3.1. Concept Lattice Modeling for Convolution Calculation
In the convolution calculation environment, the main dynamic characteristic is the sliding window that moves toward newly generated attributes. This results in both an increase and decrease in attributes. This section examines the mechanism of dynamic attribute changes in convolution calculation mode by formulating the attributes that slide into and out of the convolutional area. For simplicity, attributes that do not impact the concept lattice are filtered out and ignored in subsequent processes.
By analyzing the dynamic characteristics of convolution calculation, we can summarize the convolution calculation model into the following two change forms.
Form 1: Ordinary form. As shown in
Figure 2, the individual convolutional regions slide as a sliding window. In the ordinary form, the convolutional regions slide farther apart. The new convolutional region contains only new attributes, which do not intersect with the attributes of the previous convolutional region.
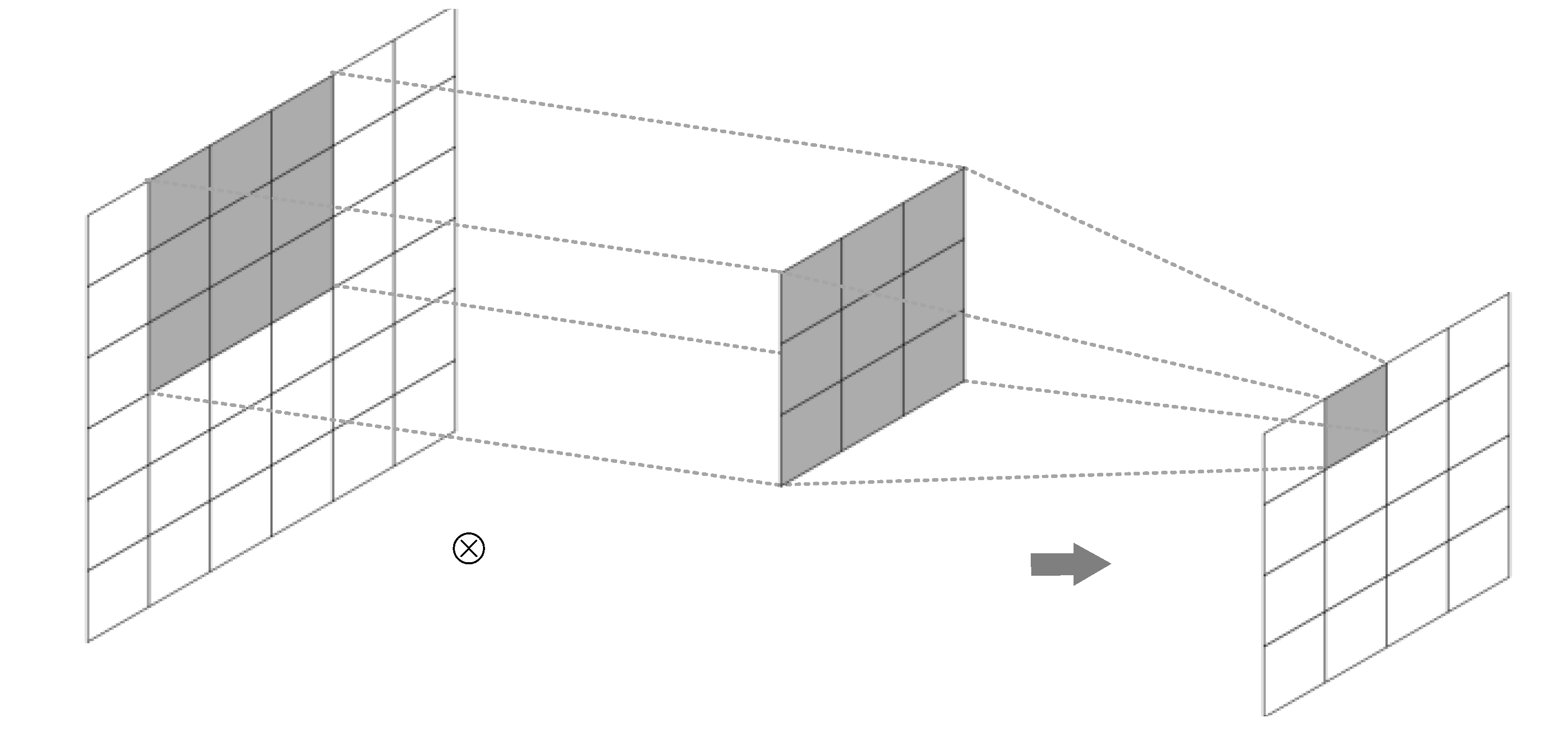
Form 2: Batch form. As shown in
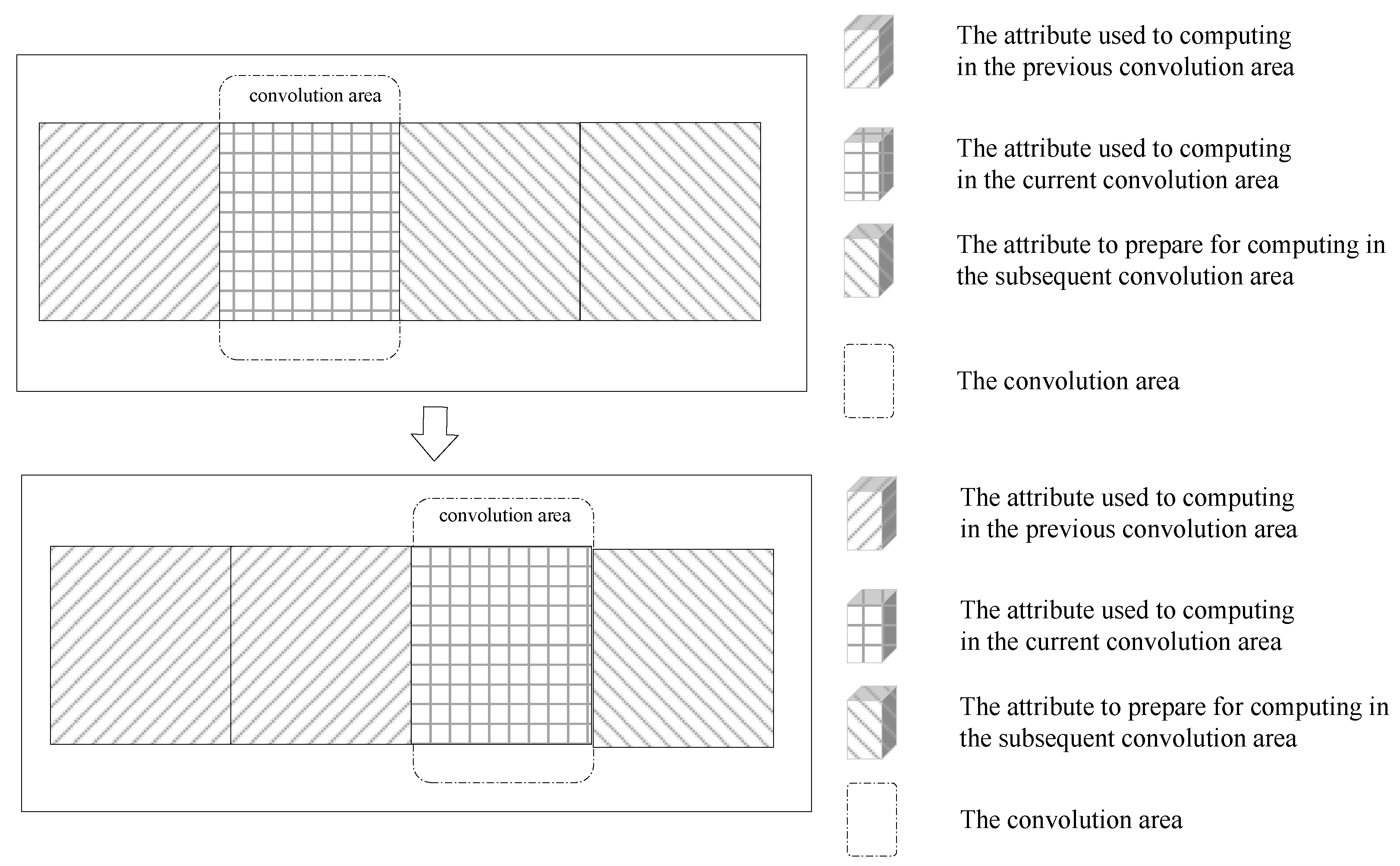
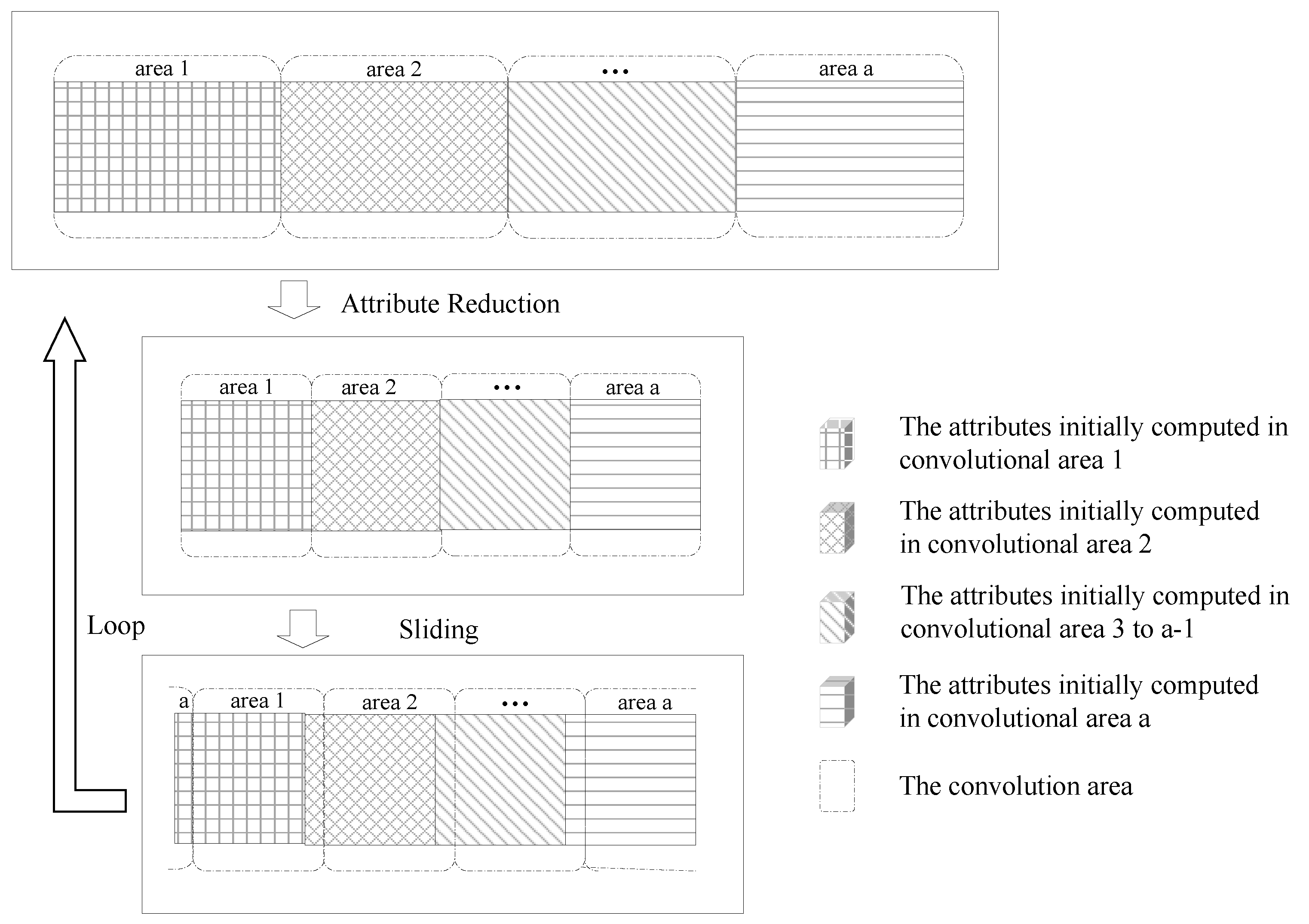
Figure 3, multiple convolutional regions slide a certain distance in the same direction in the form of a sliding window. In batch form, the attributes are divided into multiple convolutional regions, slide after the attribute reduction, and then the attribute reduction repeats. The current calculation window in the loop is based on the last convolutional region attribute reduction, sliding in a new batch of attributes and sliding out a small batch of old attributes.
