
Coherence Coefficient for Official Statistics


Abstract
:1. Introduction
2. Literature Overview of the Coherence Assessment in Official Statistics
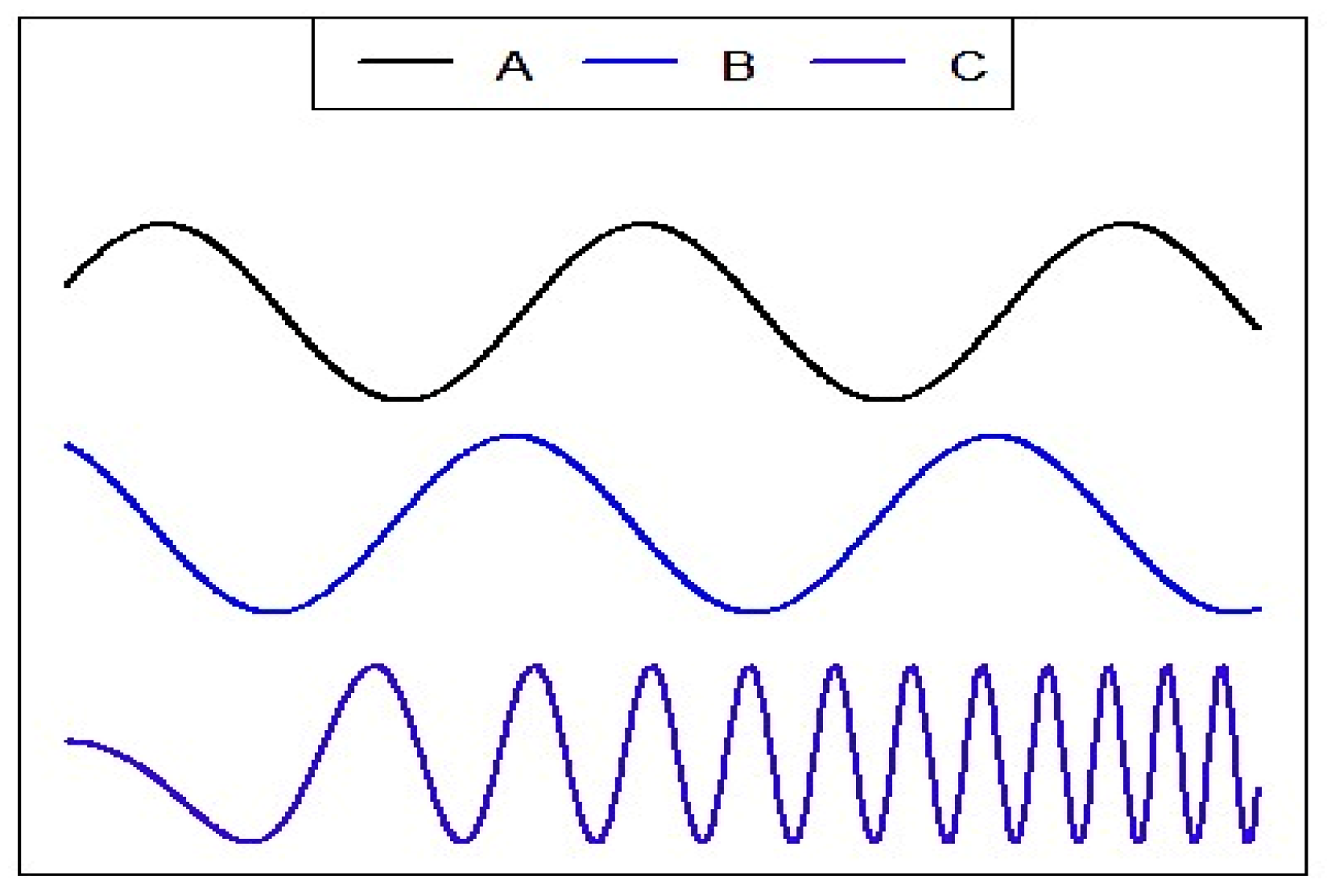
3. Coherence of the Time Series
3.1. Stationary Time Series
3.2. Jointly Stationary Time Series
3.3. Coherence Coefficient
- means that the time series are perfectly correlated or linearly related at frequency ω;
