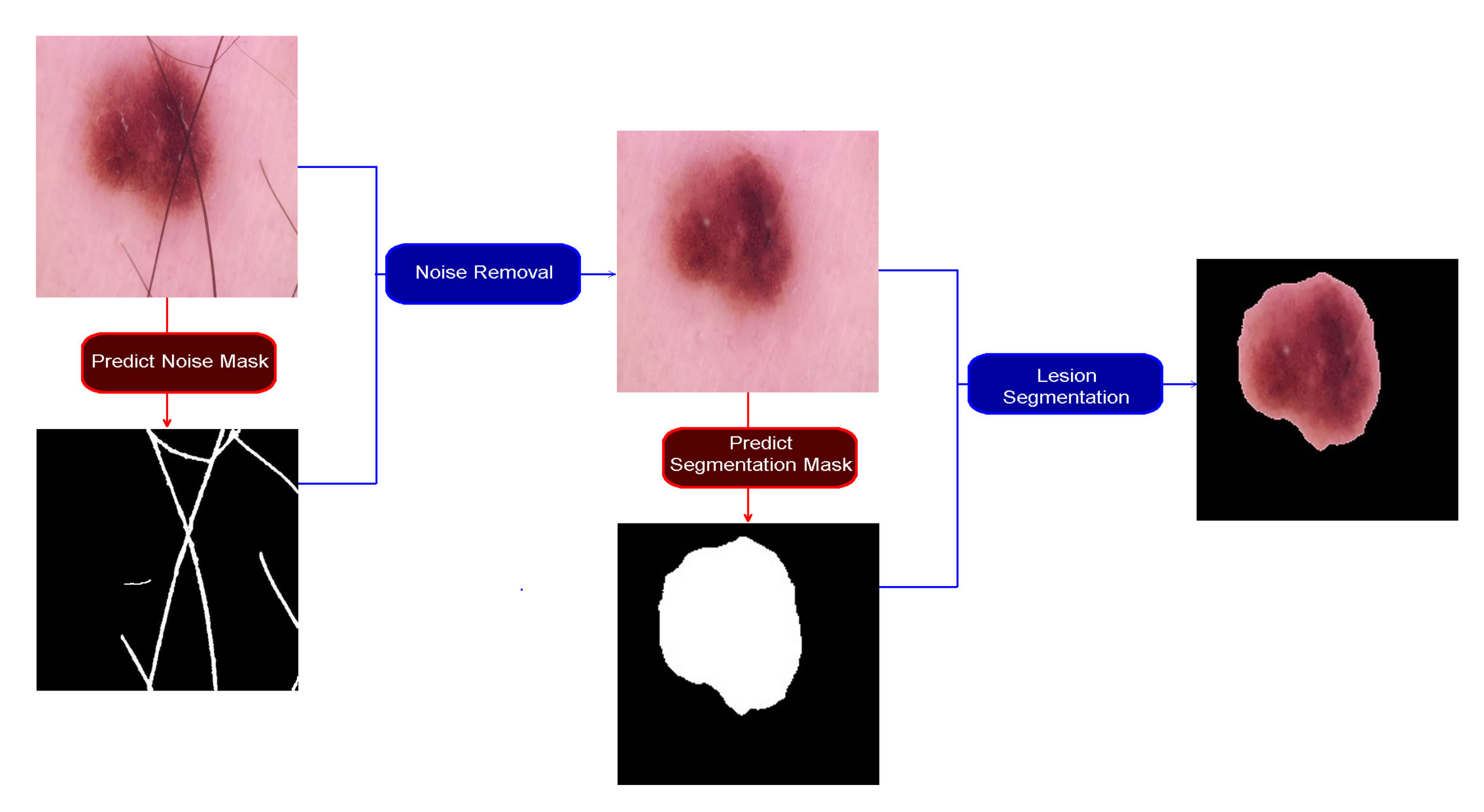
Our study consists of the noise removal and lesion segmentation phases. The data are divided into 70% training, 20% validation, and 10% test sets in both phases. These rates are acceptable values used in deep learning studies.
