
Large-Scale Simulation of Shor’s Quantum Factoring Algorithm

 , , , and
, , , and
Abstract
:1. Introduction
1.1. Related Work
- 1
- Theory: the first class of articles focuses on theoretical perspectives such as algorithmic modifications and improved lower bounds on the success probability [11,14,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60], many of which consider the case that some parameters of Shor’s algorithm are modified and certain trade-offs are made. This class contains work that estimates the number of resources required when using different levels of quantum computer technology [6,22]. This line of work culminates in Ekerå’s post-processing algorithms [34], by which the success probability for a single run of the quantum part can be brought arbitrarily close to one (see below).
- 2
- Simulation: second, Shor’s algorithm has been studied by using simulators running on conventional computers. Some use universal quantum computer simulators [24,25,26,61], sometimes also called Schrödinger simulators, since they propagate the full quantum statevector. Another approach is to use so-called Feynman simulators, which can only access certain amplitudes from the full statevector, but may require fewer computational resources; they are often based on tensor networks or matrix product states [27,28,29,30]. Finally, there is software designed to directly sample from the probability distributions generated by Shor’s algorithm (cf. Equation (26) below) and various extensions thereof. This class contains the suite of programs called Qunundrum [31,62], which can simulate distributions for large, cryptographically relevant cases. Note, however, that the solution to the factoring problem (i.e., the order or the discrete logarithm) must be known in advance, and the effect of errors in the quantum part cannot be simulated.
- 3
- Alternative Algorithms: a third line of work studies alternative ways to use gate-based quantum computers to solve the factoring problem. Some of them use Shor’s discrete logarithm quantum algorithm [62,63,64], which is also an instance of the hidden subgroup problem [65]. In the Ekerå-Håstad scheme [63], the idea to factor a semiprime is to pick a random , compute with unknown order r, and then obtain (using that [66]). If (which is the case for many g), we have , and additionally knowing allows one to compute p and q. Another alternative way to solve the factoring problem is given in [67] and is based on the classical number field sieve [3]. In particular, Bernstein et al. propose to use Grover’s quantum search algorithm [68] (and/or Shor’s algorithm for a much smaller subproblem) to accelerate the number field sieve. This proposal is asymptotically worse in time complexity than using Shor’s algorithm directly, but it requires fewer qubits and is therefore possibly easier to realize in near-term physical devices. Finally, Li et. al. [69] presented an algorithm with an exponential speedup (beyond the framework of the hidden subgroup problem [65]) that solves the square-free decomposition problem—a problem related to factoring in which the task is to find, for any integer , the unique integers and of the square-free decomposition .
- 4
- Gate-Based Experiments: fourth, there have been several experimental efforts to implement Shor’s factoring algorithm on existing gate-based quantum computer devices [15,19,20,70,71,72,73,74,75,76]. However, many of these have made use of prior knowledge about the factors to simplify the experimental setup [21]. In the extreme case (namely when a base with order is used), this reduces the computational problem to the equivalent of flipping coins. Experiments that have not used such an oversimplified method can be found in [15,19,20].
- 5
- Other Experiments: finally, quantum annealers and adiabatic quantum computers have been used to study alternative factoring algorithms [17,77,78,79,80,81,82]. The quantum annealing approach requires at most qubits to factor an L-bit number. Quantum annealing and adiabatic quantum computation are technologically significantly ahead of gate-based quantum computing, in that larger quantum processing units with more than 5000 qubits exist and that they can solve much larger problems [83,84]. In particular, numbers up to and above 200,000 have been factored on the D-Wave 2000Q [78,79] and 1,005,973 has been factored using D-Wave hybrid [80]. Although significantly larger than the numbers factored on gate-based quantum computers (without oversimplification), these numbers are still much smaller than = 549,755,813,701 factored in this work using shorgpu.
1.2. Outline
2. Materials and Methods
2.1. Initialization
2.2. Controlled Modular Multiplication Gate
2.3. Rotation Gate
2.4. Hadamard Gate
