


TKRM: Learning a Transfer Kernel Regression Model for Cross-Database Micro-Expression Recognition



Abstract
:1. Introduction
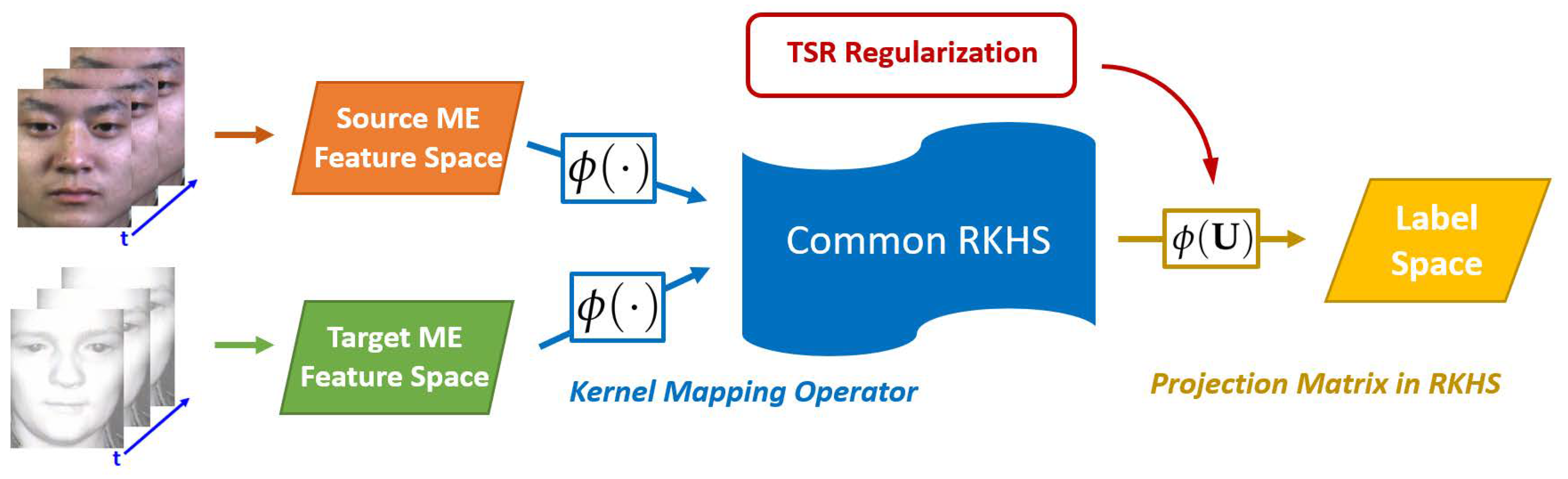
- We propose a novel transfer subspace learning model called TKRM to deal with the cross-database MER problem. The major advantage of the proposed TKRM is seeking a common reproduced kernel Hilbert space for the distribution alignment between the ME samples from different databases.
- So that TKRM possesses the database-invariant ability, a well-designed regularization term called TSR is designed, which allows any target ME sample to be reconstructed by a few source ones.
- A large number of comprehensive experiments are conducted to compare the proposed TKRM method and recent state-of-the-art transfer subspace learning methods. The results verify the effectiveness and superiority of TKRM in coping with the cross-database MER problem.
2. Related Work
3. TKRM for Cross-Database MER
3.1. Formulation of TKRM
3.2. Optimization of TKRM
- Fix and update . In this step, the original optimization problem will be reduced to:where . The inexact augmented Lagrangian multiplier (IALM) [33] method can be adopted to efficiently learn the optimal solution. Concretely, we first introduce an additional variable satisfying . Then, the original optimization problem of TKRM, which is an unconstrained one, can be converted to a constrained one as follows:Subsequently, the Lagrangian function for the above optimization problem can be written as follows:where is the Lagrangian multiplier matrix and is the trade-off parameter.By alternatively minimizing the Lagrangian function with respect to the variables until convergence, the optimal will be obtained. The detailed updating procedures are as follows:
- (a)
- Fix , , and , and update ; the optimization problem with respect to can be reformulated as:which has a closed-form solution, as follows:where is an identity matrix.
