


Breast Cancer Diagnosis Using a Novel Parallel Support Vector Machine with Harris Hawks Optimization


Abstract
:1. Introduction
2. Preliminaries
2.1. Support Vector Machine (SVM)
2.2. Harris Hawks Optimization (HHO)
2.2.1. Exploration Phase
2.2.2. Transition from Exploration to Exploitation
2.2.3. Exploitation Phase
Soft Siege (r ≥ 0.5 and |E| ≥ 0.5)
Hard Siege (r ≥ 0.5 and |E| < 0.5)
Soft Siege with Progressive Rapid Dives (|E| ≥ 0.5 and r < 0.5)
Hard Siege with Progressive Rapid Dives (|E| < 0.5 and r < 0.5)
3. The Proposed HHO-SVM Classification Model
| Algorithm 1: HHO-SVM Algorithm |
| Input: Output: :
Pass to particular functions Set function’s output to parameter of SVM () Train and test the SVM model Evaluate the fitness with EQ (21) Update Xrabbit as the position of the rabbit (best position based on the fitness value) end (for) for (every hawk (Xi)) do Update E0 and J (initial energy and jump strength) Update the E by EQ (8) if () then ▷ Exploration phase Update the position vector by EQ (6) if () then ▷ Exploration phase if (and ) then ▷ Soft siege Update the position vector by EQ (10) else if ( and ) then ▷ Hard siege Update the position vector by EQ (12) else if ( and ) then ▷ Soft siege with PRD Update the position vector by EQ (16) ▷ calculated by using RMSE else if ( and ) then ▷ Hard siege with PRD Update the position vector by EQ (17) end (for) t=t+1 end (while) t=0 end (for)
|
4. Scaling Techniques
- (1)
- Arithmetic mean:
- (2)
- Equilibration scaling technique:
- (3)
- Geometric mean:
- (4)
- Normalization [−1, 1]:
5. The Parallel Metaheuristic Algorithm
| Algorithm 2: Parallel Approach |
| 1: Begin
2: Identify (no. of cores); 3: Randomly initialize the population; 4: Compute particles with Equation (20); 5: Make sets; 6: Distribute the particles on cores. 7: Run the HHO-SVM model on each core 8: Choose the optimal particles from all cores; 9: Update the model’s parameters and particle positions; 10: For all folds, return the average accuracy. 11: End |
6. Experimental Design
6.1. Data Description
6.2. Experimental Setup
6.3. Performance Metrics
6.4. Comparative Study
7. Empirical Results and Discussion
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global Cancer Statistics 2020: GLOBOCAN Estimates of Incidence and Mortality Worldwide for 36 Cancers in 185 Countries. CA Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef] [PubMed]
- Marcano-Cedeño, A.; Quintanilla-Domínguez, J.; Andina, D. WBCD breast cancer database classification applying artificial metaplasticity neural network. Expert Syst. Appl. 2011, 38, 9573–9579. [Google Scholar] [CrossRef]
- Chen, H.-L.; Yang, B.; Liu, J.; Liu, D.-Y. A support vector machine classifier with rough set-based feature selection for breast cancer diagnosis. Expert Syst. Appl. 2011, 38, 9014–9022. [Google Scholar] [CrossRef]
- Chen, H.L.; Yang, B.; Wang, G.; Wang, S.J.; Liu, J.; Liu, D.Y. Support vector machine based diagnostic system for breast cancer using swarm intelligence. J. Med. Syst. 2012, 36, 2505–2519. [Google Scholar] [CrossRef] [PubMed]
- Bashir, S.; Qamar, U.; Khan, F.H. Heterogeneous classifiers fusion for dynamic breast cancer diagnosis using weighted vote based ensemble. Qual. Quant. 2015, 49, 2061–2076. [Google Scholar] [CrossRef]
- Tuba, E.; Tuba, M.; Simian, D. Adjusted bat algorithm for tuning of support vector machine parameters. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation (CEC), Vancouver, BC, Canada, 24–29 July 2016; pp. 2225–2232. [Google Scholar] [CrossRef]
- Aalaei, S.; Shahraki, H.; Rowhanimanesh, A.; Eslami, S. Feature selection using genetic algorithm for breast cancer diagnosis: Experiment on three different datasets. Iran. J. Basic. Med. Sci. 2016, 19, 476–482. [Google Scholar]