2.5. Measurement Operation
2.6. Reset Operation
2.7. Initialization Errors
2.7.1. Amplitude Initialization Error
2.7.2. Phase Initialization Error
2.7.3. Effective Single-Qubit Error Probability
2.8. Measurement Errors
2.8.1. Classical Measurement Error
2.8.2. Quantum Measurement Error
2.9. Details on Memory and Computing Time
3. Results
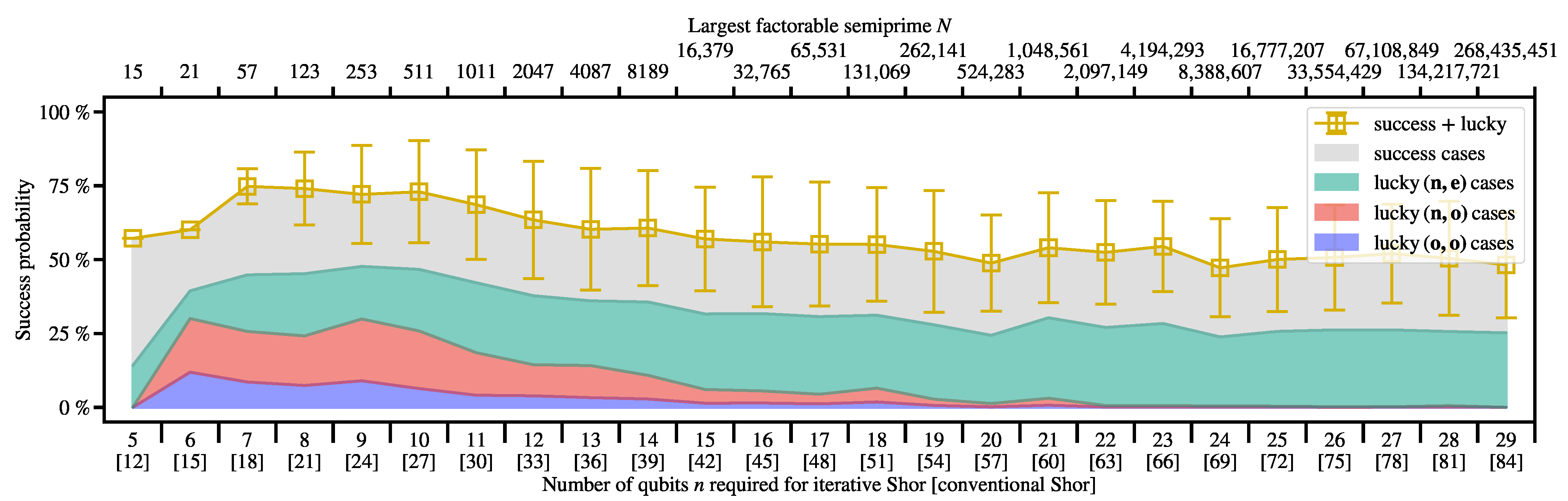
3.1. Using Shor’s Post-Processing
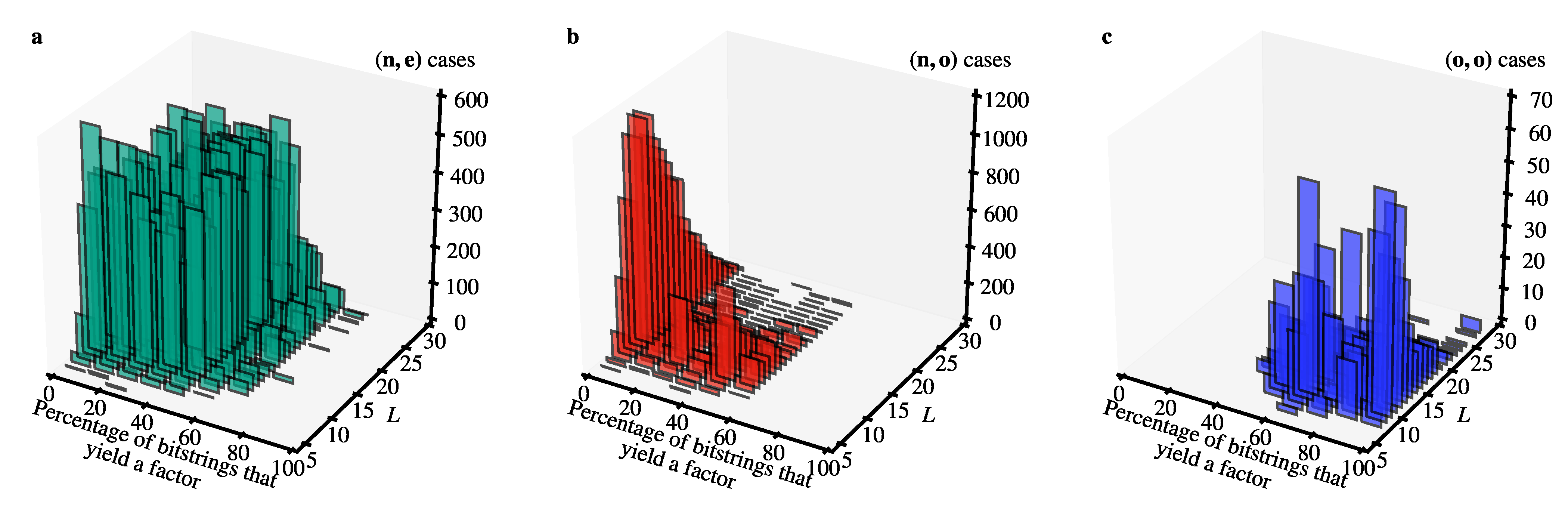
3.1.1. Classification of the “Lucky” Scenarios
- (n,e) is not the order but r is even,
- (n,o) is not the order and r is odd,
- (o,o) is the order but the order is odd.
3.1.2. The (n,e) Scenario
3.1.3. The (n,o) Scenario
3.1.4. The (o,o) Scenario
3.2. Using Ekerå’s Post-Processing
3.3. Errors during the Execution of Shor’s Algorithm
- 1
- Classical measurement errors (blue squares) are defined as misclassifications occurring directly after each quantum measurement process with a constant error probability (see Section 2.8.1).
- 2
- Quantum measurement errors (yellow circles) are modeled as depolarizing quantum noise during the measurement process with effective error probability (see Section 2.8.2).
- 3
- Amplitude initialization errors (green upward-pointing triangles) are modeled by initializing the recycled qubit not in the uniform superposition , but by increasing the amplitude of as a function of . The effective error probability is (see Section 2.7.1).
- 4
- Phase initialization errors (red down-pointing triangles) are defined by introducing a relative phase between the states and in the initialization. The effective error probability is (see Section 2.7.2).
- 5
- Bit flip errors (purple stars) are defined by flipping each bit in the final bitstring j with probability . This error model, in contrast to the others, does not affect the execution of the quantum part of the iterative Shor algorithm. While such an error (e.g., a fault in the classical computer memory) may be considered unlikely, it is still interesting to compare its consequences to the errors in the quantum part.
3.4. Discussion of Limitations and Future Directions
- 1
- In a practical realization of Shor’s quantum circuit shown in Figure 2, most of the work is expected to be in the implementation of the exponentiation in terms of the controlled modular multiplications (see Section 2.2). Our choice to simulate the multiplications using direct permutations with no extra qubits, while allowing the large-scale MPI scheme sketched in Figure 3, prevents the direct simulation of quantum errors during the multiplications (which is why, in Figure 11, essentially only initialization errors before and measurement errors after the multiplications are shown). The alternative would be to implement a general multiplication circuit using standard quantum gates and additional workspace qubits. To pursue this research direction to allow the study of errors during the multiplications, an informative exposition to start from is the construction by Gidney and Ekerå [6], which combines and optimizes many techniques discovered over the past decades to implement the modular multiplications.
- 2
- Although Shor’s order-finding algorithm is the most prominent quantum algorithm for factoring, a practical solution of the factoring problem on gate-based quantum computers might rather use the Ekerå-Håstad factoring scheme [63] based on the discrete logarithm quantum algorithm (see point 3 in Section 1.1). Instead of stages in the iterative quantum circuit (cf. Figure 2) using the semiclassical Fourier transform, this algorithm requires at most stages, with a systematic option to reduce t further at the cost of reducing the success probability below 99% [64]. In the context of quantum circuit simulation, the Ekerå-Håstad scheme would save valuable execution time (cf. Section 2.9), allowing for more statistics to be gathered for larger factoring scenarios.
- 3
- The shorgpu implementation used for this work maintains two full statevector buffers psi and psibuf, which reduce the simulation time by enabling contiguous memory transfer through the MPI network (see [23]). However, the total amount of memory fixes the maximum number of qubits that can be simulated, which puts a limit on the size of simulatable factoring problems. An alternative choice would be to use only a single statevector buffer, thereby having to replace the contiguous memory transfer with interleaved communication and computation. This choice (potentially combined with reducing computing time by switching to the Ekerå-Håstad scheme, see previous item) would allow the simulation of yet another qubit, to push the boundary of simulatable factoring problems and the threshold of the proposed challenge one step further.
