
Programming for High-Performance Computing on Edge Accelerators


Abstract
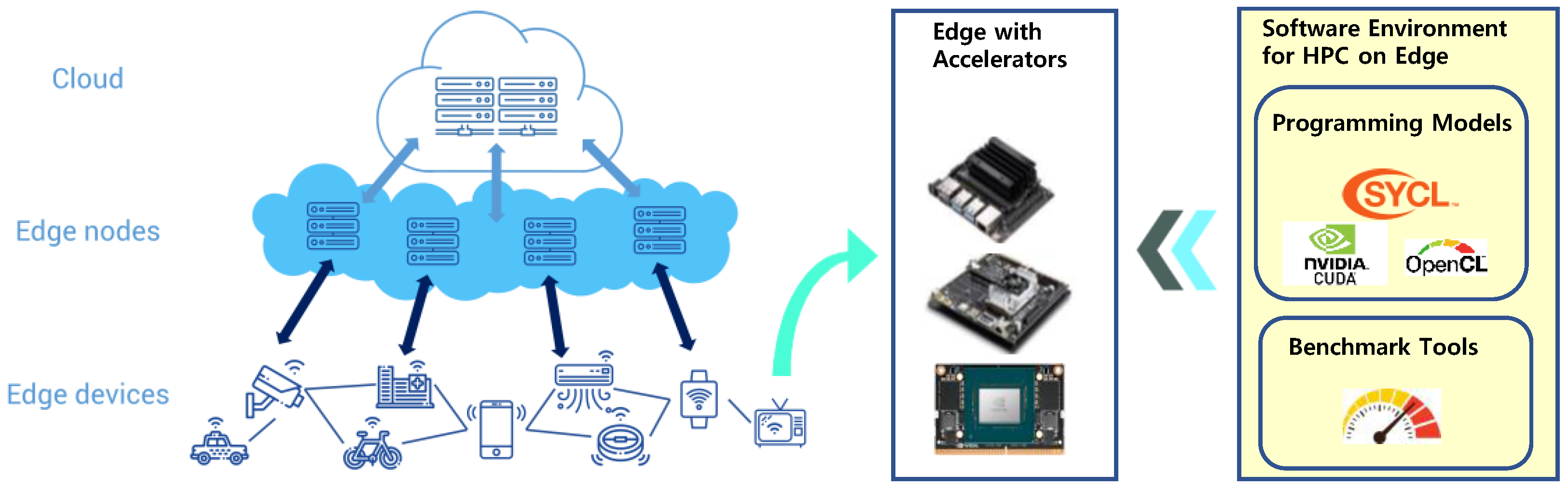
:1. Introduction
- We examine the current status of HPC research on edge devices from the software perspective. Specifically, we review the parallel programming models and benchmark tools that constitute the HPC environment for accelerator-based edge systems.
- We present potential directions for the software environment that can strengthen the development of HPC applications on edge. We discuss ideas to improve the models to program accelerator-based edge devices for better performance. We also consider more high-level programming models and accompanying benchmark software towards implementing HPC on edge.
2. Programming Models for HPC on Edge Accelerators
2.1. NVidia CUDA
- Discussions
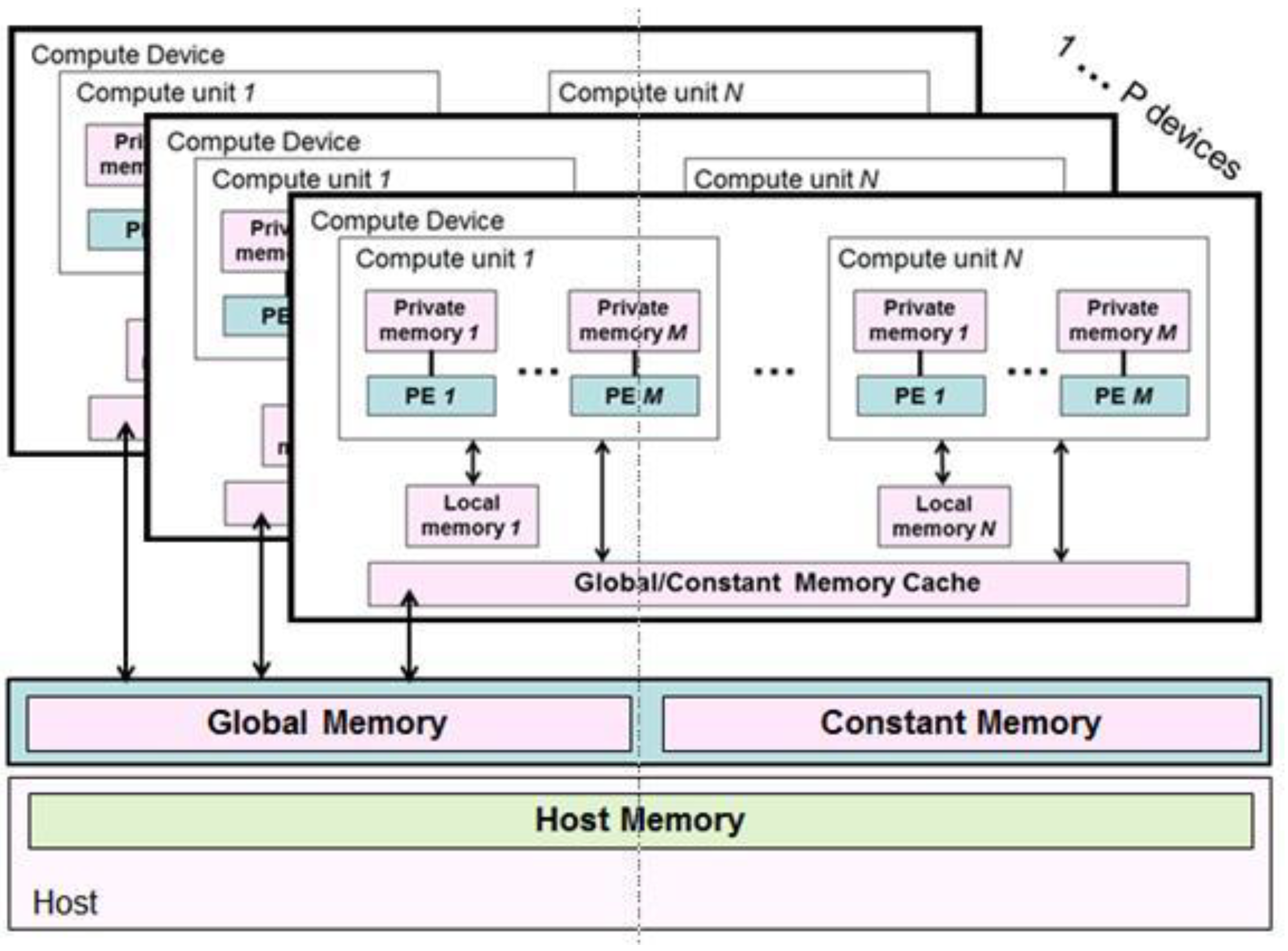
2.2. OpenCL
- Discussions
2.3. SYCL
- Discussions
2.4. OpenMP
- Discussions
3. Benchmarks for HPC on Edge Accelerators
- Discussions
4. Other Research Works Related to HPC on Edge
5. Summary and Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Frontier Supercomputer Debuts as World’s Fastest, Breaking Exascale Barrier. 2022. Available online: https://www.ornl.gov/news/frontier-supercomputer-debuts-worlds-fastest-breaking-exascale-barrier (accessed on 25 December 2022).
