1. Introduction
Strong algorithms have been developed for game classes with many elements of complexity. For example, algorithms were recently able to defeat human professional players in two-player [
1,
2] and six-player no-limit Texas hold ’em [
3]. These games have imperfect information, sequential actions, very large state spaces, and the latter has more than two players (solving multiplayer games is more challenging than two-player zero-sum games from a complexity-theoretic perspective). However, these algorithms all require an extremely large amount of computational resources for offline and/or online computations and for optimizing neural network hyperparameters. The algorithms also have a further limitation in that they are using all these resources just to solve for one very specific version of the game (e.g., Libratus and DeepStack assumed that all players start the hand with 200 times the big blind, and Pluribus assumed that all players start the hand with 100 times the big blind). In real poker, the stack sizes of the players will fluctuate as players win or lose hands, and will often differ from the starting values. While one could apply the same algorithms for any specific starting stack and blind values, there are too many possibilities to be able to run the algorithms on
all of them.
In many real-world situations, there are some game parameters that will be encountered during gameplay that are unknown in advance (such as the stack sizes in poker). Furthermore, often the real-time decision maker will be a human, who may not have the ability to perform complex computations (even though such computations may have been performed offline in advance). For example, football teams have used statistical and game-theoretic models to decide whether or not to punt on a fourth down. In advance of game play, algorithms can be run that solve for optimal solutions in these models, perhaps by utilizing databases of historical play. However, in real time, the coach has only a matter of seconds (or minutes if a timeout is used) to make the decision. The optimal decision may depend on several factors that are not known until real time; for example, the score, how much time is remaining, the overall strength of the two teams, etc. The coach will need to weigh any offline algorithmic solution with newly-observed values of these parameters to make quick real-time decisions. Similar situations are also encountered frequently in national security. In recent years game-theoretic algorithms have been increasingly applied to security domains. These algorithms must be applied offline with specific values of parameters used, which may differ from the actual values encountered in real time (e.g., an attacker may use more resources than anticipated).
In these settings it is not sufficient to develop a successful algorithm for solving the game for one specific value of parameters; it is also necessary to develop a procedure for a decision maker to compute an optimal solution in real time for the newly-observed value of the parameters. Often the decision maker is a human, who may have limited technical expertise. It is not realistic to assume that the human decision maker can perform a complex algorithmic computation, tune or optimize a neural network, or perform a search over a large historical database during the seconds or minutes available to make the decision. While it is realistic to assume that a human can perform a table lookup to implement a previously computed strategy (even one stored in a large binary file), as described above this strategy may not apply to the observed parameter values. In addition, it is reasonable to assume that the human has access to a “cheat sheet” which contains a relatively small set of general rules to be applied depending on the parameter values encountered. It is also reasonable to assume that the decision maker can perform basic arithmetic (perhaps with the aid of a calculator). In this paper we present a novel framework for enabling human decision makers to act strategically in these settings.
2. Parametrized Games
We consider a setting where a decision maker must determine a strategy for a game , which contains a vector of parameters drawn from some domain (typically subsets of the set of real numbers or integers). For any specific values of the parameters , can be solved using standard algorithms. However, it is infeasible to solve the game in advance for all possible parameter values (there may be infinitely many).
The parameters can affect different components of the game. They can affect the payoffs, set of players, strategy spaces, and/or private information. Often our goal will be to solve the game by computing a standard game-theoretic solution concept such as a Nash equilibrium. A second goal that we will also consider is opponent exploitation—computing a best response to perceived strategies of the opponents. The model of the opponents’ strategies is determined in real time based on observations of the opponents’ play, perhaps utilizing a prior distribution based on historical data. In this situation, the parameters can also affect the strategies of the opponents. In general our framework can allow for optimizing any objective, though we will focus on the natural objectives of computing Nash equilibrium or optimizing performance against assessments of opponents’ strategies.
Definition 1. A strategic-form game G is a tuple with finite set of players , finite set of pure strategies for each player , and real-valued utility for each player for each strategy vector (aka strategy profile), .
