1. Introduction
Emotion analysis has shown to be an important part of research fields such as human–computer interaction and health care, in order to improve the interactive experience and understand the behavior of patients [
1,
2]. Existing approaches in emotion recognition characterize the responses of emotions in two main modalities [
3,
4]: behavioral and physiological signals. The first type of modality includes those approaches based on facial expression [
5,
6], speech emotion recognition [
7] and body language. Unlike this type of modality, the physiological signals provide a reliable way to recognize emotions since these signals are produced by the human body that may not be susceptible to subjective approaches based on behavioral signals [
8]. In this sense, Electrocardiogram (ECG) [
9], Electromyography (EMG) [
10], Electroencephalogram (EEG) [
4] or even a combination of them [
11,
12], have been used for emotion recognition. Among these physiological-signal-based approaches, EEG has provided a reliable and promising indicator to identify different emotional states, as it directly reflects brain activity [
12]. Furthermore, EEG is a non-invasive device, easy to use, and has a low cost [
4,
13]. Thus, EEG has been widely used in emotion recognition systems in the last years [
3,
8,
13,
14,
15,
16,
17,
18].
Reported works have been mainly focused on extracting discriminative EEG emotional features and building more effective emotion recognition systems. The collected EEG signals are usually analyzed in three categories to extract discriminative features: time domain (e.g., statistics of signal), frequency domain (e.g., differential entropy), and time-frequency domain (e.g., Fourier transform). In this direction, many methods have been proposed via machine learning to leverage the features extracted from EEG signals [
17,
18,
19]. Recently, several methods are gradually moving towards the deep learning-based approaches, becoming dominant in EEG-based emotion recognition [
3,
8,
13,
14,
15,
16,
20,
21]. For example, different deep learning methods have been proposed to consider the spatial information, such as convolutional neural networks (CNNs) [
3,
14,
16], capsule networks (CapsNets) [
21] and graph neural networks (GNN) [
8,
13]. Likewise, attention mechanisms and recurrent networks [
15] have been used to extract spatial and temporal information as emotion features.
Although remarkable progress has been achieved, there is a growing demand for adaptive, scalable, and responsive deep learning methods for emotion recognition tasks. Reported works are focused on recognizing emotions with fixed models while being unable to incorporate other emotions into their knowledge. New emotions may be recorded over time so that devices with pre-installed emotion recognition models may fail to recognize this new knowledge. Whenever samples from a new emotion become available, deep neural network models require retraining the whole model from scratch. This issue may be infeasible both in time or storage while using all training data or when the size of the main memory is limited [
22]. Instead, the knowledge learned by a trained model should only be modified by using samples from a new emotion. In this sense, Class-incremental learning (CIL) provides a solution when new samples emerge, updating the knowledge of the model according to samples from new classes, avoiding re-configure the entire system [
23].
CIL methods have been widely studied in computer vision [
22] since several works have shown that deep learning models suffer from catastrophic forgetting when they are trained incrementally [
24]. The catastrophic forgetting is the performance degradation of a neural network model affecting previously learned concepts whenever new ones are incorporated sequentially [
25]. Different approaches have rapidly emerged to alleviate catastrophic forgetting. A first approach extends the model capacity to accommodate the latest knowledge as new data are integrated [
26,
27]. Although no sample is retained during incremental stages, these works may not scale well in specific scenarios since new weights are added each time. A second approach [
28,
29,
30,
31] uses a fixed model to generate feature representations across different incremental stages while multiple classifiers are trained for new classes. Although the retraining of the entire model is avoided, the performance of these methods depends on the quality of an initial representation, producing sub-optimal classification results in some cases [
22]. Moreover, a third approach [
25,
32,
33,
34,
35,
36,
37,
38,
39,
40], named memory replay, stores a small set of representative samples from old classes and updates deep learning models via Fine-tuning (FT) across different incremental stages. The memory replay-based approach has shown better performance than previous approaches [
35], but certainly the catastrophic forgetting is still under-studied. Mainly, in EEG-based signal recognition, Lee et al. [
41] explored CIL for the imagined speech recognition task, but the authors used one of the most straightforward memory replay-based methods under an undemanding evaluation, as only a single incremental stage was tested for CIL. On the other hand, no work has been reported to study the dynamic changes in class for the EEG-based emotion recognition task. Thus, this research focuses on studying CIL for emotion recognition from EEG signals to enable deep learning models to incorporate new emotions into already known.
In this paper, we introduce
Incremental Learning preserving the Learned Feature Space (IL2FS), a CIL method to address the catastrophic forgetting in EEG-based emotion recognition. The proposed method aims to preserve the feature space learned over past incremental stages, performing a bias correction on new classes, as well as encouraging the inter-class separation and feature space alignment over old classes. Firstly, we use Weighting Aligning (WA) [
36] for bias correction on the weights at the output layer since class imbalance is present. Secondly, we use margin ranking loss to set a margin between scores of the ground-truth from old classes and their nearest score from any class (old or new), instead of only ensuring a separation between old and new classes, as reported in [
33]. Finally, unlike previous CIL works for embedding networks [
42,
43,
44], we propose to use triplet loss [
45] to maintain the feature space alignment of old classes. IL2FS was implemented on a Capsule Network (CapsNet) architecture, which presents one of the best performances in terms of accuracy for emotion recognition [
21]. We evaluate and validate our proposal on incremental learning tasks over two public datasets, DREAMER [
46] and DEAP [
11], using a reduced set of samples from old classes and the maximum number of incremental stages that may be built for each dataset.
The main contributions of this work are:
We present a Class-incremental Learning method, named IL2FS, for emotion recognition from EEG signals, addressing the catastrophic forgetting problem.
IL2FS incorporates a strategy based on bias correction of the new classes while ensuring an inter-class separation and feature alignment of the old classes. This strategy allows better preservation of the learned knowledge for a greater number of incremental stages and a reduced number of reserved samples in memory.
