1. Introduction
The emergence and adoption of social media as an important communication and interaction platform in recent times cannot be overemphasized. As stated by Chaffey [
1], there are over 3 billion active users that communicate and interact with each other daily via social media. Thus, social media is pivotal to the definition and spread of information and content in the modern world. Moreover, social media platforms enable relationship- and interest-based virtual communities that allow connection and networking among people [
2,
3,
4]. The increased popularity of these social media platforms (Facebook, Twitter, Instagram, Tinder, etc.) allows the sharing of various forms of multimedia messages among its users [
5]. Mining and deriving analytics from these social media platforms have been standardized as feasible and viable methods or options to identify real-time insights from most users. For instance, these social media platforms’ operations were pivotal during the COVID-19 pandemic, as real-time data on events and discoveries were easily disseminated among people in various places [
6,
7].
Although it is apparent that social media platforms offer numerous benefits to their users, these platforms may also be exploited for malevolent purposes [
2,
8,
9]. Cyberbullying is a prominent and profound example of these malevolent trends [
10]. Specifically, the pervasiveness of these social media platforms has undeniably sparked, advanced, and worsened bullying among its users [
11].
Bullying seems to have been present throughout the history of human civilization, and it entails abusing someone by embarrassing or bothering them in any way that causes emotional, psychological, or physical harm. When this assault occurs via the Internet, it is known as cyberbullying or cybervictimization [
11]. Cyberbullying can be described as bullying a person or a group of people, who are usually referred to as “victim(s)”, with the aid of an Internet, mobile, or electronic device by sending improper textual or non-textual multimedia content [
3]. In other words, cyberbullying is the continuous display of unpleasant acts carried out on the “victim(s)” to exact fear, annoyance, pain, or harm via electronic media and social media platforms [
9]. Cyberbullying has been a major problem in the last decade, mostly impacting children and adolescents. For instance, a United States (US)-based study reported that over 43% of teenagers in the US are being cyberbullied [
12]. According to ER statistics, around 18% of Europe’s youngsters have been affected by someone bullying or harassing them via the Internet and mobile phones [
3]. As stated in the 2014 EU Kids Online Report, more than 20% of children (aged between 11 and 16 years) experience cyberbullying [
3,
13]. In Sweden, which is a developed country, the prevalence of cyberbullying has hit a tipping point, gradually growing and worsening [
2]. These reports demonstrate how critical it is to develop an acceptable, quick, and tested solution to this Internet-based problem. It is, therefore, imperative to evaluate and address cyberbullying from a variety of perspectives, including automatic identification and prevention of such incidents [
2,
3,
9,
12].
Due to technological development, the social privileges (anonymity) that social media provide, and access to a broader audience, cyberbullying has grown exponentially [
11]. This issue necessitates the development of intelligent tools and strategies that recognize, detect, and analyze cyberbullying using existing social multimedia data to mitigate its harmful impact. Automated cyberbullying detection is a classification issue, with the goal being categorizing each abusive or insulting comment/post/message/image as bullying or non-bullying [
9,
13,
14]. Although some social media platforms, such as YouTube and Twitter, have embedded safety centers to monitor and control cyberbullying, the problem still lingers, and there is a need for more definite solutions [
2,
13].
In addition, much research has been carried out to investigate new paradigms through which to deal with the uncertainty or fuzziness created by social media data, resulting in computationally effective automated cyberbullying detection systems [
15,
16,
17]. Recently, the automatic identification of cyberbullying using deep learning (DL) and machine learning (ML) has received a lot of interest [
3,
9,
14,
15,
18,
19]. For instance, Muneer and Fati [
18] investigated the performance of different ML algorithms in cyberbullying detection. Also, Alam et al. [
20] analyzed the performance of four ML methods and three ensemble methods in cyberbullying detection. Experimental results derived from these studies showed the effectiveness of ML methods of cyberbullying detection. Similarly, Dadvar and Eckert [
13] and Iwendi et al. [
3] deployed DL techniques to aid cyberbullying detection. Their respective results indicated the applicability of DL methods to cyberbullying detection. Moreover, the findings of their studies indicated the superiority of DL techniques to ML techniques in cyberbullying detection. Also, DL techniques have the advantage of being more easily used on different datasets (transfer learning) than conventional ML-based approaches [
13]. Nonetheless, the integration of an appropriate feature extraction method using a DL technique can further improve its detection performance [
21]. Moreover, the proficiency of DL techniques needs to be investigated to ascertain and validate the efficacies of the DL technique in cyberbullying detection. Hence, this study aims to propose and conduct an extensive empirical analysis of various DL techniques using multiple feature extraction methods. This study will guide researchers and practitioners on how to select appropriate DL and feature extraction methods in cyberbullying detection. Specifically, this paper has a multifold contribution as follows:
The performances of six DL-based attention mechanism techniques used in cyberbullying detection are investigated and evaluated;
The performances of two feature extraction methods used in the selection of prominent features of cyberbullying detection are evaluated;
The evaluation of the effectiveness and performance of DL methods using different feature extraction methods is performed through empirical analysis.
