
CASI-Net: A Novel and Effect Steel Surface Defect Classification Method Based on Coordinate Attention and Self-Interaction Mechanism


Abstract
:1. Introduction
- An end-to-end CASI-Net model is proposed, which combines location information and channel attention to locate defects more accurately. In addition, we construct a self-interaction module based on the biological visual interaction mechanism to learn more detailed feature information. Finally, CASI-Net can use very few parameters to achieve accurate classification.
- We introduce the CA block to CASI-Net. The CA block can not only capture cross-channel information but also capture location information, which can help CASI-Net to locate and identify targets of interest more accurately.
- The self-interaction module based on biological mechanisms is constructed to enrich the representation of feature maps, which is helpful for better recognition and classification.
- To evaluate the performance of the CASI-Net for real industrial data, we use the NEU dataset provided by Northeastern University to validate the performance of CASI-Net. The classification results on NEU will verify the effectiveness of our proposed network.
2. Related Work
2.1. Convolutional Neural Networks
2.2. Attention Mechanisms
2.3. Biological Visual Interaction Mechanism
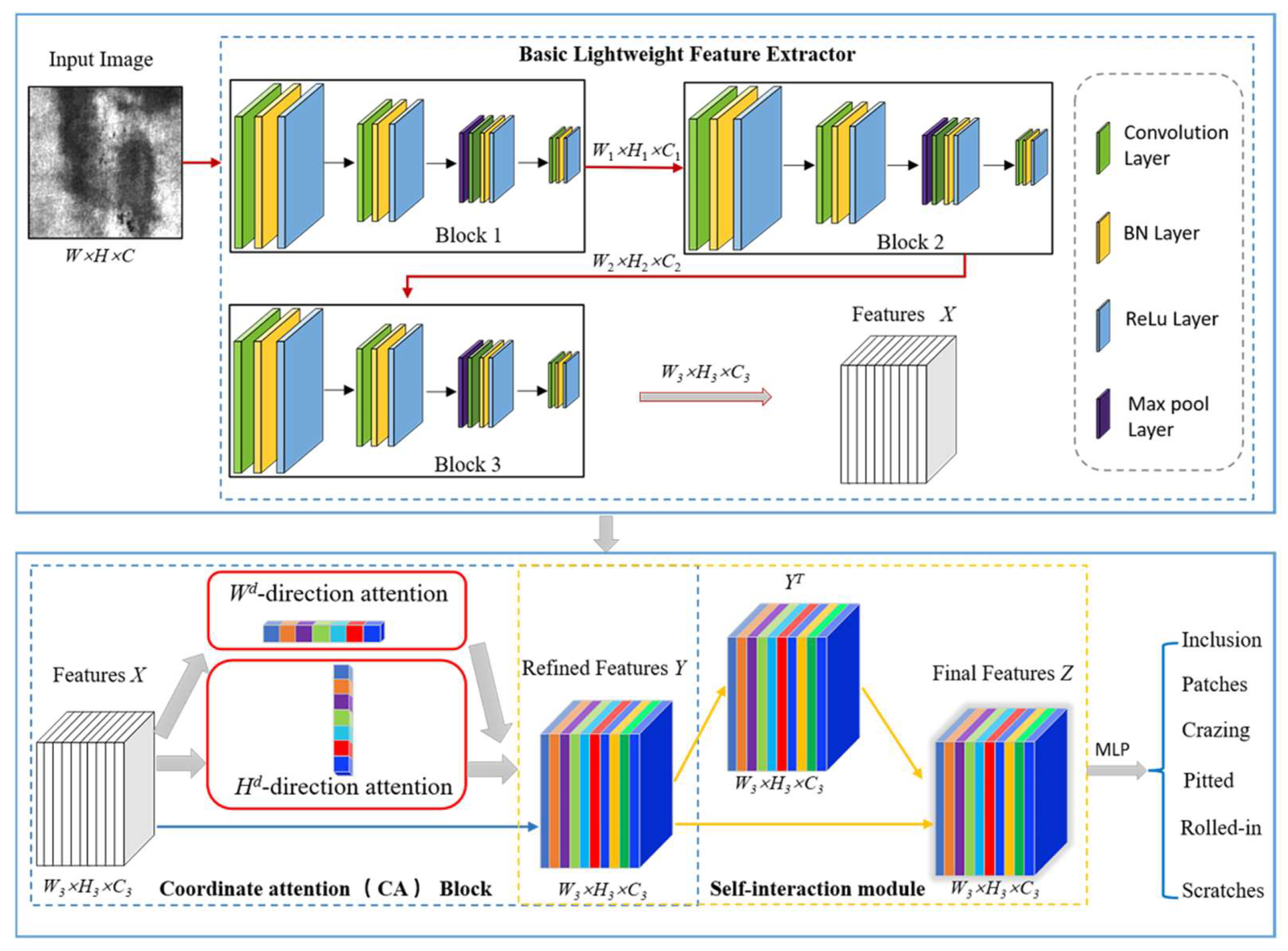
3. Proposed Method
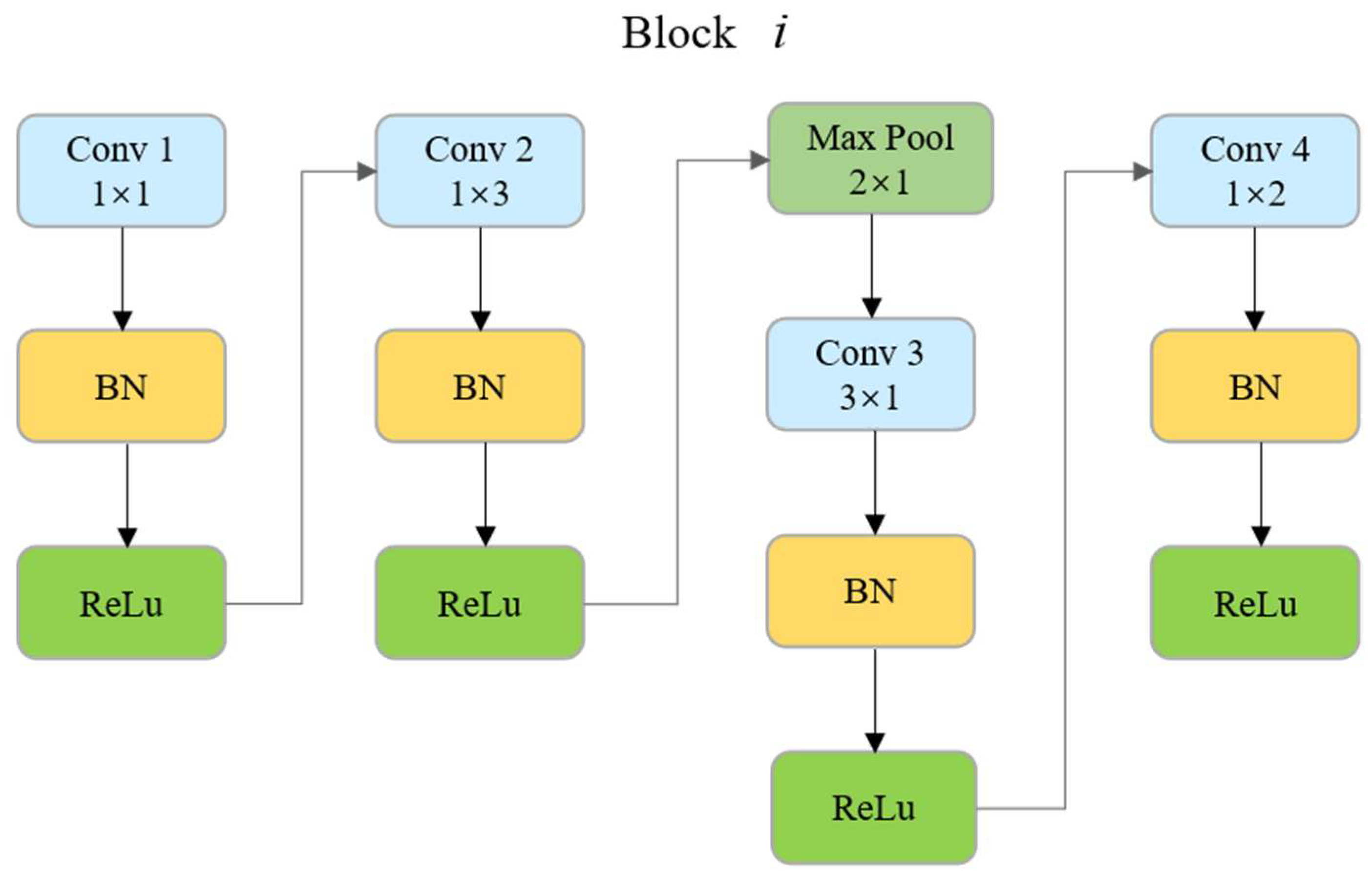
3.1. Basic Lightweight Feature Extractor
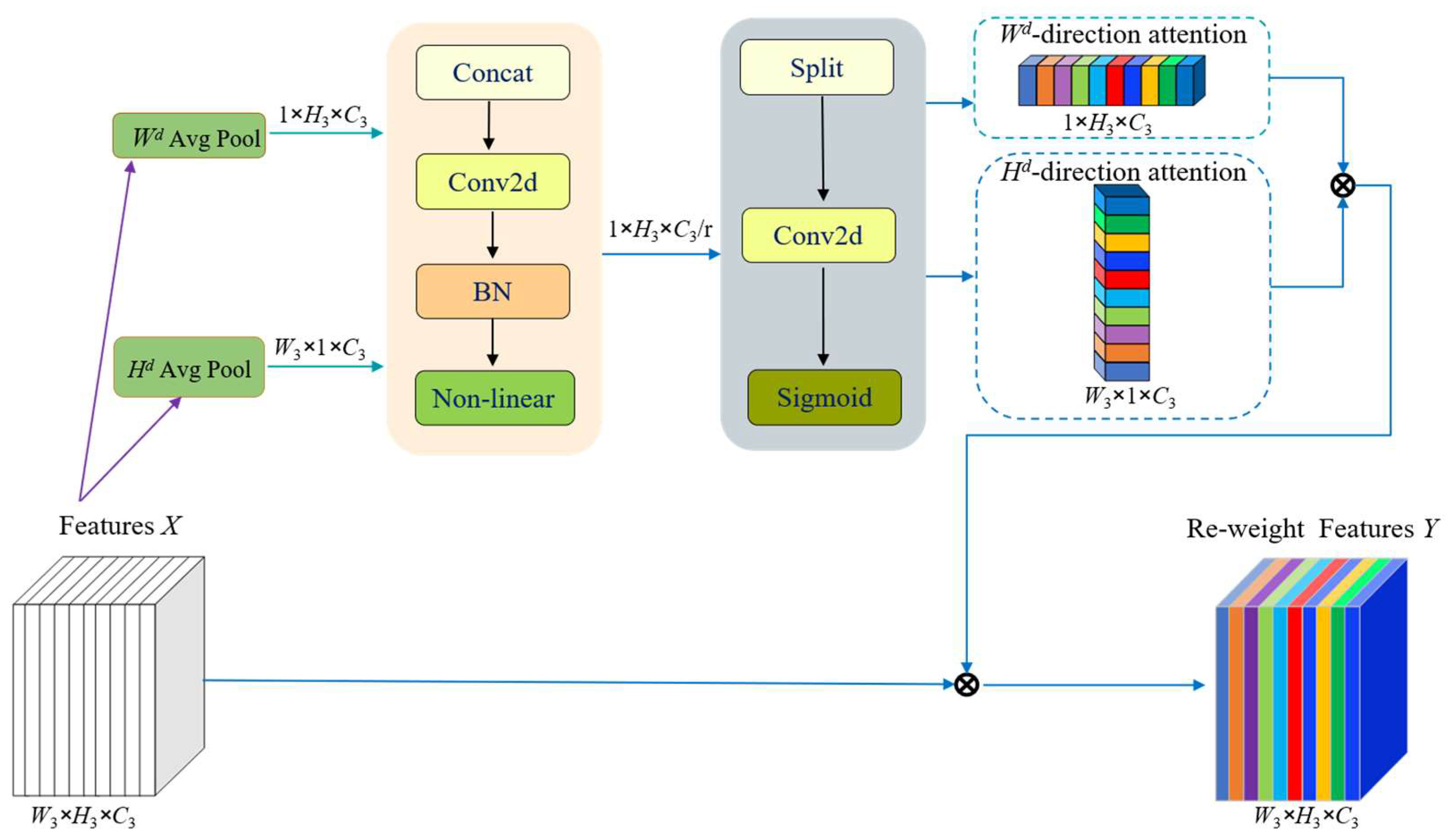
3.2. Coordinate Attention
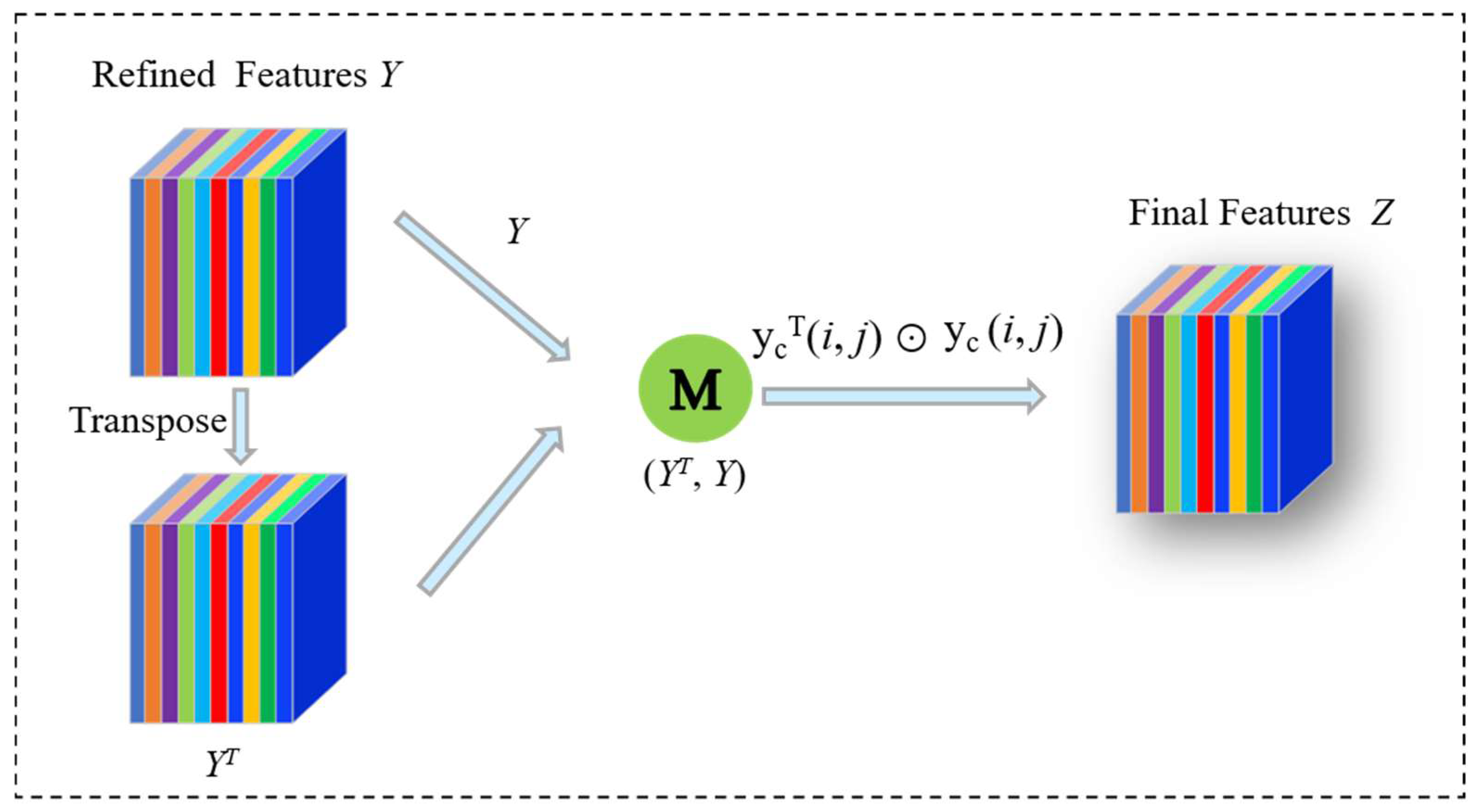
3.3. Self-Interaction Based on Biological Vision
4. Experiments
4.1. Dataset
4.2. Enhanced Dataset
4.3. Implementation Details
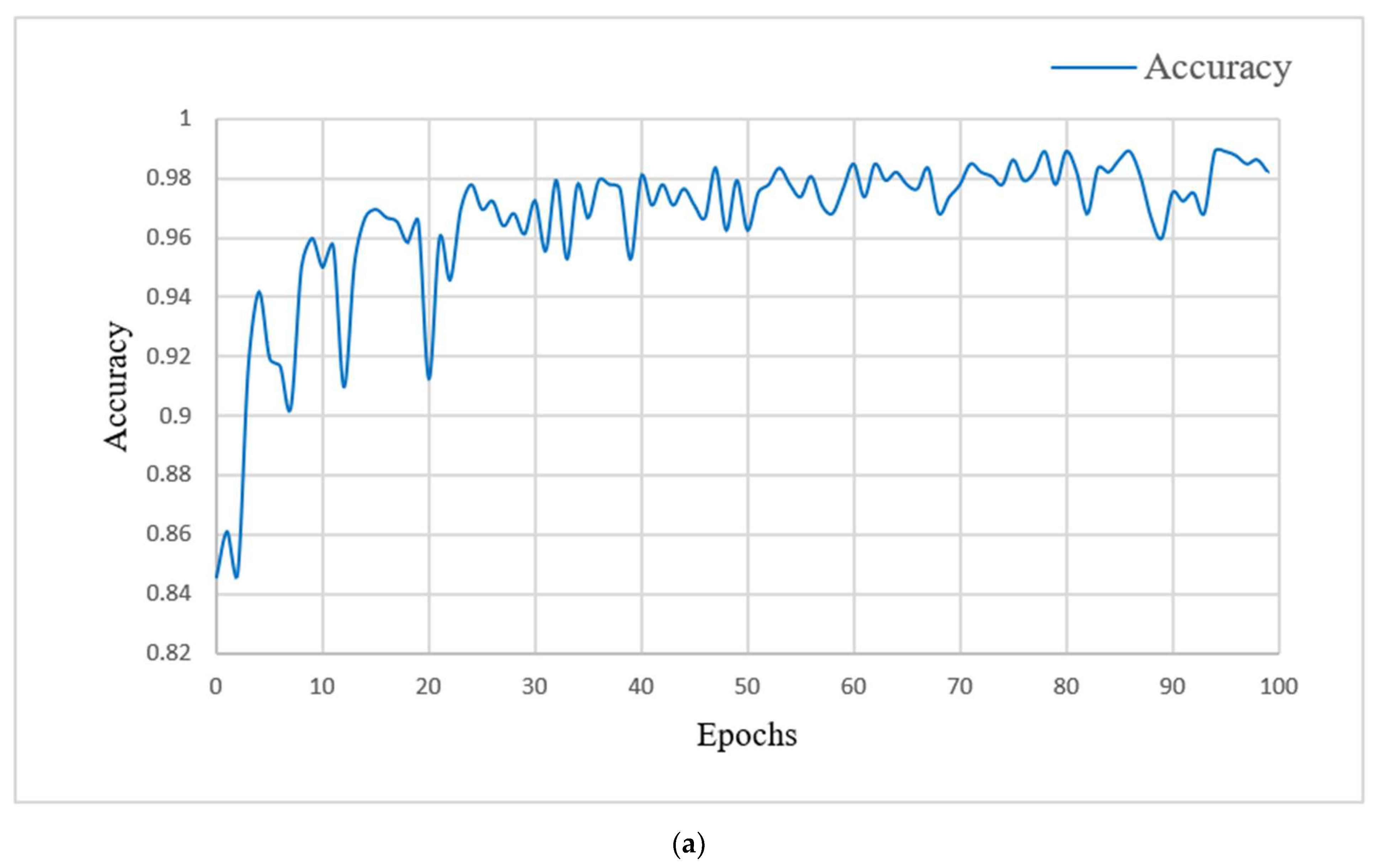
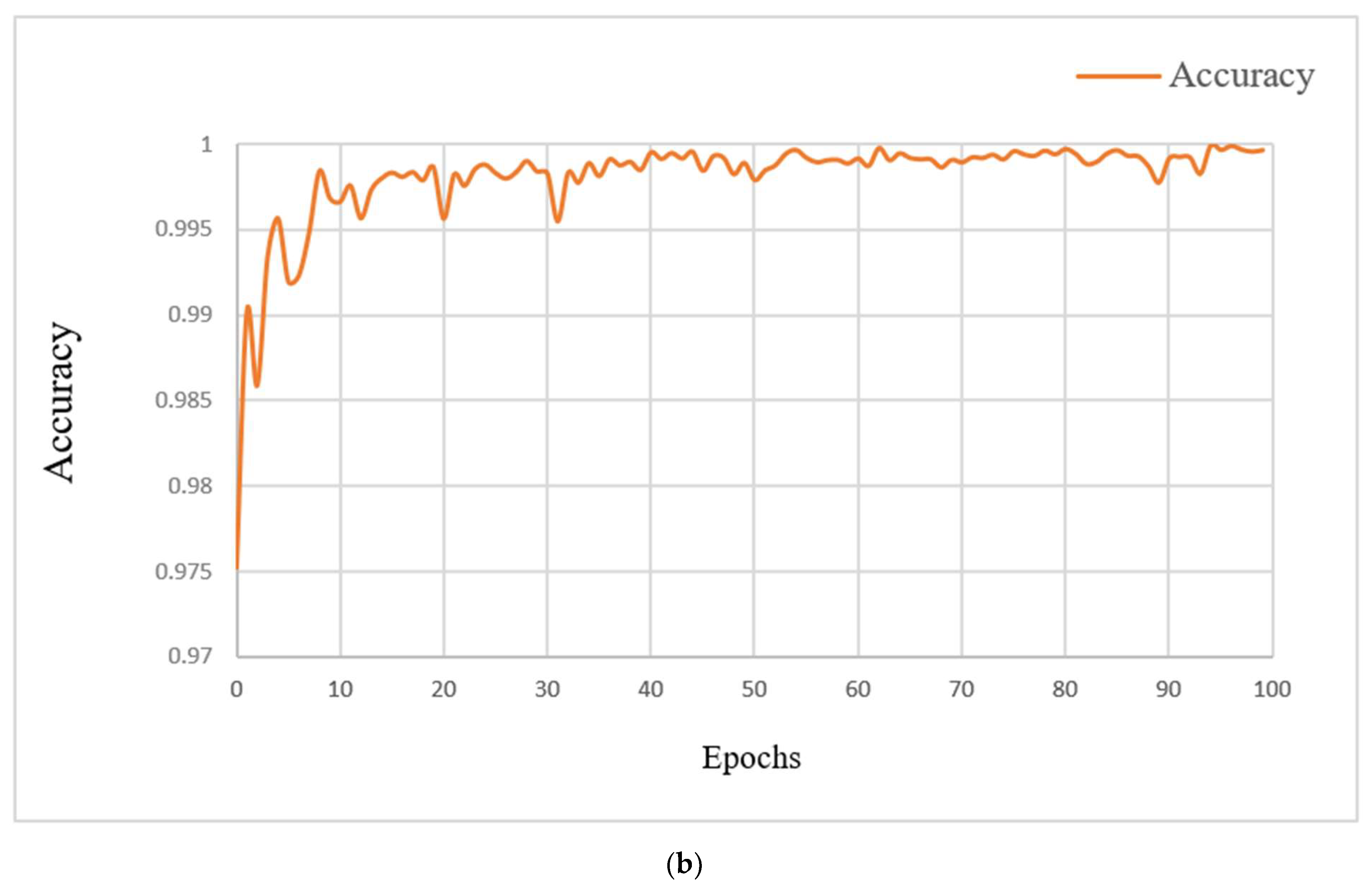
4.4. Performance Analysis
4.5. Comparison with State-of-the-Art Methods
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kechen, S.; Yunhui, Y. A noise robust method based on completed local binary patterns for hot-rolled steel strip surface defects. Appl. Surf. Sci. 2013, 285, 858–864. [Google Scholar]
- Di, H.; Ke, X.; Peng, Z.; Dongdong, Z. Surface defect classification of steels with a new semi-supervised learning method. Opt. Lasers Eng. 2019, 117, 40–48. [Google Scholar] [CrossRef]
