
Scale and Background Aware Asymmetric Bilateral Network for Unconstrained Image Crowd Counting


Abstract
:1. Introduction
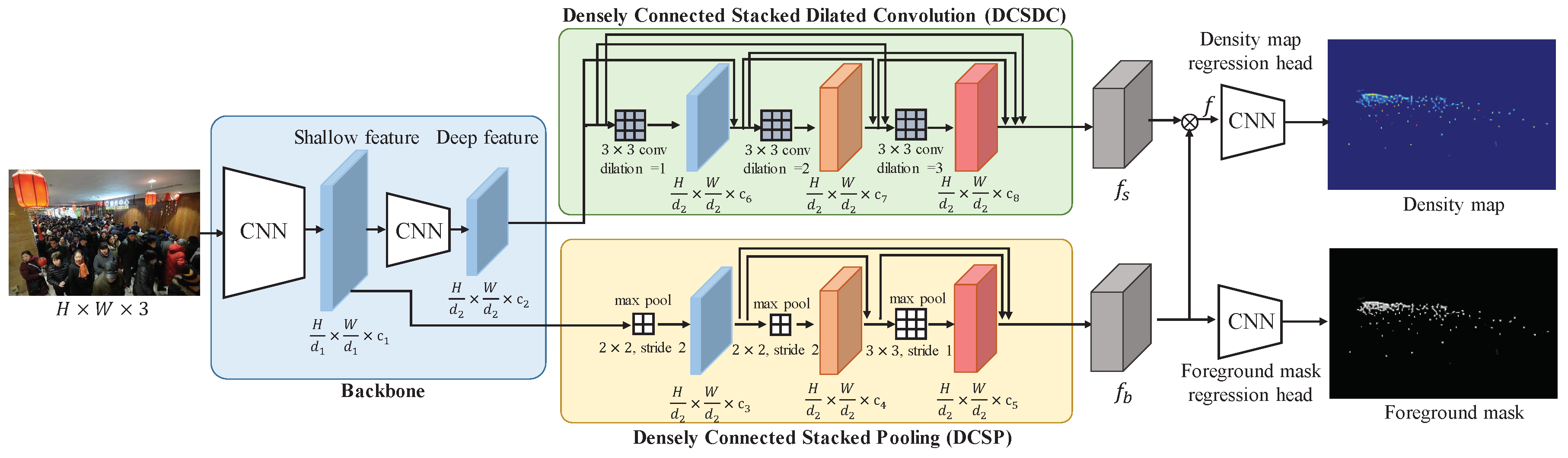
- We propose a novel asymmetric bilateral network to handle scale variation and background noise in a unified framework. The scale-aware feature is captured by a multi-convolutional branch based on one deep feature layer. The background-aware feature is captured by a multi-pooling branch based on one shallow feature layer. These two features are fused in an attention manner. On the contrary, most existing methods organize scale and background branches in a symmetric/dual structure, that is, share the image feature from one or multiple common layers.
- A new DCSP sub-network is proposed to capture background-aware feature, which can fuse features with several receptive fields by several pooling layers with different strides to reduce the impact of background noise, and without any extra learnable parameters.
- We propose a new DCSDC sub-network to extract multi-scale information based on one deep feature layer, which densely connected several stacked dilated convolution layers with different dilation rates to capture the scale-aware feature. Moreover, the scale-aware feature is refined by the background-aware feature to ensure that the final feature can handle scale and background information simultaneously.
2. Related Work
2.1. Handle Scale Variation
2.2. Handle Background Noise
2.3. Handle Scale Variation and Background Noise Simultaneously
3. Methodology
3.1. Framework
3.2. Densely Connected Stacked Dilated Convolution (DCSDC)
3.3. Densely Connected Stacked Pooling (DCSP)
3.4. Loss Function
4. Experiments
4.1. Experimental Setting
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.2. Implementation Details
4.3. Ablation Studies
4.3.1. Convergency
4.3.2. Impact of Different Components
4.4. Comparison with State-of-the-Art Methods
- Although the structures of DCSDC and DCSP are simple, the proposed SBAB-Net is able to achieve a competitive counting performance compared to state-of-the-art methods on both small and large datasets. SBAB-Net, especially, significantly outperforms baseline (DM-Count [62]) while using the same backbone as the feature extractor.
