
A Stacking Ensemble Deep Learning Model for Bitcoin Price Prediction Using Twitter Comments on Bitcoin




Abstract
:1. Introduction
2. Related Work
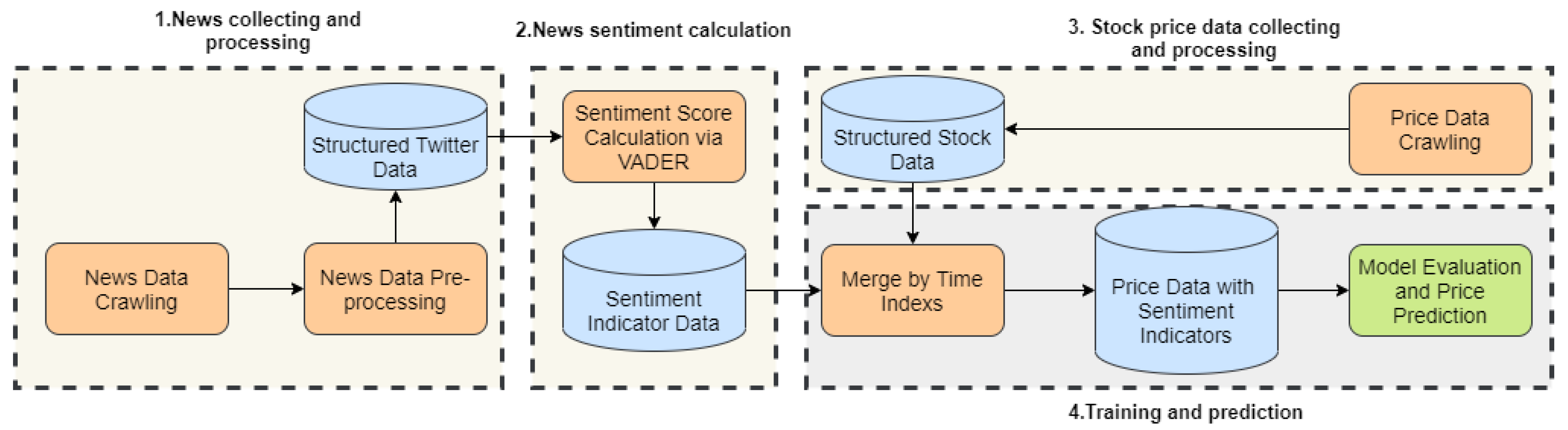
- There is less news about digital currency than stocks, which means there are not many reports about digital currency in the news, which is not enough to support our real-time prediction, so we chose social media.
- Digital currencies are traded 24 h a day and comments on Twitter are live 24 h a day, so real-time comments on Twitter can be very effective for price forecasting.
