
What Is the Best Way to Optimally Parameterize the MPC Cost Function for Vehicle Guidance?



{kind=link}
{kind=link}
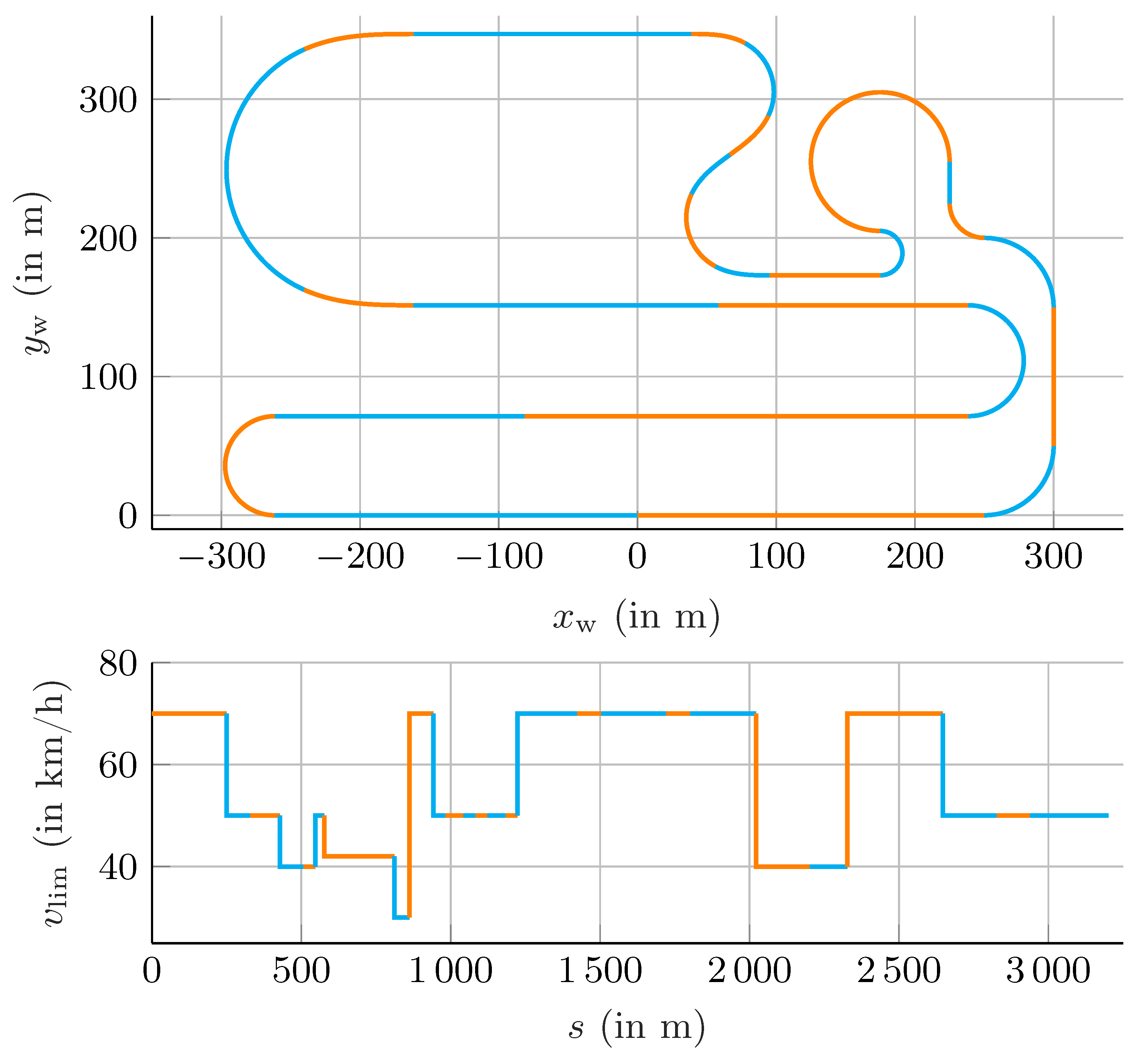{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Problem Statement
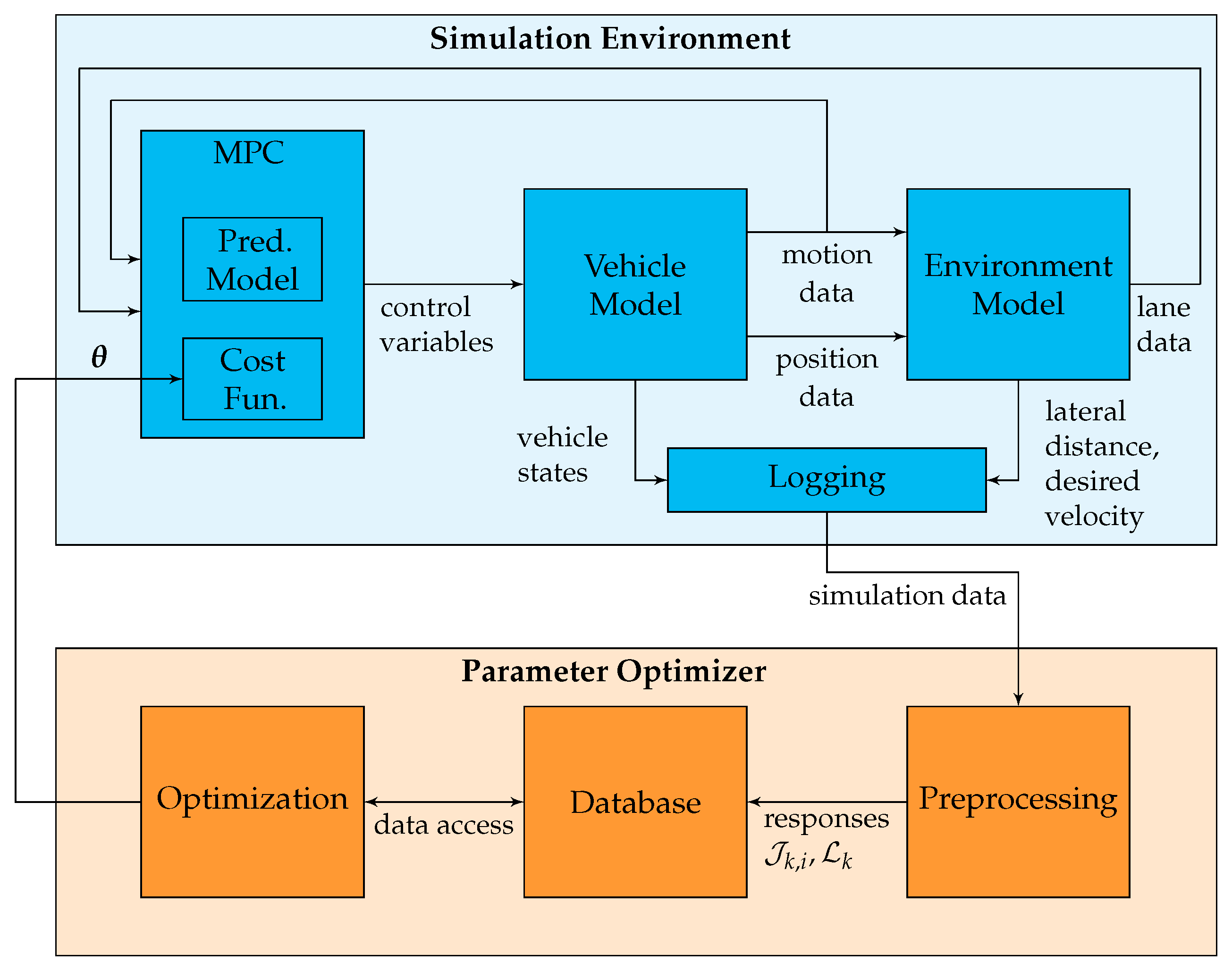
3. Simulation-Based MPC Tuning for Vehicle Guidance
3.1. Controller Tuning Framework
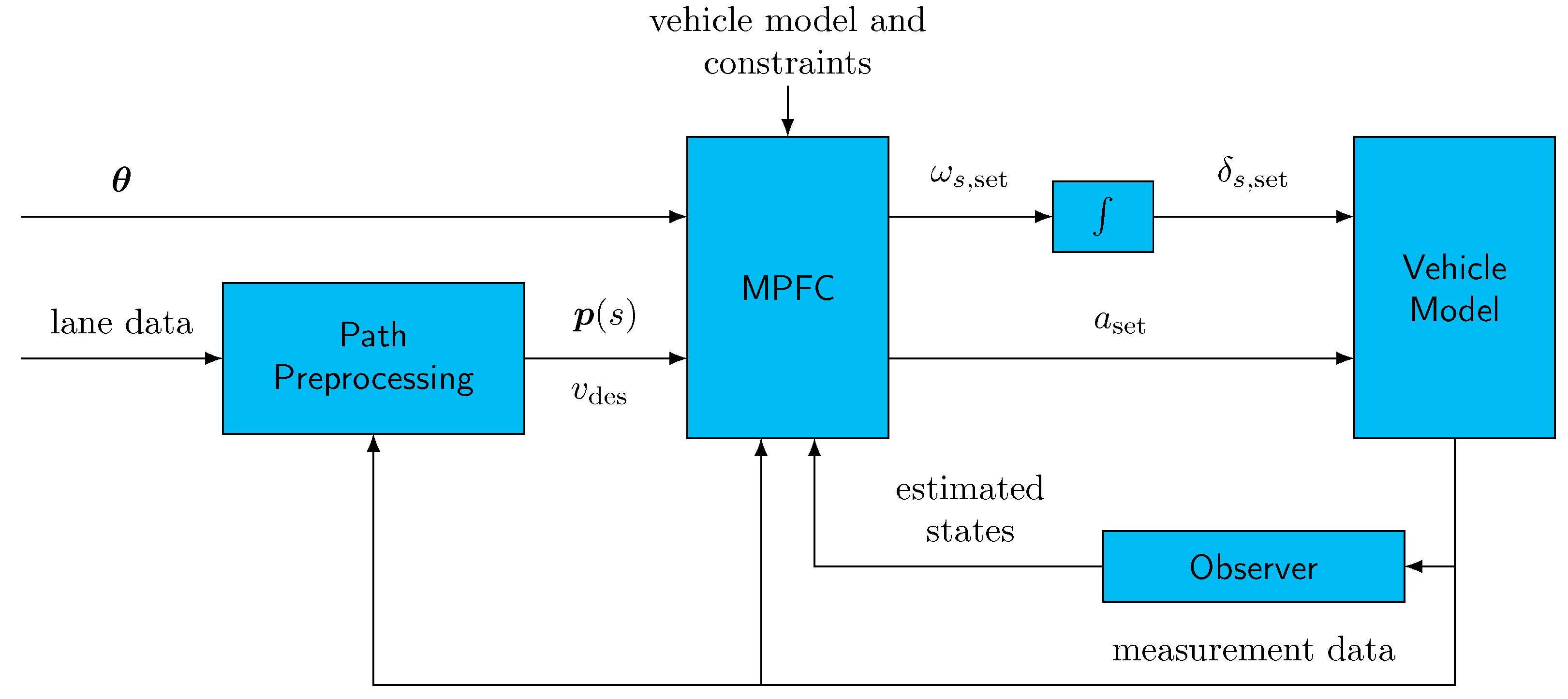
3.2. MPC for Vehicle Guidance
3.3. Multi-Objective Optimization Problem Formulation
4. Multi-Objective Optimization Algorithms
4.1. Bayesian Optimization
| Algorithm 1 Multi-objective Bayesian optimization with crash constraints and flexible batch size |
1: Generate initial data 2: for k = 1, 2, ...do 3: Calculate the set of non-dominated solutions 4: 5: Learn probabilistic surrogate models using training data 6: 7: Maximize acquisition function to get new sample points: . 8: Query objective function with to obtain responses 9: Augment data with new evaluations: 10: end for |