In the ordinary form of convolution calculation, only new attributes are present in the convolution area, and the old attributes are absent. This is not beneficial for studying the update of the concept lattice when attributes are incremented and decremented simultaneously. In the batch form, each time in the convolution area, a new batch of attributes is added whereas a small batch of old attributes is reduced based on the attributes left in the last adjacent convolution area. This is consistent with the dynamic characteristics of attributes that are incremented and decremented simultaneously. In what follows, we focus on the batch morphology for modeling concept lattice attributes in convolution calculation mode. The pipeline is shown in
Figure 4.
In the batch form, there are five dynamic attribute changes in the convolution area, namely:
- (1)
The slide-in and slide-out attributes have the same attributes.
- (2)
The slide-in and slide-out attributes have the different attributes.
- (3)
The slide-in and slide-out attributes partially intersect.
- (4)
The slide-in attributes include the slide-out attributes.
- (5)
The slide-out attributes contain the slide-in attributes.
To facilitate the discussion, we formulated the following symbolic conventions:
At time t, the formal context is denoted as , the concept lattice as , and the reduction is denoted as . Next, in the convolution area at time t + 1, the formal context is denoted as ,, and the concept lattice is denoted as , and the reduction is denoted as .
At the time of
t + 1, the attribute of sliding into the convolution area is denoted as
, while the attribute of sliding out of the convolution area is denoted as
. In fact, the attribute of sliding in is
and the attribute of sliding out is
.
represents the set cardinality of
. In the classical attribute reduction algorithm, it is generally assumed that
and
. However, in the dynamic convolution calculation mode, we analyze its dynamic features and summarize the results in Equations (
1) and (
2).
- 1.
When , the attributes in the slide-in convolution area are the same as those in the slide-out convolution area. Suppose the order of attributes of the formal context are . Given that the convolutional area contains attributes , and the attributes that slide in and slide out are and , respectively, then , and . We can then reason that and , which finally yields .
- 2.
When , the attributes in the slide-in convolution area have four different representations from those in the slide-out convolution area.
- (a)
When , the attributes in the slide-in convolution area are completely different from those in the slide-out convolution area at this time. Suppose the order of attributes of the formal context are . Given that the convolutional area contains attributes , and the attributes that slide in and slide out are and , respectively, then , and . We can then reason that and , which finally yields .
