
A Conceptual Graph-Based Method to Compute Information Content
 ,
,  , , and
, , and 
Abstract
:1. Introduction
- Edge-counting techniques [44] evaluate semantic similarity by computing the number of edges and nodes separating two concepts (nodes) within the semantic representation structures. We defined the technique preferably for taxonomic relationships (edges and nodes) in a semantic network.
- Information content-based approaches assess the similitude by applying a probabilistic model. It takes as input the concepts of an ontology and employs an information content function to determine their similarity values in the ontology [41,54,55]. The literature bases the information content computation on the distribution of tagged concepts in the corpora. Obtaining information content from concepts consists of structured and formal methods based on knowledge discovery [31,56,57,58].
- Feature-based methods assess similitude values employing the whole conventional and non-conventional features by a weighted sum of these items [19,59]. Thus, Sánchez et al. (2012) [4] designed a model of non-taxonomic and taxonomic relationships. Moreover, ref. [34,60] proposed to use interpretations of concepts retrieved from a thesaurus. Then, the edge-counting techniques improve since the evaluation considers a semantic reinforcement. In contrast, they do not consider non-taxonomic properties because they rarely appear in an ontology [61] and demand a fine tuning of the weighting variables to merge diverse semantic reinforcements [60]. Additionally, the edge-counting techniques examine the similarity concerning the shortest path about the number of taxonomic links, dividing two concepts into an ontology [42,44,62,63].
2. Related Work
2.1. Semantic Similarity
2.2. Information Content Computation
2.3. The WordNet Corpus
- Hierarchy of synonyms (Synset): WordNet’s central structure comprises sets of synonyms or “synsets”. Thus, each synset groups words that are interchangeable in a specific context and represent a concept or meaning. For example, the synset for “cat” would include words like “feline”, “pussy”, and “pet”.
- Relationships between Synsets: WordNet establishes sets of semantic relationships between synsets to represent the relationships between words and concepts. Some of the more common relationships include the following:
- –
- Hypernymy/hyponymy. It is a hierarchical relationship where a more general synset is a hyperonym of a more specific synset (hyponym). For example: “animal” (hypernym) is a hypernym of “cat” (hyponym).
- –
- Meronymy/holonymy. This relationship denotes the synsets’ part–whole or member relationship. For instance, “wheel” (meronym) is a part of “car” (holonym).
- –
- Antonymy. This relationship shows that two words have opposite meanings. For example: “good” is an antonym of “bad”.
- –
- Entailment. It indicates that one action implies another. For example: “kill” implies “injure”.
- –
- Similarity. It represents the similarity between the synsets, although they are not necessarily interchangeable. For instance, “cat” is similar to “tiger”.
- –
- Attribute. It describes the characteristics or attributes associated with a noun. For example, “high” is an attribute of “mountain”.
- –
- Cause. It indicates the cause–effect relationship between two events. For example: “rain” causes “humidity”.
- –
- Verb group. Match verbs that are used in similar contexts. For example, “to eat” and “to drink” belong to the group of feeding verbs.
- –
- Derivation. It shows the relationship between an adjective and a noun from which it is derived. For instance, “feline” is derived from “cat”.
- –
- Domain. It indicates the area of knowledge or context in which a synset is used. For example, “mathematics” is the domain of “algebra”.
- –
- Member holonymy. It indicates that an entity is a member of a larger group. For instance, “student” is a member of “class”.
- –
- Instance hyponymy. It shows that one synset is an instance of another. For example: “Wednesday” is an instance of “day of the week”.
- Word positions. Each word in a synset may be tagged as a part of speech (noun, verb, adjective, or adverb). This use makes it possible to distinguish different uses and meanings of a word.
- Definitions and examples. Synsets may be accompanied by definitions and usage examples that help clarify the meaning and context of the words.
- Synonymy and polysemy. WordNet addresses synonymy (several words with the same meaning) and polysemy (one word with multiple meanings) by providing separate synsets for each meaning and showing how they are related.
- Verb database. WordNet also includes a verb database that shows relationships between verbs and their arguments, such as “subject”, ”direct object”, and “indirect object”.
- Taxonomy. The structure of WordNet resembles a hierarchical taxonomy in which more general concepts (hyperonyms) are found at higher levels, and more specific concepts (hyperonyms) are found at lower levels.
2.4. The Wikipedia Corpus
- Articles. Wikipedia’s primary information unit is an article composed of free text following a detailed set of editorial and structural rules to ensure consistency and coherence. Each article covers a single concept, with a separate article for each. Article titles are concise sentences systematically arranged in a formal thesaurus. Wikipedia relies on collaborative efforts from its users to gather information.
- Referral pages are documents that contain nothing more than a direct link to a set of links. These pages redirect the request to the appropriate article page containing information about the object specified in the request. They lead to different phrases of an entity and thus model synonyms.
- Disambiguation pages collect links for various potential entities to which the original query could refer. These pages allow users to select the intended meaning. They serve as a mechanism for modeling homonymy.
- Hyperlinks are pointers to Wikipedia pages and serve as additional sources of synonyms, missed by the redirecting process. They eliminate ambiguity by coding polysemy. Articles related to other dictionaries and encyclopedias refer to them through resident hyperlinks, which are referred to as a cross-referenced element model.
- The category structure in Wikipedia is a semantic web organized into groups (categories). Articles are assigned to one or more groups that are grouped together and subsequently organized into a “category tree”. This “tree” is not designed as a formal hierarchy but works simultaneously with different classification methods. Additionally, the tree is implemented as an acyclic-directed graph. Thus, categories serve as only organizational nodes with minimal explanatory content.