- means that the time series are totally uncorrelated at frequency ω;
- means symmetry in x and y at frequency ω.
3.4. Coherence and Causality
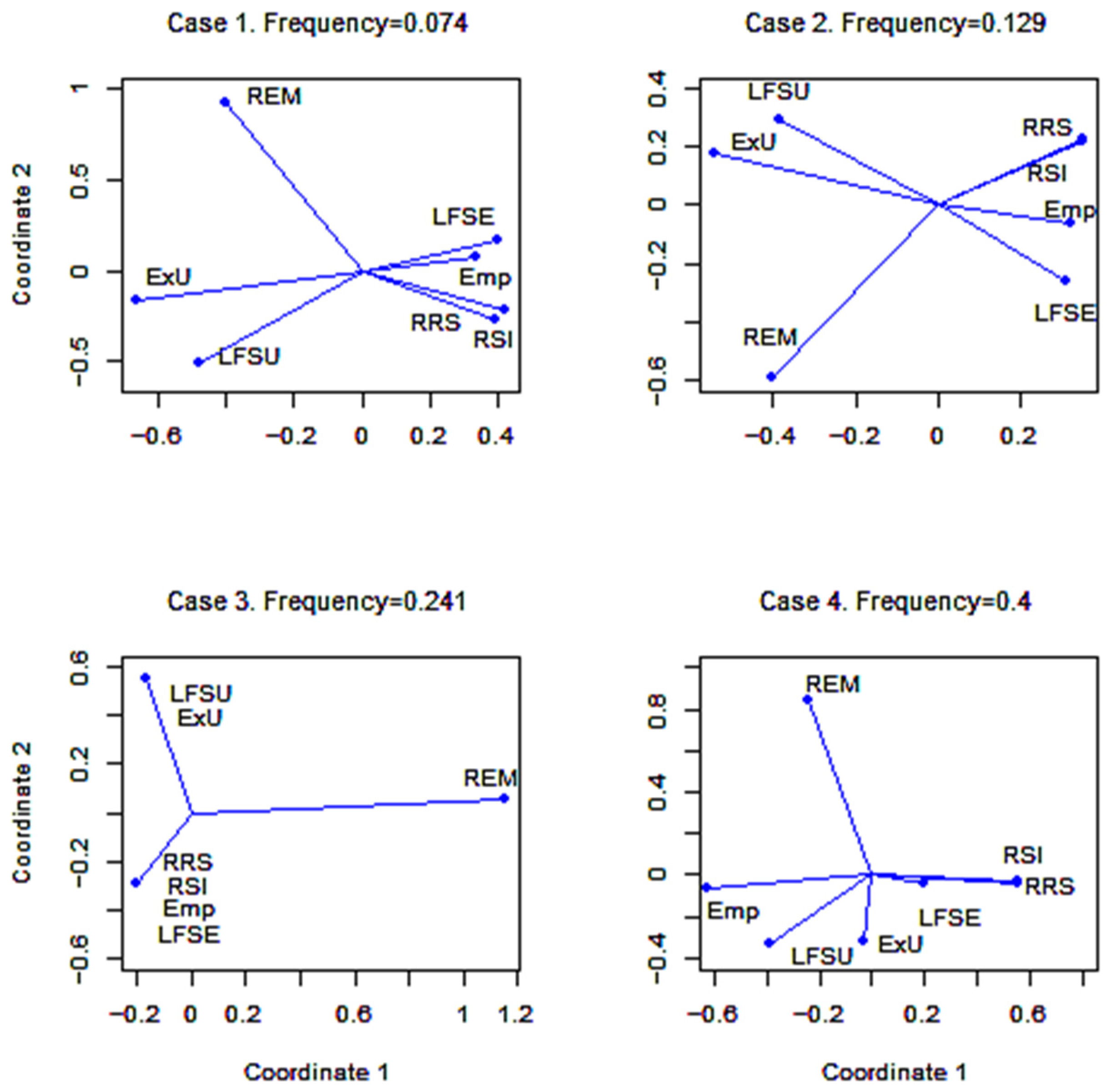
3.5. Coherence and Multivariate Data Analysis
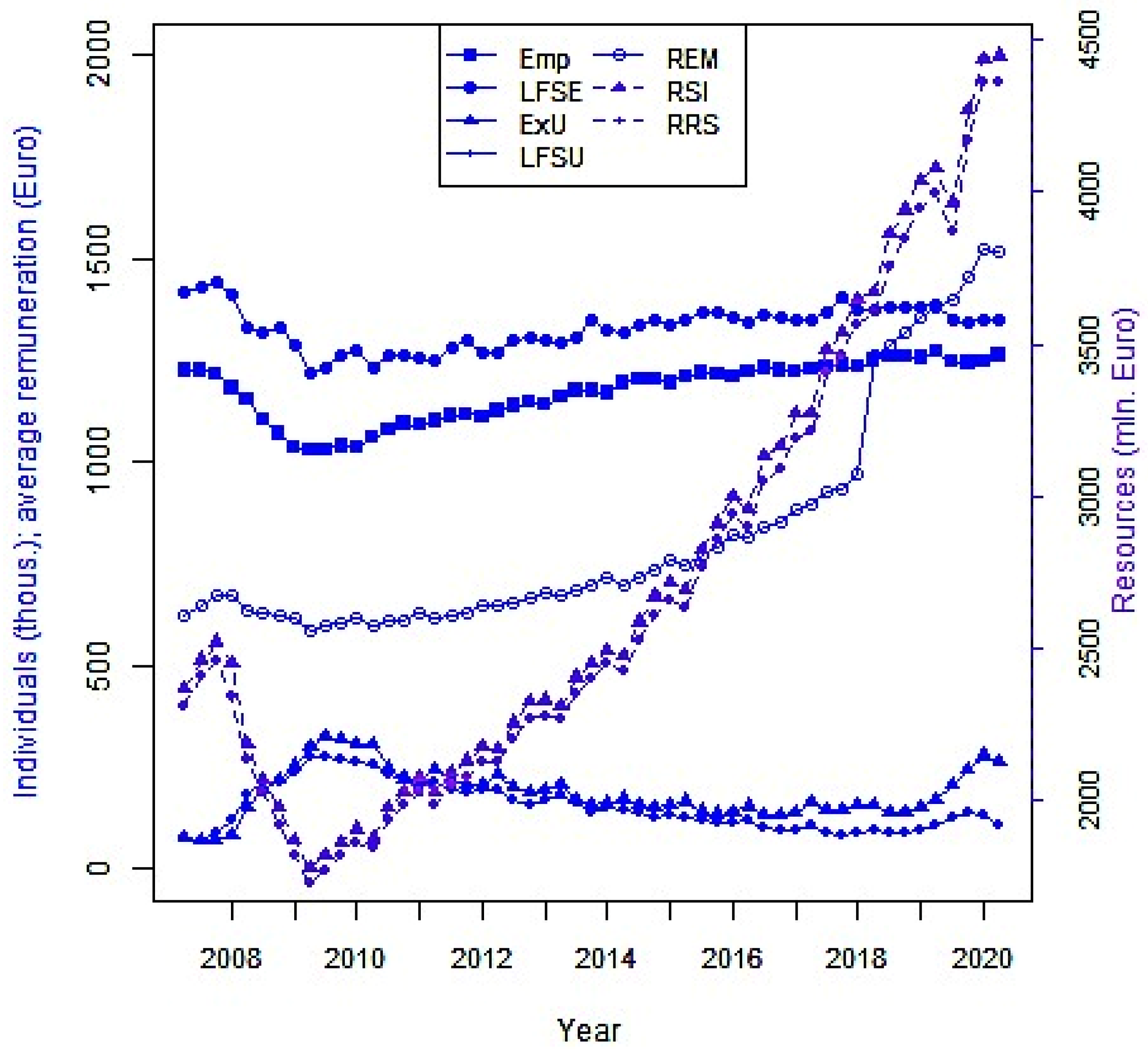
4. Experimental Results
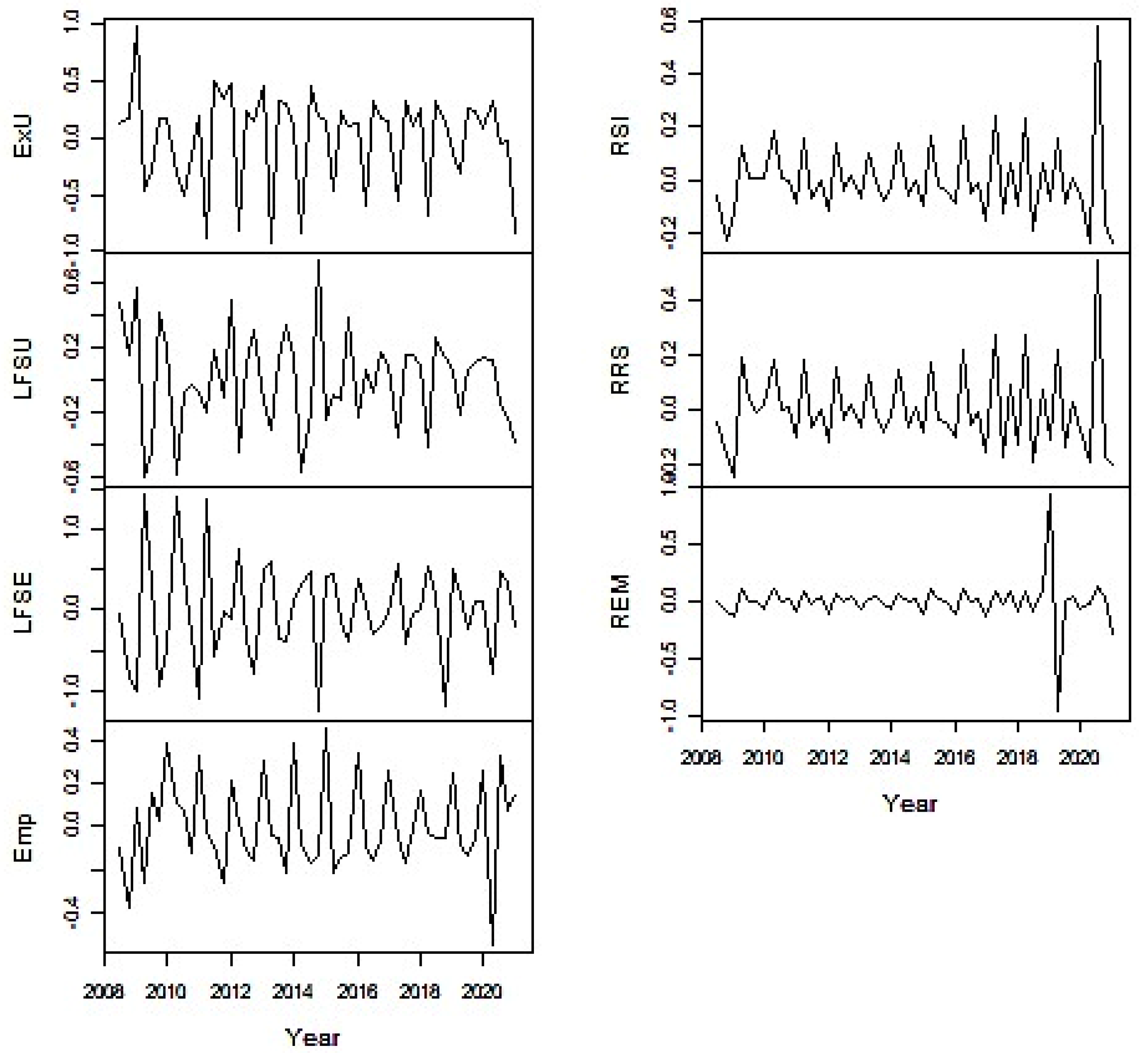
4.1. Data Used for the Study
