
Group Testing with Consideration of the Dilution Effect




Abstract
:1. Introduction
2. Materials and Methods
2.1. Dilution Effect Modeling
RT-PCR
2.2. Distribution among Infections
2.2.1. Estimation of the False Negative Rate
- , where
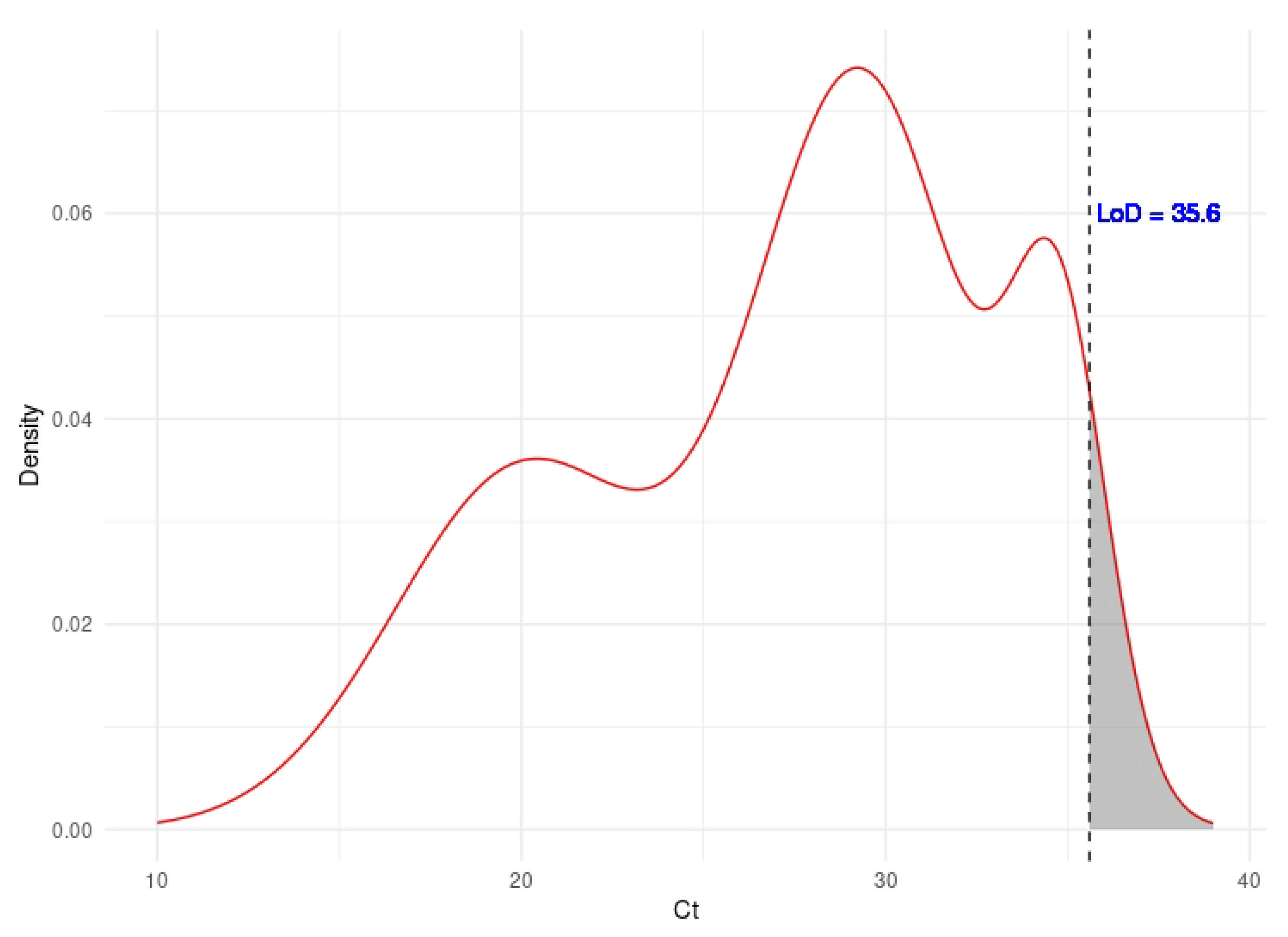
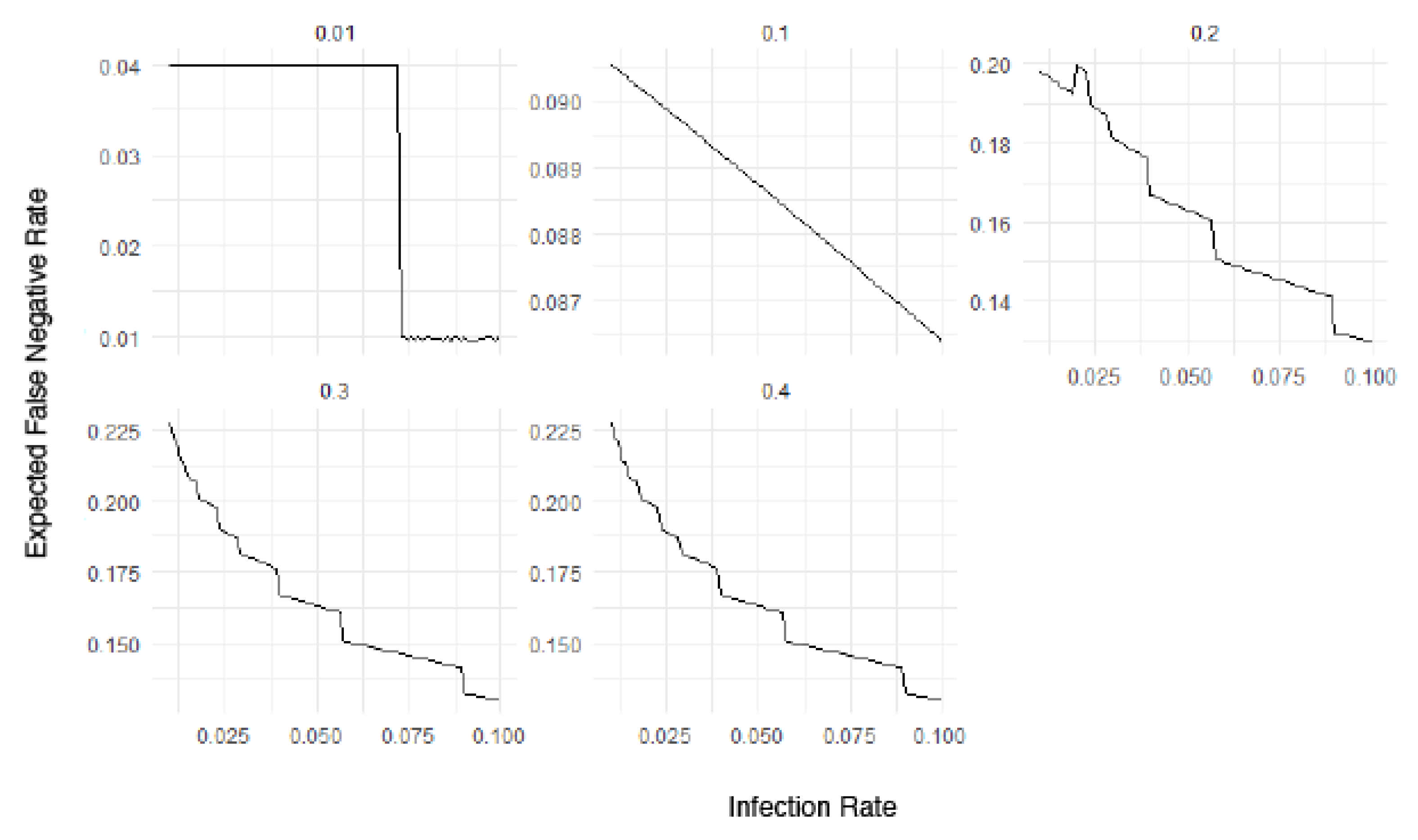
2.2.2. Dilution Effect Functions
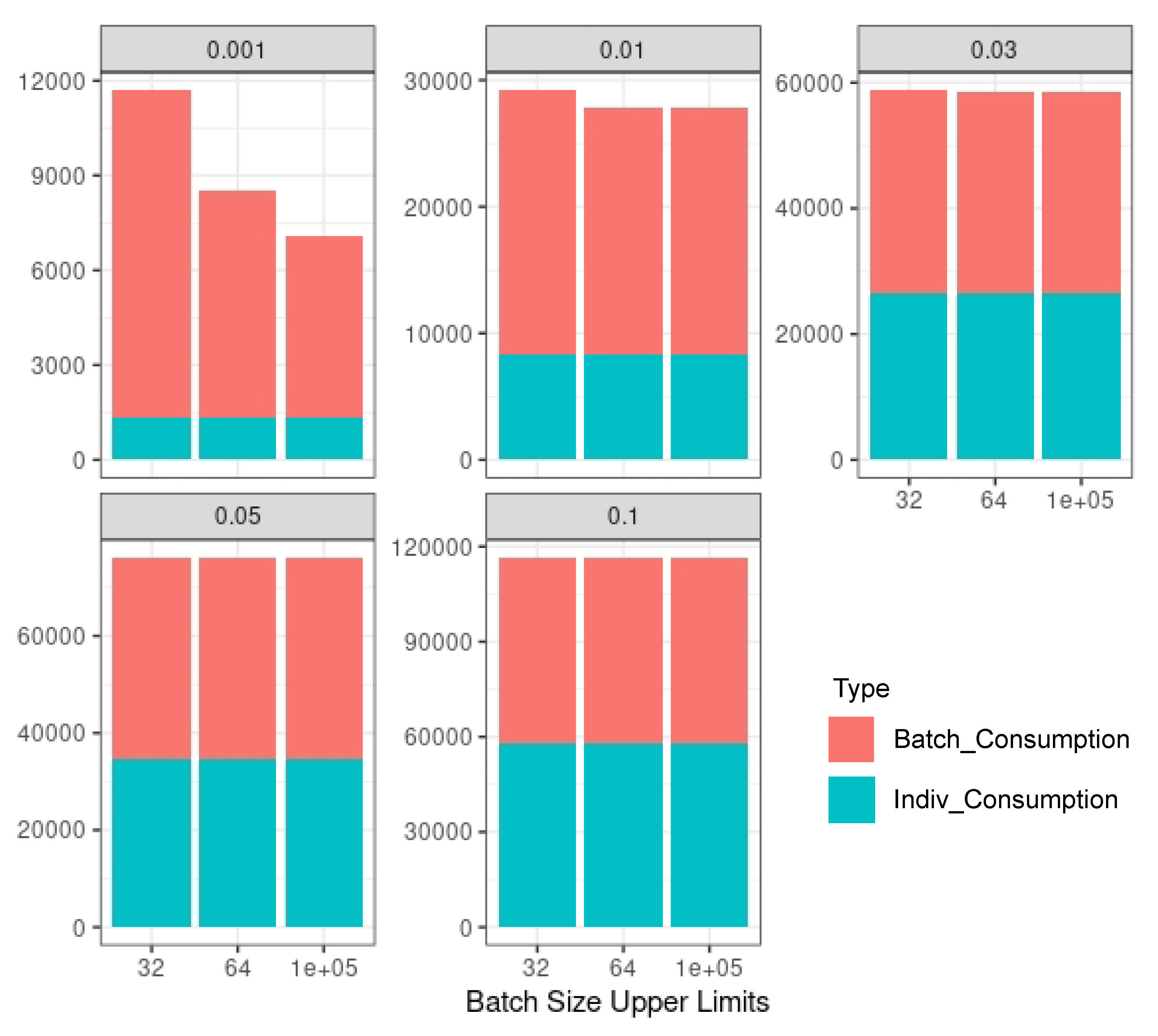
2.3. Multi-Step Group Testing with Dilution Effects