- (b)
- Fix , , and , and update . In this step, the optimization problem with respect to is:which can be rewritten as the following formulation:Referring to Step 2 of optimization procedures in [22], the solution of Equation (12) can be determined according to the following criterion, i.e.,
- (1)
- , if ,
- (2)
- , if ,
- (3)
- , otherwise,
where , , and are the entry in the ith row and jth column of matrices , , and , respectively. - (c)
- Update and : and , where is a scaled parameter greater than 1 and is a preset maximal value for .
- (d)
- Check convergence: or the interaction reaches maximal value .
- Fix and update : In this step, the original optimization problem is:where is the ith column of corresponding to the kernel function of the ith target ME sample. This is a standard Lasso problem and can be efficiently solved by a number of typical algorithms, e.g., coordinate descent.
- Check convergence or reach the preset maximal iterations.
3.3. Convergence Analysis for the Optimization of TKRM
3.4. Target Sample’s ME Label Prediction
4. Experiments
4.1. Micro-Expression Databases and Experiment Setting
4.2. Comparison Methods and Performance Metrics
4.3. Experimental Results and Discussion
4.4. Performance of TKRM with Different Kernel Functions
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Oh, Y.H.; See, J.; Le Ngo, A.C.; Phan, R.C.W.; Baskaran, V.M. A survey of automatic facial micro-expression analysis: Databases, methods, and challenges. Front. Psychol. 2018, 9, 1128. [Google Scholar] [CrossRef] [PubMed]
- Ben, X.; Ren, Y.; Zhang, J.; Wang, S.J.; Kpalma, K.; Meng, W.; Liu, Y.J. Video-based facial micro-expression analysis: A survey of datasets, features and algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 5826–5846. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V. Facial Action Coding System; Consulting Psychologist Press: Palo Alto, CA, USA, 1978. [Google Scholar]
- O’Sullivan, M.; Frank, M.G.; Hurley, C.M.; Tiwana, J. Police lie detection accuracy: The effect of lie scenario. Law Hum. Behav. 2009, 33, 530. [Google Scholar] [CrossRef] [PubMed]
- Frank, M.G.; Maccario, C.J.; Govindaraju, V. Behavior and security. In Protecting Airline Passengers in the Age of Terrorism; ABC-CLIO: Santa Barbara, CA, USA, 2009; pp. 86–106. [Google Scholar]
- Frank, M.; Herbasz, M.; Sinuk, K.; Keller, A.; Nolan, C. I see how you feel: Training laypeople and professionals to recognize fleeting emotions. In Annual Meeting of the International Communication Association; Sheraton New York: New York, NY, USA, 2009; pp. 1–35. [Google Scholar]
- Ekman, P. Lie catching and microexpressions. Philos. Decept. 2009, 1, 5. [Google Scholar]
- Yan, W.J.; Wu, Q.; Liu, Y.J.; Wang, S.J.; Fu, X. CASME database: A dataset of spontaneous micro-expressions collected from neutralized faces. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013. [Google Scholar]
- Yan, W.J.; Li, X.; Wang, S.J.; Zhao, G.; Liu, Y.J.; Chen, Y.H.; Fu, X. CASME II: An improved spontaneous micro-expression database and the baseline evaluation. PLoS ONE 2014, 9, e86041. [Google Scholar] [CrossRef] [PubMed]
