6.1. Asymptotic Convergence of EKSM and -EKSM
For a real symmetric positive definite matrix
A, EKSM with cyclic poles
converges at least linearly as follows:
where
(and see Proposition 3.6 in [
21]). Similarly,
-EKSM with cyclic poles
converges at least linearly with factor
because
,
-EKSM has a smaller upper bound on the convergence factor than EKSM.
For the optimal pole from (
20), using the Blaschke product technique we can denote the method as
-EKSM* and its optimal pole as
, with the convergence factor
in (
19). Because
is a root of a fourth-order equation, it is difficult to explicitly find its value; thus, we list several examples to compute the poles and convergence factors for both single pole methods. In addition, we list the convergence factors for the shift-inverse Arnoldi method (SI) based on one fixed nonzero pole:
(see [
26], Corollary 6.4a).
For a matrix
A with the smallest eigenvalue
and largest eigenvalue
,
Table 2 shows the difference in the upper bounds of their convergence factors; note that the asymptotic convergence factors are independent of the function
f.
It can be seen from
Table 2 that
-EKSM has a lower upper bound on the asymptotic convergence factor than EKSM, with
-EKSM* having an even lower upper bound. The optimal pole
for
-EKSM is roughly two to three times that of
for
-EKSM*. The shift-inverse Arnoldi has the largest converegence factor; thus, we did not compare it with the other methods in our later tests.
To check the asymptotic convergence factor for each method, it is necessary to know the exact vector for a given matrix A and vector b in order to calculate the norm of the residual at each step. For relatively large matrices it is only possible to directly evaluate the exact for diagonal matrices within a reasonable time. Because each SPD matrix is orthogonally similar to the diagonal matrix of its eigenvalues, our experiment results can be expected to reflect the behavior of EKSM, -EKSM, and -EKSM* applied to more general SPD matrices.
We constructed two diagonal matrices
. The diagonal entry
for
is
,
10,000, where the
s are uniformly distributed on the interval
and
,
. The diagonal entry
for
is
,
20,000,
. We approximated
using EKSM,
-EKSM, and
-EKSM*, where
b is a fixed vector with entries of standard normally distributed random numbers. The experimental results are shown in
Figure 1.
From the figures for different Markov-type functions, it can be seen that all methods converge with factors no worse than their theoretical bounds, which verifies the validity of the results shown in Theorem 1. Moreover, -EKSM and -EKSM* always converge faster than EKSM for all the test functions and matrices. In particular, for approximating , our -EKSM only takes about one quarter as many iterations to achieve a relative error less than as compared to EKSM. Furthermore, the theoretical bounds are not always sharp for those methods.
For nonsymmetric matrices with elliptic numerical ranges, the theoretical convergence rate cannot be derived by an explicit formula;
Table 1 shows the numerical results. To verify these results, we constructed a block diagonal matrix
with
diagonal blocks with eigenvalues that lie on the circle centered at
with radius
. We then constructed another block diagonal matrix
with eigenvalues that lie in the ellipse centered at
, with a semi-major axis
and semi-minor axis
. The optimal pole for
-EKSM can be computed using the strategy described in
Section 4.2 (
and
).
Figure 2 shows the spectra of the matrices
,
and
for
.
Figure 3 shows the results for the nonsymmetric matrices.
Table 1 shows the asymptotic convergence factors of EKSM and
-EKSM for matrices
and
, where
,
,
, and
for
, while
,
,
, and
for
.
Similar to the results for SPD matrices,
-EKSM converges faster than EKSM for the two artificial nonsymmetric problems. The upper bounds on the convergence factor in
Table 1 match the actual convergence factor quite well.
6.2. Test for Practical SPD Matrices
Next, we tested EKSM,
-EKSM,
-EKSM*, and adaptive RKSM on several SPD matrices and compared their runtimes and the dimension of their approximation subspaces. Note that for general SPD matrices the largest and smallest eigenvalues are usually not known in advance. The Lanczos method or its restarted variants can be applied to estimate them, and this computation time should be taken into consideration for
-EKSM and
-EKSM*. The variant of EKSM in (
5) is not considered in this section, as there is no convergence theory to compare with the actual performance and the convergence rate largely depends on the choice of
l and
m in (
5).