2.3.1. Multi-Step Group Testing
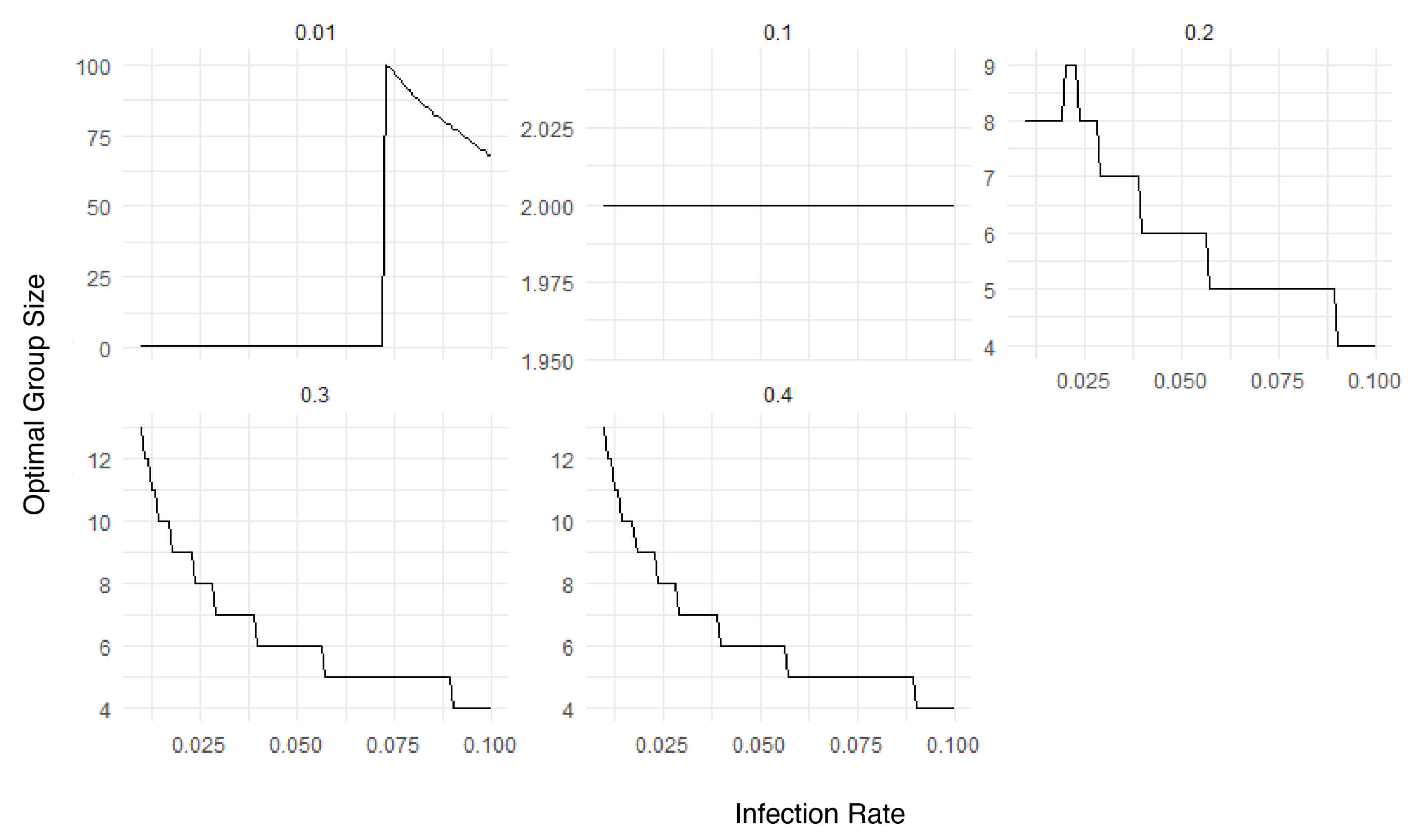
2.3.2. Optimal Group Size
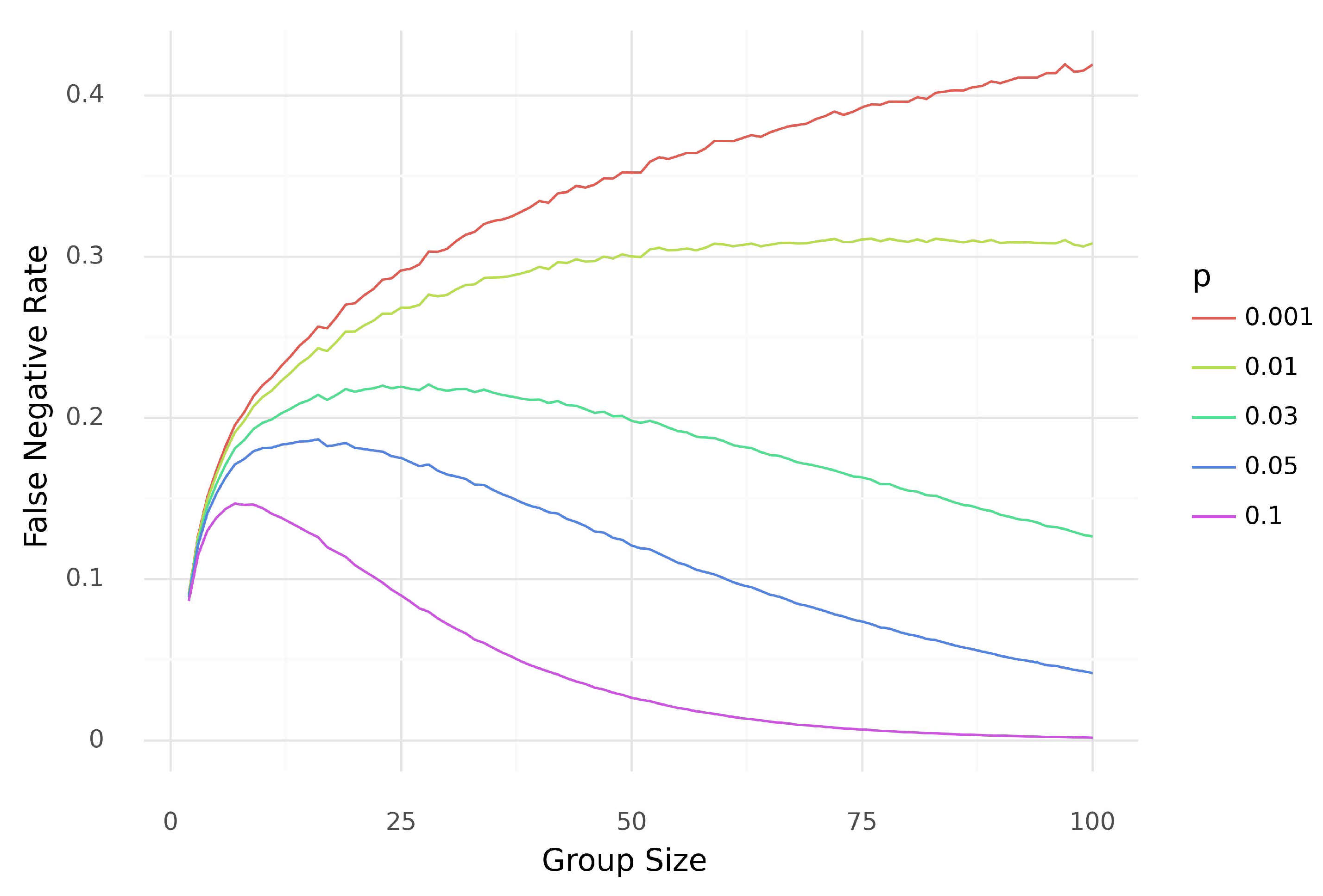
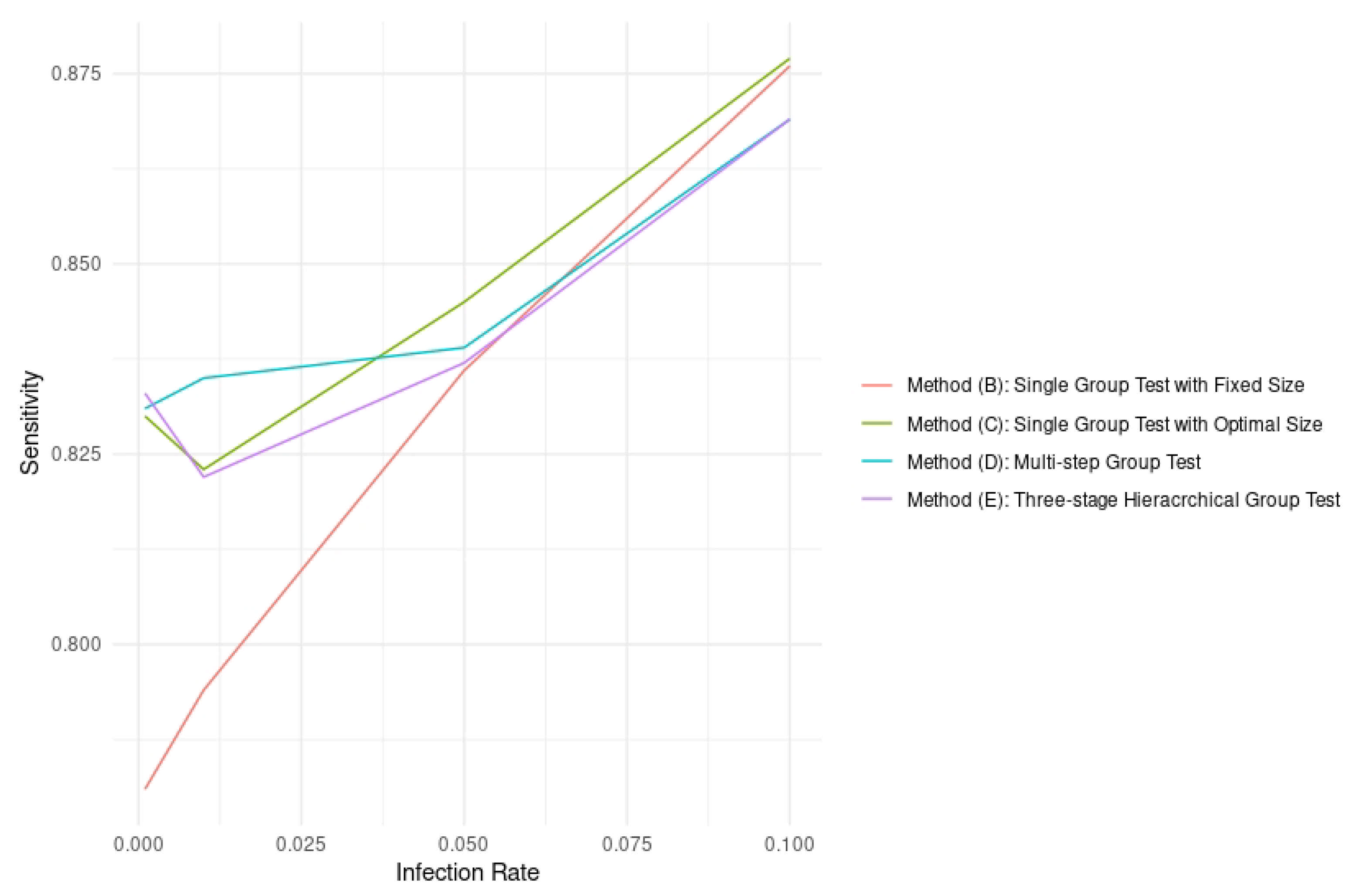
2.3.3. Sensitivity
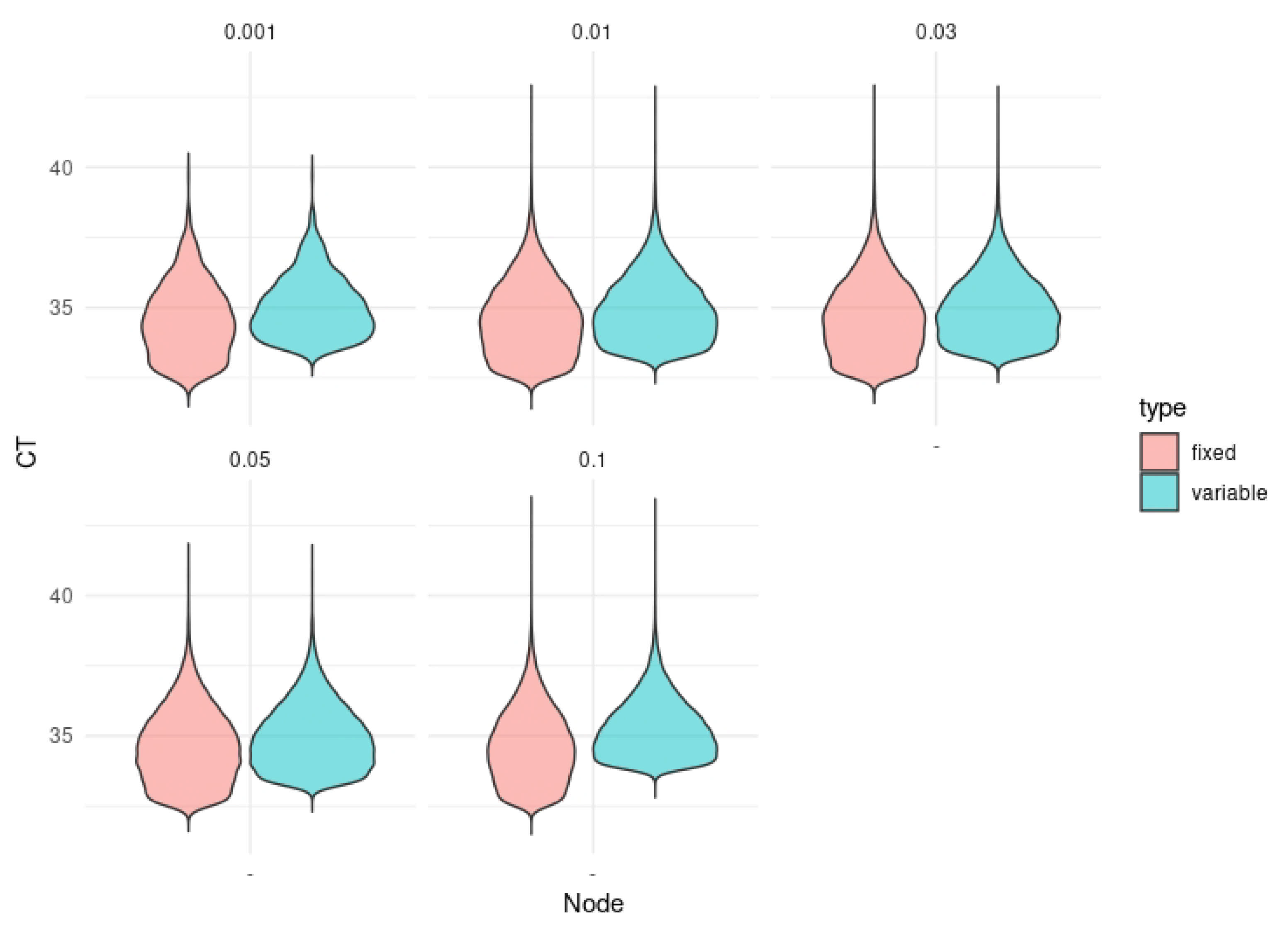
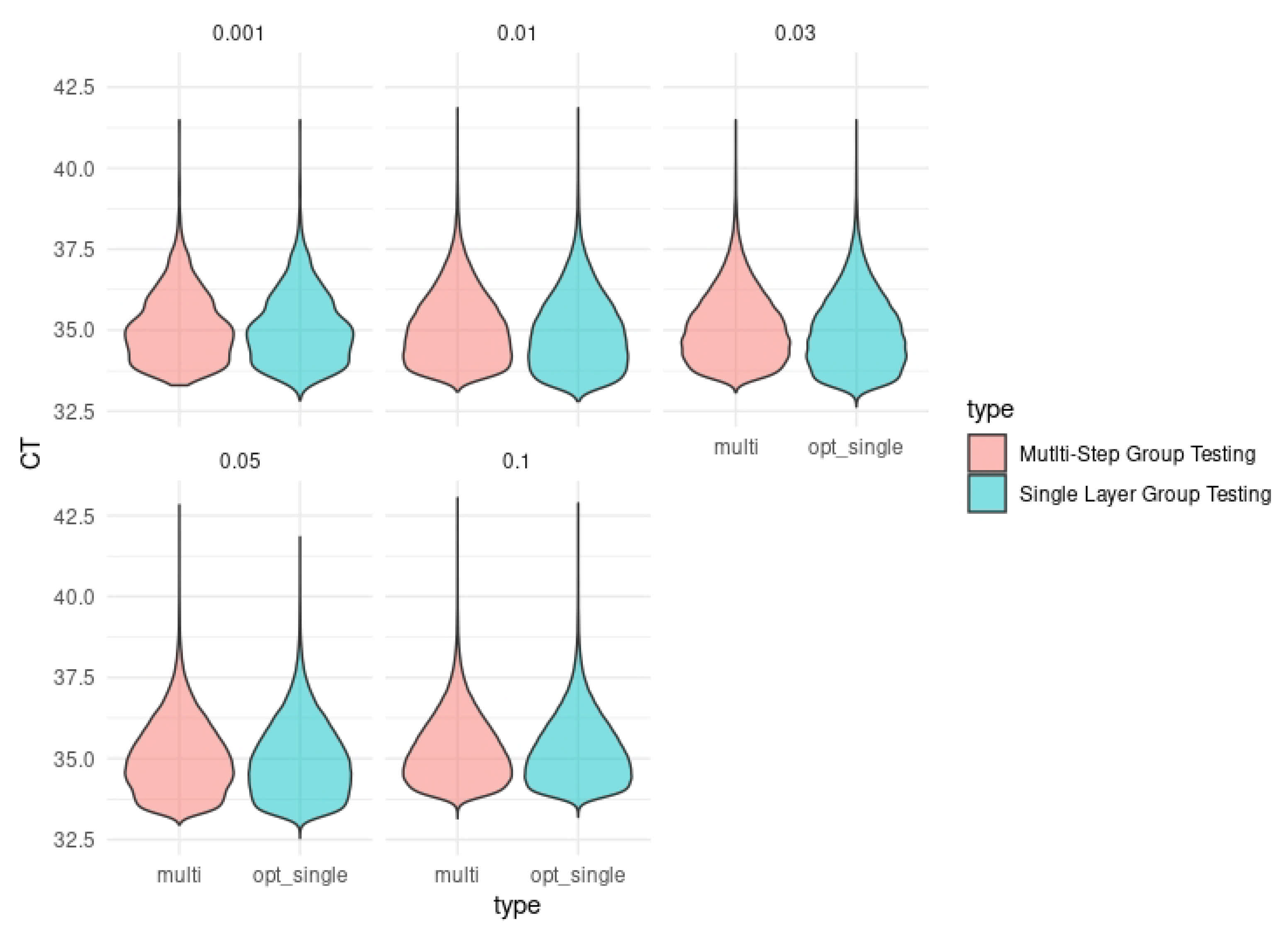
3. Results
4. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| PCR | Polymerase chain reaction |