This paper is succinctly organized as follows:
Section 2 discusses related studies and provides related works in the context of using machine learning in cyberbullying detection.
Section 3 presents the theoretical background of the proposed cyberbullying model, while
Section 4 designates the proposed method, including details such as experimental results, datasets, parameter settings, and visualized results with their discussions is provided, and concluding remarks are presented in
Section 5.
2. Related Works
Teenagers’ online activities have grown in recent years, especially on social media platforms, with more individuals being subjected to cyberbullying. Comments containing harsh words have a negative impact on adolescent psychology, demoralize teenagers, and might even escalate into despair. Chavan and Shylaja [
22] provided two feature extraction (FE) methods that were used to identify perceived unfavorable and insulting remarks frequently aimed at peers. Their combination of hand-crafted features and conventional FE methods tends to improve the suggested system’s detection accuracy. Even though current methods influenced by DL and ML techniques have enhanced cyber-bullying detection performance, the absence of acceptable standard labelled datasets continues to restrict the development of this approach. Consequently, Chen et al. [
23] presented a method in which feedback in the form of comments was combined with crowdsourcing, including actual realistic scenarios of deliberately unpleasant or pleasant remarks.
Kumar and Sachdeva [
9] investigated the concept of utilizing soft computing techniques to identify cyberbullying, particularly via social media sites. They compared their findings to prior research and concluded that social media companies should use a meta-analytic approach to cyberbullying detection. Frommholz et al. [
24] developed a technique to identify, text categorize, and customize text-based cyberstalking. It was an ethical framework and represented a means of detecting text-based cyberstalking. The suggested technique emphasized the need to use additional methods, like forensic analysis, to identify bullies.
Bruwaene et al. [
25] showed several phases and numerous approach systems that integrated crowdsourcing for topic and keyword tagging and, subsequently, used ML methods to discover additional topics requiring evaluation. They concluded that if the dataset was trained using their method, the models might perform very well. They emphasize the need for positive and regular parental, instructor, or peer monitoring to improve cyberbullying prevention measures. Khan [
26] investigated cross-lingual emotion recognition using four different languages: English, Urdu, Italian, and German. They obtained an accuracy rate of 91.25%. In another study, Zhao and Mao [
27] presented a technique to evaluate the underlying structure of cyberbullying features and acquire a robust and discriminative representation of text. Their proposed technique outperformed existing basic text portrayal methods. Rosa et al. [
28] utilized 22 studies and tests to verify existing methods of automated cyberbullying identification. They eventually concluded by presenting findings suggesting that cyberbullying is often misrepresented and the inherent imbalance nature of cyberbullying dataset is an often an issue. Sugandhi et al. [
29] explored the same technique. In this regard, the system of response grading identified the cyberbullying’s heinousness and reacted accordingly. Rakib and Soon [
30] started with a Reddit word-embedding application, before moving on to a cyberbullying detection model utilizing a public dataset of 6594 comments derived from Kaggle. The system was built and trained using the random forest (RF) algorithm. The prediction model provides 90% score in terms of area under the curve (AUC), while the precision was 0.89. The disadvantage of this study is that the sample was unbalanced, with cyberbullying messages accounting for just 25% of the total [
30]. Moreover, Agrawal and Awekar [
31] and Dadvar and Eckert [
13] performed similar studies deploying DL techniques to build the prediction models. They utilized over-sampling techniques, which may be a drawback of their proposed methods, since additional details are added to the datasets.
