
A Blockwise Empirical Likelihood Test for Gaussianity in Stationary Autoregressive Processes


Abstract
:1. Introduction
2. The Blockwise Empirical Likelihood Ratio Test Statistic
3. Monte Carlo Simulation Procedures
3.1. Block Size Selection
3.2. Finite Sample Performance
- Standard normal ,
- Standard log-normal (Log N),
- Student t with 10 degrees of freedom ,
- Chi-squared with 1 and 10 degrees of freedom ,
- Beta with parameters (2, 1) ,
- Uniform on [0, 1] .
4. Real Data Applications
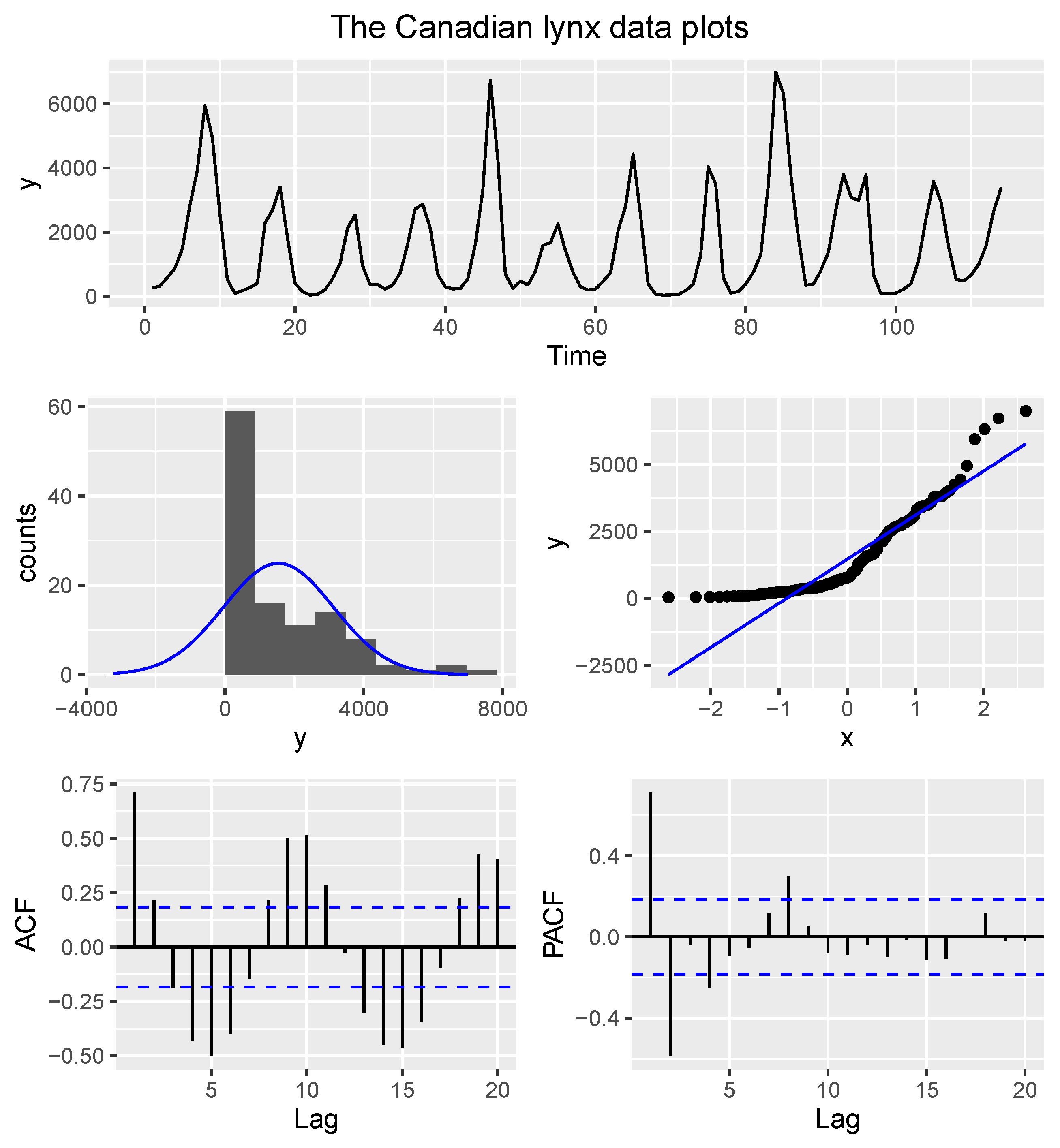
4.1. The Canadian Lynx Data
4.2. The Souvenir Data
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Epps, T.W. Testing that a stationary time series is Gaussian. Ann. Stat. 1987, 1683–1698. [Google Scholar] [CrossRef]
- Lobato, I.N.; Velasco, C. A simple test of normality for time series. Econom. Theory 2004, 20, 671–689. [Google Scholar] [CrossRef] [Green Version]
- Bai, J.; Ng, S. Tests for skewness, kurtosis, and normality for time series data. J. Bus. Econ. Stat. 2005, 23, 49–60. [Google Scholar] [CrossRef] [Green Version]
- Nieto-Reyes, A.; Cuesta-Albertos, J.A.; Gamboa, F. A random-projection based test of Gaussianity for stationary processes. Comput. Stat. Data Anal. 2014, 75, 124–141. [Google Scholar] [CrossRef]
- Psaradakis, Z.; Vávra, M. A distance test of normality for a wide class of stationary processes. Econom. Stat. 2017, 2, 50–60. [Google Scholar] [CrossRef] [Green Version]
- Moulines, E.; Choukri, K. Time-domain procedures for testing that a stationary time-series is Gaussian. IEEE Trans. Signal Process. 1996, 44, 2010–2025. [Google Scholar] [CrossRef]
- Bontemps, C.; Meddahi, N. Testing normality: A GMM approach. J. Econom. 2005, 124, 149–186. [Google Scholar] [CrossRef]
- Rao, T.S.; Gabr, M.M. A test for linearity of stationary time series. J. Time Ser. Anal. 1980, 1, 145–158. [Google Scholar] [CrossRef]
- Kitamura, Y. Empirical likelihood methods with weakly dependent processes. Ann. Stat. 1997, 25, 2084–2102. [Google Scholar] [CrossRef]
- Owen, A.B. Empirical likelihood ratio confidence intervals for a single functional. Biometrika 1988, 75, 237–249. [Google Scholar] [CrossRef]
- Owen, A. Empirical likelihood ratio confidence regions. Ann. Stat. 1990, 18, 90–120. [Google Scholar] [CrossRef]
- Shan, G.; Vexler, A.; Wilding, G.E.; Hutson, A.D. Simple and exact empirical likelihood ratio tests for normality based on moment relations. Commun. Stat. Comput. 2010, 40, 129–146. [Google Scholar] [CrossRef]
- Marange, C.S.; Qin, Y. A simple empirical likelihood ratio test for normality based on the moment constraints of a half-Normal distribution. J. Probab. Stat. 2018, 2018, 8094146. [Google Scholar] [CrossRef]
- Marange, C.S.; Qin, Y. A new empirical likelihood ratio goodness of fit test for normality based on moment constraints. Commun. Stat. Simul. Comput. 2019, 50, 1561–1575. [Google Scholar] [CrossRef]
- Marange, C.S.; Qin, Y. An Empirical Likelihood Ratio-Based Omnibus Test for Normality with an Adjustment for Symmetric Alternatives. J. Probab. Stat. 2021, 2021, 6661985. [Google Scholar] [CrossRef]
- Zhao, Y.; Moss, A.; Yang, H.; Zhang, Y. Jackknife empirical likelihood for the skewness and kurtosis. Stat. Its Interface 2018, 11, 709–719. [Google Scholar] [CrossRef]
- Lin, L.; Zhang, R. Blockwise empirical Euclidean likelihood for weakly dependent processes. Stat. Probab. Lett. 2001, 53, 143–152. [Google Scholar] [CrossRef]
- Bravo, F. Blockwise empirical entropy tests for time series regressions. J. Time Ser. Anal. 2005, 26, 185–210. [Google Scholar] [CrossRef]