4.1.1. Thompson Sampling Efficient Multi-Objective Optimization (TSEMO) with Flexible Batch Size
4.1.2. Expected Improvement Matrix Criterion
4.1.3. Virtual Datapoints (VDP) for Multi-Objective BO
| Algorithm 2 Calculation of virtual datapoints (Step 4 of Algorithm 1) |
1: Extract all crashed evaluations: 2: Fit GPR Models with successful evaluations . 3: For each crashed query 4: Calculate virtual datapoints using a pessimistic GP prediction: 5: Bound pessimistic prediction to the worst successful evaluations 6: If any virtual datapoints dominate one element in : 7: do ; Go to line 3; |
4.2. NSGA-II
| Algorithm 3 NSGA-II |
1: Generate an initial population 2: Query objective function with to obtain responses 3: Form initial dataset 4: For each generation do 5: Crossover: 6: Mutation: 7: Query objective function with to obtain responses 8: Augment data with new evaluations: 9: Non-dominated Sorting of 10: Sort each Domination-Rank of by Crowding Distance 11: Truncate the elements of to population size based on sorting 12: End for |
4.3. Multiple-Objective Particle Swarm Optimization
| Algorithm 4 MOPSO |
1: Generate an initial population 2: Query objective function with to obtain responses 3: Add non-dominated solutions to repository and generate adaptive grid 4: for k = 1, 2, ... do 5: Update speeds and positions, perform mutation and check boundaries to obtain new population 6: Query objective function with to obtain responses 7: Update repository and adaptive grid 8: End for |
5. Results
5.1. Evaluated Optimizers
- TSEMO-1-C: MOBO with TSEMO as the acquisition function and a constant batch size of one, without VDP.
- TSEMO-A-C: MOBO with TSEMO as the acquisition function and a variable batch size, without VDP.
- TSEMO-1-VDP: MOBO with TSEMO as the acquisition function and a constant batch size of one, with VDP.
- TSEMO-A-VDP: MOBO with TSEMO as the acquisition function and a variable batch size, with VDP.
- EIM-1-VDP: MOBO with EIM as the acquisition function and a constant batch size of one, with VDP.
