
Polynomial-Time Constrained Message Passing for Exact MAP Inference on Discrete Models with Global Dependencies

Abstract
:1. Introduction
2. Problem Setting
3. Exact Inference for Problem 1
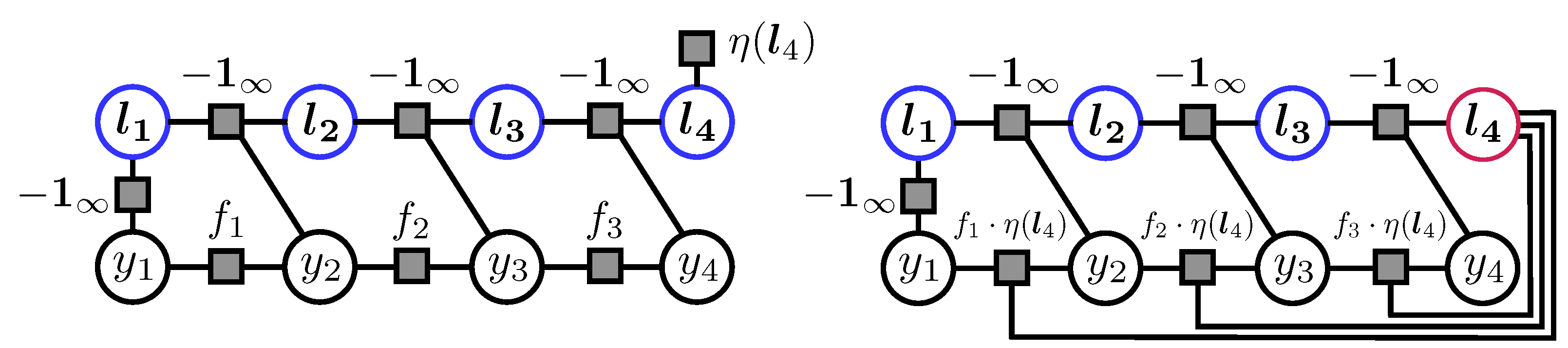
3.1. Algorithmic Core Idea for a Simple Chain Graph

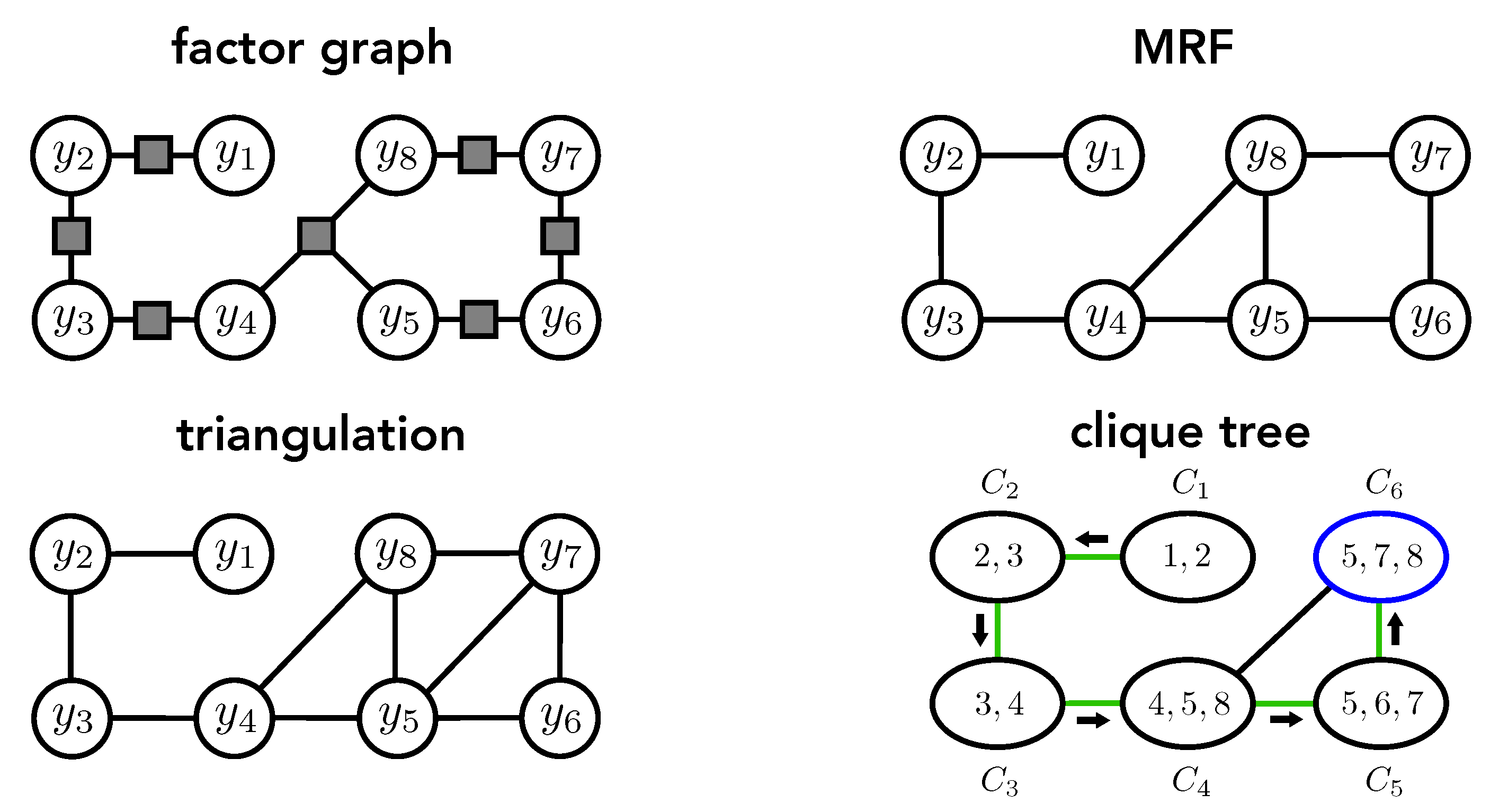
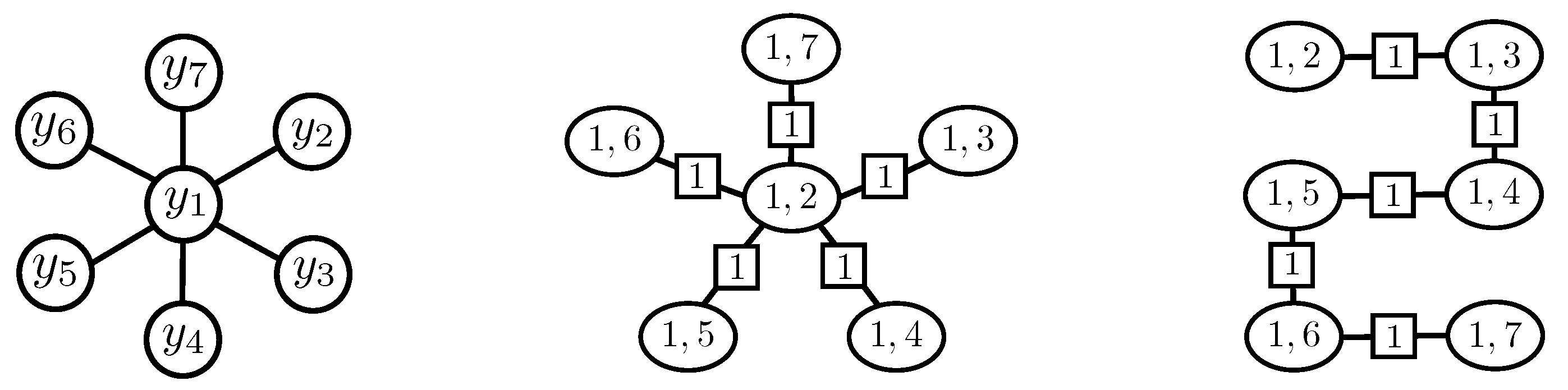
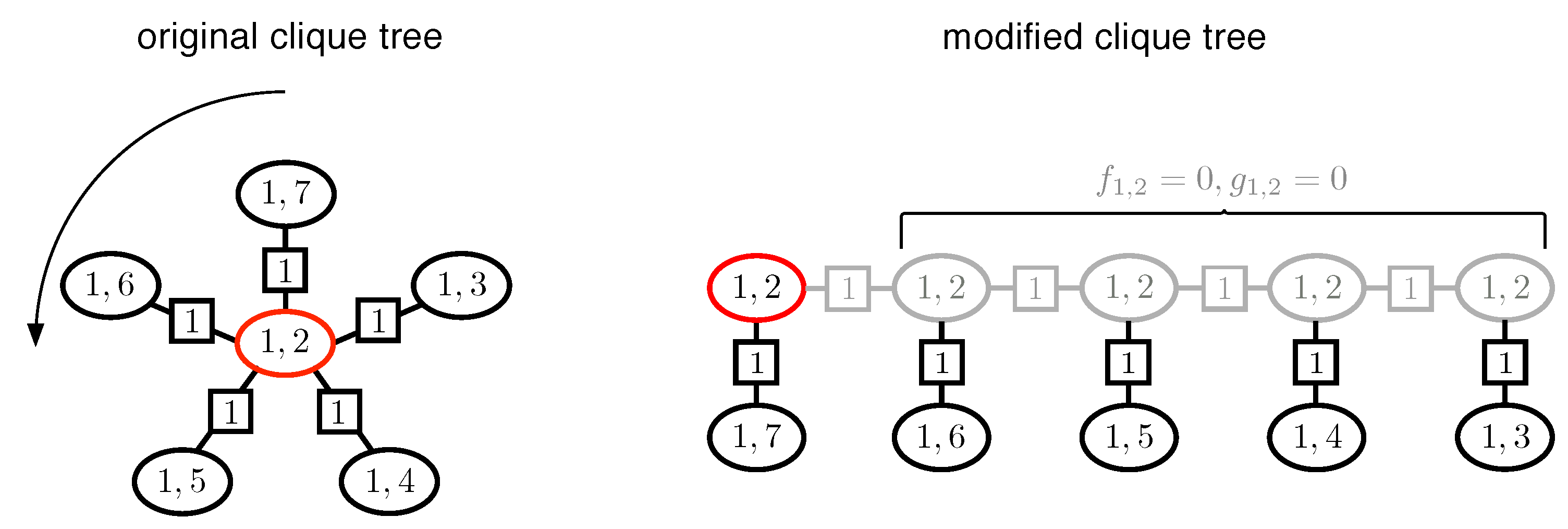
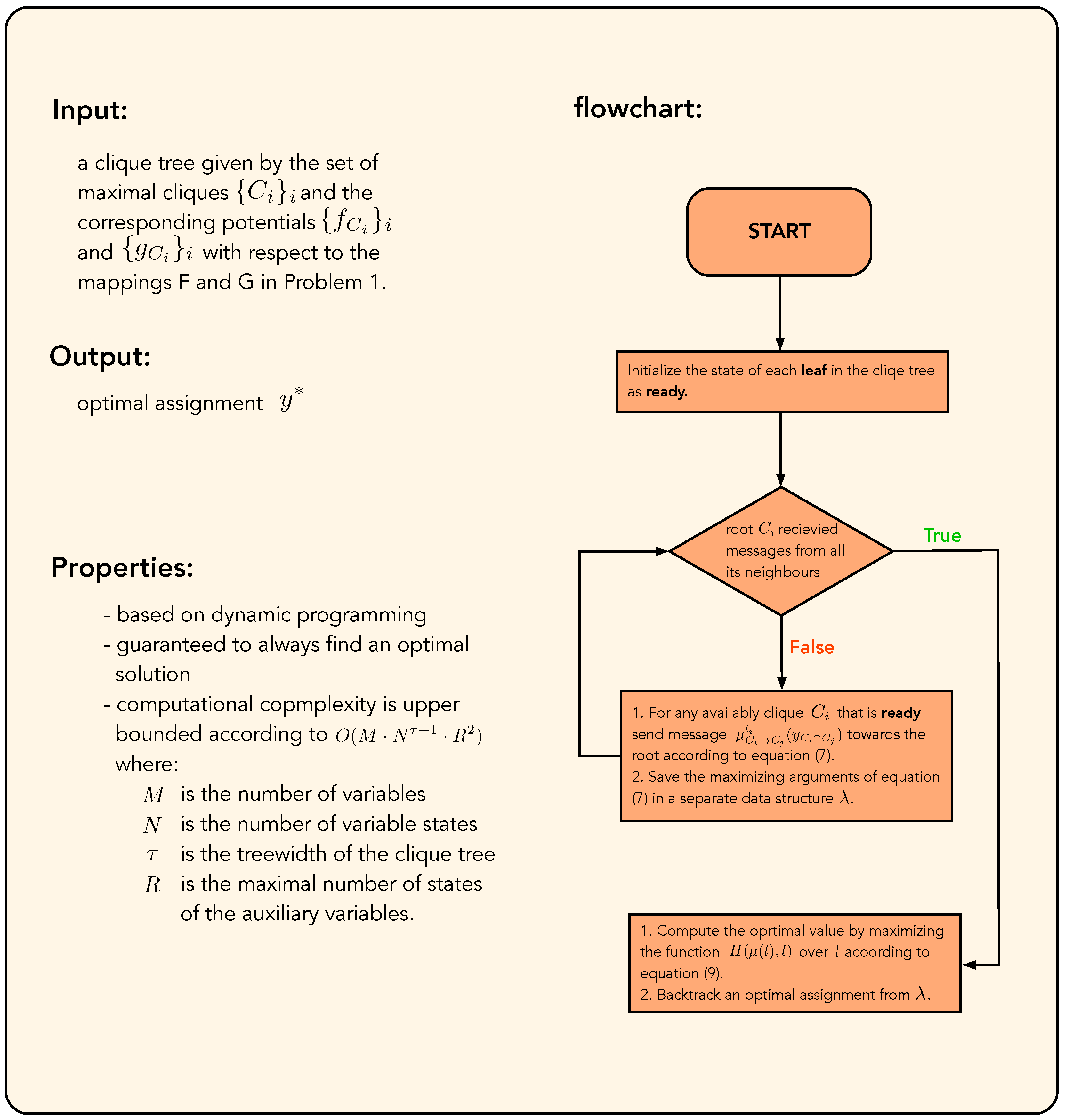
3.2. Constrained Message-Passing Algorithm on Clique Trees
| Algorithm 1 Constrained Message Passing on a Clique Tree |
|
4. Application Use Cases
- Learning with High-Order Loss FunctionsSSVM enables building complex and accurate models for structured prediction by directly integrating the desired performance measure into the training objective. However, its applicability relies on the availability of efficient inference algorithms. In the state-of-the-art training algorithms, such as cutting planes [64,65], bundle methods [67,68], subgradient methods [18], and Frank–Wolfe optimization [66], inference is repeatedly performed either to compute a subgradient or find the most violating configuration. In the literature, the corresponding computational task is generally referred to as the loss-augmented inference, which is the main computational bottleneck during training.