- Bravo, F. Blockwise generalized empirical likelihood inference for non-linear dynamic moment conditions models. Econom. J. 2009, 12, 208–231. [Google Scholar] [CrossRef]
- Nordman, D.J.; Sibbertsen, P.; Lahiri, S.N. Empirical likelihood confidence intervals for the mean of a long-range dependent process. J. Time Ser. Anal. 2007, 28, 576–599. [Google Scholar] [CrossRef] [Green Version]
- Nordman, D.J. Tapered empirical likelihood for time series data in time and frequency domains. Biometrika 2009, 96, 119–132. [Google Scholar] [CrossRef]
- Chen, S.X.; Wong, C.M. Smoothed block empirical likelihood for quantiles of weakly dependent processes. Stat. Sin. 2009, 71–81. [Google Scholar]
- Chen, Y.Y.; Zhang, L.X. Empirical Euclidean likelihood for general estimating equations under association dependence. Appl. Math. J. Chin. Univ. 2010, 25, 437–446. [Google Scholar] [CrossRef]
- Wu, R.; Cao, J. Blockwise empirical likelihood for time series of counts. J. Multivar. Anal. 2011, 102, 661–673. [Google Scholar] [CrossRef]
- Lei, Q.; Qin, Y. Empirical likelihood for quantiles under negatively associated samples. J. Stat. Plan. Inference 2011, 141, 1325–1332. [Google Scholar] [CrossRef]
- Nordman, D.J.; Bunzel, H.; Lahiri, S.N. A nonstandard empirical likelihood for time series. Ann. Stat. 2013, 3050–3073. [Google Scholar] [CrossRef] [Green Version]
- Nordman, D.J.; Lahiri, S.N. A review of empirical likelihood methods for time series. J. Stat. Plan. Inference 2014, 155, 1–18. [Google Scholar] [CrossRef]
- Nelson, C.R. Applied Time Series Analysis for Managerial Forecasting; Holden-Day Inc.: San Francisco, CA, USA, 1973. [Google Scholar]
- Wei, W. Time Series Analysis; Addison-Wisley Publishing Company Inc.: Reading, MA, USA, 1990. [Google Scholar]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C. Time Series Analysis: Forecasting and Control, 3rd ed.; Prentice Hall: Englewood Cliffs, NJ, USA, 1994. [Google Scholar]
- Kim, Y.M.; Lahiri, S.N.; Nordman, D.J. A progressive block empirical likelihood method for time series. J. Am. Stat. Assoc. 2013, 108, 1506–1516. [Google Scholar] [CrossRef]
- Ploberger, W.; Krämer, W. The CUSUM test with OLS residuals. Econom. J. Econom. Soc. 1992, 271–285. [Google Scholar] [CrossRef]
- Gombay, E.; Horvath, L. An application of the maximum likelihood test to the change-point problem. Stoch. Process. Their Appl. 1994, 50, 161–171. [Google Scholar] [CrossRef] [Green Version]
- Gurevich, G.; Vexler, A. Change point problems in the model of logistic regression. J. Stat. Plan. Inference 2005, 131, 313–331. [Google Scholar] [CrossRef]
- Vexler, A.; Wu, C. An optimal retrospective change point detection policy. Scand. J. Stat. 2009, 36, 542–558. [Google Scholar] [CrossRef] [Green Version]
- Vexler, A.; Liu, A.; Pollak, M. Transformation of Changepoint Detection Methods into a Shiryayev-Roberts Form; Department of Biostatistics, The New York State University at Buffalo: Buffalo, NY, USA, 2006. [Google Scholar]
- Wilks, S.S. The large-sample distribution of the likelihood ratio for testing composite hypotheses. Ann. Math. Stat. 1938, 9, 60–62. [Google Scholar] [CrossRef]
- Hall, P.; Horowitz, J.L.; Jing, B.Y. On blocking rules for the bootstrap with dependent data. Biometrika 1995, 82, 561–574. [Google Scholar] [CrossRef]
- Lahiri, S.N. Resampling Methods for Dependent Data; Springer: New York, NY, USA, 2003. [Google Scholar]
- Andrews, D.W. Heteroskedasticity and autocorrelation consistent covariance matrix estimation. Econom. J. Econom. Soc. 1991, 59, 817–858. [Google Scholar] [CrossRef]
- Monti, A.C. Empirical likelihood confidence regions in time series models. Biometrika 1997, 84, 395–405. [Google Scholar] [CrossRef]