3. Methods and Materials
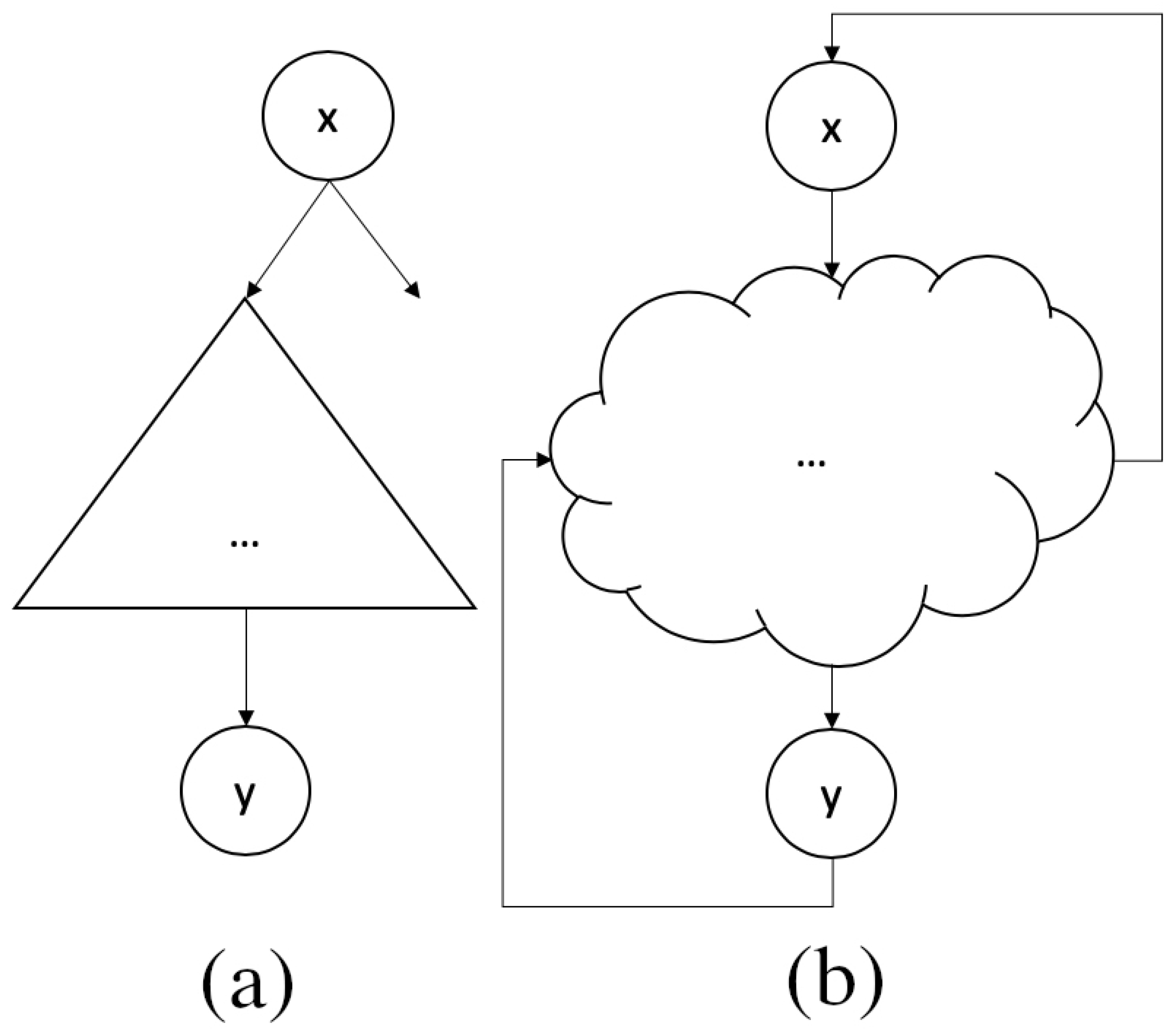
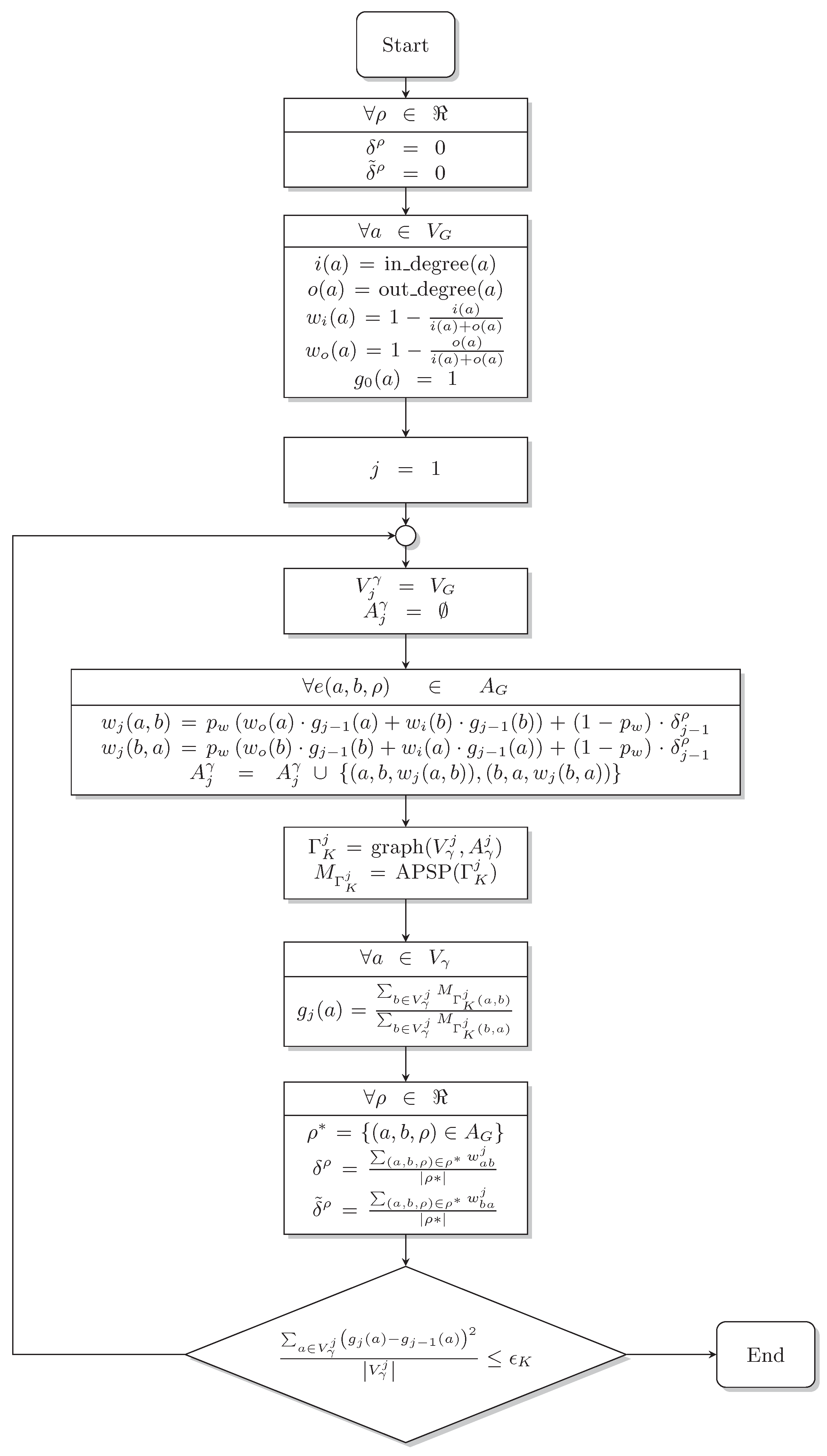
3.1. The DIS-C Algorithm for Information Content Computation
3.2. Generality
3.3. Corpus Used for the Testing: Wikipedia and WordNet
4. Results and Discussion

{kind=link}
{kind=link}
{kind=link}
| Word A | Word B | Miller and Charles (1991) [75] | WordNet Edges | Hirst et al. (1998) [97] | Jiang and Conrath (1997) [41] | Leacock and Chodorow (1998) [62] | Lin (1998) [54] | Resnik (1995) [43] | DIS-C(to) | DIS-C(from) | DIS-C(avg) | DIS-C(min) | DIS-C(max) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| asylum | madhouse | 3.61 | 29.00 | 4.00 | 0.66 | 2.77 | 0.98 | 11.28 | 1.22 | 1.64 | 1.43 | 1.22 | 1.64 |
| bird | cock | 3.05 | 29.00 | 6.00 | 0.16 | 2.77 | 0.69 | 5.98 | 0.63 | 0.33 | 0.48 | 0.33 | 0.63 |
| bird | crane | 2.97 | 27.00 | 5.00 | 0.14 | 2.08 | 0.66 | 5.98 | 1.51 | 1.35 | 1.43 | 1.35 | 1.51 |
| boy | lad | 3.76 | 29.00 | 5.00 | 0.23 | 2.77 | 0.82 | 7.77 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 |
| brother | monk | 2.82 | 29.00 | 4.00 | 0.29 | 2.77 | 0.90 | 10.49 | 0.33 | 0.63 | 0.48 | 0.33 | 0.63 |
| car | automobile | 3.92 | 30.00 | 16.00 | 1.00 | 3.47 | 1.00 | 6.34 | 1.26 | 0.59 | 0.92 | 0.59 | 1.26 |
| cemetery | woodland | 0.95 | 21.00 | 0.00 | 0.05 | 1.16 | 0.07 | 0.70 | 3.21 | 2.49 | 2.85 | 2.49 | 3.21 |
| chord | smile | 0.13 | 20.00 | 0.00 | 0.07 | 1.07 | 0.29 | 2.89 | 2.67 | 3.95 | 3.31 | 2.67 | 3.95 |
| coast | forest | 0.42 | 24.00 | 0.00 | 0.06 | 1.52 | 0.12 | 1.18 | 1.84 | 2.89 | 2.37 | 1.84 | 2.89 |
| coast | hill | 0.87 | 26.00 | 2.00 | 0.15 | 1.86 | 0.69 | 6.38 | 1.22 | 1.58 | 1.40 | 1.22 | 1.58 |
| coast | shore | 3.70 | 29.00 | 4.00 | 0.65 | 2.77 | 0.97 | 8.97 | 0.33 | 0.63 | 0.48 | 0.33 | 0.63 |
| crane | implement | 1.68 | 26.00 | 3.00 | 0.09 | 1.86 | 0.39 | 3.44 | 1.55 | 1.82 | 1.69 | 1.55 | 1.82 |
| food | fruit | 3.08 | 23.00 | 0.00 | 0.09 | 1.39 | 0.12 | 0.70 | 0.85 | 1.58 | 1.21 | 0.85 | 1.58 |
| food | rooster | 0.89 | 17.00 | 0.00 | 0.06 | 0.83 | 0.09 | 0.70 | 2.10 | 1.94 | 2.02 | 1.94 | 2.10 |
| forest | graveyard | 0.84 | 21.00 | 0.00 | 0.05 | 1.16 | 0.07 | 0.70 | 2.27 | 1.55 | 1.91 | 1.55 | 2.27 |
| furnace | stove | 3.11 | 23.00 | 5.00 | 0.06 | 1.39 | 0.24 | 2.43 | 1.26 | 0.62 | 0.94 | 0.62 | 1.26 |
| gem | jewel | 3.84 | 30.00 | 16.00 | 1.00 | 3.47 | 1.00 | 12.89 | 0.58 | 1.31 | 0.94 | 0.58 | 1.31 |
| glass | magician | 0.11 | 23.00 | 0.00 | 0.06 | 1.39 | 0.12 | 1.18 | 2.08 | 2.58 | 2.33 | 2.08 | 2.58 |
| journey | car | 1.16 | 17.00 | 0.00 | 0.08 | 0.83 | 0.00 | 0.00 | 1.24 | 1.59 | 1.42 | 1.24 | 1.59 |
| journey | voyage | 3.84 | 29.00 | 4.00 | 0.17 | 2.77 | 0.70 | 6.06 | 0.26 | 0.68 | 0.47 | 0.26 | 0.68 |
| lad | brother | 1.66 | 26.00 | 3.00 | 0.07 | 1.86 | 0.27 | 2.46 | 1.55 | 2.16 | 1.85 | 1.55 | 2.16 |
| lad | wizard | 0.42 | 26.00 | 3.00 | 0.07 | 1.86 | 0.27 | 2.46 | 1.55 | 2.23 | 1.89 | 1.55 | 2.23 |
| magician | wizard | 3.50 | 30.00 | 16.00 | 1.00 | 3.47 | 1.00 | 9.71 | 0.94 | 0.94 | 0.94 | 0.94 | 0.94 |
| midday | noon | 3.42 | 30.00 | 16.00 | 1.00 | 3.47 | 1.00 | 10.58 | 0.95 | 0.95 | 0.95 | 0.95 | 0.95 |
| monk | oracle | 1.10 | 23.00 | 0.00 | 0.06 | 1.39 | 0.23 | 2.46 | 2.78 | 2.49 | 2.63 | 2.49 | 2.78 |
| monk | slave | 0.55 | 26.00 | 3.00 | 0.06 | 1.86 | 0.25 | 2.46 | 1.90 | 1.47 | 1.69 | 1.47 | 1.90 |
| noon | string | 0.08 | 19.00 | 0.00 | 0.05 | 0.98 | 0.00 | 0.00 | 2.49 | 2.86 | 2.68 | 2.49 | 2.86 |
| rooster | voyage | 0.08 | 11.00 | 0.00 | 0.04 | 0.47 | 0.00 | 0.00 | 2.53 | 3.10 | 2.81 | 2.53 | 3.10 |
| shore | woodland | 0.63 | 25.00 | 2.00 | 0.06 | 1.67 | 0.12 | 1.18 | 1.92 | 1.92 | 1.92 | 1.92 | 1.92 |
| tool | implement | 2.95 | 29.00 | 4.00 | 0.55 | 2.77 | 0.94 | 6.00 | 0.68 | 0.26 | 0.47 | 0.26 | 0.68 |
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Harispe, S.; Sánchez, D.; Ranwez, S.; Janaqi, S.; Montmain, J. A framework for unifying ontology-based semantic similarity measures: A study in the biomedical domain. J. Biomed. Inform. 2014, 48, 38–53. [Google Scholar] [CrossRef] [PubMed]