- Li’s work uses two data sources, price and news, to predict price. Considering the financial properties of digital currency, we use price, comments on Twitter and technical indicators to predict price.
- Data preprocessing methods are also different: The text data used in Li [1], namely news data, does not need to be cleaned and can be scored directly by VADER. Moreover, the Twitter data we obtain from crawlers is very dirty, such as pictures, links, etc., which need to be cleaned.
3. Methodology
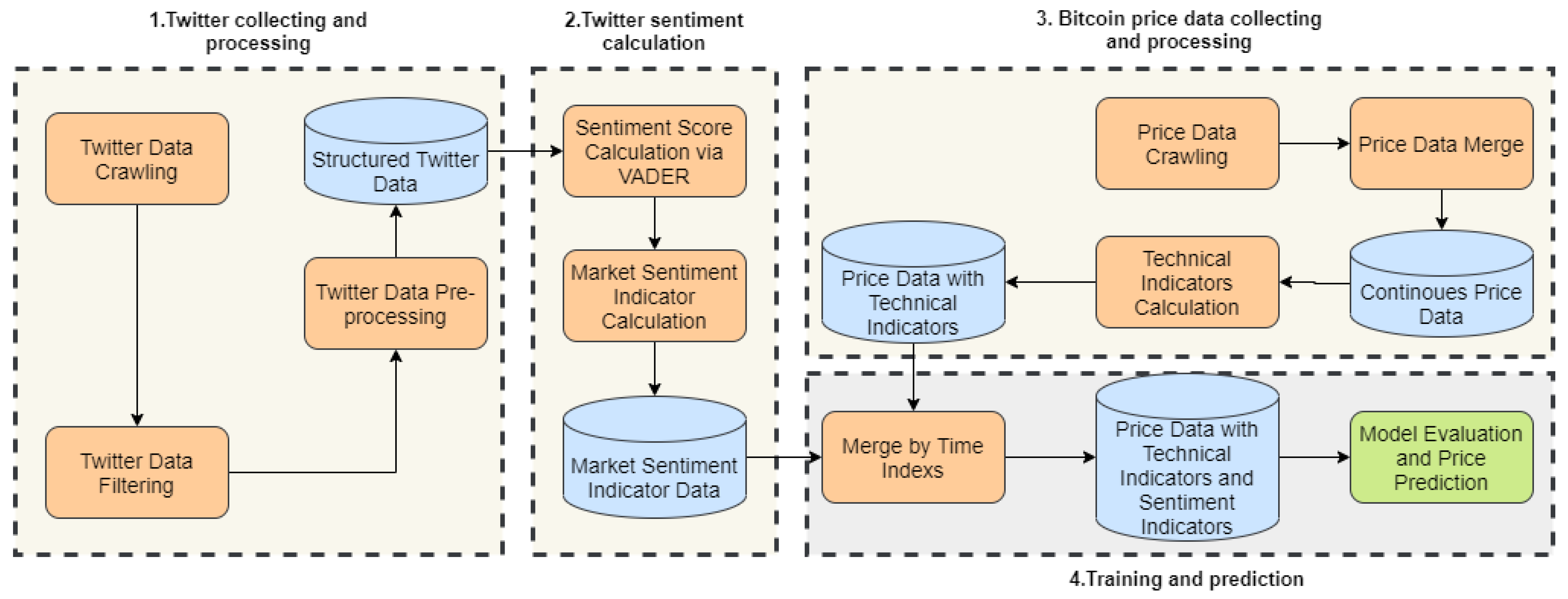
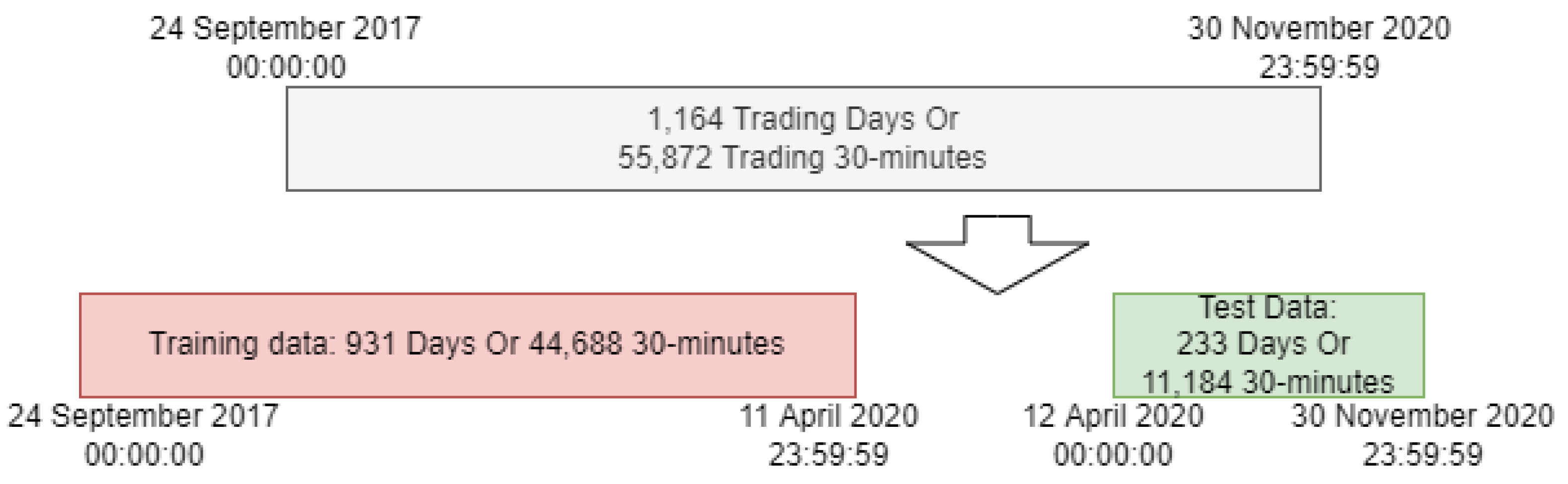