- Guidi, G.; Ellis, M.; Buluç, A.; Yelick, K.; Culler, D. 10 Years Later: Cloud Computing is Closing the Performance Gap. In Proceedings of the Companion of the ACM/SPEC International Conference on Performance Engineering, Virtual, 19–23 April 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 41–48. [Google Scholar] [CrossRef]
- Reed, D.; Gannon, D.; Dongarra, J. Reinventing High Performance Computing: Challenges and Opportunities. arXiv 2022, arXiv:2203.02544. [Google Scholar]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge Computing: Vision and Challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Varghese, B.; Wang, N.; Barbhuiya, S.; Kilpatrick, P.; Nikolopoulos, D.S. Challenges and Opportunities in Edge Computing. In Proceedings of the 2016 IEEE International Conference on Smart Cloud (SmartCloud), New York, NY, USA, 18–20 November 2016; pp. 20–26. [Google Scholar] [CrossRef] [Green Version]
- Cao, K.; Liu, Y.; Meng, G.; Sun, Q. An Overview on Edge Computing Research. IEEE Access 2020, 8, 85714–85728. [Google Scholar] [CrossRef]
- Saraf, P.D.; Bartere, M.M.; Lokulwar, P.P. A Review on Evolution of Architectures, Services, and Applications in Computing towards Edge Computing. In International Conference on Innovative Computing and Communications; Springer: Singapore, 2022; pp. 733–744. [Google Scholar]
- Karumbunathan, L. Solving Entry-Level Edge AI Challenges with NVIDIA Jetson Orin Nano. 2022. Available online: https://developer.nvidia.com/blog/solving-entry-level-edge-ai-challenges-with-nvidia-jetson-orin-nano (accessed on 25 December 2022).