- Goldstone, R.L. Similarity, interactive activation, and mapping. J. Exp. Psychol. Learn. Mem. Cogn. 1994, 20, 3. [Google Scholar] [CrossRef]
- Sánchez, D.; Batet, M. A semantic similarity method based on information content exploiting multiple ontologies. Expert Syst. Appl. 2013, 40, 1393–1399. [Google Scholar] [CrossRef]
- Sánchez, D.; Solé-Ribalta, A.; Batet, M.; Serratosa, F. Enabling semantic similarity estimation across multiple ontologies: An evaluation in the biomedical domain. J. Biomed. Inform. 2012, 45, 141–155. [Google Scholar] [CrossRef] [PubMed]
- Rodríguez, M.; Egenhofer, M. Comparing geospatial entity classes: An asymmetric and context-dependent similarity measure. Int. J. Geogr. Inf. Sci. 2004, 18, 229–256. [Google Scholar] [CrossRef]
- Schwering, A.; Raubal, M. Measuring semantic similarity between geospatial conceptual regions. In GeoSpatial Semantics; Springer: Berlin/Heidelberg, Germany, 2005; pp. 90–106. [Google Scholar]
- Wang, H.; Wang, W.; Yang, J.; Yu, P.S. Clustering by pattern similarity in large data sets. In Proceedings of the 2002 ACM SIGMOD International Conference on Management of Data, Madison, WI, USA, 4–6 June 2002; ACM: New York, NY, USA, 2002; pp. 394–405. [Google Scholar]
- Al-Mubaid, H.; Nguyen, H. A cluster-based approach for semantic similarity in the biomedical domain. In Proceedings of the Engineering in Medicine and Biology Society, 2006, EMBS’06, 28th Annual International Conference of the IEEE, New York, NY, USA, 30 August–3 September 2006; pp. 2713–2717. [Google Scholar]
- Al-Mubaid, H.; Nguyen, H. Measuring semantic similarity between biomedical concepts within multiple ontologies. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2009, 39, 389–398. [Google Scholar] [CrossRef]
- Budan, I.; Graeme, H. Evaluating WordNet-Based Measures of Semantic Distance. Comutational Linguist. 2006, 32, 13–47. [Google Scholar]
- Hliaoutakis, A.; Varelas, G.; Voutsakis, E.; Petrakis, E.G.; Milios, E. Information retrieval by semantic similarity. Int. J. Semant. Web Inf. Syst. (IJSWIS) 2006, 2, 55–73. [Google Scholar] [CrossRef]
- Kumar, S.; Baliyan, N.; Sukalikar, S. Ontology Cohesion and Coupling Metrics. Int. J. Semant. Web Inf. Syst. (IJSWIS) 2017, 13, 1–26. [Google Scholar] [CrossRef]
- Pirrò, G.; Ruffolo, M.; Talia, D. SECCO: On building semantic links in Peer-to-Peer networks. In Journal on Data Semantics XII; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–36. [Google Scholar]
- Meilicke, C.; Stuckenschmidt, H.; Tamilin, A. Repairing ontology mappings. In Proceedings of the AAAI, Vancouver, BC, Canada, 22–26 July 2007; Volume 3, p. 6. [Google Scholar]
- Tapeh, A.G.; Rahgozar, M. A knowledge-based question answering system for B2C eCommerce. Knowl.-Based Syst. 2008, 21, 946–950. [Google Scholar] [CrossRef]
- Patwardhan, S.; Banerjee, S.; Pedersen, T. Using measures of semantic relatedness for word sense disambiguation. In Computational Linguistics and Intelligent Text Processing; Springer: Berlin/Heidelberg, Germany, 2003; pp. 241–257. [Google Scholar]
- Sinha, R.; Mihalcea, R. Unsupervised graph-basedword sense disambiguation using measures of word semantic similarity. In Proceedings of the International Conference on Semantic Computing (ICSC 2007), Irvine, CA, USA, 17–19 September 2007; pp. 363–369. [Google Scholar]
- Blanco-Fernández, Y.; Pazos-Arias, J.J.; Gil-Solla, A.; Ramos-Cabrer, M.; López-Nores, M.; García-Duque, J.; Fernández-Vilas, A.; Díaz-Redondo, R.P.; Bermejo-Muñoz, J. A flexible semantic inference methodology to reason about user preferences in knowledge-based recommender systems. Knowl.-Based Syst. 2008, 21, 305–320. [Google Scholar] [CrossRef]
- Likavec, S.; Osborne, F.; Cena, F. Property-based semantic similarity and relatedness for improving recommendation accuracy and diversity. Int. J. Semant. Web Inf. Syst. (IJSWIS) 2015, 11, 1–40. [Google Scholar] [CrossRef]
- Atkinson, J.; Ferreira, A.; Aravena, E. Discovering implicit intention-level knowledge from natural-language texts. Knowl.-Based Syst. 2009, 22, 502–508. [Google Scholar] [CrossRef]