3.1. Bitcoin Price Data
3.2. Twitter Data
3.2.1. Data Collection
3.2.2. Sentiment Score Calculation
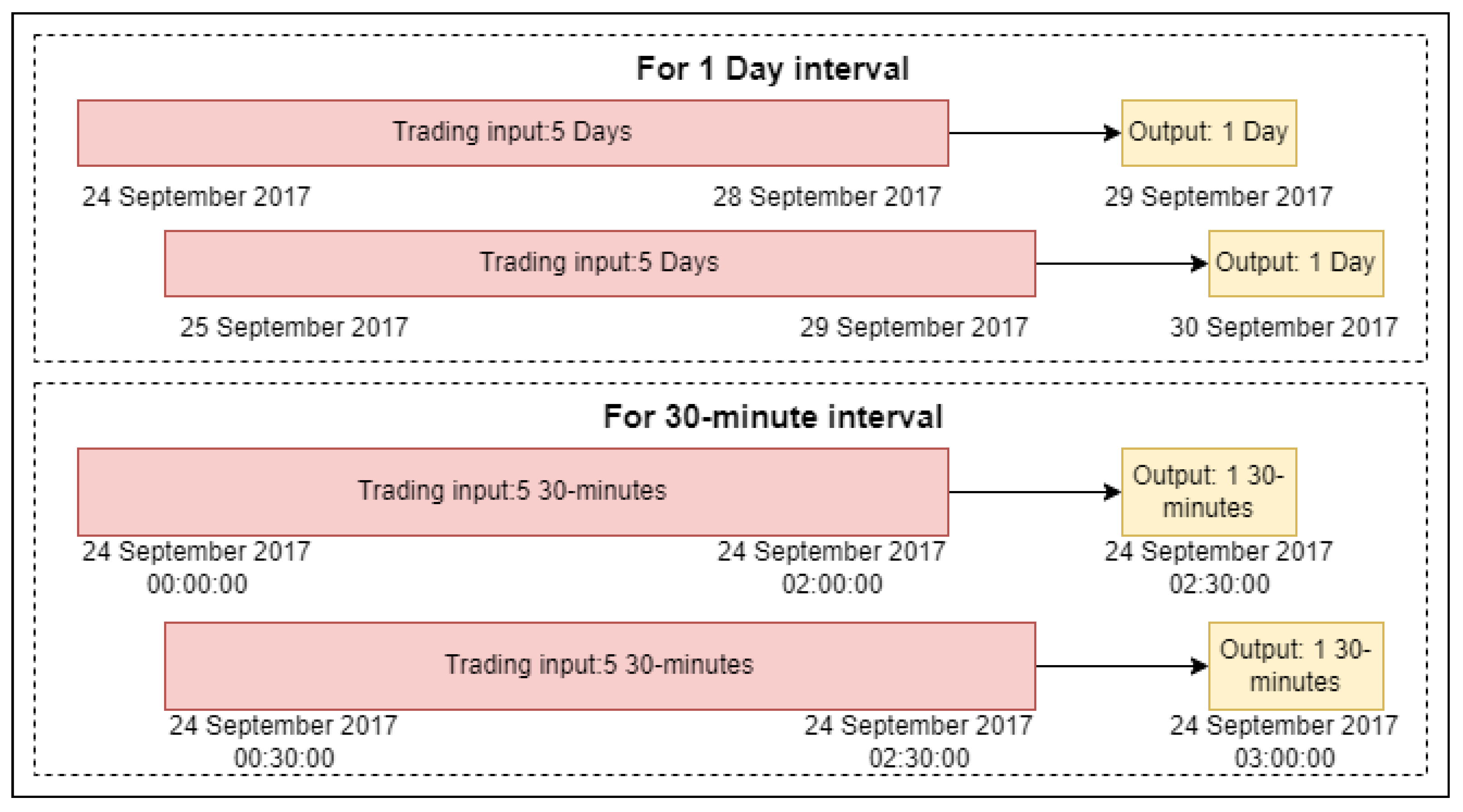
3.2.3. Small Granularity Sentiment Indicators
3.3. Technical Indicator Calculation
3.4. Stacking Ensemble Neural Network
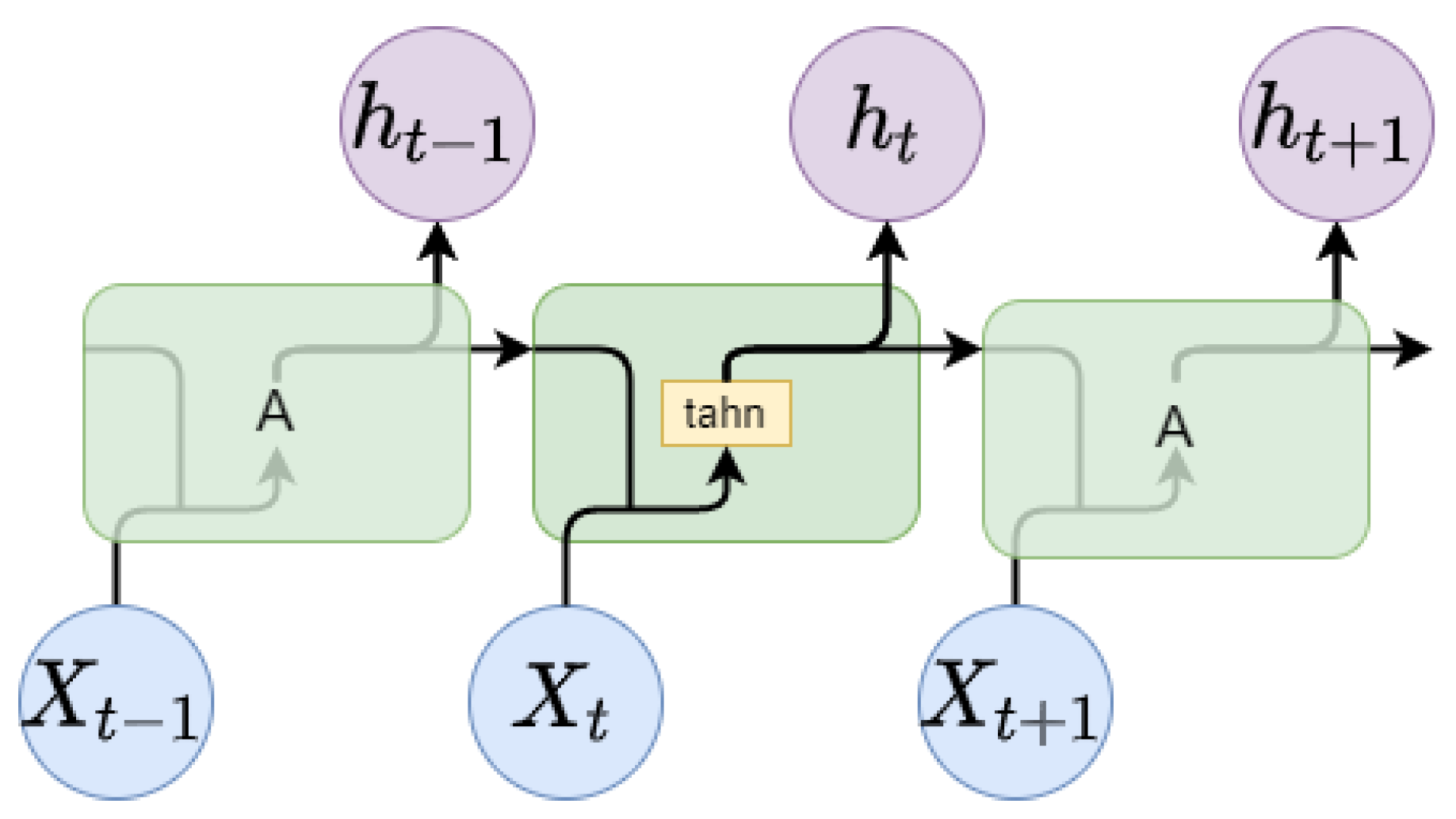
3.4.1. Long Short-Term Memory
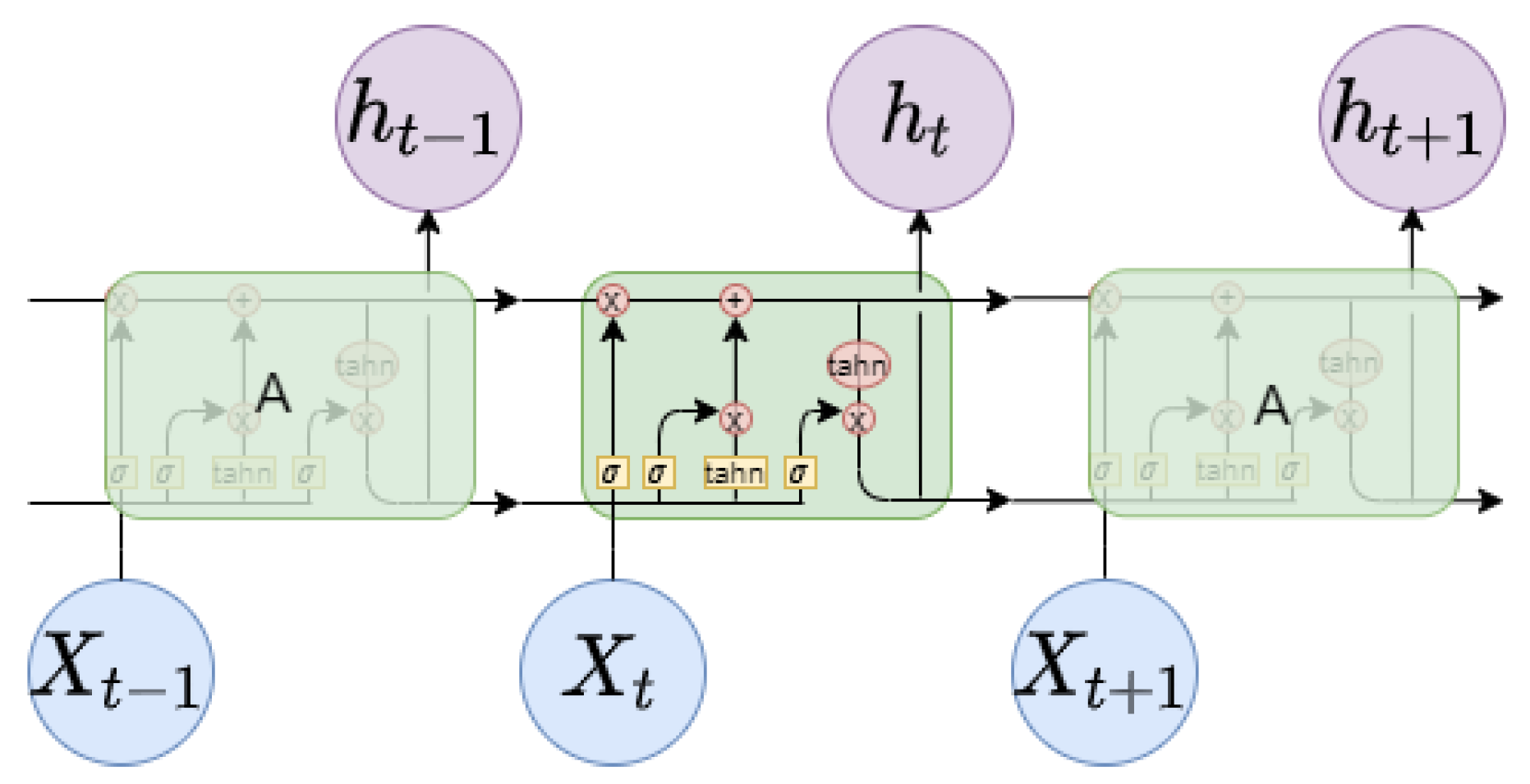
3.4.2. Gate Recurrent Unit
3.4.3. Stacking Ensemble
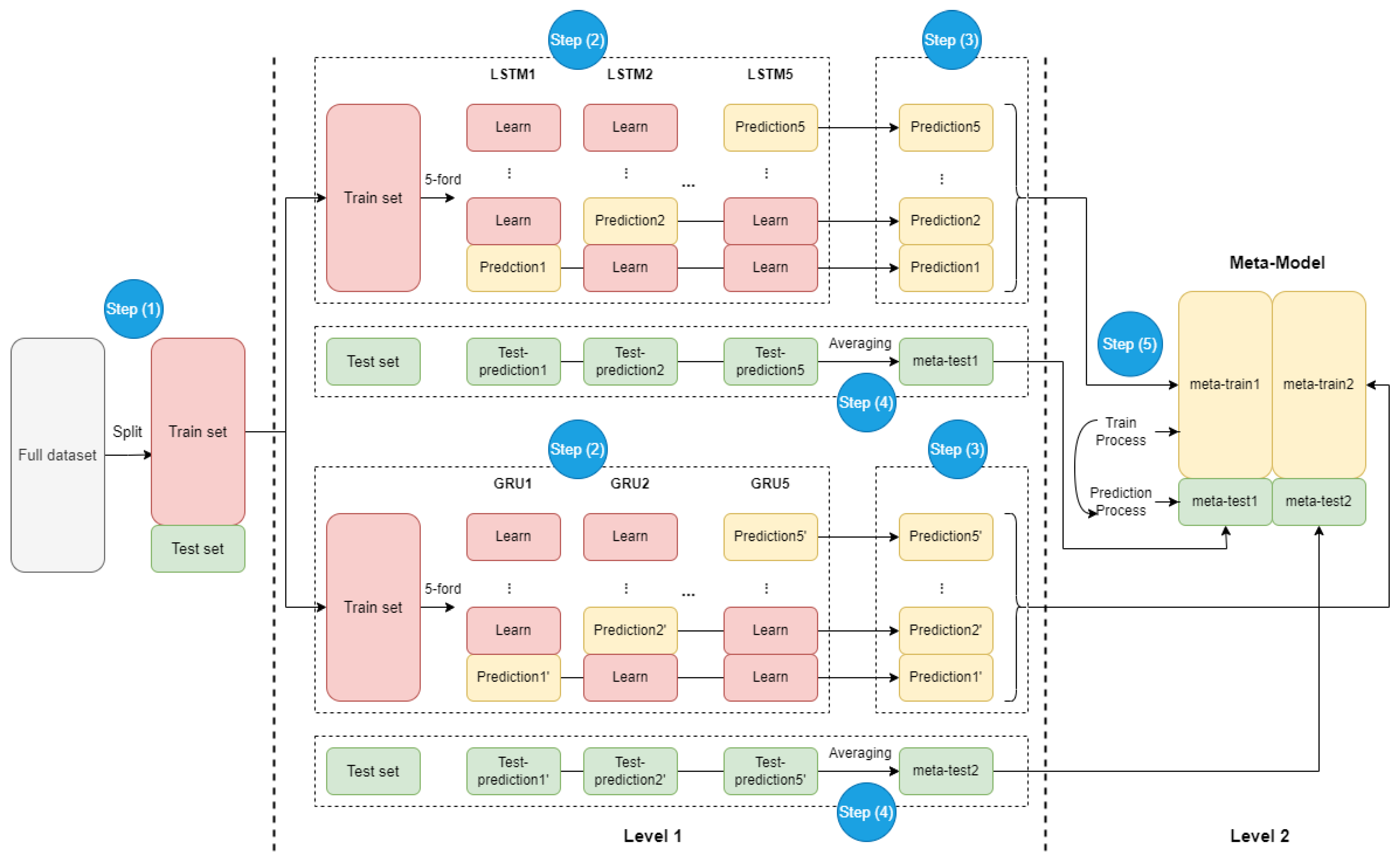
- Data split: Divide the data used into training set and test set as shown in the step (1).