Definition 2. A payoff-parametrized strategic-form game is a tuple where for each real-valued vector of parameters , is a tuple with finite set of players , finite set of pure strategies for each player , and real-valued utility for each player for each strategy vector (aka strategy profile), .
Definition 3. A strategy-parametrized strategic-form game is a tuple where for each real-valued vector of parameters , is a tuple with finite set of players N, finite set of pure strategies for each player , and real-valued utility for each player for each strategy vector (aka strategy profile), .
We can analogously define a player-parametrized game where the set of players is determined by We can also consider games that simultaneously consider several different types of parametrization. In general we will denote a strategic-form game that has payoff, strategy, and/or player parametrization as a parametrized strategic-form game, , with for .
While the strategic form can be used to model simultaneous actions, another representation, called the extensive form, is generally preferred when modeling settings that have sequential moves. The extensive form can also model simultaneous actions, as well as chance events and imperfect information (i.e., situations where some information is available to only some of the agents and not to others). Extensive-form games consist primarily of a game tree; each non-terminal node has an associated player (possibly chance) that makes the decision at that node, and each terminal node has associated utilities for the players. Additionally, game states are partitioned into information sets, where the player to act cannot distinguish among the states in the same information set. Therefore, in any given information set, a player must choose actions with the same distribution at each state contained in the information set. A pure strategy for player i is a mapping that selects an action at each information set belonging to player i.
In typical imperfect-information extensive-form games, the initial move is a chance move that assigns private information to each player (from a publicly-known distribution). For example, this could be private cards in poker, item valuations in auctions, or resource values in security games. Then players perform a sequence of publicly-observable actions until a terminal node is reached. Thus, for each sequence of public actions p, each player i selects a strategy that is dependent on their own private information, . Instead of viewing this decision as a selection of separate actions at each information set that follows the action sequence p, one can view this as a mapping that assigns an action for each possible value of the private information If the set of possible values of the private information is dictated by a vector of parameters , then we say that the game is information-parametrized.
3. Parametric Decision Lists
Our goal for parametrized games is to develop a “cheat sheet” that allows a human decision maker to quickly select a strategy in real time for any possible value of the parameters We propose a new structure, which we call a parametric decision list (PDL), which contains a small set of rules that dictate which strategy should be played for every possible parameter value in a way that can be easily understood and implemented by a human. Similarly to a standard decision list, a parametric decision list consists of a series of conditions, each resulting in the output of a strategy. For game , each condition will be of the form “if ”, where is a vector-valued function of the parameters , and is vector of comparison operators from the set For example if , , , then the condition would correspond to “if and ” If the condition is satisfied, then (mixed) strategy is output. We can view the initial condition as corresponding to an “If” statement, subsequent conditions as “Else if,” and the final condition as “Else”.
Definition 4. A parametric decision list L for is a tuple , where is a sequence of functions , is a sequence of vectors of primitive comparison operators with , with and is a sequence of (mixed) strategies.
We define the depth of parametric decision list L to equal the number of strategies, The first strategies correspond to when each of the conditions are met, and the final strategy corresponds to the default case when none are met (aka, the “else” condition). The width of L is equal to w, the length of the vectors . Each function outputs a w-dimensional vector . Then each component j is compared to 0 using operator . If all conditions of the operators are met, then the list dictates following strategy .
We say that parametrized game with objective function is -implementable if there exists a parametric decision list L with depth at most d and width at most w that achieves an objective value for all for the strategy determined by L, where is the optimal value of the objective for . The two primary objective functions we will be considering are the exploitability of a strategy in a two-player zero-sum game, which is defined as the difference between the game value and payoff of the strategy against a best response to it, and performance of a strategy against a specific strategy (or distribution of strategies) for the opponents.
4. Parameter Sampling
A second approach for generating a set of rules for a human decision-maker would be to repeatedly sample values for parameters and compute the optimal strategy in the parametrized game using standard approaches. Then when game is encountered in real time, we output the solution corresponding to the value of i that minimizes , where d is an appropriate distance metric. This sampling can be done uniformly at random over a suitably-chosen domain, or according to a more informative prior distribution if one is available. Assuming that the number of sampled games is relatively small and it is not too difficult to compute the distance function, this can potentially be another approach for human decision-making in parametrized games.