- Sánchez, D.; Isern, D. Automatic extraction of acronym definitions from the Web. Appl. Intell. 2011, 34, 311–327. [Google Scholar] [CrossRef]
- Stevenson, M.; Greenwood, M.A. A semantic approach to IE pattern induction. In Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics, Ann Arbor, MI, USA, 25–30 June 2005; pp. 379–386. [Google Scholar]
- Rissland, E.L. AI and similarity. IEEE Intell. Syst. 2006, 21, 39–49. [Google Scholar] [CrossRef]
- Fonseca, F. Ontology-Based Geospatial Data Integration. In Encyclopedia of GIS; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008; pp. 812–815. [Google Scholar]
- Kastrati, Z.; Imran, A.S.; Yildirim-Yayilgan, S. SEMCON: A semantic and contextual objective metric for enriching domain ontology concepts. Int. J. Semant. Web Inf. Syst. (IJSWIS) 2016, 12, 1–24. [Google Scholar] [CrossRef]
- Sánchez, D. A methodology to learn ontological attributes from the Web. Data Knowl. Eng. 2010, 69, 573–597. [Google Scholar] [CrossRef]
- Song, W.; Li, C.H.; Park, S.C. Genetic algorithm for text clustering using ontology and evaluating the validity of various semantic similarity measures. Expert Syst. Appl. 2009, 36, 9095–9104. [Google Scholar] [CrossRef]
- Batet, M.; Sánchez, D.; Valls, A. An ontology-based measure to compute semantic similarity in biomedicine. J. Biomed. Inform. 2011, 44, 118–125. [Google Scholar] [CrossRef]
- Couto, F.M.; Silva, M.J.; Coutinho, P.M. Measuring semantic similarity between Gene Ontology terms. Data Knowl. Eng. 2007, 61, 137–152. [Google Scholar] [CrossRef]
- Pedersen, T.; Pakhomov, S.V.; Patwardhan, S.; Chute, C.G. Measures of semantic similarity and relatedness in the biomedical domain. J. Biomed. Inform. 2007, 40, 288–299. [Google Scholar] [CrossRef] [PubMed]
- Sánchez, D.; Batet, M. Semantic similarity estimation in the biomedical domain: An ontology-based information-theoretic perspective. J. Biomed. Inform. 2011, 44, 749–759. [Google Scholar] [CrossRef] [PubMed]
- Moreno, M. Similitud Semantica Entre Sistemas de Objetos Geograficos Aplicada a la Generalizacion de Datos Geo-Espaciales. Ph.D. Thesis, Instituto Politécnico Nacional, Ciudad de México, Mexico, 2007. [Google Scholar]
- Nedas, K.; Egenhofer, M. Spatial-Scene Similarity Queries. Trans. GIS 2008, 12, 661–681. [Google Scholar] [CrossRef]
- Rodríguez, M.A.; Egenhofer, M.J. Determining semantic similarity among entity classes from different ontologies. Knowl. Data Eng. IEEE Trans. 2003, 15, 442–456. [Google Scholar] [CrossRef]
- Sheeren, D.; Mustière, S.; Zucker, J.D. A data mining approach for assessing consistency between multiple representations in spatial databases. Int. J. Geogr. Inf. Sci. 2009, 23, 961–992. [Google Scholar] [CrossRef]
- Goldstone, R.L.; Medin, D.L.; Halberstadt, J. Similarity in context. Mem. Cogn. 1997, 25, 237–255. [Google Scholar] [CrossRef]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Tversky, A.; Gati, I. Studies of similarity. Cogn. Categ. 1978, 1, 79–98. [Google Scholar]
- Chu, H.C.; Chen, M.Y.; Chen, Y.M. A semantic-based approach to content abstraction and annotation for content management. Expert Syst. Appl. 2009, 36, 2360–2376. [Google Scholar] [CrossRef]
- Sánchez, D.; Isern, D.; Millan, M. Content annotation for the semantic web: An automatic web-based approach. Knowl. Inf. Syst. 2011, 27, 393–418. [Google Scholar] [CrossRef]
- Jiang, J.J.; Conrath, D.W. Semantic similarity based on corpus statistics and lexical taxonomy. In Proceedings of the International Conference on Research in Computational Linguistics, Madrid, Spain, 7–12 July 1997; pp. 19–33. [Google Scholar]
- Wu, Z.; Palmer, M. Verbs semantics and lexical selection. In Proceedings of the 32nd Annual Meeting on Association for Computational Linguistics, Las Cruces, New Mexico, 27–30 June 1994; pp. 133–138. [Google Scholar]
- Resnik, P. Using information content to evaluate semantic similarity in a taxonomy. arXiv 1995, arXiv:cmp-lg/9511007. [Google Scholar]
- Rada, R.; Mili, H.; Bicknell, E.; Blettner, M. Development and application of a metric on semantic nets. Syst. Man Cybern. IEEE Trans. 1989, 19, 17–30. [Google Scholar] [CrossRef]