- Neogi, N.; Mohanta, D.K.; Dutta, P.K. Review of vision-based steel surface inspection systems. EURASIP J. Image Video Process. 2014, 50, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Fu, G.; Sun, P.; Zhu, W.; Yang, J.; Cao, Y.; Yang, M.Y.; Cao, Y. A deep-learning based approach for fast and robust steel surface defects classification. Opt. Lasers Eng. 2019, 121, 397–405. [Google Scholar] [CrossRef]
- Bo, T.; Jianyi, K.; Shiqian, W. Review of surface defect detection based on machine vision. J. Image Graph. 2017, 22, 1640–1663. [Google Scholar]
- Tao, X.; Hou, W.; Xu, D. A survey of surface defect detection methods based on deep learning. Acta Autom. Sin. 2021, 47, 1017–1034. [Google Scholar]
- Li, H.; Fu, X.; Huang, T. Research on surface defect detection of solar pv panels based on pre-training network and feature fusion. IOP Conf. Ser. Earth Environ. Sci. 2021, 651, 022071. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceeding of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.; Wang, H.; Xu, F.; Jin, Y.Q. Target classification using the deep convolutional networks for sar images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4806–4817. [Google Scholar] [CrossRef]
- Hamdia, K.M.; Ghasemi, H.; Bazi, Y.; AlHichri, H.; Alajlan, N.; Rabczuk, T. A novel deep learning based method for the computational material design of flexoelectric nanostructures with topology optimization. Finite Elem. Anal. Des. 2019, 165, 21–30. [Google Scholar] [CrossRef]
- Jeon, M.; Jeong, Y.-S. Compact and Accurate Scene Text Detector. Appl. Sci. 2020, 10, 2096. [Google Scholar] [CrossRef] [Green Version]
- Vu, T.; Nguyen, C.V.; Pham, T.X.; Luu, T.M.; Yoo, C.D. Fast and Efficient Image Quality Enhancement via Desubpixel Convolutional Neural Networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018; p. 11133. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Freeman, I.; Roese-Koerner, L.; Kummert, A. Effnet: An efficient structure for convolutional neural networks. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 6–10. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Ma, S.; Ban, Y.; Daichen, Z. Survey of convolutional neural network. Mod. Inf. Technol. 2021, 5, 11–15. [Google Scholar]