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CPU | Central Processing Unit |
| CUDA | Compute Unified Device Architecture |
| GPU | Graphics Processing Unit |
| JSC | Jülich Supercomputing Centre |
| JUNIQ | Jülich UNified Infrastructure for Quantum computing |
| JUQCS | Jülich Universal Quantum Computer Simulator |
| JUWELS | Jülich Wizard for European Leadership Science |
| MPI | Message Passing Interface |
| NISQ | Noisy Intermediate-Scale Quantum |
| QFT | Quantum Fourier Transform |
| RSA | Rivest Shamir Adleman |
| gcd | Greatest Common Divisor |
| lcm | Least Common Multiple |
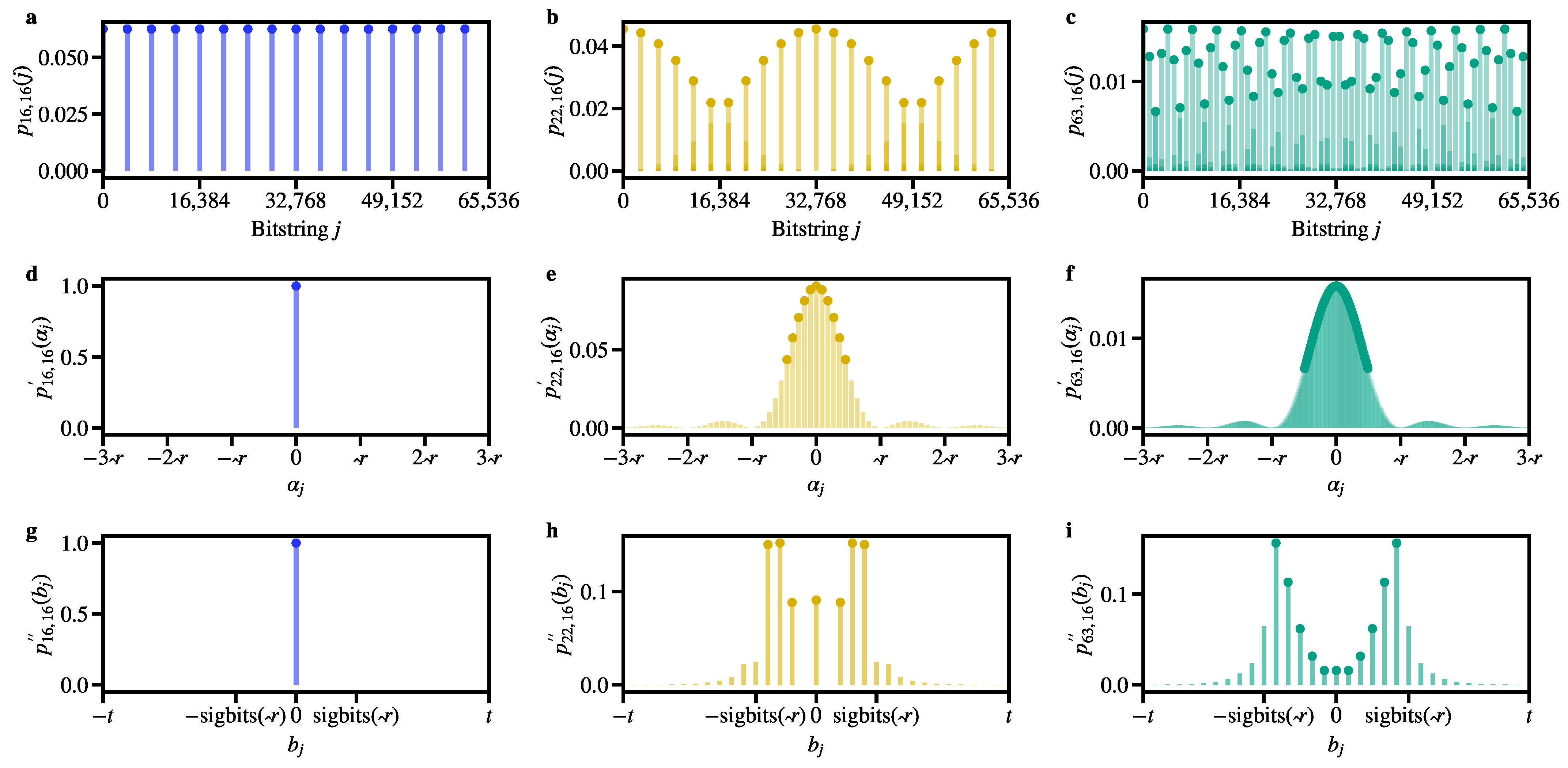
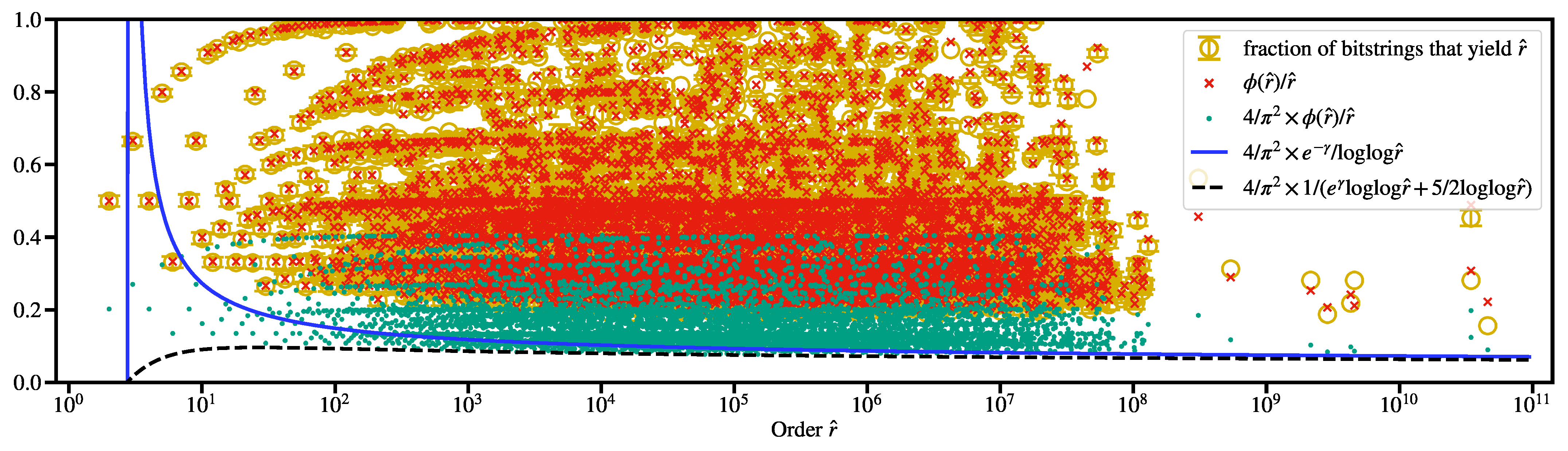
Appendix A. The Probability Distribution Generated by Shor’s Algorithm

Appendix A.1. Alternative Representations of the Probability Distribution
Appendix A.2. Probability Theory for Shor’s Factoring Procedure

Appendix B. Generation of the Factoring Problems
Appendix C. Standard Procedure: Shor’s Post-Processing
Appendix D. List of Semiprimes

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Qubits n | Semiprime N | Factor p | Factor q | t |
|---|---|---|---|---|
| 5 | 15 | 3 | 5 | 8 |
| 6 | 21 | 3 | 7 | 9 |
| 7 | 35 | 5 | 7 | 11 |
| 8 | 35 | 5 | 7 | 11 |
| 9 | 253 | 11 | 23 | 16 |
| 10 | 493 | 17 | 29 | 18 |
| 11 | 1007 | 19 | 53 | 20 |
| 12 | 2047 | 23 | 89 | 22 |
| 13 | 4087 | 61 | 67 | 24 |
| 14 | 8051 | 83 | 97 | 26 |
| 15 | 16,241 | 109 | 149 | 28 |
| 16 | 32,743 | 137 | 239 | 30 |
| 17 | 65,509 | 109 | 601 | 32 |
| 18 | 131,029 | 283 | 463 | 34 |
| 19 | 262,099 | 349 | 751 | 36 |
| 20 | 524,137 | 557 | 941 | 38 |
| 21 | 1,048,351 | 1009 | 1039 | 40 |
| 22 | 2,097,101 | 1399 | 1499 | 42 |
| 23 | 4,194,163 | 1307 | 3209 | 44 |
| 24 | 8,388,563 | 2357 | 3559 | 46 |
| 25 | 16,777,207 | 4093 | 4099 | 48 |
| 26 | 33,554,089 | 3797 | 8837 | 50 |
| 27 | 67,108,147 | 8011 | 8377 | 52 |
| 28 | 134,217,449 | 11,119 | 12,071 | 54 |
| 29 | 268,435,247 | 12,589 | 21,323 | 56 |
| 30 | 536,870,861 | 22,717 | 23,633 | 58 |
| 31 | 1,073,741,687 | 27,779 | 38,653 | 60 |
| 32 | 2,147,483,551 | 32,063 | 66,977 | 62 |
| 33 | 4,294,967,213 | 57,139 | 75,167 | 64 |
| 34 | 8,589,933,181 | 89,597 | 95,873 | 66 |
| 35 | 17,179,869,131 | 125,627 | 136,753 | 68 |
| 36 | 34,359,737,977 | 117,517 | 292,381 | 70 |
| 37 | 68,719,476,733 | 242,819 | 283,007 | 72 |
| 38 | 137,438,953,319 | 189,853 | 723,923 | 74 |
| 39 | 274,877,906,893 | 364,303 | 754,531 | 76 |
| 40 | 549,755,813,701 | 712,321 | 771,781 | 78 |
| 41 | 1,099,511,623,591 | 1,002,817 | 1,096,423 | 80 |
| 42 | 2,199,023,255,179 | 1,286,533 | 1,709,263 | 82 |
| 43 | 4,398,046,510,399 | 2,014,013 | 2,183,723 | 84 |
| 44 | 8,796,093,021,439 | 2,217,443 | 3,966,773 | 86 |
| 45 | 17,592,186,044,353 | 2,005,519 | 8,771,887 | 88 |
| 46 | 35,184,372,088,787 | 3,769,453 | 9,334,079 | 90 |
| 47 | 70,368,744,177,439 | 8,388,593 | 8,388,623 | 92 |
| 48 | 140,737,488,355,141 | 11,150,957 | 12,621,113 | 94 |
| 49 | 281,474,976,708,763 | 15,847,327 | 17,761,669 | 96 |