Haidar et al. [
32] developed a method to prevent cyberbullying in several languages. The suggested method was evaluated using an authentic Arabic dataset obtained from Arab countries. Haider et al. deployed two ML classifiers, namely support vector machine (SVM) and naive Bayes (NB), with acceptable results. Nonetheless, this study may be improved using DL techniques and expanding the dataset size. Also, Al-Ajlan and Ykhlef [
33] used 20,000 random tweets to create a cyberbullying technique. To eliminate noisy and undesirable data, data pre-processing was used, whereby the data were partitioned and labeled. To label tweets for training data, tweet categorization was given. A dataset was later classified using deep convolutional neural networks (CNN). There were no promising experimental findings. The research must be broadened by considering a big data set and many languages. Similarly, Banerjee et al. [
34] utilized deep convolutional neural networks (DCNN) to analyze the 69,874-tweet dataset derived from Twitter. Glove’s open-source word-embedding model was used to map tweets to vectors. The testing findings revealed that the authors obtained a 93.7% accuracy rate using deep convolutional neural networks. Detecting cyberbullying in conversations that include both Hindi and English may, however, broaden the scope of the study. The primary focus of Wulczyn et al.’s study [
35] was the Wiki-Detox dataset. They developed a classifier that provided results, in terms of AUC and Spearman’s correlation, that are as excellent as those of three human workers combined. Bozyiğit et al. [
2] aimed to evaluate cyberbullying detection in the Turkish language using eight diverse ANN algorithms. The study recorded a F1-measure score of 91%, which outperformed the existing ML classifiers. Pawar and Raje’s [
32] work is another example of a comparable situation. Their article provided a method of identifying and preventing cyberbullying, with a focus on Arabic-language material. Finally, their method was used to optimize DL, resulting in excellent parameter tuning. Jeyasheeli and Selva [
36] utilized another example to demonstrate the inadequacy of prior techniques’ categorization. The main research issue that is addressed in this study is the integration of an appropriate FE method that uses a DL technique to enable cyberbullying detection. Furthermore, the effectiveness of DL approaches must be studied to establish and verify the efficacy of DL approaches regarding cyberbullying detection.
Table 1 shows the comparison between the related works.
3. Research Methodology
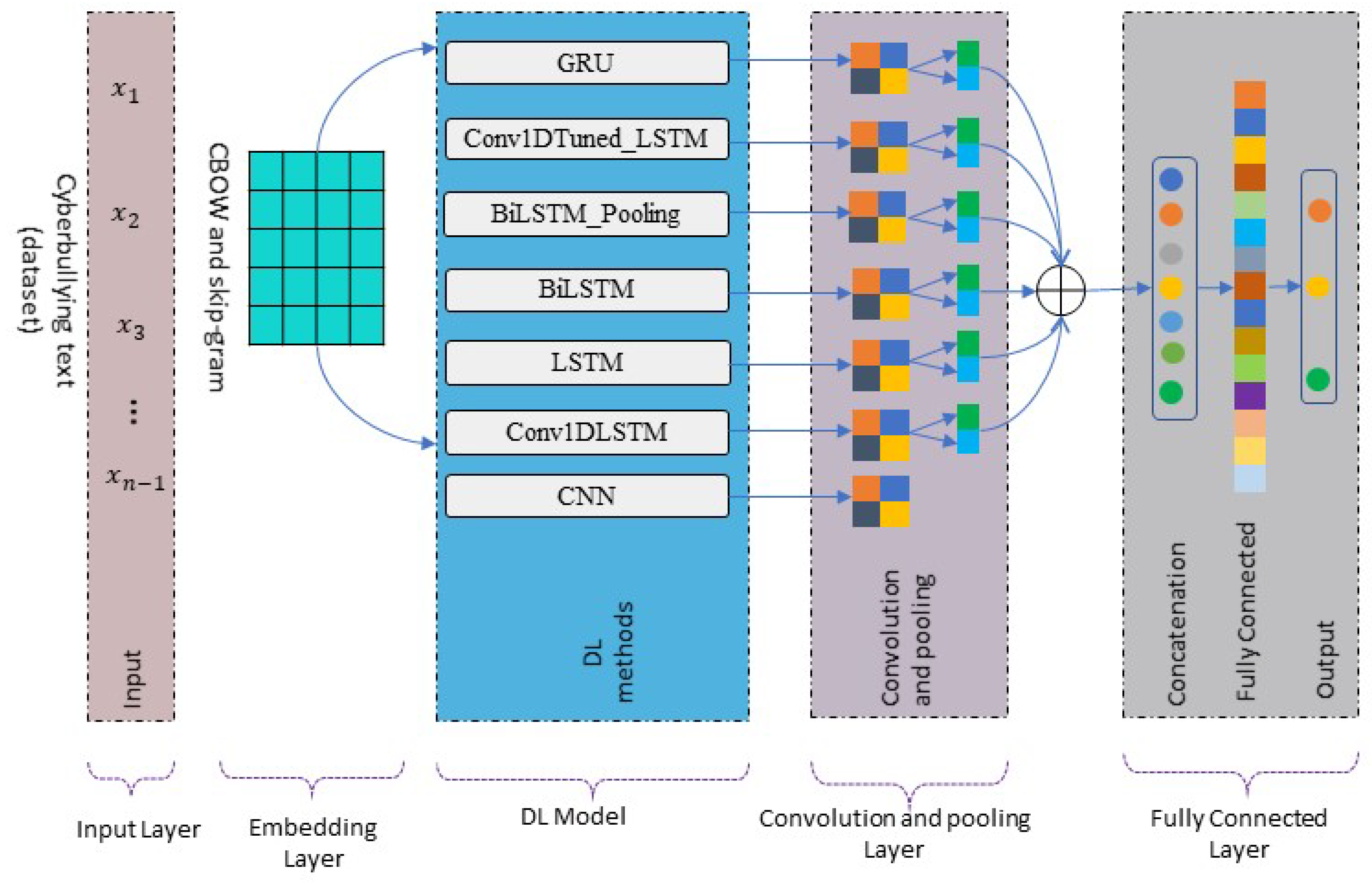
The research methodology that was followed is illustrated in
Figure 1, whereby the following steps were applied to achieve this study’s goal. Firstly, the dataset was loaded into a local machine to perform the necessary pre-processing on the dataset, including essential natural language processing (NLP) steps, such as text cleaning, stemming, tokenizing, and lemmatizing. Then, the problematic comment pattern was analyzed using linguistic techniques. Next, multiple deep learning algorithms were applied after data partitioning to allow them to be tested and evaluated using proper performance evaluation metrics.