- Qin, Y.; Lei, Q. Empirical Likelihood for Mixed Regressive, Spatial Autoregressive Model Based on GMM. Sankhya A 2021, 83, 353–378. [Google Scholar] [CrossRef]
- Caner, M.; Kilian, L. Size distortions of tests of the null hypothesis of stationarity: Evidence and implications for the PPP debate. J. Int. Money Financ. 2001, 20, 639–657. [Google Scholar] [CrossRef] [Green Version]
- De Long, J.B.; Summers, L.H. Is Increased Price Flexibility Stabilizing? Natl. Bur. Econ. Res. 1986, 76, 1031–1044. [Google Scholar]
- Campbell, M.J.; Walker, A.M. A Survey of Statistical Work on the Mackenzie River Series of Annual Canadian Lynx Trappings for the Years 1821–1934 and a New Analysis. J. R. Stat. Soc. Ser. A 1977, 140, 411–431. [Google Scholar] [CrossRef]
- Tong, H. Some comments on the Canadian lynx data. J. R. Stat. Soc. Ser. A 1977, 140, 432–436. [Google Scholar] [CrossRef]
- Haggan, V.; Heravi, S.M.; Priestley, M.B. A study of the application of state-dependent models in non-linear time series analysis. J. Time Ser. Anal. 1984, 5, 69–102. [Google Scholar] [CrossRef]
- Makridakis, S.; Wheelwright, S.; Hyndman, R. Forecasting: Methods and Applications; John Willey & Sons: New York, NY, USA, 1998. [Google Scholar]
- Coghlan, A. A Little Book of R for Time Series; Release 0.2; Parasite Genomics Group, Wellcome Trust Sanger Institute: Cambridge, UK, 2017. [Google Scholar]
- Truong, P.; Novák, V. An Improved Forecasting and Detection of Structural Breaks in time Series Using Fuzzy Techniques; Contribution to Statistics; Springer: Cham, Switzerland, 2022. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| NOL Blocks | OL Blocks | |||||||
|---|---|---|---|---|---|---|---|---|
| −0.9 | 0.9998 | 0.9970 | 0.9522 | 0.9208 | 1.0000 | 0.9988 | 0.9810 | 0.9708 |
| −0.8 | 0.9976 | 0.9888 | 0.9374 | 0.9098 | 0.9992 | 0.9928 | 0.9716 | 0.9528 |
| −0.7 | 0.9938 | 0.9742 | 0.9266 | 0.8926 | 0.9960 | 0.9846 | 0.9588 | 0.9401 |
| −0.6 | 0.9850 | 0.9636 | 0.9230 | 0.8958 | 0.9914 | 0.9762 | 0.9512 | 0.9306 |
| −0.5 | 0.9778 | 0.9564 | 0.9116 | 0.8892 | 0.9846 | 0.9704 | 0.9436 | 0.9228 |
| −0.4 | 0.9706 | 0.9492 | 0.9076 | 0.8820 | 0.9784 | 0.9610 | 0.9384 | 0.9176 |
| −0.3 | 0.9630 | 0.9420 | 0.9072 | 0.8802 | 0.9688 | 0.9546 | 0.9322 | 0.9130 |
| −0.2 | 0.9562 | 0.9370 | 0.9026 | 0.8800 | 0.9600 | 0.9486 | 0.9272 | 0.9088 |
| −0.1 | 0.9504 | 0.9340 | 0.9000 | 0.8756 | 0.9530 | 0.9440 | 0.9224 | 0.9046 |
| 0 | 0.9402 | 0.9322 | 0.8924 | 0.8624 | 0.9444 | 0.9400 | 0.9258 | 0.8998 |
| 0.1 | 0.9300 | 0.9342 | 0.9054 | 0.8580 | 0.9266 | 0.9324 | 0.9088 | 0.8952 |
| 0.2 | 0.9180 | 0.9170 | 0.8948 | 0.8558 | 0.9254 | 0.9288 | 0.9064 | 0.8894 |
| 0.3 | 0.9010 | 0.9046 | 0.8896 | 0.8582 | 0.9122 | 0.9200 | 0.9026 | 0.8816 |
| 0.4 | 0.8852 | 0.8964 | 0.8848 | 0.8466 | 0.8880 | 0.9040 | 0.8996 | 0.8752 |
| 0.5 | 0.8578 | 0.8860 | 0.8794 | 0.8448 | 0.8570 | 0.8972 | 0.8868 | 0.8736 |
| 0.6 | 0.8254 | 0.8584 | 0.8634 | 0.8398 | 0.8134 | 0.8628 | 0.8748 | 0.8614 |
| 0.7 | 0.7514 | 0.8116 | 0.8274 | 0.8180 | 0.7620 | 0.8114 | 0.8478 | 0.8266 |
| 0.8 | 0.6526 | 0.7350 | 0.7824 | 0.7780 | 0.6482 | 0.7428 | 0.7896 | 0.7830 |
| 0.9 | 0.4538 | 0.5416 | 0.6438 | 0.6508 | 0.4716 | 0.5456 | 0.6474 | 0.6510 |
| Mean | 0.89 | 0.90 | 0.88 | 0.85 | 0.89 | 0.91 | 0.90 | 0.88 |
| MAD | 0.09 | 0.07 | 0.07 | 0.10 | 0.09 | 0.06 | 0.06 | 0.07 |
| −0.9 | 0.9870 | 0.9966 | 0.9792 | 0.9602 | 0.9924 | 0.9984 | 0.9906 | 0.9836 |
| −0.8 | 0.9832 | 0.9864 | 0.9608 | 0.9398 | 0.9890 | 0.9910 | 0.9772 | 0.9628 |
| −0.7 | 0.9768 | 0.9740 | 0.9490 | 0.9302 | 0.9848 | 0.9794 | 0.9678 | 0.9538 |