- Labour Force Survey variables: number of employed persons (LFSE); number of the unemployed (LFSU), in thousand;
- Labour Remuneration Survey data: number of employees (Emp), in thousand; enterprise resources for remuneration (RRS), in EUR million;
- Labour Exchange Office data: number of the registered unemployed (ExU), in thousand;
- Administrative data of the State Social Insurance Fund Board: enterprise remuneration from which taxes are paid (RSI), in EUR million; Average wages and salaries of employees, excluding individual enterprises (average remuneration), in EUR (REM).
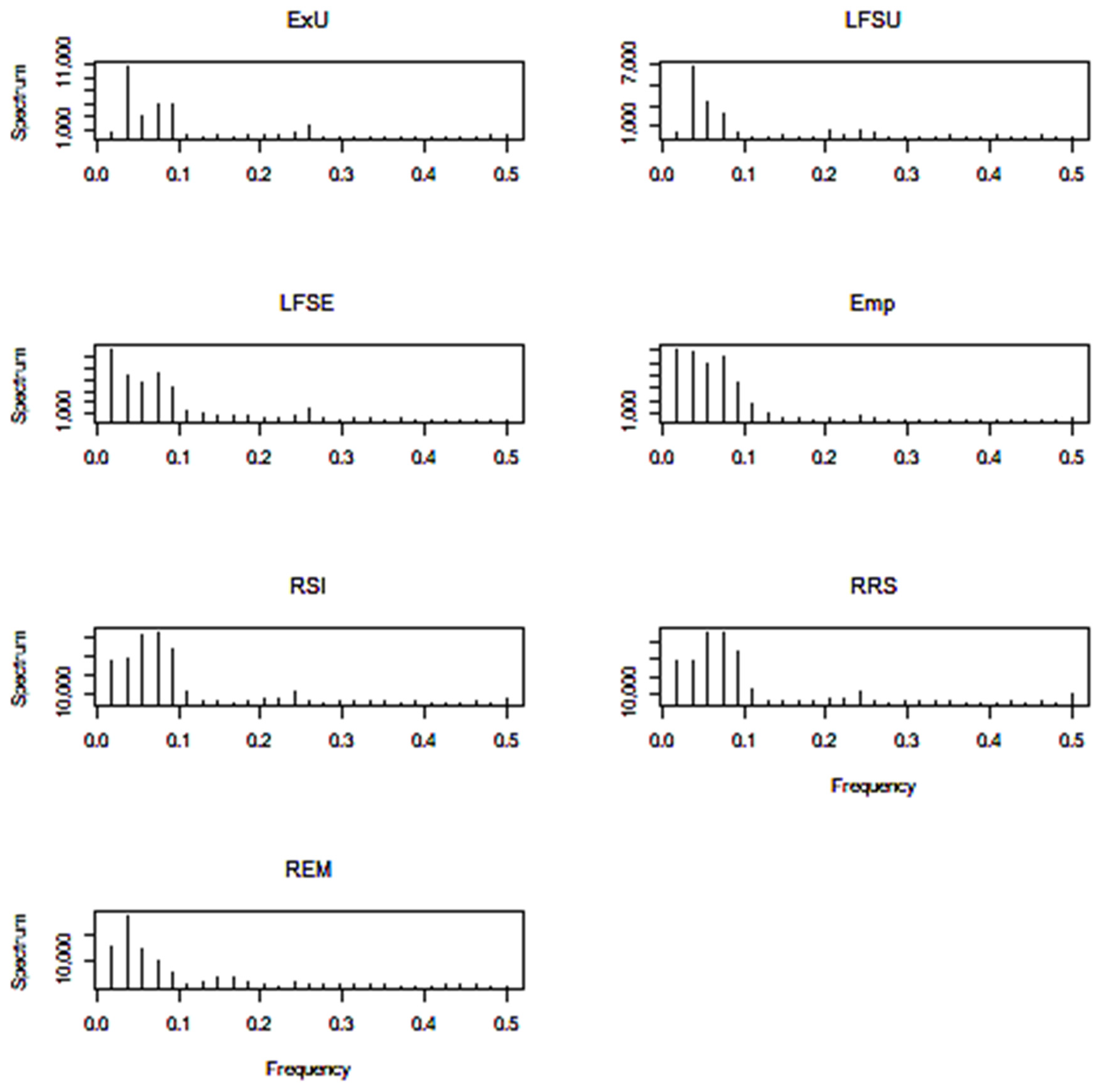
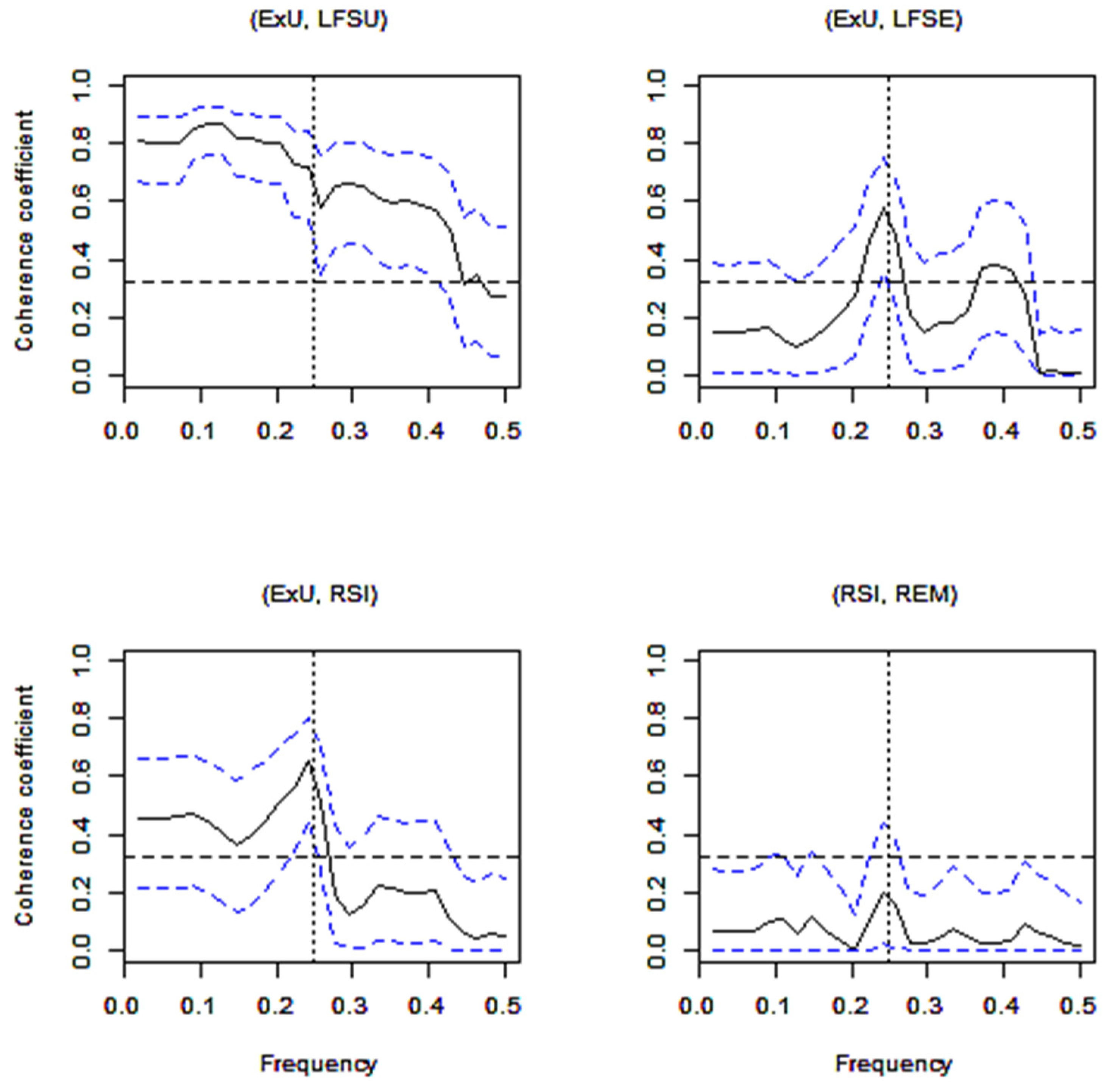
4.2. Data Analysis for Ordinary Coherence
4.3. Data Analysis for Granger Causality
- LFSE ⟹ LFSU, ;
- Emp ⟹ ExU, .
- 3.
- Emp ⟹ RSI, ;
- 4.
- Emp ⟹ RSE, .
- 5.
- ;
- 6.
- .