- Qu, F.; Wang, S.J.; Yan, W.J.; Li, H.; Wu, S.; Fu, X. CAS (ME) 2: A database for spontaneous macro-expression and micro-expression spotting and recognition. IEEE Trans. Affect. Comput. 2017, 9, 424–436. [Google Scholar] [CrossRef]
- Li, J.; Dong, Z.; Lu, S.; Wang, S.J.; Yan, W.J.; Ma, Y.; Liu, Y.; Huang, C.; Fu, X. CAS (ME) 3: A Third Generation Facial Spontaneous Micro-Expression Database with Depth Information and High Ecological Validity. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 2782–2800. [Google Scholar] [CrossRef] [PubMed]
- Pfister, T.; Li, X.; Zhao, G.; Pietikäinen, M. Recognising spontaneous facial micro-expressions. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1449–1456. [Google Scholar]
- Li, X.; Pfister, T.; Huang, X.; Zhao, G.; Pietikäinen, M. A spontaneous micro-expression database: Inducement, collection and baseline. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013. [Google Scholar]
- Davison, A.K.; Lansley, C.; Costen, N.; Tan, K.; Yap, M.H. Samm: A spontaneous micro-facial movement dataset. IEEE Trans. Affect. Comput. 2016, 9, 116–129. [Google Scholar] [CrossRef]
- Zhao, G.; Pietikainen, M. Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 915–928. [Google Scholar] [CrossRef]
- Huang, X.; Wang, S.J.; Zhao, G.; Piteikainen, M. Facial micro-expression recognition using spatiotemporal local binary pattern with integral projection. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 1–9. [Google Scholar]
- Li, X.; Hong, X.; Moilanen, A.; Huang, X.; Pfister, T.; Zhao, G.; Pietikäinen, M. Towards reading hidden emotions: A comparative study of spontaneous micro-expression spotting and recognition methods. IEEE Trans. Affect. Comput. 2017, 9, 563–577. [Google Scholar] [CrossRef]
- Zong, Y.; Huang, X.; Zheng, W.; Cui, Z.; Zhao, G. Learning from hierarchical spatiotemporal descriptors for micro-expression recognition. IEEE Trans. Multimed. 2018, 20, 3160–3172. [Google Scholar] [CrossRef]
- Xia, Z.; Hong, X.; Gao, X.; Feng, X.; Zhao, G. Spatiotemporal recurrent convolutional networks for recognizing spontaneous micro-expressions. IEEE Trans. Multimed. 2019, 22, 626–640. [Google Scholar] [CrossRef]
- Wei, M.; Zheng, W.; Jiang, X.; Zong, Y.; Lu, C.; Liu, J. A Novel Magnification-Robust Network with Sparse Self-Attention for Micro-expression Recognition. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 1120–1126. [Google Scholar]
- Zhu, J.; Zong, Y.; Chang, H.; Xiao, Y.; Zhao, L. A Sparse-Based Transformer Network with Associated Spatiotemporal Feature for Micro-Expression Recognition. IEEE Signal Process. Lett. 2022, 29, 2073–2077. [Google Scholar] [CrossRef]
- Zong, Y.; Huang, X.; Zheng, W.; Cui, Z.; Zhao, G. Learning a target sample re-generator for cross-database micro-expression recognition. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 872–880. [Google Scholar]