- Lecun, Y.; Bottou, L. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. Squeezenet: Alexnet-level accuracy with 50x fewer parameters and <0.5 mb model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Hartwig, A. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Jie, H.; Li, S.; Gang, S.; Albanie, S. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar]
- Chen, Y.; Kalantidis, Y.; Li, J.; Yan, S.; Feng, J. a2-nets: Double attention networks. arXiv 2018, arXiv:1810.11579. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Bello, I.; Zoph, B.; Le, Q.; Vaswani, A. Attention augmented convolutional networks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seul, Korea, 27 October–2 November 2019; pp. 3286–3295. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. CCNet: Criss-cross attention for semantic segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Hou, Q.; Zhang, L.; Cheng, M.M.; Feng, J. Strip pooling: Rethinking spatial pooling for scene parsing. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4002–4011. [Google Scholar]
- Rosa, M.; Palmer, S.M.; Gamberini, M.; Burman, K.J.; Yu, H.-H.; Reser, D.H.; Bourne, J.A.; Tweedale, R.; Galletti, C. Connections of the dorsomedial visual area: Pathways for early integration of dorsal and ventral streams in extrastriate cortex. J. Neurosci. 2009, 29, 4548–4563. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Milner, D.A. How do the two visual streams interact with each other? Exp. Brain Res. 2017, 235, 1297–1308. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wei, B.; He, H.; Hao, K.; Gao, L.; Tang, X.S. Visual interaction networks: A novel bio-inspired computational model for image classification. Neural Netw. 2020, 130, 100–110. [Google Scholar] [CrossRef] [PubMed]
- Van Polanen, V.; Davare, M. Interactions between dorsal and ventral streams for controlling skilled grasp. Neuropsychologia 2015, 79, 186–191. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Holtzman, J.D. Interactions between cortical and subcortical visual areas: Evidence from human commissurotomy patients. Vis. Res. 1984, 24, 801–813. [Google Scholar] [CrossRef]