3.1. Datasets
Two ISIC datasets were used, taken from the 2018 ISIC Challenge. The first dataset consists of 10,015 RGB images with lesions in jpeg format. There are no segmentation masks in the dataset of 10,015 images from the ISIC 2018 [
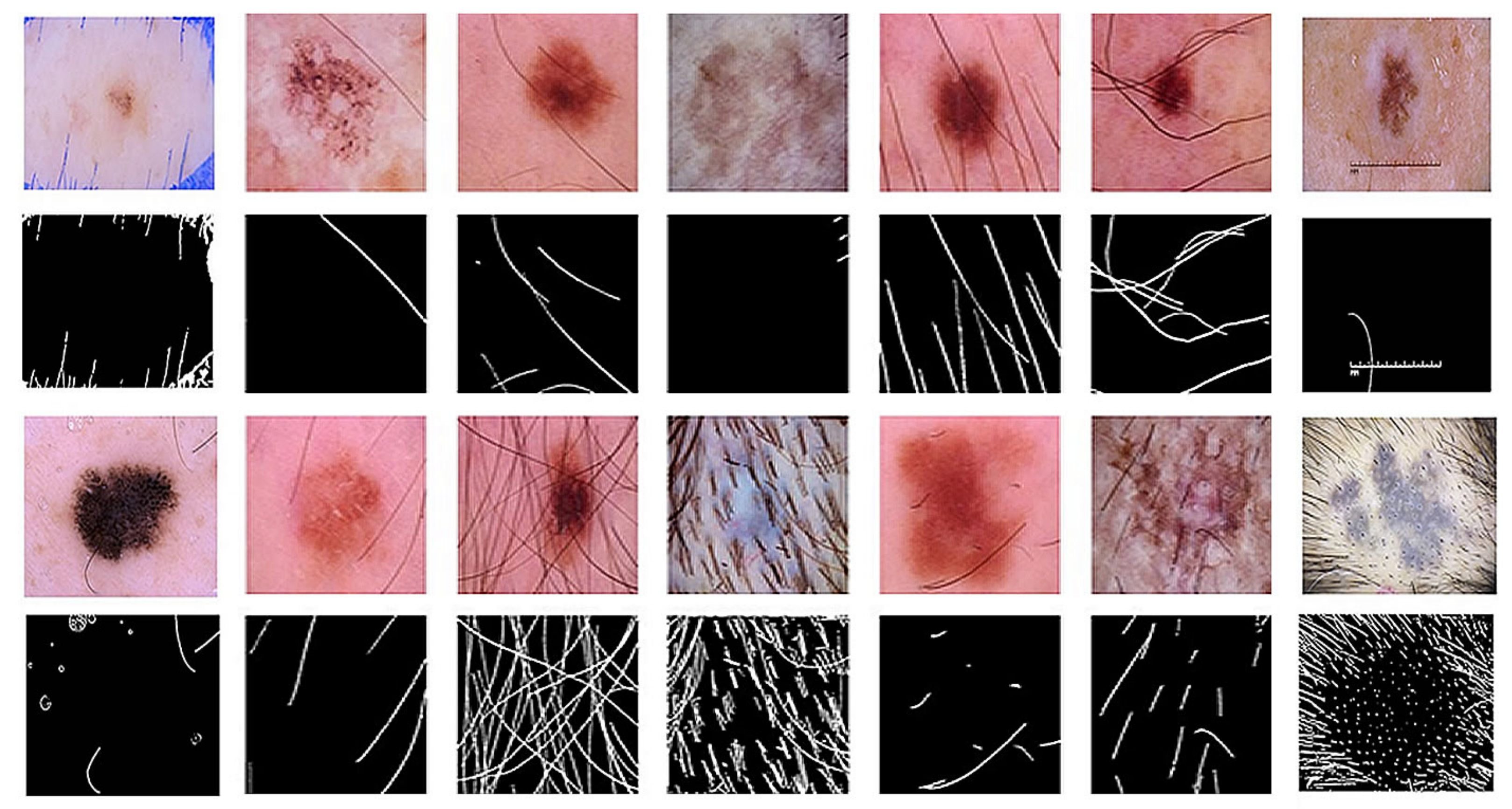
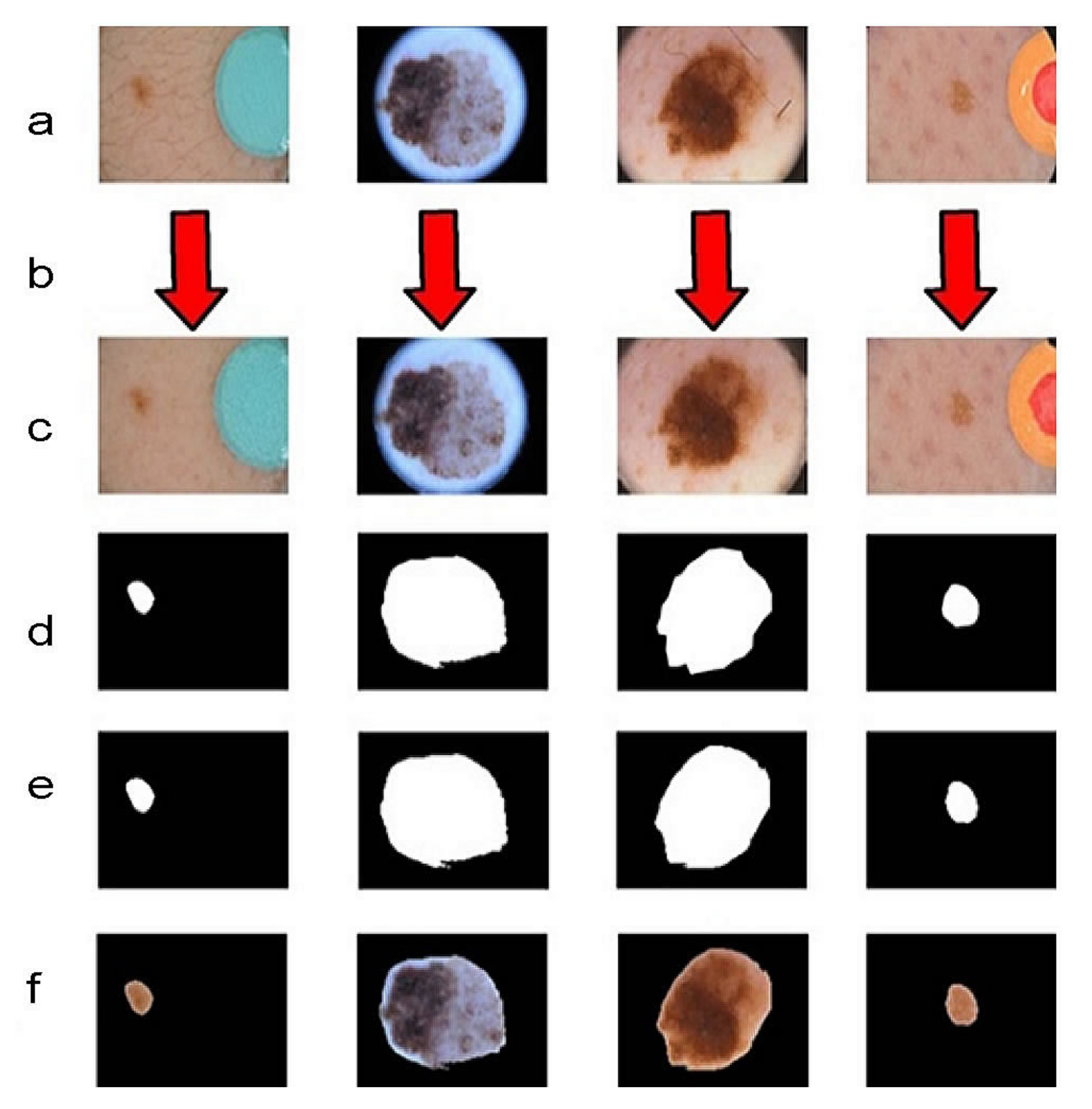
34]. Therefore, we can only use this dataset for noise removal phase. From this dataset, we created 2500 images containing noise, ink and ruler traces, and water bubble noise. We created 2500 noise masks from the cleaned dataset and increased them to 10,000 in the noise removal phase by data expansion. This dataset is now called the cleanup dataset. The process of creating this dataset is shown in
Figure 2. We could have created a mask by using fireworks without other processes; however, it was easier for us to use a different process. We used OpenCV functions. Functions and parameters used in the processes:
1. Adaptive thresholding: If the pixel value is less than the threshold, it is set to 0. Otherwise, it is set to a maximum value. The algorithm determines the threshold value for a pixel based on a small area around the pixel. Thus, we get different thresholds for other regions of the same image, leading to better results for images those suffer with uneven lighting.
We used cv2.adaptiveThreshold(image, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 8).
First parameter: Original image. Second parameter: Maximum value.
Third parameter: This is using the arithmetic mean of the local pixel neighborhood to compute our threshold value.