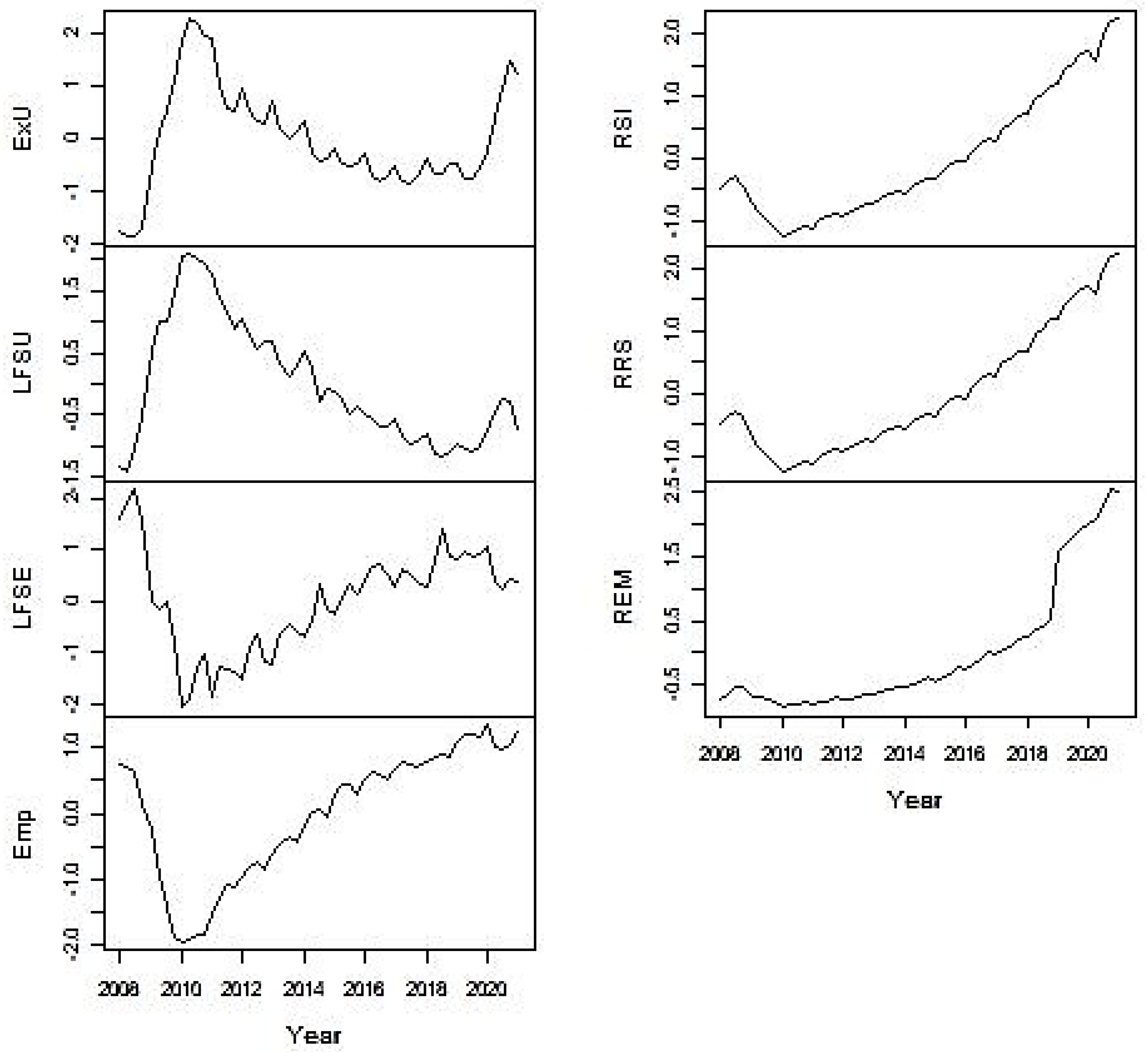
4.4. Visualization of the Time Series
4.5. Software
5. Discussion
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Quarter | ExU | LFSU | LFSE | Emp | RSI | RRS | REM |
|---|---|---|---|---|---|---|---|---|
| 2008 | 1 | 76,247 | 74.2 | 1416.3 | 1,225,579 | 623.1 | 2,308,808,359 | 2,363,109,444 |
| 2008 | 2 | 68,377 | 68.5 | 1432.1 | 1,225,139 | 647.8 | 2,406,414,174 | 2,461,320,556 |
| 2008 | 3 | 69,056 | 90.2 | 1445.8 | 1,217,387 | 671.9 | 2,461,575,844 | 2,519,700,890 |
| 2008 | 4 | 79,839 | 120.2 | 1414.2 | 1,182,155 | 671.7 | 2,344,094,370 | 2,448,874,661 |
| 2009 | 1 | 150,867 | 183.4 | 1329.9 | 1,153,522 | 635.2 | 2,133,829,174 | 2,184,921,227 |
| 2009 | 2 | 193,005 | 210.9 | 1321.6 | 1,105,870 | 629.2 | 2,022,994,119 | 2,066,057,345 |
| 2009 | 3 | 216,797 | 211.8 | 1329.8 | 1,069,554 | 620.4 | 1,920,387,308 | 1,973,800,770 |
| 2009 | 4 | 251,803 | 236.5 | 1288.3 | 1,035,599 | 613.5 | 1,820,404,831 | 1,869,016,244 |
| 2010 | 1 | 298,039 | 272.2 | 1221.9 | 1,029,803 | 588.3 | 1,727,789,493 | 1,774,727,272 |
| 2010 | 2 | 324,468 | 273.7 | 1231.0 | 1,031,499 | 595.4 | 1,772,024558 | 1,819,986,665 |
| 2010 | 3 | 319,943 | 270.5 | 1261.5 | 1,038,689 | 602.9 | 1,818,575,281 | 1,860,114,000 |
| 2010 | 4 | 306,016 | 265.3 | 1276.2 | 1,037,375 | 614.4 | 1,861,967,661 | 1,905,767,899 |
| 2011 | 1 | 303,692 | 255.1 | 1232.9 | 1,059,600 | 600.0 | 1,840,842,491 | 1,871,739,022 |
| 2011 | 2 | 246,707 | 232.9 | 1262.2 | 1,080,333 | 610.4 | 1,938,042,383 | 1,975,212,406 |
| 2011 | 3 | 221,274 | 221.3 | 1260.7 | 1,094,869 | 612.8 | 1,982,452,866 | 2,024,025,178 |
| 2011 | 4 | 217,134 | 202.8 | 1258.7 | 1,090,185 | 629.9 | 2,025,371,521 | 2,072,390,439 |
| 2012 | 1 | 242,059 | 212.7 | 1251.4 | 1,101,293 | 619.2 | 1,985,074,588 | 2,025,141,063 |
| 2012 | 2 | 216,475 | 196.5 | 1284.1 | 1,113,460 | 623.7 | 2,046,589,574 | 2,091,059,274 |
| 2012 | 3 | 205,422 | 185.5 | 1298.0 | 1,117,600 | 628.8 | 2,078,963,346 | 2,128,180,667 |
| 2012 | 4 | 203,537 | 192.5 | 1269.4 | 1,110,714 | 646.4 | 2,124,877,617 | 2,173,804,073 |
| 2013 | 1 | 229,502 | 191.2 | 1267.2 | 1,126,036 | 646.7 | 2,122,599,794 | 2,165,028,897 |
| 2013 | 2 | 197,661 | 171.8 | 1297.1 | 1,138,652 | 652.5 | 2,196,084,239 | 2,252,422,898 |
| 2013 | 3 | 185,739 | 159.6 | 1308.2 | 1,147,276 | 667.7 | 2,265,256,537 | 2,321,432,196 |
| 2013 | 4 | 192,387 | 167.2 | 1298.6 | 1,140,335 | 677.8 | 2,278,247,315 | 2,327,255,164 |
| 2014 | 1 | 206,079 | 183.4 | 1295.3 | 1,161,133 | 670.7 | 2,264,769,393 | 2,309,649,474 |
| 2014 | 2 | 167,988 | 165.5 | 1309.2 | 1,175,198 | 682.3 | 2,353,632,663 | 2,402,902,573 |
| 2014 | 3 | 157,944 | 135.4 | 1349.2 | 1,177,126 | 696.7 | 2,401,668,920 | 2,446,552,234 |
| 2014 | 4 | 160,011 | 147.8 | 1322.4 | 1,169,402 | 714.5 | 2,448,904,478 | 2,493,322,593 |
| 2015 | 1 | 171,767 | 145.8 | 1317.5 | 1,194,723 | 699.8 | 2,424,880,432 | 2,473,235,328 |
| 2015 | 2 | 154,516 | 138.0 | 1336.3 | 1,204,611 | 713.9 | 2,524,677,556 | 2,586,979,303 |