| 50 | 562,949,953,421,083 | 16,619,039 | 33,873,797 | 98 |
References
- Bressoud, D.M. Factorization and Primality Testing; Springer: New York, NY, USA, 1989. [Google Scholar] [CrossRef]
- Lehman, R.S. Factoring large integers. Math. Comput. 1974, 28, 637–646. [Google Scholar] [CrossRef]
- Lenstra, A.K.; Lenstra, H.W. The Development of the Number Field Sieve; Lecture Notes in Mathematics; Springer: Berlin/Heidelberg, Germany, 1993. [Google Scholar] [CrossRef]
- Boudot, F.; Gaudry, P.; Guillevic, A.; Heninger, N.; Thomé, E.; Zimmermann, P. Comparing the Difficulty of Factorization and Discrete Logarithm: A 240-Digit Experiment. In Proceedings of the Advances in Cryptology—CRYPTO 2020, Virtual, 17–21 August 2020; Micciancio, D., Ristenpart, T., Eds.; Springer: Cham, Switzerland, 2020; pp. 62–91. [Google Scholar] [CrossRef]
- Kleinjung, T.; Aoki, K.; Franke, J.; Lenstra, A.K.; Thomé, E.; Bos, J.W.; Gaudry, P.; Kruppa, A.; Montgomery, P.L.; Osvik, D.A.; et al. Factorization of a 768-Bit RSA Modulus. In Proceedings of the Advances in Cryptology—CRYPTO 2010, Santa Barbara, CA, USA, 15–19 August 2010; Rabin, T., Ed.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 333–350. [Google Scholar] [CrossRef]
- Gidney, C.; Ekerå, M. How to factor 2048 bit RSA integers in 8 hours using 20 million noisy qubits. Quantum 2021, 5, 433. [Google Scholar] [CrossRef]
- Biasse, J.F.; Bonnetain, X.; Kirshanova, E.; Schrottenloher, A.; Song, F. Quantum algorithms for attacking hardness assumptions in classical and post-quantum cryptography. IET Inf. Secur. 2023, 17, 171–209. [Google Scholar] [CrossRef]
- Shor, P.W. Algorithms for quantum computation: Discrete logarithms and factoring. In Proceedings of the 35th Annual Symposium on Foundations of Computer Science, Santa Fe, NM, USA, 20–22 November 1994; pp. 124–134. [Google Scholar] [CrossRef]
- Ekert, A.; Jozsa, R. Quantum computation and Shor’s factoring algorithm. Rev. Mod. Phys. 1996, 68, 733–753. [Google Scholar] [CrossRef]
- Shor, P.W. Polynomial-Time Algorithms for Prime Factorization and Discrete Logarithms on a Quantum Computer. SIAM J. Comput. 1997, 26, 1484–1509. [Google Scholar] [CrossRef]
- Van Meter, R.; Itoh, K.M. Fast quantum modular exponentiation. Phys. Rev. A 2005, 71, 052320. [Google Scholar] [CrossRef]
- Kitaev, A.Y. Quantum measurements and the Abelian Stabilizer Problem. arXiv 1995, arXiv:quant-ph/9511026. [Google Scholar]
- Griffiths, R.B.; Niu, C.S. Semiclassical Fourier Transform for Quantum Computation. Phys. Rev. Lett. 1996, 76, 3228–3231. [Google Scholar] [CrossRef]
- Parker, S.; Plenio, M.B. Efficient Factorization with a Single Pure Qubit and logN Mixed Qubits. Phys. Rev. Lett. 2000, 85, 3049–3052. [Google Scholar] [CrossRef]
- Martín-López, E.; Laing, A.; Lawson, T.; Alvarez, R.; Zhou, X.Q.; O’Brien, J.L. Experimental realization of Shor’s quantum factoring algorithm using qubit recycling. Nat. Photonics 2012, 6, 773–776. [Google Scholar] [CrossRef]