- (b)
When , the attribute that slides out of the convolution area at this time contains the attribute that slides into the convolution area. Therefore, compared with the attributes in the convolution area at the time t, there is actually no slide-in attribute, but a slide-out attribute . Suppose the order of attributes in the formal context is . Given that the convolutional area contains attributes , and the attributes that slide in and slide out are and , respectively, then , and . We can then reason that and , which finally yields .
- (c)
When , the attribute sliding into the convolution area at this time contains the attribute sliding out of the convolution area. Therefore, compared with the attributes in the convolution area at time t, there are actually no sliding-out attributes, but rather sliding-in attributes . Suppose the order of attributes in the formal context is . Given that the convolutional area contains attributes , and the attributes that slide in and slide out are and , respectively, then , , . We can then reason that . means a property that is present in but not in , and which may have originally existed in . Therefore, , which leads to
- (d)
When , the attributes in the slide-in convolution area partially intersect with the attributes in the slide-out convolution area. Suppose the order of attributes of the formal context are . Given that the convolutional area contains attributes , and the attributes that slide in and slide out are and , respectively, then , and . We can then reason that . The reason for subtracting is to prevent from adding the attributes that already contains. Therefore, , which leads to
Further analysis is conducted to determine whether any of the attributes that slide into the convolutional area already exist or not in the convolutional area at time t. If some attributes already exist in the convolution area at time t, they do not affect the result when they slide into the convolution window. These partially overlapping attributes, represented as , should be removed.
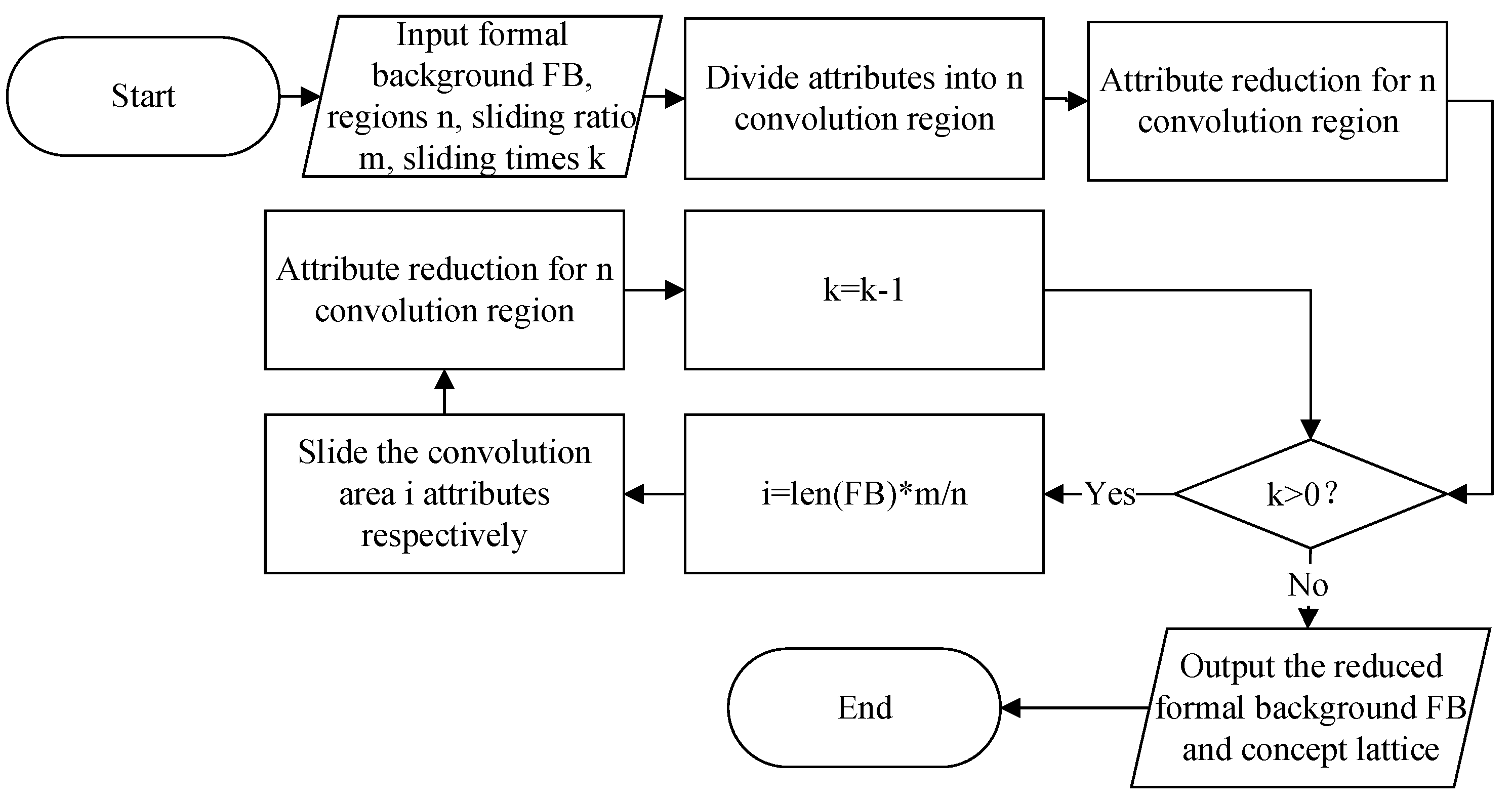
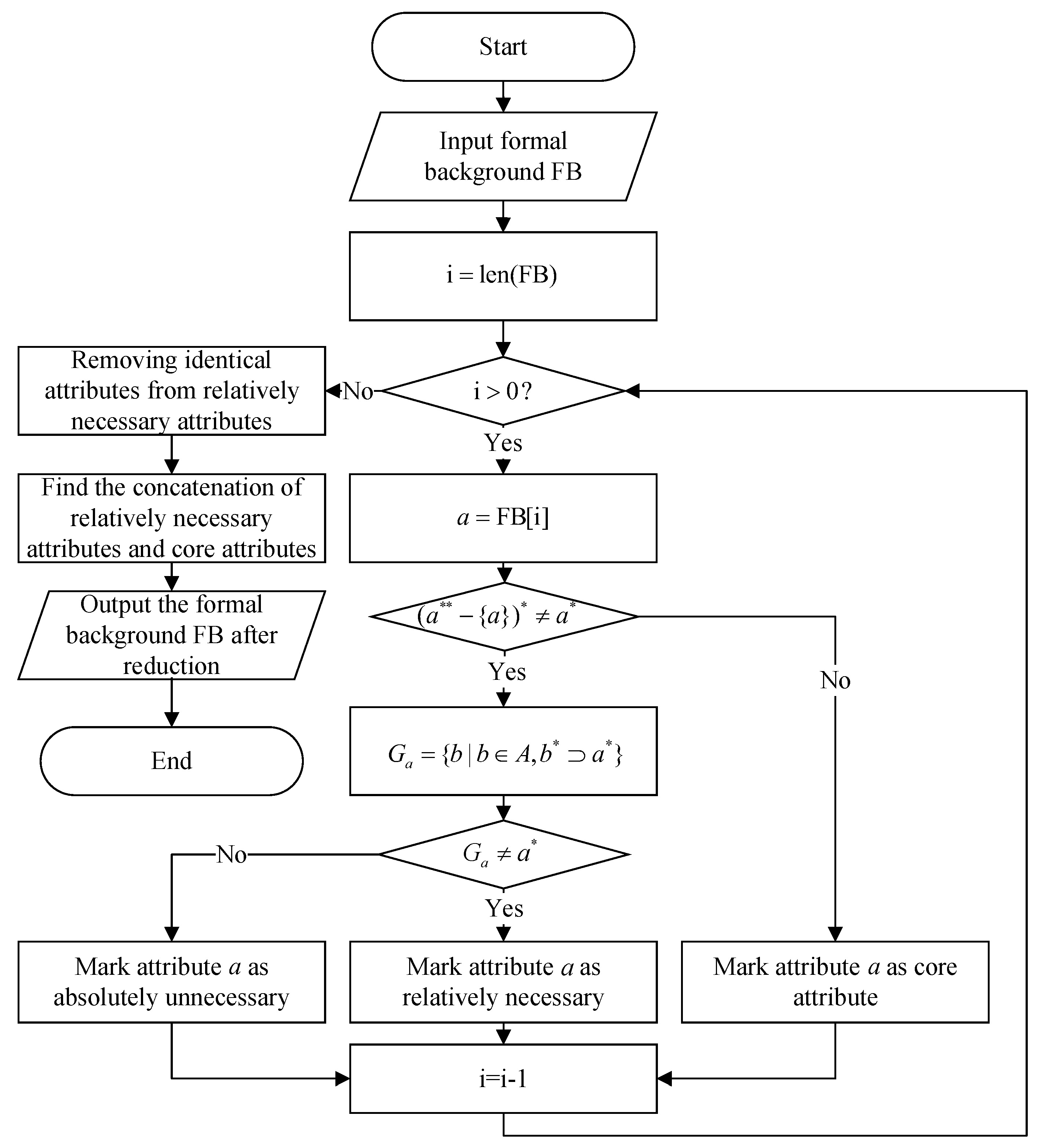
The concept lattice reduction based on the new difference matrix requires regenerating the concept and repeatedly performing merge operations at each slide. This results in excessive redundancy in the calculation process and disqualification for the convolution calculation model. The concept lattice reduction algorithm based on attribute features is a classical attribute reduction algorithm with excellent performance compared to other algorithms. Under the requirements
and
, we can compute core and relative necessary and absolute unnecessary attributes with a time complexity of
. The algorithm flow chart based on attribute characteristics is shown in
Figure 5.
3.2. Attribute Reduction Reasoning in Convolution Calculation
We investigate the influence of slide-in and slide-out attributes on the reduction set with the formal context and summarize the rules.
When adding an attribute, we compare and analyze its effect on the reduction result with the concept lattice. First, we identify the type of attribute, i.e., a core attribute, a relative necessary attribute, and an absolute unnecessary attribute. Then, we investigate how each type of attribute will be affected by adding that type of attribute to the concept lattice. Finally, we obtain Theorems 1–3.