| 2015 | 3 | 151,583 | 122.5 | 1347.4 | 1,204,198 | 735.1 | 2,606,122,113 | 2,669,476,792 |
| 2015 | 4 | 154,745 | 129.5 | 1338.5 | 1,194,923 | 756.9 | 2,655,432,571 | 2,716,650,174 |
| 2016 | 1 | 165,882 | 122.5 | 1350.8 | 1,210,243 | 748.0 | 2,635,907,896 | 2,687,204,050 |
| 2016 | 2 | 139,980 | 119.1 | 1367.7 | 1,219,175 | 771.9 | 2,766,639,327 | 2,821,945,721 |
| 2016 | 3 | 134,454 | 111.0 | 1368.7 | 1,217,086 | 793.3 | 2,857,993,212 | 2,911,196,395 |
| 2016 | 4 | 139,141 | 112.0 | 1358.4 | 1,210,342 | 822.8 | 2,937,353,990 | 2,994,475,146 |
| 2017 | 1 | 153,495 | 117.7 | 1345.3 | 1,222,378 | 817.6 | 2,900,763,204 | 2,957,958,651 |
| 2017 | 2 | 133,083 | 102.2 | 1362.8 | 1,230,629 | 838.7 | 3,045,375,323 | 3,129,433,254 |
| 2017 | 3 | 132,574 | 95.5 | 1358.8 | 1,226,833 | 850.8 | 3,092,979,211 | 3,164,580,713 |
| 2017 | 4 | 139,308 | 97.1 | 1352.3 | 1,222,817 | 884.8 | 3,190,590,164 | 3,269,956,131 |
| 2018 | 1 | 162,200 | 103.9 | 1347.1 | 1,230,548 | 895.2 | 3,212,311,031 | 3,273,567,722 |
| 2018 | 2 | 143,082 | 86.0 | 1370.9 | 1,235,994 | 926.7 | 3,408,966,239 | 3,481,541,119 |
| 2018 | 3 | 144,222 | 82.9 | 1404.9 | 1,237,430 | 935.7 | 3,460,961,589 | 3,537,412,644 |
| 2018 | 4 | 154,430 | 87.4 | 1376.0 | 1,234,872 | 970.3 | 3,561,459,073 | 3,647,635,020 |
| 2019 | 1 | 155,921 | 95.1 | 1374.0 | 1,250,723 | 1262.7 | 3,601,427,871 | 3,671,909,464 |
| 2019 | 2 | 138,469 | 90.2 | 1382.2 | 1,260,340 | 1289.0 | 3,757,034,213 | 3,858,893,280 |
| 2019 | 3 | 137,013 | 88.9 | 1378.1 | 1,260,575 | 1317.6 | 3,847,743,644 | 3,940,044,105 |
| 2019 | 4 | 150,469 | 93.7 | 1379.4 | 1,256,362 | 1358.6 | 3,941,919,691 | 4,036,791,146 |
| 2020 | 1 | 169,436 | 106.3 | 1386.4 | 1,271,002 | 1381.0 | 3,995,577,232 | 4,074,616,070 |
| 2020 | 2 | 208,074 | 125.9 | 1351.5 | 1,245,638 | 1398.5 | 3,867,650,330 | 3,964,444,596 |
| 2020 | 3 | 243,271 | 137.2 | 1342.3 | 1,244,455 | 1454.8 | 4,172,921,127 | 4,268,937,946 |
| 2020 | 4 | 277,119 | 134.5 | 1352.4 | 1,248,681 | 1524.2 | 4,357,386,170 | 4,436,727,466 |
| 2021 | 1 | 259,800 | 108.8 | 1351.8 | 1,263,441 | 1517.4 | 4,363,643,377 | 4,448,379,003 |
References
- Li, F.F.; Cox, T.J. Digital Signal Processing in Audio and Acoustical Engineering; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Cohen, D.; Tsuchiya, N. The Effect of Common Signals on Power, Coherence and Granger Causality: Theoretical Review, Simulations, and Empirical Analysis of Fruit Fly LFPs Data. Front. Syst. Neurosci. 2018, 12, 30. [Google Scholar] [CrossRef] [PubMed]
- Sun, F.T.; Miller, L.M.; D’Esposito, M. Measuring interregional functional connectivity using coherence and partial coherence analyses of fMRI data. NeuroImage 2004, 21, 647–658. [Google Scholar] [CrossRef] [PubMed]
- Kock, W.E. Wave Coherence. In Engineering Applications of Lasers and Holography; Springer: Boston, MA, USA, 1975. [Google Scholar]
- Eurostat. European Statistics Code of Practice, 2nd ed.; Eurostat: Luxembourg, 2017; Available online: https://ec.europa.eu/eurostat/web/products-catalogues/-/KS-02-18-142 (accessed on 8 January 2022).
