1. Introduction
With the innovation and rapid development of technology, unmanned aerial vehicles (UAVs) are widely used in search and rescue, road patrol, target surveillance, and other scenarios by virtue of their advantages of low cost, high reliability, and high scalability. Due to the complexity and rapid expansion of the UAV operating environment, it has become a hot field of scientific research to rationally assign the best target to the most suitable UAV at the least cost by virtue of autonomous perception and collaborative decision-making, and it is of great significance to effectively monitor and track multiple moving air targets in complex environments as well as gaming [
1,
2]. However, with the increase in the number of UAVs and the urgency of real-time surveillance, low-damage and high-efficiency many-to-many target assignment has become a crucial challenge [
3,
4,
5].
In recent years, researchers have proposed various methods to address the issue of target assignment, including mathematical programming methods [
6,
7,
8], heuristic methods [
9,
10], and optimization algorithms [
11]. Orhan et al. proposed a dynamic target allocation framework based on artificial neural networks that optimizes the target assignment plan by simultaneously considering multiple objectives and constraints [
12]. Zhu et al. proposed an intelligent decision-making framework based on reinforcement learning for multi-target assignment problems, which can effectively learn, adapt to changing environments, and optimize the overall system performance through decision-making [
13]. Zou et al. derived a decision tree-based target assignment algorithm that considers various factors such as distance, angle, and speed to effectively allocate targets to multiple space vehicles and make accurate allocation decisions [
14]. Zhen et al. derived a cooperative target allocation algorithm based on an improved Contract Network Protocol (ICNP) for heterogeneous UAV swarms. It considers UAV capabilities, target characteristics, and communication constraints to make real-time and optimal allocation decisions [
15]. Shalumov et al. introduced a dynamic programming-based approach for weapon–target allocation in multi-agent target-missile-defender engagement that considers missile flight time, defender capability, and target priority to make real-time and optimal allocation decisions, which was shown to be effective through experimental results [
16]. Duan et al. introduced a target allocation algorithm inspired by wolf behaviors for unmanned aerial systems (UASs), which considers target characteristics, UAS capabilities, and communication constraints. They can make real-time and coordinated allocation decisions [
17]. Yeduri et al. proposed a novel method of energy and throughput management in a delay-constrained small-world unmanned aerial vehicle (UAV)–IoT network [
18]. Bose et al. propose a novel method that computes the optimum height at which UAVs should hover, resulting in a maximum coverage radius with a sufficiently small outage probability [
19]. Xia et al. proposed a multi-UAV cooperative target tracking system and designed a deep reinforcement learning (DRL)-based algorithm for intelligent flight action decisions of UAVs to track a moving air target using past and current position information [
20]. Zhou et al. proposed a UAV swarm-based cooperative tracking architecture to systematically improve the UAV tracking performance [
21]. Despite recent progress, existing air combat target assignment methods still have some limitations, such as over-reliance on perfect information, lack of adaptability to dynamic environments, and single objective optimization.
Traditional optimization methods have limitations in producing optimal target assignment plans. In existing studies, when multi-UAV networks target a single target, they are often treated as independent and unrelated individuals, and the target’s survival probability is multiplied. However, obtaining accurate probability values in actual situations is often significantly challenging. The adversary process between both sides is essentially a game, and the other side’s behavior can significantly affect the effectiveness of the multi-UAV network target assignment plan. Therefore, it is necessary to estimate the target assignment plan that the other side may adopt and comprehensively judge its impact to optimize and obtain the optimal target assignment plan for our side.
Evolutionary game theory, an outgrowth of traditional game theory, incorporates principles of biological evolution [
22]. It combines the economic concept of “equilibrium” with the concept of “adaptation” to depict how groups adapt to their environment through learning, imitation, and trial-and-error under conditions of incomplete rationality, asymmetric information, and biases in expectations and environment [
23]. Furthermore, evolutionary game theory prioritizes cooperation over destructive competition, making it a means of resource assignment that enables the maximization of overall effectiveness. This process ultimately leads to an evolutionarily stable state, providing a particle framework for studying interactions among multiple intelligent agents.