Fourth parameter: THRESH_BINARY indicates that any pixel value that passes the threshold test will an output value of 0. Otherwise, it will have a value of 255.
Fifth parameter: The mean grayscale pixel intensity value of each 11 × 11 sub-region will be computed in the image to compute threshold value.
Sixth parameter: A constant which is subtracted from the mean or weighted mean calculated.
2. Median filter: The function computes the median of all the pixels under the kernel window and the central pixel is replaced with this median value. This way we can remove small noises from the image. We used cv2.medianBlur(image, 5) (5 is kernel size).
3. Morphological operations.
(a) The opening process is obtained by the erosion of an image followed by a dilation. Erosion erodes away the boundaries of foreground object. Furthermore, dilation increases the white region in the image or size of foreground object increases. It is useful for removing small objects. A kernel tells us how to change the value of any given pixel by combining it with different amounts of the neighboring pixels. kernel = np.ones((3,3),np.uint8).
We used cv.morphologyEx(image, cv.MORPH_OPEN, kernel).
(b) The closing process is the reverse of opening, dilation followed by erosion. It is useful for closing small holes in foreground objects or small black dots on the object [
35].
We used cv.morphologyEx(img, cv.MORPH_CLOSE, kernel).
In this study, three different datasets were used to increase the total number of images because the first ISIC 2018 dataset did not contain segmentation masks.
