1. Introduction
With the advancement of science and technology, an increasing volume of network data is being collected. There is an increasing need to analyze and understand the formation and features of these network-structured data. In the filed of statistics, network-structured data bring about specific challenges in statistical inference and asymptotic analysis [
1]. Many statisticians have delved into the study of network models. For example, the well-known Erdős–Rényi model [
2,
3], assumes that the formation of connections between node pairs happens independently and with a uniform probability. In recent years, two core attributes have been a pivotal focus in research on network models: network sparsity and degree heterogeneity [
4]. Network sparsity refers to the phenomenon where the actual number of connections between nodes is significantly lower than the potential maximum. It is a common occurrence in real-world networks and presents unique challenges and opportunities for analysis. Degree heterogeneity refers to the phenomenon whereby the network is characterized by a few highly connected core nodes and many low-degree nodes with fewer links. These facets are intrinsic to the comprehensive understanding of network structures and dynamics (see [
5]).
Two prominent statistical models that address degree heterogeneity are the stochastic block model [
6] and the
model [
7,
8,
9]. The stochastic block model seeks to encapsulate degree heterogeneity by grouping nodes into communities characterized by analogous connection patterns, as demonstrated in [
6,
10]. In contrast, the
model addresses degree heterogeneity directly, employing node-specific parameters to characterize the variation in node connections. Degrees of nodes are foundational in summarizing network information, with their distributions offering crucial insights into the networks’ formation processes. Recent advancements in modeling degree sequence in undirected networks have explored distributions within the framework of the exponential family, where vertex “potentials” are used as defining parameters (see [
11,
12,
13,
14]). In the context of directed networks, there many studies have been conducted on constructing and sampling graphs with specified in- and out-degree sequences, often termed “bi-degree” (see [
15,
16,
17]).
The
model is renowned for its widespread application and proven statistical efficacy. Statistically, the maximum likelihood estimation of the
-model parameters is recognized for its consistency and asymptotic normality, albeit predominantly in the context of relatively dense networks, as indicated in [
7,
18]. In practice, however, a pervasive characteristic of observed networks is their sparsity, as manifested by the presence of considerably fewer edges than the theoretically maximum attainable connections. This landscape underscores the imperative for the evolution of a sparse
model. A significant advancement in this field is related to the work reported in [
19], where a sparse
model with
penalty was studied. This innovation is not only adept at encapsulating node heterogeneity but also facilitates parameter estimation endowed with commendable statistical attributes, even within sparse network contexts. The model is distinguished by its computationally fast, theoretically tractable, and intuitively attractive nature. Nevertheless, the authors of [
19] accentuated a limitation inherent in
penalty-based estimation, particularly when the parameter support is unknown. They recommended that when the
penalty is impractical due to undefined parameter support,
-norm penalization becomes a preferred, efficient alternative for parameter estimation.
In this paper, we study the sparse model, specifically one augmented with an penalty, aiming to articulate the optimal non-asymptotic bounds in a theoretical framework. The inclusion of the penalty renders the loss function convex. This modification simplifies the resolution process, allowing for the application of convex optimization techniques, thereby boosting computational efficiency. Furthermore, theoretical analysis of the consistency of the estimated is established, and the finite-sample performance of the proposed method is verified by numerical simulation.
For the remainder of this paper, we proceed as follows. In
Section 2, we introduce the sparse
model with an
penalty and the estimation procedure for the degree parameters (
). In
Section 3, we develop theoretical results to demonstrate the consistency of the estimated
. Simulation studies are conducted in
Section 4 to empirically validate the effectiveness and efficiency of the proposed method. We encapsulate our findings and provide a discussion of potential future directions in
Section 5. Proofs of the theoretical results are comprehensively provided in
Appendix A.
3. Theoretical Analysis
In this section, we study the estimation consistency associated with in the context of the sparse model with an penalty. Our primary attention is centered around the Fisher risk () and the risk ().