- Zong, Y.; Zheng, W.; Hong, X.; Tang, C.; Cui, Z.; Zhao, G. Cross-database micro-expression recognition: A benchmark. In Proceedings of the 2019 on International Conference on Multimedia Retrieval, Ottawa, ON, Canada, 10–13 June 2019; pp. 354–363. [Google Scholar]
- Xia, Z.; Liang, H.; Hong, X.; Feng, X. Cross-database micro-expression recognition with deep convolutional networks. In Proceedings of the 2019 3rd International Conference on Biometric Engineering and Applications, Stockholm, Sweden, 29–31 May 2019; pp. 56–60. [Google Scholar]
- Zong, Y.; Zheng, W.; Huang, X.; Shi, J.; Cui, Z.; Zhao, G. Domain regeneration for cross-database micro-expression recognition. IEEE Trans. Image Process. 2018, 27, 2484–2498. [Google Scholar] [CrossRef]
- Zhang, T.; Zong, Y.; Zheng, W.; Chen, C.P.; Hong, X.; Tang, C.; Cui, Z.; Zhao, G. Cross-Database Micro-Expression Recognition: A Benchmark. IEEE Trans. Knowl. Data Eng. 2022, 34, 544–559. [Google Scholar] [CrossRef]
- Zong, Y.; Zheng, W.; Cui, Z.; Zhao, G.; Hu, B. Toward bridging microexpressions from different domains. IEEE Trans. Cybern. 2020, 50, 5047–5060. [Google Scholar] [CrossRef]
- Jiang, X.; Zong, Y.; Zheng, W.; Liu, J.; Wei, M. Seeking Salient Facial Regions for Cross-Database Micro-Expression Recognition. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 1019–1025. [Google Scholar]
- Li, J.; Hu, R.; Mukherjee, M. Discriminative Region Transfer Network for Cross-Database Micro-Expression Recognition. In Proceedings of the ICC 2022-IEEE International Conference on Communications, Seoul, Repulic of Korea, 16–20 May 2022; pp. 5082–5087. [Google Scholar]
- Song, B.; Zong, Y.; Li, K.; Zhu, J.; Shi, J.; Zhao, L. Cross-Database Micro-Expression Recognition Based on a Dual-Stream Convolutional Neural Network. IEEE Access 2022, 10, 66227–66237. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin, Germany, 1999. [Google Scholar]
- Zheng, W. Multi-view facial expression recognition based on group sparse reduced-rank regression. IEEE Trans. Affect. Comput. 2014, 5, 71–85. [Google Scholar] [CrossRef]
- Lin, Z.; Liu, R.; Su, Z. Linearized alternating direction method with adaptive penalty for low-rank representation. Adv. Neural Inf. Process. Syst. 2011, 24, 1–9. [Google Scholar]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. 2010, 22, 199–210. [Google Scholar] [CrossRef]
- Gong, B.; Shi, Y.; Sha, F.; Grauman, K. Geodesic flow kernel for unsupervised domain adaptation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2066–2073. [Google Scholar]
- Fernando, B.; Habrard, A.; Sebban, M.; Tuytelaars, T. Unsupervised visual domain adaptation using subspace alignment. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2960–2967. [Google Scholar]
- Long, M.; Wang, J.; Sun, J.; Philip, S.Y. Domain invariant transfer kernel learning. IEEE Trans. Knowl. Data Eng. 2014, 27, 1519–1532. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| ME Database | Negative | Positive | Surprise | Summation |
|---|---|---|---|---|
| CASME II (C) | 73 | 32 | 25 | 130 |
| HS (H) | 70 | 51 | 43 | 164 |
| VIS (V) | 28 | 23 | 20 | 71 |