We conduct experiments on two benchmarks, DEAP and DREAMER, for emotion recognition research. The proposed method achieves a significant improvement when compared with existing CIL methods.
The rest of this paper is organized as follows: in
Section 2, we review previous works on class-incremental learning.
Section 3 describes the proposed method in detail.
Section 4 presents datasets, preprocessing procedure, neural network architecture and experimental setup. The corresponding results are reported in
Section 5. Finally, the discussion and conclusions are reported in
Section 6 and
Section 7.
2. Related Work
Existing works in EEG-based emotion recognition have focused on dynamic data distribution changes, but dynamic changes in class have not been studied yet. In [
41], the authors explored CIL using a memory replay-based approach for the imagined speech task. Even so, a simple method [
47] based on fine-tuning and the nearest neighbor classifier was adopted. Likewise, an undemanding evaluation was performed since only a single new class was tested, while a considerable percentage of data from old classes is reserved in memory when a new class is added. On the other hand, several CIL methods are available in computer vision to address the catastrophic forgetting problem. Among different approaches, reported in [
22], we are interested in memory replay-based methods since they have shown superior performance in terms of accuracy. Thus, we describe several methods based on memory replay to deal with the catastrophic forgetting problem. We group these methods according to the problem they address.
Less forgetting. Knowledge distillation [
48] was introduced as a regularizer on the outputs of a reference network and a new network in [
49], in order to preserve the predictions of classes learned at previous CIL stages. For this, knowledge distillation aims to keep the new network weights close to the weights of the reference network. Moreover, Hou et al. [
33] presented
Learning a Unified Classifier Incrementally via Rebalancing (LUCIR), which introduces a less-forget constraint through the cosine distance, considering the local geometric structures of old classes in their feature space. More recently, Simon et al. [
25] proposed a distillation loss, named
Geodesic, by adopting the concept of geodesic flow between two tasks, that is, the gradual changes between tasks projected in intermediate subspaces.
Bias correction. In this group, CIL methods focus on updating the neural network weights in order to calibrate the bias produced by the class imbalance of representative samples. Wu et al. [
50] proposed
Bias correction (BiC) to rectify the weights of the model output, but a validation set is still required. In [
33], authors observed that magnitudes of the weight vectors for new classes are higher than those of old classes, then, cosine normalization is used over the output layer to reduce the impact of imbalanced data. In this sense,
Incremental Learning with Dual Memory (LI2M) [
47] corrects scores of old classes storing their statistical information in an additional memory.
Classifier Weights Scaling for Class Incremental Learning (ScaIL) [
51] rectifies the weights of old classes to make them more comparable to those of new classes. Zhao et al. [
36] proposed
Weight Aligning (WA) to correct the biased weights at the output layer once the training process has ended. For this, only weight vectors of new classes are aligned to those of old classes using normalization.
Inter-class separation. The knowledge distillation loss has proven to be useful while producing more discriminative results within old classes when a bias correction is performed [
36]. However, distillation loss may not be sufficient to ensure an inter-class separation between old and new classes since decision boundaries are re-configured during training over new classes. Thus, authors in [
33] introduced margin ranking loss to encourage a margin that separates old and new classes. Chaudhry et al. [
37] used bilevel optimization to update the model with new classes, keeping predictions intact on anchor points of old classes that lie close to the class decision boundaries.
Representative samples. Some strategies have been reported to select representative samples of old classes in order to avoid the model from overfitting to new classes. The baseline method, named Herding [
32,
52], selects the closest samples as most representative of a class, based on a histogram of the distances to the mean sample of that class. Authors in [
53] introduced a more complex solution, named
Mnemonics, which uses a strategy based on meta-learning to update the memory via gradient descent, selecting those samples located on boundary decisions. Generative solutions may also be found in [
54,
55], where artificial samples are drawn from each incremental stage, using generative adversarial networks (GANs). However, since GANs have proven to be difficult to optimize, they present scalability issues.
3. Proposed Method
In this section, we introduce the proposed method in detail. First, the Class-incremental learning setting is described. Then, we introduce an overview of the proposed method and its components. Finally, the training algorithm of the proposed method is presented.
3.1. Class Incremental Learning Setting
This research is focused on Class-Incremental Learning (CIL) based on the memory replay approach [
22,
32], where the neural network model complexity is maintained constant through
S incremental stages, while new emotions are sequentially incorporated. In each incremental stage, samples from new emotions and a few samples from old emotions are available to retrain an existing neural network model.
Let be a feature space with a label space belonging to classes (emotions) in . A labeled dataset is defined as . We assume one initial stage and S incremental stages, where is split into sets with and for . A budget is determined for the memory , which is used to store a limited amount of representative samples from old classes. In the initial stage, a deep neural network model is trained on a labeled dataset . Next, a representative set of samples is selected and stored in memory as a replacement of , with . In the incremental stage s, a deep network model is updated using the labeled dataset and memory , that is, . Notice that now contains representative samples of old classes from incremental stage 0 to . We assume all training samples in are available to train a neural network. In CIL, the main objective is to use a deep network model and to accurately classify samples belonging to old and new classes in each incremental stage s, avoiding catastrophic forgetting.
A deep neural network model is usually denoted as a labeling function f with trainable weights , such that . The function f may be represented as composite of two functions, . Here, represents the part of network that encodes an input into a latent feature representation , that is, ; is the set of trainable weights. Then, latent features are fed to a feature labeling function with weights , in order to produce a classification score , i.e., . In CIL, the number of classes of the model output increases at each incremental stage. Thus, the network model f is expected to classify more classes at incremental stage s than at stage .