5.2. Metrics
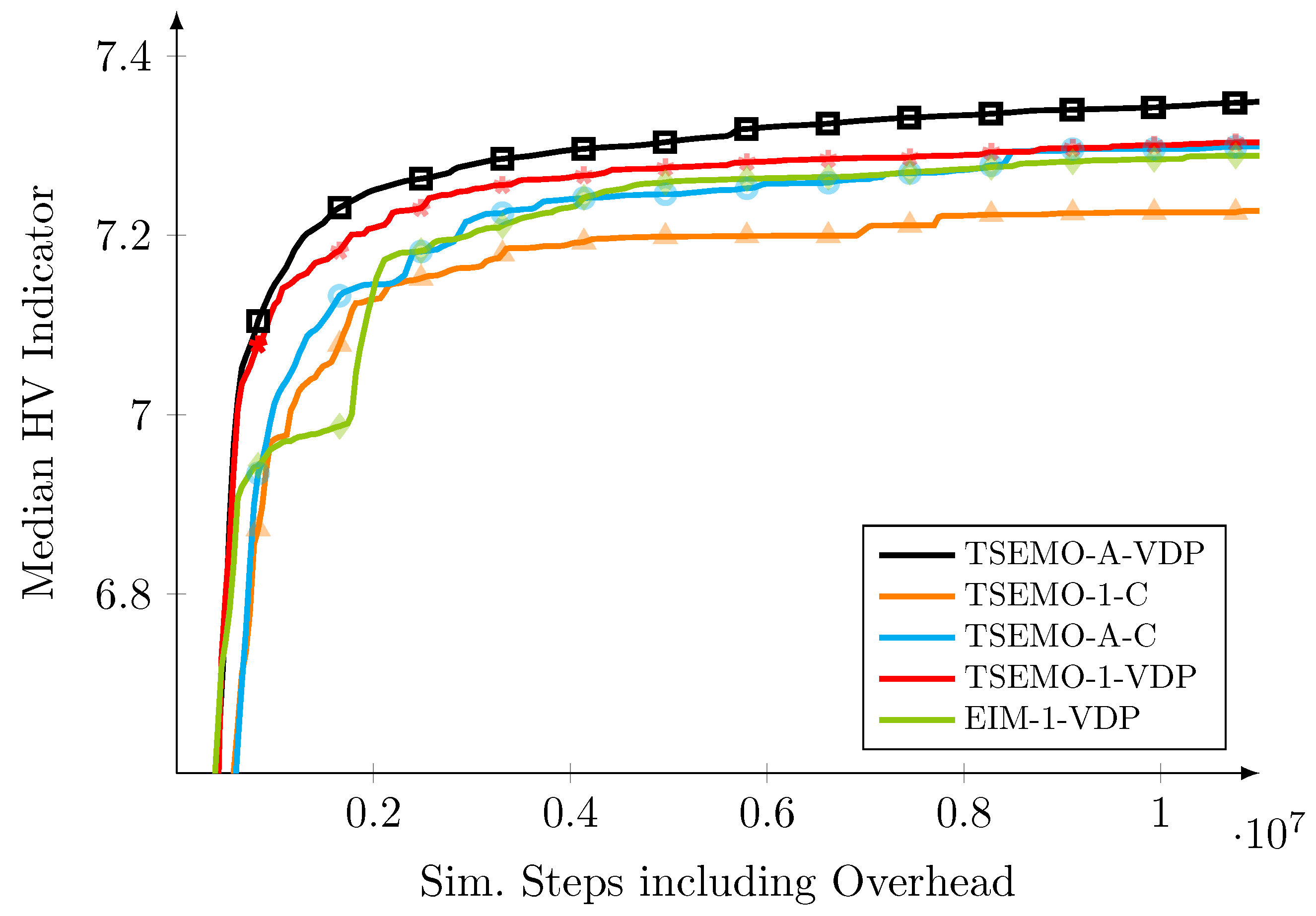
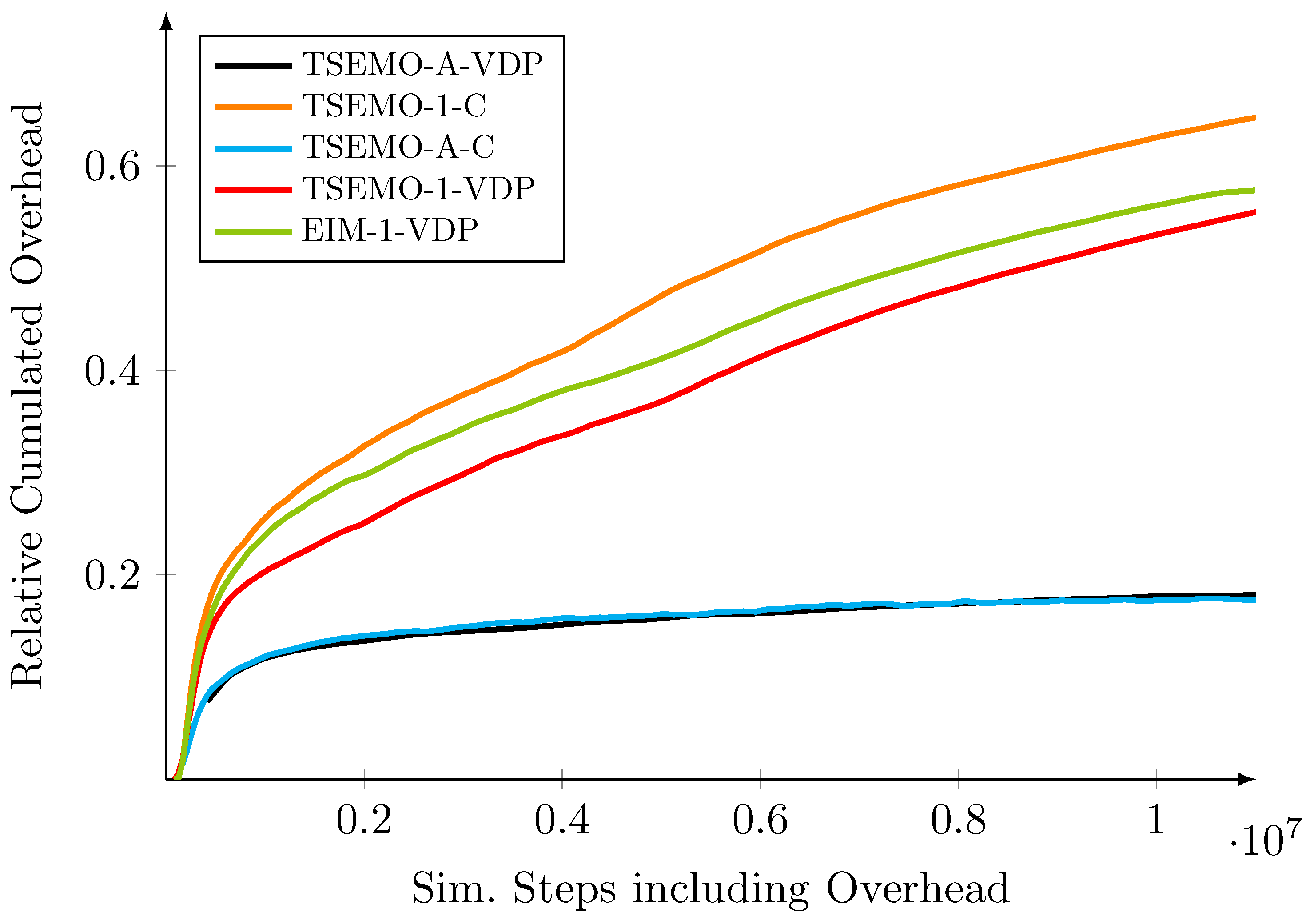
5.3. Comparison of BO Variants
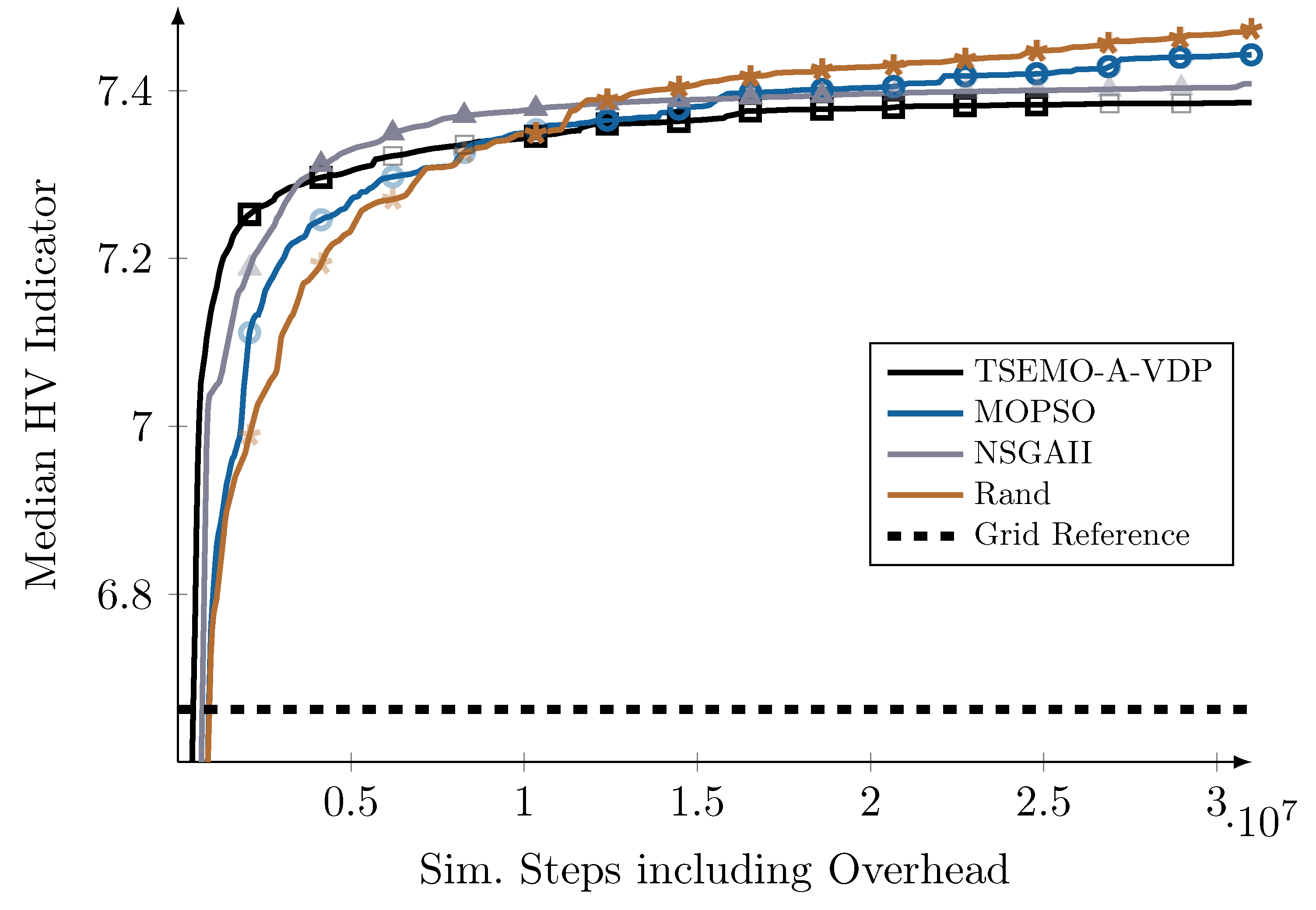
5.4. Overall Comparison
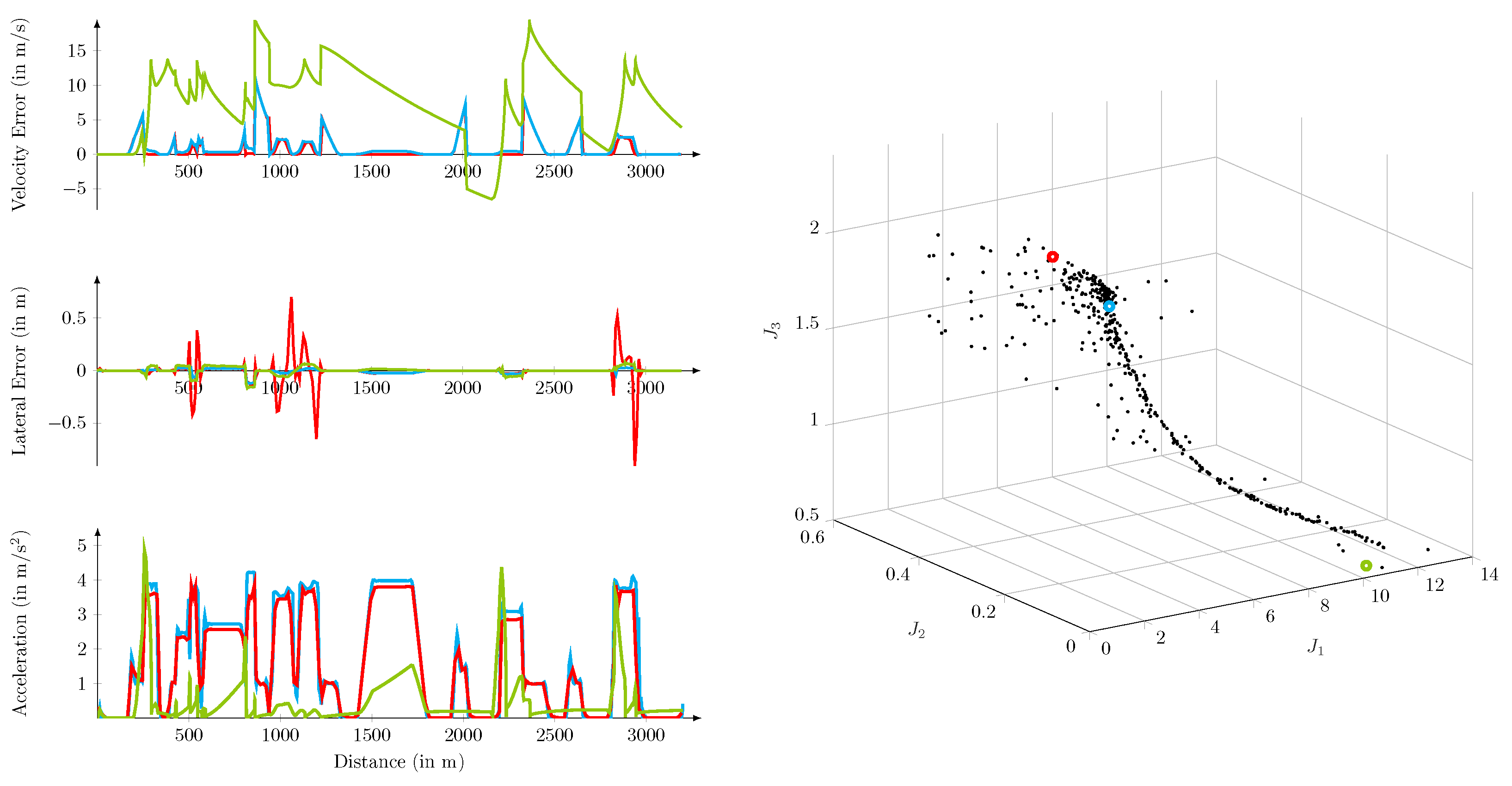
5.5. Practical Implications
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ulsoy, A.G.; Peng, H.; Çakmakci, M. Automotive Control Systems; Cambridge University Press: Cambridge, MA, USA, 2012. [Google Scholar] [CrossRef]
- Kiencke, U.; Nielsen, L. Automotive Control Systems: For Engine, Driveline, and Vehicle; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Isermann, R. Automotive Control: Modeling and Control of Vehicles; ATZ/MTZ-Fachbuch, Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- No, T.S.; Chong, K.T.; Roh, D.H. A Lyapunov function approach to longitudinal control of vehicles in a platoon. In Proceedings of the IEEE 51st Conference on Vehicular Technology (VTC2000), Tokyo, Japan, 15–18 May 2000; Volume 1, pp. 336–340. [Google Scholar] [CrossRef]
- Liaw, D.C.; Chung, W.C. A Feedback Linearization Design for the Control of Vehicle’s Lateral Dynamics. Nonlinear Dyn. 2008, 52, 313–329. [Google Scholar] [CrossRef]