| NIR (N) | 28 | 23 | 20 | 71 |
| Method | C→ H | H→C | C→V | V→C | C→N | N→C | Average |
|---|---|---|---|---|---|---|---|
| SVM | 36.97 | 32.45 | 47.01 | 53.67 | 52.95 | 23.68 | 41.12 |
| TCA | 46.37 | 48.70 | 68.34 | 57.89 | 49.92 | 39.37 | 51.77 |
| GFK | 41.26 | 47.76 | 63.61 | 60.56 | 51.80 | 44.69 | 51.61 |
| SA | 43.02 | 54.47 | 59.39 | 52.43 | 57.38 | 35.92 | 48.77 |
| TKL | 38.29 | 46.61 | 60.42 | 53.78 | 53.92 | 42.48 | 49.25 |
| TSRG | 50.42 | 51.71 | 59.35 | 62.08 | 56.24 | 41.05 | 53.48 |
| DRLS-T | 45.24 | 54.60 | 62.17 | 67.62 | 53.69 | 46.53 | 54.98 |
| DRLS | 49.24 | 52.67 | 57.57 | 59.42 | 48.85 | 38.38 | 51.02 |
| RSTR | 52.97 | 56.22 | 58.82 | 70.21 | 50.09 | 46.93 | 55.87 |
| TKRM | 52.53 | 59.41 | 70.20 | 65.31 | 50.29 | 51.35 | 58.18 |
| Method | C→ H | H→C | C→V | V→C | C→N | N→C | Average |
|---|---|---|---|---|---|---|---|
| SVM | 45.12 | 48.46 | 50.70 | 53.08 | 42.11 | 23.85 | 45.55 |
| TCA | 46.34 | 53.08 | 69.01 | 59.23 | 50.70 | 42.31 | 50.73 |
| GFK | 46.95 | 50.77 | 66.20 | 61.50 | 53.52 | 46.92 | 54.31 |
| SA | 47.56 | 62.31 | 59.15 | 51.54 | 47.89 | 36.92 | 50.90 |
| TKL | 44.51 | 54.62 | 60.56 | 53.08 | 54.93 | 43.85 | 51.93 |
| TSRG | 51.83 | 60.77 | 59.15 | 63.08 | 56.34 | 46.15 | 56.22 |
| DRLS-T | 46.95 | 60.00 | 63.38 | 68.46 | 56.34 | 50.77 | 57.65 |
| DRLS | 53.05 | 59.23 | 57.75 | 60.00 | 49.83 | 42.37 | 53.71 |
| RSTR | 54.27 | 60.77 | 59.15 | 70.77 | 50.70 | 50.77 | 57.74 |
| TKRM | 52.44 | 66.15 | 70.42 | 65.38 | 50.70 | 52.31 | 59.57 |
| Kernel Function | C→ H | H→C | C→V |
|---|---|---|---|
| Linear | 52.53/52.44 | 59.41/66.15 | 70.20/70.42 |
| Polynomial () | 52.53/52.44 | 60.02/65.38 | 58.89/69.01 |
| Polynomial () | 51.99/51.83 | 58.46/60.77 | 67.31/67.61 |
| Polynomial () | 52.53/52.44 | 59.39/62.31 | 63.89/63.38 |
| PolyPlus () | 52.53/52.44 | 60.02/65.38 | 68.89/69.01 |
| PolyPlus () | 51.99/51.83 | 58.46/60.77 | 67.35/67.61 |
| PolyPlus () | 51.85/51.83 | 59.39/62.31 | 70.20/70.42 |
| Gaussian () | 37.93/40.24 | 47.14/57.69 | 51.25/50.70 |
| Gaussian () | 50.61/50.61 | 57.22/57.60 | 67.65/67.61 |
| Gaussian () | 49.45/49.35 | 51.74/52.31 | 66.05/66.20 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Lu, C.; Zhou, F.; Zong, Y. TKRM: Learning a Transfer Kernel Regression Model for Cross-Database Micro-Expression Recognition. Mathematics 2023, 11, 918. https://doi.org/10.3390/math11040918
Chen Z, Lu C, Zhou F, Zong Y. TKRM: Learning a Transfer Kernel Regression Model for Cross-Database Micro-Expression Recognition. Mathematics. 2023; 11(4):918. https://doi.org/10.3390/math11040918
Chicago/Turabian StyleChen, Zixuan, Cheng Lu, Feng Zhou, and Yuan Zong. 2023. "TKRM: Learning a Transfer Kernel Regression Model for Cross-Database Micro-Expression Recognition" Mathematics 11, no. 4: 918. https://doi.org/10.3390/math11040918
APA StyleChen, Z., Lu, C., Zhou, F., & Zong, Y. (2023). TKRM: Learning a Transfer Kernel Regression Model for Cross-Database Micro-Expression Recognition. Mathematics, 11(4), 918. https://doi.org/10.3390/math11040918