- Although the same three dilation rates are utilized in the proposed framework and CSRNet [16], we achieve a much better performance, which indicates the advantage of our DCSDC structure.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | ShanghaiTech Part-A | |
|---|---|---|
| MAE | MSE | |
| CSRNet [16] | 68.2 | 115.0 |
| SFCN [70] | 64.8 | 107.5 |
| CAN [71] | 62.3 | 100.0 |
| Bayesian+ [65] | 62.8 | 101.8 |
| S-DCNet [72] | 58.3 | 95.0 |
| SANet + SPANet [73] | 59.4 | 92.5 |
| SDANet [35] | 63.6 | 101.8 |
| ADSCNet [15] | 55.4 | 97.7 |
| ADNet [15] | 61.3 | 103.9 |
| ASNet [74] | 57.78 | 90.13 |
| AMRNet [75] | 61.59 | 98.36 |
| AMSNet [76] | 56.7 | 93.4 |
| DM-Count [62] | 59.7 | 95.7 |
| DADNet [38] | 64.2 | 99.9 |
| SFANet [32] | 63.8 | 105.2 |
| Ours | 57.69 | 93.77 |
| Methods | UCF-QNRF | |
|---|---|---|
| MAE | MSE | |
| CSRNet [16] | 120.3 | 208.5 |
| SFCN [70] | 102 | 171 |
| CAN [71] | 107 | 183 |
| Bayesian+ [65] | 88.7 | 154.8 |
| S-DCNet [72] | 104.4 | 176.1 |
| ASNet [74] | 91.59 | 159.71 |
| AMRNet [75] | 86.6 | 152.2 |
| AMSNet [76] | 101.8 | 163.2 |
| DM-Count [62] | 85.6 | 148.3 |
| SFANet [32] | 100.8 | 174.5 |
| P2PNet [64] | 85.32 | 154.5 |
| ADNet [15] | 90.1 | 147.1 |
| DADNet [38] | 113.2 | 189.4 |
| Ours | 84.81 | 152.17 |
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, T.; Chang, H.; Wang, M.; Ni, B.; Hong, R.; Yan, S. Crowded scene analysis: A survey. IEEE Trans. Circuits Syst. Video Technol. 2014, 25, 367–386. [Google Scholar] [CrossRef] [Green Version]
- Gao, G.; Gao, J.; Liu, Q.; Wang, Q.; Wang, Y. Cnn-based density estimation and crowd counting: A survey. arXiv 2020, arXiv:2003.12783. [Google Scholar]
- Ge, W.; Collins, R.T. Marked point processes for crowd counting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2913–2920. [Google Scholar]
- Idrees, H.; Saleemi, I.; Seibert, C.; Shah, M. Multi-source multi-scale counting in extremely dense crowd images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2547–2554. [Google Scholar]
- Idrees, H.; Soomro, K.; Shah, M. Detecting humans in dense crowds using locally-consistent scale prior and global occlusion reasoning. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1986–1998. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Zhang, Z.; Huang, K.; Tan, T. Estimating the number of people in crowded scenes by mid based foreground segmentation and head-shoulder detection. In Proceedings of the International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Pham, V.Q.; Kozakaya, T.; Yamaguchi, O.; Okada, R. Count forest: Co-voting uncertain number of targets using random forest for crowd density estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3253–3261. [Google Scholar]
- Fu, M.; Xu, P.; Li, X.; Liu, Q.; Ye, M.; Zhu, C. Fast crowd density estimation with convolutional neural networks. Eng. Appl. Artif. Intell. 2015, 43, 81–88. [Google Scholar] [CrossRef]
- Hu, Y.; Chang, H.; Nian, F.; Wang, Y.; Li, T. Dense crowd counting from still images with convolutional neural networks. J. Vis. Commun. Image Represent. 2016, 38, 530–539. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-image crowd counting via multi-column convolutional neural network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 589–597. [Google Scholar]
- Babu Sam, D.; Surya, S.; Venkatesh Babu, R. Switching convolutional neural network for crowd counting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 5744–5752. [Google Scholar]