Numerous scholars have utilized evolutionary game theory to study cooperation problems, yielding significant results that have been widely applied to practical issues [
24,
25,
26]. Given that the concept of stable cooperation and target assignment in a multi-UAV system, under limited information and resources, aligns with the principles of evolutionary game theory, a comprehensive analysis of the stable long-term trends of both parties engaged in the game becomes possible by leveraging these principles. Both sides in the target assignment problem face a choice between cooperation and competition. They must consider the balance between their own interests and the overall benefits. This decision-making process can be analyzed using the concept of evolutionary games, including the choice of game strategies, the dynamics of evolution, and the final equilibrium state. Evolutionary game theory can explore the effects of different decision-making strategies and evolutionary dynamics on the advantages of both sides, which can help to deeply understand the strategic decision-making and competitive mechanisms in multi-UAV network target assignments and provide effective solutions to the problem of optimal target assignment. The proposed method establishes a multi-UAV network target assignment evolutionary game model, with both sides’ UAVs in this model regarded as game participants and their respective target assignment plans serving as the game strategies. The payoff function of the game is constructed based on the total attack effectiveness and ineffectiveness achieved by both sides in the target assignment plan, with the confidence level used to measure the attack effectiveness of each UAV against its target [
27]. Additionally, a multi-level information fusion method, based on evidence theory, is used to calculate the total attack effectiveness of multi-UAVs against multiple targets [
28]. Based on the multi-UAV network target assignment evolutionary game model, a replicator equation is constructed to determine the evolutionarily stable strategy (ESS) and obtain the optimal assignment plan. Finally, the effectiveness of the proposed method is verified through typical case studies and experiments.
The main contributions of this paper can be summarized as follows: (i) evolutionary game theory is utilized to solve the multi-UAV network target assignment problem; (ii) a multi-level information fusion method based on evidence theory is designed to calculate the total attack effectiveness of multi-UAVs against multiple targets; and (iii) an experiment in different scenarios is conducted to demonstrate the effectiveness of the proposed method.
2. Problem Formulation and Model Construction
2.1. Problem Formulation
The problem studied in this paper can be described as follows: Both our multi-UAV and target multi-UAV consist of multiple UAVs of the same type and each of our UAVs evaluates the expected benefits based on environmental information, its own capabilities, and the threat of targets. Using this information, each of our UAVs will be able to determine the optimal target assignment plan for the target multi-UAVs, thus gaining an advantage in the game.