- Córcoles, A.D.; Takita, M.; Inoue, K.; Lekuch, S.; Minev, Z.K.; Chow, J.M.; Gambetta, J.M. Exploiting Dynamic Quantum Circuits in a Quantum Algorithm with Superconducting Qubits. Phys. Rev. Lett. 2021, 127, 100501. [Google Scholar] [CrossRef] [PubMed]
- Peng, X.; Liao, Z.; Xu, N.; Qin, G.; Zhou, X.; Suter, D.; Du, J. Quantum Adiabatic Algorithm for Factorization and Its Experimental Implementation. Phys. Rev. Lett. 2008, 101, 220405. [Google Scholar] [CrossRef] [PubMed]
- Hegade, N.N.; Paul, K.; Albarrán-Arriagada, F.; Chen, X.; Solano, E. Digitized adiabatic quantum factorization. Phys. Rev. A 2021, 104, L050403. [Google Scholar] [CrossRef]
- Monz, T.; Nigg, D.; Martinez, E.A.; Brandl, M.F.; Schindler, P.; Rines, R.; Wang, S.X.; Chuang, I.L.; Blatt, R. Realization of a scalable Shor algorithm. Science 2016, 351, 1068–1070. [Google Scholar] [CrossRef] [PubMed]
- Amico, M.; Saleem, Z.H.; Kumph, M. Experimental study of Shor’s factoring algorithm using the IBM Q Experience. Phys. Rev. A 2019, 100, 012305. [Google Scholar] [CrossRef]
- Smolin, J.A.; Smith, G.; Vargo, A. Oversimplifying quantum factoring. Nature 2013, 499, 163–165. [Google Scholar] [CrossRef]
- Gouzien, E.; Sangouard, N. Factoring 2048-bit RSA Integers in 177 Days with 13 436 Qubits and a Multimode Memory. Phys. Rev. Lett. 2021, 127, 140503. [Google Scholar] [CrossRef]
- shorgpu: Simulation of Shor’s Algorithm with the Semiclassical Fourier Transform Using Multiple GPUs and MPI. Available online: https://jugit.fz-juelich.de/qip/shorgpu.git (accessed on 18 September 2023).
- De Raedt, K.; Michielsen, K.; De Raedt, H.; Trieu, B.; Arnold, G.; Richter, M.; Lippert, T.; Watanabe, H.; Ito, N. Massively parallel quantum computer simulator. Comput. Phys. Commun. 2007, 176, 121. [Google Scholar] [CrossRef]
- De Raedt, H.; Jin, F.; Willsch, D.; Willsch, M.; Yoshioka, N.; Ito, N.; Yuan, S.; Michielsen, K. Massively parallel quantum computer simulator, eleven years later. Comput. Phys. Commun. 2019, 237, 47–61. [Google Scholar] [CrossRef]
- Tankasala, A.; Ilatikhameneh, H. Quantum-Kit: Simulating Shor’s Factorization of 24-Bit Number on Desktop. arXiv 2020, arXiv:1908.07187. [Google Scholar]
- Wang, D.S.; Hill, C.D.; Hollenberg, L.C.L. Simulations of Shor’s algorithm using matrix product states. Quantum Inf. Process. 2017, 16, 176. [Google Scholar] [CrossRef]
- Dang, A.; Hill, C.D.; Hollenberg, L.C.L. Optimising Matrix Product State Simulations of Shor’s Algorithm. Quantum 2019, 3, 116. [Google Scholar] [CrossRef]
- Dumitrescu, E. Tree tensor network approach to simulating Shor’s algorithm. Phys. Rev. A 2017, 96, 062322. [Google Scholar] [CrossRef]
- Zhao, Y.Q.; Li, R.G.; Jiang, J.Z.; Li, C.; Li, H.Z.; Wang, E.D.; Gong, W.F.; Zhang, X.; Wei, Z.Q. Simulation of quantum computing on classical supercomputers with tensor-network edge cutting. Phys. Rev. A 2021, 104, 032603. [Google Scholar] [CrossRef]
- Ekerå, M. Qunundrum. 2020. Available online: https://github.com/ekera/qunundrum.git (accessed on 18 September 2023).