- Das, A.; Gilbert, C.D. Topography of contextual modulations mediated by short-range interactions in primary visual cortex. Nature 1999, 399, 655. [Google Scholar] [CrossRef] [PubMed]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Chen, F.C.; Jahanshahi, R.M.R. NB-CNN: Deep learning-based crack detection using convolutional neural network and Naïve bayes data fusion. IEEE Trans. Ind. Electron. 2018, 65, 4392–4400. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. J. Mach. Learn. Res. 2011, 15, 315–323. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Original |
Luminance () |
Luminance () | Noise (20 db) | Noise (35 db) | Blur (2) | Blur (5) |
|---|---|---|---|---|---|---|---|
| BLFE + MLP | 94.79 | 92.93 | 82.54 | 80.33 | 92.87 | 94.31 | 80.62 |
| BLFE + SI + MLP | 95.22 | 93.53 | 84.66 | 85.34 | 93.26 | 94.53 | 82.33 |
| BLFE + CA + MLP | 95.47 | 93.68 | 87.14 | 90.63 | 94.97 | 95.26 | 90.19 |
| BLFE + CA + SI + MLP | 95.83 | 94.21 | 92.56 | 94.71 | 95.26 | 95.66 | 91.62 |
| Method | Params | Accuracy |
|---|---|---|
| ResNet | 25.56 M | 95.09 |
| EffNet | 2.21 M | 94.81 |
| MobileNet | 2.23 M | 95.57 |