- Jiang, Y.; Bai, W.; Zhang, X.; Hu, J. Wikipedia-based information content and semantic similarity computation. Inf. Process. Manag. 2017, 53, 248–265. [Google Scholar] [CrossRef]
- Mathur, S.; Dinakarpandian, D. Finding disease similarity based on implicit semantic similarity. J. Biomed. Inform. 2012, 45, 363–371. [Google Scholar] [CrossRef] [PubMed]
- Batet, M.; Sánchez, D.; Valls, A.; Gibert, K. Semantic similarity estimation from multiple ontologies. Appl. Intell. 2013, 38, 29–44. [Google Scholar] [CrossRef]
- Ahsaee, M.G.; Naghibzadeh, M.; Naeini, S.E.Y. Semantic similarity assessment of words using weighted WordNet. Int. J. Mach. Learn. Cybern. 2014, 5, 479–490. [Google Scholar] [CrossRef]
- Liu, H.; Bao, H.; Xu, D. Concept vector for semantic similarity and relatedness based on WordNet structure. J. Syst. Softw. 2012, 85, 370–381. [Google Scholar] [CrossRef]
- Maguitman, A.G.; Menczer, F.; Erdinc, F.; Roinestad, H.; Vespignani, A. Algorithmic computation and approximation of semantic similarity. World Wide Web 2006, 9, 431–456. [Google Scholar] [CrossRef]
- Medelyan, O.; Milne, D.; Legg, C.; Witten, I.H. Mining meaning from Wikipedia. Int. J. Hum.Comput. Stud. 2009, 67, 716–754. [Google Scholar] [CrossRef]
- Pirró, G. A semantic similarity metric combining features and intrinsic information content. Data Knowl. Eng. 2009, 68, 1289–1308. [Google Scholar] [CrossRef]
- Meng, L.; Huang, R.; Gu, J. A review of semantic similarity measures in wordnet. Int. J. Hybrid Inf. Technol. 2013, 6, 1–12. [Google Scholar]
- Lin, D. An information-theoretic definition of similarity. In Proceedings of the ICML, Madison, WI, USA, 24–27 July 1998; Volume 98, pp. 296–304. [Google Scholar]
- Resnik, P. Semantic similarity in a taxonomy: An information-based measure and its application to problems of ambiguity in natural language. J. Artif. Intell. Res. (JAIR) 1999, 11, 95–130. [Google Scholar] [CrossRef]
- Sánchez, D.; Batet, M.; Isern, D. Ontology-based information content computation. Knowl. Based Syst. 2011, 24, 297–303. [Google Scholar] [CrossRef]
- Seco, N.; Veale, T.; Hayes, J. An intrinsic information content metric for semantic similarity in WordNet. In Proceedings of the ECAI, Valencia, Spain, 22–27 August 2004; Volume 16, p. 1089. [Google Scholar]
- Zhou, Z.; Wang, Y.; Gu, J. A new model of information content for semantic similarity in WordNet. In Proceedings of the FGCNS’08, Second International Conference on Future Generation Communication and Networking Symposia, Washington, DC, USA, 13–15 December 2008; Volume 3, pp. 85–89. [Google Scholar]
- Sánchez, D.; Batet, M.; Isern, D.; Valls, A. Ontology-based semantic similarity: A new feature-based approach. Expert Syst. Appl. 2012, 39, 7718–7728. [Google Scholar] [CrossRef]
- Petrakis, E.G.; Varelas, G.; Hliaoutakis, A.; Raftopoulou, P. X-similarity: Computing semantic similarity between concepts from different ontologies. JDIM 2006, 4, 233–237. [Google Scholar]
- Ding, L.; Finin, T.; Joshi, A.; Pan, R.; Cost, R.S.; Peng, Y.; Reddivari, P.; Doshi, V.; Sachs, J. Swoogle: A search and metadata engine for the semantic web. In Proceedings of the Thirteenth ACM International Conference on Information and Knowledge Management, Washington, DC, USA, 8–13 November 2004; ACM: New York, NY, USA, 2004; pp. 652–659. [Google Scholar]
- Leacock, C.; Chodorow, M. Combining Local Context and WordNet Similarity for Word Sense Identification; MIT Press: Cambridge, MA, USA, 1998; Volume 49, pp. 265–283. [Google Scholar]
- Li, Y.; Bandar, Z.; McLean, D. An approach for measuring semantic similarity between words using multiple information sources. Knowl. Data Eng. IEEE Trans. 2003, 15, 871–882. [Google Scholar]
- Schickel-Zuber, V.; Faltings, B. OSS: A Semantic Similarity Function based on Hierarchical Ontologies. In Proceedings of the IJCAI, Hyderabad, India, 6–12 January 2007; Volume 7, pp. 551–556. [Google Scholar]
- Schwering, A. Hybrid model for semantic similarity measurement. In On the Move to Meaningful Internet Systems 2005: CoopIS, DOA, and ODBASE; Springer: Berlin/Heidelberg, Germany, 2005; pp. 1449–1465. [Google Scholar]