- Mandal, S.K. Performance Analysis of Data Mining Algorithms for Breast Cancer Cell Detection Using Naïve Bayes, Logistic Regression and Decision Tree. Int. J. Eng. Comput. Sci. 2017, 6, 20388–20391. [Google Scholar]
- Muslim, M.A.; Rukmana, S.H.; Sugiharti, E.; Prasetiyo, B.; Alimah, S. Optimization of C4.5 algorithm-based particle swarm optimization for breast cancer diagnosis. J. Phys. Conf. Ser. 2018, 983, 012063. [Google Scholar] [CrossRef]
- Liu, N.; Shen, J.; Xu, M.; Gan, D.; Qi, E.-S.; Gao, B. Improved Cost-Sensitive Support Vector Machine Classifier for Breast Cancer Diagnosis. Math. Probl. Eng. 2018, 2018, 3875082. [Google Scholar] [CrossRef]
- Agarap, A.F.M. On breast cancer detection: An application of machine learning algorithms on the wisconsin diagnostic dataset. In Proceedings of the 2nd International Conference on Machine Learning and Soft Computing, Phuoc Island, Vietnam, 2–4 February 2018; pp. 5–9. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Feng, X.; Zhou, S.; Jiang, J.; Chen, H.; Li, Y.; Li, C. A new fruit fly optimization algorithm enhanced support vector machine for diagnosis of breast cancer based on high-level features. BMC Bioinform. 2019, 20, 290. [Google Scholar] [CrossRef] [Green Version]
- Xie, T.; Yao, J.; Zhou, Z. DA-Based Parameter Optimization of Combined Kernel Support Vector Machine for Cancer Diagnosis. Processes 2019, 7, 263. [Google Scholar] [CrossRef] [Green Version]
- Rajaguru, H.; SR, C.S. Analysis of Decision Tree and K-Nearest Neighbor Algorithm in the Classification of Breast Cancer. Asian Pac. J. Cancer Prev. 2019, 20, 3777–3781. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dhahri, H.; Al Maghayreh, E.; Mahmood, A.; Elkilani, W.; Nagi, M.F. Automated Breast Cancer Diagnosis Based on Machine Learning Algorithms. J. Health Eng. 2019, 2019, 4253641. [Google Scholar] [CrossRef] [PubMed]
- Hemeida, A.; Alkhalaf, S.; Mady, A.; Mahmoud, E.; Hussein, M.; Eldin, A.M.B. Implementation of nature-inspired optimization algorithms in some data mining tasks. Ain Shams Eng. J. 2020, 11, 309–318. [Google Scholar] [CrossRef]
- Telsang, V.A.; Hegde, K. Breast Cancer Prediction Analysis using Machine Learning Algorithms. In Proceedings of the 2020 International Conference on Communication, Computing and Industry 4.0 (C2I4), Bangalore, India, 17–18 December 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Salma, M.U.; Doreswamy, N. Hybrid BATGSA: A metaheuristic model for classification of breast cancer data. Int. J. Adv. Intell. Paradig. 2020, 15, 207. [Google Scholar] [CrossRef]
- Singh, I.; Bansal, R.; Gupta, A.; Singh, A. A Hybrid Grey Wolf-Whale Optimization Algorithm for Optimizing SVM in Breast Cancer Diagnosis. In Proceedings of the 2020 Sixth International Conference on Parallel, Distributed and Grid Computing (PDGC), Waknaghat, India, 6–8 November 2020; pp. 286–290. [Google Scholar] [CrossRef]
- Badr, E.; Almotairi, S.; Salam, M.A.; Ahmed, H. New Sequential and Parallel Support Vector Machine with Grey Wolf Optimizer for Breast Cancer Diagnosis. Alex. Eng. J. 2021, 61, 2520–2534. [Google Scholar] [CrossRef]
- Badr, E.; Salam, M.A.; Almotairi, S.; Ahmed, H. From Linear Programming Approach to Metaheuristic Approach: Scaling Techniques. Complexity 2021, 2021, 9384318. [Google Scholar] [CrossRef]
- Badr, E.S.; Paparrizos, K.; Samaras, N.; Sifaleras, A. On the Basis Inverse of the Exterior Point Simplex Algorithm. In Proceedings of the 17th National Conference of Hellenic Operational Research Society (HELORS), Rio, Greece, 16–18 June 2005; pp. 677–687. [Google Scholar]
- Badr, E.S.; Paparrizos, K.; Thanasis, B.; Varkas, G. Some computational results on the efficiency of an exterior point algorithm. In Proceedings of the 18th National conference of Hellenic Operational Research Society (HELORS), Kozani, Greece, 15–17 June 2006; pp. 1103–1115. [Google Scholar]