- Zhang, S.; Zhou, S.; Sun, J. Vehicle dynamics control based on sliding mode control technology. In Proceedings of the 2009 Chinese Control and Decision Conference, Shanghai, China, 16–18 December 2009; pp. 2435–2439. [Google Scholar] [CrossRef]
- Hrovat, D.; Di Cairano, S.; Tseng, H.; Kolmanovsky, I. The development of Model Predictive Control in automotive industry: A survey. In Proceedings of the 2012 IEEE International Conference on Control Applications, Dubrovnik, Croatia, 3–5 October 2012; pp. 295–302. [Google Scholar] [CrossRef]
- Feng, G.; Han, Y.; Li, S.E.; Xu, S.; Dang, D. Accurate Pseudospectral Optimization of Nonlinear Model Predictive Control for High-performance Motion Planning. IEEE Trans. Intell. Veh. 2022. [Google Scholar] [CrossRef]
- Yamashita, A.; Zanin, A.; Odloak, D. Tuning of model predictive control with multi-objective optimization. Braz. J. Chem. Eng. 2016, 33, 333–346. [Google Scholar] [CrossRef]
- Shah, G.; Engell, S. Tuning MPC for desired closed-loop performance for MIMO systems. In Proceedings of the 2011 American Control Conference, San Francisco, CA, USA, 29 June–1 July 2011; pp. 4404–4409. [Google Scholar] [CrossRef]
- Vega, P.; Francisco, M.; Sanz, E. Norm based approaches for automatic tuning of Model Based Predictive Control. In Proceedings of the European Congress of Chemical Engineering, Copenhagen, Denmark, 16–20 September 2007; pp. 1–10. [Google Scholar]
