

Dual-Word Embedding Model Considering Syntactic Information for Cross-Domain Sentiment Classification

Abstract
:1. Introduction
- A CDSC method is proposed using BERT and word2vec to obtain dual-word embeddings;
- Dual-channel feature extraction and adversarial training to obtain transferable semantic and syntactic information;
- Extensive experiments are conducted on two real-world datasets, and experimental results show that our model achieves better results compared to other strong baselines.
2. Related Work
2.1. CDSC
2.2. Graph Attention Work
2.3. Word Embedding
3. Methodology
3.1. Problem Definition
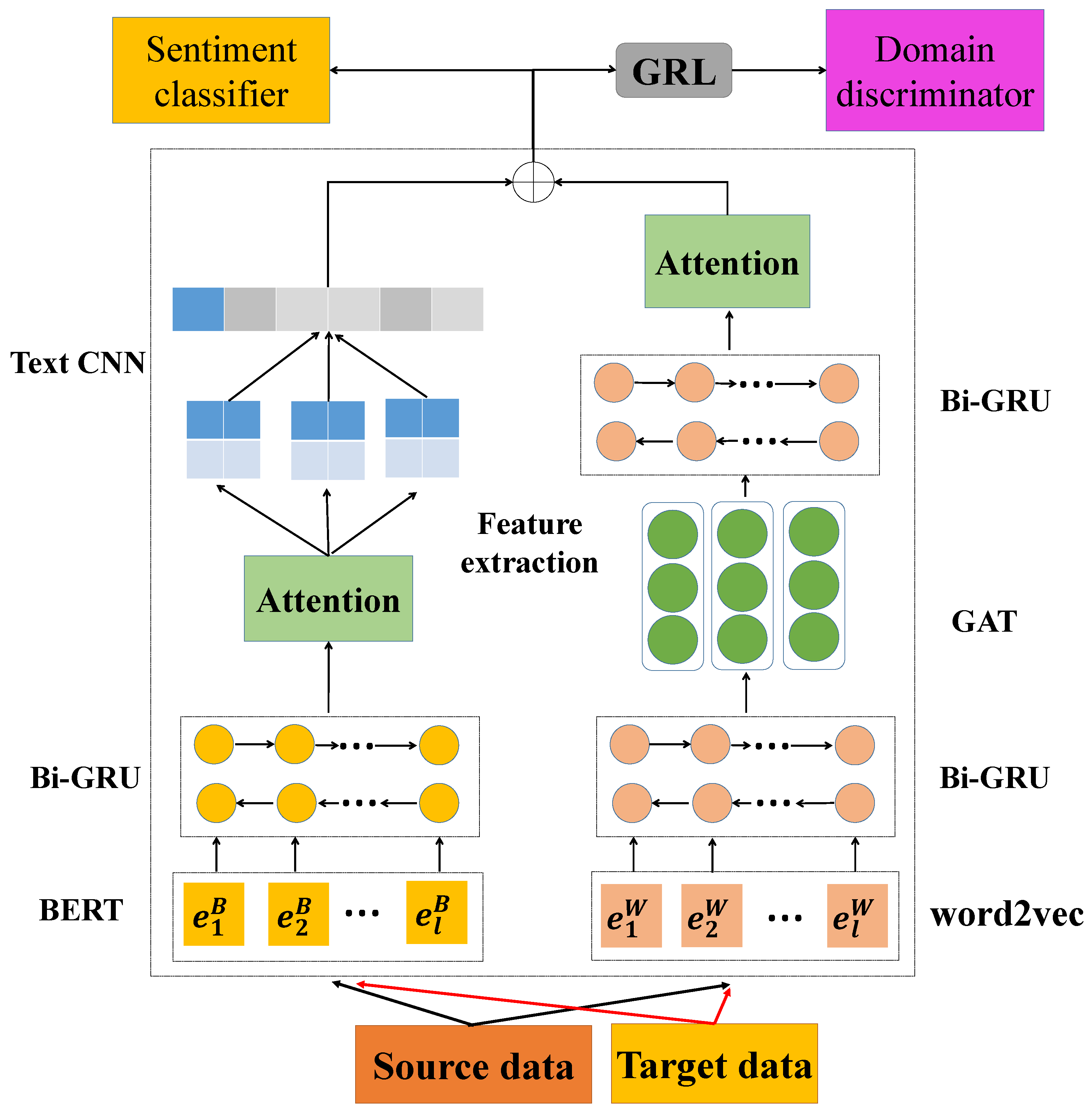
3.2. Model Structure
3.3. Feature Extraction
3.3.1. Bert Semantic Channel
3.3.2. Word2vec Syntax Channel
3.3.3. Final Document Representation
3.4. Sentiment Classifier
3.5. Domain Discriminator
3.6. Training Strategy
4. Experiment
4.1. Datasets
4.2. Experiment Setup
4.3. Experimental Results
- DANN [21]: The model is trained using the domain adversarial network approach, including GRL for domain obfuscation;
- AuxNN [41]: The model uses auxiliary tasks for CDSC;
- AMN [42]: The model is based on memory network and the adversarial training method to obtain domain-invariant features;
- DAS [40]: It uses feature adaptation and semi-supervised learning to improve classifiers while minimizing domain divergence;
- HATN [22]: The hierarchical attention network is used for CDSC, and pivots and non-pivots features are extracted to assist classification tasks;
- IATN [23]: Interactive attention mechanism is used to connect sentences with important aspects;
- WTN [25]: A Wasserstein-based transfer network is used to obtain domain-invariant features;
- PTASM [43]: The attention-sharing mechanism and parameter transferring method are used for CDSC;
- DWE w/o BERT: The BERT word embedding is removed from our proposed model;
- DWE w/o word2vec: The word2vec word embedding is removed from our proposed model.