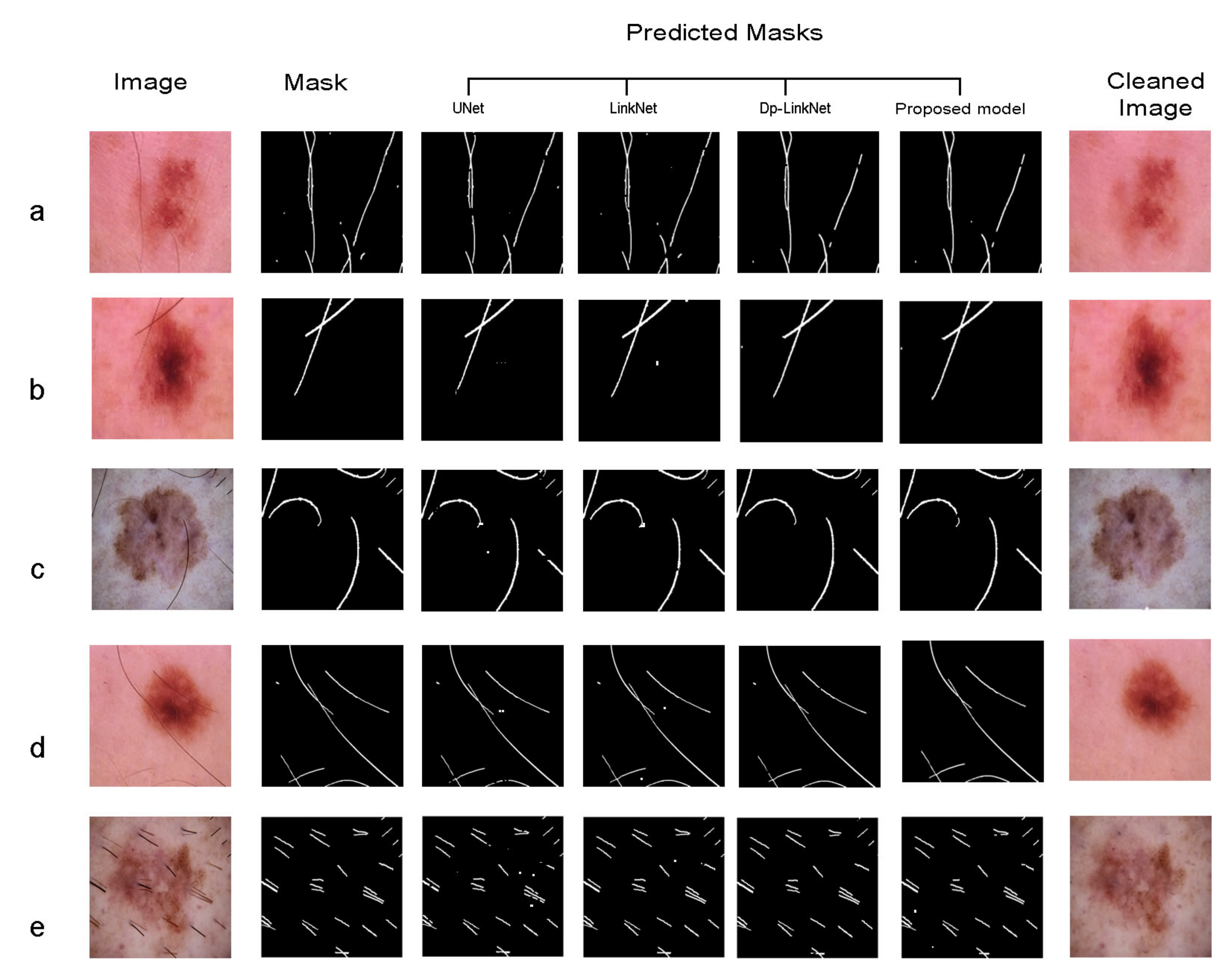
Figure 3 shows examples of our cleaned dataset.
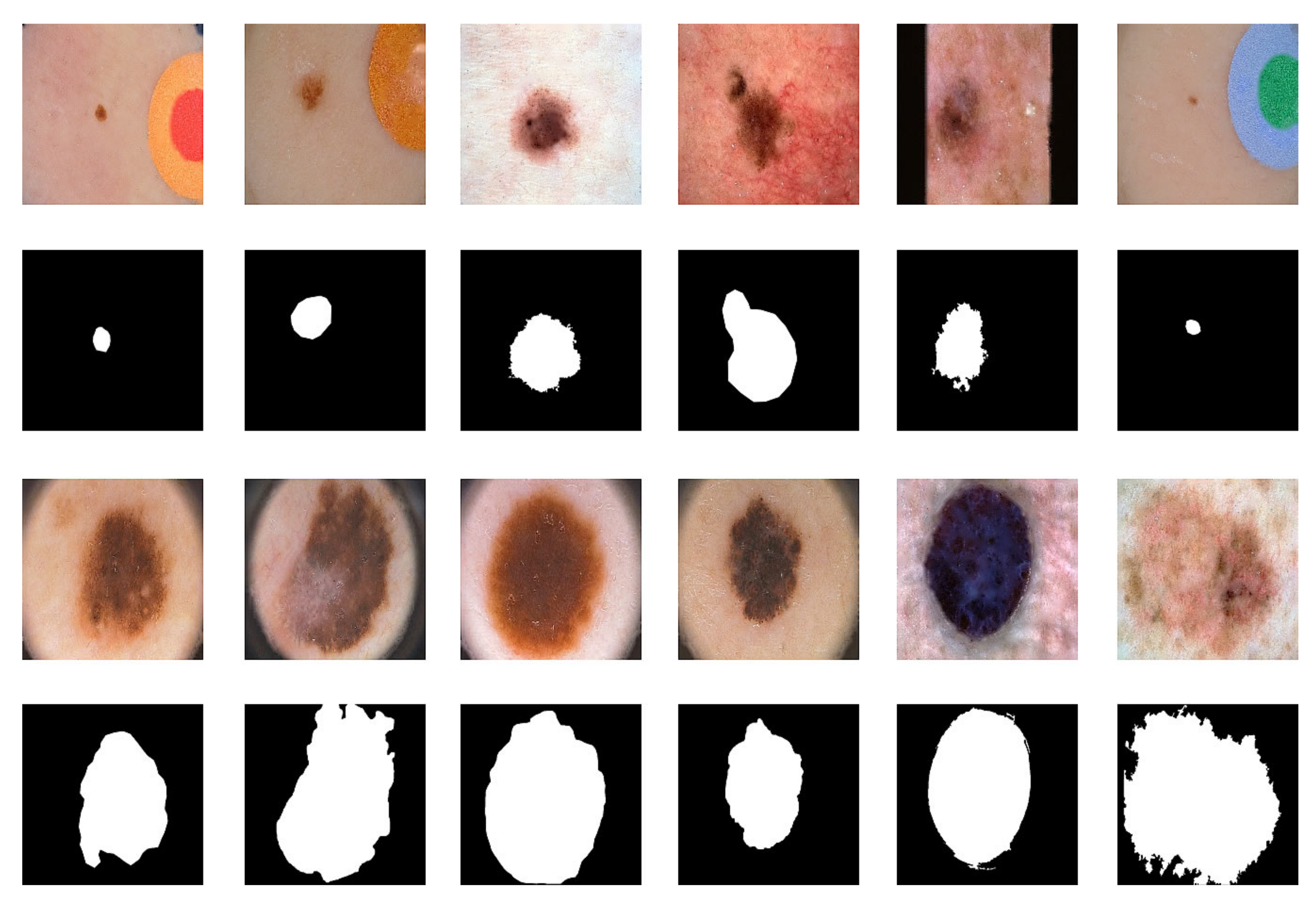
The second ISIC dataset (13,000 images in jpeg format and masks in png format) [
36] and the PH2 dataset (200 images and masks in .bmp format) [