3.1. Dataset Discription
This study utilized a global benchmark dataset of 37,373 tweets to detect cyberbullying by identifying offensive and non-offensive tweets [
18]. The dataset had 37,373 columns and four rows (ID, label, tweet, and tag). It was numerically labeled, with tweets assigned a label of 1 for offensive tweets and 0 for neutral tweets that did not belong to the offensive category. The first characteristic evaluated was the timestamp of the comments, although this information was often missing or incomplete, making it challenging to obtain precise timestamps. The dataset primarily consisted of English-language tweets, and pre-processing methods and data cleaning techniques were applied, as explained in the subsequent subsections. To identify offensive tweets within the Twitter dataset, a set of unique bullying keywords was manually selected (e.g., “stupid”, “idiot”, “hoe”, “nigga”, “moron”, “loser”, “fool”, “dumb”, “retard”, “slut”, “bitch”, and “ugly”) for insults and name-calling tweets.
Figure 2 illustrates the distribution of tweet lengths, with a significant number of tweets containing fewer than 10 words. Among these tweets, there were 1972 tweets specifically consisting of 9 words, which was the highest count within the dataset.
Figure 3 provides a count of tweets with higher numbers of words, showcasing that there were 1865 tweets comprising exactly 11 words. The longest tweet in the dataset contained 52 words, as depicted in
Figure 3. Additionally,
Figure 4 presents an illustration of the dataset’s unique bullying words alongside the most frequently used words. These unique bullying words were manually selected based on their presence within the dataset.
3.2. Embedding Layer
As mentioned earlier, this study used NLP in the pre-processing stage. In NLP, the word was represented as a one-hot vector, whereby all of the cells should be filled with 0, except for the cell that contained the word. Such representation was somehow impractical due to the sparsity and high dimensionality. Thus, in this study, we used the continuous vector space, whereby similar words were aggregated in a cluster. Such a vector space was more efficient.
Recently, using neural networks to obtain word representations has attracted researchers’ attention as the learner vectors explicitly encode uneven patterns in the texts with several linguistic. Word-embedding representations can be learned using the word2vec with skip-gram [
38] and continuous bag-of-words (CBOW) [
39] models. Both models have the same objective, except that the skip-gram model relies on maximizing the prediction probability of the adjacent attributes based on the main word.
Figure 5 shows how the CBOW uses word vector representations to anticipate the middle words in context.
Due to the similarities between the CBOW and skip-gram models, we delved into their derivation. As both models entail a substantial computational cost, training methods such as hierarchical SoftMax or negative sampling were employed to mitigate this issue. Hierarchical SoftMax entailed the representation of all words in the vocabulary as tree units at the output layer. This process was accomplished using a frequency-based Huffman tree, which was typically a binary tree [
40]. In the CBOW model that used hierarchical SoftMax, the output was replaced by a Huffman tree, facilitating more efficient computation. In the CBOW model, the hidden layer performed the task of averaging the input word vectors. As a result, the output of the hidden layer could be represented as the average of the following vectors:
In the given expression,
v(
u) represents the vector of the word
u, context(
w) represents the set of contextual information associated with the word
w, and
C represents the cardinality of the context set. Consequently, within each context, the conditional probability of the word
w could be defined as follows:
where
represent the
inner point from root to word w in the Huffman tree,
and represents the vector of an inner point
, where
represents the length of the Huffman tree for word
and || is a function defined as follows:
where
is the
bit of the Huffman code for word
. In this study, we implemented it by maximizing the conditional probability of the equation during the model’s training in
Figure 5 for the context (or target) of the word
. The log of the conditional probability provides the loss function as follows:
The derivative = obtained
as a loss function of the vector of the inner point
as follows:
where
. We define the derivative of l of vector of information contextual of words
as follows:
They are mirror images of one another. The CBOW model’s learning goal is to train a word vector that predicts the cantered word inside of a certain context; the skip-gram is used to learn a word vector that predicts surrounding words based on the cantered word.