- Sub-model training: Further divide the training set into five subsets, defined as train1 to train5. Then define the five LSTM instances as LSTM1 to LSTM5, and the five GRU instances as GRU1 to GRU5.
- Train sub models: Train LSTM1 on train1 to train4, and then predict the result as Prediction1 on data subset train5. Train LSTM2 on train1, train3 to train5, and then predict the result as Prediction2 on data subset train4, and so on. The same action was repeated in the five instances of GRU as shown in the step (2);
- Generate training features for meta-model: Combine prediction1-5 of LSTM successively and therefore obtain the feature meta-train1 for training meta-model. The same action was repeated on GRU to obtain the feature meta-train2 for training meta-model as shown in the step (3);
- Create new prediction features for layer two: Make predictions respectively on LSTM1-5 to obtain five prediction results by using the test set. Average these results to yield a feature meta-test1 for prediction. The same operation was repeated on GRU to obtain another feature for prediction as shown in the step (4).
- Meta-model training and predicting: Concatenate meta-train1 and meta-train2 for training the meta-model. Predict the result by using meta-model through the merging of meta-test1 and meta-test2 as shown in the step (5).
3.5. Evaluation Metrics
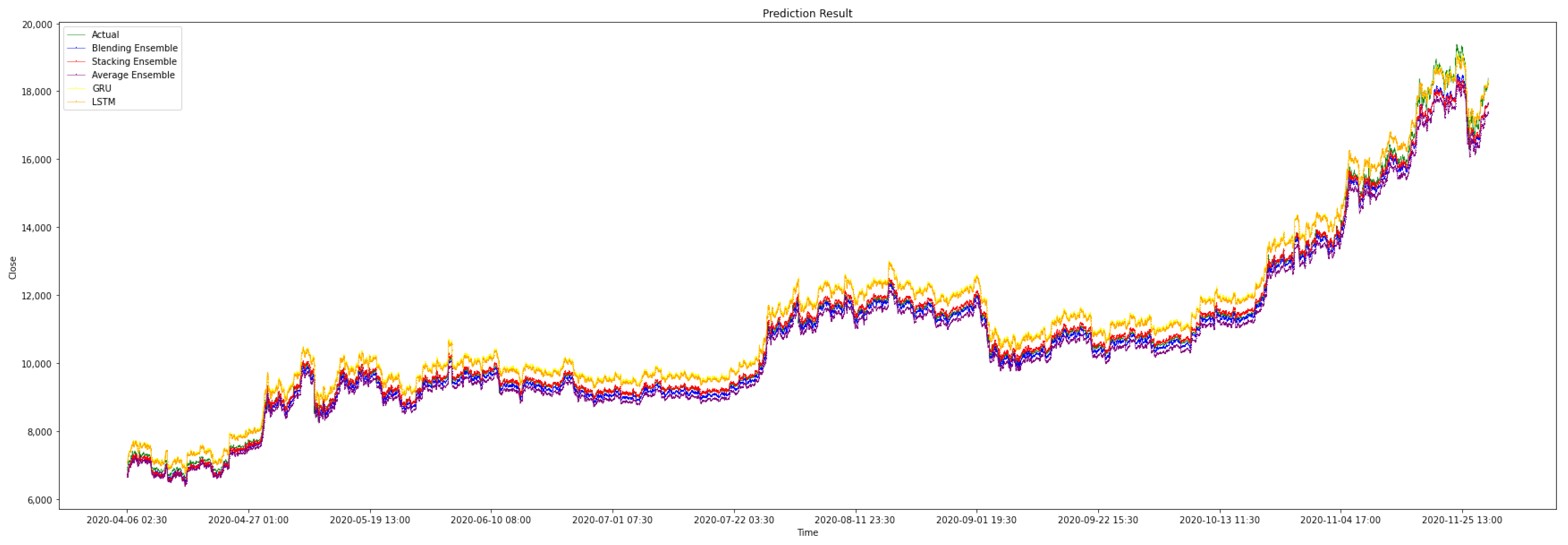
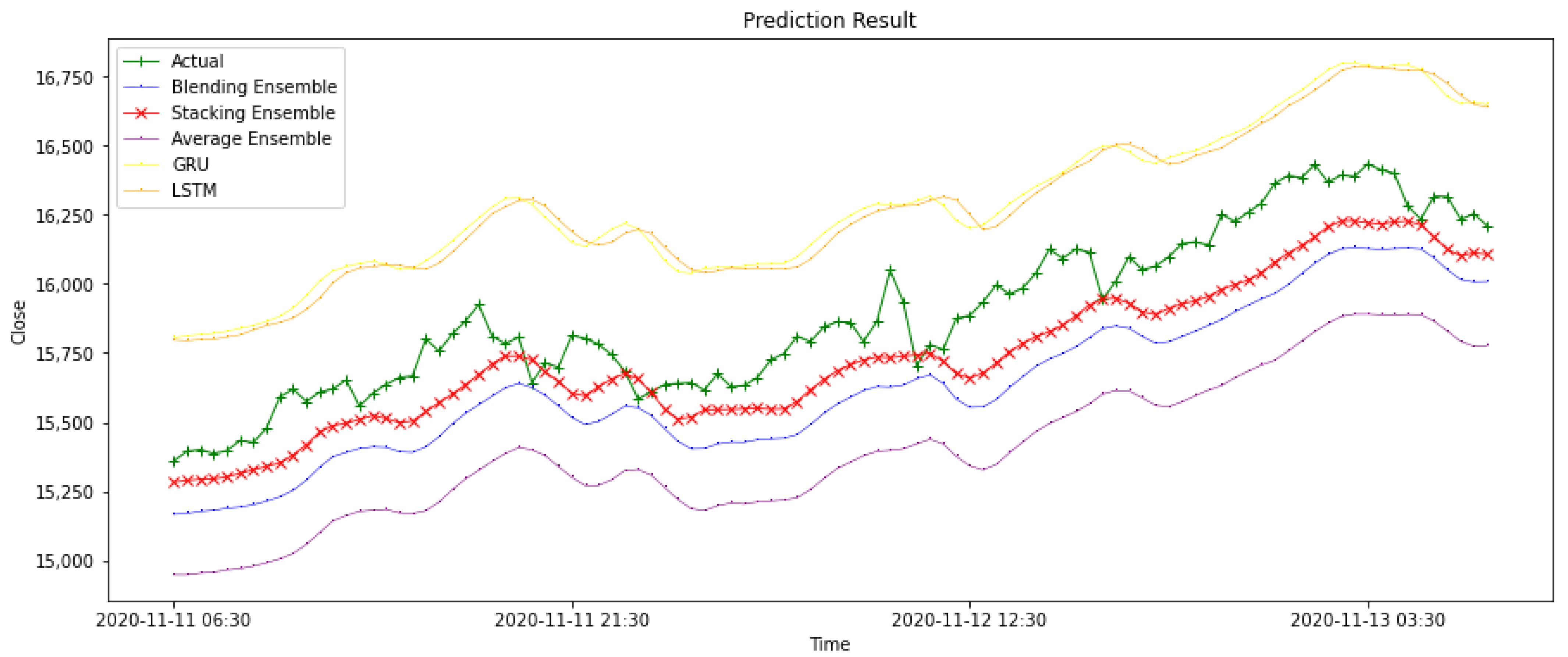
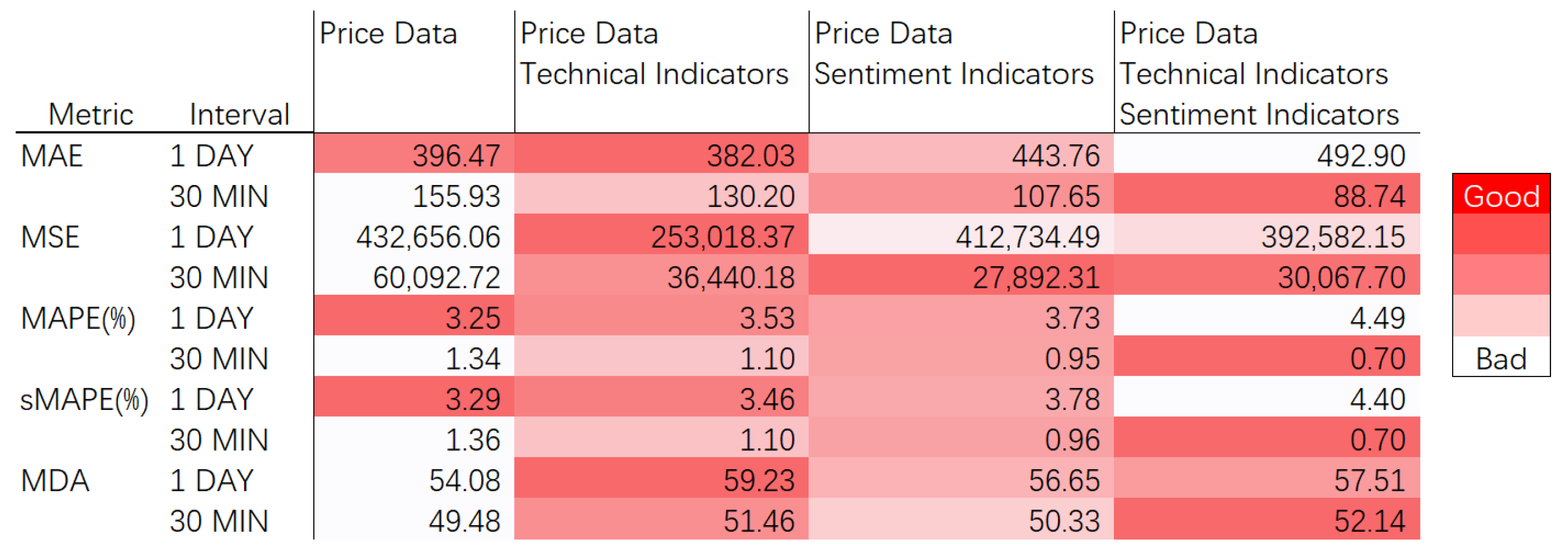
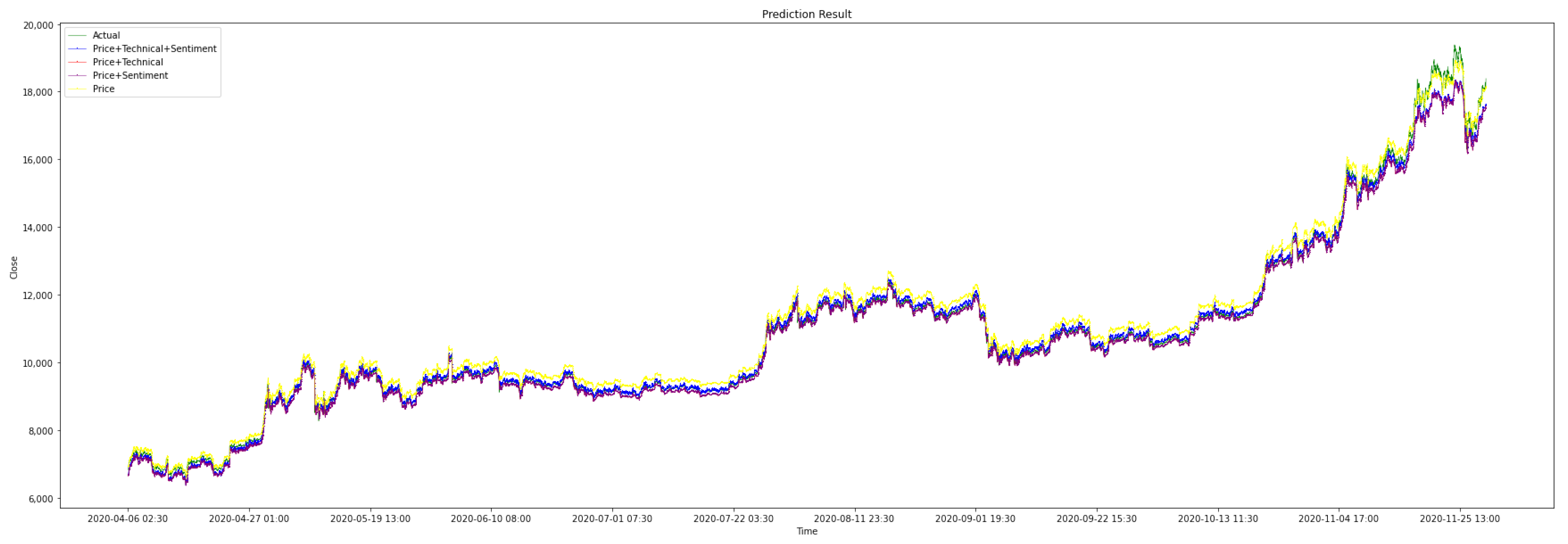
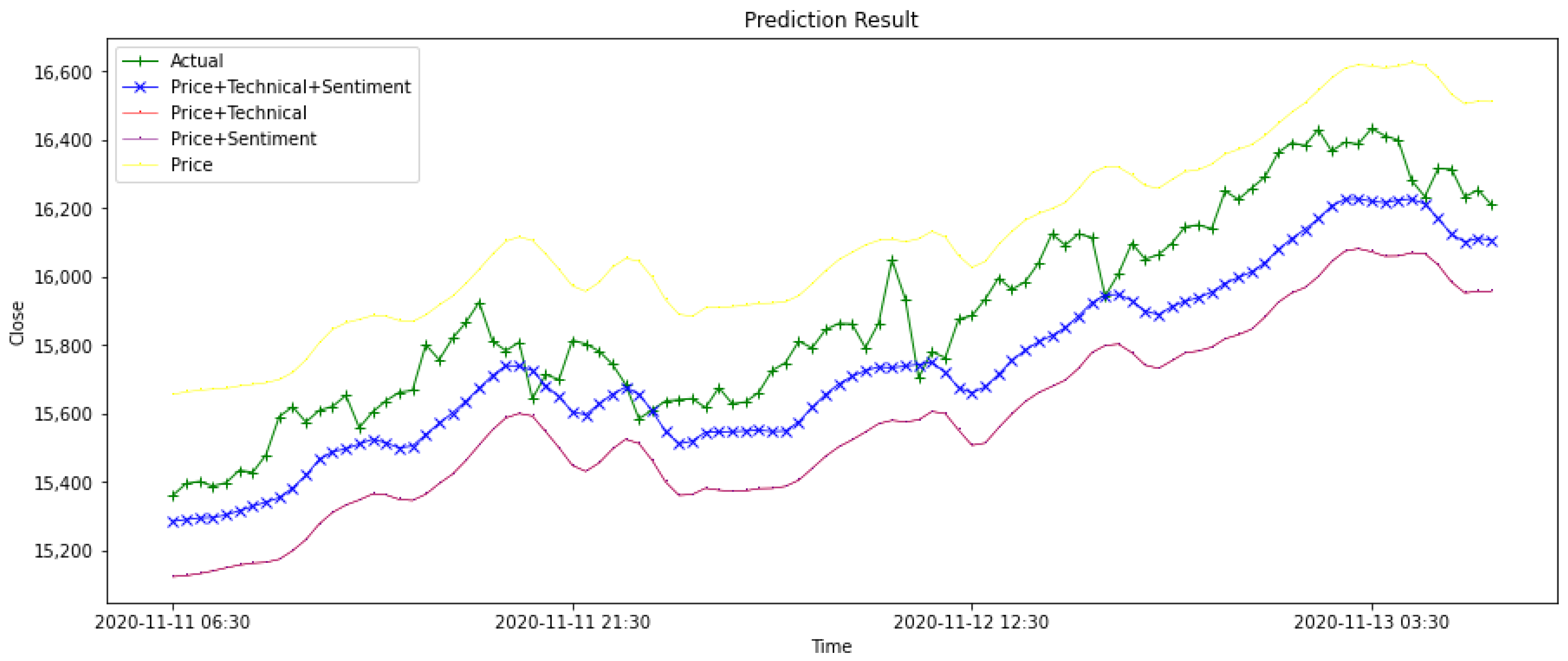
4. Result Evaluation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, Y.; Pan, Y. A novel ensemble deep learning model for stock prediction based on stock prices and news. Int. J. Data Sci. Anal. 2021, 13, 139–149. [Google Scholar] [CrossRef] [PubMed]
