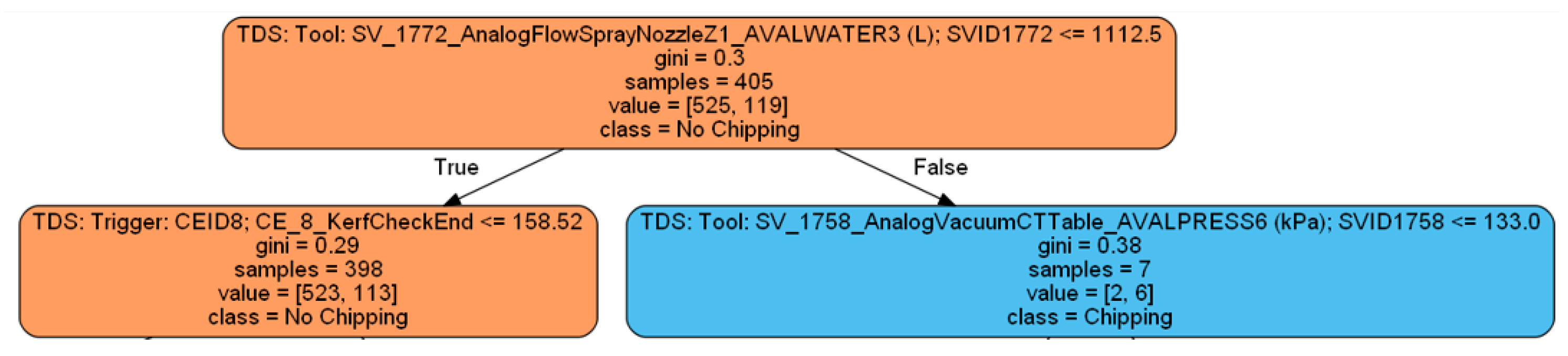
- We have checked the judgment conditions of each key parameter in different decision trees, as shown in Figure 12. According to the judgment conditions of each node in the decision tree, we can observe different parameter values, which are the normal and chipping situations. According to the parameter values within the judgment conditions, it is possible to know which key parameters will have a greater impact on the occurrence of wafer chipping. In Figure 12, we found that the parameter SVID_1772 of the node in the decision tree has eight data values greater than 1112.5, of which the machines judged six to be chipping situations. Therefore, the key grinding parameter SVID_1772 has an important influence on whether wafer chipping occurs. In random forest estimation, we can filter the ten key parameters extracted from the importance analysis to the eight most important parameters for the next step. These key parameters are SpindleCurrent_Z1, SpindleCurrent_Z2, SVID_1772, SVID_1773, SVID_1775, SVID_1752, SVID_1753, and SVID_1785. Among them, Information Gain can evaluate the chaos evaluation index of the decision tree in Equation (8), where p is the probability that the condition is true, and q is the probability that the condition is false. When Entropy in Equation (9) is 0, it means that the data types classified in this area of the data are all consistent.
- (4)
- Meanwhile, we use the decision tree presented in the previous step (3) to explore how every grinding parameter’s importance can affect the wafer grinding result and determine which ones are the key grinding parameters. After that, we conduct the correlation analysis on these parameters, as shown in Figure 13. We found that the spindle current of two blades will significantly impact the yield of wafer grinding and then continue to pick out the other eight key grinding parameters. The random forest method can estimate the possible chipping phenomenon caused by these ten key grinding parameters. We have imported these ten key grinding parameters into the random forest, and the pairings can achieve 87% accuracy when estimating wafer chipping coverage areas of less than 30% of the wafer surface area. This estimation accuracy is higher than the 78% accuracy using all grinding parameters.
- (5)
- First, this study used a time series analysis to check the data distribution relationship between the normal situation and the occurrence of chipping. This check goes through many wafers to examine whether normal behavior exists in the data distribution relationship where red dots represent the occurrence of wafer chipping, as shown in Figure 14. When examining the wafer grinding process, we found that the parameter SVID_1752 of the cleaning gas emission on the wafer may chip when its pressure is lower than 586. In addition, we also found that if the air pressure of the parameter SVID_1753 fluctuates too much, it is easy to cause this chipping phenomenon, as shown in Figure 15.