The state of each UAV is represented as
, where
represents the UAV’s three-dimensional coordinates,
represents the UAV’s speed,
represents the UAV’s pitch angle, and
represents the UAV’s heading angle. Let
be the set of multi-UAVs and
be the set of targets. The multi-UAV assignment plan is denoted by
, where
represents that the UAV
selects the target
. Similarly, the targets’ assignment plan is denoted by
, where
represents that target
selects the UAV
. The relative situation diagram between the UAV
and target
is shown in
Figure 1, where the red UAV represents our UAV and the blue UAV represents the target UAV.
Assuming that each UAV flies toward its target based on the target assignment results, and if the target is within attacking range and the situation is in favor, the UAV will attack its target. Let the number of attacks by our side’s UAV be denoted by
. Similarly, let the number of attacks by the target side’s UAV be denoted by
.
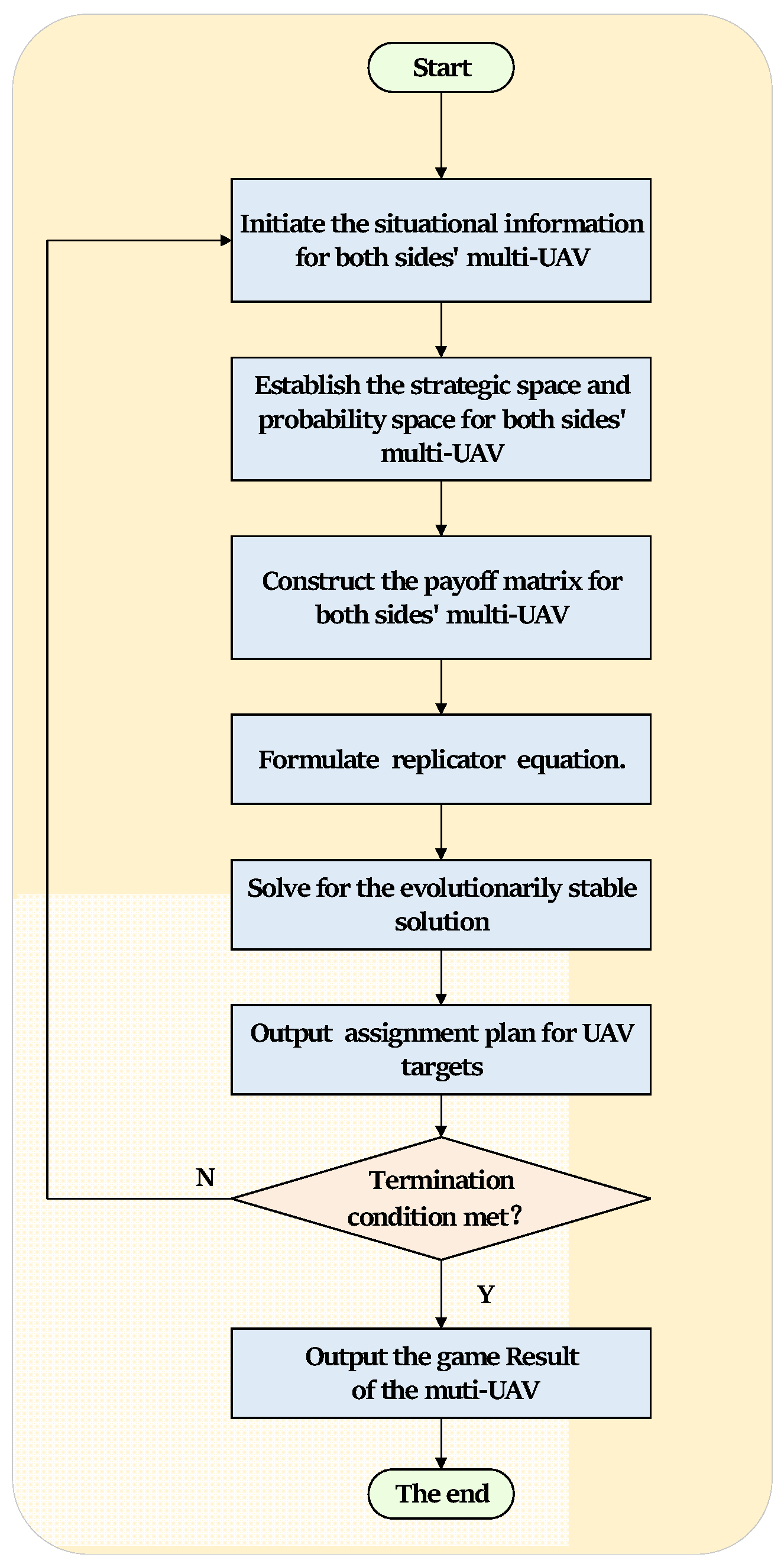
Figure 2 provides a comprehensive overview of the multi-UAV cooperative target assignment problem, illustrating the entire flow of the problem.
2.2. Model Construction
We can model the problem of multi-UAV network target assignment as an evolutionary game model, denoted by with the following specifications:
Let be the participating entities of the two sides of the game: represents our side’s multi-UAV and represents the target side’s.
Let be the strategy space in the evolutionary game model, where is the set of our side’s pure strategies, and is the set of pure strategies for the target side. Specifically, the -th pure strategy in corresponds to the -th target assignment plan for our side and the -th pure strategy in corresponds to the -th target assignment plan for the target side. Let denote the number of our side’s multi-UAVs and let denote the number of the target side’s multi-UAVs. Let denote the number of pure strategies for our side and let denote the number of pure strategies for the target side. Therefore, we have that and .
Let be the payoff matrix in the evolutionary game model, where is the payoff matrix for our side and is the payoff matrix for the target side. Specifically, is the payoff value obtained by our side when we choose the pure strategy and the target side chooses the pure strategy . Similarly, is the payoff value obtained by the target side when they choose the pure strategy and our side chooses the pure strategy .
Let be the probability space for both sides to choose their respective strategies in the evolutionary game model. Let denote the probability space for our side, and let denote the probability space for the target side. Specifically, denotes the probability of our side choosing a pure strategy , and denotes the probability of the target side choosing a pure strategy .