- Badr, E.M.; Moussa, M.I. An upper bound of radio k-coloring problem and its integer linear programming model. Wirel. Netw. 2020, 26, 4955–4964. [Google Scholar] [CrossRef]
- Badr, E.; AlMotairi, S. On a Dual Direct Cosine Simplex Type Algorithm and Its Computational Behavior. Math. Probl. Eng. 2020, 2020, 7361092. [Google Scholar] [CrossRef]
- Badr, E.S.; Moussa, M.; Paparrizos, K.; Samaras, N.; Sifaleras, A. Some computational results on MPI parallel implementation of dense simplex method. Trans. Eng. Comput. Technol. 2006, 17, 228–231. [Google Scholar]
- Elble, J.M.; Sahinidis, N.V. Scaling linear optimization problems prior to application of the simplex method. Comput. Optim. Appl. 2012, 52, 345–371. [Google Scholar] [CrossRef]
- Ploskas, N.; Samaras, N. The impact of scaling on simplex type algorithms. In Proceedings of the 6th Balkan Conference in Informatics, Thessaloniki Greece, 19–21 September 2013; pp. 17–22. [Google Scholar] [CrossRef]
- Triantafyllidis, C.; Samaras, N. Three nearly scaling-invariant versions of an exterior point algorithm for linear programming. Optimization 2015, 64, 2163–2181. [Google Scholar] [CrossRef]
- Ploskas, N.; Samaras, N. A computational comparison of scaling techniques for linear optimization problems on a graphical processing unit. Int. J. Comput. Math. 2015, 92, 319–336. [Google Scholar] [CrossRef]
- Badr, E.M.; Elgendy, H. A hybrid water cycle-particle swarm optimization for solving the fuzzy underground water confined steady flow. Indones. J. Electr. Eng. Comput. Sci. 2020, 19, 492–504. [Google Scholar] [CrossRef]
- Tapkan, P.; Özbakır, L.; Baykasoglu, A. Bee algorithms for parallel two-sided assembly line balancing problem with walking times. Appl. Soft Comput. 2016, 39, 275–291. [Google Scholar] [CrossRef]
- Tian, T.; Gong, D. Test data generation for path coverage of message-passing parallel programs based on co-evolutionary genetic algorithms. Autom. Softw. Eng. 2016, 23, 469–500. [Google Scholar] [CrossRef]
- Maleki, S.; Musuvathi, M.; Mytkowicz, T. Efficient parallelization using rank convergence in dynamic programming algorithms. Commun. ACM 2016, 59, 85–92. [Google Scholar] [CrossRef] [Green Version]
- Sandes, E.F.D.O.; Boukerche, A.; De Melo, A.C.M.A. Parallel Optimal Pairwise Biological Sequence Comparison. ACM Comput. Surv. 2016, 48, 1–36. [Google Scholar] [CrossRef]
- Truchet, C.; Arbelaez, A.; Richoux, F.; Codognet, P. Estimating parallel runtimes for randomized algorithms in constraint solving. J. Heuristics 2016, 22, 613–648. [Google Scholar] [CrossRef]
- Połap, D.; Kęsik, K.; Woźniak, M.; Damaševičius, R. Parallel Technique for the Metaheuristic Algorithms Using Devoted Local Search and Manipulating the Solutions Space. Appl. Sci. 2018, 8, 293. [Google Scholar] [CrossRef] [Green Version]
- Jiao, S.; Gao, Y.; Feng, J.; Lei, T.; Yuan, X. Does deep learning always outperform simple linear regression in optical imag-ing? Opt. Express 2020, 28, 3717–3731. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chauhan, D.; Anyanwu, E.; Goes, J.; Besser, S.A.; Anand, S.; Madduri, R.; Getty, N.; Kelle, S.; Kawaji, K.; Mor-Avi, V.; et al. Comparison of machine learning and deep learning for view identification from cardiac magnetic resonance images. Clin. Imaging 2022, 82, 121–126. [Google Scholar] [CrossRef]
- Sain, S.R.; Vapnik, V.N. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1996; Volume 38. [Google Scholar]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Meth-Ods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar] [CrossRef] [Green Version]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Futur. Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- UCI Machine Learning Repository. Breast Cancer Wisconsin (Diagnostic) Data Set 1995. Available online: https://archive.ics.uci.edu/dataset/17/breast+cancer+wisconsin+diagnostic (accessed on 1 January 2015).