4.4. Case Study
4.5. Visualization of Feature Representation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, B. Sentiment analysis and opinion mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–167. [Google Scholar]
- Tang, D.; Qin, B.; Liu, T. Document modeling with gated recurrent neural network for sentiment classification. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015. [Google Scholar]
- Gou, J.; He, X.; Lu, J.; Ma, H.; Ou, W.; Yuan, Y. A class-specific mean vector-based weighted competitive and collaborative representation method for classification. Neural Netw. 2022, 150, 12–27. [Google Scholar] [CrossRef] [PubMed]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004. [Google Scholar]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment classification using machine learning techniques. arXiv 2002, arXiv:cs/0205070. [Google Scholar]
- Gou, J.; Yuan, X.; Du, L.; Xia, S.; Yi, Z. Hierarchical Graph Augmented Deep Collaborative Dictionary Learning for Classification. IEEE Trans. Intell. Transp. Syst. 2022, 23, 25308–25322. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, K.; Zhang, M.; Zhao, H.; Liu, Q.; Wu, W.; Chen, E. Incorporating Dynamic Semantics into Pre-Trained Language Model for Aspect-based Sentiment Analysis. arXiv 2022, arXiv:2203.16369. [Google Scholar]
- Cambria, E.; Das, D.B.; Yopadhyay, S.; Feraco, A. Affective computing and sentiment analysis. In A Practical Guide to Sentiment Analysis; Springer: Cham, Switzerland, 2017; pp. 1–10. [Google Scholar]
- Wang, D.; Jing, B.; Lu, C.; Wu, J.; Liu, G.; Du, C.; Zhuang, F. Coarse alignment of topic and sentiment: A unified model for cross-lingual sentiment classification. IEEE Trans. Neural Networks Learn. Syst. 2020, 32, 736–747. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching word vectors with subword information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef] [Green Version]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Chi, E.A.; Hewitt, J.; Manning, C.D. Finding universal grammatical relations in multilingual BERT. arXiv 2020, arXiv:2005.04511. [Google Scholar]
- Guarasci, R.; Silvestri, S.; De Pietro, G.; Fujita, H.; Esposito, M. BERT syntactic transfer: A computational experiment on Italian, French and English languages. Comput. Speech Lang. 2022, 71, 101261. [Google Scholar] [CrossRef]
- Du, C.; Sun, H.; Wang, J.; Qi, Q.; Liao, J. Adversarial and domain-aware bert for cross-domain sentiment analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar]
- Huang, B.; Carley, K.M. Syntax-aware aspect level sentiment classification with graph attention networks. arXiv 2019, arXiv:1909.02606. [Google Scholar]
- Blitzer, J.; Dredze, M.; Pereira, F. Biographies, bollywood, boom-boxes and blenders: Domain adaptation for sentiment classification. In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, Prague, Czech Republic, 23–30 June 2007; pp. 440–447. [Google Scholar]
- Pan, S.J.; Ni, X.; Sun, J.-T.; Yang, Q.; Chen, Z. Cross-domain sentiment classification via spectral feature alignment. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 2096–2030. [Google Scholar]
- Zhang, K.; Zhang, H.; Liu, Q.; Zhao, H.; Zhu, H.; Chen, E. Hierarchical Attention Transfer Network for Cross-domain Sentiment Classification. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Zhang, K.; Zhang, H.; Liu, Q.; Zhao, H.; Zhu, H.; Chen, E. Interactive attention transfer network for cross-domain sentiment classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33. [Google Scholar]