- (6)
- This study has tried three methods for correlation analysis: Pearson, Spearman, and Kendall tau. Technically speaking, we chose Kendall tau, which is more suitable for working on non-linear data distribution. It will make a comparison based on sorting the respective sequence sizes in the two parameters. First, it will make a comparison based on sorting the respective sequence sizes in the two parameters. Then, Equation (10) can compute the Kendall tau correlation, where represents the total number of concordant pairs and stands for the total number of discordant pairs. Finally, we can visualize the result of the correlation matrix among the various parameters, as shown in Figure 16. We found that the kerf width, kerf displacement, and the length of each blade between the two blades had a correlation between 0.45 and 0.74. According to the correlation between the parameters mentioned above, people can judge a considerable degree of mutual influence between the blades.
- (7)
- This study standardized eight key grinding parameters mentioned above for data preprocessing and then aggregated these key parameters into a high-dimensional parameter vector. Furthermore, dimensionality reduction can condense this parameter vector to a one-dimensional constant value as an index. Finally, we apply the heat map analysis to this index, explaining the trend in potential chipping. This study has introduced two vector dimensionality reduction methods, PCA and Barnes-Hut t-SNE, as shown in Figure 17 and Figure 18. In Figure 17 and Figure 18, the x-axis in (a) represents the current cutline map with starting cutline number 0. Since the leftmost part of the wafer map in (d) is drawn from coordinate 3, the x-axis of the wafer map in (d) corresponding to the cutline map in (a) is the cutline number + 3. The x-axis of the cutline map in (c) corresponding to the wafer map in (d) is 81, the cutline number. Compared with PCA, Barnes-Hut t-SNE is more pronounced concerning the degree of change in the value of dimensionality reduction. This discovery indicates that the Barnes-Hut t-SNE data changes are more sensitive than PCA when chipping occurs. Therefore, this study selected the Barnes-Hut t-SNE dimensionality reduction to better judge chipping occurrence than PCA.
- (8)
- To increase the amount of training data before training DD-BLSTM, we will partition the data set of wafer chipping area of less than 30% into four groups: 10%, 10~15%, 15~20%, and 20~30%, and then perform average pooling to smooth the four sampled data picked up from each group at the same corresponding sequence in order to obtain a new datum, increasing the amount of training data. The dimensionality-reduced data called index has been imported into the DD-BLSTM model to make an inference for predicting potential large-scale chipping, as shown in Figure 5. We can use it to check how effective the key grinding parameters are in predicting the occurrence of wafer chipping. In addition, we can also verify whether a decisive influence exists on the occurrence of wafer chipping. Figure 19 shows that the DD-BLSTM model with index inputs can get a loss (error) of 0.1126 during the training phase. After the test phase, we can use the trained model to predict the occurrence of wafer chipping in the other wafer grinding processes, as shown in Figure 20. In Figure 20, we found that in the early stage of the wafer grinding process, this study imported the index to the DD-BLSTM model, which can accurately predict the index that will happen shortly. In such a way, it is possible to determine whether chipping will occur soon. Therefore, we can use the predicted index to detect whether the wafer chipping has occurred or, based on the trend in the potential chipping, tell people that chipping may occur soon.
4. Experiment Results and Discussion
4.1. Experiment Setting
4.2. Experimental Design
4.2.1. Settings for Parameter Dimensionality Reduction
4.2.2. Settings for Chipping Prediction
4.3. Experimental Results
4.3.1. Chipping Prediction Accuracy
4.3.2. Wafer Grinding Results
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rosa-Zurera, M.; Jarabo-Amores, P.; Lopez-Ferreras, F.; Sanz-Gonzalez, J.L. Comparative analysis of importance sampling techniques to estimate error functions for training neural networks. In Proceedings of the IEEE/SP 13th Workshop on Statistical Signal Processing, Bordeaux, France, 17–20 July 2005; pp. 121–126. [Google Scholar] [CrossRef]
- Onda, H. Framework for wafer level control APC model. In Proceedings of the 2011 e-Manufacturing & Design Collaboration Symposium & International Symposium on Semiconductor Manufacturing (eMDC & ISSM), Hsinchu, Taiwan, 5–6 September 2011; pp. 1–10. Available online: http://resolver.scholarsportal.info/resolve/1523553x/v2011inone/1_ffwlcam.xml (accessed on 21 October 2022).