37] were used for lesion segmentation. The dataset was increased to 52,800 by data expansion. This dataset is now called the segmentation dataset.
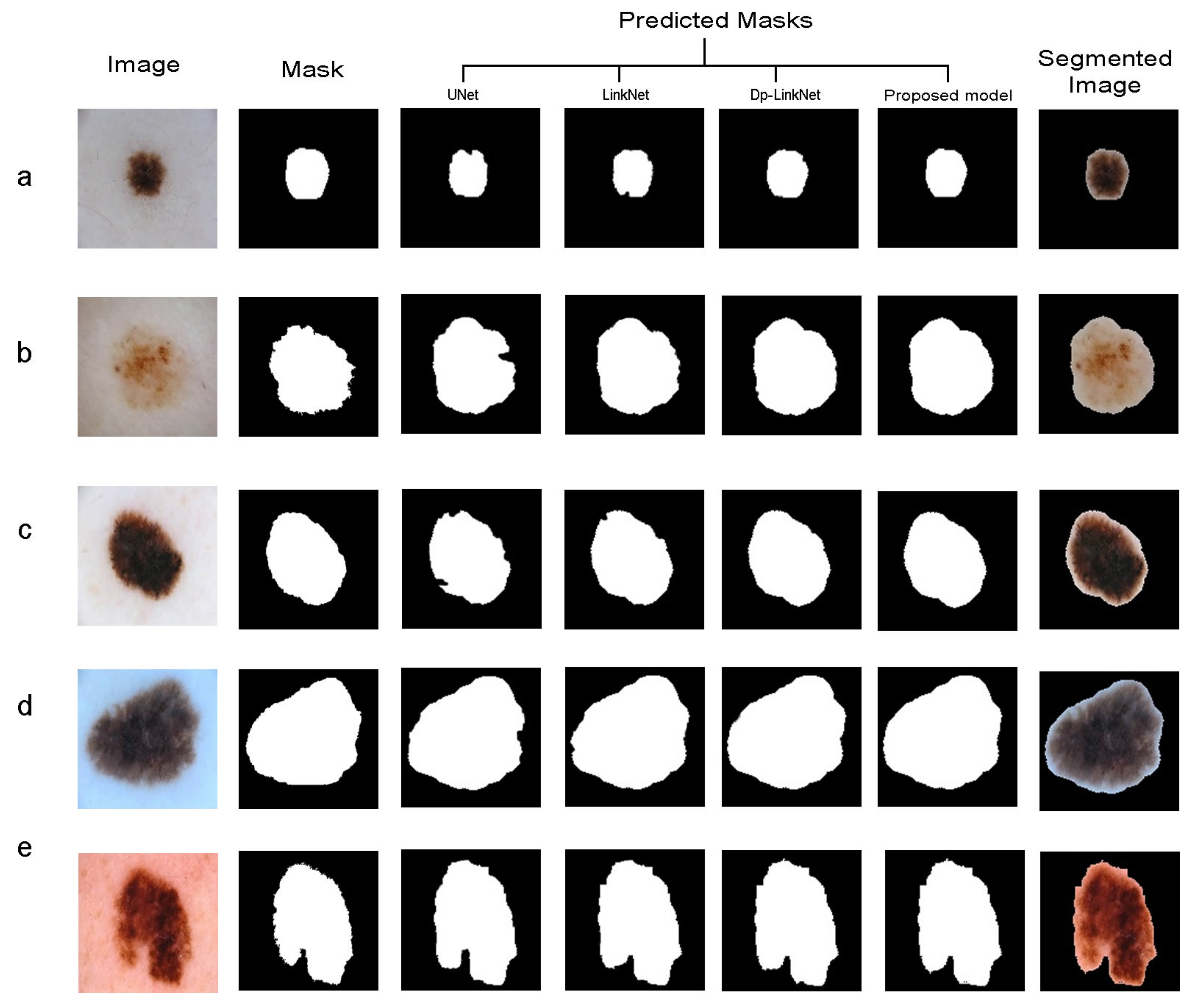
Figure 4 shows some examples of the segmentation dataset.