Theorem 1 shows that as the number of samples grows large, this approach produces an optimal strategy if the payoffs are continuous functions of the parameters. The analysis is for the minimum exploitability metric in two-player zero-sum games, though similar analysis can also apply for other objectives. For simplicity we assume that the parameter is one-dimensional and use the absolute value for the distance function, though an analogous result can be shown for the multi-dimensional case using an arbitrary distance metric.
Lemma 1. Suppose all payoffs of are within ϵ of the payoffs of . Let be a strategy profile in Then
Proof. The utility against equals the sum of the utilities against each of the opponent’s pure strategies multiplied by the weight that places on . Since each of the utilities in is within of the utilities in , the weighted sums must be within of each other. □
Lemma 2. Suppose all payoffs of are within ϵ of the payoffs of . Let be a strategy for player i of , let be a nemesis strategy against in , and let be a nemesis strategy against in . Then
Proof. Suppose that
By Lemma 1,
which contradicts the fact that
is a nemesis strategy against
in
We obtain a similar contradiction if
So we conclude that
□
Lemma 3. Suppose all payoffs of are within ϵ of the payoffs of . Let be the game value of to player i and be the value of . Then
Proof. Let be a Nash equilibrium strategy profile in Then Let be a nemesis against in By Lemma 2, So So We know that So Similar reasoning shows that So □
Lemma 4. Suppose is a Nash equilibrium of , and all payoffs of are within ϵ of the payoffs of . Then the exploitability of in is at most
Proof. Let
be a Nash equilibrium of
, and
be a nemesis strategy to
in
Let
denote the value of
and
denote the value of
The exploitability of
in
equals
By the triangle inequality and Lemmas 1 and 3,
□
Denote as . Without loss of generality suppose and that we repeatedly sample from and compute optimal strategy in the game . Then when we encounter in real time, calculate , and play . Suppose the game has players, has m actions per player, is zero sum, and that we take t samples. Let denote the exploitability of in .
Theorem 1. If is continuous in λ for all , then .
Proof. Let be arbitrary, and set From continuity of , there exists such that for all such that Let Let , and let be arbitrary.
Suppose that
is the actual value of
encountered. The probability that at least one of the sampled values
satisfies
equals
If this occurs, then
by Lemma 4. Otherwise, the exploitability is at most 2 (since we assume all payoffs are in [0, 1]). So
□
Theorem 2. Suppose that we have t samples producing exploitability . Then is -implementable using the minimum exploitability objective.
Proof. We can construct parametric decision list L as follows. First, we construct the function The first component of is with operation ≤. So in other words, this corresponds to the condition The ith component of is , with also For the strategy, we set These conditions put together tell us to play strategy if for all
In general the ith component of is , with ≤ and We can omit the final set of conditions for since it is implied by the first sets of conditions all failing, and output as the default strategy at depth The constructed parametric decision list L has depth and width t, and produces a strategy with exploitability of . □
5. Comparison of Approaches in 2 × 2 Games
In general it may be challenging to construct a small parametric decision list that achieves an approximately optimal value of the objective function. Similarly, for the sampling approach we may require a large number of samples to obtain a small approximation error. The sampling approach could be improved by first sampling as many values for the parameters as possible, then clustering the games generated (e.g., using k-means) into k clusters. We then implement the strategy corresponding to the parameter values from the cluster mean with smallest distance from the parameters we encounter in real time. This approach would require an effective distance metric between parameter vectors that can be efficiently computed, while such a metric is not required for the parametric decision list approach. Furthermore, it may be challenging to determine the optimal value of k, and there is no guarantee that this approach with k clusters will produce small error.
In this section we compare the two approaches for the problem of computing Nash equilibrium strategies (i.e., using the objective of minimizing exploitability) in two-player zero-sum strategic-form games with two pure strategies per player. We can represent a two-player
game as a matrix
M depicted in Equation (
1), where the parameters correspond to the payoffs of the row and column players. For general-sum games we can view this game as having 8 parameters (
a–
h), while for zero-sum games there are 4, since
While we can easily solve a specific game given the payoff parameters, we seek to construct a small set of rules that allow a human to easily obtain a solution for arbitrary parameter values.