- Chang, C.; Lin, C. LIBSVM: A Library for Support Vector Machines. ACM Trans. Intell. Syst. Technol. 2013, 2, 1–27. [Google Scholar] [CrossRef]
- Salzberg, S.L. On Comparing Classifiers: Pitfalls to Avoid and a Recommended Approach. Data Min. Knowl. Discov. 1997, 1, 317–328. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Term | Meaning |
|---|---|
| matrix (with m entities and n attributes) | |
| The scaling factor of row | |
| The scaling factor of row | |
| (diagonal matrix) | |
| (diagonal matrix) | |
| The cardinality of the set | |
| The cardinality of the set | |
| The scaled matrix by row scaling factor | |
| The scaled matrix in its final form. |
| No | Attribute Name | Description |
|---|---|---|
| 3 | Radius | The range between the center and point on the perimeter |
| 4 | Texture | Gray-scale values’ standard deviation |
| 5 | Perimeter | The total distance between the points that make up the nuclear perimeter |
| 6 | Area | The average of the cancer cell areas |
| 7 | Smoothness | The distance between a radial line’s length and the mean length of the lines that surround it. |
| 8 | Compactness | |
| 9 | Concavity | The severity of the contour’s concave parts |
| 10 | Concave points | The number of concave contour parts |
| 11 | Fractal dimension | (“coastline approximation”—1) |
| 12 | Symmetry | In both directions, the length difference between lines perpendicular to the major axis and the cell boundary. |
| Center Processing Unit | Intel (R) Core (TM) i5—7200U CPU@ 2.70 GHz |
|---|---|
| RAM size | 4 GB RAM |
| MATLAB ver. | R2015a |
| Fold | (S0) | (S1) | ||||
|---|---|---|---|---|---|---|
| C | γ | Accuracy % | C | γ | Accuracy % | |
| 1 | 23 | 2−13 | 94.76 | 211 | 21 | 94.64 |
| 2 | 27 | 2−15 | 91.59 | 215 | 21 | 92.98 |
| 3 | 215 | 2−13 | 100 | 213 | 21 | 100 |
| 4 | 25 | 2−13 | 97.18 | 213 | 21 | 98.25 |
| 5 | 21 | 2−11 | 96.23 | 215 | 21 | 96.49 |
| 6 | 2−1 | 2−9 | 91.29 | 215 | 2−1 | 96.49 |
| 7 | 211 | 2−15 | 97.59 | 213 | 21 | 100 |
| 8 | 29 | 2−15 | 98.60 | 215 | 21 | 96.49 |
| 9 | 29 | 2−15 | 97.59 | 213 | 21 | 94.74 |
| 10 | 215 | 2−9 | 96.23 | 213 | 2−1 | 96.49 |
| Avg. | 6877.9 | 0.00049 | 96.10 | 17408 | 1.7 | 96.66 |
| Time | 52.62167 | 19.208797 | ||||