- Aslam, S.; Rasool, A.; Jiang, Q.; Qu, Q. LSTM based model for real-time stock market prediction on unexpected incidents. In Proceedings of the 2021 IEEE International Conference on Real-Time Computing and Robotics (RCAR), Xining, China, 15–19 July 2021; pp. 1149–1153. [Google Scholar] [CrossRef]
- Sutiksno, D.U.; Ahmar, A.S.; Kurniasih, N.; Susanto, E.; Leiwakabessy, A. Forecasting historical data of bitcoin using ARIMA and α-Sutte indicator. J. Phys. Conf. Ser. 2018, 1028, 012194. [Google Scholar] [CrossRef] [Green Version]
- Roy, S.; Nanjiba, S.; Chakrabarty, A. Bitcoin price forecasting using time series analysis. In Proceedings of the International Conference of Computer and Information Technology, Dhaka, Bangladesh, 21–23 December 2018; Volume 1, pp. 1–5. [Google Scholar] [CrossRef]
- Pant, D.R.; Neupane, P.; Poudel, A.; Pokhrel, A.K.; Lama, B.K. Recurrent neural network based bitcoin price prediction by Twitter sentiment analysis. In Proceedings of the 2018 IEEE 3rd International Conference on Computing, Communication and Security (ICCCS), Kathmandu, Nepal, 25–27 October 2018; Volume 1, pp. 128–132. [Google Scholar] [CrossRef]
- Gulker, M. Bitcoin’s largest Price Changes Coincide with Major News Events about the Cryptocurrency. Available online: https://www.aier.org/article/bitcoins-largest-price-changes-coincide-with-major-news-events-about-the-cryptocurrency/ (accessed on 15 December 2021).
- Li, T.R.; Chamrajnagar, A.S.; Fong, X.R.; Rizik, N.R.; Fu, F. Sentiment-based prediction of alternative cryptocurrency price fluctuations using gradient boosting tree model. Front. Phys. 2019, 7, 98. [Google Scholar] [CrossRef]
- Ötürk, S.S.; Bilgiç, M.E. Twitter & Bitcoin: Are the most influential accounts really influential? Appl. Econ. Lett. 2021, 1–4. [Google Scholar] [CrossRef]