3.2. Overview of the Proposed Method
The proposed method, named
Incremental Learning preserving the Learned Feature Space (IL2FS), faces the catastrophic forgetting problem aiming to preserve the learned feature space from old classes. For this, IL2FS performs a bias correction of new classes, while the inter-class separation and feature space alignment of old classes are ensured. Firstly, a bias correction is performed on the weights at the output layer via Weight Aligning [
36], as imbalanced data are present when trained over a reduced set of representative samples of old classes. Then, an inter-class separation is encouraged between scores from old classes and their nearest class (old or new) via margin ranking loss, instead of only encouraging a separation between old and new classes, as reported in [
33]. Finally, since that new knowledge may modify the learned feature space at previous CIL stages, we propose to use triplet loss [
45] to preserve the feature space alignment of old classes.
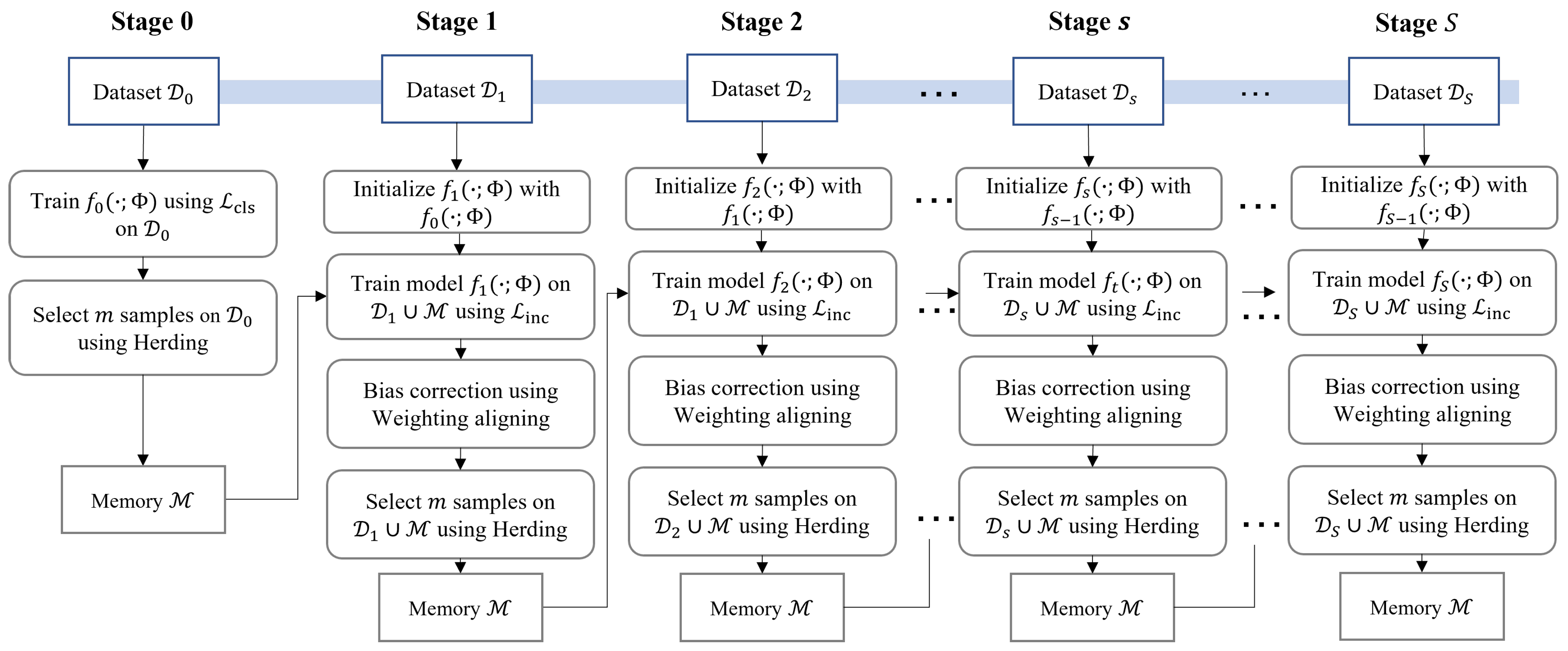
The complete flowchart is shown in
Figure 1 and the overall objective can be written as follows
where
is the triplet loss,
is a classification loss, and
is the margin ranking loss.
,
,
are the trade-off hyper-parameters.
As shown in
Figure 1, the network model
is trained at stage 0 on
, using the classification loss. Next, the Herding method [
32,
52] is employed to select
m representative samples to be stored in memory
. At the incremental stage
s, weights
are initialized using those learned at stage
. Then, the network model
is retrained on
, using loss function
. Exponential Moving Average (EMA) [
56] is also incorporated into IL2FS in order to stabilize the training of
over
n training steps:
where
is the EMA of successive
weights over
n and
is the decay rate or momentum. Then, at the end of the model’s training, Weighting Aligning is used to align the norms of the weight vectors between old and new classes at the output layer. Likewise,
m representative samples are selected on
, considering a balanced selection. This procedure is repeated every time new classes emerge, which must be incorporated into an existing model.
3.3. Bias Correction
Weight Aligning (WA) [
36] has been used for bias correction, given that a class imbalance is produced by using a reduced set of representative samples of old classes in new incremental stages. Thus, WA rectifies the weight vectors at the output layer of a network model, aligning the norms of the weight vectors between old and new classes.
The output layer is rewritten as
where
while the norms of the weight vectors are expressed as follows
Then, the weights of new classes are normalized by using
where
Here, computes the mean value using these weight vectors.
3.4. Inter-Class Separation
We assume that decision regions of old classes may change during model retraining, as representative samples of old classes are used for this process. Then, an inter-class separation is ensured by setting a margin over class scores throughout the different incremental learning stages.
Margin ranking loss was introduced in [
33] to ensure a separation between old and new classes (see
Section 2). Unlike previous work, we use a variant of the margin ranking loss to encourage an inter-class separation between the ground-truth score of an old class and its nearest score coming from any class, old or new.
For each sample
in memory
, a separation is encouraged between the ground-truth old classes and their nearest class (old or new). For each sample
in memory
, the score
of the ground-truth old class is considered positive, while the maximum score
among the remaining classes is considered hard negative. We have:
where
b is the margin,
is the score of the ground-truth class for the sample
, and
is the nearest class score for
.