- Martinez-Gil, J.; Aldana-Montes, J.F. Semantic similarity measurement using historical google search patterns. Inf. Syst. Front. 2013, 15, 399–410. [Google Scholar] [CrossRef]
- Retzer, S.; Yoong, P.; Hooper, V. Inter-organisational knowledge transfer in social networks: A definition of intermediate ties. Inf. Syst. Front. 2012, 14, 343–361. [Google Scholar] [CrossRef]
- Quintero, R.; Torres-Ruiz, M.; Menchaca-Mendez, R.; Moreno-Armendariz, M.A.; Guzman, G.; Moreno-Ibarra, M. DIS-C: Conceptual distance in ontologies, a graph-based approach. Knowl. Inf. Syst. 2019, 59, 33–65. [Google Scholar] [CrossRef]
- Torres, M.; Quintero, R.; Moreno-Ibarra, M.; Menchaca-Mendez, R.; Guzman, G. GEONTO-MET: An Approach to Conceptualizing the Geographic Domain. Int. J. Geogr. Inf. Sci. 2011, 25, 1633–1657. [Google Scholar] [CrossRef]
- Zadeh, P.D.H.; Reformat, M.Z. Assessment of semantic similarity of concepts defined in ontology. Inf. Sci. 2013, 250, 21–39. [Google Scholar] [CrossRef]
- Albertoni, R.; De Martino, M. Semantic similarity of ontology instances tailored on the application context. In On the Move to Meaningful Internet Systems 2006: CoopIS, DOA, GADA, and ODBASE; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1020–1038. [Google Scholar]
- Li, Y.; McLean, D.; Bandar, Z.; O’shea, J.D.; Crockett, K. Sentence similarity based on semantic nets and corpus statistics. Knowl. Data Eng. IEEE Trans. 2006, 18, 1138–1150. [Google Scholar] [CrossRef]
- Cilibrasi, R.L.; Vitanyi, P. The google similarity distance. Knowl. Data Eng. IEEE Trans. 2007, 19, 370–383. [Google Scholar] [CrossRef]
- Bollegala, D.; Matsuo, Y.; Ishizuka, M. Measuring semantic similarity between words using web search engines. In Proceedings of the 16th International Conference on World Wide Web, WWW 2007, Banff, AB, Canada, 8–12 May 2007; Volume 7, pp. 757–766. [Google Scholar]
- Miller, G.A.; Charles, W.G. Contextual correlates of semantic similarity. Lang. Cogn. Process. 1991, 6, 1–28. [Google Scholar] [CrossRef]
- Sánchez, D.; Moreno, A.; Del Vasto-Terrientes, L. Learning relation axioms from text: An automatic Web-based approach. Expert Syst. Appl. 2012, 39, 5792–5805. [Google Scholar] [CrossRef]
- Saruladha, K.; Aghila, G.; Bhuvaneswary, A. Information content based semantic similarity for cross ontological concepts. Int. J. Eng. Sci. Technol. 2011, 3, 45–62. [Google Scholar]
- Formica, A. Ontology-based concept similarity in formal concept analysis. Inf. Sci. 2006, 176, 2624–2641. [Google Scholar] [CrossRef]
- Albacete, E.; Calle-Gómez, J.; Castro, E.; Cuadra, D. Semantic Similarity Measures Applied to an Ontology for Human-Like Interaction. J. Artif. Intell. Res. (JAIR) 2012, 44, 397–421. [Google Scholar] [CrossRef]
- Goldstone, R. An efficient method for obtaining similarity data. Behav. Res. Methods Instruments Comput. 1994, 26, 381–386. [Google Scholar] [CrossRef]
- Niles, I.; Pease, A. Towards a standard upper ontology. In Proceedings of the International Conference on Formal Ontology in Information Systems-Volume, Ogunquit, ME, USA, 17–19 October 2001; ACM: New York, NY, USA, 2001; pp. 2–9. [Google Scholar]
- Fellbaum, C. WordNet: An Electronic Database; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Jain, P.; Yeh, P.Z.; Verma, K.; Vasquez, R.G.; Damova, M.; Hitzler, P.; Sheth, A.P. Contextual ontology alignment of lod with an upper ontology: A case study with proton. In The Semantic Web: Research and Applications; Springer: Berlin/Heidelberg, Germany, 2011; pp. 80–92. [Google Scholar]
- Héja, G.; Surján, G.; Varga, P. Ontological analysis of SNOMED CT. BMC Med. Inform. Decis. Mak. 2008, 8, S8. [Google Scholar] [CrossRef] [PubMed]
- Gene Ontology Consortium. The Gene Ontology (GO) database and informatics resource. Nucleic Acids Res. 2004, 32, D258–D261. [Google Scholar] [CrossRef] [PubMed]
- Gangemi, A.; Guarino, N.; Masolo, C.; Oltramari, A.; Schneider, L. Sweetening ontologies with DOLCE. In Knowledge Engineering and Knowledge Management: Ontologies and the Semantic Web; Springer: Berlin/Heidelberg, Germany, 2002; pp. 166–181. [Google Scholar]