- Al-Ghazzawi, A.; Ali, E.; Nouh, A.; Zafiriou, E. On-line tuning strategy for model predictive controllers. J. Process Control 2001, 11, 265–284. [Google Scholar] [CrossRef]
- Stenger, D.; Ay, M.; Abel, D. Robust Parametrization of a Model Predictive Controller for a CNC Machining Center Using Bayesian Optimization. IFAC-PapersOnLine 2020, 53, 10388–10394. [Google Scholar] [CrossRef]
- Ramasamy, V.; Sidharthan, R.; Kannan, R.; Muralidharan, G. Optimal Tuning of Model Predictive Controller Weights Using Genetic Algorithm with Interactive Decision Tree for Industrial Cement Kiln Process. Processes 2019, 7, 938. [Google Scholar] [CrossRef] [Green Version]
- Marco, A.; Baumann, D.; Khadiv, M.; Hennig, P.; Righetti, L.; Trimpe, S. Robot Learning With Crash Constraints. IEEE Robot. Autom. Lett. 2021, 6, 1439–1446. [Google Scholar] [CrossRef]
- Stenger, D.; Abel, D. Benchmark of Bayesian Optimization and Metaheuristics for Control Engineering Tuning Problems with Crash Constraints. arXiv 2022, arXiv:2211.02571. [Google Scholar]
- Ryo, A.; Matthew, T.; Kenta, K.; Howie, C.; Fumitoshi, M. Multiobjective Optimization Based on Expensive Robotic Experiments under Heteroscedastic Noise. IEEE Trans. Robot. 2017, 33, 468–483. [Google Scholar] [CrossRef]