Theorem 1. Let be the formal context, R the reduction of K, and a the attribute to be added. If , then the reduction remains the same as R.
Proof. Since , it is clear from Definition 6 that the added attribute a is unnecessary. Therefore, the added unnecessary attribute has no effect on the result of the reduction, which means the reduction remains unchanged. □
Theorem 2. Let be the formal context, R the reduction of K, and a the attribute to be added. If there exists an attribute such that , then the reduction R remains unchanged.
Proof. Since , , according to Definition 6, it is known that the added attribute a is a relative necessary attribute. Since , regardless of whether belongs to R, the added relative necessary attribute a has no effect on the reduction result, and thus the reduction remains unchanged. □
Theorem 3. Let be the formal context, R the reduction of K, and a the attribute to be added. If , and there is no such that , there exists , then the reduction is updated to . Conversely, if there exists , such that , there exists , then the reduction is updated to .
Proof. Since , it follows Definition 6 that the added attribute a is the core attribute.
If such that , there exists , the reduction result is updated to .
If there exists , satisfying , there exists , it means that the addition of attribute a causes the attribute d in the previous reduction results to become an unnecessary attribute. Therefore, d needs to be removed from R, so the reduction result is updated to . □
The process for deleting an attribute is analogous. First, we determine the attribute type, i.e., a core attribute, a relative necessary attribute, or an absolute unnecessary attribute. Then, we investigate whether the attribute is already present in the result. If it holds, we remove it from the result and reanalyze whether the attributes of associated attributes have changed after its deletion. Otherwise, we analyze whether its deletion will impact the reduction result. Based on these changes, we summarize Theorems 4–6.
Theorem 4. Let be the formal context, R the reduction of K, and attribute a the attribute to be deleted. If , then the reduction remains R.
Proof. Since , it is clear from Definition 6 that the deleted attribute a is unnecessary. Therefore, the deleted unnecessary attribute a has no effect on the reduction, i.e., the reduction R remains unchanged. □
Theorem 5. Let be the formal context, R the reduction of K, and attribute a the attribute to be deleted. If and there is no such that , or , then the reduction is updated to . Conversely, if and there exists , such that , or , then the reduction is updated to .
Proof. Since , it follows from Definition 6 that the deleted attribute a is the core attribute.
If and there is no , such that either or holds, then the attribute a degenerates from core to unnecessary, which means the reduction is updated to .
If there exists such that , it means that there is a new core attribute d generated after removing attribute a. Therefore, the reduction is updated to .
If there exists , such that , it means that d is originally an unnecessary attribute. After removing attribute a, , attribute d becomes the new core attribute, therefore it is necessary to add attribute d to the reduction result, i.e., the reduction is updated to . □
Theorem 6. Let be a formal context, R the reduction of K, and a the attribute to be deleted. If , there exists such that , then the reduction update is . Conversely, if , there exists such that , then the reduction remains the same still as R. Let R be the reduction of K, and a is the attribute to be deleted. If , there exists such that , then the reduction is updated to . Conversely, if , there exists such that , then the reduction remains the unchanged.
Proof. Since there exists , such that , it follows from Definition 6 that the deleted attribute a is relative necessary.
If , it means that the deletion of attribute a has effects on the existing reduction result. Since , then replaces a in R, generating a reduction with constant number, i.e., the reduction is updated to .
If , it means that deleting the attribute a will have no effects on the existing reduction result, and thus the reduction remains unchanged. □
3.4. Example of CLARA-DC
Table 1 shows the formal context
for “students and courses”, where the set of student objects
G consists of objects 1, 2, 3, 4, 5, 6; the set of attributes
M consists of seven attributes:
a,
b,
c,
d,
e,
f,
h. If
, then the student has the course and it is marked as 1 in the table; if
, i.e., the student does not have the course, then it is marked as 1 in the table; in the convolution area at time
t, it contains only attributes
a,
b,
c,
d,
e. However, as the convolution window slides, at time
t + 1, attributes
d,
e,
f,
h slide into the convolution area, while attributes
a,
c,
d,
e slide out of the convolution area.
According to Definition 1, we obtain the concept of the corresponding form of data in the convolutional area at time
t. For instance, Object 1 has attributes
b,
c, and
d, and only Object 1 contains all three attributes. According to Definition 1, this is shown in
Table 1.