| −0.6 | 0.9744 | 0.9658 | 0.9398 | 0.9238 | 0.9804 | 0.9732 | 0.9630 | 0.9452 |
| −0.5 | 0.9708 | 0.9594 | 0.9372 | 0.9220 | 0.9768 | 0.9656 | 0.9592 | 0.9392 |
| −0.4 | 0.9668 | 0.9554 | 0.9338 | 0.9200 | 0.9696 | 0.9622 | 0.9552 | 0.9356 |
| −0.3 | 0.9628 | 0.9504 | 0.9326 | 0.9182 | 0.9644 | 0.9570 | 0.9524 | 0.9318 |
| −0.2 | 0.9586 | 0.9450 | 0.9310 | 0.9174 | 0.9592 | 0.9518 | 0.9502 | 0.9294 |
| −0.1 | 0.9532 | 0.9422 | 0.9282 | 0.9156 | 0.9538 | 0.9482 | 0.9474 | 0.9274 |
| 0 | 0.9424 | 0.9428 | 0.9298 | 0.9148 | 0.9534 | 0.9456 | 0.9344 | 0.9330 |
| 0.1 | 0.9422 | 0.9354 | 0.9246 | 0.9118 | 0.9402 | 0.9344 | 0.9322 | 0.9252 |
| 0.2 | 0.9258 | 0.9324 | 0.9224 | 0.9154 | 0.9374 | 0.9318 | 0.9304 | 0.9224 |
| 0.3 | 0.9158 | 0.9270 | 0.9130 | 0.9098 | 0.9260 | 0.9310 | 0.9308 | 0.9230 |
| 0.4 | 0.9142 | 0.9210 | 0.9228 | 0.9018 | 0.9012 | 0.9256 | 0.9296 | 0.9180 |
| 0.5 | 0.8880 | 0.9062 | 0.9126 | 0.9020 | 0.8922 | 0.9136 | 0.9158 | 0.9144 |
| 0.6 | 0.8594 | 0.8850 | 0.9088 | 0.8946 | 0.8654 | 0.9006 | 0.9050 | 0.9060 |
| 0.7 | 0.8182 | 0.8652 | 0.8918 | 0.8938 | 0.8094 | 0.8794 | 0.8968 | 0.9006 |
| 0.8 | 0.7348 | 0.7998 | 0.8558 | 0.8706 | 0.7350 | 0.8084 | 0.8692 | 0.8730 |
| 0.9 | 0.5880 | 0.6746 | 0.7578 | 0.7906 | 0.5614 | 0.6742 | 0.7664 | 0.8020 |
| Mean | 0.91 | 0.92 | 0.92 | 0.91 | 0.91 | 0.93 | 0.93 | 0.92 |
| MAD | 0.06 | 0.05 | 0.04 | 0.04 | 0.06 | 0.04 | 0.03 | 0.03 |
| NOL Blocks | OL Blocks | |||||||
|---|---|---|---|---|---|---|---|---|
| −0.9 | 0.9890 | 0.9886 | 0.9768 | 0.9610 | 0.9938 | 0.9884 | 0.9826 | 0.9780 |
| −0.8 | 0.9854 | 0.9800 | 0.9678 | 0.9492 | 0.9902 | 0.9821 | 0.9712 | 0.9668 |
| −0.7 | 0.9810 | 0.9764 | 0.9600 | 0.9428 | 0.9870 | 0.9764 | 0.9644 | 0.9594 |
| −0.6 | 0.9768 | 0.9704 | 0.9564 | 0.9398 | 0.9826 | 0.9707 | 0.9606 | 0.9556 |
| −0.5 | 0.9724 | 0.9652 | 0.9518 | 0.9388 | 0.9784 | 0.9664 | 0.9560 | 0.9522 |
| −0.4 | 0.9674 | 0.9630 | 0.9494 | 0.9360 | 0.9734 | 0.9631 | 0.9538 | 0.9506 |
| −0.3 | 0.9460 | 0.9592 | 0.9470 | 0.9334 | 0.9704 | 0.9602 | 0.9522 | 0.9480 |
| −0.2 | 0.9598 | 0.9566 | 0.9452 | 0.9316 | 0.9646 | 0.9564 | 0.9508 | 0.9462 |
| −0.1 | 0.9560 | 0.9528 | 0.9444 | 0.9314 | 0.9600 | 0.9544 | 0.9490 | 0.9440 |
| 0 | 0.9486 | 0.9496 | 0.9440 | 0.9212 | 0.9498 | 0.9540 | 0.9460 | 0.9346 |
| 0.1 | 0.9426 | 0.9440 | 0.9364 | 0.9302 | 0.9478 | 0.9458 | 0.9424 | 0.9356 |
| 0.2 | 0.9442 | 0.9384 | 0.9316 | 0.9224 | 0.9324 | 0.9426 | 0.9384 | 0.9306 |
| 0.3 | 0.9234 | 0.9280 | 0.9360 | 0.9216 | 0.9238 | 0.9384 | 0.9376 | 0.9344 |
| 0.4 | 0.9096 | 0.9312 | 0.9288 | 0.9198 | 0.9142 | 0.9330 | 0.9366 | 0.9272 |
| 0.5 | 0.8836 | 0.9262 | 0.9266 | 0.9182 | 0.8926 | 0.9240 | 0.9312 | 0.9290 |
| 0.6 | 0.8676 | 0.9092 | 0.9192 | 0.9160 | 0.8690 | 0.9118 | 0.9294 | 0.9336 |
| 0.7 | 0.8264 | 0.8778 | 0.9114 | 0.9140 | 0.8168 | 0.8914 | 0.9240 | 0.9274 |
| 0.8 | 0.7408 | 0.8304 | 0.8892 | 0.9018 | 0.7448 | 0.8498 | 0.9150 | 0.9076 |
| 0.9 | 0.5626 | 0.7070 | 0.8178 | 0.8372 | 0.5862 | 0.7280 | 0.8964 | 0.8548 |
| Mean | 0.91 | 0.93 | 0.93 | 0.92 | 0.91 | 0.93 | 0.94 | 0.94 |
| MAD | 0.06 | 0.04 | 0.02 | 0.03 | 0.06 | 0.03 | 0.02 | 0.02 |
| −0.9 | 0.9998 | 0.9860 | 0.9732 | 0.9638 | 1.0000 | 0.9868 | 0.9786 | 0.9720 |
| −0.8 | 0.9944 | 0.9776 | 0.9660 | 0.9504 | 0.9966 | 0.9792 | 0.9668 | 0.9586 |
| −0.7 | 0.9830 | 0.9720 | 0.9606 | 0.9470 | 0.9878 | 0.9732 | 0.9600 | 0.9524 |
| −0.6 | 0.9750 | 0.9664 | 0.9562 | 0.9430 | 0.9776 | 0.9690 | 0.9564 | 0.9500 |
| −0.5 | 0.9676 | 0.9616 | 0.9540 | 0.9416 | 0.9722 | 0.9642 | 0.9522 | 0.9482 |
| −0.4 | 0.9618 | 0.9598 | 0.9524 | 0.9402 | 0.9680 | 0.9604 | 0.9502 | 0.9454 |