| Fold | (S2) | (S3) | ||||
|---|---|---|---|---|---|---|
| C | γ | Accuracy % | C | γ | Accuracy % | |
| 1 | 23 | 2−7 | 100.00 | 21 | 2−5 | 100 |
| 2 | 215 | 2−9 | 98.25 | 29 | 2−5 | 98.25 |
| 3 | 29 | 2−5 | 96.49 | 29 | 2−5 | 96.49 |
| 4 | 2−1 | 2−5 | 96.49 | 2−1 | 2−5 | 96.49 |
| 5 | 29 | 2−9 | 100.00 | 29 | 2−9 | 100 |
| 6 | 25 | 2−5 | 98.25 | 27 | 2−5 | 98.25 |
| 7 | 27 | 2−7 | 98.25 | 23 | 2−3 | 100.00 |
| 8 | 2−1 | 2−3 | 98.25 | 215 | 2−3 | 98.25 |
| 9 | 29 | 2−9 | 100.00 | 29 | 2−9 | 100 |
| 10 | 215 | 2−9 | 98.25 | 25 | 2−3 | 98.25 |
| Avg. | 6724 | 0.024 | 98.42 | 3498.7 | 0.0535 | 98.59 |
| Time | 7.237509 | 6.822561 | ||||
| Fold | (S4) | ||
|---|---|---|---|
| C | γ | Accuracy % | |
| 1 | 25 | 2−1 | 100.00 |
| 2 | 23 | 21 | 98.25 |
| 3 | 25 | 2−1 | 100.00 |
| 4 | 215 | 21 | 98.25 |
| 5 | 21 | 2−1 | 100.00 |
| 6 | 29 | 2−1 | 98.25 |
| 7 | 215 | 21 | 100.00 |
| 8 | 215 | 21 | 100.00 |
| 9 | 23 | 21 | 94.74 |
| 10 | 23 | 21 | 100.00 |
| Avg. | 9890.6 | 1.4 | 98.95 |
| CPU Time | 6.066946 | ||
| No | Symbol | Accuracy | CPU Time |
|---|---|---|---|
| 1 | (S4) | 98.95 | 6.066946 |
| 2 | (S3) | 98.59 | 6.822561 |
| 3 | (S2) | 98.42 | 7.237509 |
| 4 | (S1) | 96.66 | 19.208797 |
| 6 | (S0) | 96.10 | 52.62167 |
| Fold | HHO-SVM (S0) | |||
|---|---|---|---|---|
| Accuracy % | Sensitivity % | Specificity % | Precision % | |
| 1 | 91.07 | 90.48 | 91.43 | 91.07 |
| 2 | 98.98 | 81.82 | 100 | 98.98 |
| 3 | 100 | 100 | 100 | 100 |
| 4 | 96.49 | 95.24 | 97.22 | 96.49 |
| 5 | 63.16 | 0 | 100 | 63.16 |
| 6 | 92.98 | 80.95 | 100 | 92.98 |
| 7 | 96.49 | 95.24 | 97.22 | 96.49 |
| 8 | 63.16 | 0 | 100 | 63.16 |
| 9 | 96.49 | 95.24 | 97.22 | 96.49 |
| 10 | 98.25 | 100 | 97.22 | 98.25 |
| Avg. | 89.11 | 73.90 | 98.03 | 89.11 |
| CPU Time | 1.88 × 104 | |||
| Fold | HHO-SVM (S0) | |||
|---|---|---|---|---|
| Recall % | F-Score % | G-Mean % | RMSE | |
| 1 | 90.48 | 90.95 | 0.2988 | 90.48 |
| 2 | 81.82 | 90.45 | 0.2649 | 81.82 |
| 3 | 100 | 100 | 0.00 | 100 |
| 4 | 95.24 | 96.23 | 0.1873 | 95.24 |
| 5 | 0.00 | 0.00 | 0.6070 | 0.00 |
| 6 | 80.95 | 89.97 | 0.2649 | 80.95 |
| 7 | 95.24 | 96.23 | 0.1873 | 95.24 |
| 8 | 0.00 | 0.00 | 0.6070 | 0.00 |
| 9 | 95.24 | 96.23 | 0.1873 | 95.24 |
| 10 | 100 | 98.60 | 0.1325 | 100 |