We know that
is a formal concept; Object 2 has attributes
a,
d,
e, but Objects 2 and 6 also contain the attributes
a,
d,
e. Therefore,
is not a formal concept according to Definition 1. All formal concepts are thus determined according to Definition 1, as shown in
Table 2.
| Algorithm 1 CLARA-DC |
- Input:
At time t, is the formal context and reduction result is . At time t + 1, the attribute of sliding into the convolution area and the attribute of sliding out of the convolution area. - Output:
At the time of t + 1, the reduction result . - 1:
Step 1: According to Equations ( 1) and ( 2), the actual sliding-in and sliding-out attributes of t + 1 are computed, namely, and . - 2:
Step 2: Iterate over the actual slide-in attribute , denoting one of the attributes by a. According to Theorems 1–3, is updated. Define . - 3:
Step 2.1: If , then . - 4:
Step 2.2: If there exists , such that , then . - 5:
Step 2.3: If and there are no such that , then . - 6:
Step 2.4: If and there exists such that , then . - 7:
Step 2.5: Return to step 2 and take the next attribute of . Until all the attributes in are added to get the new reduction , go to step 3. - 8:
Step 3: Iterate over the actual slide-out attribute , and denote one of the attributes by a. According to Theorems 4–6, is updated. - 9:
Step 3.1: If , then . - 10:
Step 3.2: If and there is no such that or , then . - 11:
Step 3.3: If and there exists such that or , then . - 12:
Step 3.4: There exists such that . If , then . However, if , then . - 13:
Step 3.5: Return to Step 3 and take the next attribute of , until all the attributes in are deleted. - 14:
Step 4: Output .
|
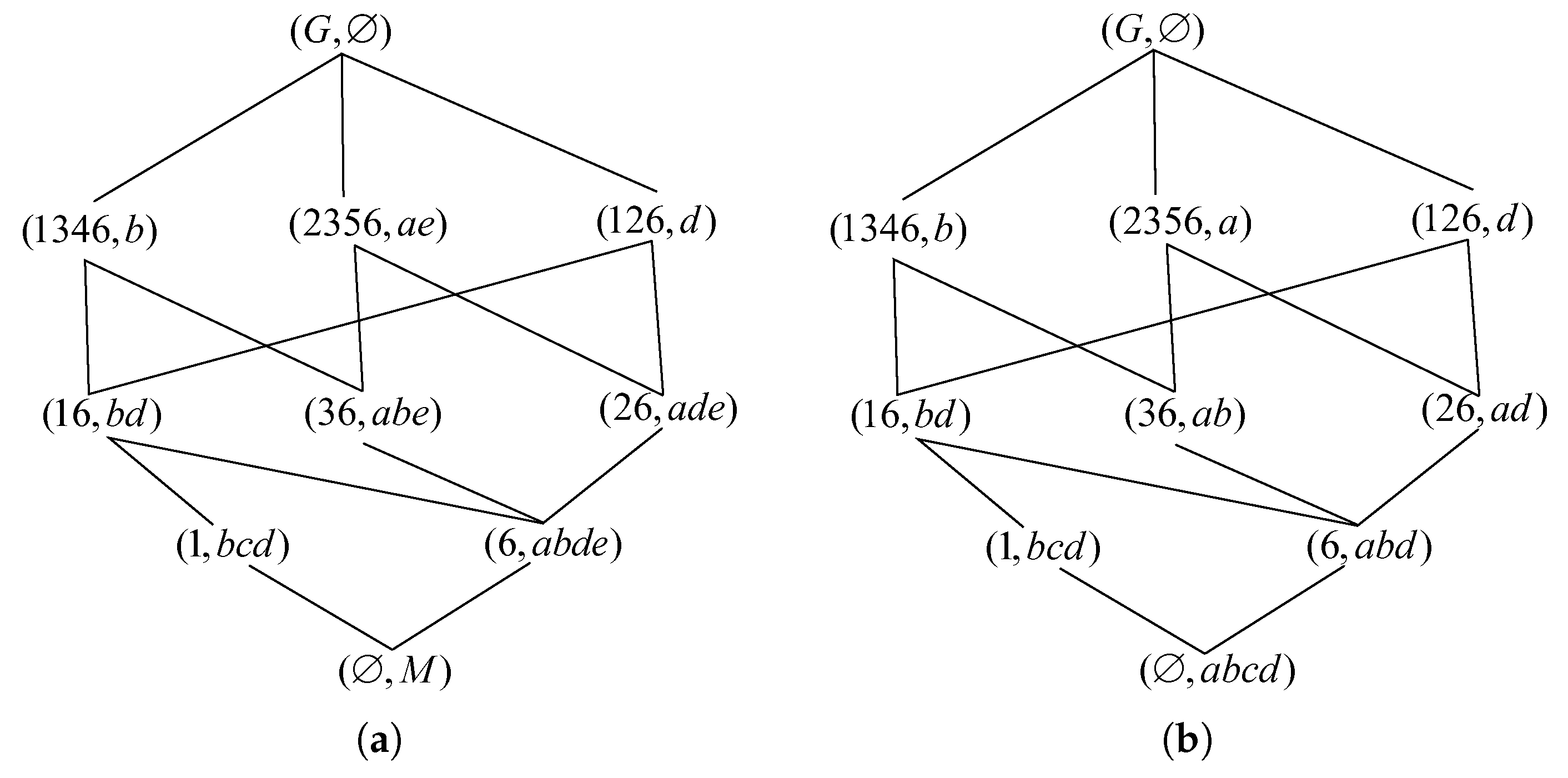
Formal concepts have certain partial order relations, and the concept lattice corresponding to the formal context at the time
t is shown in
Figure 6a. According to Definition 6, in the formal context, the core attributes are
b,
c,
d and the relative necessary attributes are
a,
e. One of the attribute reductions is
. The concept lattice corresponding to the time
t is shown in
Figure 6b.