3.3. Deep Neural Networks (DNN) Models
The deep neural network models in this work comprise LSTM (long short-term memory), Conv1DLSTM (convolutional 1D long short-term memory), CNN (convolutional neural network), and BiLSTM_Pooling (bidirectional long short-term memory with pooling), which were employed to detect cyberbullying via social media LSTM-, Conv1DLSTM-, CNN-, and BiLSTM_Pooling-based attention mechanism models using the same tweeter dataset. The following sub-sections briefly describe the building model procedure of each DNN architecture used in cyberbullying detection.
3.3.1. Bidirectional Long Short-Term Memory and Gated Recurrent Unit Layer
Recurrent neural networks (RNN) are believed to be the most effective designs used in sequence modeling. As the internal structure of the RNN grants for time-based feeding, their method of operation is built to sequentially handle the inputs.
Figure 6 depicts a graph illustration of an RNN neuron with a cycle surrounding it at the point where the graph expanded, and the temporal sequence can be seen. Therefore, the input from prior steps fed into the current step.
The RNN neuron can utilize prior information at each time step and has two enhancements, namely the long-short term memory (LSTM) and the gated recurrent unit (GRU). The capacity of RNN to parse sequences of indefinite length is an important attribute. This state is critical to processing language sentences because in a natural language phrase, all words are required to understand the meaning. A sentence could be long, and as the method processes the words one by one, authors know that the first words are essential for the whole meaning, and they must be learned when the final words in the sequence are processed.
The weights learnt via separate neurons prevent typical DNNs from determining exact representations of the attributes related to cyberbullying tweets due to the complicated language structure. To tackle the aforementioned problem, the RNN used a repetition loop over timesteps to circumvent the restriction. A sequence vector {
x1,…,
xn} was handled by employing a recurrence of the form
, where f was the activation function, α was a set of parameters employed at each time step
t, and
was the input at timestep
t [
41,
42].
To construct the potential RNN model for this work, three kinds of re-current neurons, such as the simple RNN unit, the GRU unit (shown in
Figure 6), and the LSTM unit, were employed. The parameters defining the connections between the input and hidden layers, as well as the horizontal relationship between activations and the hidden layer to the output layer, were allocated for each timestep in a basic recurrent neuron. The forward pass of a primary recurrent neuron was represented as follows:
In the given context, the activation function is represented by the variable g, and “t” represents the current timestep. The input at timestep t is represented by , represents the bias term, and represents the cumulative weights with respect to timestep t for the activation output, which is denoted as . If necessary, this activation can be used to estimate the value at time t.
In addition, DNNs with simple RNN neurons indicated beneficial results in numerous applications. Thus, these neurons remained prone to vanishing gradients and struggled to learn long-term dependencies [
41]. To solve the gradient disappearance issue and enable the learning of long-term dependencies, the research community has suggested several altered recurrent neuron architectures to resolve the simple RNN neuron limitation, such as the GRU method suggested by [
43] and the LSTM method introduced by [
44]. The work in [
45] suggested a GRU that could show improved implementation for long-term relationship learning using input data. Additionally,
=
factor memory was employed in the GRU unit at each stage
t that offered a revised list of the entire samples handled by the GRU unit. Therefore, the GRU unit considered overwriting the
at each timestep
t. However, the regulation of factor memory overwriting was employed using the update gate
when the GRU unit superimposed the
value at each step “
t” with the candidate value
. GRU neuron functionality was represented using the following equations:
where
, and
correspond to the respective weights, and
,
, and
correspond to the subsequent bias terms for input
at timestep
t.
σ is the logistic regression function, and the activation value at timestep
t is symbolized by
. Apart from for the usage of GRU neurons, the employed RNN model built using GRU was similar to those of the simple RNNs models.
Figure 7 shows the LSTM-based model architecture used in cyberbullying detection.
As mentioned earlier, the authors in [
44] suggested the LSTM neuron with several enhancements to the design of the simple RNN unit that delivers a strong generalization of GRU. The following examples are some of the noticeable variances in LSTM and GRU cells:
There was no importance gate that was utilized in standard LSTM units for computation.