| RT-PCR | Reverse transcription-Polymerase chain reaction |
| FNR | False negative rate |
References
- Dorfman, R. The detection of defective members of large populations. Ann. Math. Stat. 1943, 14, 436–440. [Google Scholar] [CrossRef]
- Hogan, C.A.; Sahoo, M.K.; Pinsky, B.A. Sample pooling as a strategy to detect community transmission of SARS-CoV-2. JAMA 2020, 323, 1967–1969. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abdalhamid, B.; Bilder, C.R.; McCutchen, E.L.; Hinrichs, S.H.; Koepsell, S.A.; Iwen, P.C. Assessment of specimen pooling to conserve SARS CoV-2 testing resources. Am. J. Clin. Pathol. 2020, 153, 715–718. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, H.; Hudgens, M.G.; Dreyfuss, J.M.; Westreich, D.J.; Pilcher, C.D. Comparison of group testing algorithms for case identification in the presence of test error. Biometrics 2007, 63, 1152–1163. [Google Scholar] [CrossRef] [PubMed]
- Ahn, H.; Jiang, H.; Li, X. Modeling and computation of multistep batch testing for infectious diseases. Biom. J. 2021, 63, 1272–1289. [Google Scholar] [CrossRef] [PubMed]
- Bilder, C.R.; Iwen, P.C.; Abdalhamid, B.; Tebbs, J.M.; McMahan, C.S. Tests in short supply? Try group testing. Significance 2020, 17, 15–16. [Google Scholar] [CrossRef] [PubMed]
- Hwang, F.K. Group testing with a dilution effect. Biometrika 1976, 63, 671–673. [Google Scholar] [CrossRef]
- Burns, K.C.; Mauro, C.A. Group testing with test error as a function of concentration. Commun. Stat.-Theory Methods 1987, 16, 2821–2837. [Google Scholar] [CrossRef]
- Saraiva, G. Pool testing with dilution and heterogeneous priors. Preprint. 2021. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3789077 (accessed on 28 December 2021).