- Enabling Training of Slack Scaling Formulation for SSVMsThe maximum-margin framework of SSVMs includes two loss-sensitive formulations known as margin scaling and slack scaling. Since the original paper on SSVMs [39], there has been much speculation about the differences in training using either of these two formulations. In particular, training via slack scaling has been conjectured to be more accurate and beneficial than margin scaling. Nevertheless, it has rarely been used in practice due to the lack of known efficient inference algorithms.
- Evaluating Generalization Bounds for Structured PredictionThe purpose of generalization bounds is to provide useful theoretical insights into the behavior and stability of a learning algorithm by upper bounding the expected loss or the risk of a prediction function. Evaluating such a bound could provide certain guarantees on how a system trained on some finite data will perform in the future on unseen examples. Unlike in standard regression or classification tasks with univariate real-valued outputs, in structured prediction, evaluating generalization bounds requires solving a combinatorial optimization problem, thereby limiting its use in practice [48].
- Globally Constrained MAP InferenceIn many cases, evaluating a prediction function with structured outputs technically corresponds to performing MAP inference on a discrete graphical model, including Markov random fields (MRFs) [1], probabilistic context-free grammars (PCFGs) [72,73,74], hidden Markov models (HMMs) [75], conditional random fields (CRFs) [3], probabilistic relational models (PRMs) [76,77], and Markov logic networks (MLNs) [78]. In practice, we might want to modify the prediction function by imposing additional (global) constraints on its output. For example, we could perform a corresponding MAP inference subject to the constraints on the label counts specifying the size of the output or the distribution of the resulting labels, which is a common approach in applications such as sequence tagging and image segmentation. Alternatively, we might want to generate the best output with a score from a specific range that can provide deeper insights into the energy function of a corresponding model. Finally, we might want to restrict the set of possible outputs directly by excluding specific label configurations. The latter is closely related to the computational task known as (diverse) k-best MAP inference [62,63].