| Avg. | 73.90 | 75.87 | 0.2737 | 73.90 |
| CPU Time | 1.88 × 104 | |||
| Fold | HHO-SVM (S1) | |||
|---|---|---|---|---|
| Accuracy % | Sensitivity % | Specificity % | Precision % | |
| 1 | 94.64 | 95.24 | 94.29 | 90.91 |
| 2 | 98.25 | 100 | 97.14 | 95.65 |
| 3 | 96.49 | 100 | 94.29 | 91.67 |
| 4 | 100 | 100 | 100 | 100 |
| 5 | 98.25 | 95.24 | 100 | 100 |
| 6 | 100 | 100 | 100 | 100 |
| 7 | 100 | 100 | 100 | 100 |
| 8 | 94.74 | 85.71 | 100 | 100 |
| 9 | 100 | 100 | 100 | 100 |
| 10 | 100 | 100 | 100 | 100 |
| Avg. | 98.24 | 97.62 | 98.57 | 97.82 |
| CPU Time | 1.13 × 105 | |||
| Fold | HHO-SVM (S1) | |||
|---|---|---|---|---|
| Recall % | F-Score % | G-Mean % | RMSE | |
| 1 | 95.24 | 93.02 | 94.76 | 0.2315 |
| 2 | 100 | 97.78 | 98.56 | 0.1325 |
| 3 | 100 | 95.65 | 97.1 | 0.1873 |
| 4 | 100 | 100 | 100 | 0 |
| 5 | 95.24 | 97.56 | 97.59 | 0.1325 |
| 6 | 100 | 100 | 100 | 0 |
| 7 | 100 | 100 | 100 | 0 |
| 8 | 85.71 | 92.31 | 92.58 | 0.2294 |
| 9 | 100 | 100 | 100 | 0 |
| 10 | 100 | 100 | 100 | 0 |
| Avg. | 97.62 | 97.63 | 98.06 | 0.0913 |
| CPU Time | 1.13 × 105 | |||
| Fold | HHO-SVM (S2) | |||
|---|---|---|---|---|
| Accuracy % | Sensitivity % | Specificity % | Precision % | |
| 1 | 100 | 100 | 100 | 100 |
| 2 | 100 | 100 | 100 | 100 |
| 3 | 94.74 | 90.91 | 97.14 | 95.24 |
| 4 | 98.25 | 95.24 | 100 | 100 |
| 5 | 100 | 100 | 100 | 100 |
| 6 | 100 | 100 | 100 | 100 |
| 7 | 100 | 100 | 100 | 100 |
| 8 | 94.74 | 90.48 | 97.22 | 95 |
| 9 | 98.25 | 95.24 | 100 | 100 |
| 10 | 96.49 | 90.48 | 100 | 100 |
| Avg. | 98.25 | 96.23 | 99.44 | 99.02 |
| CPU Time | 2.20 × 104 | |||
| Fold | HHO-SVM (S2) | |||
|---|---|---|---|---|
| Recall % | F-Score % | G-Mean % | RSME | |
| 1 | 100 | 100 | 100 | 0 |
| 2 | 100 | 100 | 100 | 0 |
| 3 | 90.91 | 93.02 | 93.97 | 0.2294 |
| 4 | 95.24 | 97.56 | 97.59 | 0.1325 |
| 5 | 100 | 100 | 100 | 0 |
| 6 | 100 | 100 | 100 | 0 |
| 7 | 100 | 100 | 100 | 0 |
| 8 | 90.48 | 92.68 | 93.79 | 0.2294 |
| 9 | 95.24 | 97.56 | 97.59 | 0.1325 |
| 10 | 90.48 | 95 | 95.12 | 0.1873 |
| Avg. | 96.23 | 97.58 | 97.81 | 0.0911 |
| CPU Time | 2.20 × 104 | |||
| Fold | HHO-SVM (S3) | |||
|---|---|---|---|---|
| Accuracy % | Sensitivity % | Specificity % | Precision % | |
