Probability-Distribution-Guided Adversarial Sample Attacks for Boosting Transferability and Interpretability

Abstract
:1. Introduction
- We found that the probability-distribution-guided adversarial sample generation method could easily break through the decision boundary of different structural classifiers and achieve higher transferability when compared to traditional methods based on the decision boundary guidance of classifiers.
- We proved that classification models can be transformed into energy-based models so that we could estimate the probability density of samples in classification models.
- We proposed the SMBA method to allow classifiers to learn the probability distribution of the samples by aligning the gradient of the classifiers with the samples, which could guide the adversarial sample generation directionally and improve the transferability and interpretability in the face of different structural models.
2. Related Works
2.1. Adversarial Sample Attack Methods
2.2. Probability Density Estimation Methods
2.3. Score Matching Methods
3. Methodology
3.1. Estimation of the Logarithmic Gradient of the True Conditional Probability Density
3.2. Transformation of Classification Model to EBM
3.3. Generation of Adversarial Samples on Gradient-Aligned and High-Precision Classifier
3.4. Pseudo-Code of SMBA Method
| Algorithm 1: SMBA: Given classifier network parameterized by , constraint coefficient , epochs T, total batches M, learning rate , original image x, ground-truth label , target label , adversarial perturbation maximum perturbation radius , step size , iterations N, randomly sliced vector v, and score function , denotes the single output of the logits layer of the classifier corresponding to input x and label y. |
 |
4. Experiments and Results
4.1. Experimental Settings
4.2. Metrics Comparison
4.2.1. Attack Target Model Experiments
4.2.2. Experiments on the CIFAR-100 Dataset
4.3. Visualization and Interpretability
4.3.1. Generating Adversarial Samples
4.3.2. Corresponding Feature Space
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Akhtar, N.; Mian, A. Threat of adversarial attacks on deep learning in computer vision: A survey. IEEE Access 2018, 6, 14410–14430. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Duan, R.; Ma, X.; Wang, Y.; Bailey, J.; Qin, A.K.; Yang, Y. Adversarial camouflage: Hiding physical-world attacks with natural styles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1000–1008. [Google Scholar]
- Zhang, Y.; Gong, Z.; Zhang, Y.; Bin, K.; Li, Y.; Qi, J.; Wen, H.; Zhong, P. Boosting transferability of physical attack against detectors by redistributing separable attention. Pattern Recognit. 2023, 138, 109435. [Google Scholar] [CrossRef]
- Welling, M.; Teh, Y.W. Bayesian learning via stochastic gradient Langevin dynamics. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Washington, DC, USA, 28 June–2 July 2011; pp. 681–688. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Artificial Intelligence Safety and Security; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018; pp. 99–112. [Google Scholar]