4.1. Loss-Augmented Inference with High-Order Loss Functions
4.2. Evaluating Generalization Bounds in Structured Prediction
4.3. Globally-Constrained MAP Inference
4.3.1. Constraints on Label Counts
4.3.2. Constraints on Objective Value
4.3.3. Constraints on Search Space
5. Compact Representation of Loss Functions

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
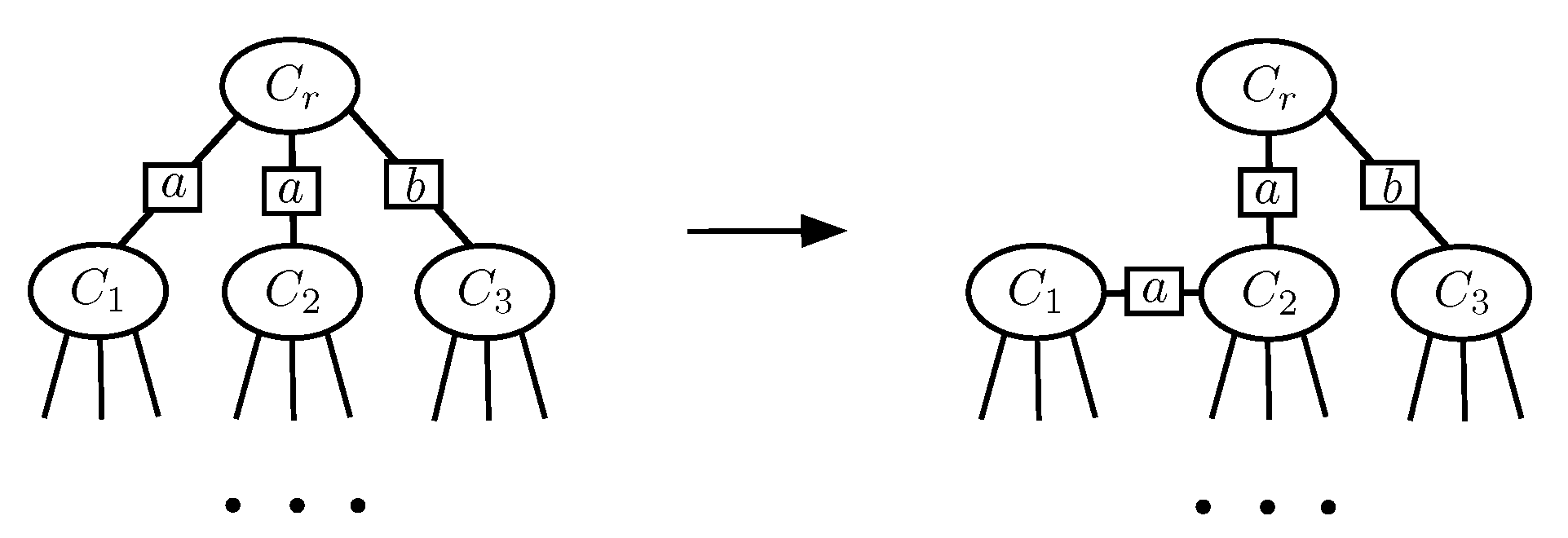{kind=link}
| Loss | R | ||
|---|---|---|---|
| G | M | ||
| M | |||
| G | M | ||
| M | |||
| M | |||
| G | M | ||
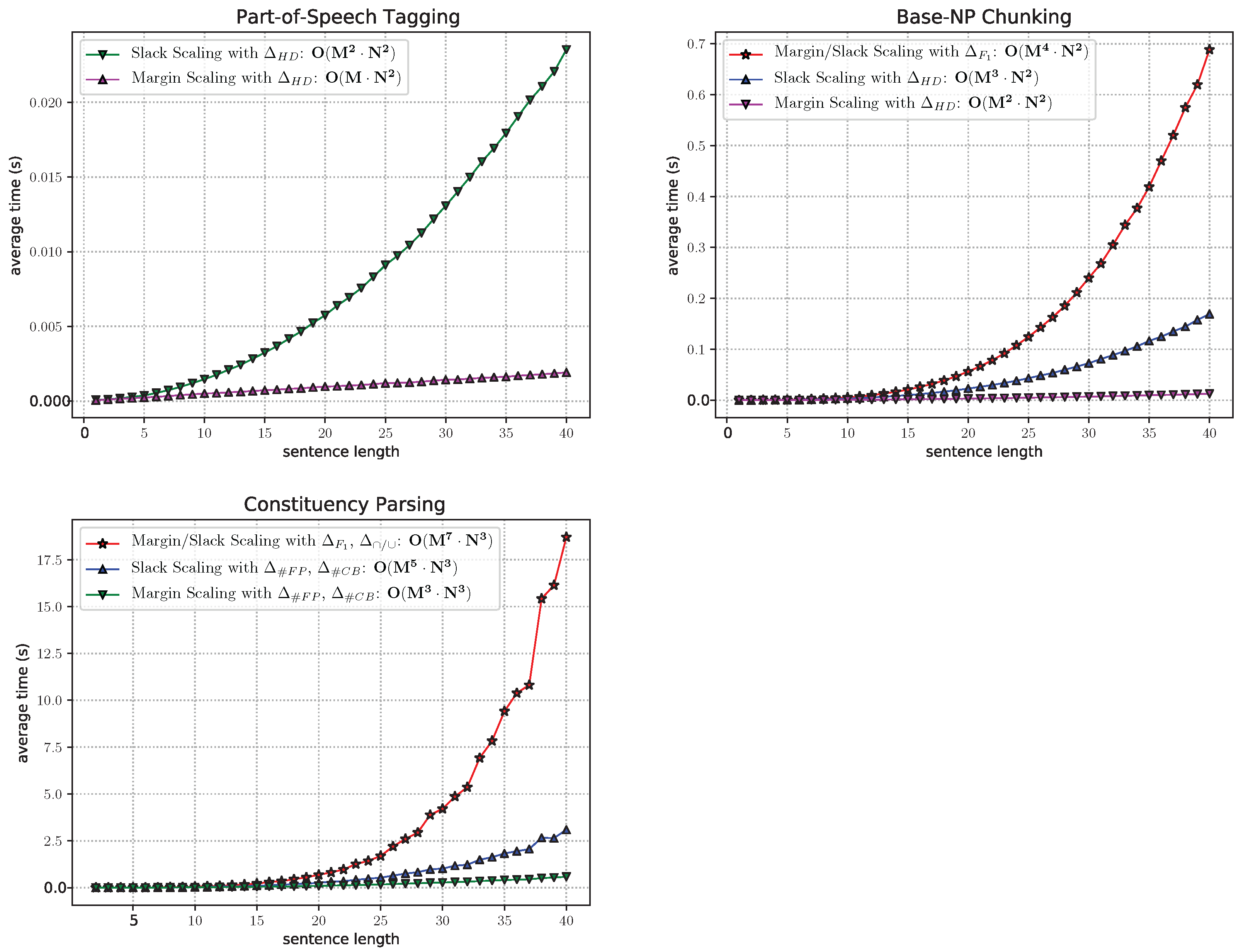
6. Validation of Theoretical Time Complexity
7. Summary of Contributions
- Abstract definition of the target problem (see Problem 1);
- Constrained message-passing algorithm on clique trees (see Algorithm 1);
- Formal statements to ensure theoretical properties such as correctness and efficiency (see Theorem 1, Proposition 2, Corollary 1, Theorem 2).