- Hwang, F.K. A generalized binomial group testing problem. J. Am. Stat. Assoc. 1975, 70, 923–926. [Google Scholar] [CrossRef]
- Jones, T.C.; Biele, G.; Mühlemann, B.; Veith, T.; Schneider, J.; Beheim-Schwarzbach, J.; Bleicker, T.; Tesch, J.; Schmidt, M.L.; Sander, L.E.; et al. Estimating infectiousness throughout SARS-CoV-2 infection course. Science 2021, 373. [Google Scholar] [CrossRef] [PubMed]
- Brault, V.; Mallein, B.; Rupprecht, J. Group testing as a strategy for COVID-19 epidemiological monitoring and community surveillance. PLoS Comput. Biol. 2021, 17, e1008726. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.; Ren, Y.; Wan, J.; Cashore, M.; Wan, J.; Zhang, Y.; Frazier, P.; Zhou, E. Group testing enables asymptomatic screening for COVID-19 mitigation: Feasibility and optimal pool size selection with dilution effects. arXiv 2020, arXiv:2008.06642. [Google Scholar]
- Yelin, I.; Aharony, N.; Tamar, E.; Argoetti, A.; Messer, E.; Berenbaum, D.; Shafran, E.; Kuzli, A.; Gandali, N.; Shkedi, O.; et al. Evaluation of COVID-19 RT-qPCR test in multi sample pools. Clin. Infect. Dis. 2020, 71, 2073–2078. [Google Scholar] [CrossRef] [PubMed]
- Malinovsky, Y.; Albert, P.S.; Roy, A. Reader reaction: A note on the evaluation of group testing algorithms in the presence of misclassification. Biometrics 2016, 72, 299–302. [Google Scholar] [CrossRef] [PubMed]
- Huang, S.; Huang, M.L.; Shedden, K. Cost considerations for efficient group testing studies. Statstica Sin. 2020, 30, 285–302. [Google Scholar] [CrossRef]
- Hitt, B.D.; Bilder, C.R.; Tebbs, J.M.; McMahan, C.S. The objective function controversy for group testing: Much ado about nothing? Stat. Med. 2019, 38, 4912–4923. [Google Scholar] [CrossRef] [PubMed]
- Johnson, N.L.; Kotz, S.; Wu, X. Inspection Errors for Attributes in Quality Control; CRC Press: New York, NY, USA, 2020. [Google Scholar]
- Batson, J.; Bottman, N.; Cooper, Y.; Janda, F. A comparison of group testing architectures for COVID-19 testing. arXiv 2020, arXiv:2005.03051. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| True Condition | |||
|---|---|---|---|
| No Samples Are Infected | At Least One Sample is Infected | ||
| Test | + | ||
| Result | − | ||
| p | Group Size | Approximate Sensitivity | Simulated Sensitivity | sd |
|---|---|---|---|---|
| 10 | ||||
| 10 | ||||
| 10 | ||||
| 10 | ||||
| 10 |
| 0.001 | 0.01 | 0.03 | 0.05 | 0.10 | ||
|---|---|---|---|---|---|---|
| (A) | Acc. | 0.999 (0.000) | 0.999 (0.000) | 0.998 (0.000) | 0.997 (0.000) | 0.995 (0.000) |
| Indiv | Sens. | 0.955 (0.018) | 0.960 (0.005) | 0.960 (0.005) | 0.960 (0.000) | 0.959 (0.000) |
| Tests | Spec. | 10.000 (0.000) | 10.000 (0.000) | 10.000 (0.000) | 0.998 (0.000) | 0.995 (0.000) |
| PPV | 0.484 (0.020) | 0.910 (0.010) | 0.968 (0.002) | 0.983 (0.002) | 0.990 (0.001) | |
| NPV | 10.000 (0.000) | 10.000 (0.000) | 0.999 (0.000) | 0.998 (0.000) | 0.995 (0.000) | |
| #Tests | 100,000 (0) | 100,000 (0) | 100,000 (0) | 100,000 (0) | 100,000 (0) | |
| (B) | Acc. | 10.00 (0.000) | 0.998 (0.000) | 0.994 (0.000) | 0.992 (0.000) | 0.987 (0.000) |
| Single | Sens. | 0.781 (0.042) | 0.794 (0.013) | 0.815 (0.008) | 0.836 (0.001) | 0.876 (0.000) |
| Group | Spec. | 10.000 (0.000) | 10.000 (0.000) | 10.000 (0.000) | 10.000 (0.000) | 10.000 (0.000) |