- Dong, Y.; Liao, F.; Pang, T.; Su, H.; Zhu, J.; Hu, X.; Li, J. Boosting adversarial attacks with momentum. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9185–9193. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Xie, C.; Zhang, Z.; Zhou, Y.; Bai, S.; Wang, J.; Ren, Z.; Yuille, A.L. Improving transferability of adversarial examples with input diversity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2730–2739. [Google Scholar]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Saarbrucken, Germany, 21–24 March 2016; pp. 372–387. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 2013, arXiv:1312.6034. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar]
- Su, J.; Vargas, D.V.; Sakurai, K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef] [Green Version]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical black-box attacks against machine learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 506–519. [Google Scholar]
- Pengcheng, L.; Yi, J.; Zhang, L. Query-efficient black-box attack by active learning. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 1200–1205. [Google Scholar]
- Wu, W.; Su, Y.; Chen, X.; Zhao, S.; King, I.; Lyu, M.R.; Tai, Y.W. Boosting the transferability of adversarial samples via attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1161–1170. [Google Scholar]
- Li, Y.; Bai, S.; Zhou, Y.; Xie, C.; Zhang, Z.; Yuille, A. Learning transferable adversarial examples via ghost networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11458–11465. [Google Scholar]
- Hu, Z.; Li, H.; Yuan, L.; Cheng, Z.; Yuan, W.; Zhu, M. Model scheduling and sample selection for ensemble adversarial example attacks. Pattern Recognit. 2022, 130, 108824. [Google Scholar] [CrossRef]
- Dong, Y.; Su, H.; Wu, B.; Li, Z.; Liu, W.; Zhang, T.; Zhu, J. Efficient decision-based black-box adversarial attacks on face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7714–7722. [Google Scholar]
- Hansen, N.; Ostermeier, A. Completely derandomized self-adaptation in evolution strategies. Evol. Comput. 2001, 9, 159–195. [Google Scholar] [CrossRef]
- Brunner, T.; Diehl, F.; Le, M.T.; Knoll, A. Guessing smart: Biased sampling for efficient black-box adversarial attacks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4958–4966. [Google Scholar]
- Shi, Y.; Han, Y.; Tian, Q. Polishing decision-based adversarial noise with a customized sampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1030–1038. [Google Scholar]
- Rahmati, A.; Moosavi-Dezfooli, S.M.; Frossard, P.; Dai, H. Geoda: A geometric framework for black-box adversarial attacks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8446–8455. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Xiao, C.; Li, B.; Zhu, J.Y.; He, W.; Liu, M.; Song, D. Generating adversarial examples with adversarial networks. arXiv 2018, arXiv:1801.02610. [Google Scholar]
- Jandial, S.; Mangla, P.; Varshney, S.; Balasubramanian, V. Advgan++: Harnessing latent layers for adversary generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1765–1773. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Vadillo, J.; Santana, R.; Lozano, J.A. Extending adversarial attacks to produce adversarial class probability distributions. arXiv 2023, arXiv:2004.06383. [Google Scholar]
- Joyce, J.M. Kullback-leibler divergence. In International Encyclopedia of Statistical Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 720–722. [Google Scholar]
