

Geo-Spatial Mapping of Hate Speech Prediction in Roman Urdu

 ,
, 
 , and
, and 
Abstract
:1. Introduction
- This research work contributes to a detailed analysis of current approaches employed for the classification of hate speech in Roman Urdu. It also presents a review of the literature on data sets developed by previous studies and a comparative analysis that highlights the strengths and weaknesses of these studies.
- This research proposes a complete dataset of Roman Urdu political hate speech (RU-PHS) containing 5002 instances along with their labels and city-level location information.
- To overcome the vast lexical structure of Roman Urdu, an algorithm for the lexical unification of Roman Urdu is proposed, by leveraging regular expressions.
- A comparative analysis between conventional machine learning models, a feed-forward neural network, and a conventional neural network using dense word representations (i.e., TF-IDF, word2vec, and fastText) is presented for the classification and prediction of political hate speech.
- A spatial data analysis of the RU-PHS dataset in terms of hotspots and clusters is conducted to predict future affected areas in Pakistan.
2. Preliminaries
2.1. Text Classification
2.2. Sentiment Analysis
2.2.1. Fine-Grained
2.2.2. Aspect Based
2.2.3. Emotion Detection
2.2.4. Intent Analysis
3. Related Work
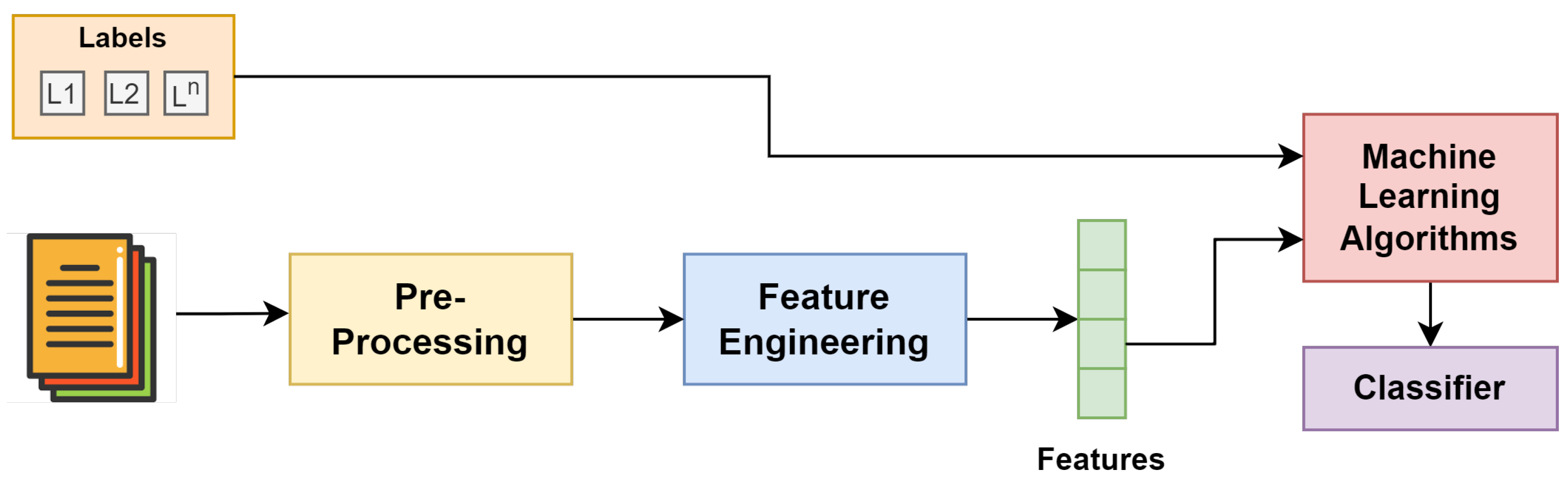
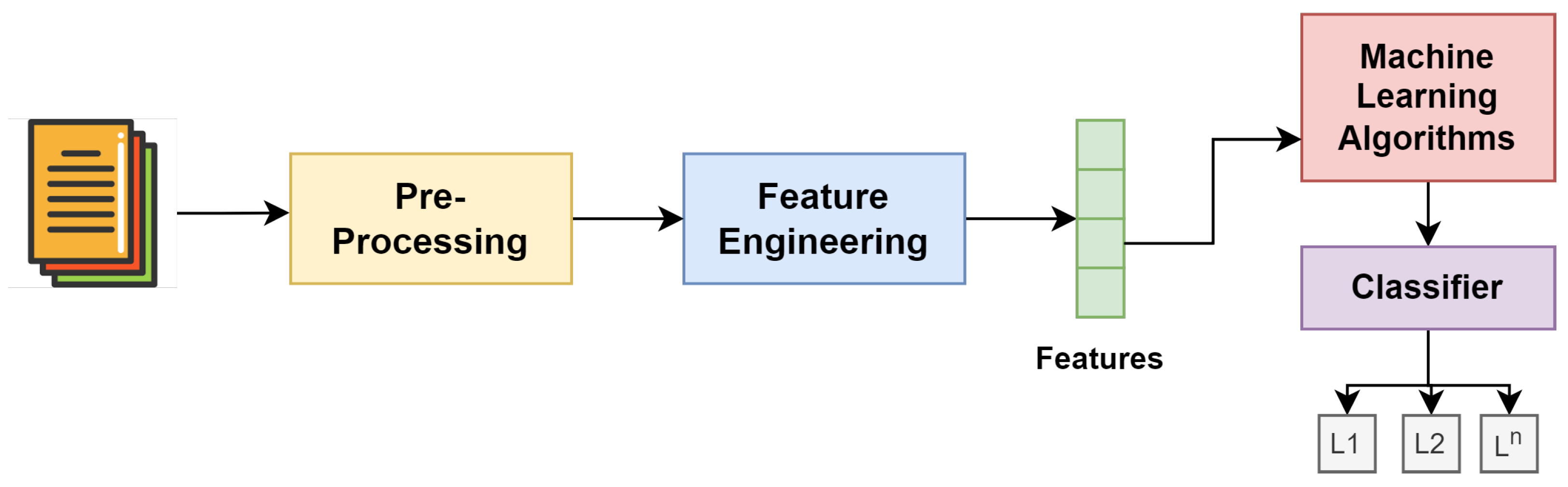
4. Proposed Methodology
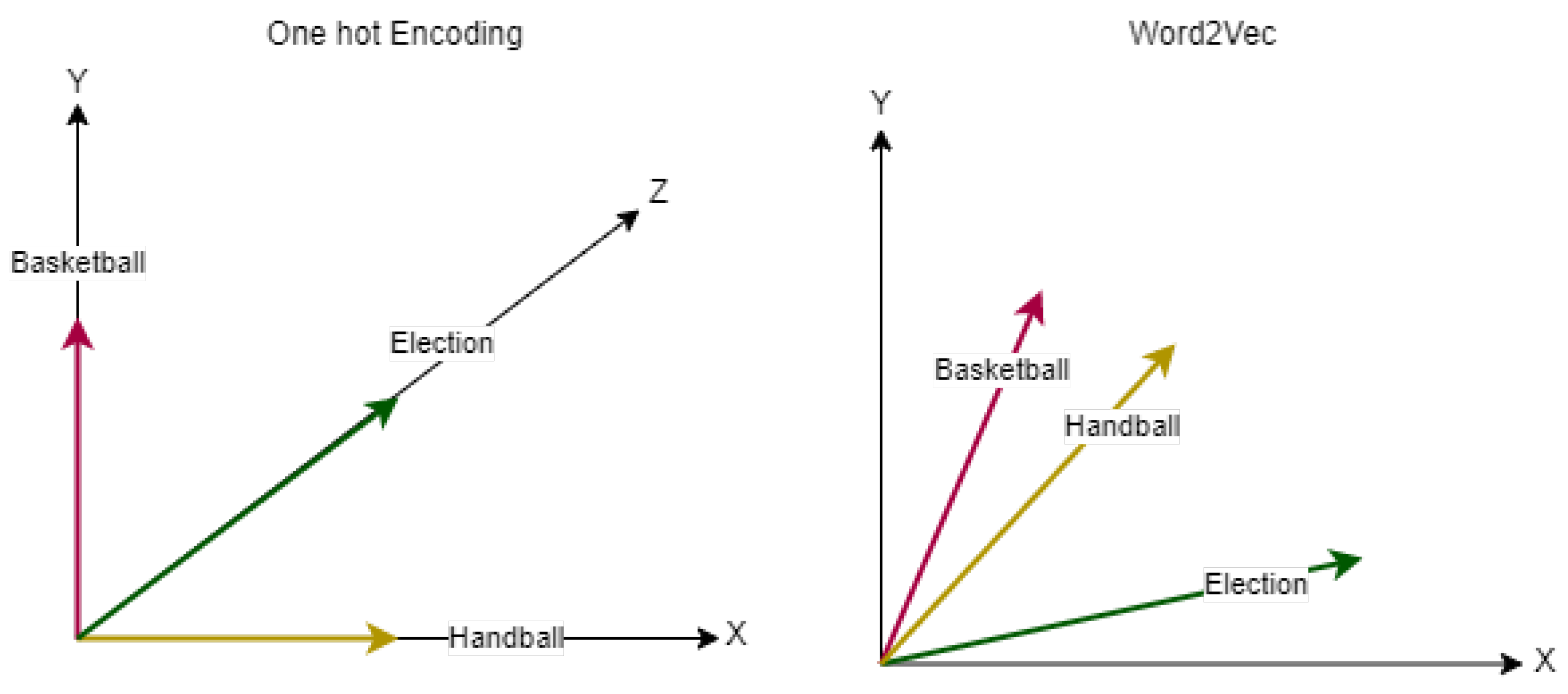
4.1. Representing Words
4.1.1. TF-IDF
4.1.2. word2vec
- Continuous bag-of-words (CBOW);
- Continuous skip-gram (CSG).