- Matthew, T.; Jeff, S.; Howie, C. Expensive multiobjective optimization for robotics. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 973–980. [Google Scholar] [CrossRef]
- Matteo, T.; Andreas, K.; Sebastian, T. Robust Model-free Reinforcement Learning with Multi-objective Bayesian Optimization. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 10702–10708. [Google Scholar] [CrossRef]
- Kim, Y.; Pan, Z.; Hauser, K.K. MO-BBO: Multi-Objective Bilevel Bayesian Optimization for Robot and Behavior Co-Design. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 9877–9883. [Google Scholar]
- Gharib, A.; Stenger, D.; Ritschel, R.; Voßwinkel, R. Multi-Objective Optimization of a Path-following MPC for Vehicle Guidance: A Bayesian Optimization Approach. In Proceedings of the 2021 European Control Conference (ECC), Virtual, 29 June–2 July 2021; pp. 2197–2204. [Google Scholar] [CrossRef]
- Emmerich, M.; Klinkenberg, J.W.; Bohrweg, N. The Computation of the Expected Improvement in Dominated Hypervolume of Pareto Front Approximations; Rapport Technique: Leiden, The Netherlands, 2008; Available online: https://liacs.leidenuniv.nl/~emmerichmtm/moda/material/TR-ExI.pdf (accessed on 10 January 2023).