| −0.3 | 0.9570 | 0.9568 | 0.9508 | 0.9386 | 0.9634 | 0.9572 | 0.9484 | 0.9450 |
| −0.2 | 0.9530 | 0.9552 | 0.9490 | 0.9380 | 0.9592 | 0.9550 | 0.9474 | 0.9440 |
| −0.1 | 0.9502 | 0.9524 | 0.9480 | 0.9374 | 0.9560 | 0.9534 | 0.9454 | 0.9418 |
| 0 | 0.9504 | 0.9488 | 0.9422 | 0.9404 | 0.9486 | 0.9570 | 0.9442 | 0.9414 |
| 0.1 | 0.9428 | 0.9442 | 0.9404 | 0.9406 | 0.9432 | 0.9494 | 0.9482 | 0.9442 |
| 0.2 | 0.9402 | 0.9450 | 0.9368 | 0.9396 | 0.9380 | 0.9472 | 0.9452 | 0.9464 |
| 0.3 | 0.9256 | 0.9354 | 0.9464 | 0.9348 | 0.9332 | 0.9428 | 0.9436 | 0.9372 |
| 0.4 | 0.9216 | 0.9360 | 0.9430 | 0.9318 | 0.9250 | 0.9334 | 0.9360 | 0.9414 |
| 0.5 | 0.9148 | 0.9324 | 0.9338 | 0.9368 | 0.9166 | 0.9296 | 0.9374 | 0.9402 |
| 0.6 | 0.8856 | 0.9246 | 0.9294 | 0.9284 | 0.8722 | 0.9194 | 0.9344 | 0.9360 |
| 0.7 | 0.8412 | 0.9064 | 0.9306 | 0.9288 | 0.8550 | 0.9012 | 0.9290 | 0.9264 |
| 0.8 | 0.7870 | 0.8696 | 0.9066 | 0.9186 | 0.7814 | 0.8652 | 0.9030 | 0.9124 |
| 0.9 | 0.6516 | 0.7660 | 0.8492 | 0.8882 | 0.6476 | 0.7626 | 0.8628 | 0.8842 |
| Mean | 0.92 | 0.94 | 0.94 | 0.94 | 0.92 | 0.94 | 0.94 | 0.94 |
| MAD | 0.05 | 0.03 | 0.02 | 0.02 | 0.05 | 0.03 | 0.02 | 0.01 |
| NOL Blocks | OL Blocks | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| b | Log N | Log N | |||||||
| −0.9 | 0.0636 | 0.0474 | 0.0670 | 0.0512 | 0.0240 | 0.0460 | 0.0470 | 0.0564 | |
| 0.0986 | 0.0502 | 0.0676 | 0.0468 | 0.0382 | 0.0486 | 0.0616 | 0.0652 | ||
| −0.5 | 0.9884 | 0.0632 | 0.5088 | 0.2832 | 0.9928 | 0.0620 | 0.5098 | 0.2908 | |
| 0.9806 | 0.0542 | 0.4582 | 0.2484 | 0.9846 | 0.0538 | 0.4578 | 0.2630 | ||
| 0 | 1.0000 | 0.0690 | 0.8842 | 0.9996 | 1.0000 | 0.0772 | 0.8730 | 0.9988 | |
| 1.0000 | 0.0518 | 0.8464 | 0.9948 | 1.0000 | 0.0586 | 0.8250 | 0.9938 | ||
| 0.5 | 0.9996 | 0.0544 | 0.4812 | 0.4612 | 1.0000 | 0.0532 | 0.4456 | 0.4244 | |
| 0.9984 | 0.0396 | 0.3624 | 0.4046 | 0.9954 | 0.0452 | 0.3272 | 0.3836 | ||
| 0.6 | 0.9964 | 0.0544 | 0.3000 | 0.2486 | 0.9948 | 0.0456 | 0.3064 | 0.2146 | |
| 0.9896 | 0.0314 | 0.2196 | 0.2328 | 0.9764 | 0.0470 | 0.2346 | 0.2208 | ||
| 0.7 | 0.9672 | 0.0470 | 0.1978 | 0.1198 | 0.9542 | 0.0506 | 0.1924 | 0.1218 | |
| 0.9226 | 0.0400 | 0.1204 | 0.1206 | 0.8884 | 0.0476 | 0.1282 | 0.1124 | ||
| 0.8 | 0.7766 | 0.0516 | 0.1048 | 0.0656 | 0.7674 | 0.0518 | 0.0998 | 0.0612 | |
| 0.6770 | 0.0260 | 0.0720 | 0.0760 | 0.6450 | 0.0420 | 0.0706 | 0.0728 | ||
| 0.9 | 0.3268 | 0.0562 | 0.0596 | 0.0858 | 0.3284 | 0.1012 | 0.0595 | 0.0828 | |
| 0.3118 | 0.0490 | 0.0558 | 0.0552 | 0.2928 | 0.0770 | 0.0520 | 0.0544 | ||
| −0.9 | 0.7696 | 0.0496 | 0.1158 | 0.0600 | 0.6694 | 0.0442 | 0.1060 | 0.0652 | |
| 0.7984 | 0.0490 | 0.1288 | 0.0550 | 0.6254 | 0.0462 | 0.1146 | 0.0562 | ||
| −0.5 | 1.0000 | 0.0974 | 0.9988 | 0.9186 | 1.0000 | 0.0974 | 0.9990 | 0.9282 | |
| 1.0000 | 0.0808 | 0.9986 | 0.8860 | 0.9994 | 0.0892 | 0.9992 | 0.8962 | ||
| 0 | 1.0000 | 0.4280 | 1.0000 | 1.0000 | 1.0000 | 0.4474 | 1.0000 | 1.0000 | |
| 1.0000 | 0.3596 | 1.0000 | 1.0000 | 1.0000 | 0.4050 | 1.0000 | 1.0000 | ||
| 0.5 | 1.0000 | 0.2174 | 0.9982 | 0.9906 | 1.0000 | 0.2280 | 0.9990 | 0.9914 | |
| 1.0000 | 0.1954 | 0.9972 | 0.9880 | 1.0000 | 0.1818 | 0.9960 | 0.9842 | ||
| 0.6 | 1.0000 | 0.1332 | 0.9778 | 0.7884 | 1.0000 | 0.1364 | 0.9730 | 0.7884 | |
| 1.0000 | 0.1090 | 0.9656 | 0.7754 | 1.0000 | 0.1156 | 0.9618 | 0.7704 | ||
| 0.7 | 1.0000 | 0.0802 | 0.8274 | 0.3436 | 1.0000 | 0.0802 | 0.8420 | 0.3524 | |
| 1.0000 | 0.0738 | 0.7862 | 0.3622 | 1.0000 | 0.0730 | 0.7890 | 0.3512 | ||
| 0.8 | 1.0000 | 0.0572 | 0.4684 | 0.1204 | 1.0000 | 0.0600 | 0.4742 | 0.1092 | |
| 1.0000 | 0.0516 | 0.4388 | 0.1310 | 0.9998 | 0.0506 | 0.4166 | 0.1248 | ||