| Tests | PPV | 0.990 (0.012) | 0.992 (0.004) | 0.992 (0.002) | 0.993 (0.001) | 0.995 (0.001) |
| Fixed | NPV | 10.00 (0.000) | 0.998 (0.000) | 0.994 (0.000) | 0.991 (0.000) | 0.986 (0.000) |
| Size 10 | #Tests | 10,878 (91) | 17,649 (261) | 31,190 (348) | 42,926 (463) | 65,750 (500) |
| (C) | Acc. | 10.00 (0.000) | 0.998 (0.000) | 0.995 (0.000) | 0.992 (0.000) | 0.988 (0.000) |
| Single | Sens. | 0.830 (0.038) | 0.823 (0.013) | 0.834 (0.006) | 0.845 (0.005) | 0.877 (0.003) |
| Group | Spec. | 10.000 (0.000) | 10.000 (0.000) | 10.000 | 10.000 (0.000) | 10.000 (0.000) |
| Optimal | PPV | 0.994 (0.010) | 0.995 (0.002) | 0.995 (0.001) | 0.996 (0.001) | 0.998 (0.001) |
| Sizes | NPV | 10.00 (0.000) | 0.998 (0.000) | 0.995 (0.000) | 0.992 (0.000) | 0.987 (0.000) |
| #Tests | 20,517 (54) | 21,579 (158) | 30,569 (257) | 38,872 (352) | 54,995 (304) | |
| B+Ind | 20,000 + 517 | 16,667 + 491 | 16,667 + 13,902 | 16,667 + 22,205 | 25,000 + 29,995 | |
| (D) | Acc. | 10.00 (0.000) | 0.998 (0.000) | 0.995 (0.000) | 0.992 (0.000) | 0.987 (0.000) |
| Multi-step | Sens0. | 0.831 (0.039) | 0.835 (0.012) | 0.841 (0.000) | 0.839 (0.006) | 0.869 (0.004) |
| Group | Spec0. | 10.000 (0.000) | 10.000 (0.000) | 10.000 (0.000) | 10.000 (0.000) | 10.000 (0.000) |
| Variable | PPV | 0.997 (0.006) | 0.997 (0.002) | 0.998 (0.001) | 0.998 (0.001) | 0.999 (0.000) |
| Sizes | NPV | 10.00 (0.000) | 0.998 (0.000) | 0.995 (0.000) | 0.992 (0.000) | 0.986 (0.000) |
| 1 indiv | #Tests | 40,388 (41) | 40,396 (126) | 46,898 (191) | 50,739 (280) | 70,175 (290) |
| Test | B+Ind | 40,082 + 306 | 37,278 + 3118 | 39,571 + 7327 | 38,801 + 11,938 | 48,314 + 21,861 |
| (E) e | Acc. | 10.00 (0.000) | 0.998 (0.000) | 0.995 (0.000) | 0.992 (0.000) | 0.987 (0.000) |
| Three Stage | Sens0. | 0.833 (0.034) | 0.822 (0.014) | 0.829 (0.007) | 0.837 (0.005) | 0.869 (0.003) |
| Hierarchical | Spec. | 10.000 (0.000) | 10.000 (0.000) | 10.000 (0.000) | 10.00 (0.000) | 10.00 (0.000) |
| Variable | PPV | 0.998 (0.006) | 0.997 (0.002) | 0.998 (0.001) | 0.998 (0.001) | 0.999 (0.000) |
| Sizes | NPV | 10.00 (0.000) | 0.998 (0.000) | 0.995 (0.000) | 0.991 (0.000) | 0.986 (0.000) |
| Group | #Tests | 20,436 (48) | 20,964 (154) | 28,527 (224) | 35,956 (304) | 56,906 (295) |
| Test | B+Ind | 20,130 + 306 | 17,896 + 3067 | 21,308 + 7219 | 24,078 + 11,878 | 35,013 + 21,893 |
| p | Step I False Negatives | Step II False Negatives |
|---|---|---|
| 0.001 | 14.4 (5.86) | 15.3 (4.87) |
| 0.01 | 88.2 (74.8) | 86.3 (80.4) |
| 0.03 | 242 (203) | 235 (210) |
| 0.05 | 367 (350) | 392 (325) |
| 0.1 | 717 (546) | 623 (510) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, H.; Ahn, H.; Li, X. Group Testing with Consideration of the Dilution Effect. Mathematics 2022, 10, 497. https://doi.org/10.3390/math10030497
Jiang H, Ahn H, Li X. Group Testing with Consideration of the Dilution Effect. Mathematics. 2022; 10(3):497. https://doi.org/10.3390/math10030497
Chicago/Turabian StyleJiang, Haoran, Hongshik Ahn, and Xiaolin Li. 2022. "Group Testing with Consideration of the Dilution Effect" Mathematics 10, no. 3: 497. https://doi.org/10.3390/math10030497
APA StyleJiang, H., Ahn, H., & Li, X. (2022). Group Testing with Consideration of the Dilution Effect. Mathematics, 10(3), 497. https://doi.org/10.3390/math10030497