- Nielsen, M.A.; Chuang, I.L. Quantum Computation and Quantum Information: 10th Anniversary Edition; Cambridge University Press: New York, NY, USA, 2010. [Google Scholar] [CrossRef]
- Ekerå, M. On completely factoring any integer efficiently in a single run of an order-finding algorithm. Quantum Inf. Process. 2021, 20, 205. [Google Scholar] [CrossRef]
- Ekerå, M. On the success probability of quantum order finding. arXiv 2022, arXiv:2201.07791v2. [Google Scholar]
- Arute, F.; Arya, K.; Babbush, R.; Bacon, D.; Bardin, J.C.; Barends, R.; Biswas, R.; Boixo, S.; Brandao, F.G.S.L.; Buell, D.A.; et al. Quantum supremacy using a programmable superconducting processor. Nature 2019, 574, 505–510. [Google Scholar] [CrossRef] [PubMed]
- Rønnow, T.F.; Wang, Z.; Job, J.; Boixo, S.; Isakov, S.V.; Wecker, D.; Martinis, J.M.; Lidar, D.A.; Troyer, M. Defining and detecting quantum speedup. Science 2014, 345, 420–424. [Google Scholar] [CrossRef]
- Knill, E. On Shor’s Quantum Factor Finding Algorithm: Increasing the Probability of Success and Tradeoffs Involving the Fourier Transform Modulus; Tech. Rep. LAUR-95-3350; Los Alamos National Laboratory: Santa Fe, NM, USA, 1995. [Google Scholar]
- DiVincenzo, D.P. Quantum Computation. Science 1995, 270, 255–261. [Google Scholar] [CrossRef]
- Barenco, A.; Ekert, A.; Suominen, K.A.; Törmä, P. Approximate quantum Fourier transform and decoherence. Phys. Rev. A 1996, 54, 139–146. [Google Scholar] [CrossRef]
- Vedral, V.; Barenco, A.; Ekert, A. Quantum networks for elementary arithmetic operations. Phys. Rev. A 1996, 54, 147–153. [Google Scholar] [CrossRef]
- Seifert, J.P. Using Fewer Qubits in Shor’s Factorization Algorithm via Simultaneous Diophantine Approximation. In Proceedings of the Topics in Cryptology—CT-RSA 2001, San Francisco, CA, USA, 8–12 April 2001; Naccache, D., Ed.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 319–327. [Google Scholar] [CrossRef]
- McAnally, D. A Refinement of Shor’s Algorithm. arXiv 2001, arXiv:quant-ph/0112055. [Google Scholar]
- Leander, G. Improving the Success Probability for Shor’s Factoring Algorithm. arXiv 2002, arXiv:quant-ph/0208183. [Google Scholar]
- Coppersmith, D. An approximate Fourier transform useful in quantum factoring. arXiv 2002, arXiv:quant-ph/0201067. [Google Scholar]
- Beauregard, S. Circuit for Shor’s algorithm using 2n+3 qubits. Quantum Inf. Comput. 2003, 3, 175. [Google Scholar] [CrossRef]
- Fowler, A.G.; Hollenberg, L.C.L. Scalability of Shor’s algorithm with a limited set of rotation gates. Phys. Rev. A 2004, 70, 032329. [Google Scholar] [CrossRef]
- Kendon, V.M.; Munro, W.J. Entanglement and its Role in Shor’s Algorithm. Quantum Inf. Comput. 2006, 6, 630. [Google Scholar] [CrossRef]
- Gerjuoy, E. Shor’s factoring algorithm and modern cryptography. An illustration of the capabilities inherent in quantum computers. Am. J. Phys 2005, 73, 521–540. [Google Scholar] [CrossRef]
- Devitt, S.J.; Fowler, A.G.; Hollenberg, L.C.L. Robustness of Shor’s algorithm. Quantum Inf. Comput. 2006, 6, 616–629. [Google Scholar] [CrossRef]
- Zalka, C. Shor’s algorithm with fewer (pure) qubits. arXiv 2016, arXiv:quant-ph/0601097. [Google Scholar]
- Bourdon, P.S.; Williams, H.T. Sharp Probability Estimates for Shor’s Order-Finding Algorithm. Quantum Inf. Comput. 2007, 7, 522–550. [Google Scholar]
- Markov, I.L.; Saeedi, M. Constant-optimized quantum circuits for modular multiplication and exponentiation. Quantum Inf. Comput. 2012, 12, 0361. [Google Scholar] [CrossRef]
- Markov, I.L.; Saeedi, M. Faster quantum number factoring via circuit synthesis. Phys. Rev. A 2013, 87, 012310. [Google Scholar] [CrossRef]
- Grosshans, F.; Lawson, T.; Morain, F.; Smith, B. Factoring Safe Semiprimes with a Single Quantum Query. arXiv 2015, arXiv:1511.04385. [Google Scholar]
- Lawson, T. Odd orders in Shor’s factoring algorithm. Quantum Inf. Process. 2015, 14, 831–838. [Google Scholar] [CrossRef]
- Johnston, A. Shor’s Algorithm and Factoring: Don’t Throw Away the Odd Orders. Cryptology ePrint Archive, Report 2017/083. 2017. Available online: https://ia.cr/2017/083 (accessed on 18 September 2023).
- Häner, T.; Roetteler, M.; Svore, K.M. Factoring using 2n+2 qubits with Toffoli based modular multiplication. Quantum Inf. Comput. 2017, 17, 0673. [Google Scholar] [CrossRef]
- Davis, E.D. Benchmarks for quantum computers from Shor’s algorithm. arXiv 2021, arXiv:2111.13856. [Google Scholar]
- Bastos, D.C.; Brasil Kowada, L.A. How to detect whether Shor’s algorithm succeeds against large integers without a quantum computer. Procedia Comput. Sci. 2021, 195, 145–151. [Google Scholar] [CrossRef]
- Antipov, A.V.; Kiktenko, E.O.; Fedorov, A.K. Efficient realization of quantum primitives for Shor’s algorithm using PennyLane library. PLoS ONE 2022, 17, e0271462. [Google Scholar] [CrossRef] [PubMed]
- Nam, Y.S.; Blümel, R. Performance scaling of Shor’s algorithm with a banded quantum Fourier transform. Phys. Rev. A 2012, 86, 044303. [Google Scholar] [CrossRef]