According to algebraic knowledge, if Hessian has a consistent lower bound of eigenvalues, then a strictly convex function H is strongly convex. Generally, the exponential family is only represented in a sufficiently small neighborhood of in a strongly convex manner. Below, we quantify this behavior in the form of a theorem for the model.
Theorem 1 (Almost strong convexity)
. Suppose μ is the analytical standardized moment or cumulant of about a certain subspace () and is an estimator of β that satisfies . Ifthen we have Proof Theorem 1. First, we consider that if
, using Lemma A2 in
Appendix A, then
and the theorem is proven. Thus, we suppose that
. If
holds, the previous conclusion shows that the theorem has been proven. Therefore, let
. Hence,
. According to (
A5) in
Appendix A,
, which is obviously contradictory. Therefore, we have completed the proof of Theorem 1. □
Remark 1. In general, the exponential family exhibits strong convexity, primarily within localized neighborhoods of , especially in sufficiently small regions. The main outcome of Theorem 1 is to quantify when this behavior occurs. Additionally, the conditions outlined in (8) can be construed as initial “burn-in” phases. Our idea is that an initial set of samples is required until the loss of approximates the minimum loss; subsequently, quadratic convergence takes effect. This parallels the idea in Newton’s method, quantifying the steps needed to enter the quadratic convergence phase. Constants and in inequality (9) can approach , particularly with an extended “burn-in” phase. A crucial element in the proof of Theorem 1 involves expanding the prediction error in terms of moments/products. Lemma 1. Let and . If infinite series and converge for any , where and with . Here, represents the i-th-order derivative of the function. Then, we have Next, we will provide the error risk bound for estimation under the RE conditions. Generally, under a specific noise model, we set the regularization parameter () as a function of the noise level. Here, the statement of our theorem is carried out in a quantitative manner, clearly showing that the choice of the appropriate value depends on the norm of the measurement error (). Therefore, under relatively mild distribution assumptions, we can easily quantify in Theorem 2. In addition, we must make the measurement error sufficiently small so that the following conditions in Lemma 2 hold.
Lemma 2. (Risk boundary) For the subspace () defined in (6), let be the analytical standardized moment or cumulant of . Assuming Condition (A) holds and λ satisfies bothif is a solution of (7), then we have the Fisher risk bound as:and the risk bound as: Note that the entry of measurement errors results in a mild dimensional dependence. Therefore, Lemma 2 shows that under RE conditions, the
model shows good convergence rates. According to Hoeffding’s lemma and the inequality reported in [
25], below, we present Proposition 1 and quantify the mild distribution hypothesis to obtain Theorem 2.
Proposition 1. Assuming that are independent random variables and have a common Bernoulli distribution, it is obvious that meets the boundary condition () for . Then, we have
(i) Hoeffding’s lemma: for ;
(ii) Hoeffding’s inequality: , .
Furthermore, let ; then, for any , we havewith a probability of at least . Since the degree sequence () in the model is the sum of Bernoulli random variables, which are obviously bounded so that is sub-Gaussian, the following Theorem can be immediately drawn.
Theorem 2. Let be a solution of (7) for the β model (). When , K is a constant, we haveandwith a probability of at least . Proof Theorem 2. Let
; then,
satisfies the conditions of Lemma 2. Using (
13) in Lemma 2, we have
By applying (
15) in Proposition 1, for any
, with a probability of at least
which proves (
16). For the second claim of Theorem 2, according to (
14) we can obtain
with a probability of at least
. So far, we have completed the proof of Theorem 2. □
Remark 2. We observe that Lemma 2 provides a general result, and Theorem 2 represents the specific outcome of Lemma 2 under a chosen. It is a concrete result of Lemma 2 in a specific scenario and can be directly proven through Lemma 2. The main theorem established in this paper, Theorem 2, is tighter than existing bounds.
4. Simulation Study
In this section, we conduct experiments to evaluate the performance of the consistency through finite sizes of networks. For a undirected graph with nodes
, we generate the
model as follows. Given
n dimensional parameters (
), the element of adjacent matrix
A of an undirected graph follows a Bernoulli distribution with a success probability of
In this simulation, the true values of parameter
are set to the following three cases (see [
19]):
Case 1: for and for , ;
Case 2: for and for , ;
Case 3: for and for , .