- Li, E.; Zeng, L.; Zhou, Z.; Chen, X. Edge AI: On-Demand Accelerating Deep Neural Network Inference via Edge Computing. IEEE Trans. Wirel. Commun. 2020, 19, 447–457. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Ran, X. Deep Learning With Edge Computing: A Review. Proc. IEEE 2019, 107, 1655–1674. [Google Scholar] [CrossRef]
- Riha, L.; Le Moigne, J.; El-Ghazawi, T. Optimization of Selected Remote Sensing Algorithms for Many-Core Architectures. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 5576–5587. [Google Scholar] [CrossRef]
- Tu, W.; Pop, F.; Jia, W.; Wu, J.; Iacono, M. High-Performance Computing in Edge Computing Networks. J. Parallel Distrib. Comput. 2019, 123, 230. [Google Scholar] [CrossRef]
- Cecilia, J.M.; Cano, J.C.; Morales-Garcia, J.; Llanes, A.; Imbernon, B. Evaluation of Clustering Algorithms on GPU-Based Edge Computing Platforms. Sensors 2020, 20, 6335. [Google Scholar] [CrossRef]
- Poulos, A.; McKee, S.A.; Calhoun, J.C. Posits and the State of Numerical Representations in the Age of Exascale and Edge Computing. Softw. Pract. Exp. 2022, 52, 619–635. [Google Scholar] [CrossRef]
- Zamora-Izquierdo, M.A.; Santa, J.; Martínez, J.A.; Martínez, V.; Skarmeta, A.F. Smart Farming IoT Platform based on Edge and Cloud Computing. Biosyst. Eng. 2019, 177, 4–17. [Google Scholar] [CrossRef]
- Kalyani, Y.; Collier, R. A Systematic Survey on the Role of Cloud, Fog, and Edge Computing Combination in Smart Agriculture. Sensors 2021, 21, 5922. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Liu, L.; Tang, J.; Yu, B.; Wang, Y.; Shi, W. Edge Computing for Autonomous Driving: Opportunities and Challenges. Proc. IEEE 2019, 107, 1697–1716. [Google Scholar] [CrossRef]
- Facing the Edge Data Challenge with HPC + AI. 2022. Available online: https://developer.nvidia.com/blog/facing-the-edge-data-challenge-with-hpc-ai (accessed on 25 December 2022).
- Stone, J.E.; Gohara, D.; Shi, G. OpenCL: A Parallel Programming Standard for Heterogeneous Computing Systems. Comput. Sci. Eng. 2010, 12, 66–73. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nickolls, J.; Buck, I.; Garland, M.; Skadron, K. Scalable Parallel Programming with CUDA. Queue 2008, 6, 40–53. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Dong, W. EdgeProg: Edge-centric Programming for IoT Applications. In Proceedings of the 2020 IEEE 40th International Conference on Distributed Computing Systems (ICDCS), Singapore, 29 November–1 December 2020; pp. 212–222. [Google Scholar] [CrossRef]
- IEEE. IEEE Standard for Floating-Point Arithmetic; IEEE Std 754-2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–70. [Google Scholar] [CrossRef]
- Li, W.; Jin, G.; Cui, X.; See, S. An Evaluation of Unified Memory Technology on NVIDIA GPUs. In Proceedings of the 2015 15th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, Shenzhen, China, 4–7 May 2015; pp. 1092–1098. [Google Scholar] [CrossRef]
- Jarząbek, Z.; Czarnul, P. Performance Evaluation of Unified Memory and Dynamic Parallelism for Selected Parallel CUDA Applications. J. Supercomput. 2017, 73, 5378–5401. [Google Scholar] [CrossRef] [Green Version]
- Choi, J.; You, H.; Kim, C.; Young Yeom, H.; Kim, Y. Comparing Unified, Pinned, and Host/Device Memory Allocations for Memory-intensive Workloads on Tegra SoC. Concurr. Comput. Pract. Exp. 2021, 33, e6018. [Google Scholar] [CrossRef]
- Allen, T.; Ge, R. In-Depth Analyses of Unified Virtual Memory System for GPU Accelerated Computing. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, St. Louis, MO, USA, 14–19 November 2021; Association for Computing Machinery: New York, NY, USA, 2021. [Google Scholar] [CrossRef]
- NVidia. Accelerated Linux Graphics Driver README and Installation Guide, Chapter 44. Open Linux Kernel Modules. 2022. Available online: http://download.nvidia.com/XFree86/Linux-x86_64/515.43.04/README/kernel_open.html (accessed on 25 December 2022).