8. Related Works
9. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| LCS | Longest Common Subsequence |
| MAP | Maximum A Posteriori |
| MRF | Markov Random Field |
| SSVM | Structural Support Vector Machine |
Appendix A. Proof of Theorem 1
Appendix B. Flowchart Diagram of Algorithm 1

Appendix C. Proof of Proposition 2

Appendix D. Proof of Theorem 2
References
- Koller, D.; Friedman, N. Probabilistic Graphical Models: Principles and Techniques-Adaptive Computation and Machine Learning; The MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Wainwright, M.J.; Jordan, M.I. Graphical Models, Exponential Families, and Variational Inference. Found. Trends Mach. Learn. 2008, 1, 1–305. [Google Scholar] [CrossRef] [Green Version]
- Lafferty, J. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the ICML, Williamstown, MA, USA, 28 June– 1 July 2001; pp. 282–289. [Google Scholar]
- Kappes, J.H.; Andres, B.; Hamprecht, F.A.; Schnörr, C.; Nowozin, S.; Batra, D.; Kim, S.; Kausler, B.X.; Kröger, T.; Lellmann, J.; et al. A Comparative Study of Modern Inference Techniques for Structured Discrete Energy Minimization Problems. Int. J. Comput. Vis. 2015, 115, 155–184. [Google Scholar] [CrossRef] [Green Version]
- Bauer, A.; Nakajima, S.; Görnitz, N.; Müller, K.R. Partial Optimality of Dual Decomposition for MAP Inference in Pairwise MRFs. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics, Naha, Okinawa, 16–18 April 2019; Volume 89, pp. 1696–1703. [Google Scholar]
- Wainwright, M.J.; Jaakkola, T.S.; Willsky, A.S. MAP estimation via agreement on trees: Message-passing and linear programming. IEEE Trans. Inf. Theory 2005, 51, 3697–3717. [Google Scholar] [CrossRef]
- Kolmogorov, V. Convergent Tree-Reweighted Message Passing for Energy Minimization. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1568–1583. [Google Scholar] [CrossRef] [PubMed]
- Kolmogorov, V.; Wainwright, M.J. On the Optimality of Tree-reweighted Max-product Message-passing. In Proceedings of the 21st Conference in Uncertainty in Artificial Intelligence, Edinburgh, UK, 26–29 July 2005; pp. 316–323. [Google Scholar]
- Sontag, D.; Meltzer, T.; Globerson, A.; Jaakkola, T.S.; Weiss, Y. Tightening LP Relaxations for MAP using Message Passing. In Proceedings of the Twenty-Fourth Conference on Uncertainty in Artificial Intelligence, Helsinki, Finland, 9–12 July 2012. [Google Scholar]
- Sontag, D. Approximate Inference in Graphical Models Using LP Relaxations. Ph.D. Thesis, Department of Electrical Engineering and Computer Science, Massachusetts Institute of Technology, Cambridge, MA, USA, 2010. [Google Scholar]
- Sontag, D.; Globerson, A.; Jaakkola, T. Introduction to Dual Decomposition for Inference. In Optimization for Machine Learning; MIT Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Wang, J.; Yeung, S. A Compact Linear Programming Relaxation for Binary Sub-modular MRF. In Proceedings of the Energy Minimization Methods in Computer Vision and Pattern Recognition-10th International Conference, EMMCVPR 2015, Hong Kong, China, 13–16 January 2015; pp. 29–42. [Google Scholar]
- Iii, H.D.; Marcu, D. Learning as search optimization: Approximate large margin methods for structured prediction. In Proceedings of the ICML, Bonn, Germany, 7–11 August 2005; pp. 169–176. [Google Scholar]
- Sheng, L.; Binbin, Z.; Sixian, C.; Feng, L.; Ye, Z. Approximated Slack Scaling for Structural Support Vector Machines in Scene Depth Analysis. Math. Probl. Eng. 2013, 2013, 817496. [Google Scholar]
- Kulesza, A.; Pereira, F. Structured Learning with Approximate Inference. In Proceedings of the 20th NIPS, Vancouver, BC, Canada, 3–6 December 2007; pp. 785–792. [Google Scholar]
- Rush, A.M.; Collins, M.J. A Tutorial on Dual Decomposition and Lagrangian Relaxation for Inference in Natural Language Processing. J. Artif. Intell. Res. 2012, 45, 305–362. [Google Scholar] [CrossRef]
- Bodenstab, N.; Dunlop, A.; Hall, K.B.; Roark, B. Beam-Width Prediction for Efficient Context-Free Parsing. In Proceedings of the 49th ACL, Portland, OR, USA, 19–24 June 2011; pp. 440–449. [Google Scholar]
- Ratliff, N.D.; Bagnell, J.A.; Zinkevich, M. (Approximate) Subgradient Methods for Structured Prediction. In Proceedings of the 11th AISTATS, San Juan, Puerto Rico, 21–24 March 2007; pp. 380–387. [Google Scholar]
- Lim, Y.; Jung, K.; Kohli, P. Efficient Energy Minimization for Enforcing Label Statistics. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1893–1899. [Google Scholar] [CrossRef]
- Ranjbar, M.; Vahdat, A.; Mori, G. Complex loss optimization via dual decomposition. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2304–2311. [Google Scholar]
- Komodakis, N.; Paragios, N. Beyond pairwise energies: Efficient optimization for higher-order MRFs. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), Miami, FL, USA, 20–25 June 2009; pp. 2985–2992. [Google Scholar]
- Boykov, Y.; Veksler, O. Graph Cuts in Vision and Graphics: Theories and Applications. In Handbook of Mathematical Models in Computer Vision; 2006; pp. 79–96. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=279e0f5d885110c173bb86d37c997becf198651b (accessed on 16 May 2017).