4. Analysis of Evolutionary Game Model
Under bounded rationality, game players have limited initial knowledge, which can result in the adoption of suboptimal strategies. This leads to constant adjustment and improvement of the payoffs of both sides during the game. Due to the differences in interests, those with lower payoffs will improve their strategies by learning from those with higher payoffs, resulting in changes in the proportion of each strategy over time. The dynamic change of strategies can be defined as a function of time. The dynamic change rate can be represented by a replicator equation based on biological evolution ideas [
29]. This equation describes the dynamic change process of strategies and analyzes the equilibrium state of the evolutionary game to solve the equilibrium solution of the multi-UAV cooperative target assignment evolutionary game model. The specific algorithm is described as follows:
- (I)
Given the probability space and of the UAVs’ and targets’ choices of each strategy in the evolutionary game,
- (II)
The payoffs and expected payoffs of different target assignment strategies for both sides can be calculated using the probability space
and
, and the payoff matrix. Equations (16)–(19) show the formulas for calculating these:
- (III)
The replicator equations for UAVs on both sides are established as follows:
- (IV)
To solve for the evolutionary stable equilibrium, we can combine the replicator equations for UAVs on both sides obtained in the previous step (III) to construct the following system of replicator equations:
Solving the above system of equations yields the evolutionary equilibrium strategy for the multi-UAV cooperative target assignment evolutionary game model, which is a strategy where the selection probabilities of each player’s strategies remain unchanged. However, some of the evolutionary equilibrium strategies may be unstable. This means that if both players deviate from this equilibrium state, the replicator equation will cause the evolutionary outcome to no longer converge to this strategy. Therefore, further analysis of the stability of the evolutionary equilibrium strategy is necessary to identify the stable strategies within the equilibrium and achieve optimal target assignment.
5. Simulation Results and Analysis
5.1. Introduction to the RflySim Simulation Platform
This study utilizes the RflySim platform, which is built in the Matlab/Simulink environment for flight simulation. The RflySim platform is a UAV flight control ecosystem released by the Reliable Flight Control Group at Beihang University. In reference [
30], a comparison between the multi-wing flight entity experiment and the simulation experiment based on the RflySim platform validates the high accuracy level of the platform’s simulation. The platform has undergone quantitative analysis tests and comparison experiments with fault injection, and its platform’s credibility was found to be above 90% (with 60% being the lowest value in the accuracy confidence interval). This fully confirms the high fidelity and practicality of the platform. The platform’s core value is reflected in the software and hardware in the loop simulation, which includes the unique CopterSim, visual system plugins, and developed models. The software platform components are shown in
Figure 9.
5.2. Analysis of the Typical Scenario
This section constructs a typical scenario of three UAVs and two targets, as shown in
Figure 10, where the red UAV represents our UAVs and the blue UAV represents the targets. Each UAV had two attacks and the same probability of being damaged. The situational information of each UAV is provided in
Table 1.
In
Table 1, the units of
x,y,z are meters (m), the unit of v is meters per second (m/s), and the units of
θ and
φ are radians (rad). Both sides must strategize to maximize their advantage in the conflict. The target assignment problem is modeled as an evolutionary game model
.
The specific process of its construction is as follows:
- (I)
represents the UAVs on both sides in the evolutionary game model.
- (II)
represents the strategy space in the evolutionary game model, as shown specifically in
Table 2.
- (III)
represents the probability space in the evolutionary game model, with equal initial probabilities as shown in
Table 3.
- (IV)
Construct the payoff matrices on both sides.
First, calculate the attack effectiveness of each UAV based on the situational advantage function, resulting in the effectiveness matrices
and
, as shown in Equations (23) and (24):
Then, calculate the total effectiveness for each target assignment plan, based on Equations (10) and (11), as shown in
Table 4.
On this basis, calculate the payoffs for UAVs on both sides for each combination of strategies, based on Equations (12) and (13), resulting in the payoff matrices
and
for the UAVs on both sides, as shown in Equations (25) and (26).
To obtain an evolutionary equilibrium solution for the multi-UAV network target assignment game, a replicator equation is constructed. This equation describes how the distribution of strategies evolves based on their relative payoffs. The resulting equilibrium solution represents a stable distribution of strategies that will persist over time. The evolutionary trend of strategies for UAVs on both sides can be visualized through
Figure 11 and
Figure 12, which show the proportion of different strategies over time.
It can be observed from
Figure 11 and
Figure 12 that to achieve higher payoffs, our side will eventually tend to select the 6-th strategy as the target assignment plan. In contrast, the target side will eventually tend to select the 2-nd strategy as the target assignment plan. The target assignment results of both sides are shown in
Figure 13, where the red dots represent our UAVs, the blue dots represent the target UAVs, the red lines represents the strategy of our UAVs to select the target, and the blue lines represents the strategy of the target UAVs to select the target. This figure provides a visual representation of the final target assignments resulting from the use of the selected strategies by both sides. As can be seen in
Figure 13, our
chooses target
, and our
and
choose target
; under this strategy, our side has the greatest benefit, choosing this strategy to eliminate
first, and
attacks
for cover, and targets
and
choose our
. Under this strategy, the target side has the greatest benefit; choosing this strategy can eliminate
in a short period, reducing their own loss risk.