| 1 | 96.43 | 90.48 | 100 | 100 |
| 2 | 100 | 100 | 100 | 100 |
| 3 | 96.49 | 90.91 | 100 | 100 |
| 4 | 100 | 100 | 100 | 100 |
| 5 | 96.49 | 90.48 | 100 | 100 |
| 6 | 100 | 100 | 100 | 100 |
| 7 | 96.49 | 95.24 | 97.22 | 95.24 |
| 8 | 98.25 | 100 | 97.22 | 95.45 |
| 9 | 98.25 | 95.24 | 100 | 100 |
| 10 | 100 | 100 | 100 | 100 |
| Avg. | 98.24 | 96.23 | 99.44 | 99.07 |
| Time | 2.71 × 104 | |||
| Fold | HHO-SVM (S3) | |||
|---|---|---|---|---|
| Recall % | F-Score % | G-Mean % | RSME | |
| 1 | 90.48 | 95 | 95.12 | 0.1890 |
| 2 | 100 | 100 | 100 | 0 |
| 3 | 90.91 | 95.24 | 95.35 | 0.1873 |
| 4 | 100 | 100 | 100 | 0 |
| 5 | 90.48 | 95 | 95.12 | 0.1873 |
| 6 | 100 | 100 | 100 | 0 |
| 7 | 95.24 | 95.24 | 96.23 | 0.1873 |
| 8 | 100 | 97.67 | 98.60 | 0.1325 |
| 9 | 95.24 | 97.56 | 97.59 | 0.1325 |
| 10 | 100 | 100 | 100 | 0 |
| Avg. | 96.23 | 97.57 | 97.80 | 0.1016 |
| CPU Time | 2.71 × 104 | |||
| Fold | HHO-SVM (S4) | |||
|---|---|---|---|---|
| Accuracy % | Sensitivity % | Specificity % | Precision % | |
| 1 | 100 | 100 | 100 | 100 |
| 2 | 96.49 | 90.91 | 100 | 100 |
| 3 | 100 | 100 | 100 | 100 |
| 4 | 100 | 100 | 100 | 100 |
| 5 | 100 | 100 | 100 | 100 |
| 6 | 100 | 100 | 100 | 100 |
| 7 | 100 | 100 | 100 | 100 |
| 8 | 100 | 100 | 100 | 100 |
| 9 | 100 | 100 | 100 | 100 |
| 10 | 98.25 | 95.24 | 100 | 100 |
| Avg. | 99.47 | 98.61 | 100 | 100 |
| CPU Time | 8.14 × 103 | |||
| Fold | HHO-SVM (S4) | |||
|---|---|---|---|---|
| Recall % | F-Score % | G-Mean % | RMSE | |
| 1 | 100 | 100 | 100 | 0 |
| 2 | 90.91 | 95.24 | 95.35 | 0.1873 |
| 3 | 100 | 100 | 100 | 0 |
| 4 | 100 | 100 | 100 | 0 |
| 5 | 100 | 100 | 100 | 0 |
| 6 | 100 | 100 | 100 | 0 |
| 7 | 100 | 100 | 100 | 0 |
| 8 | 100 | 100 | 100 | 0 |
| 9 | 100 | 100 | 100 | 0 |
| 10 | 95.24 | 97.56 | 97.59 | 0.1325 |
| Avg. | 98.61 | 99.28 | 99.29 | 0.0320 |
| CPU Time | 8.14 × 103 | |||
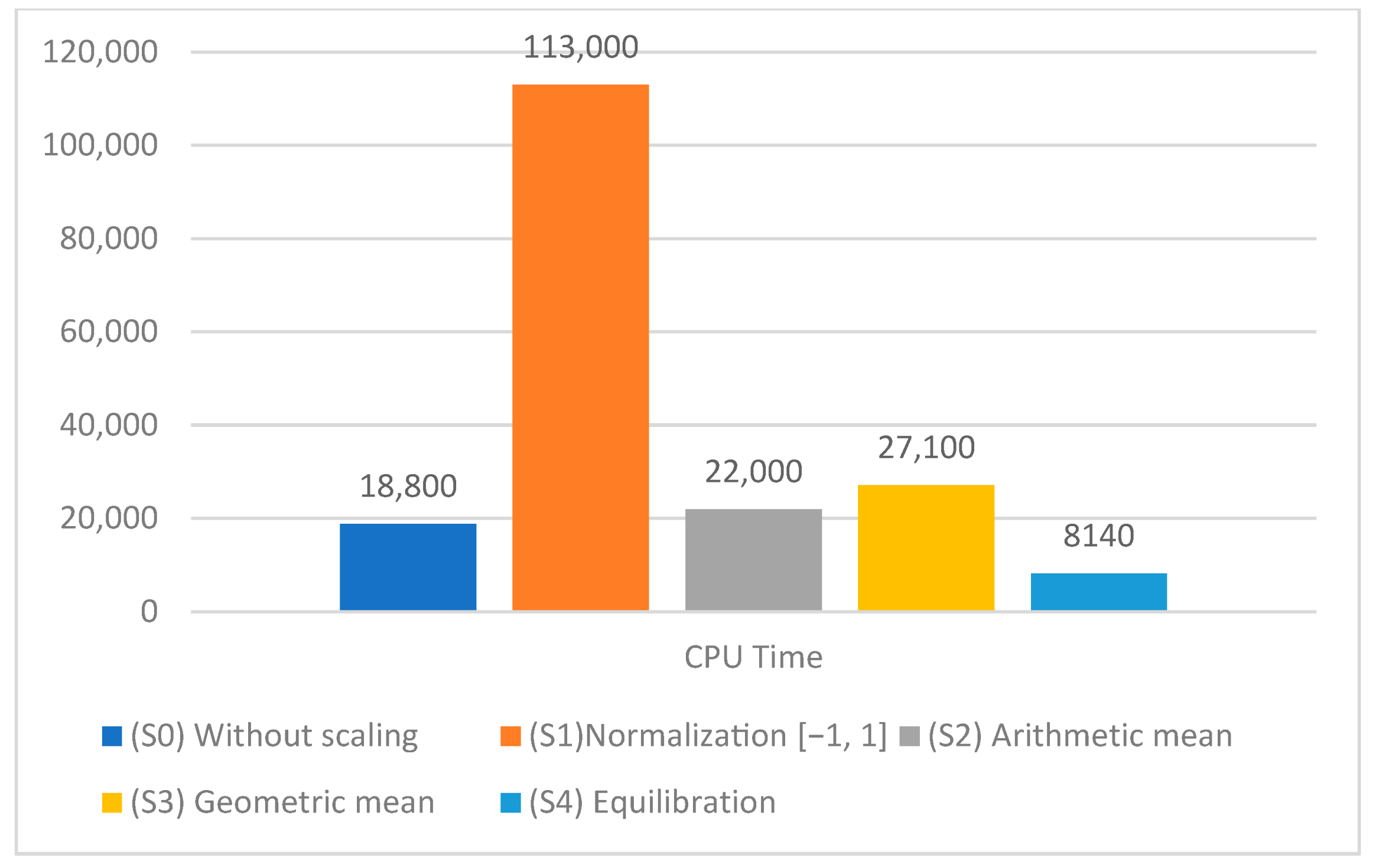
| No | Symbol | Accuracy | CPU Time |
|---|---|---|---|
| 1 | (S0) | 89.11 | 18,800 |
| 1 | (S1) | 98.24 | 113,000 |
| 2 | (S2) | 98.25 | 22,000 |
| 3 | (S3) | 98.24 | 27,100 |
| 4 | (S4) | 99.47 | 8140 |
| Symbol | Scaling Techniques | HHO-SVM Accuracy | Grid-SVM Accuracy |
|---|---|---|---|
| (S1) | Normalization [−1, 1] | 98.24 | 96.49 |