- NVidia. NVIDIA Linux Open GPU Kernel Module Source. 2022. Available online: https://github.com/NVIDIA/open-gpu-kernel-modules (accessed on 25 December 2022).
- Khronos OpenCL Working Group. The OpenCL Specification Version v3.0.12. 2022. Available online: https://registry.khronos.org/OpenCL/specs/3.0-unified/pdf/OpenCL_API.pdf (accessed on 25 December 2022).
- Cavicchioli, R.; Capodieci, N.; Bertogna, M. Memory Interference Characterization between CPU Cores and Integrated GPUs in Mixed-Criticality Platforms. In Proceedings of the 2017 22nd IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Limassol, Cyprus, 12–15 September 2017; pp. 1–10. [Google Scholar] [CrossRef]
- Portable Computing Language (PoCL). Available online: http://portablecl.org (accessed on 25 December 2022).
- Khronos OpenCL Working Group. SYCL 1.2.1 Specification. 2022. Available online: https://www.khronos.org/registry/SYCL/specs/sycl-1.2.1.pdf (accessed on 25 December 2022).
- Burns, R.; Davidson, C.; Dodds, A. Enabling OpenCL and SYCL for RISC-V Processors. In Proceedings of the International Workshop on OpenCL, Munich, Germany, 27–29 April 2021; Association for Computing Machinery: New York, NY, USA, 2021. [Google Scholar] [CrossRef]
- Asanović, K.; Patterson, D.A. Instruction Sets Should Be Free: The Case For RISC-V; Technical Report UCB/EECS-2014-146; EECS Department, University of California, Berkeley: Berkeley, CA, USA, 2014. [Google Scholar]
- Reddy Kuncham, G.K.; Vaidya, R.; Barve, M. Performance Study of GPU applications using SYCL and CUDA on Tesla V100 GPU. In Proceedings of the 2021 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 20–24 September 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Intel DPC++ SYCL for CUDA User Manual. Available online: https://github.com/intel/llvm/blob/sycl/sycl/doc/UsersManual.md (accessed on 25 December 2022).
- Dagum, L.; Menon, R. OpenMP: An Industry Standard API for Shared-Memory Programming. IEEE Comput. Sci. Eng. 1998, 5, 46–55. [Google Scholar] [CrossRef] [Green Version]
- Chapman, B.; Huang, L.; Biscondi, E.; Stotzer, E.; Shrivastava, A.; Gatherer, A. Implementing OpenMP on a High Performance Embedded Multicore MPSoC. In Proceedings of the 2009 IEEE International Symposium on Parallel and Distributed Processing, Rome, Italy, 23–29 May 2009; pp. 1–8. [Google Scholar] [CrossRef]
- Liang, T.Y.; Li, H.F.; Chen, Y.C. An OpenMP Programming Environment on Mobile Devices. Mob. Inf. Syst. 2016, 2016, 4513486. [Google Scholar] [CrossRef] [Green Version]
- Gayatri, R.; Yang, C.; Kurth, T.; Deslippe, J. A Case Study for Performance Portability Using OpenMP 4.5. In Accelerator Programming Using Directives, Proceedings of the 5th International Workshop, WACCPD 2018, Dallas, TX, USA, 11–17 November 2018; Springer: Cham, Switzerland, 2019; pp. 75–95. [Google Scholar]
- OpenACC. Available online: http://www.openacc-standard.org (accessed on 25 December 2022).