- Ekerå, M. Quantum algorithms for computing general discrete logarithms and orders with tradeoffs. J. Math. Cryptol. 2021, 15, 359–407. [Google Scholar] [CrossRef]
- Ekerå, M.; Håstad, J. Quantum Algorithms for Computing Short Discrete Logarithms and Factoring RSA Integers. In Proceedings of the Post-Quantum Cryptography, Utrecht, The Netherlands, 26–28 June 2017; Lange, T., Takagi, T., Eds.; Springer: Cham, Switzerland, 2017; pp. 347–363. [Google Scholar] [CrossRef]
- Ekerå, M. On post-processing in the quantum algorithm for computing short discrete logarithms. Des. Codes Cryptogr. 2020, 88, 2313–2335. [Google Scholar] [CrossRef]
- Jozsa, R. Quantum factoring, discrete logarithms, and the hidden subgroup problem. Comput. Sci. Eng. 2001, 3, 34–43. [Google Scholar] [CrossRef]
- Hardy, G.H.; Wright, E.M. An Introduction to the Theory of Numbers, 6th ed.; Oxford University Press: Oxford, UK, 2008. [Google Scholar]
- Bernstein, D.J.; Biasse, J.F.; Mosca, M. A Low-Resource Quantum Factoring Algorithm. In Proceedings of the Post-Quantum Cryptography, Utrecht, The Netherlands, 26–28 June 2017; Lange, T., Takagi, T., Eds.; Springer: Cham, Switzerland, 2017; pp. 330–346. [Google Scholar] [CrossRef]
- Grover, L.K. A Fast Quantum Mechanical Algorithm for Database Search. In Proceedings of the Twenty-Eighth Annual ACM Symposium on Theory of Computing, Philadelphia, PA, USA, 22–24 May 1996; pp. 212–219. [Google Scholar] [CrossRef]
- Li, J.; Peng, X.; Du, J.; Suter, D. An Efficient Exact Quantum Algorithm for the Integer Square-free Decomposition Problem. Sci. Rep. 2012, 2, 1–5. [Google Scholar] [CrossRef]
- Vandersypen, L.M.K.; Steffen, M.; Breyta, G.; Yannoni, C.S.; Sherwood, M.H.; Chuang, I.L. Experimental realization of Shor’s quantum factoring algorithm using nuclear magnetic resonance. Nature 2001, 414, 883–887. [Google Scholar] [CrossRef] [PubMed]
- Lu, C.Y.; Browne, D.E.; Yang, T.; Pan, J.W. Demonstration of a Compiled Version of Shor’s Quantum Factoring Algorithm Using Photonic Qubits. Phys. Rev. Lett. 2007, 99, 250504. [Google Scholar] [CrossRef] [PubMed]
- Lanyon, B.P.; Weinhold, T.J.; Langford, N.K.; Barbieri, M.; James, D.F.V.; Gilchrist, A.; White, A.G. Experimental Demonstration of a Compiled Version of Shor’s Algorithm with Quantum Entanglement. Phys. Rev. Lett. 2007, 99, 250505. [Google Scholar] [CrossRef]
- Politi, A.; Matthews, J.C.F.; O’Brien, J.L. Shor’s Quantum Factoring Algorithm on a Photonic Chip. Science 2009, 325, 1221. [Google Scholar] [CrossRef] [PubMed]
- Lucero, E.; Barends, R.; Chen, Y.; Kelly, J.; Mariantoni, M.; Megrant, A.; O’Malley, P.; Sank, D.; Vainsencher, A.; Wenner, J.; et al. Computing prime factors with a Josephson phase qubit quantum processor. Nat. Phys. 2012, 8, 719–723. [Google Scholar] [CrossRef]
- Skosana, U.; Tame, M. Demonstration of Shor’s factoring algorithm for N = 21 on IBM quantum processors. Sci. Rep. 2021, 11, 16599. [Google Scholar] [CrossRef]
- Abhijith, J.; Adedoyin, A.; Ambrosiano, J.; Anisimov, P.; Casper, W.; Chennupati, G.; Coffrin, C.; Djidjev, H.; Gunter, D.; Karra, S.; et al. Quantum Algorithm & Implementations for Beginners. ACM Trans. Quantum Comput. 2022, 3, 18. [Google Scholar] [CrossRef]
- Andriyash, E.; Bian, Z.; Chudak, F.; Drew-Brook, M.; King, A.D.; Macready, W.G.; Roy, A. Boosting Integer Factoring Performance via Quantum Annealing Offsets; Technical Report; D-Wave Technical Report Series 14-1002A-B; D-Wave Systems Inc.: Burnaby, BC, Canada, 2016. [Google Scholar]
- Dridi, R.; Alghassi, H. Prime factorization using quantum annealing and computational algebraic geometry. Sci. Rep. 2017, 7, 43048. [Google Scholar] [CrossRef]
- Jiang, S.; Britt, K.A.; McCaskey, A.J.; Humble, T.S.; Kais, S. Quantum Annealing for Prime Factorization. Sci. Rep. 2018, 8, 17667. [Google Scholar] [CrossRef] [PubMed]
- Peng, W.; Wang, B.; Hu, F.; Wang, Y.; Fang, X.; Chen, X.; Wang, C. Factoring larger integers with fewer qubits via quantum annealing with optimized parameters. Sci. China Phys. Mech. Astron. 2019, 62, 60311. [Google Scholar] [CrossRef]
- Mengoni, R.; Ottaviani, D.; Iorio, P. Breaking RSA Security With A Low Noise D-Wave 2000Q Quantum Annealer: Computational Times, Limitations And Prospects. arXiv 2020, arXiv:2005.02268. [Google Scholar]
- Wang, B.; Hu, F.; Yao, H.; Wang, C. Prime factorization algorithm based on parameter optimization of Ising model. Sci. Rep. 2020, 10, 7106. [Google Scholar] [CrossRef]
- King, A.D.; Suzuki, S.; Raymond, J.; Zucca, A.; Lanting, T.; Altomare, F.; Berkley, A.J.; Ejtemaee, S.; Hoskinson, E.; Huang, S.; et al. Coherent quantum annealing in a programmable 2,000qubit Ising chain. Nat. Phys. 2022, 18, 1324–1328. [Google Scholar] [CrossRef]
- King, A.D.; Raymond, J.; Lanting, T.; Harris, R.; Zucca, A.; Altomare, F.; Berkley, A.J.; Boothby, K.; Ejtemaee, S.; Enderud, C.; et al. Quantum critical dynamics in a 5,000-qubit programmable spin glass. Nature 2023, 617, 61–66. [Google Scholar] [CrossRef] [PubMed]
- Message Passing Interface Forum. MPI: A Message-Passing Interface Standard Version 4.0, 2021.