For the SPD matrices, we used Cholesky decomposition with approximate minimum degree ordering to solve the linear systems involving A or for all four methods. The stopping criterion of all methods was to check whether the angle between the approximate solutions obtained at two successive steps fell below a certain tolerance. EKSM and -EKSM, and -EKSM* all apply the Lanczos three-term recurrence and perform local re-orthogonalization to enlarge the subspace, whereas adaptive RKSM applies a full orthogonalization process with global re-orthogonalization.
We tested four 2D discrete Laplacian matrices of orders , , , and based on standard five-point stencils on a square. For all problems, the vector b was a vector with entries of standard normally distributed random numbers, allowing the behavior of all four methods to be compared for matrices with different condition numbers.
Table 3 reports the runtimes and the dimensions of the rational Krylov subspaces that the four methods entail when applied to all test problems; in the table, EK, FEK, and ARK are abbreviation of EKSM,
-EKSM, and adaptive RKSM, respectively. The stopping criterion was that the angle between the approximate solutions from two successive steps was less than
. The single pole
results for
-EKSM are
, and
, respectively, while for
-EKSM* the
results are
, and
, respectively. The shortest CPU time appearing in each line listed in the table is marked in bold.
With only one exception, that of , it is apparent that -EKSM converges the fastest of the four methods in terms of wall clock time for all the test functions and matrices with different condition numbers. While -EKSM takes more steps than adaptive RKSM to converge, it requires fewer steps than EKSM. Furthermore, the advantage of -EKSM becomes more pronounced for matrices with a larger condition number. Notably, the advantage of -EKSM in terms of computation time is stronger than in terms of the spatial dimension, which is due to the orthogonalization cost being proportional to the square of the spatial dimension. -EKSM* takes slightly more steps than -EKSM to converge in these examples, and both methods have similar computation times.