| (S2) | Arithmetic mean | 98.25 | 98.42 |
| (S3) | Geometric mean | 98.24 | 98.59 |
| (S4) | Equilibration | 99.47 | 98.95 |
| Symbol | Scaling Techniques | HHO-SVM | ||
|---|---|---|---|---|
| Core1 | Core2 | Core4 | ||
| (S1) | Normalization [−1, 1] | 91,600 | 47,461.14 | 23,073.04 |
| (S2) | Arithmetic mean | 8560 | 4703.30 | 2338.80 |
| (S3) | Geometric mean | 11,000 | 5820.11 | 2941.18 |
| (S4) | Equilibration | 3500 | 2023.12 | 980.39 |
| Symbol | HHO-SVM | ||
|---|---|---|---|
| Core1 | Core2 | Core4 | |
| (S1) | 1 | 1.93 | 3.97 |
| (S2) | 1 | 1.82 | 3.66 |
| (S3) | 1 | 1.89 | 3.74 |
| (S4) | 1 | 1.73 | 3.57 |
| Study | Year | Method | Accuracy (%) |
|---|---|---|---|
| Tuba et al. [6] | (2016) | ABA-SVM | 96.49 % |
| Aalaei et al. [7] | (2016) | GA-ANN | 97.30% |
| S. Mandal [8] | (2017) | Logistic regression | 97.90% |
| Liu et al. [10] | (2018) | ICS-SVM | 98.83% |
| Agarap [11] | (2018) | GRU-SVM | 93.80% |
| Dhahri et al. [15] | (2019) | GA-AB | 98.23% |
| Telsang et al. [17] | (2020) | SVM | 96.25% |
| Umme et al. [18] | (2020) | BATGSA-FNN | 92.10% |
| Singh et al. [19] | (2020) | GWWOA-SVM | 97.72% |
| Badr et al. [20] | (2021) | GWO-SVM | 99.3% |
| Our study | (2023) | HHO-SVM | 99.47% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almotairi, S.; Badr, E.; Abdul Salam, M.; Ahmed, H. Breast Cancer Diagnosis Using a Novel Parallel Support Vector Machine with Harris Hawks Optimization. Mathematics 2023, 11, 3251. https://doi.org/10.3390/math11143251
Almotairi S, Badr E, Abdul Salam M, Ahmed H. Breast Cancer Diagnosis Using a Novel Parallel Support Vector Machine with Harris Hawks Optimization. Mathematics. 2023; 11(14):3251. https://doi.org/10.3390/math11143251
Chicago/Turabian StyleAlmotairi, Sultan, Elsayed Badr, Mustafa Abdul Salam, and Hagar Ahmed. 2023. "Breast Cancer Diagnosis Using a Novel Parallel Support Vector Machine with Harris Hawks Optimization" Mathematics 11, no. 14: 3251. https://doi.org/10.3390/math11143251
APA StyleAlmotairi, S., Badr, E., Abdul Salam, M., & Ahmed, H. (2023). Breast Cancer Diagnosis Using a Novel Parallel Support Vector Machine with Harris Hawks Optimization. Mathematics, 11(14), 3251. https://doi.org/10.3390/math11143251