3.3. EfficientNet and ResNet
The basic building block of the EfficientNet architecture is Mobile Inverted Bottleneck Convolution (MBConv) [
38] with a squeeze and excitation optimization. The concept of MBConv is shown in
Figure 4. The family of EfficientNet networks has different numbers of these MBConv blocks. From EfficientNetB0 to EfficientNetB7, depth, width, resolution, and model size continue to increase, and the accuracy also improves. The best performing model, EfficientNetB7, outperforms previous state-of-the-art CNNs in terms of ImageNet accuracy and is also 8.4-fold smaller and 6.1-fold faster than the best existing CNN [
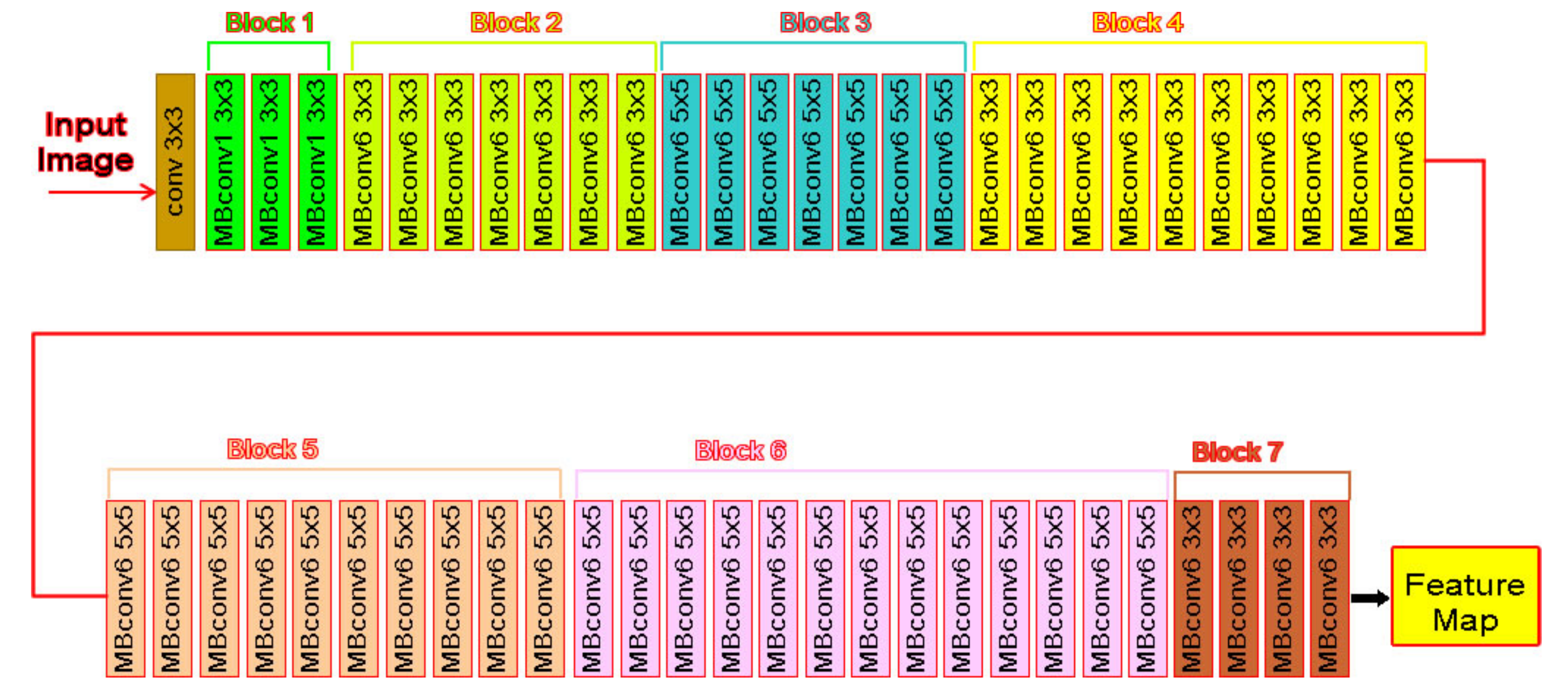
21]. The network architecture of EfficientNetB7 is shown in
Figure 6. It can be divided into seven blocks based on the filter size, striding, and a number of channels [
23].