LSTM units employed two distinctive gates as substitutes for an update gate These two gates were output gate and update gate . The output gate determined the next hidden state value of the memory cell to process the LSTM unit activation outputs of additional concealed network components. The forget gate dealt with the extent of overwriting using to achieve , such as how much memory cell information could be ignored for memory cells to work properly.
As the memory cell content may not have been comparable to the activation at time t, the LSTM-based network differs from the GRU-based network.
Furthermore, the RNN approach-based LSTM was built using the same architecture as the GRU and basic RNN models. The sole distinction was that the LSTM units were located in recurrent layers [
46].
3.3.2. Convolutional Neural Network
CNNs are specifically designed to handle learning tasks that involve high-dimensional input data with complex spatial structures. They have been successfully applied to various types of data, including images [
47,
48], videos [
49], protein sequences [
50,
51], etc. CNNs aim to minimize the number of trainable parameters while effectively learning hierarchical filters that can accurately classify large volumes of incoming data. This goal is achieved by enabling sparse interactions between the input data and the trainable parameters through a technique called parameter sharing. This technique allows the network to develop a transformation process through which the learned filters are applied to different parts of the input, facilitating the extraction of meaningful features. Through this process, CNNs learn equivariant representations, also known as feature maps, of the complex and spatially structured input data. These feature maps capture important patterns and structures present in the data, enabling the network to effectively extract and utilize relevant information required to complete classification tasks [
52]. The hierarchical nature of the learned filters allowed the network to progressively capture more abstract and high-level features, leading to improved classification accuracy.
CNNs comprise various convolution layers. These layers are utilized in NLP applications to better understand the local distinctive feature. The study conducted convolution operations using the feature vector from the attention layer by adding a linear filter. For a provided post on social media in sentence
with distinct
words, firstly, the embedding vector of size
was generated, and a filter
of size
was repeatedly used as a sub-matrix to represent the input data. The results of this generated a feature map
as follows:
where
, and
is a sub-matrix of
from row
I to
j, as popular method is to input feature maps into a pooling or sub-sample layer to increase their dimension. The max-pooling is a regular pooling layer that choses the highly significant feature
b from the map as follows:
The output of the pooling layer is combined or concatenated to create a pooled feature vector, which serves as the input for the fully connected layer (FCL) (
Figure 8).
3.4. Attention Mechanism
Attention models were used to assign various weights to words differently contributing to the bullying tweets to be detected via the proposed DL models. A customary practice of assigning various weights to diverse offensive contents in an unlabeled tweet was to use a weighted combination (
Figure 9) of all hidden states
as follows:
where
and
are defined, as revealed in Equation (11), the element is a trainable parameter [
53].
3.5. Fully Connected Layer (FC)
In the FC layer, the feature vector representation, which obtained by concatenating the pooling layers’ weight vectors, was mapped to the input vector using a matrix of weights. This mapping process enabled the learning of the bullying patterns required to construct the cyberbullying model. The FC layer comprised multiple dense layers, non-linear activation functions, SoftMax, and a prediction function used to accurately classify instances as either bullying or non-bullying as follows:
where
and
are parameters learned in training,
is obtained from the pooled concatenated feature vector and
is the feature map received from the CNN layers. The output layer performs the correct classification using the
SoftMax function, as shown in
Figure 1. The cross-entropy loss was minimized to learn the model parameters, which was the training objective when using the Adam optimization algorithm [
54]. It was provided by
In this scenario, p represents the true distribution of a one-hot vector that represents characters in the messages posted onto social media. On the other hand, q represents the output of the SoftMax function. This calculation involves computing the negative logarithm probability of the true bullying tweet.
4. Results and Discussion
This section presents the experimental findings, along with commentary on their importance. The Keras library in the TensorFlow machine learning framework was used to implement the proposed cyberbullying model and the other baseline models. The objective was to minimize the complexity of the model by removing unnecessary elements, such as the number of hidden nodes, and, in the dense layer, by finding optimal hyperparameters with the hyperband method in Keras tuner [
55]. An input matrix of 35,873 words was constructed to divide the raw input data into tokens, which helped the cyberbullying model to understand the context and interpret the vital information in the text by analyzing the word sequence using tokenization in the Keras library. A pre-processing step was applied before tokenization by removing irregular text formats, text content loss, and incomplete and duplicate documents.
Words in the text that added no meaning to the sentence were removed; they would not affect text processing for the defined purpose and were removed from the vocabulary to reduce noise and the dimension of the feature set. The word2vec with CBOW concatenated formed the weights in the embedding layer. The 75-dimension of word2vec was trained using word vectors of 147 words and phrases of 35873 words derived from a tweeter cyberbullying dataset. In the proposed DL methods, each neuron spanned between 32 and 256 memory units, having a step size of 32, but the Conv1DLSTM, CNN, and LSTM provided an optimum value using the Adam optimization in the Keras tuner. The library was used to establish the optimum value while restricting the number of iterations to a low value. The maximum number of trials was set between five and 10, corresponding to two or three per execution trial, with a dropout rate of 0.4. In the convolutional layer, 480 filters with kernel sizes of four and six provided the optimum values, as shown in
Figure 1.