- Nasekin, S.; Chen, C.Y.-H. Deep Learning-Based Cryptocurrency Sentiment Construction; SSRN Scholarly Paper ID 3310784; Social Science Research Network: Rochester, NY, USA, 2019. [Google Scholar] [CrossRef]
- Liu, W.; Jiang, Q.; Jiang, H.; Hu, J.; Qu, Q. A Sentiment Analysis Method Based on FinBERT-CNN for Guba Stock Forum. J. Integr. Technol. 2022, 11, 27–39. [Google Scholar] [CrossRef]
- Katsiampa, P. Volatility estimation for Bitcoin: A comparison of GARCH models. Econ. Lett. 2017, 158, 3–6. [Google Scholar] [CrossRef] [Green Version]
- Ayaz, Z.; Fiaidhi, J.; Sabah, A.; Anwer Ansari, M. Bitcoin price prediction using ARIMA model. TechRxiv 2020. [Google Scholar] [CrossRef]
- Bonifazi, G.; Corradini, E.; Ursino, D.; Virgili, L. A Social Network Analysis–based approach to investigate user behaviour during a cryptocurrency speculative bubble. J. Inf. Sci. 2021. [Google Scholar] [CrossRef]
- Jana, R.K.; Ghosh, I.; Das, D. A differential evolution-based regression framework for forecasting Bitcoin price. Ann. Oper. Res. 2021, 306, 295–320. [Google Scholar] [CrossRef]
- Kim, J.M.; Cho, C.; Jun, C. Forecasting the Price of the Cryptocurrency Using Linear and Nonlinear Error Correction Model. J. Risk Financ. Manag. 2022, 15, 74. [Google Scholar] [CrossRef]
- Jang, H.; Lee, J. An Empirical Study on Modeling and Prediction of Bitcoin Prices With Bayesian Neural Networks Based on Blockchain Information. IEEE Access 2018, 6, 5427–5437. [Google Scholar] [CrossRef]
- Mangla, N. Bitcoin price prediction using machine learning. Int. J. Inf. Comput. Sci. 2019, 6, 318–320. [Google Scholar]
- Shen, Z.; Wan, Q.; Leatham, D.J. Bitcoin Return Volatility Forecasting: A Comparative Study of GARCH Model and Machine Learning Model; Technical Report 290696; Agricultural and Applied Economics Association: Washington, DC, USA, 2019; Available online: https://ideas.repec.org/p/ags/aaea19/290696.html (accessed on 15 December 2021).