- Liang, L.; He, H.; Zhao, J.; Liu, C.; Luo, Q.; Chu, X. An Erasure-Coded Storage System for Edge Computing. IEEE Access 2020, 8, 96271–96283. [Google Scholar] [CrossRef]
- Huber, J.; Cornelius, M.; Georgakoudis, G.; Tian, S.; Diaz, J.M.M.; Dinel, K.; Chapman, B.; Doerfert, J. Efficient Execution of OpenMP on GPUs. In Proceedings of the 2022 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), Seoul, Republic of Korea, 2–6 April 2022; pp. 41–52. [Google Scholar] [CrossRef]
- Bailey, D.; Barszcz, E.; Barton, J.; Browning, D.; Carter, R.; Dagum, L.; Fatoohi, R.; Frederickson, P.; Lasinski, T.; Schreiber, R.; et al. The NAS Parallel Benchmarks. Int. J. High Perform. Comput. Appl. 1991, 5, 63–73. [Google Scholar] [CrossRef] [Green Version]
- NAS Parallel Benchmarks. Available online: https://www.nas.nasa.gov/software/npb.html (accessed on 25 December 2022).
- NAS Parallel Benchmarks Changes. Available online: https://www.nas.nasa.gov/software/npb_changes.html (accessed on 25 December 2022).
- Varghese, B.; Wang, N.; Bermbach, D.; Hong, C.H.; Lara, E.D.; Shi, W.; Stewart, C. A Survey on Edge Performance Benchmarking. ACM Comput. Surv. 2021, 54, 1–33. [Google Scholar] [CrossRef]
- Seo, S.; Jo, G.; Lee, J. Performance Characterization of the NAS Parallel Benchmarks in OpenCL. In Proceedings of the 2011 IEEE International Symposium on Workload Characterization (IISWC), Austin, TX, USA, 6–8 November 2011; pp. 137–148. [Google Scholar] [CrossRef]
- Do, Y.; Kim, H.; Oh, P.; Park, D.; Lee, J. SNU-NPB 2019: Parallelizing and Optimizing NPB in OpenCL and CUDA for Modern GPUs. In Proceedings of the 2019 IEEE International Symposium on Workload Characterization (IISWC), Orlando, FL, USA, 3–5 November 2019; pp. 93–105. [Google Scholar] [CrossRef]
- Araujo, G.; Griebler, D.; Rockenbach, D.A.; Danelutto, M.; Fernandes, L.G. NAS Parallel Benchmarks with CUDA and beyond. Softw. Pract. Exp. 2021, 53, 53–80. [Google Scholar] [CrossRef]
- Kang, P.; Lim, S. A Taste of Scientific Computing on the GPU-Accelerated Edge Device. IEEE Access 2020, 8, 208337–208347. [Google Scholar] [CrossRef]
- Ionica, M.H.; Gregg, D. The Movidius Myriad Architecture’s Potential for Scientific Computing. IEEE Micro 2015, 35, 6–14. [Google Scholar] [CrossRef]
- Amazon AWS for the Edge. Available online: https://aws.amazon.com/edge (accessed on 25 December 2022).
- Microsoft Azure Edge Zone. Available online: https://docs.microsoft.com/azure/networking/edge-zones-overview (accessed on 25 December 2022).




{kind=link}
{kind=link}
{kind=link}
| CUDA | OpenCL | SYCL | OpenMP | |
|---|---|---|---|---|
| Level of Expression | middle | low | high | high |
| Supported Architecture | NVidia GPUs | CPU/GPU/FPGA | CPU/GPU/FPGA | CPU/GPU |
| Framework Implementation | C/C++/Fortran extension | C/C++ extension | C++ extension | compiler directives |
| Open or Proprietary | proprietary | open | open | open |
| Major Feature | popularity for NVidia GPUs | heterogeneous system support | single-source model | ease of programming |
| Research | Model | Year | Benchmark Target | Major Contributions |
|---|---|---|---|---|
| Seo [48] | OpenCL | 2011 | High-end GPUs |
|
| Do [49] | OpenCL & CUDA | 2019 | High-end GPUs |
|
| Kang [51] | CUDA | 2020 | Edge GPUs |
|
| Arajuo [50] | CUDA | 2021 | High-end GPUs |
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, P. Programming for High-Performance Computing on Edge Accelerators. Mathematics 2023, 11, 1055. https://doi.org/10.3390/math11041055
Kang P. Programming for High-Performance Computing on Edge Accelerators. Mathematics. 2023; 11(4):1055. https://doi.org/10.3390/math11041055
Chicago/Turabian StyleKang, Pilsung. 2023. "Programming for High-Performance Computing on Edge Accelerators" Mathematics 11, no. 4: 1055. https://doi.org/10.3390/math11041055
APA StyleKang, P. (2023). Programming for High-Performance Computing on Edge Accelerators. Mathematics, 11(4), 1055. https://doi.org/10.3390/math11041055