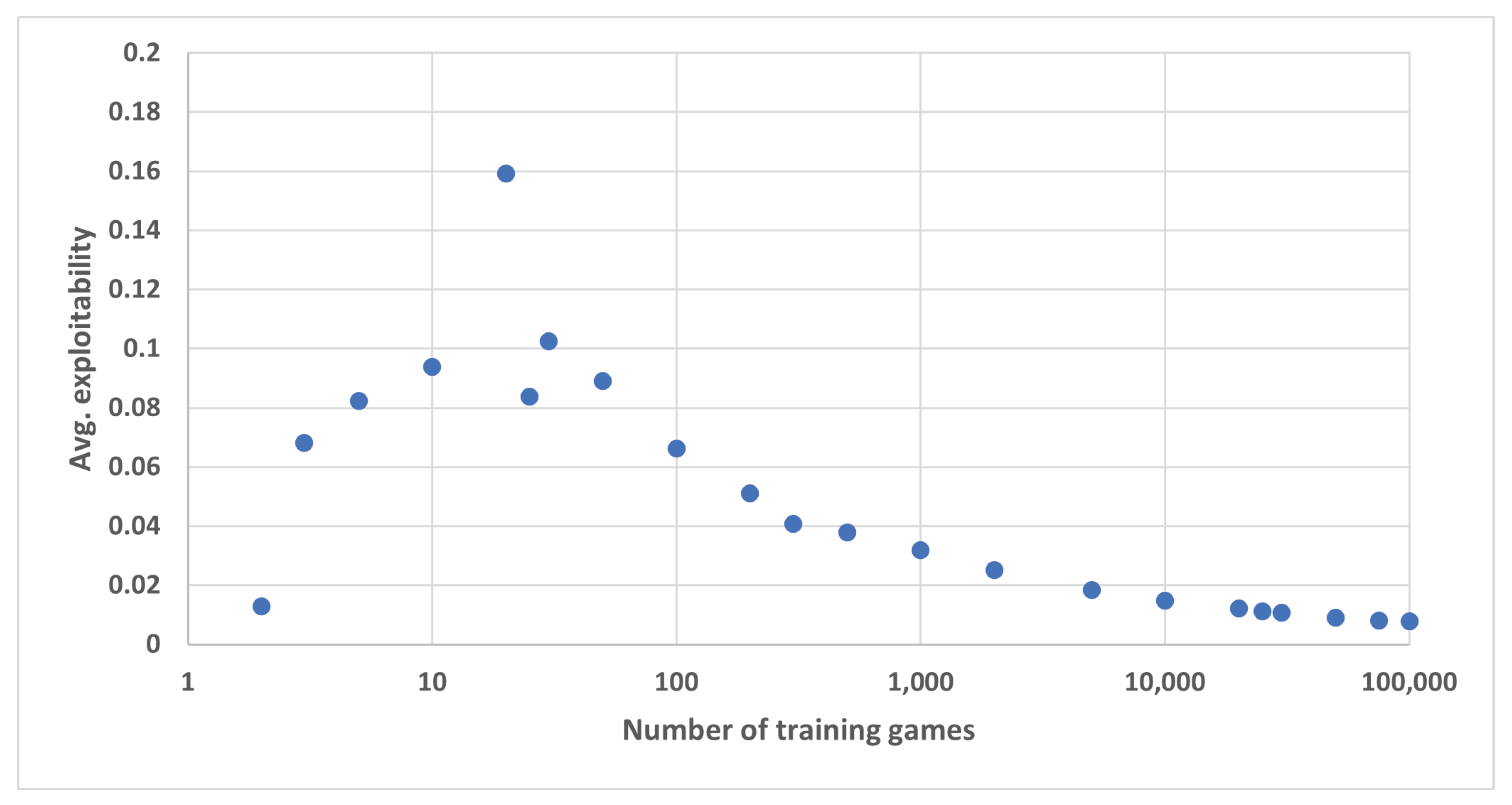
We first explore the sampling approach. We generated 100,000
2-player zero-sum games with payoffs for the row player chosen uniformly at random in
. We then used the first
k games from this set as training data, for various values of
k. For each value of
k, we generated 10,000 new test games with uniform random payoffs. For each test game, we determine which of the
k training games is “closest.” For the distance metric, we use the L2-norm over vectors for the values
We then compute the exploitability of the previously-computed equilibrium strategies from the closest training game in the new test game. The average exploitability over the 10,000 games is plotted as a function of
k in
Figure 1. From the figure we can see that as the number of training games gets large the average exploitability approaches zero, as expected. Surprisingly, training on just the first two games actually produces a very small average exploitability of 0.0129, while training on all 100,000 produces exploitability 0.0077. The exploitability for 3 training games is significantly higher than that for 2, and jumps up sharply to a peak of 0.159 for 20 training games before descending towards zero. This erratic behavior shows that, on the one hand, the L2 distance metric has limitations for this problem and does not lead average exploitability to decrease monotonically with number of training games as we may expect. However, it also shows that it may be possible to generate a very small sample of training games (just 2) that produces a very low average exploitability.
As it turns out, there actually exists a small parametric decision list (PDL) that computes an exact Nash equilibrium for
two-player general-sum strategic-form games (we can view zero-sum games as a special case). This is depicted below, using the notation for the parameters from Equation (
1). We actually output equilibrium strategies for both players 1 and 2 in our PDL, though in practice we would only need to specify the strategy for the one player we are interested in. The final condition outputs a mixed strategy for both players, where the row player plays his strategies with probability
p and
while the column player plays his strategies with probability
q and
. This PDL provides a
implementation of the problem of computing a Nash equilibrium in this game class. A proof of correctness is in
Appendix A.
If and then (1,1).
Else if and then (1,2).
Else if and then (2,1).
Else if and then (2,2).
Else for , .
6. Parametrized Game Examples
In this section we present several examples of realistic games that depict various forms of our model. In