- Li, Y.; Dai, W. Bitcoin price forecasting method based on CNN-LSTM hybrid neural network model. J. Eng. 2020, 2020, 344–347. [Google Scholar] [CrossRef]
- Jay, P.; Kalariya, V.; Parmar, P.; Tanwar, S.; Kumar, N. Stochastic Neural Networks for Cryptocurrency Price Prediction. IEEE Access 2020, 8, 82804–82818. [Google Scholar] [CrossRef]
- Wołk, K. Advanced social media sentiment analysis for short-term cryptocurrency price prediction. Expert Syst. 2020, 37, e12493. [Google Scholar] [CrossRef]
- Jagannath, N.; Barbulescu, T.; Sallam, K.M.; Elgendi, I. A Self-Adaptive Deep Learning-Based Algorithm for Predictive Analysis of Bitcoin Price. IEEE Access 2021, 9, 34054–34066. [Google Scholar] [CrossRef]
- Guo, H.Z.; Zhang, D.; Liu, S.Y.; Wang, L. Bitcoin price forecasting: A perspective of underlying blockchain transactions. Decis. Support Syst. 2021, 151, 113650. [Google Scholar] [CrossRef]
- Loginova, E.; Tsang, W.K.; van Heijningen, G.; Kerkhove, L.; Benoit, D.F. Forecasting directional bitcoin price returns using aspect-based sentiment analysis on online text data. Mach. Learn. 2021. [Google Scholar] [CrossRef]
- Sridhar, S.; Sanagavarapu, S. Multi-Head Self-Attention Transformer for Dogecoin Price Prediction. In Proceedings of the 2021 14th International Conference on Human System Interaction (HSI), Gdansk, Poland, 8–10 July 2021. [Google Scholar] [CrossRef]
- Parekh, R.; Patel, N.P.; Thakkar, N.; Gupta, R.; Tanwar, S. DL-GuesS: Deep Learning and Sentiment Analysis-based Cryptocurrency Price Prediction. IEEE Access 2022, 10, 35398–35409. [Google Scholar] [CrossRef]
- Ibrahim, A.; Kashef, R.; Li, M.; Valencia, E.; Huang, E. Bitcoin network mechanics: Forecasting the btc closing price using vector auto-regression models based on endogenous and exogenous feature variables. J. Risk Financ. Manag. 2020, 13, 189. [Google Scholar] [CrossRef]
- Livieris, I.E.; Pintelas, E.; Stavroyiannis, S.; Pintelas, P. Ensemble deep learning models for forecasting cryptocurrency time-series. Algorithms 2020, 13, 121. [Google Scholar] [CrossRef]
- Shin, M.; Mohaisen, D.; Kim, J. Bitcoin price forecasting via ensemble-based LSTM deep learning networks. In Proceedings of the 2021 International Conference on Information Networking (ICOIN), Jeju Island, Korea, 13–16 January 2021; Volume 1, pp. 603–608. [Google Scholar] [CrossRef]
- Ye, Z.; Liu, W.; Jiang, Q.; Pan, Y. A cryptocurrency price prediction model based on Twitter sentiment indicators. In Proceedings of the International Conference on Big Data and Security, Shenzhen, China, 26–28 November 2021. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A critical review of recurrent neural networks for sequence learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Colah Understanding LSTM Networks. 2015. Available online: http://colah.github.io/posts/2015-08-Understanding-LSTMs/ (accessed on 15 December 2021).
- Cho, K.; van Merrienboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Zhou, Z.-H. Ensemble Methods: Foundations and Algorithms; Chapman and Hall/CRC: London, UK, 2012. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble methods in machine learning. In Multiple Classifier Systems; Springer: Berlin/Heidelberg, Germany, 2000; pp. 1–15. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; Jiang, Q.; Li, X. Application of neural networks in financial data mining. In Proceedings of the International Conference on Computational Intelligence, Xi’an, China, 15–19 December 2005; Volume 4. [Google Scholar]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Ganaie, M.A.; Hu, M.; Tanveer, M.; Suganthan, P.N. Ensemble deep learning: A review. arXiv 2021, arXiv:2104.02395. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, UK, 2016. [Google Scholar]
- Rocca, J. Ensemble Methods: Bagging, Boosting and Stacking. Available online: https://towardsdatascience.com/ensemble-methods-bagging-boosting-and-stacking-c9214a10a205 (accessed on 15 December 2021).
- Ji, S.; Kim, J.; Im, H. A comparative study of bitcoin price prediction using deep learning. Mathematics 2019, 7, 898. [Google Scholar] [CrossRef] [Green Version]
- Raju, S.M.; Tarif, A.M. Real-time prediction of BITCOIN price using machine learning techniques and public sentiment analysis. arXiv 2020, arXiv:2006.14473. [Google Scholar]
- Hu, X.; Chu, L.; Pei, J.; Liu, W.; Bian, J. Model complexity of deep learning: A survey. arXiv 2021, arXiv:2103.05127. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technical Indicators | Type | Description |
|---|---|---|
| MACD: Moving Average Convergence/Divergence | Momentum Indicator Functions | |
| SMA: Simple Moving Average | Overlap Studies Functions | |
| = the price of asset at period n | ||
| n = the number of total periods | ||
| SAR: Stop And Reverse | Overlap Studies Functions | |
| OBV: On Balance Volume | Volume Indicators | : |
| : | ||
| : | ||
| RSI: Relative Strength Index | Momentum Indicator Functions | |
| MFI: Money Flow Index | Momentum Indicator Functions | |
| Price Data | Technical Indicators | Sentiment Indicators |
|---|---|---|
| Open | MACD | CA |
| High | RSI | SGSBI |
| Low | MFI | SGSDI |
| Close | OBV | |
| Volume | SMA | |
| Quote Asset Volume | ||
| Number of Trades | ||
| Taker Buy Base Asset Volume | ||
| Taker Buy Quote Asset Volume |
| Model | Training Duration (Unit Second) | Training Duration (Unit Second) |
|---|---|---|
| (30-min Interval) | (1-Day Interval) | |
| LSTM | 169 | 26 |
| GRU | 154 | 16 |
| AE | 266 | 33 |
| BE | 322 | 48 |
| SE | 1576 | 99 |
| Price Data | Price Data | Price Data | Price Data | ||
|---|---|---|---|---|---|
| Technical Indicators | Sentiment Indicators | Technical Indicators | |||
| Metric | Model | Sentiment Indicators | |||
| MAE | LSTM | 312.011825 | 374.999918 | 330.661338 | 412.554188 |