In semantic segmentation, each pixel of an image is labeled, and therefore the preservation of spatial information is of paramount importance [
26]. EfficientNet is widely used in image classification and segmentation. For example, Chetoui et al. [
39] used EfficientNet to achieve the best performance in work on diabetic retinopathy (DR). Kamble et al. [
40] used EfficientNet as an encoder combined with UNet++ and achieved high accuracy in optic disk segmentation (OD). Messaoudi et al. [
41] used EfficientNet to convert a 2D classification network into a 3D semantic segmentation of brain tumors, which also resulted in satisfactory performance [
24]. The figure shows the architecture of EfficientNetB7.
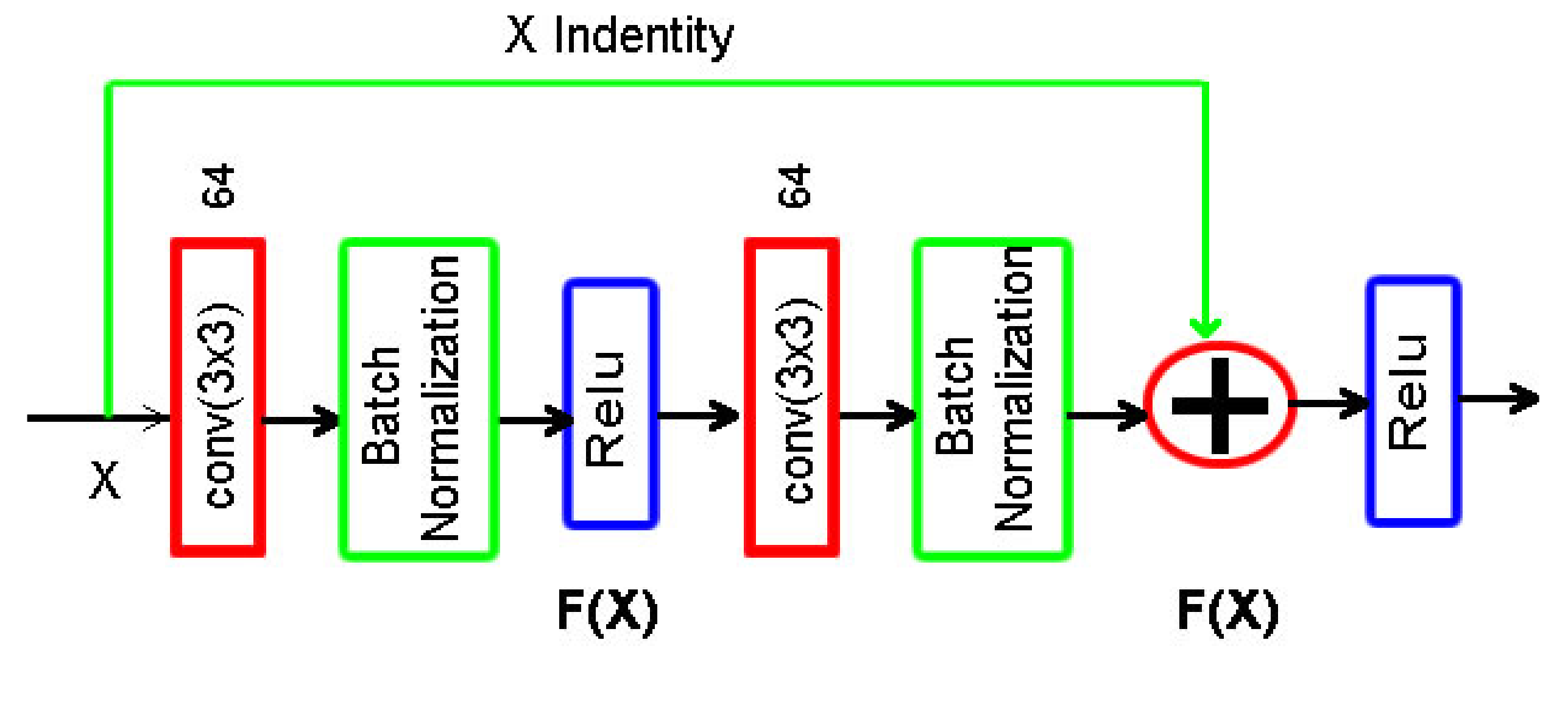
The formulation of F(x) + x can be realized by neural feedforward networks with “shortcut connections”. The ResNet architecture the network is shown in
Figure 7. Shortcut connections are connections that skip one or more layers [
42].