- Yang, Y.; Li, G.; Du, D.; Huang, Q.; Sebe, N. Embedding Perspective Analysis Into Multi-Column Convolutional Neural Network for Crowd Counting. IEEE Trans. Image Process. 2020, 30, 1395–1407. [Google Scholar] [CrossRef]
- Cheng, Z.Q.; Li, J.X.; Dai, Q.; Wu, X.; He, J.Y.; Hauptmann, A.G. Improving the learning of multi-column convolutional neural network for crowd counting. In Proceedings of the ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1897–1906. [Google Scholar]
- Xu, W.; Liang, D.; Zheng, Y.; Xie, J.; Ma, Z. Dilated-Scale-Aware Category-Attention ConvNet for Multi-Class Object Counting. IEEE Signal Process. Lett. 2021, 28, 1570–1574. [Google Scholar] [CrossRef]
- Bai, S.; He, Z.; Qiao, Y.; Hu, H.; Wu, W.; Yan, J. Adaptive dilated network with self-correction supervision for counting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4594–4603. [Google Scholar]
- Li, Y.; Zhang, X.; Chen, D. Csrnet: Dilated convolutional neural networks for understanding the highly congested scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1091–1100. [Google Scholar]
- Liu, N.; Long, Y.; Zou, C.; Niu, Q.; Pan, L.; Wu, H. Adcrowdnet: An attention-injective deformable convolutional network for crowd understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 3225–3234. [Google Scholar]
- Zou, Z.; Su, X.; Qu, X.; Zhou, P. Da-net: Learning the fine-grained density distribution with deformation aggregation network. IEEE Access 2018, 6, 60745–60756. [Google Scholar] [CrossRef]
- Amirgholipour, S.; He, X.; Jia, W.; Wang, D.; Liu, L. Pdanet: Pyramid density-aware attention net for accurate crowd counting. arXiv 2020, arXiv:2001.05643. [Google Scholar]
- Chen, X.; Bin, Y.; Sang, N.; Gao, C. Scale pyramid network for crowd counting. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1941–1950. [Google Scholar]
- Sindagi, V.A.; Patel, V.M. Generating high-quality crowd density maps using contextual pyramid cnns. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1861–1870. [Google Scholar]
- Liu, J.; Gao, C.; Meng, D.; Hauptmann, A.G. Decidenet: Counting varying density crowds through attention guided detection and density estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5197–5206. [Google Scholar]
- Hossain, M.; Hosseinzadeh, M.; Chanda, O.; Wang, Y. Crowd counting using scale-aware attention networks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1280–1288. [Google Scholar]
- Liu, L.; Wang, H.; Li, G.; Ouyang, W.; Lin, L. Crowd counting using deep recurrent spatial-aware network. arXiv 2018, arXiv:1807.00601. [Google Scholar]
- Chen, J.; Su, W.; Wang, Z. Crowd counting with crowd attention convolutional neural network. Neurocomputing 2020, 382, 210–220. [Google Scholar] [CrossRef]
- Sun, G.; Liu, Y.; Probst, T.; Paudel, D.P.; Popovic, N.; Van Gool, L. Boosting crowd counting with transformers. arXiv 2021, arXiv:2105.10926. [Google Scholar]
- Gao, J.; Gong, M.; Li, X. Congested Crowd Instance Localization with Dilated Convolutional Swin Transformer. arXiv 2021, arXiv:2108.00584. [Google Scholar]
- Sajid, U.; Chen, X.; Sajid, H.; Kim, T.; Wang, G. Audio-visual transformer based crowd counting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 2249–2259. [Google Scholar]
- Tian, Y.; Chu, X.; Wang, H. Cctrans: Simplifying and improving crowd counting with transformer. arXiv 2021, arXiv:2109.14483. [Google Scholar]
- Liang, D.; Xu, W.; Bai, X. An End-to-End Transformer Model for Crowd Localization. arXiv 2022, arXiv:2202.13065. [Google Scholar]