- Buggenhout, C.V.; Ceusters, W. A novel view on information content of concepts in a large ontology and a view on the structure and the quality of the ontology. Int. J. Med. Inform. 2005, 74, 125–132. [Google Scholar] [CrossRef] [PubMed]
- Fellbaum, C. WordNet. In Theory and Applications of Ontology: Computer Applications; Springer: Berlin/Heidelberg, Germany, 2010; pp. 231–243. [Google Scholar]
- Ponzetto, S.P.; Strube, M. Knowledge derived from Wikipedia for computing semantic relatedness. J. Artif. Intell. Res. 2007, 30, 181–212. [Google Scholar] [CrossRef]
- Ittoo, A.; Bouma, G. Minimally-supervised extraction of domain-specific part–whole relations using Wikipedia as knowledge-base. Data Knowl. Eng. 2013, 85, 57–79. [Google Scholar] [CrossRef]
- Kaptein, R.; Kamps, J. Exploiting the category structure of Wikipedia for entity ranking. Artif. Intell. 2013, 194, 111–129. [Google Scholar] [CrossRef]
- Nothman, J.; Ringland, N.; Radford, W.; Murphy, T.; Curran, J.R. Learning multilingual named entity recognition from Wikipedia. Artif. Intell. 2013, 194, 151–175. [Google Scholar] [CrossRef]
- Sorg, P.; Cimiano, P. Exploiting Wikipedia for cross-lingual and multilingual information retrieval. Data Knowl. Eng. 2012, 74, 26–45. [Google Scholar] [CrossRef]
- Yazdani, M.; Popescu-Belis, A. Computing text semantic relatedness using the contents and links of a hypertext encyclopedia. Artif. Intell. 2013, 194, 176–202. [Google Scholar] [CrossRef]
- Rubenstein, H.; Goodenough, J.B. Contextual correlates of synonymy. Commun. ACM 1965, 8, 627–633. [Google Scholar] [CrossRef]
- Jarmasz, M.; Szpakowicz, S. Roget’s Thesaurus and Semantic Similarity. In Proceedings of the International Conference on Recent Advances in Natural Language Processing, Online, 1–3 September 2003; pp. 212–219. [Google Scholar]
- Hirst, G.; St-Onge, D. Lexical Chains as Representations of Context for the Detection and Correction of Malapropisms; MIT Press: Cambridge, MA, USA, 1998; Volume 305, pp. 305–332. [Google Scholar]



| Correlation Value | |
|---|---|
| Miller and Charles (1991) [75] | 1.00 |
| WordNet edge counting | 0.73 |
| Hirst et al. (1998) [97] | 0.69 |
| Jiang and Conrath (1997) [41] | 0.70 |
| Leacock and Chodorow (1998) [62] | 0.82 |
| Lin (1998) [54] | 0.82 |
| Resnik (1995) [43] | 0.78 |
| Jiang et al. (2017) [45] | 0.82 |
| DIS-C—From word A to B | 0.80 |
| DIS-C—From word B to A | 0.81 |
| DIS-C—Average of distances | 0.84 |
| DIS-C—Min distance | 0.84 |
| DIS-C—Max distance | 0.83 |
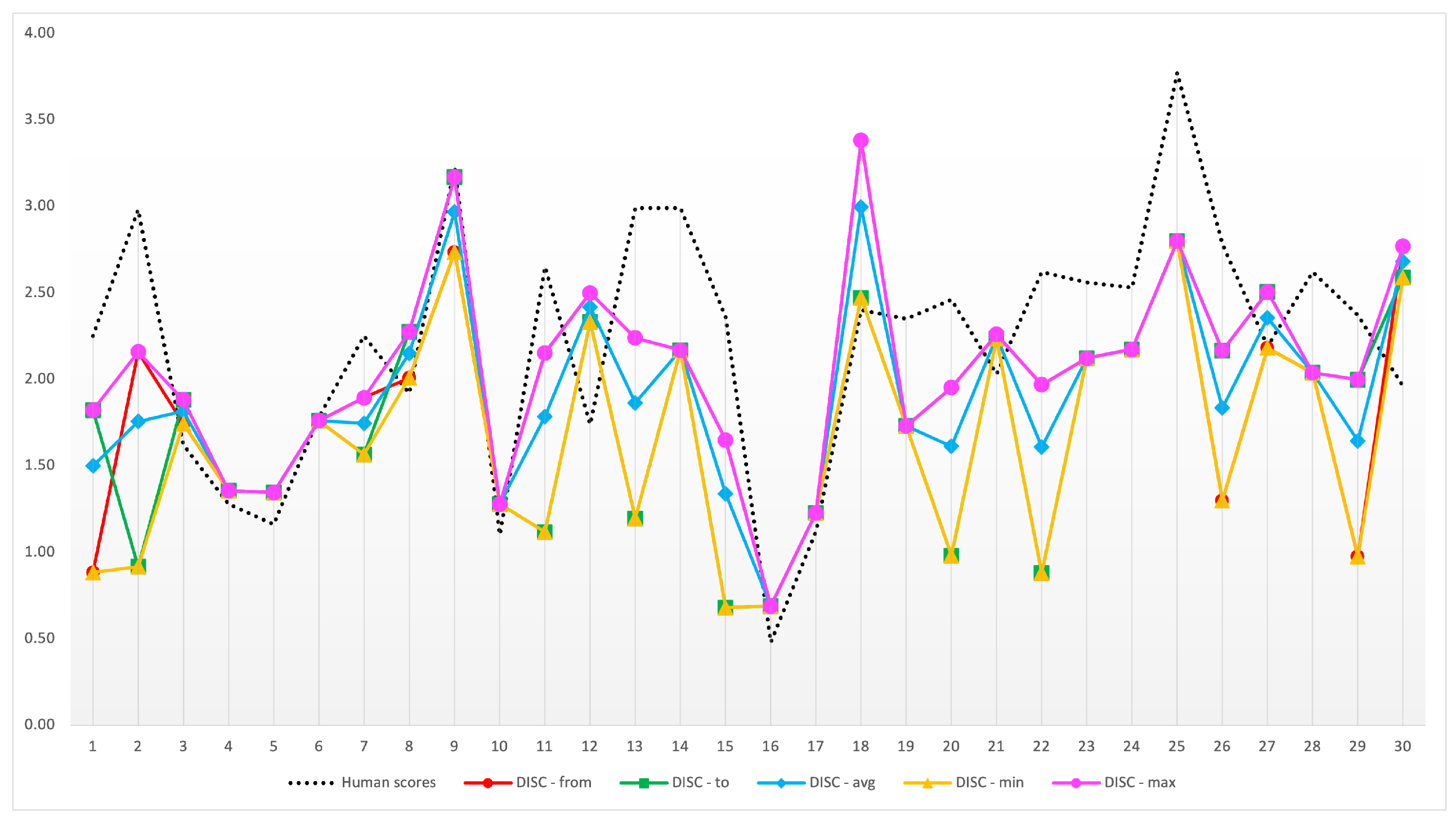
| Pair | Term A | Term B | Human Scores | DIS-C(to) | DIS-C(from) | DIS-C(avg) | DIS-C(min) | DIS-C(max) |
|---|---|---|---|---|---|---|---|---|
| 1 | Action film | Science fiction film | 2.25 | 0.88 | 1.82 | 1.50 | 0.88 | 1.82 |
| 2 | Aircraft | Airliner | 2.98 | 2.16 | 0.92 | 1.76 | 0.92 | 2.16 |
| 3 | Egyptian pyramids | Great Wall of China | 1.62 | 1.74 | 1.88 | 1.81 | 1.74 | 1.88 |
| 4 | Artificial intelligence | Cloud computing | 1.28 | 1.36 | 1.36 | 1.36 | 1.36 | 1.36 |
| 5 | Blog | 1.16 | 1.35 | 1.35 | 1.35 | 1.35 | 1.35 | |
| 6 | Book | Paper | 1.78 | 1.76 | 1.76 | 1.76 | 1.76 | 1.76 |
| 7 | Computer | Internet | 2.25 | 1.89 | 1.56 | 1.74 | 1.56 | 1.89 |
| 8 | Financial crisis | Bank | 1.92 | 2.01 | 2.27 | 2.15 | 2.01 | 2.27 |
| 9 | Category:Educators | Category:Educational theorists | 3.23 | 2.73 | 3.17 | 2.97 | 2.73 | 3.17 |
| 10 | Food safety | Health education | 1.10 | 1.28 | 1.28 | 1.28 | 1.28 | 1.28 |
| 11 | Fruit | Food | 2.65 | 2.15 | 1.12 | 1.78 | 1.12 | 2.15 |
| 12 | Health | Wealth | 1.74 | 2.50 | 2.33 | 2.42 | 2.33 | 2.50 |
| 13 | Knowledge | Information | 2.99 | 2.24 | 1.20 | 1.86 | 1.20 | 2.24 |
| 14 | Laptop | Tablet computer | 2.99 | 2.17 | 2.17 | 2.17 | 2.17 | 2.17 |
| 15 | Law | Lawyer | 2.36 | 1.65 | 0.68 | 1.34 | 0.68 | 1.65 |
| 16 | Literature | Medicine | 0.48 | 0.69 | 0.69 | 0.69 | 0.69 | 0.69 |
| 17 | Mobile phone | Television | 1.12 | 1.23 | 1.23 | 1.23 | 1.23 | 1.23 |
| 18 | National Basketball Association | Athletic sport | 2.40 | 3.38 | 2.47 | 2.99 | 2.47 | 3.38 |
| 19 | PC game | Online game | 2.35 | 1.73 | 1.73 | 1.73 | 1.73 | 1.73 |