5.3. Results and Analysis of the Effectiveness Experiment
The advantage or disadvantage between both sides is largely dependent on the number of UAVs, their performance, and the relative situation between them. When the performance of the UAVs on both sides is equal, the advantage or disadvantage between the sides is primarily determined by the number of UAVs and the relative situation between them. To evaluate the effectiveness of the target assignment method for multi-UAVs based on the evolutionary game, we designed typical scenarios that include our advantageous scenario, our disadvantageous scenario, and an evenly-matched scenario by adjusting the number of UAVs on both sides. To compare the effectiveness of our proposed method, we selected the Min–Max strategy, PSO, GA and Hungarian Algorithm as baselines [
31,
32,
33,
34]. These methods represent commonly used approaches for multi-UAV network target assignment and provide a useful benchmark for evaluating the performance of our proposed method.
At the conclusion of the simulation experiment, three simulation results were defined from the perspective of our sides based on the remaining number of UAVs on both sides, as follows:
Our side victory: At the end of the simulation, our side has more remaining UAVs than the target side.
Our side defeat: At the end of the simulation, our side has fewer remaining UAVs than the target side.
Draw: At the end of the simulation, both sides have the same number of remaining UAVs.
The simulation results are analyzed through the winning rate, losing rate, and draw rate [
35], for which the detailed descriptions and calculations are shown in
Table 5.
For each typical scenario, the target side used the proposed method outlined in this paper, while our side used the method proposed in this paper and the baselines to conduct 400 simulation experiments. Based on the simulation results, our side’s win, loss, and draw rates were calculated, as shown in
Table 6.
The experimental results demonstrate that the proposed method outperforms the selected baselines to varying degrees in the three typical scenarios. In our advantageous scenario, the proposed method achieved a winning rate of 89.75%, a draw rate of 2.75%, and a loss rate of 7.5%, while the selected baselines achieved success rates ranging from 83% to 87.25%. In the evenly-matched scenario, the proposed method achieved a winning rate of 38.5%, a draw rate of 27.25%, and a loss rate of 34.25%, while the selected baselines achieved success rates ranging from 30.75% to 37.5%. In our disadvantageous scenario, the proposed method achieved a winning rate of 9.25%, a draw rate of 4.25%, and a loss rate of 86.5%, while the selected baselines achieved success rates ranging from 5.5% to 8%. Across our advantageous, evenly-matched, and disadvantageous scenarios, the proposed method achieved an average winning rate of 45.83%, an average draw rate of 11.42%, and an average loss rate of 42.75%, outperforming the average success rates of the selected baselines which ranged from 40% to 44.17%.
The results of our proposed method indicate its potential to both enhance advantages for our side in advantage scenarios, as well as mitigate disadvantages in unfavorable situations. By implementing evolutionary game theory, we are able to consider possible countermeasures that the target side may adopt in response to our actions. This allows our approach to outperform selected baseline methods by anticipating dynamic interactions between our system and the target. Evolutionary game theory takes into account the adversarial nature of real-world environments when assigning UAV targets. It models the evolution of combined strategies over time as both sides continuously adapt to each other’s decisions and equilibrium shifts. This makes evolutionary game theory a more robust and flexible framework compared to alternative approaches. Overall, evolutionary game theory enhances the resilience and long-term effectiveness of our target assignment scheme in practical situations involving strategic adversaries.
6. Conclusions
In this paper, the multi-UAV network target assignment problem is investigated in a 3D scenario to solve the assignment problem for moving air targets. The method uses evolutionary game theory to model the multi-UAV network target assignment problem, and constructs the payment matrices of both sides by establishing the situational assessment function and a multi-level information fusion algorithm. Then, the evolutionary equilibrium solution is solved by constructing replicator equations to find the optimal target assignment strategy for both sides, which confers the benefit of balancing each side’s interest and the overall benefit. Finally, the whole process of the proposed method is analyzed through the typical scenario and the effectiveness experiment is analyzed in comparison with other algorithms in three scenarios. The experimental results show that the win rate of the game under the proposed method is higher than that for the Min–Max strategy, PSO, GA, and Hungarian Algorithm, and the performance of the proposed method is the best.
In future work, we plan to expand our analysis to consider factors such as opponent occupancy uncertainty and resource adequacy and uncertainty to further study the problem of multi-UAV network target assignment. We aim to improve the applicability and robustness of our solution method. Additionally, we will incorporate a UAV maneuvering decision-making algorithm to maximize the exceptional efficiency of the UAV during the movement process. These future efforts will help to advance our understanding of multi-UAV application scenarios and provide valuable insights into the development of effective target assignment strategies.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}