- Wang, F.; Liu, K.; Long, F.; Sang, N.; Xia, X.; Sang, J. Joint CNN and Transformer Network via weakly supervised Learning for efficient crowd counting. arXiv 2022, arXiv:2203.06388. [Google Scholar]
- Zhu, L.; Zhao, Z.; Lu, C.; Lin, Y.; Peng, Y.; Yao, T. Dual path multi-scale fusion networks with attention for crowd counting. arXiv 2019, arXiv:1902.01115. [Google Scholar]
- Rong, L.; Li, C. A Strong Baseline for Crowd Counting and Unsupervised People Localization. arXiv 2020, arXiv:2011.03725. [Google Scholar]
- Modolo, D.; Shuai, B.; Varior, R.R.; Tighe, J. Understanding the impact of mistakes on background regions in crowd counting. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Breckenridge, CO, USA, 5–7 January 2021; pp. 1650–1659. [Google Scholar]
- Miao, Y.; Lin, Z.; Ding, G.; Han, J. Shallow feature based dense attention network for crowd counting. In Proceedings of the AAAI Conference on Artificial Intelligence, Hilton New York Midtown, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11765–11772. [Google Scholar]
- Yi, Q.; Liu, Y.; Jiang, A.; Li, J.; Mei, K.; Wang, M. Scale-aware network with regional and semantic attentions for crowd counting under cluttered background. arXiv 2021, arXiv:2101.01479. [Google Scholar]
- Huang, S.; Li, X.; Cheng, Z.Q.; Zhang, Z.; Hauptmann, A. Stacked Pooling for Boosting Scale Invariance of Crowd Counting. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Barcelona, Spain, 4–8 May 2020; pp. 2578–2582. [Google Scholar]
- Guo, D.; Li, K.; Zha, Z.J.; Wang, M. Dadnet: Dilated-attention-deformable convnet for crowd counting. In Proceedings of the ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1823–1832. [Google Scholar]
- Idrees, H.; Tayyab, M.; Athrey, K.; Zhang, D.; Al-Maadeed, S.; Rajpoot, N.; Shah, M. Composition loss for counting, density map estimation and localization in dense crowds. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 532–546. [Google Scholar]
- Wang, Q.; Gao, J.; Lin, W.; Li, X. NWPU-crowd: A large-scale benchmark for crowd counting and localization. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2141–2149. [Google Scholar] [CrossRef]
- Leibe, B.; Seemann, E.; Schiele, B. Pedestrian detection in crowded scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 878–885. [Google Scholar]
- Chan, A.B.; Liang, Z.S.J.; Vasconcelos, N. Privacy preserving crowd monitoring: Counting people without people models or tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–7. [Google Scholar]
- Zhang, C.; Li, H.; Wang, X.; Yang, X. Cross-scene crowd counting via deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 833–841. [Google Scholar]
- Iqbal, M.; Rehman, M.A.; Iqbal, N.; Iqbal, Z. Effect of Laplacian Smoothing Stochastic Gradient Descent with Angular Margin Softmax Loss on Face Recognition. In International Conference on Intelligent Technologies and Applications; Springer: Berlin/Heidelberg, Germany, 2019; pp. 549–561. [Google Scholar]
- Zeng, L.; Xu, X.; Cai, B.; Qiu, S.; Zhang, T. Multi-scale convolutional neural networks for crowd counting. In Proceedings of the IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 465–469. [Google Scholar]
- Kang, D.; Chan, A. Crowd counting by adaptively fusing predictions from an image pyramid. arXiv 2018, arXiv:1805.06115. [Google Scholar]
- Xu, C.; Liang, D.; Xu, Y.; Bai, S.; Zhan, W.; Bai, X.; Tomizuka, M. AutoScale: Learning to Scale for Crowd Counting and Localization. arXiv 2019, arXiv:1912.09632. [Google Scholar]