- Kolmogorov, V.; Zabih, R. What Energy Functions Can Be Minimized via Graph Cuts? IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 147–159. [Google Scholar] [CrossRef] [Green Version]
- Hurley, B.; O’Sullivan, B.; Allouche, D.; Katsirelos, G.; Schiex, T.; Zytnicki, M.; de Givry, S. Multi-language evaluation of exact solvers in graphical model discrete optimization. Constraints 2016, 21, 413–434. [Google Scholar] [CrossRef]
- Haller, S.; Swoboda, P.; Savchynskyy, B. Exact MAP-Inference by Confining Combinatorial Search With LP Relaxation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, LA, USA, 2–7 February 2018; pp. 6581–6588. [Google Scholar]
- Savchynskyy, B.; Kappes, J.H.; Swoboda, P.; Schnörr, C. Global MAP-Optimality by Shrinking the Combinatorial Search Area with Convex Relaxation. In Proceedings of the Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 1950–1958. [Google Scholar]
- Kappes, J.H.; Speth, M.; Reinelt, G.; Schnörr, C. Towards Efficient and Exact MAP-Inference for Large Scale Discrete Computer Vision Problems via Combinatorial Optimization. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1752–1758. [Google Scholar]
- Forney, G.D. The Viterbi algorithm. Proc. IEEE 1973, 61, 268–278. [Google Scholar] [CrossRef]
- Tarlow, D.; Givoni, I.E.; Zemel, R.S. HOP-MAP: Efficient message passing with high order potentials. In Proceedings of the 13th AISTATS, Sardinia, Italy, 13–15 May 2010. [Google Scholar]
- McAuley, J.J.; Caetano, T.S. Faster Algorithms for Max-Product Message-Passing. J. Mach. Learn. Res. 2011, 12, 1349–1388. [Google Scholar]
- Younger, D.H. Recognition and Parsing of Context-Free Languages in Time n3. Inf. Control 1967, 10, 189–208. [Google Scholar] [CrossRef] [Green Version]
- Klein, D.; Manning, C.D. A* Parsing: Fast Exact Viterbi Parse Selection. In Proceedings of the HLT-NAACL, Edmonton, AB, Canada, 31 May 2003; pp. 119–126. [Google Scholar]
- Gupta, R.; Diwan, A.A.; Sarawagi, S. Efficient inference with cardinality-based clique potentials. In Proceedings of the Twenty-Fourth International Conference (ICML 2007), Corvallis, OR, USA, 20–24 June 2007; pp. 329–336. [Google Scholar]
- Kolmogorov, V.; Boykov, Y.; Rother, C. Applications of parametric maxflow in computer vision. In Proceedings of the IEEE 11th International Conference on Computer Vision, ICCV 2007, Rio de Janeiro, Brazil, 14–20 October 2007; pp. 1–8. [Google Scholar]
- McAuley, J.J.; Caetano, T.S. Exploiting Within-Clique Factorizations in Junction-Tree Algorithms. In Proceedings of the 13th AISTATS, Sardinia, Italy, 13–15 May 2010; pp. 525–532. [Google Scholar]
- Bodlaender, H. A Tourist Guide Through Treewidth. Acta Cybern. 1993, 11, 1–22. [Google Scholar]
- Chandrasekaran, V.; Srebro, N.; Harsha, P. Complexity of Inference in Graphical Models. In Proceedings of the 24th Conference in Uncertainty in Artificial Intelligence, Helsinki, Finland, 9–12 July 2008; pp. 70–78. [Google Scholar]
- Taskar, B.; Guestrin, C.; Koller, D. Max-Margin Markov Networks. In Proceedings of the 16th NIPS, Whistler, BC, Canada, 9–11 December 2003; pp. 25–32. [Google Scholar]
- Tsochantaridis, I.; Joachims, T.; Hofmann, T.; Altun, Y. Large Margin Methods for Structured and Interdependent Output Variables. J. Mach. Learn. Res. 2005, 6, 1453–1484. [Google Scholar]
- Joachims, T.; Hofmann, T.; Yue, Y.; Yu, C.N. Predicting Structured Objects with Support Vector Machines. Commun. ACM Res. Highlight 2009, 52, 97–104. [Google Scholar] [CrossRef] [Green Version]
- Sarawagi, S.; Gupta, R. Accurate max-margin training for structured output spaces. In Proceedings of the 25th ICML, Helsinki, Finland, 5–9 July 2008; pp. 888–895. [Google Scholar]
- Taskar, B.; Klein, D.; Collins, M.; Koller, D.; Manning, C.D. Max-Margin Parsing. In Proceedings of the EMNLP, Barcelona, Spain, 25–26 July 2004; pp. 1–8. [Google Scholar]
- Nam John Yu, C.; Joachims, T. Learning Structural SVMs with Latent Variables. In Proceedings of the ICML, Montreal, QC, Canada, 14–18 June 2009; pp. 1169–1176. [Google Scholar]
- Bakir, G.; Hoffman, T.; Schölkopf, B.; Smola, A.J.; Taskar, B.; Vishwanathan, S.V.N. Predicting Structured Data; The MIT Press: Cambridge, MA, USA, 2007. [Google Scholar]
- Bauer, A.; Görnitz, N.; Biegler, F.; Müller, K.R.; Kloft, M. Efficient Algorithms for Exact Inference in Sequence Labeling SVMs. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 870–881. [Google Scholar] [CrossRef]
- Bauer, A.; Braun, M.L.; Müller, K.R. Accurate Maximum-Margin Training for Parsing With Context-Free Grammars. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 44–56. [Google Scholar] [CrossRef]
- Bauer, A.; Nakajima, S.; Görnitz, N.; Müller, K.R. Optimizing for Measure of Performance in Max-Margin Parsing. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 2680–2684. [Google Scholar] [CrossRef]
- McAllester, D. Generalization bounds and consistency for structured labeling. In Proceedings of the Predicting Structured Data; Gökhan, B.H., Hofmanns, T., Schölkopf, B., Smola, A.J., Taskar, B., Vishwanathan, S.V.N., Eds.; The MIT Press: Cambridge, MA, USA, 2006; pp. 247–262. [Google Scholar]