- OECD. Glossary of Statistical Terms. Available online: https://stats.oecd.org/glossary/ (accessed on 8 January 2022).
- Statistics Canada. Statistics Canada Quality Guidelines, 6th ed.; Statistics Canada: Ottawa, ON, Canada, 2019; pp. 14–15. Available online: https://www150.statcan.gc.ca/n1/pub/12-539-x/12-539-x2019001-eng.htm (accessed on 8 January 2022).
- Australian Bureau of Statistics. Available online: https://www.abs.gov.au/ (accessed on 8 January 2022).
- Eurostat. ESS Handbook for Quality Reports; Eurostat: Luxembourg, 2014; Available online: http://ec.europa.eu/eurostat/web/ess/-/the-ess-handbook-for-quality-reports-2014-edition (accessed on 8 January 2022).
- European Commission. ESSnet on Quality of Multisource Statistics—Komuso; Eurostat: Luxembourg, 2019; Available online: https://ec.europa.eu/eurostat/cros/content/essnet-quality-multisource-statistics-komuso_en/ (accessed on 8 January 2022).
- Pankūnas, V.; Janeiko, J.; Krapavickaitė, D. Coherence studies in time series. In Proceedings of the Workshop of Baltic-Nordic-Ukrainian Network on Survey Statistics, Jelgava, Latvia, 21–25 August 2018; pp. 66–69. Available online: http://www.statistikuasociacija.lv/workshop2018/files/papers/BNU2018-Pank%C5%ABnas-and-Janeiko.pdf (accessed on 3 March 2022).
- Till-Tentschert, U. Coherence Assessment of EU-SILC in Austria, 2006. In Proceedings of the Conference and Methodological Workshop “Comparative EU Statistics on Income and Living Conditions: Issues and Challenges”, Finland, Helsinki, 6–8 November 2006; Available online: https://www.stat.fi/eusilc/ws_5-2_till.pdf (accessed on 8 January 2022).
- African Development Bank. Labour Force Data Analysis: Guidelines with African Specificities; African Development Bank: Tunis, Tunisia, 2012; pp. 92–97. Available online: https://www.afdb.org/fileadmin/uploads/afdb/Documents/Publications/Labour%20Force%20Data%20Analysis_WEB.pdf (accessed on 8 January 2022).
- Eurostat. Quality Report of the European Union Labour Force Survey 2015; Eurostat: Luxembourg, 2017; pp. 28–32. Available online: http://ec.europa.eu/eurostat/documents/7870049/7887033/KS-FT-17-003-EN-N.pdf/22ed8f4e-9eb3-455c-924a-8df102620f89 (accessed on 8 January 2022).
- Wiener, N. Generalized harmonic analysis. Acta Math. 1930, 55, 117–258. [Google Scholar] [CrossRef]
- Shumway, R.H.; Stoffer, D.S. Time Series Analysis and Its Applications: With R Examples; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Wei, W.W.S. Time Series Analysis: Univariate and Multivariate Methods; Pearson Education: London, UK, 2006. [Google Scholar]
- Bendat, J.S.; Piersol, A.G. Random Data. Analysis and Measurement Procedures; Wiley-Interscience: Hoboken, NJ, USA, 2010. [Google Scholar]
- Papana, A. Connectivity Analysis for Multivariate Time Series: Correlation vs. Causality. Entropy 2021, 23, 1570. [Google Scholar] [CrossRef] [PubMed]
- Yue, J.; Takaahara, G.; Franczak, B.; Burr, W.S. Time Series Clustering using Coherence. In Proceedings of the 2nd International Conference on Statistics: Theory and Applications (ICSTA’20), Prague, Czech Republic, 19–21 August 2020. [Google Scholar] [CrossRef]
- Euán, C.; Sun, Y.; Ombao, H. Coherence-based time series clustering for statistical inference and visualization of brain connectivity. Ann. Appl. Stat. 2019, 13, 990–1015. [Google Scholar] [CrossRef] [Green Version]
- Foster, M.R.; Guinzy, N.J. The Coefficient of Coherence: Its estimation and Use in Geophysical Data Processing. Geophysics 1967, 32, 602–616. [Google Scholar] [CrossRef]
- Koopmans, L.H. On the Coefficient of Coherence for Weakly Stationary Stochastic Processes. Ann. Math. Stat. 1964, 35, 532–549. [Google Scholar] [CrossRef]
- Granger, C.W. Investigating causal relations by econometric models and cross-spectral methods. Econometrica 1969, 37, 424–438. [Google Scholar] [CrossRef]
- Breitung, J.; Candelon, B. Testing for short- and long-run causality: A frequency-domain approach. J. Econom. 2006, 132, 363–378. [Google Scholar] [CrossRef]
- Contreras-Reyes, J.E.; Hernández-Santoro, C. Assessing Granger-causality in the southern Humboldt current ecosystem using cross-spectral methods. Entropy 2021, 22, 1071. [Google Scholar] [CrossRef]
- Borlaf-Mena, I.; Badea, O.; Tanase, M.A. Assessing the Utility of Sentinel-1 Coherence Time Series for Temperate and Tropical Forest Mapping. Remote Sens. 2021, 13, 4814. [Google Scholar] [CrossRef]
- Kayer, A.S.; Sun, T.C.; D’Esposito, M. A Comparison of Granger causality and Coherency in fMRI-Based Analysis of the Motor System. Hum. Brain Mapp. 2009, 30, 3475–3494. [Google Scholar]
- Faes, L.; Erla, S.; Porta, A.; Nollo, G. A framework for assessing frequency domain causality in physiological time series with instantaneous effects. Philos. Trans. R. Soc. A 2013, 371, 20110618. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, Z.; Song, C.; Cai, H.; Yao, X.; Hu, G. Enhanced coherence using principal component analysis. Interpretation 2017, 5, T351–T359. [Google Scholar] [CrossRef]
- Le, N.; Song, S.; Zhang, Q.; Wang, R. Robust principal component analysis in optical micro-angiography. Quant. Imaging Med. Surg. 2017, 7, 654–667. Available online: https://qims.amegroups.com/article/view/17862 (accessed on 8 January 2022). [CrossRef] [PubMed] [Green Version]
- Cui, D.; Qi, S.; Gu, G.; Li, X.; Li, Z.; Wang, L.; Yin, S. Magnitude Squared Coherence Method based on Weighted Canonical Correlation Analysis for EEG Synchronization Analysis in Amnesic Mild Cognitive Impairment of Diabetes Mellitus. IEEE Trans. Neural Syst. Rehabil. Eng. 2018, 26, 1908–1917. [Google Scholar] [CrossRef]
- Zhao, Y.; Wachowski, N.; Azimi-Sadjadi, M.R. Target Coherence Analysis Using Canonical Correlation Decomposition for SAS Data. In Proceedings of the OCEANS 2009, Biloxi, MS, USA, 26–29 October 2009. [Google Scholar] [CrossRef]
- Nedungadi, A.G.; Ding, M.; Rangarajan, G. Block coherence: A method for measuring the interdependence between two blocks of neurobiological time series. Biol. Cybern. 2011, 104, 197–207. [Google Scholar] [CrossRef]
- Borg, I.; Groenen, P.J.F. Modern Multidimensional Scaling; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Dzemyda, G.; Kurasova, O.; Žilinskas, J. Multidimensional Data Visualization, Methods and Applications; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Statistics Lithuania: Official Statistics Portal. Available online: https://osp.stat.gov.lt/ (accessed on 20 January 2022).