| 0.9 | 0.9610 | 0.0576 | 0.1576 | 0.0558 | 0.9616 | 0.0518 | 0.1404 | 0.0490 | |
| 0.9508 | 0.0484 | 0.1242 | 0.0564 | 0.9466 | 0.0462 | 0.1254 | 0.0516 | ||
| −0.9 | 0.9832 | 0.0562 | 0.2254 | 0.0556 | 0.9836 | 0.0482 | 0.2190 | 0.0632 | |
| 0.9842 | 0.0520 | 0.2448 | 0.0526 | 0.9696 | 0.0502 | 0.2130 | 0.0482 | ||
| −0.5 | 1.0000 | 0.1926 | 1.0000 | 1.0000 | 1.0000 | 0.2130 | 1.0000 | 1.0000 | |
| 1.0000 | 0.1862 | 1.0000 | 0.9974 | 1.0000 | 0.1770 | 1.0000 | 0.9986 | ||
| 0 | 1.0000 | 0.8058 | 1.0000 | 1.0000 | 1.0000 | 0.8220 | 1.0000 | 1.0000 | |
| 1.0000 | 0.7844 | 1.0000 | 1.0000 | 1.0000 | 0.7946 | 1.0000 | 1.0000 | ||
| 0.5 | 1.0000 | 0.4934 | 1.0000 | 1.0000 | 1.0000 | 0.4788 | 1.0000 | 1.0000 | |
| 1.0000 | 0.4656 | 0.9998 | 0.9970 | 1.0000 | 0.4860 | 1.0000 | 1.0000 | ||
| 0.6 | 1.0000 | 0.2872 | 1.0000 | 0.9782 | 1.0000 | 0.3018 | 1.0000 | 0.9818 | |
| 1.0000 | 0.2710 | 0.9936 | 0.9768 | 1.0000 | 0.2882 | 0.9998 | 0.9754 | ||
| 0.7 | 1.0000 | 0.1354 | 0.9862 | 0.6346 | 1.0000 | 0.1422 | 0.9852 | 0.6174 | |
| 1.0000 | 0.1296 | 0.9790 | 0.6280 | 1.0000 | 0.1426 | 0.9846 | 0.6170 | ||
| 0.8 | 1.0000 | 0.0746 | 0.7962 | 0.1862 | 1.0000 | 0.0654 | 0.7786 | 0.1744 | |
| 1.0000 | 0.0720 | 0.7476 | 0.1912 | 1.0000 | 0.0652 | 0.7372 | 0.1840 | ||
| 0.9 | 0.9992 | 0.0474 | 0.2714 | 0.0610 | 0.9994 | 0.0530 | 0.2564 | 0.0658 | |
| 0.9966 | 0.0472 | 0.2330 | 0.0608 | 0.9992 | 0.0500 | 0.2388 | 0.0606 | ||
| Rejection Rates for | ||||||||
|---|---|---|---|---|---|---|---|---|
| Test | Log N | (2,1) | ||||||
| −0.9 | BELT | 0.0474 | 0.0226 | 0.0478 | 0.0280 | 0.0684 | 0.0514 | 0.0574 |
| EPPS | 0.1268 | 0.0534 | 0.1216 | 0.0728 | 0.1226 | 0.1438 | 0.1574 | |
| LV | 0.0284 | 0.1454 | 0.0316 | 0.0892 | 0.0400 | 0.0224 | 0.0234 | |
| PV | 0.0628 | 0.2972 | 0.0640 | 0.1642 | 0.0880 | 0.0824 | 0.0302 | |
| −0.5 | BELT | 0.0530 | 0.9950 | 0.0610 | 0.9966 | 0.4956 | 0.4862 | 0.2932 |
| EPPS | 0.0712 | 0.6810 | 0.0532 | 0.8528 | 0.2044 | 0.4840 | 0.5538 | |
| LV | 0.0456 | 0.9994 | 0.1896 | 0.9988 | 0.4794 | 0.1698 | 0.0096 | |
| PV | 0.0482 | 0.9984 | 0.1286 | 0.9980 | 0.3584 | 0.3780 | 0.2664 | |
| 0 | BELT | 0.0468 | 1.0000 | 0.0552 | 1.0000 | 0.8868 | 0.9576 | 0.9978 |
| EPPS | 0.0632 | 0.9672 | 0.0858 | 0.9960 | 0.5426 | 0.9706 | 0.9948 | |
| LV | 0.0428 | 1.0000 | 0.2950 | 1.0000 | 0.7820 | 0.7460 | 0.5446 | |
| PV | 0.0484 | 1.0000 | 0.1568 | 1.0000 | 0.8048 | 0.9820 | 0.9602 | |
| 0.5 | BELT | 0.0510 | 0.9998 | 0.0532 | 0.9996 | 0.4534 | 0.3762 | 0.4248 |
| EPPS | 0.0732 | 0.8566 | 0.0646 | 0.9598 | 0.2658 | 0.5590 | 0.5668 | |
| LV | 0.0342 | 0.9978 | 0.1578 | 0.9984 | 0.4160 | 0.1030 | 0.0002 | |
| PV | 0.0384 | 0.9998 | 0.0862 | 0.9992 | 0.4040 | 0.4242 | 0.1100 | |
| 0.6 | BELT | 0.0554 | 0.9960 | 0.0520 | 0.9962 | 0.3084 | 0.2122 | 0.2214 |
| EPPS | 0.0750 | 0.6182 | 0.0610 | 0.8188 | 0.1990 | 0.3596 | 0.3392 | |
| LV | 0.0332 | 0.9872 | 0.1204 | 0.9738 | 0.2848 | 0.0676 | 0.0020 | |
| PV | 0.0660 | 0.9932 | 0.0826 | 0.9864 | 0.2932 | 0.2108 | 0.0510 | |
| 0.7 | BELT | 0.0524 | 0.9624 | 0.0500 | 0.9494 | 0.1986 | 0.1540 | 0.1064 |
| EPPS | 0.0798 | 0.3232 | 0.0664 | 0.4846 | 0.1462 | 0.2170 | 0.2158 | |
| LV | 0.0324 | 0.9050 | 0.0832 | 0.8292 | 0.1646 | 0.0382 | 0.0028 | |
| PV | 0.0600 | 0.9340 | 0.0868 | 0.8900 | 0.1520 | 0.0846 | 0.0326 | |
| 0.8 | BELT | 0.0482 | 0.7980 | 0.0488 | 0.7238 | 0.0952 | 0.0986 | 0.0606 |
| EPPS | 0.1104 | 0.1464 | 0.0972 | 0.2038 | 0.1308 | 0.1576 | 0.1636 | |
| LV | 0.0154 | 0.6246 | 0.0408 | 0.4400 | 0.0658 | 0.0240 | 0.0050 | |
| PV | 0.0648 | 0.6964 | 0.0684 | 0.5388 | 0.0920 | 0.0692 | 0.0546 | |
| 0.9 | BELT | 0.0522 | 0.4330 | 0.0502 | 0.2026 | 0.0576 | 0.1026 | 0.0874 |