| CASI-Net | 2.22 M | 95.83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Wu, C.; Han, Q.; Hou, M.; Chen, G.; Weng, T. CASI-Net: A Novel and Effect Steel Surface Defect Classification Method Based on Coordinate Attention and Self-Interaction Mechanism. Mathematics 2022, 10, 963. https://doi.org/10.3390/math10060963
Li Z, Wu C, Han Q, Hou M, Chen G, Weng T. CASI-Net: A Novel and Effect Steel Surface Defect Classification Method Based on Coordinate Attention and Self-Interaction Mechanism. Mathematics. 2022; 10(6):963. https://doi.org/10.3390/math10060963
Chicago/Turabian StyleLi, Zhong, Chen Wu, Qi Han, Mingyang Hou, Guorong Chen, and Tengfei Weng. 2022. "CASI-Net: A Novel and Effect Steel Surface Defect Classification Method Based on Coordinate Attention and Self-Interaction Mechanism" Mathematics 10, no. 6: 963. https://doi.org/10.3390/math10060963
APA StyleLi, Z., Wu, C., Han, Q., Hou, M., Chen, G., & Weng, T. (2022). CASI-Net: A Novel and Effect Steel Surface Defect Classification Method Based on Coordinate Attention and Self-Interaction Mechanism. Mathematics, 10(6), 963. https://doi.org/10.3390/math10060963