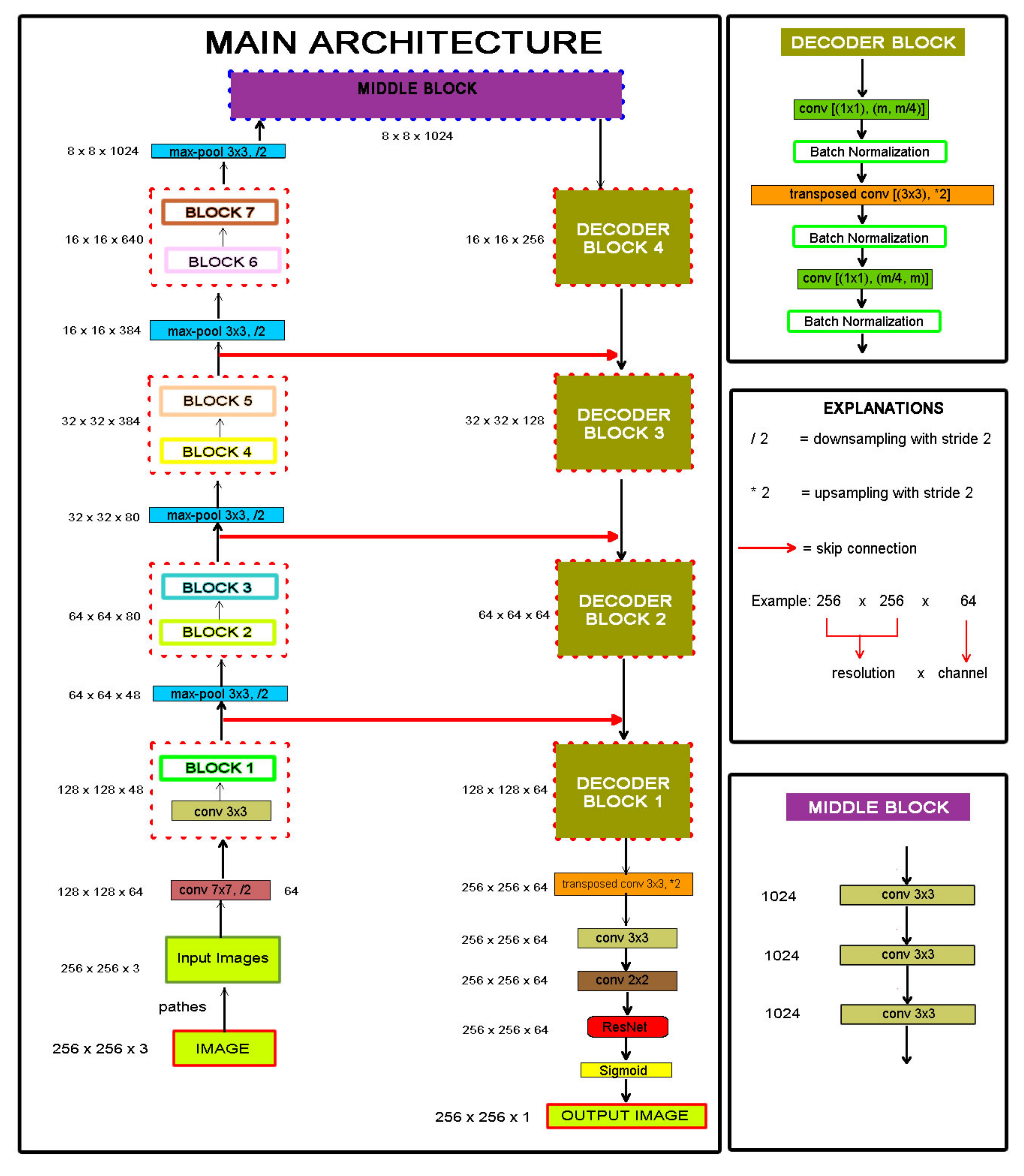
3.4. Proposed Model: LinkNet-B7
The optimizer was determined to be Adam. Sigmoid was used as the output function. The activation function for the output is usually chosen as a sigmoid function when there are two potential output classes [
43]. The parameters are given in
Table 1.
There are four encoder blocks and four decoder blocks [
29]. LinkNet was chosen because of its high accuracy and low epoch time in medical image segmentation [
30]. We used EfficientNetB7 as the encoder. This is because it has higher accuracy and parameter count than other types [
30]. We proposed a LinkNet-based deep learning algorithm called LinkNet-B7 with input size 256 × 256 × 3 and EfficentNetB7 as the encoder.
Table 2 shows the structure of the encoder.
We added a single ResNet block to our model before the last layer, because other ResNet models have more layers which increases the epoch time and slows down the model. Moreover, we used a middle block before the decoder blocks. This way we could obtain more features before the decoder blocks and thus improve the accuracy.
Finally, we used a modified hybrid model called LinkNet-B7. The first block of the model performs a convolution of the input image using a kernel of size 7 × 7 with a stride of 2. A max-pooling layer follows this with a stride of 2. The model is shown in
Figure 8.
3.6. Noise Removal Phase
• Step 1: The cleanup dataset is divided into 112,000 training, 32,000 validation, and 16,000 test datasets.
• Step 2: The model has been trained for 5000 epochs.
• Step 3: Make predictions with the model.
• Step 4: Postprocess: Remove noise from the results using median filter and morphological operations (opening, closing). During postprocessing, the noise was removed from the image using the mask estimated by the INPAINT function.
3.7. Lesion Segmentation Phase
The noise in the dataset was removed using the model created in the previous step. The training accuracy of nearly 2% increases with the dataset that has been cleared of noise.
• Step 1: The segmentation dataset is divided into 591,360 training, 168,960 validation, and 84,480 datasets.
• Step 2: The model has been trained for 5000 epochs.
• Step 3: Make predictions with the model.
• Step 4: Postprocess: Remove noise from the results using median filter and morphological operations (opening, closing).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}