| 20 | People | Human | 2.46 | 1.95 | 0.98 | 1.61 | 0.98 | 1.95 |
| 21 | President | Civil servant | 2.03 | 2.26 | 2.23 | 2.25 | 2.23 | 2.26 |
| 22 | Public transport | Train | 2.62 | 1.97 | 0.88 | 1.61 | 0.88 | 1.97 |
| 23 | Religion | Monk | 2.56 | 2.12 | 2.12 | 2.12 | 2.12 | 2.12 |
| 24 | Scholar | Academia | 2.53 | 2.17 | 2.17 | 2.17 | 2.17 | 2.17 |
| 25 | Scholar | Academic | 3.77 | 2.80 | 2.80 | 2.80 | 2.80 | 2.80 |
| 26 | Social network | 2.78 | 1.30 | 2.16 | 1.83 | 1.30 | 2.16 | |
| 27 | Spring festival | Christmas | 2.19 | 2.18 | 2.51 | 2.35 | 2.18 | 2.51 |
| 28 | Swimming | Water sport | 2.62 | 2.04 | 2.04 | 2.04 | 2.04 | 2.04 |
| 29 | Transport | Car | 2.37 | 0.97 | 2.00 | 1.64 | 0.97 | 2.00 |
| 30 | Travel agency | Service industry | 1.96 | 2.77 | 2.59 | 2.68 | 2.59 | 2.77 |
| Term | g(term) | IC |
|---|---|---|
| Academic | 0.4749 | 0.7446 |
| Lawyer | 0.4740 | 0.7466 |
| Public transport | 0.4710 | 0.7529 |
| Scholar | 0.4707 | 0.7535 |
| Scholar | 0.4707 | 0.7535 |
| Christmas | 0.4705 | 0.7540 |
| Literature | 0.4694 | 0.7562 |
| Information | 0.4688 | 0.7577 |
| Blog | 0.4663 | 0.7630 |
| Law | 0.4656 | 0.7645 |
| Civil servant | 0.4655 | 0.7646 |
| 0.4654 | 0.7648 | |
| Airliner | 0.4650 | 0.7658 |
| Aircraft | 0.4619 | 0.7724 |
| Water sport | 0.4615 | 0.7734 |
| Book | 0.4613 | 0.7736 |
| Train | 0.4613 | 0.7737 |
| Service industry | 0.4554 | 0.7866 |
| Travel agency | 0.4547 | 0.7882 |
| Monk | 0.4547 | 0.7882 |
| Transport | 0.4538 | 0.7900 |
| Artificial intelligence | 0.4530 | 0.7919 |
| Human | 0.4505 | 0.7974 |
| Television | 0.4490 | 0.8008 |
| Computer | 0.4479 | 0.8033 |
| Internet | 0.4470 | 0.8052 |
| Mobile phone | 0.4469 | 0.8055 |
| Academia | 0.4445 | 0.8108 |
| Great Wall of China | 0.4444 | 0.8111 |
| Swimming | 0.4443 | 0.8112 |
| People | 0.4442 | 0.8115 |
| Laptop | 0.4441 | 0.8118 |
| Car | 0.4431 | 0.8141 |
| Fruit | 0.4416 | 0.8172 |
| President | 0.4413 | 0.8181 |
| Religion | 0.4410 | 0.8187 |
| National Basketball Association | 0.4393 | 0.8226 |
| Health | 0.4358 | 0.8307 |
| Paper | 0.4353 | 0.8316 |
| Food | 0.4351 | 0.8321 |
| Bank | 0.4349 | 0.8327 |
| Action film | 0.4197 | 0.8683 |
| Science fiction film | 0.4196 | 0.8683 |
| Online game | 0.4154 | 0.8784 |
| Knowledge | 0.4126 | 0.8853 |
| Cloud computing | 0.4112 | 0.8888 |
| Financial crisis | 0.4069 | 0.8993 |
| PC game | 0.4044 | 0.9053 |
| Category:Educators | 0.4028 | 0.9093 |
| Food safety | 0.3986 | 0.9197 |
| Category:Educational theorists | 0.3985 | 0.9200 |
| 0.3857 | 0.9526 | |
| Medicine | 0.3832 | 0.9591 |
| Wealth | 0.3829 | 0.9599 |
| Health education | 0.3747 | 0.9817 |
| Social network | 0.3697 | 0.9950 |
| Athletic sport | 0.3672 | 1.0020 |
| Spring festival | 0.3599 | 1.0220 |
| Tablet computer | 0.3125 | 1.1631 |
| Egyptian pyramids | 0.2726 | 1.2997 |
| Correlation Value | |
|---|---|
| Human scores [45] | 1.00 |
| DIS-C—From word A to B | 0.56 |
| DIS-C—From word B to A | 0.56 |
| DIS-C—Average of distances | 0.86 |
| DIS-C—Min distance | 0.88 |
| DIS-C—Max distance | 0.72 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Quintero, R.; Torres-Ruiz, M.; Saldaña-Pérez, M.; Guzmán Sánchez-Mejorada, C.; Mata-Rivera, F. A Conceptual Graph-Based Method to Compute Information Content. Mathematics 2023, 11, 3972. https://doi.org/10.3390/math11183972
Quintero R, Torres-Ruiz M, Saldaña-Pérez M, Guzmán Sánchez-Mejorada C, Mata-Rivera F. A Conceptual Graph-Based Method to Compute Information Content. Mathematics. 2023; 11(18):3972. https://doi.org/10.3390/math11183972
Chicago/Turabian StyleQuintero, Rolando, Miguel Torres-Ruiz, Magdalena Saldaña-Pérez, Carlos Guzmán Sánchez-Mejorada, and Felix Mata-Rivera. 2023. "A Conceptual Graph-Based Method to Compute Information Content" Mathematics 11, no. 18: 3972. https://doi.org/10.3390/math11183972
APA StyleQuintero, R., Torres-Ruiz, M., Saldaña-Pérez, M., Guzmán Sánchez-Mejorada, C., & Mata-Rivera, F. (2023). A Conceptual Graph-Based Method to Compute Information Content. Mathematics, 11(18), 3972. https://doi.org/10.3390/math11183972