The size of the fully connected layer was 416, which initialized word embeddings using Glorot uniform initialization [
56] for the model to converge over a SoftMax classifier. The entire model was trained to cover 30 epochs using the Adam stochastic optimizer. A mini-batch size of 64 yielded better performance for tweet datasets when the class label had over 10 or 20 words per tweet; however, the learning rate of 0.0001 and the dropout of 0.55 varied from 0.3 to 0.7 and were constant for all training datasets, irrespective of the class label. The SoftMax function was employed in the output layer without the hashing trick.
Finally, the training process was accelerated using the dataset with a class label of less than 50 by setting the learning rate, embedding size, mini-batch size, and number of epochs to 0.001, 50, 32, and 20, respectively. A 10-fold cross-validation and early stopping through monitoring validation loss in max mode with the patience of five trials were applied to the training process to prevent overfitting problems.
4.1. Evaluation Metrics
In this study, the effectiveness of a proposed model was examined by employing various assessment metrics to evaluate its ability to distinguish between cyberbullying and non-cyberbullying content. Several deep learning-based attention mechanisms, such as LSTM, Conv1DLSTM, CNN, BiLSTM Pooling, and GRU, were developed in this study. Evaluation criteria play a crucial role in understanding the performances of competing models in the scientific community. The following evaluation criteria are commonly used to assess the performance of cyberbullying classifiers for social media networks: Accuracy in Equation (14) is the proportion of actual identified instances to all cases, and it is frequently used to assess cyberbullying prediction models. Precision in Equation (15) determines the percentage of relevant tweets among tweets that are both true positives and false positives for a given group. Recall in Equation (16) measures the proportion of relevant tweets retrieved from all relevant tweets. The F-measure (17) provides a means of combining recall and precision into a single metric that takes into account both aspects.
where fp stands for false positive,
fn for false negative,
tp for true positive, and tn for true negative. Therefore, (i) True positive is when a sample contains offensive text and the model correctly predicts its presence as offensive, it is considered a true positive. The model’s prediction aligns with the actual presence of offensive words. (ii) False positive (FP): If a sample does not contain offensive text, but the model incorrectly predicts it as offensive, it is considered a false positive. The model mistakenly identifies non-offensive content as offensive. (iii) False negative (FN): When a sample contains offensive words, but the model fails to detect them and predicts the absence of offensive content, it is a false negative. The model misses the presence of offensive words. (iv) True negative (TN): If a sample does not contain offensive words, and the model accurately predicts the absence of offensive content, it is a true negative. The model correctly identifies non-offensive content as such.
Figure 10 shows confusion matrices of Conv1DLSTM-based attention predictors models.
4.2. Performance Result of DL Models
The proposed work utilizes six0 DL detector models without theword2vec-based CBOW feature extractor and without the word2vec-based CBOW feature extractor. Firstly, we experimented with the six proposed DL detector models without implementing the word2vec-based CBOW feature extractor, and the DL-based models’ performance was recorded and tabulated, as demonstrated in
Table 2. The Conv1DLSTM model outperformed other predictors, having an accuracy of 0.8649, a precision of 0.8146, a recall of 0.8919, and an F1-score of 0.8515. Therefore, the GRU model obtained the lowest performance in detecting cyberbullying, having an accuracy of 0.7093, a precision of 0.7089, a recall of 0.7561, and an F1-score of 0.7317.
Figure 11 summarizes the accuracy, precision, recall, and F1-score of DL-based attention predictors without the feature extractor.
Additionally, the proposed work utilizes six DL detector models with word2vec-based CBOW concatenated formed weights in the embedding layer for feature extraction. These methods were set empirically to attain higher accuracy. For example, Conv1DLSTM had the best accuracy in our dataset, where the proposed model obtained a classification accuracy of 94.49% and an F1 score of 0.9518. Meanwhile, the CNN-based attention mechanism obtained the same accuracy in this classification problem (93.96%); on the other hand, the CNN-based attention mechanism achieved slightly lower performance in terms of F1-score (0.9025) than the LSTM-based attention mechanism, which had a value of (0.9218). Accuracies of 86.92%, 88.92%, and 89.90% were obtained for BiLSTM, BiLSTM_Pooling, and GRU-based attention, respectively. This result means that the Conv1DLSTM attention-based model performs better than other classifiers, as shown in
Table 3. Moreover, we observed that by employing the word2vec-based CBOW feature extractor, the DL-based models were significantly improved in terms of distinguishing between the cyberbullying tweets and the non-cyberbullying tweets.