The unusual behavior of all methods for can be explained as follows. For these Laplacian matrices, the largest eigenvalues range from to . Because and (because decreases monotonically on ), the eigenvector components in vector b associated with relatively large eigenvalues would be eliminated in vector in double precision. In fact, because , all eigenvalues of A greater than are essentially ‘invisible’ for under tolerance , and the effective condition number of all four Laplacian matrices is about . As a result, it takes EKSM the same number of steps to converge for all these matrices; the shift for -EKSM and -EKSM* computed using and of these matrices is in fact not optimal for matrices with such a small effective condition number.
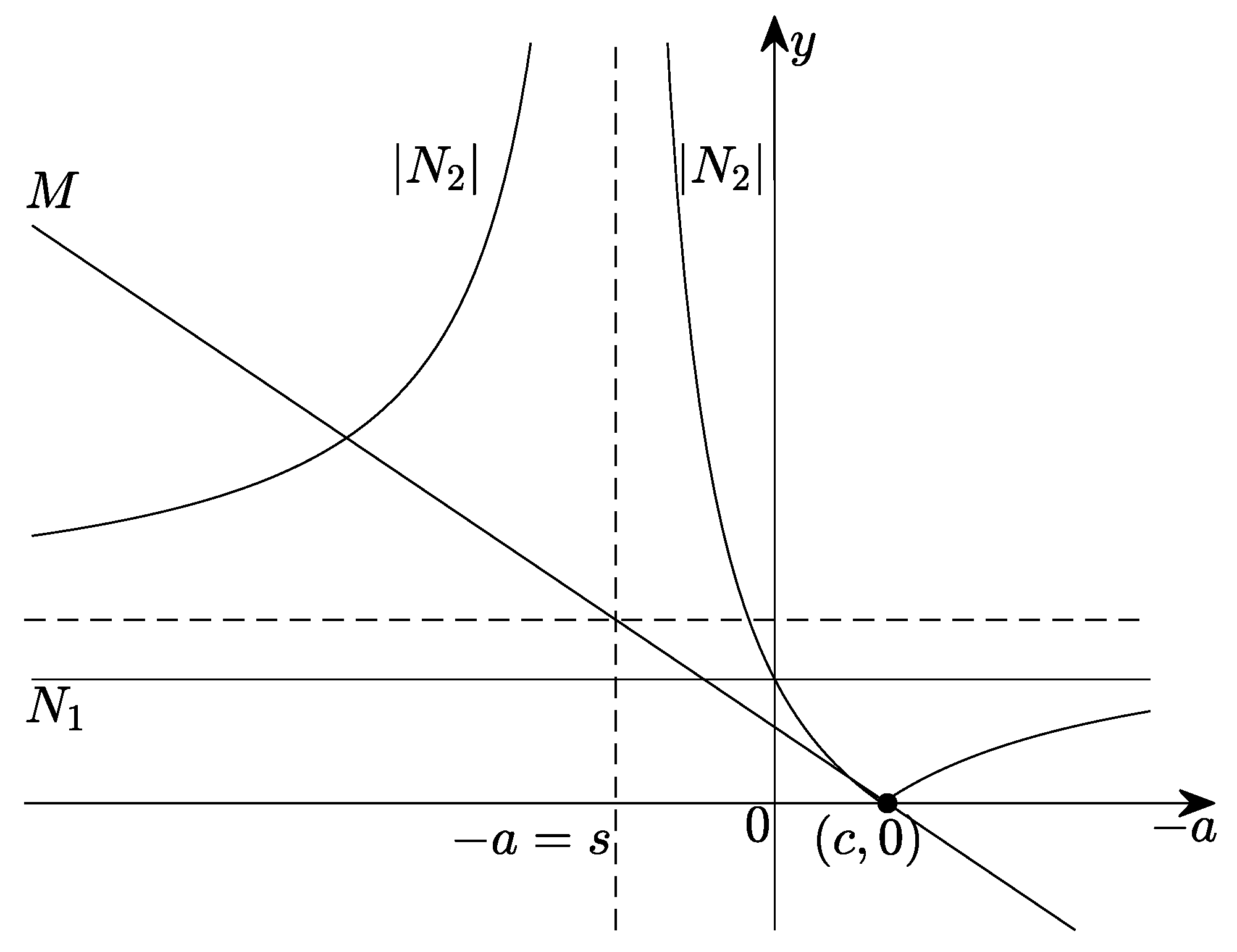
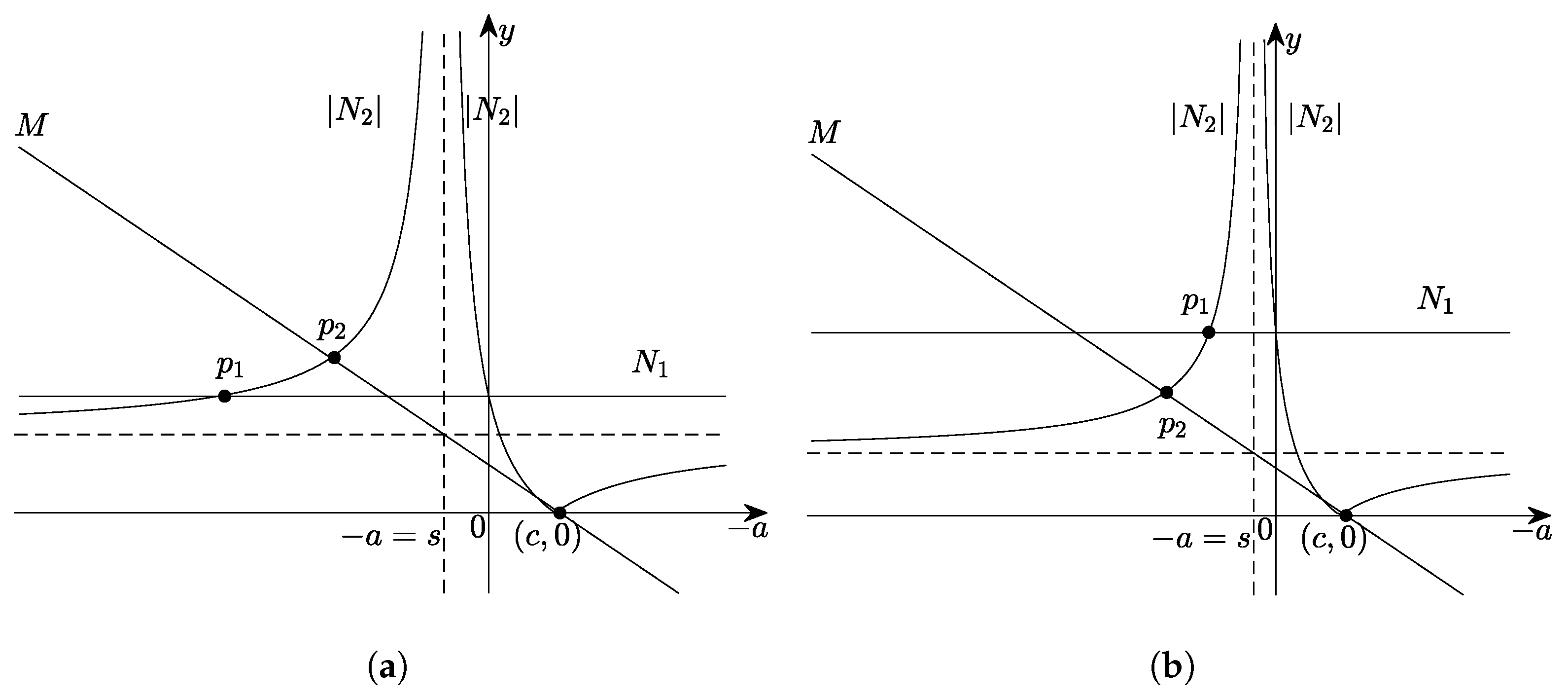
The pole
in (
17) for the SPD matrix is
optimal, as we have proved that it has the smallest asymptotic convergence factor among all choices of the single pole. In order to numerically compare the behaviors for different setting of the single pole, we tested matrices Lap. B and Lap. C in
Table 3 with
and
, respectively. For each problem, we tested
-EKSM by setting different single poles
s to
,
,
,
,
and setting
for
-EKSM*.
Figure 4 shows the experimental results. It can be seen that
-EKSM has the fastest asymptotic convergence rate among all the 6 different values of single poles when setting the optimal single pole
, which confirms that
is indeed optimal in our experiments.
6.3. Test for Practical Nonsymmetric Matrices
We consider 18 nonsymmetric real matrices, all of which have all eigenvalues on the right half of the complex plane. While these are all real sparse matrices, they all have complex eigenvalues with positive real parts. Half are in the form of
, where both
M and
K are sparse and
is not formed explicitly.
Table 4 reports several features for each matrix
A: the matrix size is
n, the smallest and largest eigenvalues in terms of absolute value are
and
, respectively, the smallest and largest real parts of the eigenvalues are
and