- McAllester, D.A.; Keshet, J. Generalization Bounds and Consistency for Latent Structural Probit and Ramp Loss. In Proceedings of the 25th NIPS, Granada, Spain, 12–15 December 2011; pp. 2205–2212. [Google Scholar]
- London, B.; Huang, B.; Getoor, L. Stability and Generalization in Structured Prediction. J. Mach. Learn. Res. 2016, 17, 1–52. [Google Scholar]
- Ranjbar, M.; Mori, G.; Wang, Y. Optimizing Complex Loss Functions in Structured Prediction. In Proceedings of the 11th ECCV, Heraklion, Crete, Greece, 5–11 September 2010; pp. 580–593. [Google Scholar]
- Rätsch, G.; Sonnenburg, S. Large Scale Hidden Semi-Markov SVMs. In Proceedings of the 19 NIPS, Barcelona, Spain, 9 December 2007; pp. 1161–1168. [Google Scholar]
- Tarlow, D.; Zemel, R.S. Structured Output Learning with High Order Loss Functions. In Proceedings of the 15th AISTATS, La Palma, Canary Islands, Spain, 21–23 April 2012; pp. 1212–1220. [Google Scholar]
- Taskar, B.; Chatalbashev, V.; Koller, D.; Guestrin, C. Learning structured prediction models: A large margin approach. In Proceedings of the 22nd ICML, Bonn, Germany, 7–11 August 2005; pp. 896–903. [Google Scholar]
- Finley, T.; Joachims, T. Training Structural SVMs when Exact Inference is Intractable. In Proceedings of the 25th ICML, Helsinki, Finland, 5–9 July 2008; pp. 304–311. [Google Scholar]
- Meshi, O.; Sontag, D.; Jaakkola, T.S.; Globerson, A. Learning Efficiently with Approximate Inference via Dual Losses. In Proceedings of the 27th ICML, Haifa, Israel, 21–24 June 2010; pp. 783–790. [Google Scholar]
- Balamurugan, P.; Shevade, S.K.; Sundararajan, S. A Simple Label Switching Algorithm for Semisupervised Structural SVMs. Neural Comput. 2015, 27, 2183–2206. [Google Scholar] [CrossRef]
- Shevade, S.K.; Balamurugan, P.; Sundararajan, S.; Keerthi, S.S. A Sequential Dual Method for Structural SVMs. In Proceedings of the Eleventh SIAM International Conference on Data Mining, SDM 2011, Mesa, AZ, USA, 28–30 April 2011; pp. 223–234. [Google Scholar]
- Taskar, B.; Lacoste-Julien, S.; Jordan, M.I. Structured Prediction, Dual Extragradient and Bregman Projections. J. Mach. Learn. Res. 2006, 7, 1627–1653. [Google Scholar]
- Nowozin, S.; Gehler, P.V.; Jancsary, J.; Lampert, C.H. Advanced Structured Prediction; The MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Martins, A.F.T.; Figueiredo, M.A.T.; Aguiar, P.M.Q.; Smith, N.A.; Xing, E.P. An Augmented Lagrangian Approach to Constrained MAP Inference. In Proceedings of the 28th International Conference on Machine Learning, ICML 2011, Bellevue, WA, USA, 28 June–2 July 2011; Getoor, L., Scheffer, T., Eds.; Omnipress: Paraskevi, Greece, 2011; pp. 169–176. [Google Scholar]
- Batra, D.; Yadollahpour, P.; Guzmán-Rivera, A.; Shakhnarovich, G. Diverse M-Best Solutions in Markov Random Fields. In Proceedings of the Computer Vision-ECCV 2012-12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Part V. pp. 1–16. [Google Scholar]
- Guzmán-Rivera, A.; Kohli, P.; Batra, D. DivMCuts: Faster Training of Structural SVMs with Diverse M-Best Cutting-Planes. In Proceedings of the Sixteenth International Conference on Artificial Intelligence and Statistics, AISTATS 2013, Scottsdale, AZ, USA, 29 April–1 May 2013; pp. 316–324. [Google Scholar]
- Joachims, T.; Finley, T.; Yu, C.N. Cutting-Plane Training of Structural SVMs. Mach. Learn. 2009, 77, 27–59. [Google Scholar] [CrossRef] [Green Version]
- Kelley, J.E. The Cutting-Plane Method for Solving Convex Programs. J. Soc. Ind. Appl. Math. 1960, 8, 703–712. [Google Scholar] [CrossRef]
- Lacoste-Julien, S.; Jaggi, M.; Schmidt, M.W.; Pletscher, P. Block-Coordinate Frank-Wolfe Optimization for Structural SVMs. In Proceedings of the 30th ICML, Atlanta, GA, USA, 16–21 June 2013; pp. 53–61. [Google Scholar]
- Teo, C.H.; Vishwanathan, S.V.N.; Smola, A.J.; Le, Q.V. Bundle Methods for Regularized Risk Minimization. J. Mach. Learn. Res. 2010, 11, 311–365. [Google Scholar]
- Smola, A.J.; Vishwanathan, S.V.N.; Le, Q.V. Bundle Methods for Machine Learning. In Proceedings of the 21st NIPS, Vancouver, BC, Canada, 7–8 December 2007; pp. 1377–1384. [Google Scholar]
- Bauer, A.; Nakajima, S.; Müller, K.R. Efficient Exact Inference with Loss Augmented Objective in Structured Learning. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2566–2579. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer, Inc.: Secaucus, NJ, USA, 2006. [Google Scholar]
- Lauritzen, S.L.; Spiegelhalter, D.J. Chapter Local Computations with Probabilities on Graphical Structures and Their Application to Expert Systems. In Readings in Uncertain Reasoning; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1990; pp. 415–448. [Google Scholar]
- Johnson, M. PCFG Models of Linguistic Tree Representations. Comput. Linguist. 1998, 24, 613–632. [Google Scholar]
- Heemskerk, J.S. A Probabilistic Context-free Grammar for Disambiguation in Morphological Parsing. In Proceedings of the EACL, Utrecht, The Netherlands, 19–23 April 1993; pp. 183–192. [Google Scholar]