| GRU | 268.728793 | 415.652382 | 419.355862 | 389.918484 | |
| AE | 168.247519 | 262.082363 | 172.195087 | 271.482766 | |
| SE | 155.933634 | 130.200637 | 107.650458 | 88.740831 | |
| BE | 156.373369 | 210.544757 | 103.320151 | 188.535888 | |
| MSE | LSTM | 108,823.7765 | 153,829.8002 | 121,815.3616 | 184,271.5385 |
| GRU | 105,638.9155 | 186,314.9489 | 190,762.1637 | 165,616.467 | |
| AE | 48,081.01116 | 88,879.84332 | 50,461.551 | 97,194.7086 | |
| SE | 60,092.71839 | 36,440.18042 | 27,892.31183 | 30,067.70409 | |
| BE | 43,270.7287 | 59,769.57549 | 31,385.89856 | 58,818.47366 | |
| MAPE | LSTM | 2.969864 | 3.592678 | 3.151563 | 3.966612 |
| GRU | 2.361411 | 4.008615 | 4.0305 | 3.740284 | |
| AE | 1.483315 | 2.387113 | 1.533826 | 2.457365 | |
| SE | 1.341431 | 1.103336 | 0.951954 | 0.69763 | |
| BE | 1.376177 | 1.932841 | 0.849297 | 1.651553 | |
| sMAPE | LSTM | 2.922733 | 3.524576 | 3.098525 | 3.884225 |
| GRU | 2.393608 | 3.924512 | 3.945382 | 3.666772 | |
| AE | 1.497166 | 2.418689 | 1.548865 | 2.490969 | |
| SE | 1.356031 | 1.101221 | 0.958526 | 0.70038 | |
| BE | 1.388322 | 1.954286 | 0.855509 | 1.66841 | |
| MDA | LSTM | 51.591618 | 51.618368 | 51.654035 | 51.645118 |
| GRU | 48.773963 | 51.627285 | 51.716451 | 51.618368 | |
| AE | 49.166295 | 48.72938 | 49.121712 | 48.747214 | |
| SE | 49.478377 | 51.457869 | 50.325457 | 52.144449 | |
| BE | 49.193045 | 48.952296 | 50.50379 | 48.970129 |
| Price Data | Price Data | Price Data | Price Data | ||
|---|---|---|---|---|---|
| Technical Indicators | Sentiment Indicators | Technical Indicators | |||
| Metric | Model | Sentiment Indicators | |||
| MAE | LSTM | 848.14 | 886.21 | 710.44 | 724.19 |
| GRU | 853.15 | 547.62 | 612.19 | 854.11 | |
| AE | 446.10 | 489.68 | 454.78 | 902.65 | |
| SE | 396.47 | 382.03 | 443.76 | 492.90 | |
| BE | 395.78 | 359.08 | 461.73 | 521.10 | |
| MSE | LSTM | 1,269,660.00 | 1,295,847.00 | 1,019,135.00 | 1,047,841.00 |
| GRU | 1,118,205.00 | 428,177.66 | 525,815.54 | 911,621.13 | |
| AE | 439,481.27 | 514,340.94 | 421,803.11 | 1,010,587.00 | |
| SE | 432,656.06 | 253,018.37 | 412,734.49 | 392,582.15 | |
| BE | 334,694.01 | 276,185.43 | 357,483.50 | 430,310.16 | |
| MAPE | LSTM | 7.05 | 7.45 | 5.81 | 5.92 |
| GRU | 7.27 | 5.26 | 5.87 | 8.34 | |
| AE | 3.73 | 4.09 | 3.91 | 8.82 | |
| SE | 3.25 | 3.53 | 3.73 | 4.49 | |
| BE | 3.37 | 3.18 | 4.25 | 4.89 | |
| sMAPE | LSTM | 7.42 | 7.83 | 6.06 | 6.17 |
| GRU | 7.62 | 5.10 | 5.67 | 7.93 | |
| AE | 3.80 | 4.19 | 3.91 | 8.36 | |
| SE | 3.29 | 3.46 | 3.75 | 4.40 | |
| BE | 3.44 | 3.16 | 4.16 | 4.74 | |
| MDA | LSTM | 47.21 | 46.35 | 48.50 | 48.93 |
| GRU | 42.49 | 57.94 | 59.23 | 57.51 | |
| AE | 54.51 | 49.36 | 57.08 | 58.37 | |
| SE | 54.08 | 59.23 | 56.65 | 57.51 | |
| BE | 52.79 | 57.08 | 59.66 | 59.23 |
| Interval | 30 min | 1 Day | |
|---|---|---|---|
| Price Data | Price Data | ||
| Technical Indicators | Technical Indicators | ||
| Metric | Model | Sentiment Indicators | Sentiment Indicators |
| MAE | LSTM | 412.554188 | 724.19 |
| GRU | 389.918484 | 854.11 | |
| AE | 271.482766 | 902.65 | |
| SE | 88.740831 | 492.90 | |
| BE | 188.535888 | 521.10 | |
| MSE | LSTM | 184,271.5385 | 1,047,841.00 |
| GRU | 165,616.467 | 911,621.13 | |
| AE | 97,194.7086 | 1,010,587.00 | |
| SE | 30,067.70409 | 392,582.15 | |
| BE | 58,818.47366 | 430,310.16 | |
| MAPE | LSTM | 3.966612 | 5.92 |
| GRU | 3.740284 | 8.34 | |
| AE | 2.457365 | 8.82 | |
| SE | 0.69763 | 4.49 | |
| BE | 1.651553 | 4.89 | |
| sMAPE | LSTM | 3.884225 | 6.17 |
| GRU | 3.666772 | 7.93 | |
| AE | 2.490969 | 8.36 | |
| SE | 0.70038 | 4.40 | |
| BE | 1.66841 | 4.74 | |
| MDA | LSTM | 51.645118 | 48.93 |
| GRU | 51.618368 | 57.51 | |
| AE | 48.747214 | 58.37 | |
| SE | 52.144449 | 57.51 | |
| BE | 48.970129 | 59.23 |
| Price Data | Price Data | Price Data | Price Data | |
|---|---|---|---|---|
| Technical Indicators | Sentiment Indicators | Technical Indicators | ||
| Interval | Sentiment Indicators | |||
| 1 day | 396.47 | 382.03 | 443.76 | 492.90 |
| 30 min | 155.933634 | 130.200637 | 107.650458 | 88.740831 |
| Author & Reference No. | Year | Method | Dataset | Metric |
|---|---|---|---|---|
| S, Ji [42] | 2019 | Deep neural network (DNN) | Daily Bitcoin price data and blockchain infomation from 29 November 2011 to 31 December 2018 | MAPE: 3.61% |
| S, Raju [43] | 2020 | LSTM (LSTM) | 634 daily Bitcoin English tweets and transaction data from 2017 to 2018 | RMSE: 197.515 |
| M, Shin [29] | 2021 | Ensemble Minute + Hour + Day LSTM | Transaction data from December 2017 to November 2018 per 3 min | RMSE: 31.60 (weighted price) |
| Proposed work (ensemble deep model) | 2021 | Stacking ensemble deep model of 2 base models: LSTM & GRU | Tweets, transaction data, technical data from September 2017 to January 2021 per 30 min | MAE: 88.740831 RMSE: 173.400415 MAPE: 0.69763% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, Z.; Wu, Y.; Chen, H.; Pan, Y.; Jiang, Q. A Stacking Ensemble Deep Learning Model for Bitcoin Price Prediction Using Twitter Comments on Bitcoin. Mathematics 2022, 10, 1307. https://doi.org/10.3390/math10081307
Ye Z, Wu Y, Chen H, Pan Y, Jiang Q. A Stacking Ensemble Deep Learning Model for Bitcoin Price Prediction Using Twitter Comments on Bitcoin. Mathematics. 2022; 10(8):1307. https://doi.org/10.3390/math10081307
Chicago/Turabian StyleYe, Zi, Yinxu Wu, Hui Chen, Yi Pan, and Qingshan Jiang. 2022. "A Stacking Ensemble Deep Learning Model for Bitcoin Price Prediction Using Twitter Comments on Bitcoin" Mathematics 10, no. 8: 1307. https://doi.org/10.3390/math10081307
APA StyleYe, Z., Wu, Y., Chen, H., Pan, Y., & Jiang, Q. (2022). A Stacking Ensemble Deep Learning Model for Bitcoin Price Prediction Using Twitter Comments on Bitcoin. Mathematics, 10(8), 1307. https://doi.org/10.3390/math10081307