3.5. Feature Space Alignment
We incorporate triplet loss [
45] to leverage the less forgetting, preserving the alignment of the feature space of classes learned at previous incremental stages. Note that existing strategies are mainly focused on maintaining the same output predictions of old classes (see
Section 2). On the other hand, previous works in CIL [
42,
43,
44] have mainly used triplet loss to train embedding networks and ensure an inter-class separation. However, unlike previous works, we incorporate triplet loss to preserve the feature space alignment of old samples, producing near feature representations from
and
for the same processed sample. Here,
is the model learned at the last incremental stage
and
is the new model to train in the current stage
s. Representations from different samples, processed by
and
, are pushed away from each other by a small margin. Note that class labels for the processed samples are not used in our proposal, as an inter-class separation is not pursued.
More specifically, we use triplet loss to push latent feature representations and close to each other for the same sample . Meanwhile, the latent features and , produced by and , but coming from samples and , are pushed away from each other by a margin.
The triplet loss is defined as follows
where
is the anchor input,
is a positive input of the same label as
, while
is a negative input of a different label as
;
a is the margin and
d is the cosine dissimilarity measure. Anchor-positive pairs are formed by latent features generated by
and
for the same sample, while anchor-negative pairs are formed by latent features generated by
and
for a pair of different samples.
processes all samples within the current batch to generate their respective latent feature representations. After, each featured sample is labeled according to its index into the batch of samples. This procedure is repeated for all samples but using
; later, featured samples are concatenated with those obtained by
. Then, the multi-similarity miner [
57] is used to generate anchor-positive pairs
and anchor-negative pairs
over labeled feature representations in order to preserve the feature alignment of old classes.
3.6. Training of IL2FS
Algorithm 1 presents the training procedure of IL2FS at incremental stage
s. First, the set of weights
is initialized using weights
(line 1). Next, we compute latent features for
using the reference model and current model (lines 7–8). Featured samples are labeled according to their indices into the dataset (lines 9–10). Anchor-positive and anchor-negative pairs are generated using the Multi-similarity miner (line 11) to be employed in triplet loss
. Then, scores for ground-truth old classes and their nearest classes are computed in order to be used in margin ranking loss
(lines 12–14). After, neural network model
is trained using the loss function
(line 15). Note that
is composed of classification loss
, triplet loss
and margin ranking loss
. The EMA weights
are computed from
(line 16). After training
, weight vectors of the output layer are rectified employing the Weighting Aligning method (line 18). Finally, the memory
is updated by selecting
m representative samples on
by means of the Herding method (line 19).
| Algorithm 1 Training algorithm of IL2FS at incremental stage s. |
| Inputs: – training labeled dataset from new classes; – memory containing representative samples from old classes; – reference model trained at incremental stage ; , , – trade-off hyperparameters; – decay rate; – learning rate; n – number of epochs. |
| Output: – a trained neural network model; – updated memory with representative samples from old classes. |
| 1: Initialize with . |
| 2: |
| 3: |
| 4: |
| 5: |
| 6: repeat |
| 7: ▹ Compute features for samples using the reference model |
| 8: ▹ Compute features for samples using the current model |
| 9: ▹ Assign labels based on indices into the dataset |
| 10: |
| 11: ▹ Generate anchor-positive and anchor-negative pairs |
| 12: ▹ Compute scores for samples from old classes using the reference model |
| 13: ▹ Compute scores for all samples using the current model |
| 14: ▹ Obtain scores from the nearest classes to old classes |
| 15: |
| 16: |
| 17: until n epochs are reached |
| 18: ▹ Bias correction |
| 19: . ▹ memory is updated using the Herding method |
| 20: return, |
4. Experimental Design
This section first describes two public datasets used in our experiments. Then, the neural network architecture, comparison methods and implementation details are introduced. (Code is available at
https://github.com/mjmnzg/IL2FS. Accessed on 11 January 2022).
4.1. Datasets
Experiments were performed on two public datasets, DREAMER [
46] and DEAP [
11], since they are benchmarks for emotion recognition research [
3,
14,
15,
21]. DREAMER is a multi-channel dataset containing records of nine emotions from EEG signals per subject. Likewise, DEAP is a large-scale dataset containing EEG signals with different emotional evaluations. More importantly, both datasets were selected since a high number of classes may be obtained from EEG data, making it useful for the analysis of the catastrophic forgetting problem in emotion recognition.
The DREAMER dataset comprises EEG data from 23 subjects (14 male and nine female). EEG data were collected while the subjects watched 18 film clips, which contain cut-out scenes to evoke nine emotions: calmness, surprise, amusement, fear, excitement, disgust, happiness, anger, and sadness. The length of each film clip is between 65 to 393 s (M = 199 s). EEG signals were recorded at a sampling rate of 128 Hz using an Emotiv EPOC system that uses 16 electrodes, following locations according to the International 10–20 systems: AF3, F7, F3, FC5, T7, P7, O1, O2, P8, T8, FC6, F4, F8, AF4, M1, and M2. Sensor M1 acts as a ground reference, while M2 is a feed-forward reference; then, the remaining 14 electrodes were recorded and used for feature extraction. EEG data from all subjects have 18 experimental EEG trials, two per elicited emotion. Each EEG trial begins with a neural film to help the subjects return to the neutral emotion state, while data serve as a baseline. EEG signals of each trial were filtered with Hamming bandpass linear phase FIR filters to extract frequencies inside the ranges of interest (4–30 Hz). Likewise, artifacts were removed by using artifact subspace reconstruction (ASR) [
58]. At the final step, the Common Average Reference (CAR) method [
59] was applied to compute the average value over all electrodes and subtracts it from each sample of each electrode. In our experiments, we adopt a discrete categorization instead of a dimensional categorization, with nine classes available.