- Song, Q.; Wang, C.; Wang, Y.; Tai, Y.; Wang, C.; Li, J.; Wu, J.; Ma, J. To Choose or to Fuse? Scale Selection for Crowd Counting. In Proceedings of the AAAI Conference on Artificial Intelligence, Arlington, VA, USA, 4–6 November 2021; Volume 35, pp. 2576–2583. [Google Scholar]
- Ma, Z.; Wei, X.; Hong, X.; Gong, Y. Learning scales from points: A scale-aware probabilistic model for crowd counting. In Proceedings of the ACM International Conference on Multimedia, Singapore, 16–18 December 2020; pp. 220–228. [Google Scholar]
- Gao, J.; Wang, Q.; Yuan, Y. SCAR: Spatial-/channel-wise attention regression networks for crowd counting. Neurocomputing 2019, 363, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Sindagi, V.A.; Patel, V.M. Ha-ccn: Hierarchical attention-based crowd counting network. IEEE Trans. Image Process. 2019, 29, 323–335. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sindagi, V.A.; Patel, V.M. Inverse attention guided deep crowd counting network. In Proceedings of the IEEE International Conference on Advanced Video and Signal Based Surveillance, Taipei, Taiwan, 18–21 September 2019; pp. 1–8. [Google Scholar]
- Shi, Z.; Mettes, P.; Snoek, C.G. Counting with focus for free. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 4200–4209. [Google Scholar]
- Liu, C.; Weng, X.; Mu, Y. Recurrent attentive zooming for joint crowd counting and precise localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 1217–1226. [Google Scholar]
- Zhang, A.; Yue, L.; Shen, J.; Zhu, F.; Zhen, X.; Cao, X.; Shao, L. Attentional neural fields for crowd counting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 5714–5723. [Google Scholar]
- Gao, J.; Wang, Q.; Li, X. Pcc net: Perspective crowd counting via spatial convolutional network. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3486–3498. [Google Scholar] [CrossRef] [Green Version]
- Sindagi, V.A.; Patel, V.M. Cnn-based cascaded multi-task learning of high-level prior and density estimation for crowd counting. In Proceedings of the IEEE International Conference on Advanced Video and Signal Based Surveillance, Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Jiang, S.; Lu, X.; Lei, Y.; Liu, L. Mask-aware networks for crowd counting. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3119–3129. [Google Scholar] [CrossRef] [Green Version]
- Zhao, M.; Zhang, J.; Zhang, C.; Zhang, W. Leveraging heterogeneous auxiliary tasks to assist crowd counting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 12736–12745. [Google Scholar]
- Huang, S.; Li, X.; Zhang, Z.; Wu, F.; Gao, S.; Ji, R.; Han, J. Body structure aware deep crowd counting. IEEE Trans. Image Process. 2017, 27, 1049–1059. [Google Scholar] [CrossRef]
- Lian, D.; Li, J.; Zheng, J.; Luo, W.; Gao, S. Density map regression guided detection network for rgb-d crowd counting and localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 1821–1830. [Google Scholar]
- Wang, B.; Liu, H.; Samaras, D.; Nguyen, M.H. Distribution Matching for Crowd Counting. arXiv 2020, arXiv:2009.13077. [Google Scholar]
- Villani, C. Optimal transport, old and new. Notes for the 2005 Saint-Flour summer school. In Grundlehren der Mathematischen Wissenschaften [Fundamental Principles of Mathematical Sciences]; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Song, Q.; Wang, C.; Jiang, Z.; Wang, Y.; Tai, Y.; Wang, C.; Li, J.; Huang, F.; Wu, Y. Rethinking Counting and Localization in Crowds: A Purely Point-Based Framework. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 3365–3374. [Google Scholar]