- Zhan, D.; Cheng, Y.; Liu, J. Expected Improvement Matrix-Based Infill Criteria for Expensive Multiobjective Optimization. IEEE Trans. Evol. Comput. 2017, 21, 956–975. [Google Scholar] [CrossRef]
- Bradford, E.; Schweidtmann, A.M.; Lapkin, A. Efficient multiobjective optimization employing Gaussian processes, spectral sampling and a genetic algorithm. J. Glob. Optim. 2018, 71, 407–438. [Google Scholar] [CrossRef] [Green Version]
- Ritschel, R.; Schrödel, F.; Hädrich, J.; Jäkel, J. Nonlinear Model Predictive Path-Following Control for Highly Automated Driving. In Proceedings of the 10th IFAC Symposium on Intelligent Autonomous Vehicles IAV 2019, Gdansk, Poland, 3–5 July 2019; Volume 52, pp. 350–355. [Google Scholar] [CrossRef]
- Faulwasser, T. Optimization-Based Solutions to Constrained Trajectory-Tracking and Path-Following Problems; Shaker Verlag: Aachen, Germany, 2013. [Google Scholar]
- Wang, C.; Zhao, X.; Fu, R.; Li, Z. Research on the Comfort of Vehicle Passengers Considering the Vehicle Motion State and Passenger Physiological Characteristics: Improving the Passenger Comfort of Autonomous Vehicles. Int. J. Environ. Res. Public Health 2020, 17, 6821. [Google Scholar] [CrossRef] [PubMed]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; de Freitas, N. Taking the Human Out of the Loop: A Review of Bayesian Optimization. Proc. IEEE 2016, 104, 148–175. [Google Scholar] [CrossRef] [Green Version]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning (Adaptive Computation and Machine Learning); The MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Deb, K.; Agrawal, S.; Pratap, A.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Schweidtmann, A. Multi-Objective Optimization Algorithm for Expensive-to-Evaluate Function. 2019. Available online: https://github.com/Eric-Bradford/TS-EMO (accessed on 10 December 2021).
- Stenger, D.; Nitsch, M.; Abel, D. Joint Constrained Bayesian Optimization of Planning, Guidance, Control, and State Estimation of an Autonomous Underwater Vehicle. In Proceedings of the 2022 European Control Conference (ECC), London, UK, 11–14 July 2022; pp. 1982–1987. [Google Scholar] [CrossRef]
- Kato, K.; Ariizumi, R.; Matsuno, F. Multiobjective Optimization Method for Expensive Functions with Unknown Failure Regions and Its Application to Mobile Robot. J. Robot. Soc. Jpn. 2017, 35, 143–152. [Google Scholar] [CrossRef] [Green Version]
- Branke, J.; Deb, K.; Miettinen, K.; Slowinski, R. Multiobjective Optimization; The MIT Press: Cambridge, MA, USA, 2008. [Google Scholar]
- Martínez-Cagigal, V. Multi-Objective Particle Swarm Optimization (MOPSO). Version 1.3.2.0. 2019. Available online: https://www.mathworks.com/matlabcentral/fileexchange/62074-multi-objective-particle-swarm-optimization-mopso (accessed on 28 May 2022).
- Coello, C.A.C.; Pulido, G.T.; Lechuga, M.S. Handling multiple objectives with particle swarm optimization. IEEE Trans. Evol. Comput. 2004, 8, 256–279. [Google Scholar] [CrossRef]
- Sierra, M.R.; Coello Coello, C.A. Improving PSO-Based Multi-objective Optimization Using Crowding, Mutation and ϵ-Dominance. In Evolutionary Multi-Criterion Optimization, EMO 2005; Coello Coello, C.A., Hernández Aguirre, A., Zitzler, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 505–519. [Google Scholar]
- Guerreiro, A.P.; Fonseca, C.M.; Paquete, L. The Hypervolume Indicator: Computational Problems and Algorithms. ACM Comput. Surv. 2021, 54, 1–42. [Google Scholar] [CrossRef]
- Riquelme, N.; Von Lücken, C.; Baran, B. Performance metrics in multi-objective optimization. In Proceedings of the 2015 Latin American Computing Conference (CLEI), Arequipa, Peru, 19–23 October 2015; pp. 1–11. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stenger, D.; Ritschel, R.; Krabbes, F.; Voßwinkel, R.; Richter, H. What Is the Best Way to Optimally Parameterize the MPC Cost Function for Vehicle Guidance? Mathematics 2023, 11, 465. https://doi.org/10.3390/math11020465
Stenger D, Ritschel R, Krabbes F, Voßwinkel R, Richter H. What Is the Best Way to Optimally Parameterize the MPC Cost Function for Vehicle Guidance? Mathematics. 2023; 11(2):465. https://doi.org/10.3390/math11020465
Chicago/Turabian StyleStenger, David, Robert Ritschel, Felix Krabbes, Rick Voßwinkel, and Hendrik Richter. 2023. "What Is the Best Way to Optimally Parameterize the MPC Cost Function for Vehicle Guidance?" Mathematics 11, no. 2: 465. https://doi.org/10.3390/math11020465
APA StyleStenger, D., Ritschel, R., Krabbes, F., Voßwinkel, R., & Richter, H. (2023). What Is the Best Way to Optimally Parameterize the MPC Cost Function for Vehicle Guidance? Mathematics, 11(2), 465. https://doi.org/10.3390/math11020465