The DEAP dataset contains EEG and peripheral physiological signals from 32 subjects while watching 40 music videos. EEG signals were collected using a cap of 32 electrodes, placed according to the international 10–20 system [
60]. For this, a sampling rate of 512 Hz was used, then downsampled to 128 Hz. We used the pre-processed data (
https://www.eecs.qmul.ac.uk/mmv/datasets/deap/readme.html. Accessed on 1 June 2021), where each trial contains 60 s of recorded signals under stimulation and 3 s of baseline signals in a relaxed state. A bandpass filter from 4.0–45.0 Hz was applied over EEG signals, and eye artifacts were removed as in [
11] using independent component analysis (ICA). EEG data were averaged to the common reference. Subjects rate their levels of arousal, valence, linking, and dominance from 1 to 9 for each music video. In our experiments, we adopt a multi-class categorization scheme, combining discrete ratings of valence, arousal and dominance. Firstly, we divide each emotion dimension into two categories using a rating of 5 as threshold: low/high valence, low/high arousal and low/high dominance. Secondly, we label each EEG trial used as a combination of binary categorization in three dimensions. For instance, its label is 0 when the rating is low for the three dimensions, while the label is 1 when the rating for valence and arousal is low, but the rating for dominance is high. Finally, the recognition task is a multi-class classification composed of a maximum of 8 classes, given that not all subjects rate for every level of arousal, valence and dominance.
4.2. Preprocessing
We applied the preprocessing procedure of baseline removal on EEG signals as in the works reported by [
3,
15,
21,
61] since this method highlights the effects of stimulated emotions. We begin by using a non-overlapping window to slice baseline signals into
N segments of 1 s for each trial and
C electrodes. From the set of
N segments, we obtain the mean segment, which represents the base emotional state without stimulation. Next, the mean segment is subtracted from the EEG signals under stimulation. The obtained differences represent the electrical changes in the brain under stimulation. Following this pre-processing, 1080 EEG samples are obtained for each subject in DREAMER, where 60 segments are obtained from each experimental trial; 18 experimental trials per subject. In this direction, each trial in DEAP is divided into 60 segments, each one containing 128 sampling points. Then, we obtain 2400 EEG samples for each subject since there are 40 trials per subject. Finally, each EEG sample in DREAMER and DEAP is a 32 × 128 matrix and 14 × 128 matrix, composed of the number of electrodes and sampling points, respectively.
4.3. Neural Network Architecture
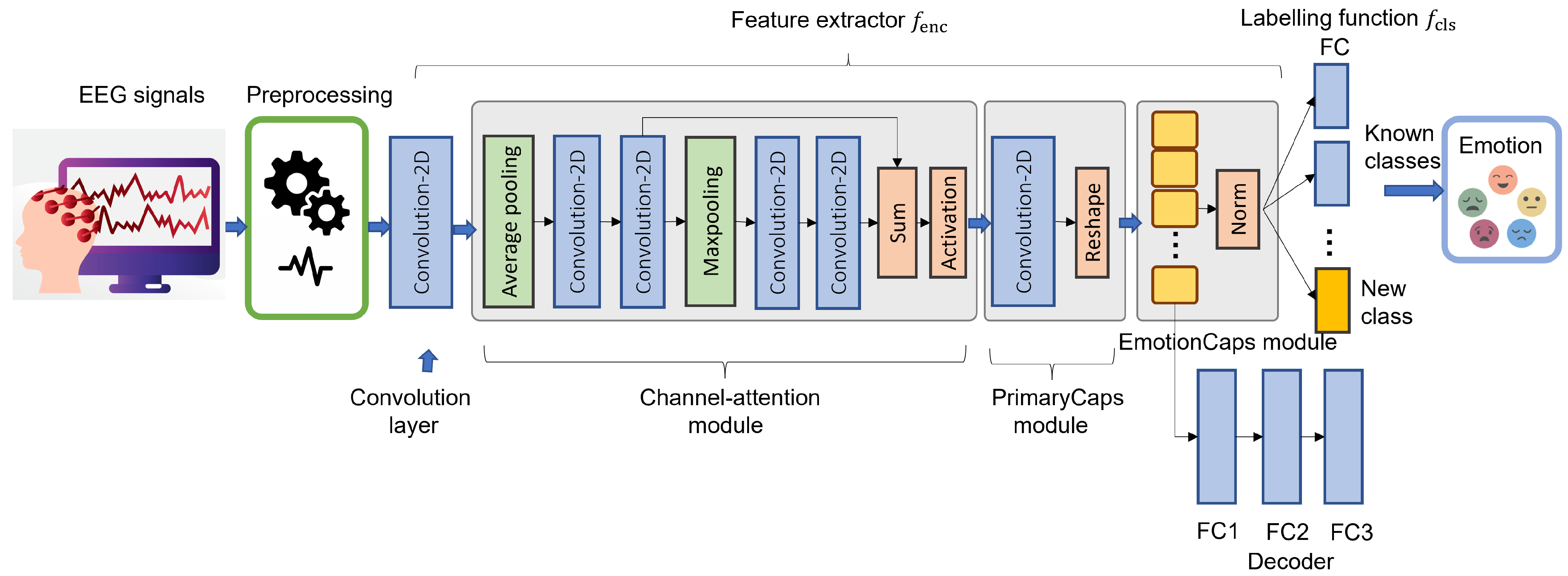
We adopted a Capsule Network (CapsNet) architecture [
21], which showed one of the best accuracy performances for EEG-based emotion recognition research.
Figure 2 presents the CapsNet architecture and
Table 1 describes the implementation details. Unlike the original CapsNet architecture, we add a module based on an attention mechanism, which includes a Channel-Attention block [
62] into the modules from Convolutional to PrimaryCaps. In addition, the bottleneck layer proposed in [
21] was removed since it dramatically increases the resources used in memory. To train CapsNet, the classification loss
uses the margin and reconstruction losses, as suggested in [
63]. For this purpose, CapsNet employs a separated margin loss
for each class
k. On the other hand, reconstruction loss
uses the sum of squared differences between the outputs of a decoder and the input EEG signal values. This decoder consists of 3 fully-connected layers that model the EEG signals.