, respectively, and the largest imaginary part of the eigenvalues is
. Note that all these original matrices have spectra strictly in the left half of the complex plane; we simply switched their signs to make
well-defined for Markov-type functions.
For the single pole of
-EKSM and the initial pole of the four-pole variant (4Ps) in
Section 5, we used the optimal pole for the SPD case matrices (
17) by setting
and
. The same setting of
and
for building the Riemann mapping
in (
14) was applied to compute the optimal pole for
-EKSM* in (
20). In particular, because precise evaluation of
and
is time-consuming, we approximated them using the ‘
eigs’ function in MATLAB, which is based on the Krylov–Schur Algorithm; see, e.g., [
55]. We set the residual tolerance to equal
for ‘
eigs’, ensuring that all the test matrices could find the largest and smallest eigenvalues within a reasonable time. Higher accuracy in computing the eigenvalues is not required when determining the optimal pole, as the convergence performance for
-EKSM does not change noticeably with tiny changes of the value of the pole. Note that the single pole we used for each problem is independent of the Markov-type function; see
Table 4. For nonsymmetric matrices, we used LU factorizations to solve the linear systems involving coefficient matrices of
A or
for all methods. The stopping criterion was either when the angle between the approximate solutions was less than a tolerance for two successive steps, or when the dimension of the Krylov subspaces reached 1000. There have been a few discussions about restarting for approximating
, though only for polynomial approximation based on Arnoldi-like methods; see, e.g., [
17,
56]. In this paper, we only focus on the comparison of convergence rates for several different Krylov methods without restarting. Here, we need to choose a proper tolerance for each problem such that it is small enough to fully exhibit the rate of convergence for all methods while not being too small to satisfy. The last column of
Table 4 reports the tolerances, which are fixed regardless of the different Markov-type functions.