- Khokhar, M.S.; Cheng, K.; Ayoub, M.; Zakria; Eric, L.K. Multi-Dimension Projection for Non-Linear Data Via Spearman Correlation Analysis (MD-SCA). In Proceedings of the 2019 8th International Conference on Information and Communication Technologies (ICICT), Karachi, Pakistan, 16–17 November 2019; pp. 14–18. [Google Scholar] [CrossRef]
- Dong, Y.-Q. Value Ranges of Spearman’s Rho and Kendall’s Tau of a Class of Copulas. In Proceedings of the 2010 International Conference on Computational and Information Sciences, Chengdu, China, 17–19 December 2010; pp. 182–185. [Google Scholar] [CrossRef]
- Zhang, Z.; Yang, X. Constructing Copulas on the Parabolic Boundary of Kendall’s Tau-Spearman’s Rho Region. In Proceedings of the 2010 First ACIS International Symposium on Cryptography, and Network Security, Data Mining and Knowledge Discovery, E-Commerce and Its Applications, and Embedded Systems, Qinhuangdao, China, 23–24 October 2010; pp. 324–327. [Google Scholar] [CrossRef]
- Sangwan, A.; Zhu, W.; Ahmad, M.O. Design and Performance Analysis of Bayesian, Neyman–Pearson, and Competitive Neyman–Pearson Voice Activity Detectors. IEEE Trans. Signal Process. 2007, 55, 4341–4353. [Google Scholar] [CrossRef]
- Zhang, Q.T.; Song, S.H. Model Selection and Estimation for Lognormal Sums in Pearson’s Framework. In Proceedings of the 2006 IEEE 63rd Vehicular Technology Conference, Melbourne, VIC, Australia, 7–10 May 2006; pp. 2823–2827. [Google Scholar] [CrossRef]
- Jiao, Y.; Vert, J. The Kendall and Mallows Kernels for Permutations. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1755–1769. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Z.; Wang, H. Within Wafer & Wafer to Wafer Thickness Uniformity Controllable Study on ILD-CMP Via Polishing Pad’s Physical Property Analysis and Linear Interval Feedback APC’s Implementation. In Proceedings of the 2019 China Semiconductor Technology International Conference (CSTIC), Shanghai, China, 18–19 March 2019; pp. 1–3. [Google Scholar] [CrossRef]
- Gang, D.; He, Y.; Shao, X. Anomaly Detection and Analysis of FDC Data. In Proceedings of the 2021 5th IEEE Electron Devices Technology & Manufacturing Conference (EDTM), Chengdu, China, 8–11 April 2021; pp. 1–3. [Google Scholar] [CrossRef]
- Thiry, L.; Zhao, H.; Hassenforder, M. Categorical Models for BigData. In Proceedings of the 2018 IEEE International Congress on Big Data (BigData Congress), San Francisco, CA, USA, 2–7 July 2018; pp. 272–275. [Google Scholar] [CrossRef]
- Yamaki, S.; Seki, S.; Sugita, N.; Yoshizawa, M. Performance Evaluation of Cross Correlation Functions Based on Correlation Filters. In Proceedings of the 2021 20th International Symposium on Communications and Information Technologies (ISCIT), Tottori, Japan, 19–22 October 2021; pp. 145–149. [Google Scholar] [CrossRef]
- Garibo-Morante, A.A.; Tellez, F.O. Univariate and Multivariate Time Series Modeling using a Harmonic Decomposition Methodology. IEEE Lat. Am. Trans. 2022, 20, 372–378. [Google Scholar] [CrossRef]
- Kang, S.; Cho, S.; An, D.; Rim, J. Using Wafer Map Features to Better Predict Die-Level Failures in Final Test. IEEE Trans. Semicond. Manuf. 2015, 28, 431–437. [Google Scholar] [CrossRef]
- Schelthoff, K.; Jacobi, C.; Schlosser, E.; Plohmann, D.; Janus, M.; Furmans, K. Feature Selection for Waiting Time Predictions in Semiconductor Wafer Fabs. IEEE Trans. Semicond. Manuf. 2022, 35, 546–555. [Google Scholar] [CrossRef]