- Wang, X.; Zhai, C.; Roth, D. Understanding evolution of research themes: A probabilistic generative model for citations. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 1115–1123. [Google Scholar]
- Alain, G.; Bengio, Y.; Yao, L.; Yosinski, J.; Thibodeau-Laufer, E.; Zhang, S.; Vincent, P. GSNs: Generative stochastic networks. Inf. Inference J. IMA 2016, 5, 210–249. [Google Scholar] [CrossRef] [Green Version]
- Taketo, M.; Schroeder, A.C.; Mobraaten, L.E.; Gunning, K.B.; Hanten, G.; Fox, R.R.; Roderick, T.H.; Stewart, C.L.; Lilly, F.; Hansen, C.T. FVB/N: An inbred mouse strain preferable for transgenic analyses. Proc. Natl. Acad. Sci. USA 1991, 88, 2065–2069. [Google Scholar] [CrossRef] [PubMed]
- Germain, M.; Gregor, K.; Murray, I.; Larochelle, H. Made: Masked autoencoder for distribution estimation. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 881–889. [Google Scholar]
- Van den Oord, A.; Kalchbrenner, N.; Espeholt, L.; Vinyals, O.; Graves, A.; Kavukcuoglu, K. Conditional image generation with pixelcnn decoders. Adv. Neural Inf. Process. Syst. 2016, 29, 1–13. [Google Scholar]
- An, J.; Cho, S. Variational autoencoder based anomaly detection using reconstruction probability. Spec. Lect. IE 2015, 2, 1–18. [Google Scholar]
- Llorente, F.; Curbelo, E.; Martino, L.; Elvira, V.; Delgado, D. MCMC-driven importance samplers. Appl. Math. Model. 2022, 111, 310–331. [Google Scholar] [CrossRef]
- Du, Y.; Mordatch, I. Implicit generation and modeling with energy based models. Adv. Neural Inf. Process. Syst. 2019, 32, 1–11. [Google Scholar]
- Hinton, G.E. A practical guide to training restricted Boltzmann machines. In Neural Networks: Tricks of the Trade: Second Edition; Springer: Berlin/Heidelberg, Germany, 2012; pp. 599–619. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Hyvärinen, A.; Dayan, P. Estimation of non-normalized statistical models by score matching. J. Mach. Learn. Res. 2005, 6, 695–709. [Google Scholar]
- Song, Y.; Garg, S.; Shi, J.; Ermon, S. Sliced score matching: A scalable approach to density and score estimation. In Proceedings of the Uncertainty in Artificial Intelligence, Virtual, 3–6 August 2020; pp. 574–584. [Google Scholar]
- Grathwohl, W.; Wang, K.C.; Jacobsen, J.H.; Duvenaud, D.; Norouzi, M.; Swersky, K. Your classifier is secretly an energy based model and you should treat it like one. arXiv 2019, arXiv:1912.03263. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Wu, D.; Wang, Y.; Xia, S.T.; Bailey, J.; Ma, X. Skip connections matter: On the transferability of adversarial examples generated with resnets. arXiv 2020, arXiv:2002.05990. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Salman, H.; Ilyas, A.; Engstrom, L.; Kapoor, A.; Madry, A. Do adversarially robust imagenet models transfer better? Adv. Neural Inf. Process. Syst. 2020, 33, 3533–3545. [Google Scholar]
- Geirhos, R.; Rubisch, P.; Michaelis, C.; Bethge, M.; Wichmann, F.A.; Brendel, W. ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. arXiv 2018, arXiv:1811.12231. [Google Scholar]
- Hendrycks, D.; Mu, N.; Cubuk, E.D.; Zoph, B.; Gilmer, J.; Lakshminarayanan, B. Augmix: A simple method to improve robustness and uncertainty under data shift. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020; Volume 1, p. 6. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Shlens, J. A tutorial on principal component analysis. arXiv 2014, arXiv:1404.1100. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