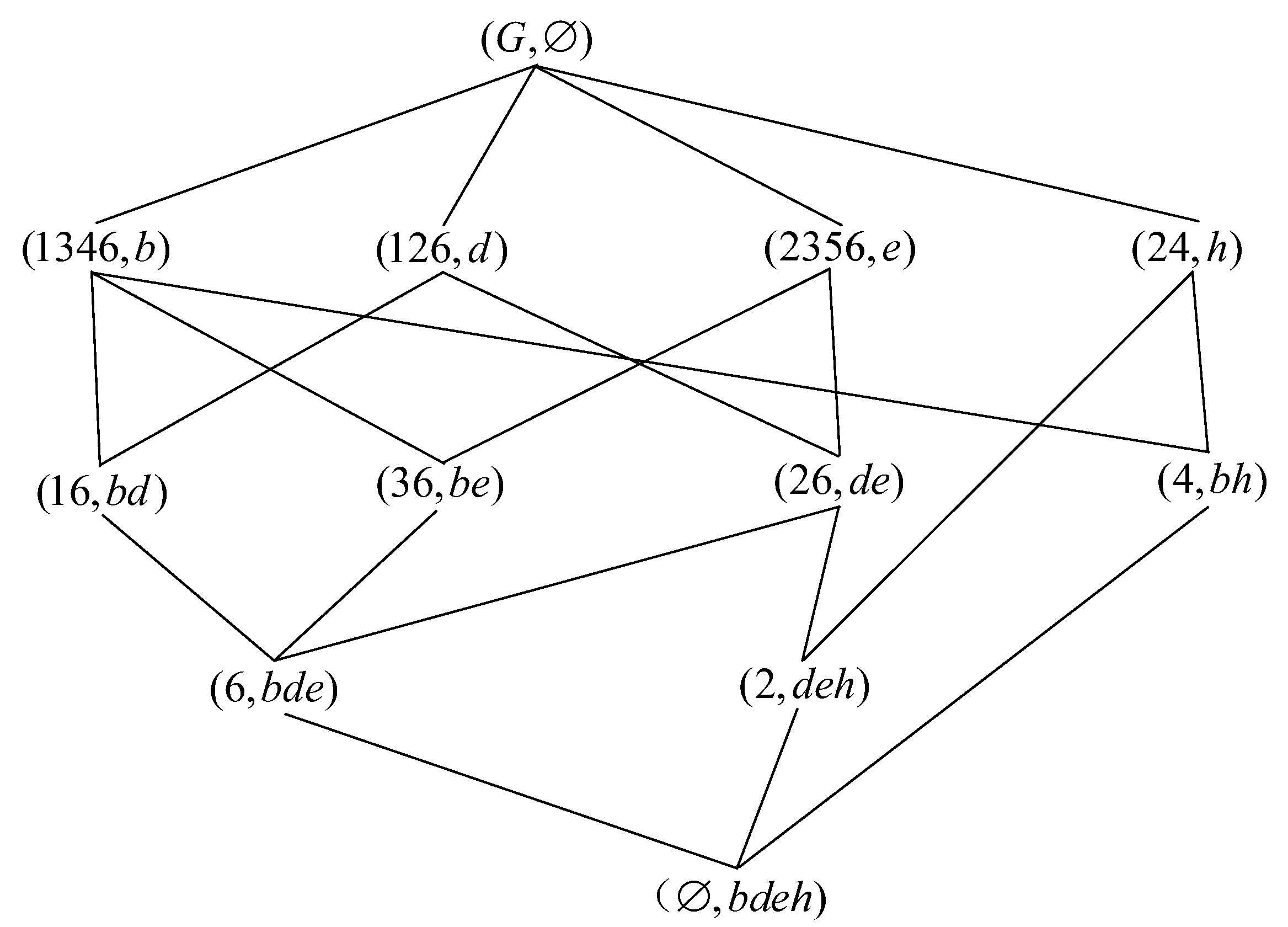
At time t + 1, the attributes sliding into the convolution area are d, e, f, h and the attributes sliding out of the convolution area are a, c, d, e. According to the CLARA-DC algorithm, the update reduction .
Compute the actual slide-in and slide-out attributes f, h and a, c at time t + 1 according to the Equations (1) and (2). The attributes f, h are related to the objects , .
The attribute f is an unnecessary absolute attribute since . Adding the attribute f has no effects on the reduction, and thus the result of the reduction remains unchanged, denoted as .
For attribute h, since , and there is no such that , there exists , and thus attribute h is a core attribute, .
For attribute a, since there is and there is to make , attribute a is thus a relative necessary attribute. Replacing e with a in means that the reduction is updated to .
For attribute c, since and there is no , such that or , and thus attribute c is an absolute unnecessary attribute, then the reduction is updated to
The output is
. The corresponding concept lattice is shown in
Figure 7.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