- Li, K.S.-M.; Jiang, X.-H.; Chen, L.L.-Y.; Wang, S.-Y.; Huang, A.Y.-A.; Chen, J.E.; Liang, H.S.; Hsu, C.-L. Wafer Defect Pattern Labeling and Recognition Using Semi-Supervised Learning. IEEE Trans. Semicond. Manuf. 2022, 35, 291–299. [Google Scholar] [CrossRef]
- Tsuda, T.; Inoue, S.; Kayahara, A.; Imai, S.-i.; Tanaka, T.; Sato, N.; Yasuda, S. Advanced Semiconductor Manufacturing Using Big Data. IEEE Trans. Semicond. Manuf. 2015, 28, 229–235. [Google Scholar] [CrossRef]
- Fan, S.-K.S.; Hsu, C.-Y.; Tsai, D.-M.; He, F.; Cheng, C.-C. Data-Driven Approach for Fault Detection and Diagnostic in Semiconductor Manufacturing. IEEE Trans. Autom. Sci. Eng. 2020, 17, 1925–1936. [Google Scholar] [CrossRef]
- Sunny, M.A.I.; Maswood, M.M.S.; Alharbi, A.G. Deep Learning-Based Stock Price Prediction Using LSTM and Bi-Directional LSTM Model. In Proceedings of the 2020 2nd Novel Intelligent and Leading Emerging Sciences Conference (NILES), Giza, Egypt, 24–26 October 2020; pp. 87–92. [Google Scholar] [CrossRef]
- Yang, S. Research on Network Behavior Anomaly Analysis Based on Bidirectional LSTM. In Proceedings of the 2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 March 2019; pp. 798–802. [Google Scholar] [CrossRef]
- Liu, D.; Wang, J.; Shang, S.; Han, P. MSDR: Multi-Step Dependency Relation Networks for Spatial-Temporal Forecasting. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022. [Google Scholar] [CrossRef]
- Ou, J.; Sun, J.; Zhu, Y.; Jin, H.; Zhang, F.; Huang, J.; Wang, X. STP-TrellisNets: Spatial-Temporal Parallel TrellisNets for Metro Station Passenger Flow Prediction. In Proceedings of the 29th ACM International Conference on Information and Knowledge Management, Virtual Event, 19–23 October 2020. [Google Scholar] [CrossRef]
- Deng, S.; Rangwala, H.; Ning, Y. Robust Event Forecasting with Spatiotemporal Confounder Learning. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022. [Google Scholar] [CrossRef]
- Yumeng, C.; Yinglan, F. Research on PCA Data Dimension Reduction Algorithm Based on Entropy Weight Method. In Proceedings of the 2020 2nd International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Taiyuan, China, 23–25 October 2020; pp. 392–396. [Google Scholar] [CrossRef]
- White, M.T.; Jeon, S. Using t-SNE to explore Misclassification. In Proceedings of the 2019 IEEE MIT Undergraduate Research Technology Conference (URTC), Cambridge, MA, USA, 11–13 October 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Meyer, B.H.; Pozo, A.T.R.; Zola, W.M.N. Improving Barnes-Hut t-SNE Scalability in GPU with Efficient Memory Access Strategies. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Xue, D.; Zhong, C.; Zhang, E.; Jiang, W.; Zhang, C. Die chipping FDC development at wafer saw process. In Proceedings of the 2021 22nd International Conference on Electronic Packaging Technology (ICEPT), Xiamen, China, 14–17 September 2021; pp. 1–2. [Google Scholar] [CrossRef]
- Zeng, Y.; Lou, Z. The New PCA for Dynamic and Non-Gaussian Processes. In Proceedings of the 2020 Chinese Automation Congress (CAC), Shanghai, China, 6–8 November 2020; pp. 935–938. [Google Scholar] [CrossRef]
- Xia, Z.; Chen, Y.; Xu, C. Multiview PCA: A Methodology of Feature Extraction and Dimension Reduction for High-Order Data. IEEE Trans. Cybern. 2022, 52, 11068–11080. [Google Scholar] [CrossRef] [PubMed]
- Liu, D.; Guo, T.; Chen, M. Fault Detection Based on Modified t-SNE. In Proceedings of the 2019 CAA Symposium on Fault Detection, Supervision and Safety for Technical Processes (SAFEPROCESS), Xiamen, China, 5–7 July 2019; pp. 269–273. [Google Scholar] [CrossRef]