Section 6.1, we present a game we call Simplified Final Jeopardy, which is a simplified two-player variant of the problem of determining how much to wager in final jeopardy (we can view it as the three-player version in which the third player has
$0). The three-player version is played for large amounts of money on the popular game show. We will assume that the player balances are fixed. Our model has two parameters which denote assessments of the probabilities that each player will answer correctly. We can assume that the assessments are based on observations of play throughout the game, as well as the category. These parameters affect the payoffs of the players. So the game exemplifies payoff parametrization. This game is two-player zero-sum, and we use the Nash equilibrium approximation/minimum exploitability objective.
In
Section 6.2 we consider a generalization of a simplified poker game that has been widely studied. Kuhn poker was one of the first games studied by game theorists [
4]. More recently, it has received significant attention in the artificial intelligence community as a tractable test problem for equilibrium-finding [
5,
6,
7,
8,
9,
10] and opponent-exploitation [
11] algorithms. In the standard version, there are two players, each dealt one card from a three-card deck. We consider a variant in which the deck has
n cards. (Previously a version with a 13-card deck has been studied [
12].) The cards represent private information to the players, and therefore the game exemplifies information parametrization, though no strategy or payoff parametrization.
Finally in
Section 6.3, we study a game model based on the game show Weakest Link. In the Weakest Link game show, eight contestants answer a series of trivia questions to accumulate a “bank” of money, with one contestant (the “weakest link”) voted off at each round. When there are two contestants remaining, they face off for a series of five questions each, with the winner receiving the entire amount that was banked. In theory the champion could win “up to a million dollars”, though in practice the total bank ends up being in the
$50k–100k range. When three contestants remain, the players face an interesting strategic decision of deciding whom to vote for. Our model has five parameters: the total amount in the bank, assessments of the probability of winning against each opponent in the final round, and assessments of voting strategies of the opposing players (the probabilities that they will vote for each player). Thus, this is a three-player game using the opponent exploitation metric with strategy parametrization over the opponents’ strategies as well as payoff parametrization.