Figure 12 summarizes the accuracy, precision, recall, and F1-score of each DL-based attention predictor with feature extractor.
The proposed work utilizes additional important evaluation methods,0 such as the receiver ROC and precision–recall curves. The ROC curve provides a valuable visual representation of the balance between the true positive and false positive rates. To assess the generalization capabilities of each deep learning (DL) model, separate test data collections were used during the training phase. This approach guarantees unbiased outcomes and allows the testing of the detectors’ ability to generalize.
The Area under the curve (AUC) is a measure used to assess how effectively a classifier can distinguish between different classes, and it is often employed as a summary of the ROC curve. A higher AUC indicates a better performance of the model in distinguishing between positive and negative samples [
57]. In essence, the ROC curve is a graphical representation of the trade-off between the recall of false positive rates and true positive rates [
57]. It provides valuable insights into evaluating the costs and benefits of the classifier. The false positive rate is computed by dividing the number of false positives by the total number of negative samples. This rate is considered a cost, since any subsequent action taken based on a false positive outcome would be wasted, as it is a misprediction. On the other hand, the true positive rate, which represents the proportion of positive cases accurately predicted, can be seen as a benefit, as it indicates successful predictions of the analyzed issue.
Figure 13a shows AUC curve for the classical Conv1DLSTM predictor, and
Figure 13b shows the TPR and FPR for different threshold values for the classification Conv1DLSTM model used to enable a better understanding of the classification performances of cyberbullying prediction models.
Figure 14 shows AUC curves for the second and third models depicted in our study.
Figure 14a shows the LSTM-based model, while
Figure 14b shows the AUC curve-based CNN predictor performance.
The proposed attention-based Conv1DLSTM classifier presents several significant advantages in terms of cyberbullying detection. Firstly, the integration of attention mechanisms allows the model to focus on the most relevant parts of the input text, facilitating a deeper understanding of the context in which offensive language or cyberbullying occurs. This contextual understanding is crucial to distinguishing between harmless content and harmful behavior in social media posts. Additionally, the Conv1DLSTM architecture proves advantages related to handling the variable length nature of social media text, enabling effective processing of tweets with differing word counts. The model’s feature extraction capability further enhances its cyberbullying detection accuracy by capturing spatial patterns and temporal dependencies within the text.
Moreover, the Conv1DLSTM’s ability to learn position-invariant features using the input text ensures the identification of offensive words or phrases, regardless of their specific location within the tweet. This feature is particularly relevant in the context of social media, where abusive content can be interspersed with non-offensive language. The incorporation of LSTM units within the Conv1DLSTM allows the model to capture long-term dependencies in the text, enabling a holistic consideration of the entire tweet’s context when making predictions of cyberbullying. The attention mechanism’s capacity to highlight offensive words or phrases within the text also aids in understanding the model’s decision-making process and enables the interpretability of the results. Furthermore, the superior performance of the attention-based Conv1DLSTM classifier to those of other deep learning methods, as demonstrated using benchmark experimental datasets and evaluation measures, underscores its effectiveness in accurately identifying instances of cyberbullying. Lastly, the attention-based Conv1DLSTM classifier showcases its potential to significantly advance cyberbullying detection methodologies and contribute to the creation of a safer online environment for social media users.
5. Conclusions and Future Work
Complex and multifaceted problems, such as cyberbullying, are challenging to track down using standard methods. This study investigated the use of deep learning and attention mechanisms to identify the best model to predict text-based cyberbullying tweets on social media. Conv1DLSTM achieved the best accuracy in our dataset, where the classification accuracy and F1 score were 94.49%. Meanwhile, LSTM- and CNN-based attention mechanisms obtained the same accuracy in this classification problem (93.96%), whereas the LSTM-based attention mechanism achieved a better performance in terms of F1-score measure (0.9218) than CNN, which scored a value of (0.9025). The attention-based Conv1DLSTM consistently produced more precise predictions. Therefore, it is possible to conclude that the proposed approach detects most offensive cyberbullying tweets. The suggested model includes the following limitations: (i) this work did not consider image-based cyberbullying detection, which means a post solely containing images was not part of this research, and (ii) the scope of this research was confined to text-based cyberbullying detection. As a result, the future scope of this research is up for debate, as it involves numerous subproblems. The proposed system achieved an accuracy rate of 94.49%, which could be enhanced by increasing the training sample size. Additionally, an ensemble or stacking model will be explored in future research to improve prediction accuracy.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}