In
Table 5,
Table 6,
Table 7,
Table 8 and
Table 9, we report the runtime and dimension of the approximation spaces that the four methods entail for approximating
to the specified tolerances. The runtime
includes the time spent on the evaluation of optimal poles for
-EKSM,
-EKSM*, and the four-pole variant. The “−” symbol indicates failure to find a sufficiently accurate solution when the maximum dimension of approximation space (1000) was reached. The shortest CPU time appeared in each line of the listed tables is marked in bold.
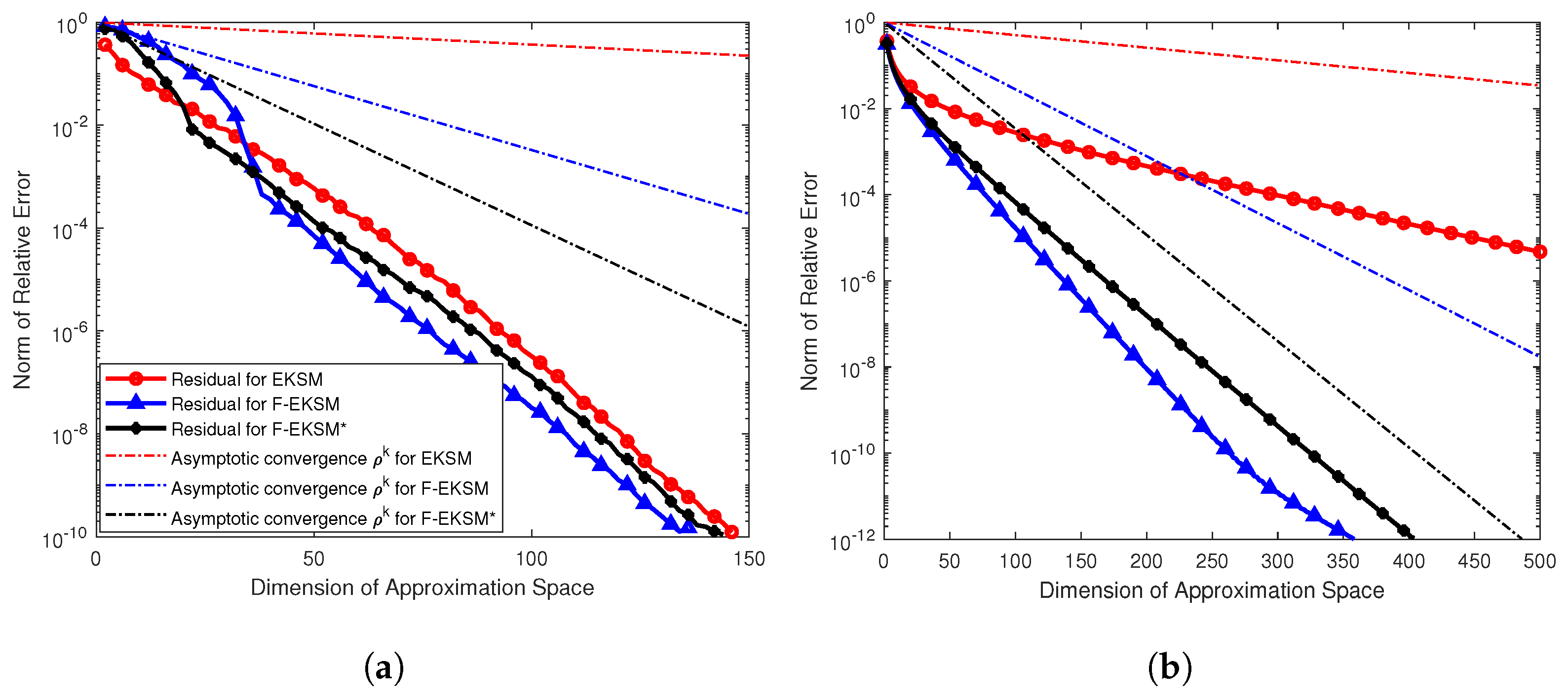
Figure 5 shows an example plot for each method, with the relative error
(where
is the approximation to
at step
k) plotted against the dimension of the approximation space for each function.