Furthermore, we consider three scenarios for the support of corresponding to different sparsity levels of , from sparse to dense, that is, , where denotes the largest integer smaller than a.
We generate undirected network
A based on the above settings. Then, we implement the proposed sparse
model with
penalty to obtain the estimated parameter (
). The gradient descent method is applied directly to the convex objective function (
7) defined in
Section 2. During the optimization procedure, the tuning parameter (
) is set to
, with
set to be
. To compute support constrained MLEs, we used the proximal gradient descent algorithm, where the time-invariant step size is set to
.
We carry out simulations under four different sizes of networks:
, 200, 300, and 400. Each simulation is repeated
= 1000 times.
denotes the estimate of
from the
i-th simulation results, i.e.,
. Two evaluation criteria are used in this paper: the
error and the
error, which are defined as follows:
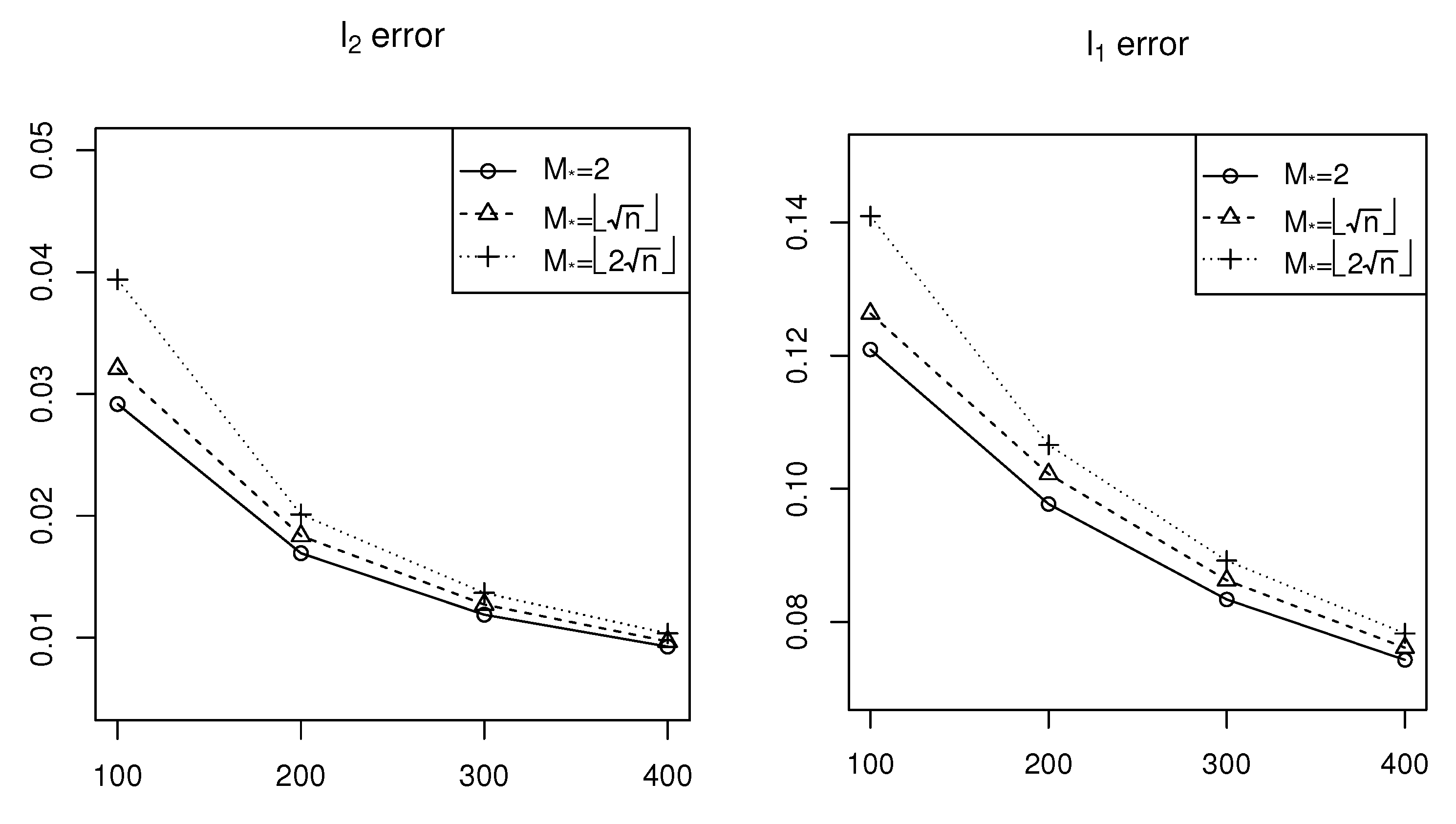
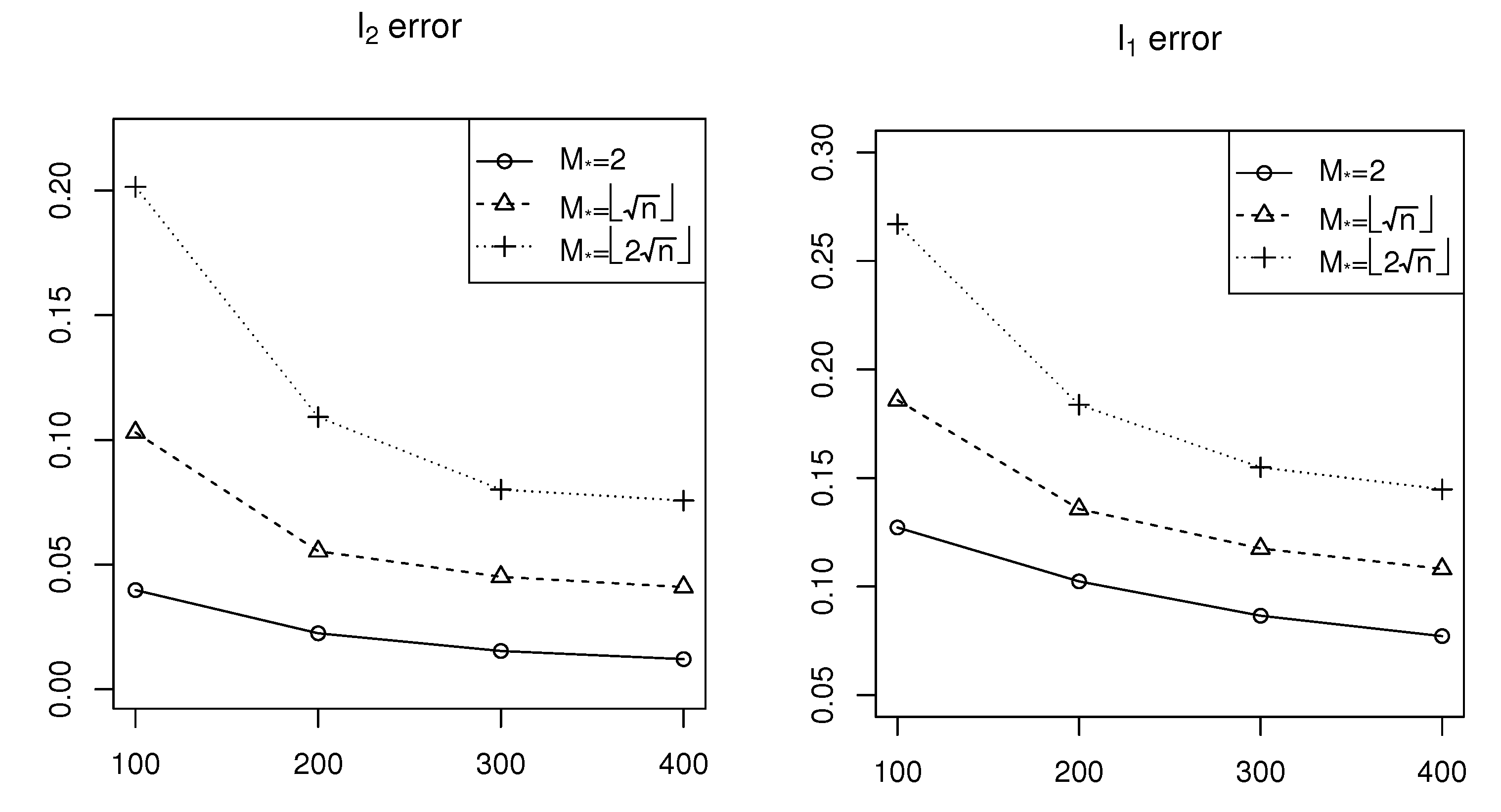
The simulation results are shown in
Figure 1,
Figure 2 and
Figure 3 for Cases 1–3, respectively. According to
Figure 1, we can see that both the
error and the
error decrease as the network size (
n) increases, which means the estimation accuracy of
generally improves as
n increases. On the other hand, both the
error and the
error increase as
increases, corresponding to variation in the sparsity level from sparse to dense, that is, the estimation accuracy of
improves for sparse cases. Similar conclusions can be obtained from
Figure 2 and
Figure 3 relative to that derived from