These three games exemplify several of the different types of parametrization we have discussed: payoff, strategy, information, and opponent strategy. They exemplify the main objectives we have considered: minimizing exploitability for two-player zero-sum games, and maximizing opponent exploitation in multiplayer games. They also exemplify several different game classes (two-player zero-sum, imperfect-information, and multiplayer). These are simplified models of real popular games that are frequently played for large amounts of money. The purpose of these examples is to demonstrate the realistic applicability of the new concepts and frameworks we have presented.
In each of the games human players must make their decision under extreme time pressure in real time without any computational assistance (though of course they can prepare a strategy in advance). While the optimal strategy can be computed easily in advance for fixed values of the parameters, the players must be prepared to face any possible values for the parameters. It turns out that for the games we consider we are able to construct parametric decision lists with small width and depth that exactly solve the problem based on the derivation of closed-form solutions. While in general larger games will clearly often not have closed-form solutions, the new concepts and frameworks can still be applied, though they may require the development of new focused algorithms.
For each of the games we consider, we present the rules, as well as a small PDL that exactly optimizes the objective. Full derivations and additional analysis are in
Appendix A,
Appendix B,
Appendix C and
Appendix D.
6.1. Final Jeopardy
In the simplified final jeopardy game, two players each have an amount and must select a non-negative amount to wager. We will assume that , , and the must be non-negative integers. The player who finishes with a higher amount wins and obtains payoff 1, while the losing player obtains payoff 0 (we can then subtract 0.5 from each payoff to make the game zero sum). If there is a tie, then we assume each player obtains payoff 0.5. Finally, there are parameters that denote the probability that the players expect player i to correctly answer the question. We assume that these values are correct and are common knowledge.
For specific fixed values of the parameters
, the game is a two-player zero-sum strategic-form game, and can be solved easily using standard algorithms. But such an approach is not helpful for a human player who must be prepared to be able to quickly construct his strategy in real time for any possible values of the parameters. The parametrized game is a
strategic-form game where the payoffs are functions of the parameters, and it is not obvious how to compute equilibrium strategies for all possible parameter values. As it turns out, we can construct the following small PDL which determines exact equilibrium strategies for all values of the parameters for player 1 (a derivation is provided in
Appendix B).
The PDL for player 2 is the following:
If wager 0.
Else if wager 3.
Else if wager 0.
Else if and wager 2.
Else if wager 3.
Otherwise wager 0 with probability and wager 3 with probability
6.2. Generalized Kuhn Poker
The rules of three-card Kuhn poker are as follows:
Two players: A and B
Both players ante $1
Deck containing three cards: 1, 2, and 3
Each player is dealt one card uniformly at random
Player A acts first and can either bet $1 or check
- –
If A bets, player B can call or fold
- ∗
If A bets and B calls, then whoever has the higher card wins the $4 pot
- ∗
If A bets and B folds, then A wins the entire $3 pot
- –
If A checks, B can bet $1 or check.
- ∗
If A checks and B bets, then A can call or fold.
- ·
If A checks, B bets, and A calls, then whoever has the higher card wins the $4 pot
- ·
If A checks, B bets, and A folds, B wins the $3 pot
- ∗
If A and B check, then whoever has the higher card wins the $2 pot
An analysis of the equilibria is provided in
Appendix C. The equilibrium strategies contain some elements of deceptive behavior, as is present in larger variants of poker. For example, player
A sometimes checks with a 3 as a
trap or
slowplay, and both players sometimes bet with a 1 as a
bluff.
Generalized Kuhn poker has the same rules as standard Kuhn poker except that the deck contains
n cards instead of 3. We will denote the game with
n cards by
As it turns out, we can represent equilibrium strategies for both players in
by the following PDL, which is derived in
Appendix C.
- 1.
Player A’s strategy in the first round:
A always bets if
If , then A bets with with probability
A always checks if
A always bets if
If , then A bets with with probability
- 2.