- Charniak, E. Statistical Parsing with a Context-Free Grammar and Word Statistics. In Proceedings of the 40th National Conference on Artificial Intelligence and 9th Innovative Applications of Artificial Intelligence, Providence, RI, USA, 27–31 July 1997; pp. 598–603. [Google Scholar]
- Rabiner, L.R. A tutorial on hidden markov models and selected applications in speech recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar] [CrossRef] [Green Version]
- Koller, D. Probabilistic Relational Models. In Proceedings of the Inductive Logic Programming, 9th International Workshop, ILP-99, Bled, Slovenia, 24–27 June 1999; pp. 3–13. [Google Scholar]
- Taskar, B.; Abbeel, P.; Koller, D. Discriminative Probabilistic Models for Relational Data. In Proceedings of the Eighteenth Conference on Uncertainty in Artificial Intelligence, Edmonton, AB, Canada, 11–15 July 2013. [Google Scholar]
- Richardson, M.; Domingos, P.M. Markov logic networks. Mach. Learn. 2006, 62, 107–136. [Google Scholar] [CrossRef] [Green Version]
- Komodakis, N.; Paragios, N.; Tziritas, G. MRF Energy Minimization and Beyond via Dual Decomposition. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 531–552. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Eslami, S.M.A.; Gool, L.J.V.; Williams, C.K.I.; Winn, J.M.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- He, T.; Chen, J.; Ma, L.; Gui, Z.; Li, F.; Shao, W.; Wang, Q. ROUGE-C: A Fully Automated Evaluation Method for Multi-document Summarization. In Proceedings of the 2008 IEEE International Conference on Granular Computing, GrC 2008, Hangzhou, China, 26–28 August 2008; pp. 269–274. [Google Scholar]
- Manning, C.D. Part-of-Speech Tagging from 97% to 100%: Is It Time for Some Linguistics? In Computational Linguistics and Intelligent Text Processing, Proceedings of the 12th International Conference, CICLing 2011, Tokyo, Japan, 20–26 February 2011; Proceedings, Part I; Lecture Notes in Computer Science; Gelbukh, A.F., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6608, pp. 171–189. [Google Scholar]
- Tongchim, S.; Sornlertlamvanich, V.; Isahara, H. Experiments in Base-NP Chunking and Its Role in Dependency Parsing for Thai. In Proceedings of the 22nd COLING, Manchester, UK, 18–22 August 2008; pp. 123–126. [Google Scholar]
- Marcus, M.P.; Kim, G.; Marcinkiewicz, M.A.; MacIntyre, R.; Bies, A.; Ferguson, M.; Katz, K.; Schasberger, B. The Penn Treebank: Annotating Predicate Argument Structure. In Proceedings of the Human Language Technology, Plainsboro, NJ, USA, 8–11 March 1994. [Google Scholar]
- Joachims, T. A Support Vector Method for Multivariate Performance Measures. In Proceedings of the 22nd ICML, Bonn, Germany, 7–11 August 2005; pp. 377–384. [Google Scholar]
- Tarlow, D.; Swersky, K.; Zemel, R.S.; Adams, R.P.; Frey, B.J. Fast Exact Inference for Recursive Cardinality Models. In Proceedings of the 28th UAI, Catalina Island, CA, USA, 14–18 August 2012. [Google Scholar]
- Mezuman, E.; Tarlow, D.; Globerson, A.; Weiss, Y. Tighter Linear Program Relaxations for High Order Graphical Models. In Proceedings of the 29th Conference on Uncertainty in Artificial Intelligence (UAI), Bellevue, WA, USA, 11–15 July 2013. [Google Scholar]
- Kohlbrenner, M.; Bauer, A.; Nakajima, S.; Binder, A.; Samek, W.; Lapuschkin, S. Towards Best Practice in Explaining Neural Network Decisions with LRP. In Proceedings of the 2020 International Joint Conference on Neural Networks, IJCNN 2020, Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Schnake, T.; Eberle, O.; Lederer, J.; Nakajima, S.; Schütt, K.T.; Müller, K.; Montavon, G. Higher-Order Explanations of Graph Neural Networks via Relevant Walks. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 7581–7596. [Google Scholar] [CrossRef]
- Xiong, P.; Schnake, T.; Montavon, G.; Müller, K.R.; Nakajima, S. Efficient Computation of Higher-Order Subgraph Attribution via Message Passing. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; Volume 162, pp. 24478–24495. [Google Scholar]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bauer, A.; Nakajima, S.; Müller, K.-R. Polynomial-Time Constrained Message Passing for Exact MAP Inference on Discrete Models with Global Dependencies. Mathematics 2023, 11, 2628. https://doi.org/10.3390/math11122628
Bauer A, Nakajima S, Müller K-R. Polynomial-Time Constrained Message Passing for Exact MAP Inference on Discrete Models with Global Dependencies. Mathematics. 2023; 11(12):2628. https://doi.org/10.3390/math11122628
Chicago/Turabian StyleBauer, Alexander, Shinichi Nakajima, and Klaus-Robert Müller. 2023. "Polynomial-Time Constrained Message Passing for Exact MAP Inference on Discrete Models with Global Dependencies" Mathematics 11, no. 12: 2628. https://doi.org/10.3390/math11122628
APA StyleBauer, A., Nakajima, S., & Müller, K. -R. (2023). Polynomial-Time Constrained Message Passing for Exact MAP Inference on Discrete Models with Global Dependencies. Mathematics, 11(12), 2628. https://doi.org/10.3390/math11122628