Figure 1.
Comparing
Figure 1,
Figure 2 and
Figure 3 vertically, it is observable that as the signal strength or signal-to-noise ratio of
increases, estimation errors also increase. This indicates an inverse relationship between the estimation accuracy and the signal-to-noise ratio. These simulation results show the efficiency of the estimation procedure of the sparse
model with
penalty proposed in this paper.
Finally, we use an example to introduce an undirected graph. We use the Enron email dataset as an example analysis [
26] available from (
https://www.cs.cmu.edu/~enron/, accessed on 7 May 2015). This dataset was originally acquired and made public by the Federal Energy Regulatory Commission during its investigation into fraudulent accounting practices. Some of the emails were deleted upon requests from affected employees. Therefore, the raw data are messy and need to be cleaned before any analysis is conducted. Ref. [
27] applied data cleaning strategies to compile the Enron email dataset. We use their cleaned data for the subsequent analysis. We treat the data as a simple, undirected graph for our analysis, where each edge denotes that there is at least one message between the corresponding two nodes. For our analysis, we exclude messages with more than ten recipients, which is a subjectively chosen cutoff. The dataset contains 156 nodes with 1634 undirected edges, as shown in
Figure 4. The quantiles of
, and 1 are 0, 13, 19, 27, and 55 for the degrees, respectively. The sparse
model can capture node heterogeneity. For example, the degree of the 52th node is 1, and the degree of the 156th node is 55. It is therefore natural to associate those important nodes with their individual parameters while leaving the less important nodes as background nodes without associated parameters.
5. Conclusions
In this study, we investigated a sparse
model with an
penalty in the dynamic field of network data models. The degree parameter was estimated through an
regularization problem, which can be easily solved by the proximal gradient descent method due to the convexity of the loss function. We established an optimal bound, corroborating the consistency of our proposed estimator, with empirical validations underscored by comprehensive simulation studies. One pivotal avenue for future research emanates from the unearthing and integration of alternative penalties that are more adaptive and efficient, facilitating enhanced model performance and a broader applicative scope. Furthermore, more effective optimization algorithms focusing on enhanced computational efficiency and adaptability to diverse network scenarios should be investigated in future studies. The sparse
model proposed in this study serves as both a theoretical foundation and an algorithmic reference for future explorations into the sparse structures of other network models, such as network models with covariates [
28], as well as functional covariates [
29] partially functional covariates [
30]. We aim to establish non-asymptotic optimal prediction error bounds. This contribution is instrumental in propelling the evolution of network models, offering insights and tools that can be adapted and optimized for diverse network structures and scenarios.