Player B’s strategy facing a bet:
B always calls if
If , then B calls with with probability
B always folds if
- 3.
Player B’s strategy facing a check:
B always bets if
If , then B bets with with probability
B always checks if
B always bets if
If , then B bets with with probability
- 4.
Player A’s strategy after A checks and B bets:
A always calls if
If then A calls with with probability
A always folds otherwise
6.3. Weakest Link
Our final example game is a model for the final voting round (three players remain) in the show Weakest Link. Suppose that the total amount of money to be awarded to the winner is
(the loser gets
$0). Suppose that if you are head-to-head against opponent 1 you will win with probability
, and against opponent 2 you will win with probability
. Assume that player 2 is stronger than player 1, so that
. Finally, assume that player 1 will vote for you with probability
(and therefore will vote for player 2 with probability 1-
), and that player 2 will vote for you with probability
. We will assume that clearly no player will vote for themselves. See
Appendix D for further details.
If there is a three-way tie, we will assume that each player is voted out with probability 1/3. (In reality, the “statistically strongest link” from the previous round gets to cast a tie-breaking vote, but we will ignore this aspect of the problem to simplify the analysis.) Under this assumption, our expected payoff in the case of a tie equals
Using this game model, our analysis (provided in
Appendix D) shows that we should vote for player 1 if the following condition is met (and otherwise should vote for player 2):
This constitutes an optimal depth 1 PDL for the objective. If , then it is always optimal to vote for player 2 (the stronger player) regardless of your beliefs of the strategies taken by the other players.
7. Related Research
The current state of the art for creating strong game-theoretic strategies is to train an algorithm on a supercomputer for a significant period of time for one specific value of the game parameters. For example, strong agents were recently developed for two-player no-limit Texas hold ’em assuming that both players start with 200 times the big blind [
1,
2]. The strategies are typically stored in a large binary file and looked up during runtime. In real poker the values of the stack sizes relative to the blinds often change, and can be viewed as parameters. The standard approach would require performing a massive computation for each possible value of the parameters, which is intractable. Human poker players must devise a strategy for any possible combination of stack sizes. So for the realistic version of poker and many other games, which are naturally modeled as parametrized games, the standard existing approaches are inadequate.
There has recently been some recent work exploring the construction of human-understandable strategy rules in the parametrized setting. One paper showed that equilibrium strategies for endgames in two-player limit Texas hold ’em conform to one of three qualitative models, which enabled improved equilibrium computation algorithms [
6]. Recent work in other imperfect-information poker games has applied machine learning algorithms (decision trees and regression) to compute human-understandable rules for fundamental situations: when a player should make a very large or small bet, and when a player should call a bet by the opponent [
13,
14]. The former can be viewed as a special case of the current work, and the latter computes a single general “rule of thumb” while the approach in this paper constructs a full strategy for a human player for all possible values of the game parameters.
There has also been some recent study of theoretical properties of certain classes of parametrized games in game theory literature [
15,
16].
8. Conclusions
We presented a new framework that enables human decision makers to make fast decisions without the aid of real-time solvers. In many settings it is unrealistic to assume that a human strategic player can perform complex computations in real time in a matter of minutes or seconds. Many real-world settings also contain parameters whose values are unknown until runtime, and it is infeasible to solve for all possible parameter values using the standard existing game-solving approaches. If a concise parametric decision list can be constructed for a given game and objective, then a human can quickly execute the corresponding strategy for any value of the parameters encountered. We presented several examples of realistic scenarios that demonstrate applicability to a variety of situations including settings with multiple players and imperfect information, and to different objectives such as minimizing exploitability and maximizing exploitation of opponents.
While we have constructed optimal PDLs analytically for several example games, this may not be possible in general. In the future we plan to explore algorithms for computing small PDLs that achieve low objective error. Such algorithms are needed to achieve large-scale applicability of the new framework. Given the similarities to decision trees and decision lists, algorithms for computing those models may be useful for PDLs [
17]. We would also like to perform experiments on human subjects to determine the practical usefulness of the PDL representation for human strategic decision-making in realistic complex games.


{kind=link}