- Ma, Z.; Wei, X.; Hong, X.; Gong, Y. Bayesian loss for crowd count estimation with point supervision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6142–6151. [Google Scholar]
- Ranjan, V.; Le, H.; Hoai, M. Iterative crowd counting. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 270–285. [Google Scholar]
- Ranjan, V.; Sharma, U.; Nguyen, T.; Hoai, M. Learning To Count Everything. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3394–3403. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Wang, Q.; Gao, J.; Lin, W.; Yuan, Y. Learning from synthetic data for crowd counting in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 8198–8207. [Google Scholar]
- Liu, W.; Salzmann, M.; Fua, P. Context-aware crowd counting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 5099–5108. [Google Scholar]
- Xiong, H.; Lu, H.; Liu, C.; Liu, L.; Cao, Z.; Shen, C. From open set to closed set: Counting objects by spatial divide-and-conquer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8362–8371. [Google Scholar]
- Cheng, Z.Q.; Li, J.X.; Dai, Q.; Wu, X.; Hauptmann, A.G. Learning spatial awareness to improve crowd counting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6152–6161. [Google Scholar]
- Jiang, X.; Zhang, L.; Xu, M.; Zhang, T.; Lv, P.; Zhou, B.; Yang, X.; Pang, Y. Attention scaling for crowd counting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4706–4715. [Google Scholar]
- Liu, X.; Yang, J.; Ding, W.; Wang, T.; Wang, Z.; Xiong, J. Adaptive mixture regression network with local counting map for crowd counting. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 241–257. [Google Scholar]
- Hu, Y.; Jiang, X.; Liu, X.; Zhang, B.; Han, J.; Cao, X.; Doermann, D. Nas-count: Counting-by-density with neural architecture search. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 747–766. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]







| Components | ShanghaiTech Part-A | ShanghaiTech Part-B | UCF-QNRF | NWPU | ||||
|---|---|---|---|---|---|---|---|---|
| MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | |
| Baseline | 68.92 | 108.08 | 8.57 | 15.38 | 210.56 | 393.69 | 85.29 | 401.35 |
| SBAB-Net w/o DCSDC | 65.06 | 105.29 | 8.34 | 14.88 | 172.11 | 255.84 | - | - |
| SBAB-Net w/o DCSP | 62.50 | 100.31 | 8.17 | 13.72 | - | - | 82.87 | 389.29 |
| SBAB-Net | 60.57 | 95.89 | 8.03 | 12.24 | 108.58 | 185.38 | 69.91 | 237.14 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, G.; Xu, Y.; Ma, Z.; Sun, Y.; Nian, F. Scale and Background Aware Asymmetric Bilateral Network for Unconstrained Image Crowd Counting. Mathematics 2022, 10, 1053. https://doi.org/10.3390/math10071053
Lv G, Xu Y, Ma Z, Sun Y, Nian F. Scale and Background Aware Asymmetric Bilateral Network for Unconstrained Image Crowd Counting. Mathematics. 2022; 10(7):1053. https://doi.org/10.3390/math10071053
Chicago/Turabian StyleLv, Gang, Yushan Xu, Zuchang Ma, Yining Sun, and Fudong Nian. 2022. "Scale and Background Aware Asymmetric Bilateral Network for Unconstrained Image Crowd Counting" Mathematics 10, no. 7: 1053. https://doi.org/10.3390/math10071053
APA StyleLv, G., Xu, Y., Ma, Z., Sun, Y., & Nian, F. (2022). Scale and Background Aware Asymmetric Bilateral Network for Unconstrained Image Crowd Counting. Mathematics, 10(7), 1053. https://doi.org/10.3390/math10071053