- Yang, C.; Zhou, B.; Hu, X.; Chen, J.; Cai, Q.; Xue, Y. Dual-Channel Domain Adaptation Model. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, Melbourne, VIC, Australia, 14–17 December 2021. [Google Scholar]
- Du, Y.; He, M.; Wang, L.; Zhang, H. Wasserstein based transfer network for cross-domain sentiment classification. Knowl.-Based Syst. 2020, 204, 106162. [Google Scholar] [CrossRef]
- Fu, Y.; Liu, Y. Domain adaptation with a shrinkable discrepancy strategy for cross-domain sentiment classification. Neurocomputing 2022, 494, 56–66. [Google Scholar] [CrossRef]
- Wu, M.; Pan, S.; Zhu, X.; Zhou, C.; Pan, L. Domain-adversarial graph neural networks for text classification. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019. [Google Scholar]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Zhang, C. Graph wavenet for deep spatial-temporal graph modeling. arXiv 2019, arXiv:1906.00121. [Google Scholar]
- Zhu, S.; Zhou, C.; Pan, S.; Zhu, X.; Wang, B. Relation structure-aware heterogeneous graph neural network. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019. [Google Scholar]
- Zhu, S.; Zhou, L.; Pan, S.; Zhou, C.; Yan, G.; Wang, B. GSSNN: Graph smoothing splines neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Vashishth, S.; Dasgupta, S.S.; Ray, S.N.; Talukdar, P. Dating documents using graph convolution networks. arXiv 2019, arXiv:1902.00175. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Zhou, M.; Liu, D.; Zheng, Y.; Zhu, Q.; Guo, P. A text sentiment classification model using double word embedding methods. Multimed. Tools Appl. 2020, 81, 18993–19012. [Google Scholar] [CrossRef]
- Vuong Nguyen, L.; Nguyen, T.H.; Jung, J.J.; Camacho, D. Extending collaborative filtering recommendation using word embedding: A hybrid approach. Concurr. Comput. Pract. Exp. 2021, e6232. [Google Scholar] [CrossRef]
- Wang, H.; Zuo, Y.; Li, H.; Wu, J. Cross-domain recommendation with user personality. Knowl.-Based Syst. 2021, 213, 106664. [Google Scholar] [CrossRef]
- Naderalvojoud, B.; Sezer, E.A. Sentiment aware word embeddings using refinement and senti-contextualized learning approach. Neurocomputing 2020, 405, 149–160. [Google Scholar] [CrossRef]
- Jawahar, G.; Sagot, B.; Seddah, D. What does BERT learn about the structure of language? In Proceedings of the ACL 2019-57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Chen, Y. Convolutional Neural Network for Sentence Classification. Master’s Thesis, University of Waterloo, Waterloo, ON, Canada, 2015. [Google Scholar]
- He, R.; Lee, W.S.; Ng, H.T.; Dahlmeier, D. Adaptive semi-supervised learning for cross-domain sentiment classification. arXiv 2018, arXiv:1809.00530. [Google Scholar]
- Yu, J.; Jiang, J. Learning sentence embeddings with auxiliary tasks for cross-domain sentiment classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016. [Google Scholar]
- Li, Z.; Zhang, Y.; Wei, Y.; Wu, Y.; Yang, Q. End-to-End Adversarial Memory Network for Cross-domain Sentiment Classification. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17), Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Zhao, C.; Wang, S.; Li, D.; Liu, X.; Yang, X.; Liu, J. Cross-domain sentiment classification via parameter transferring and attention sharing mechanism. Inf. Sci. 2021, 578, 281–296. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Domain | Positive | Negative | Vocabulary |