4.4. Comparison Methods
We compared IL2FS with eight popular and recent CIL methods based on memory replay: Fine-tuning (FT) [
51], Fine-tuning+Nearest Centroid Classifier (FT+NCC) [
41,
51], Less without Forgetting (LwF) [
49], Incremental Classifier and Representation Learning (iCARL) [
32], Mnemonics [
53], ScaIL [
51], Weighting Aligning (WA) [
36], and Geodesic+LUCIR [
25]. We selected such CIL methods in our comparison since they arise as promising solutions to address the catastrophic forgetting problem in emotion recognition. All comparison methods were downloaded from repositories of original authors and then adapted for our experiments, except FT and FT+NCC, which do not represent a challenge to implement as they are basic methods. Note that all CIL methods use the same preprocessing procedure and the CapsNet architecture described in the previous sections.
4.5. Implementation Details
We first configured the hyper-parameters for the classification loss of the CapsNet architecture. Thus, the margins
and
for the separated margin loss
were set to 0.9 and 0.1, as suggested in [
21,
63]. Likewise, the reconstruction loss
was scaled by 0.3 during training; this value was selected from {0.01, 0.1, 0.2, 0.3, and 0.5}.
Concerning the specific configuration of our proposed method, we adopted a mean layer instead of a normalization layer (N14) in the CapsNet architecture. For , we used a margin since a feature space alignment is pursued between extracted features from a reference network model and a new network model; a larger margin showed to affect the classification results negatively. To ensure an inter-class separation via margin ranking loss , we used a margin b equal to 5, which was selected from {1, 3, 5, 8, and 10}. Finally, for trade-off hyper-parameters, we used and , which were selected from {0.01, 0.1, 1, and 2}. We use a momentum to place a greater significance on the most recent values.
Table 2 describes the specific hyper-parameters of CIL methods used in our comparison. Similar to our proposal, all hyperparameters were selected via grid search in combination with coordinated descent [
64] in order to ensure the best configuration. Specifically, we select a small finite list of values for each hyper-parameter and each value is changed at a time while the rest of the hyper-parameters remains fixed.
Regarding the training algorithm of the CIL methods, we used Adam optimizer employing a mini-batch size of 10; a larger size showed to reduce the classification results using an incremental learning evaluation. For DREAMER, we set a learning rate of 0.001 up to epoch 30, when it decays to 0.0001, keeping this value until epoch 50 when the training concludes. For DEAP, we set an initial learning rate of 0.001 up to epoch 15, when it also decays by a factor of 10, and then holds this value until the end of epoch 20. Other learning rates (0.1, 0.01, 0.001, 0.0001) were evaluated, but they did not improve the accuracy performance. An L1 regularizer was incorporated to CapsNet with a weight decay of 0.0004 for the Adam algorithm.
Our proposal and the comparison methods were implemented with PyTorch and trained on an Intel(R) Core (TM) i7 PC with an Nvidia GTX 1080 graphics card and Ubuntu v20.04 LTS.
4.6. Evaluation
As reported in [
22,
32], we follow the standard evaluation protocol used for the CIL setting based on the memory replay approach. The Holdout method is applied for a given dataset to build the training and testing data for each available class. Likewise, classes are arranged in a fixed random order. Each method is trained in a class-incremental way on available training data, as described in
Section 3.1. At the end of each incremental stage, the resulting classifier is evaluated on testing data for already trained classes. Note that the testing dataset is not revealed to the CIL methods during training in each incremental stage to avoid overfitting. At the end of
S incremental stages, we obtain
S classification accuracies, averaged and reported as the final result.
We adopted an instantiation of the above protocol for each subject’s data on the DREAMER and DEAP datasets, considering the most challenging scenario possible. Firstly, we start from a model trained on two classes, while remaining classes in DREAMER and DEAP come in 7 and at most six incremental stages, respectively. Secondly, we set the memory size to approximately 1% of the full training set from each subject in order to store representative samples from old classes. We used 90% of the data of each class for training, while the rest of the data was used for testing. Thus, about ten samples can be stored in memory for DREAMER through 7 incremental stages, while at least 28 samples can be stored for DEAP during six stages. Note that not all subjects in DEAP rate the same levels of arousal, valence and dominance, producing an imbalanced dataset; an oversampling was applied using a random selection. Classes from incremental stages are arranged in sequence with a fixed random order. We performed five repetitions with different partitions of data and different classes, using different random seeds; a stratified sampling was performed with respect to the classes. From accuracy results by training in a class-incremental way, we compute the average and standard deviation over the incremental stages as final results. We assumed that training and testing datasets are independent and identically distributed, i.e., both datasets were drawn from the same distribution. Thus, we did not consider any change of distribution.