{kind=link}
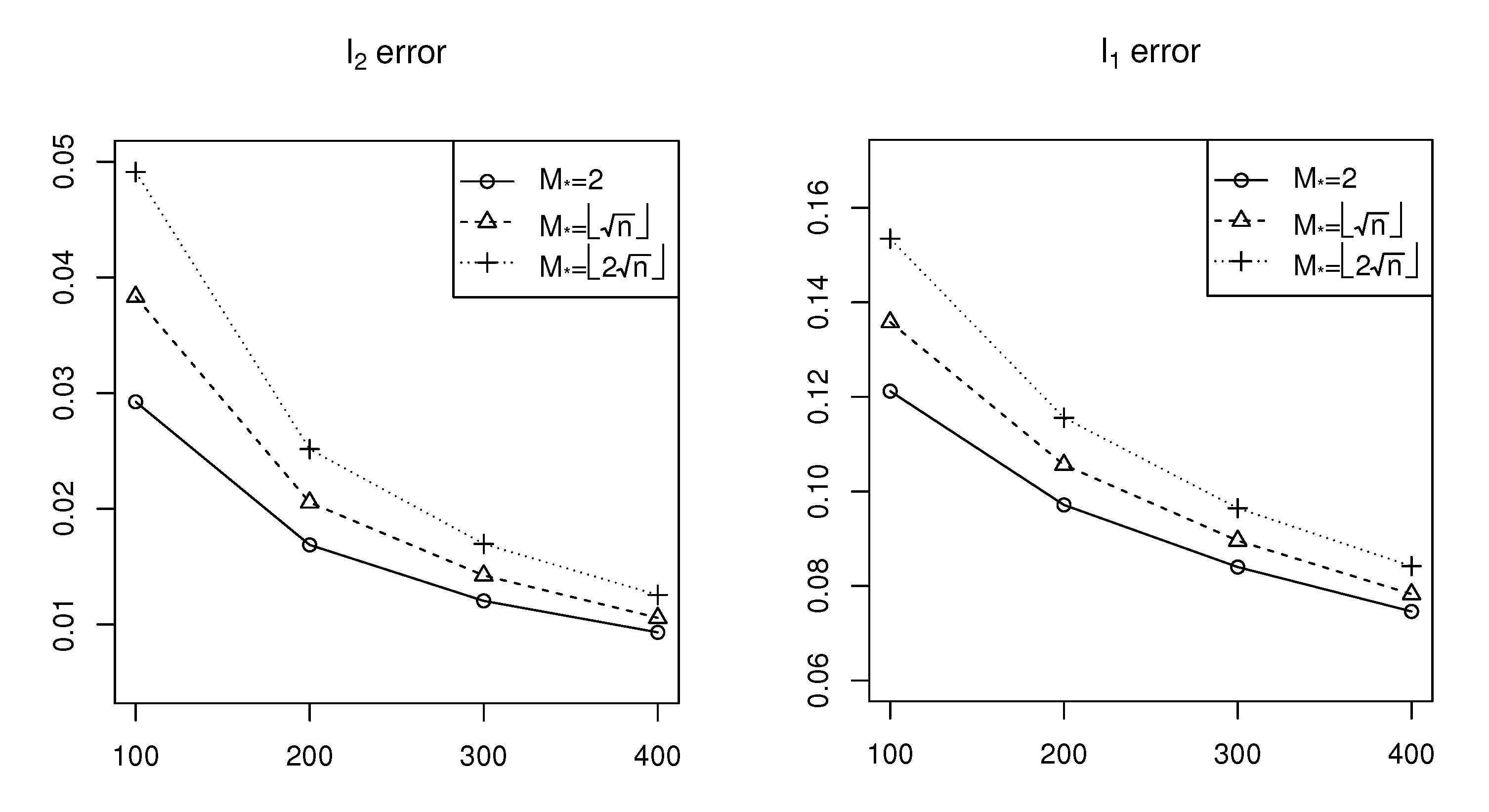{kind=link}
{kind=link}
{kind=link}