|---|---|---|---|
| Books | 1000 | 1000 | 26,278 |
| DVD | 1000 | 1000 | 26,940 |
| Electronics | 1000 | 1000 | 13,256 |
| Kitchen | 1000 | 1000 | 11,187 |
| Domain | Positive | Negative | Neutral | |
|---|---|---|---|---|
| Book | Set1 | 2000 | 2000 | 2000 |
| Set2 | 4824 | 513 | 663 | |
| Beauty | Set1 | 2000 | 2000 | 2000 |
| Set2 | 4709 | 616 | 675 | |
| Music | Set1 | 2000 | 2000 | 2000 |
| Set2 | 4441 | 785 | 774 | |
| Electronics | Set1 | 2000 | 2000 | 2000 |
| Set2 | 4817 | 694 | 489 |
| S → T | DANN | AMN | DAS | HATN | IATN | WTN | PTASM | DWE |
|---|---|---|---|---|---|---|---|---|
| B → D | 0.8330 | 0.8450 | 0.8390 | 0.8590 | 0.8680 | 0.9090 | 0.9012 | 0.9150 |
| B → K | 0.7920 | 0.8090 | 0.8220 | 0.8470 | 0.8590 | 0.8840 | 0.9060 | 0.9100 |
| B → E | 0.7730 | 0.8030 | 0.8120 | 0.8490 | 0.8650 | 0.8960 | 0.9010 | 0.9075 |
| D → B | 0.8050 | 0.8360 | 0.8190 | 0.8600 | 0.8700 | 0.9080 | 0.8990 | 0.9125 |
| D → E | 0.7980 | 0.8050 | 0.8160 | 0.8510 | 0.8690 | 0.9150 | 0.9110 | 0.9150 |
| D → K | 0.8080 | 0.8160 | 0.8140 | 0.8580 | 0.8580 | 0.8910 | 0.9080 | 0.9100 |
| K → B | 0.7490 | 0.8010 | 0.8020 | 0.8260 | 0.8470 | 0.9160 | 0.9210 | 0.9250 |
| K → E | 0.8320 | 0.8540 | 0.8590 | 0.8640 | 0.8760 | 0.9190 | 0.9190 | 0.9200 |
| K → D | 0.7680 | 0.8120 | 0.8150 | 0.8400 | 0.8440 | 0.8890 | 0.9140 | 0.9150 |
| E → K | 0.8380 | 0.8580 | 0.8490 | 0.8760 | 0.8870 | 0.9320 | 0.9170 | 0.9300 |
| E → B | 0.7350 | 0.7740 | 0.7970 | 0.8060 | 0.8180 | 0.9010 | 0.9140 | 0.9175 |
| E → D | 0.7790 | 0.8170 | 0.8020 | 0.8380 | 0.8410 | 0.8920 | 0.9070 | 0.9075 |
| Average | 0.7930 | 0.8190 | 0.8210 | 0.8480 | 0.8590 | 0.9040 | 0.9110 | 0.9154 |
| S → T | AuxNN | DAS | WTN | DWE w/o BERT | DWE w/o word2vec | DWE |
|---|---|---|---|---|---|---|
| BK → BT | 0.478 | 0.547 | 0.576 | 0.5160 | 0.558 | 0.588 |
| BK → E | 0.482 | 0.539 | 0.579 | 0.504 | 0.559 | 0.587 |
| BK → M | 0.488 | 0.535 | 0.582 | 0.551 | 0.587 | 0.603 |
| BT → BK | 0.585 | 0.633 | 0.640 | 0.550 | 0.643 | 0.655 |
| BT → E | 0.591 | 0.598 | 0.631 | 0.571 | 0.650 | 0.654 |
| BT → M | 0.536 | 0.560 | 0.576 | 0.534 | 0.600 | 0.615 |
| M → BK | 0.582 | 0.608 | 0.623 | 0.591 | 0.686 | 0.692 |
| M → BT | 0.469 | 0.497 | 0.545 | 0.499 | 0.588 | 0.595 |
| M → E | 0.494 | 0.529 | 0.545 | 0.485 | 0.583 | 0.603 |
| E → BK | 0.577 | 0.552 | 0.588 | 0.570 | 0.579 | 0.646 |
| E → BT | 0.544 | 0.560 | 0.590 | 0.544 | 0.644 | 0.654 |
| E → M | 0.523 | 0.554 | 0.561 | 0.505 | 0.577 | 0.592 |
| Average | 0.529 | 0.559 | 0.586 | 0.535 | 0.605 | 0.624 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, Z.; Hu, X.; Xue, Y. Dual-Word Embedding Model Considering Syntactic Information for Cross-Domain Sentiment Classification. Mathematics 2022, 10, 4704. https://doi.org/10.3390/math10244704
Lu Z, Hu X, Xue Y. Dual-Word Embedding Model Considering Syntactic Information for Cross-Domain Sentiment Classification. Mathematics. 2022; 10(24):4704. https://doi.org/10.3390/math10244704
Chicago/Turabian StyleLu, Zihao, Xiaohui Hu, and Yun Xue. 2022. "Dual-Word Embedding Model Considering Syntactic Information for Cross-Domain Sentiment Classification" Mathematics 10, no. 24: 4704. https://doi.org/10.3390/math10244704
APA StyleLu, Z., Hu, X., & Xue, Y. (2022). Dual-Word Embedding Model Considering Syntactic Information for Cross-Domain Sentiment Classification. Mathematics, 10(24), 4704. https://doi.org/10.3390/math10244704