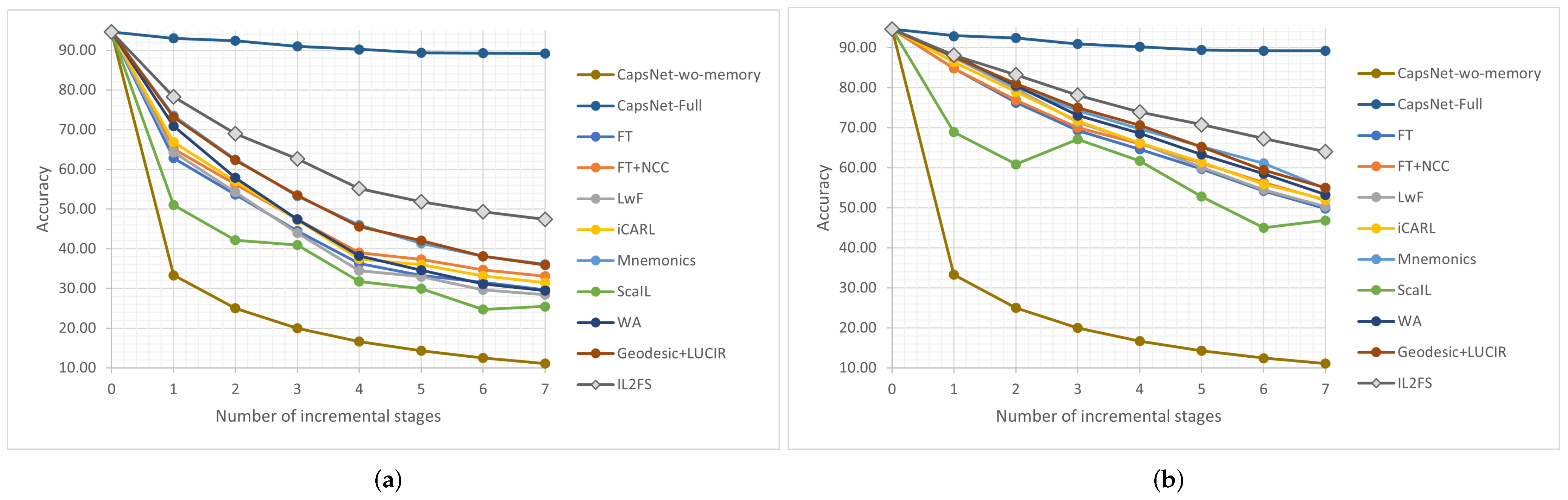
6. Discussion
Experiments showed that a standard deep learning model for emotion recognition (CapsNet) degrades its accuracy performance when trained in a class-incremental way over only samples from new emotions. This problem, known as catastrophic forgetting, is presented because previously learned emotions are negatively affected when new ones are incorporated into the classifier model. Thus, unlike previous works as reported in [
3,
8,
13,
14,
15,
16,
20,
21], this research is focused on studying the catastrophic forgetting problem in EEG-based emotion recognition.
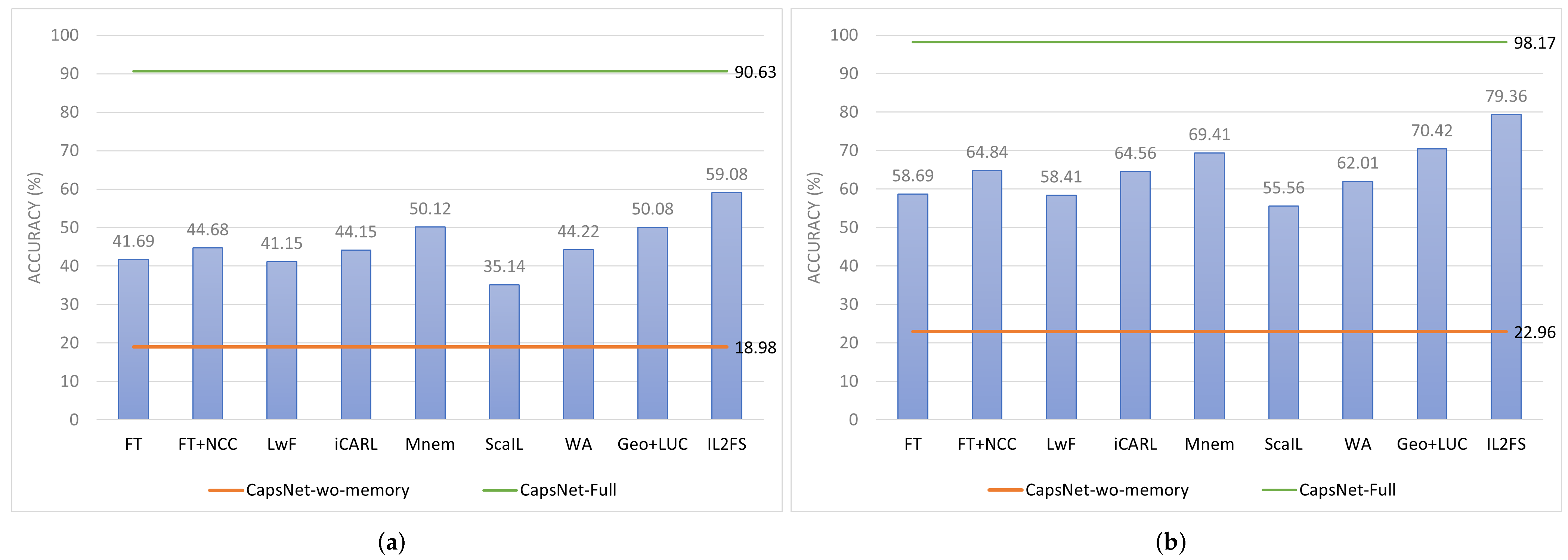
By incorporating existing CIL methods to CapsNet, we showed that classification results of the baseline approach (CapsNet-wo-memory) can be improved, suggesting that CIL methods can help mitigate the catastrophic forgetting in EEG-based emotion recognition. However, experimental results on two public datasets showed that existing CIL methods do not ensure high average accuracies. Thus, a CIL method was developed and validated to address the catastrophic forgetting problem.