- Willsch, D.; Willsch, M.; Jin, F.; Michielsen, K.; De Raedt, H. GPU-accelerated simulations of quantum annealing and the quantum approximate optimization algorithm. Comput. Phys. Commun. 2022, 278, 108411. [Google Scholar] [CrossRef]
- Michielsen, K.; Nocon, M.; Willsch, D.; Jin, F.; Lippert, T.; De Raedt, H. Benchmarking gate-based quantum computers. Comput. Phys. Commun. 2017, 220, 44–55. [Google Scholar] [CrossRef]
- Weiss, U. Quantum Dissipative Systems, 4th ed.; World Scientific: Singapore, 2012. [Google Scholar] [CrossRef]
- Paladino, E.; Galperin, Y.M.; Falci, G.; Altshuler, B.L. 1/f noise: Implications for solid-state quantum information. Rev. Mod. Phys. 2014, 86, 361–418. [Google Scholar] [CrossRef]
- Carroll, M.; Rosenblatt, S.; Jurcevic, P.; Lauer, I.; Kandala, A. Dynamics of superconducting qubit relaxation times. NPJ Quantum Inf. 2022, 8, 132. [Google Scholar] [CrossRef]
- Fox, M. Quantum Optics: An Introduction; Oxford Master Series in Physics; Oxford University Press: Oxford, UK, 2006. [Google Scholar]
- Wallraff, A.; Schuster, D.I.; Blais, A.; Frunzio, L.; Majer, J.; Devoret, M.H.; Girvin, S.M.; Schoelkopf, R.J. Approaching Unit Visibility for Control of a Superconducting Qubit with Dispersive Readout. Phys. Rev. Lett. 2005, 95, 060501. [Google Scholar] [CrossRef] [PubMed]
- Gambetta, J.; Blais, A.; Schuster, D.I.; Wallraff, A.; Frunzio, L.; Majer, J.; Devoret, M.H.; Girvin, S.M.; Schoelkopf, R.J. Qubit-photon interactions in a cavity: Measurement-induced dephasing and number splitting. Phys. Rev. A 2006, 74, 042318. [Google Scholar] [CrossRef]
- Reed, M.D.; DiCarlo, L.; Johnson, B.R.; Sun, L.; Schuster, D.I.; Frunzio, L.; Schoelkopf, R.J. High-Fidelity Readout in Circuit Quantum Electrodynamics Using the Jaynes-Cummings Nonlinearity. Phys. Rev. Lett. 2010, 105, 173601. [Google Scholar] [CrossRef]
- Jacobs, K. Quantum Measurement Theory and Its Applications; Cambridge University Press: Cambridge, MA, USA, 2014. [Google Scholar] [CrossRef]
- Naghiloo, M. Introduction to Experimental Quantum Measurement with Superconducting Qubits. arXiv 2019, arXiv:1904.09291. [Google Scholar]
- Boissonneault, M.; Gambetta, J.M.; Blais, A. Improved Superconducting Qubit Readout by Qubit-Induced Nonlinearities. Phys. Rev. Lett. 2010, 105, 100504. [Google Scholar] [CrossRef]
- Holevo, A.S. Quantum Systems, Channels, Information: A Mathematical Introduction; De Gruyter: Berlin, Germany, 2019. [Google Scholar] [CrossRef]
- Wilde, M.M. Quantum Information Theory; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar] [CrossRef]
- Jülich Supercomputing Centre. JUWELS: Modular Tier-0/1 Supercomputer at the Jülich Supercomputing Centre. J. Large-Scale Res. Facil. 2019, 5, A135. [Google Scholar] [CrossRef]
- Jülich Supercomputing Centre. JUWELS Cluster and Booster: Exascale Pathfinder with Modular Supercomputing Architecture at Juelich Supercomputing Centre. J. Large-Scale Res. Facil. 2021, 7, A138. [Google Scholar] [CrossRef]
- NVIDIA A100 Tensor Core GPU. Data Sheet. 2022. Available online: https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/a100/pdf/nvidia-a100-datasheet-nvidia-us-2188504-web.pdf (accessed on 18 September 2023).
- Miller, G.L. Riemann’s hypothesis and tests for primality. J. Comput. Syst. Sci 1976, 13, 300–317. [Google Scholar] [CrossRef]
- Michielsen, K.; De Raedt, K.; De Raedt, H. Simulation of Quantum Computation: A Deterministic Event-Based Approach. J. Comput. Theor. Nanosci. 2005, 2, 227–239. [Google Scholar] [CrossRef]
- Ekerå, M. Quppy. 2023. To Appear. Available online: https://github.com/ekera/quppy.git (accessed on 6 October 2023).
- Google Quantum AI. Exponential suppression of bit or phase errors with cyclic error correction. Nature 2021, 595, 383–387. [Google Scholar] [CrossRef]
- Krinner, S.; Lacroix, N.; Remm, A.; Di Paolo, A.; Genois, E.; Leroux, C.; Hellings, C.; Lazar, S.; Swiadek, F.; Herrmann, J.; et al. Realizing repeated quantum error correction in a distance-three surface code. Nature 2022, 605, 669–674. [Google Scholar] [CrossRef] [PubMed]
- Sivak, V.V.; Eickbusch, A.; Royer, B.; Singh, S.; Tsioutsios, I.; Ganjam, S.; Miano, A.; Brock, B.L.; Ding, A.Z.; Frunzio, L.; et al. Real-time quantum error correction beyond break-even. Nature 2023, 616, 50–55. [Google Scholar] [CrossRef] [PubMed]
- Einarsson, G. Probability Analysis of a Quantum Computer. arXiv 2003, arXiv:quant-ph/0303074. [Google Scholar]
- Press, W.H.; Teukolsky, S.A.; Vetterling, W.T.; Flannery, B.P. Numerical Recipes 3rd Edition: The Art of Scientific Computing; Cambridge University Press: New York, NY, USA, 2007. [Google Scholar]
- Jaynes, E.T.; Bretthorst, G.L. Probability Theory: The Logic of Science; Cambridge University Press: Cambridge, MA, USA, 2003. [Google Scholar] [CrossRef]
- Nicolas, J.L. Petites valeurs de la fonction d’Euler. J. Number Theory 1983, 17, 375–388. [Google Scholar] [CrossRef]
- Rosser, J.B.; Schoenfeld, L. Approximate formulas for some functions of prime numbers. Illinois J. Math. 1962, 6, 64. [Google Scholar] [CrossRef]
- Nielsen, M.A. Errata List for “Quantum Computation and Quantum Information”. 2014. Available online: https://michaelnielsen.org/qcqi/errata/errata/errata.html (accessed on 18 September 2023).
- Carmichael, R.D. Note on a new number theory function. Bull. Am. Math. Soc. 1910, 16, 232–238. [Google Scholar] [CrossRef]











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Willsch, D.; Willsch, M.; Jin, F.; De Raedt, H.; Michielsen, K. Large-Scale Simulation of Shor’s Quantum Factoring Algorithm. Mathematics 2023, 11, 4222. https://doi.org/10.3390/math11194222
Willsch D, Willsch M, Jin F, De Raedt H, Michielsen K. Large-Scale Simulation of Shor’s Quantum Factoring Algorithm. Mathematics. 2023; 11(19):4222. https://doi.org/10.3390/math11194222
Chicago/Turabian StyleWillsch, Dennis, Madita Willsch, Fengping Jin, Hans De Raedt, and Kristel Michielsen. 2023. "Large-Scale Simulation of Shor’s Quantum Factoring Algorithm" Mathematics 11, no. 19: 4222. https://doi.org/10.3390/math11194222
APA StyleWillsch, D., Willsch, M., Jin, F., De Raedt, H., & Michielsen, K. (2023). Large-Scale Simulation of Shor’s Quantum Factoring Algorithm. Mathematics, 11(19), 4222. https://doi.org/10.3390/math11194222