- Chatzimparmpas, A.; Martins, R.M.; Kerren, A. t-viSNE: Interactive Assessment and Interpretation of t-SNE Projections. IEEE Trans. Vis. Comput. Graph. 2020, 26, 2696–2714. [Google Scholar] [CrossRef] [PubMed]
- Aparna, R.; Chitralekha, C.K.; Chaudhari, S. Comparative study of CNN, VGG16 with LSTM and VGG16 with Bidirectional LSTM using kitchen activity dataset. In Proceedings of the 2021 Fifth International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Palladam, India, 11–13 November 2021; pp. 836–843. [Google Scholar] [CrossRef]




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Specification | Unit | High Speed (Option) with 1.8 kW | ||
|---|---|---|---|---|
| Z1 | Z2 | |||
| Max. workpiece size | mm | Φ300 | ||
| X-axis | Cutting range | mm | 310 | |
| Cutting speed | mm/s | 0.1~1000 | ||
| Y1·Y2-axis | Cutting range | mm | 310 | |
| Index step | mm | 0.0001 | ||
| Positioning accuracy | mm | Within 0.002/310 (Single error) Within 0.002/5 | ||
| Z-axis | Max. stroke | mm | 14.2 (For Φ2 inch blade) | |
| Moving resolution | mm | 0.00005 | ||
| Repeatability accuracy | mm | 0.001 | ||
| θ-axis | Max. rotating angle | deg | 380 | |
| Spindle | Rated torque | N·m | 0.29 | 0.19 |
| Revolution speed range | min−1 | 6000~60,000 | 20,000~80,000 | |
| Machine dimensions (W × D × H) | mm | 1240 × 1550 × 1960 | 81 mm convex (left side) | |
| Machine weight | kg | Approx. 1640 | ||
| Software | Version |
|---|---|
| Anaconda® Individual Edition | 4.10.3 |
| Jupyter Notebook | 4.3.1 |
| Tensorflow | 2.6.2 |
| Keras | 2.6.0 |
| Pandas | 1.1.5 |
| Numpy | 1.19.5 |
| Matplotlib | 3.3.4 |
| Pyplot | 5.5.0 |
| Scikit-learn | 0.23.2 |
| Dimensionality Reduction | PCA | Barnes-Hut t-SNE | |
|---|---|---|---|
| Chipping Area of a Wafer | |||
| Class I: Less than 30% | 0.7612 | 0.9314 | |
| Class II: More than 30% | 0.5236 | 0.8412 | |
| Models | LSTM | AutoEncoder | BLSTM | DD-BLSTM | |
|---|---|---|---|---|---|
| Wafer Chipping Area | |||||
| Class I: Less than 30% | 0.8122 | 0.8611 | 0.9234 | 0.9314 | |
| Class II: More than 30% | 0.6413 | 0.5219 | 0.8216 | 0.8412 | |
| Model and Class | DD-BLSTM | ||
|---|---|---|---|
| Dimensionality | Class I | Class II | |
| 1-dimensional | 0.9314 | 0.8412 | |
| 2-dimensional | 0.9223 | 0.8212 | |
| 3-dimensional | 0.9121 | 0.8303 | |
| 4-dimensional | 0.9222 | 0.8083 | |
| 5-dimensional | 0.9313 | 0.8155 | |
| 6-dimensional | 0.8771 | 0.7798 | |
| 7-dimensional | 0.8511 | 0.7421 | |
| 8-dimensional | 0.8365 | 0.7254 | |
| Method | Original Approach | Proposed Approach | |
|---|---|---|---|
| Attribute | |||
| Number of grinding wafers needed to change kerf immediately | 3 | 8 | |
| Backside wall chipping distributed | Whole wafer | The bottom half of a wafer | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, B.R.; Tsai, H.-F.; Mo, H.-Y. Detection and Prediction of Chipping in Wafer Grinding Based on Dicing Signal. Mathematics 2022, 10, 4631. https://doi.org/10.3390/math10244631
Chang BR, Tsai H-F, Mo H-Y. Detection and Prediction of Chipping in Wafer Grinding Based on Dicing Signal. Mathematics. 2022; 10(24):4631. https://doi.org/10.3390/math10244631
Chicago/Turabian StyleChang, Bao Rong, Hsiu-Fen Tsai, and Hsiang-Yu Mo. 2022. "Detection and Prediction of Chipping in Wafer Grinding Based on Dicing Signal" Mathematics 10, no. 24: 4631. https://doi.org/10.3390/math10244631
APA StyleChang, B. R., Tsai, H. -F., & Mo, H. -Y. (2022). Detection and Prediction of Chipping in Wafer Grinding Based on Dicing Signal. Mathematics, 10(24), 4631. https://doi.org/10.3390/math10244631