In the ninety total cases for eighteen problems and five functions shown in
Table 5,
Table 6,
Table 7,
Table 8 and
Table 9, the four-pole variant is the fastest in runtime in sixty cases and
-EKSM is the fastest in fourteen cases. Among all cases when the four-pole variant is not the fastest, it is no more than
slower than the fastest in twelve cases and 10–
slower in eight cases.
Overall, the four-pole variant is the best in terms of runtime, though there are several exceptions. The first is
tolosa, which is the only problem on which adaptive RKSM ran the fastest for all functions. For this problem, the dimension of the matrix is relatively small; this makes it more efficient to perform a new linear solver at each step, as the LU cost is cheap. Moreover, for
tolosa,
is close to
, meaning that the algorithms based on repeated poles converge slower; see
Table 1. The second exception is
venkat, where the four-pole variant is not the fastest for
. In fact, for
, EKSM,
-EKSM, and
-EKSM* converge within a much smaller dimension of the approximation space than for the other functions. A possible explanation is that in computer arithmetic it is difficult to accurately capture the relative change in function values for
at small variables, and
venkat has majority of eigenvalues that are small in terms of absolute value. For example,
, which means that a relative change of
in the independent variable of
near
can lead to a relative change of
in function value; thus,
fails to observe such a difference in input above the given tolerance
. The third exception is
convdiffA, for which EKSM is fastest for four out of all five functions. In fact, EKSM takes fewer steps to converge than
-EKSM, which can be seen at the bottom right of
Figure 5. A possible reason for this is that
and
can only be evaluated approximately by several iterations of the Arnoldi method, and sometimes their values cannot be found accurately. The ‘optimal’ pole based on inaccurate
can sometimes be far away from the real optimal pole. Notable, for this exception
-EKSM* takes fewer steps to converge than EKSM, though it requires more computation time. This is because EKSM uses infinite poles; for the matrix in the form of
, where
M is an identity matrix, it is not necessary to apply a linear solver for infinite poles, only a simple matrix vector multiplication. For the other cases in which
-EKSM or
-EKSM* runs fastest, the four-pole variant usually runs only slightly slower, as in those cases it takes less time to enlarge the approximation space than to compute more LU factorizations for using more repeated poles.
It is important to underscore that the runtime needed for
-EKSM with our optimal pole is less than that for
-EKSM* with an optimal pole derived based on [
26] for a majority of the nonsymmetric test matrices, which is similar to the minor advantage in runtime of our
-EKSM shown in
Table 3 for Laplacian matrices. In addition, the runtime of the four-pole variant suggests that if sparse LU factorization is efficient for the shifted matrices needed for RKSM, then using a small number of near optimal poles seems to be an effective way to achieve the lowest overall runtime.
In terms of the dimension of the approximation space, adaptive RKSM always need the smallest subspace to converge, with the four-pole variant in second place except for for tolosa. In most, cases EKSM needs the largest subspace to converge, while in others -EKSM needs the largest subspace. In the cases where -EKSM and the four-pole variant converge, the four-pole variant takes to fewer steps.
In summary, our experiments suggest that -EKSM, -EKSM*, and the four-pole variant are competitive in reducing the runtime of rational Krylov methods based on direct linear solvers for approximating ; on the other hand, if the goal is to save storage cost, adaptive RKSM is preferable.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}