Previously, Lee et al. [
41] studied the CIL over the imagined speech task from EEG signals. Authors used fine-tuning and the nearest neighbor classifier to address the catastrophic forgetting, however, they stored 20% of the full data of every old class in each incremental stage. Furthermore, only one incremental stage was used for CIL evaluation, while more stages are needed to observe the negative impact of catastrophic forgetting. On the other hand, our experiments consider a rigorous evaluation over two datasets for emotion recognition, including popular and recent CIL methods in our comparison. Based on our results, we found that IL2FS outperformed existing CIL methods on two public datasets: DREAMER and DEAP. Note that we integrated a weighting aligning as the WA method for bias correction, but an inter-class separation and a feature space alignment were also considered by IL2FS, outperforming WA by 14.28 pp and 17.35 pp on DREAMER and DEAP, respectively. Like IL2FS, the Mnemonics and Geodesic+LUCIR methods ensure an inter-class separation via margin ranking loss, but IL2FS encourages the separation between old classes and their nearest one, including old or new, instead of only ensuring a separation between old and new classes. Although Mnemonics and Geodesic+LUCIR also consider strategies for bias correction and an alignment of output predictions, our proposal outperformed Mnemonics by 8.96 pp and 9.95 pp on DREAMER and DEAP, while Geodesic+LUCIR was outperformed by 9 pp and 8.94 pp, respectively. In addition, note that comparison methods, such as LwF, iCARL, WA, Mnemonics, and Geodesic+LUCIR, use different strategies to align the output predictions of old classes to leverage the less forgetting. Unlike these works, IL2FS incorporates triplet loss to preserve the feature space alignment of old classes instead of the output predictions.
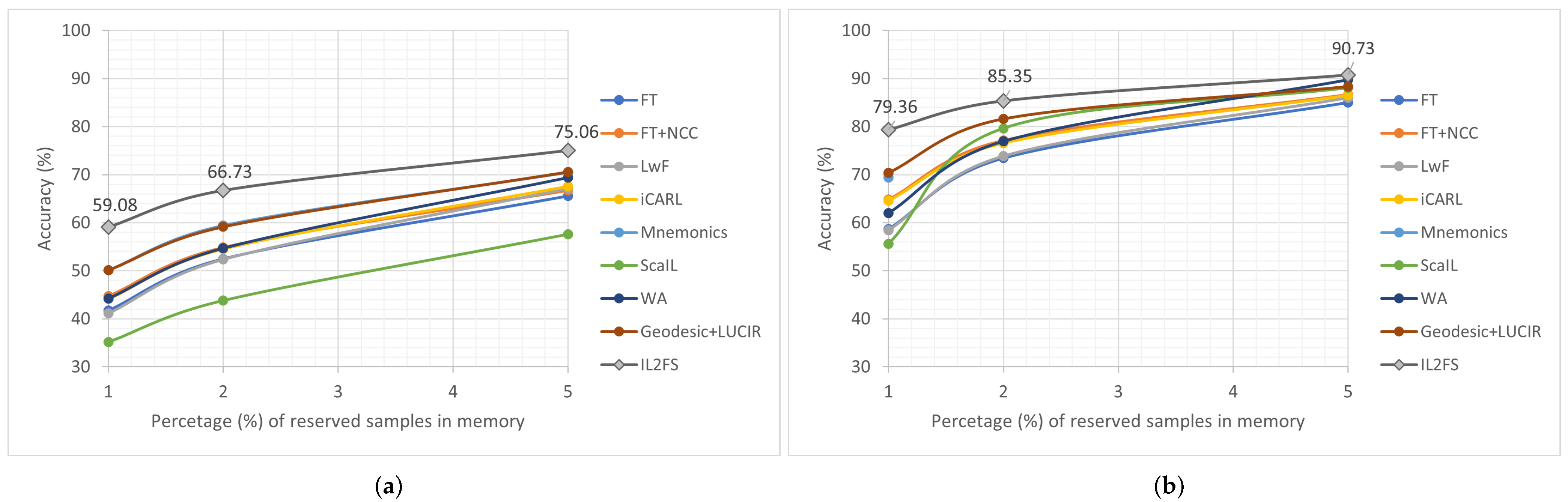
Regarding the evaluation which varies the number of reserved samples and the number of incremental stages, IL2FS showed a clear advantage compared to existing methods when the number of reserved samples in the memory is reduced. This issue is also observed when a greater number of CIL stages are achieved since a lower number of samples per class may be stored in memory. The above indicates that IL2FS preserves the learned knowledge better than compared methods throughout different incremental stages on the most challenging scenario possible for the evaluated datasets. On the other hand, as expected, every evaluated method improved its accuracy performance whenever the number of reserved samples in the memory is increased. However, by using a memory size near 5%, IL2FS still obtained the best average accuracy on the DREAMER, while it is similar with respect to the existing CIL methods for the DEAP dataset.
Concerning the effect of each component of IL2FS, weight aligning improved the average accuracy over the Fine-tuning method, which indicates that performing a bias correction is important to reduce the catastrophic forgetting problem in EEG-based emotion recognition. Then, margin ranking loss was incorporated to ensure an inter-class separation between each old class and its nearest class (old or new). Previous work in [
33] showed that a separation between old and new classes might be sufficient to help reduce the catastrophic forgetting. However, we found that this strategy [
33] on IL2FS obtained a similar average accuracy on DREAMER (58.55 ± 7.33% vs. 58.74 ± 07.56%), but the accuracy performance is drastically reduced on DEAP (53.36 ± 08.84% vs. 79.36 ± 04.68%). These results suggest that it is preferable to encourage an inter-class separation between each old class and its nearest class (old or new) instead of only ensuring a separation between old and new classes. Finally, unlike previous CIL works [
42,
43,
44] where triplet loss is mainly used to train embedding networks and provide an inter-class separation, we used such loss function to maintain the same aligning of the feature space learned at previous incremental stages. For this, IL2FS aims to produce near feature representations coming from a reference model and a new model for the same processed sample, while features from different samples are pushed away from each other by a small margin. This strategy showed to be beneficial for the CIL task in two emotion recognition datasets.
The presented study may contribute to designing and building more adaptive and scalable classifiers, as our study showed a first Class-incremental Learning solution to avoid reconfiguring the entire system when new emotions are incorporated sequentially. For this, we consider an evaluation of the most challenging scenario that may be built over the two public datasets for emotion recognition. However, our study did not consider other CIL settings and evaluation protocols. Furthermore, other preprocessing procedures and neural network architectures were also not explored.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}