- Dickey, D.A.; Fuller, W.A. Distribution of the estimates for autoregressive time series with a unit root. J. Am. Stat. Assoc. 1979, 74, 427–431. [Google Scholar]
- Gomez Gonzalez, A.; Rodrıguez, J.; Sagartzazu, X.; Schuhmacher, A.; Isasa, I. Multiple coherence method in time domain for the analysis of the transmission paths of noise and vibrations with non-stationary signals. In Proceedings of the ISMA2010 International Conference on Noise and Vibration Engineering including USD2010; Sas, P., Bergen, B., Eds.; Katholieke Universiteit Leuven: Leuven, Belgium, 2010; pp. 3927–3942. [Google Scholar]
- The Comprehensive R Archive Network. Available online: https://cran.r-project.org/ (accessed on 8 January 2022).
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Huang, Y.; Fergusson, N. Principal component analysis of the cross-axis apparent mass nonlinearity during whole-body vibration. Mech. Syst. Signal Process. 2021, 146, 107008. [Google Scholar] [CrossRef]
- Tesfaye, G.-M.; Tucker, J.D. Canonical correlation analysis for coherent change detection in synthetic aperture Sonar Imagery. Inst. Acoust. Proc. 2010, 32, 117–122. [Google Scholar]
- Innocenti, G.; Materassi, D. Econometrics as Sorcery. Statistical Finance (q-fin.ST). arXiv 2008, arXiv:0801.3047. [Google Scholar] [CrossRef]
- Materassi, D.; Innocenti, G. Coherence-based multivariate analysis of high frequency stock market values. arXiv 2008, arXiv:0805.2713. [Google Scholar] [CrossRef]
- Tzeng, J.; Lu, H.H.S.; Li, W.H. Multidimensional scaling for large genomic data sets. BMC Bioinform. 2008, 9, 179. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lima, M.F.M.; Machado, J.A.T.; Costa, A.C. A Multidimensional Scaling Analysis of Musical Sounds Based on Pseudo Phase Plane. Abstr. Appl. Anal. 2012, 2012, 436108. [Google Scholar] [CrossRef] [Green Version]
- Bernatavičienė, J.; Dzemyda, G.; Bazilevičius, G.; Medvedev, V.; Marcinkevičius, V.; Treigys, P. Method for visual detection of similarities in medical streaming data. Int. J. Comput. Commun. Control 2015, 10, 8–21. [Google Scholar] [CrossRef] [Green Version]







| ExU | LFSU | LFSE | Emp | RSI | RRS | REM | |
|---|---|---|---|---|---|---|---|
| ExU | 1.000 | ||||||
| LFSU | 0.581 | 1.000 | |||||
| LFSE | 0.482 | 0.347 | 1.000 | ||||
| Emp | 0.466 | (0.159) | 0.590 | 1.000 | |||
| RSI | 0.513 | 0.312 | 0.573 | 0.497 | 1.000 | ||
| RRS | 0.517 | 0.317 | 0.590 | 0.505 | 0.985 | 1.000 | |
| REM | (0.186) | (0.054) | (0.034) | (0.045) | (0.154) | (0.145) | 1.000 |
| ExU | LFSU | LFSE | Emp | RSI | RRS | REM | |
|---|---|---|---|---|---|---|---|
| ExU | 1 | F = 4.0304 p = 0.0080 ⟸ | F = 2.2583 p = 0.0808 ⟸ | ||||
| LFSU | 0.5777 | 1 | F = 2.9724 p = 0.0313 ⟸ | F = 3.598 p = 0.0139 ⟸ | |||
| LFSE | 0.5458 | 0.5509 | 1 | ||||
| Emp | 0.3540 | (0.2115) | 0.2765 | 1 | F = 2.4902 p = 0.0593 ⟹ | F = 2.7536 p = 0.0418 ⟹ | |
| RSI | (0.1235) | (0.1462) | 0.2609 | (0.0765) | 1 | F = 2.9798 p = 0.0310 ⟹ F2.1892 p = 0.0886 ⟸ | F = 2.4902 p = 0.0593 ⟸ |
| RRS | (0.2144) | (0.2125) | 0.3209 | (0.0720) | 0.9554 | 1 | F = 2.7536 p = 0.0418 ⟸ |
| REM | (0.0190) | (0.0049) | (0.0533) | (0.0082) | (0.0209) | (0.0125) | 1 |
| Case | Frequency ω | Period | Meaning |
|---|---|---|---|
| 1 | 0.074 | 13.5 | 3 years |
| 2 | 0.129 | 7.75 | 2 years |
| 3 | 0.241 | 4.15 | 1 year |
| 4 | 0.4 | 2.5 | 7.5 months |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krapavickaitė, D. Coherence Coefficient for Official Statistics. Mathematics 2022, 10, 1159. https://doi.org/10.3390/math10071159
Krapavickaitė D. Coherence Coefficient for Official Statistics. Mathematics. 2022; 10(7):1159. https://doi.org/10.3390/math10071159
Chicago/Turabian StyleKrapavickaitė, Danutė. 2022. "Coherence Coefficient for Official Statistics" Mathematics 10, no. 7: 1159. https://doi.org/10.3390/math10071159
APA StyleKrapavickaitė, D. (2022). Coherence Coefficient for Official Statistics. Mathematics, 10(7), 1159. https://doi.org/10.3390/math10071159