| EPPS | 0.1708 | 0.1304 | 0.1474 | 0.1390 | 0.1516 | 0.1832 | 0.1844 | |
| LV | 0.0092 | 0.1750 | 0.0142 | 0.0836 | 0.0184 | 0.0048 | 0.0002 | |
| PV | 0.0782 | 0.3020 | 0.0744 | 0.1830 | 0.0840 | 0.0642 | 0.0324 | |
| Rejection Rates for | ||||||||
|---|---|---|---|---|---|---|---|---|
| Test | Log N | (2,1) | ||||||
| −0.9 | BELT | 0.0490 | 0.6774 | 0.0478 | 0.4806 | 0.1046 | 0.0904 | 0.0538 |
| EPPS | 0.0760 | 0.3736 | 0.0594 | 0.2214 | 0.0694 | 0.0896 | 0.0986 | |
| LV | 0.0692 | 0.8852 | 0.0866 | 0.6136 | 0.1222 | 0.0728 | 0.0562 | |
| PV | 0.0460 | 0.7134 | 0.0780 | 0.3820 | 0.0630 | 0.0660 | 0.0492 | |
| −0.5 | BELT | 0.0466 | 1.0000 | 0.0888 | 1.0000 | 0.9986 | 0.9992 | 0.9248 |
| EPPS | 0.0604 | 0.9998 | 0.1372 | 1.0000 | 0.7692 | 0.9900 | 0.9928 | |
| LV | 0.0422 | 1.0000 | 0.4564 | 1.0000 | 0.9942 | 0.9968 | 0.9638 | |
| PV | 0.0558 | 1.0000 | 0.2216 | 1.0000 | 0.9680 | 0.9954 | 0.9570 | |
| 0 | BELT | 0.0560 | 1.0000 | 0.3856 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| EPPS | 0.0554 | 1.0000 | 0.3266 | 1.0000 | 0.9976 | 1.0000 | 1.0000 | |
| LV | 0.0452 | 1.0000 | 0.7436 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| PV | 0.0452 | 1.0000 | 0.4938 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| 0.5 | BELT | 0.0520 | 1.0000 | 0.1900 | 1.0000 | 0.9958 | 0.9982 | 0.9888 |
| EPPS | 0.0610 | 1.0000 | 0.1494 | 1.0000 | 0.8748 | 0.9972 | 0.9948 | |
| LV | 0.0430 | 1.0000 | 0.4528 | 1.0000 | 0.9938 | 0.9960 | 0.9708 | |
| PV | 0.0384 | 1.0000 | 0.2072 | 1.0000 | 0.9930 | 0.9980 | 0.9196 | |
| 0.6 | BELT | 0.0542 | 1.0000 | 0.1218 | 1.0000 | 0.9766 | 0.9226 | 0.7842 |
| EPPS | 0.0596 | 0.9994 | 0.1040 | 1.0000 | 0.7276 | 0.9060 | 0.8186 | |
| LV | 0.0482 | 1.0000 | 0.3238 | 1.0000 | 0.9558 | 0.8890 | 0.4742 | |
| PV | 0.0420 | 1.0000 | 0.1386 | 0.9990 | 0.9274 | 0.9172 | 0.4590 | |
| 0.7 | BELT | 0.0534 | 1.0000 | 0.0856 | 1.0000 | 0.8334 | 0.6234 | 0.3440 |
| EPPS | 0.0634 | 0.9998 | 0.0824 | 1.0000 | 0.4724 | 0.5792 | 0.4224 | |
| LV | 0.0414 | 1.0000 | 0.2088 | 1.0000 | 0.7392 | 0.4152 | 0.0690 | |
| PV | 0.0480 | 0.9970 | 0.1074 | 0.9968 | 0.7186 | 0.5494 | 0.0842 | |
| 0.8 | BELT | 0.0512 | 1.0000 | 0.0742 | 1.0000 | 0.4812 | 0.2648 | 0.1168 |
| EPPS | 0.0850 | 0.9812 | 0.0728 | 0.9622 | 0.2554 | 0.2584 | 0.1844 | |
| LV | 0.0410 | 1.0000 | 0.1174 | 0.9988 | 0.3758 | 0.1288 | 0.0166 | |
| PV | 0.0514 | 0.9896 | 0.0752 | 0.9920 | 0.3744 | 0.2070 | 0.0308 | |
| 0.9 | BELT | 0.0450 | 0.9582 | 0.0422 | 0.8414 | 0.1450 | 0.0878 | 0.0584 |
| EPPS | 0.1174 | 0.5838 | 0.0962 | 0.4574 | 0.1516 | 0.1580 | 0.1430 | |
| LV | 0.0176 | 0.8318 | 0.0384 | 0.5552 | 0.0688 | 0.0218 | 0.0100 | |
| PV | 0.0452 | 0.5176 | 0.0720 | 0.3350 | 0.0212 | 0.0104 | 0.0072 | |
| Rejection Rates for | ||||||||
|---|---|---|---|---|---|---|---|---|
| Test | Log N | (2,1) | ||||||
| −0.9 | BELT | 0.0510 | 0.9816 | 0.0474 | 0.9098 | 0.2172 | 0.1236 | 0.0646 |
| EPPS | 0.0688 | 0.7914 | 0.0542 | 0.4806 | 0.0822 | 0.0786 | 0.0990 | |
| LV | 0.0910 | 0.9920 | 0.1182 | 0.8958 | 0.2408 | 0.1294 | 0.0684 | |
| PV | 0.0590 | 0.9240 | 0.0520 | 0.6160 | 0.0840 | 0.0450 | 0.0520 | |
| −0.5 | BELT | 0.0480 | 1.0000 | 0.2096 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| EPPS | 0.0544 | 1.0000 | 0.2508 | 1.0000 | 0.9784 | 1.0000 | 1.0000 | |