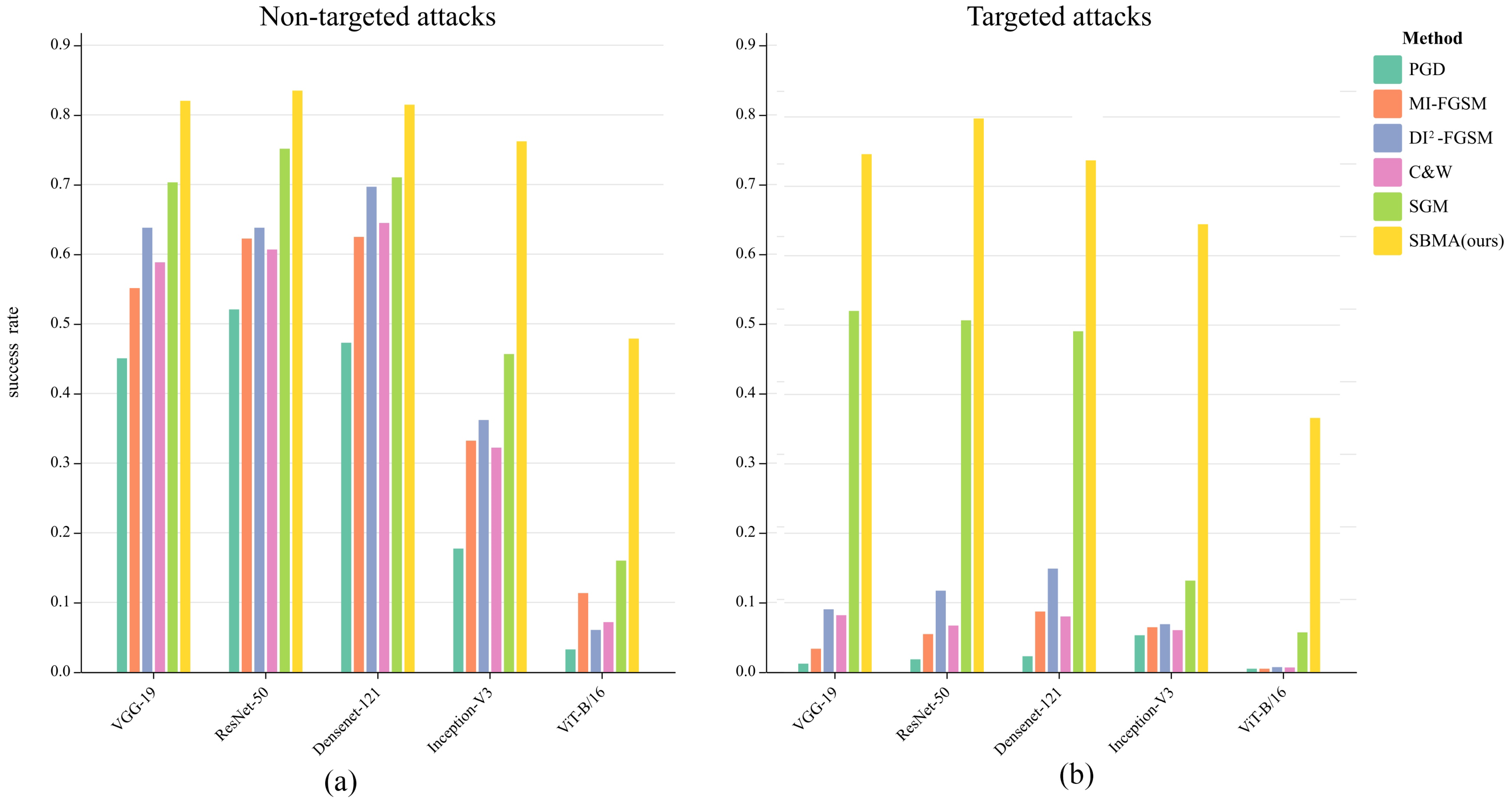
| Surrogate Model | Attack Method | VGG-19 | ResNet-50 | DenseNet-121 | Inception-V3 | ViT-B/16 |
|---|---|---|---|---|---|---|
| ResNet-18 | PGD [9] | 45.05% | 52.07% | 47.28% | 17.73% | 3.25% |
| MI-FGSM [8] | 55.13% | 62.24% | 62.48% | 33.22% | 11.34% | |
| -FGSM [10] | 63.80% | 63.80% | 69.68% | 36.19% | 6.05% | |
| C&W [13] | 58.83% | 60.67% | 64.48% | 32.22% | 7.17% | |
| SGM [50] | 70.31% | 75.14% | 71.03% | 45.66% | 16.00% | |
| SBMA (ours) | 82.02% | 83.48% | 81.46% | 76.20% | 47.88% |
| Surrogate Model | Attack Method | VGG-19 | ResNet-50 | DenseNet-121 | Inception-V3 | ViT-B/16 |
|---|---|---|---|---|---|---|
| ResNet-18 | PGD [9] | 1.21% | 1.84% | 2.28% | 5.30% | 0.48% |
| MI-FGSM [8] | 3.36% | 5.47% | 8.72% | 6.46% | 0.48% | |
| -FGSM [10] | 9.04% | 11.73% | 14.91% | 6.90% | 0.71% | |
| C&W [13] | 8.19% | 6.70% | 8.01% | 6.04% | 0.66% | |
| SGM [50] | 52.04% | 50.69% | 49.11% | 13.18% | 5.72% | |
| SBMA (ours) | 74.63% | 79.77% | 73.10% | 64.54% | 36.62% |
| Surrogate Model | Attack Method | Normal | Adversarial Training | SIN | Augmix |
|---|---|---|---|---|---|
| ResNet-18 | PGD [9] | 2.28% | 0.59% | 1.26% | 1.21% |
| MI-FGSM [8] | 8.72% | 1.83% | 4.71% | 4.54% | |
| -FGSM [10] | 14.91% | 3.60% | 8.40% | 8.10% | |
| C&W [13] | 8.01% | 1.64% | 4.23% | 4.08% | |
| SGM [50] | 49.11% | 9.22% | 28.53% | 27.50% | |
| SBMA (ours) | 73.10% | 15.13% | 60.27% | 54.62% |
| Surrogate Model | Attack Method | VGG-19 | ResNet-50 | DenseNet-121 | Inception-V3 | ViT-B/16 |
|---|---|---|---|---|---|---|
| ResNet-18 | PGD [9] | 0.98% | 1.56% | 1.93% | 4.49% | 0.37% |
| MI-FGSM [8] | 2.84% | 4.52% | 7.39% | 5.95% | 0.40% | |
| -FGSM [10] | 7.66% | 9.94% | 11.43% | 5.85% | 0.48% | |
| C&W [13] | 6.93% | 5.67% | 6.78% | 5.12% | 0.56% | |
| SGM [50] | 44.08% | 40.80% | 41.60% | 11.16% | 3.65% | |
| SBMA (ours) | 52.68% | 51.31% | 49.38% | 41.56% | 20.85% |
| Number of Samples with 3 × 224 × 224 | Size of Samples with 1300p | ||
|---|---|---|---|
| 1300p | 73.10% | 3 × 224 × 224 | 73.10% |
| 650p | 62.69% | 3 × 112 × 112 | 67.52% |
| 300p | 45.16% | 3 × 64 × 64 | 58.35% |
| 100p | 21.08% | 3 × 32 × 32 | 40.44% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Yu, M.; Li, X.; Zhang, J.; Li, S.; Lei, J.; Huang, H. Probability-Distribution-Guided Adversarial Sample Attacks for Boosting Transferability and Interpretability. Mathematics 2023, 11, 3015. https://doi.org/10.3390/math11133015
Li H, Yu M, Li X, Zhang J, Li S, Lei J, Huang H. Probability-Distribution-Guided Adversarial Sample Attacks for Boosting Transferability and Interpretability. Mathematics. 2023; 11(13):3015. https://doi.org/10.3390/math11133015
Chicago/Turabian StyleLi, Hongying, Miaomiao Yu, Xiaofei Li, Jun Zhang, Shuohao Li, Jun Lei, and Hairong Huang. 2023. "Probability-Distribution-Guided Adversarial Sample Attacks for Boosting Transferability and Interpretability" Mathematics 11, no. 13: 3015. https://doi.org/10.3390/math11133015
APA StyleLi, H., Yu, M., Li, X., Zhang, J., Li, S., Lei, J., & Huang, H. (2023). Probability-Distribution-Guided Adversarial Sample Attacks for Boosting Transferability and Interpretability. Mathematics, 11(13), 3015. https://doi.org/10.3390/math11133015