| LV | 0.0464 | 1.0000 | 0.6976 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| PV | 0.0520 | 1.0000 | 0.4010 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| 0 | BELT | 0.0496 | 1.0000 | 0.8112 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| EPPS | 0.0572 | 1.0000 | 0.5934 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| LV | 0.0488 | 1.0000 | 0.9422 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| PV | 0.0480 | 1.0000 | 0.7910 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| 0.5 | BELT | 0.0560 | 1.0000 | 0.4866 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| EPPS | 0.0560 | 1.0000 | 0.2586 | 1.0000 | 0.9940 | 1.0000 | 1.0000 | |
| LV | 0.0488 | 1.0000 | 0.6720 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| PV | 0.0490 | 1.0000 | 0.3960 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| 0.6 | BELT | 0.0442 | 1.0000 | 0.3028 | 1.0000 | 1.0000 | 1.0000 | 0.9798 |
| EPPS | 0.0572 | 1.0000 | 0.1738 | 1.0000 | 0.9592 | 0.9972 | 0.9826 | |
| LV | 0.0438 | 1.0000 | 0.4970 | 1.0000 | 0.9996 | 1.0000 | 0.9722 | |
| PV | 0.0590 | 0.9994 | 0.2300 | 1.0000 | 0.9998 | 0.9992 | 0.8800 | |
| 0.7 | BELT | 0.0552 | 1.0000 | 0.1394 | 1.0000 | 0.9888 | 0.9202 | 0.6256 |
| EPPS | 0.0618 | 0.9998 | 0.1016 | 1.0000 | 0.7678 | 0.8564 | 0.6302 | |
| LV | 0.0470 | 1.0000 | 0.3144 | 1.0000 | 0.9774 | 0.8898 | 0.3628 | |
| PV | 0.0490 | 1.0000 | 0.1404 | 0.9990 | 0.9580 | 0.9072 | 0.2490 | |
| 0.8 | BELT | 0.0468 | 1.0000 | 0.0690 | 1.0000 | 0.7744 | 0.4996 | 0.1740 |
| EPPS | 0.0744 | 1.0000 | 0.0754 | 0.9996 | 0.4172 | 0.4036 | 0.2364 | |
| LV | 0.0510 | 1.0000 | 0.1512 | 1.0000 | 0.6782 | 0.3184 | 0.0408 | |
| PV | 0.0622 | 0.9930 | 0.0880 | 0.9924 | 0.6550 | 0.3826 | 0.0430 | |
| 0.9 | BELT | 0.0496 | 1.0000 | 0.0536 | 0.9886 | 0.2578 | 0.1454 | 0.0652 |
| EPPS | 0.0902 | 0.9200 | 0.0882 | 0.7720 | 0.1780 | 0.1624 | 0.1220 | |
| LV | 0.0362 | 0.9924 | 0.0538 | 0.9008 | 0.1550 | 0.0624 | 0.0120 | |
| PV | 0.0514 | 0.5760 | 0.0560 | 0.4746 | 0.0008 | 0.0006 | 0.0002 | |
| Power Rankings | |||||||
|---|---|---|---|---|---|---|---|
| n | Ranking | Log N | (2,1) | ||||
| 100 | 1 | BELT, PV | LV | BELT | BELT | EPPS | EPPS |
| 2 | LV | EPPS, PV | PV | LV, PV | BELT, PV | BELT | |
| 3 | EPPS | BELT | LV | EPPS | LV | PV | |
| 4 | EPPS | LV | |||||
| 500 | 1 | BELT, LV | LV | BELT | BELT | BELT, EPPS | EPPS |
| 2 | PV | PV | LV | LV | PV, LV | BELT | |
| 3 | EPPS | BELT | PV, EPPS | PV | PV, LV | ||
| 4 | EPPS | EPPS | |||||
| 1000 | 1 | BELT, LV | LV | BELT | BELT | BELT | EPPS |
| 2 | PV, EPPS | PV, BELT | LV | LV | EPPS | BELT | |
| 3 | EPPS | EPPS, PV | PV | LV, PV | LV | ||
| 4 | EPPS | PV | |||||
| Test | Replications | Elapsed | Relative | User.self | Sys.self |
|---|---|---|---|---|---|
| BELT | 1000 | 13.91 | 5.434 | 13.31 | 0.59 |
| EPPS | 1000 | 8.09 | 3.160 | 7.40 | 0.66 |
| LV | 1000 | 2.56 | 1.000 | 2.47 | 0.09 |
| PV | 1000 | 1394.86 | 544.867 | 1381.02 | 13.16 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marange, C.S.; Qin, Y.; Chiruka, R.T.; Batidzirai, J.M. A Blockwise Empirical Likelihood Test for Gaussianity in Stationary Autoregressive Processes. Mathematics 2023, 11, 1041. https://doi.org/10.3390/math11041041
Marange CS, Qin Y, Chiruka RT, Batidzirai JM. A Blockwise Empirical Likelihood Test for Gaussianity in Stationary Autoregressive Processes. Mathematics. 2023; 11(4):1041. https://doi.org/10.3390/math11041041
Chicago/Turabian StyleMarange, Chioneso S., Yongsong Qin, Raymond T. Chiruka, and Jesca M. Batidzirai. 2023. "A Blockwise Empirical Likelihood Test for Gaussianity in Stationary Autoregressive Processes" Mathematics 11, no. 4: 1041. https://doi.org/10.3390/math11041041
APA StyleMarange, C. S., Qin, Y., Chiruka, R. T., & Batidzirai, J. M. (2023). A Blockwise Empirical Likelihood Test for Gaussianity in Stationary Autoregressive Processes. Mathematics, 11(4), 1041. https://doi.org/10.3390/math11041041