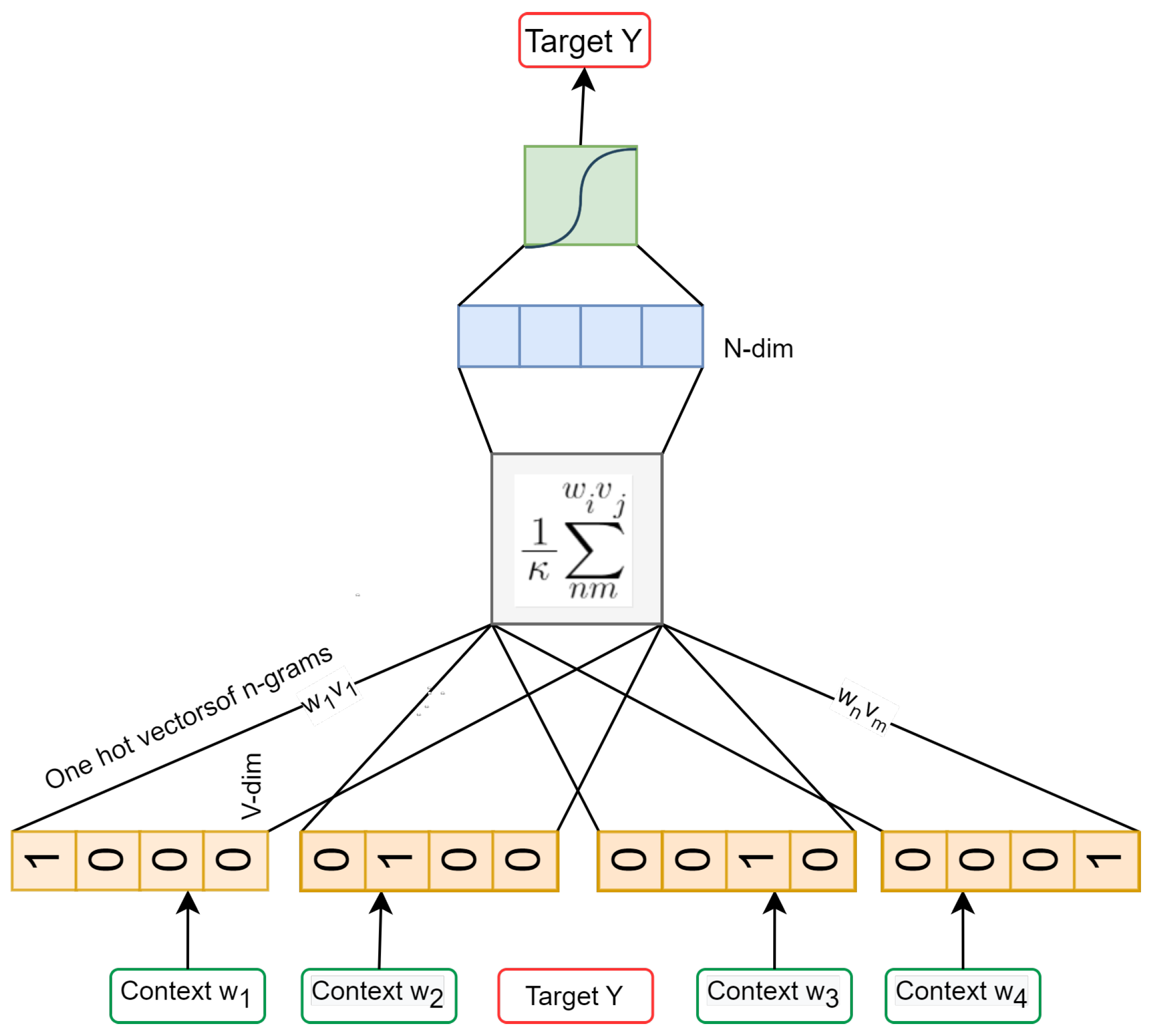
4.1.3. fastText
4.2. Machine Learning for Political Hate Speech Detection
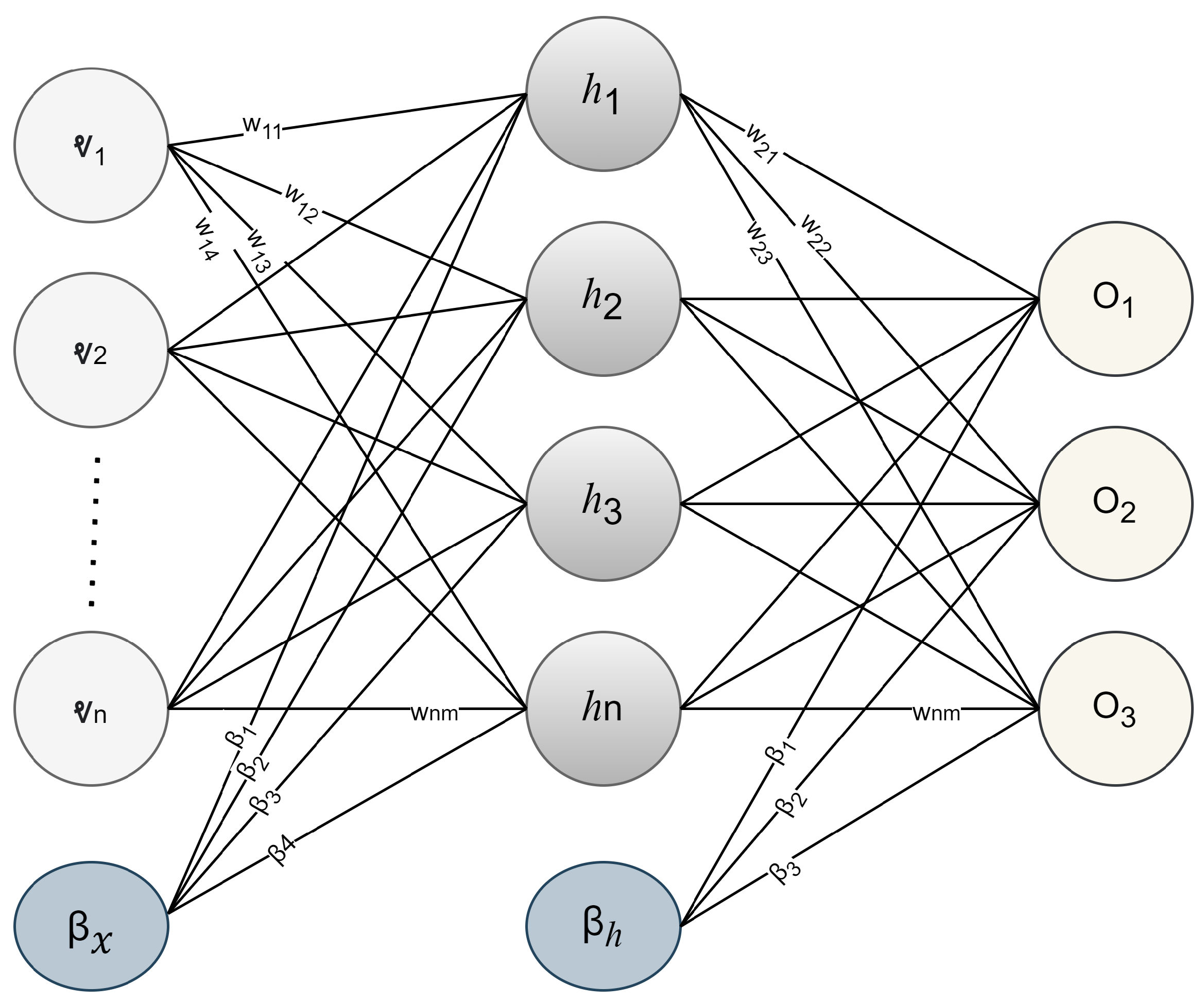
4.2.1. Feed-Forward Neural Network
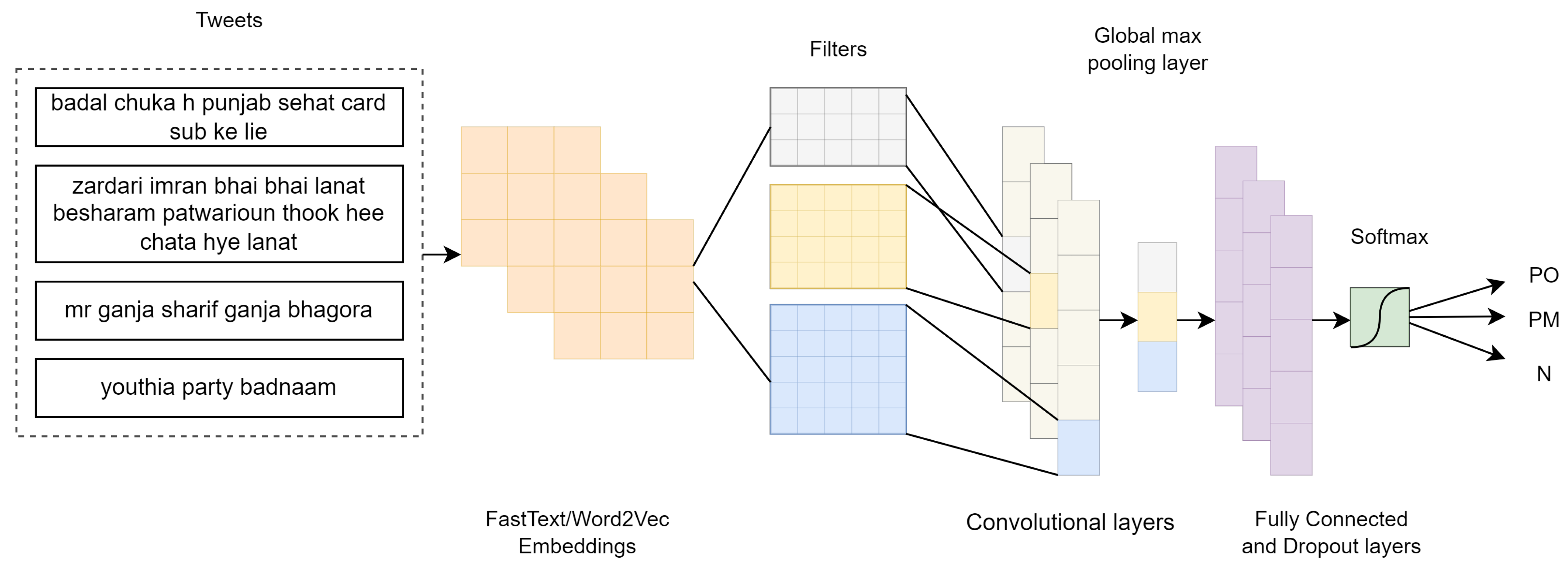
4.2.2. Convolutional Neural Network
5. Implementation
5.1. RU-PHS Dataset
5.2. Preprocessing
5.2.1. Guideline Development
5.2.2. Data Annotation
5.2.3. Custom Stop Words
5.2.4. Lexical Unification
| Algorithm 1: RU Lexical Unification by Removing Vowels. | |
| 1. | Read CSV file containing scraped data |
| 2. | Clean the data by removing |
| a. @mentions, #hashtags, URLs, and Unicode characters. b. White spaces including from the start and end of the line. c. Non-English, numeric values, and special symbols. | |
| 3. | Compute a list F of the most frequently occurring words |
| 4. | Select strings with the highest frequency |
| 5. | Create a list of vowels V |
| 6. | Compare each string to the list of vowels |
| a. Convert strings to lowercase b. For each x in input string S c. If x is in V Replace it with empty space else Retain it as it is | |
| 7. | Replace all instances of the original string in the CSV file with the resultant string. |
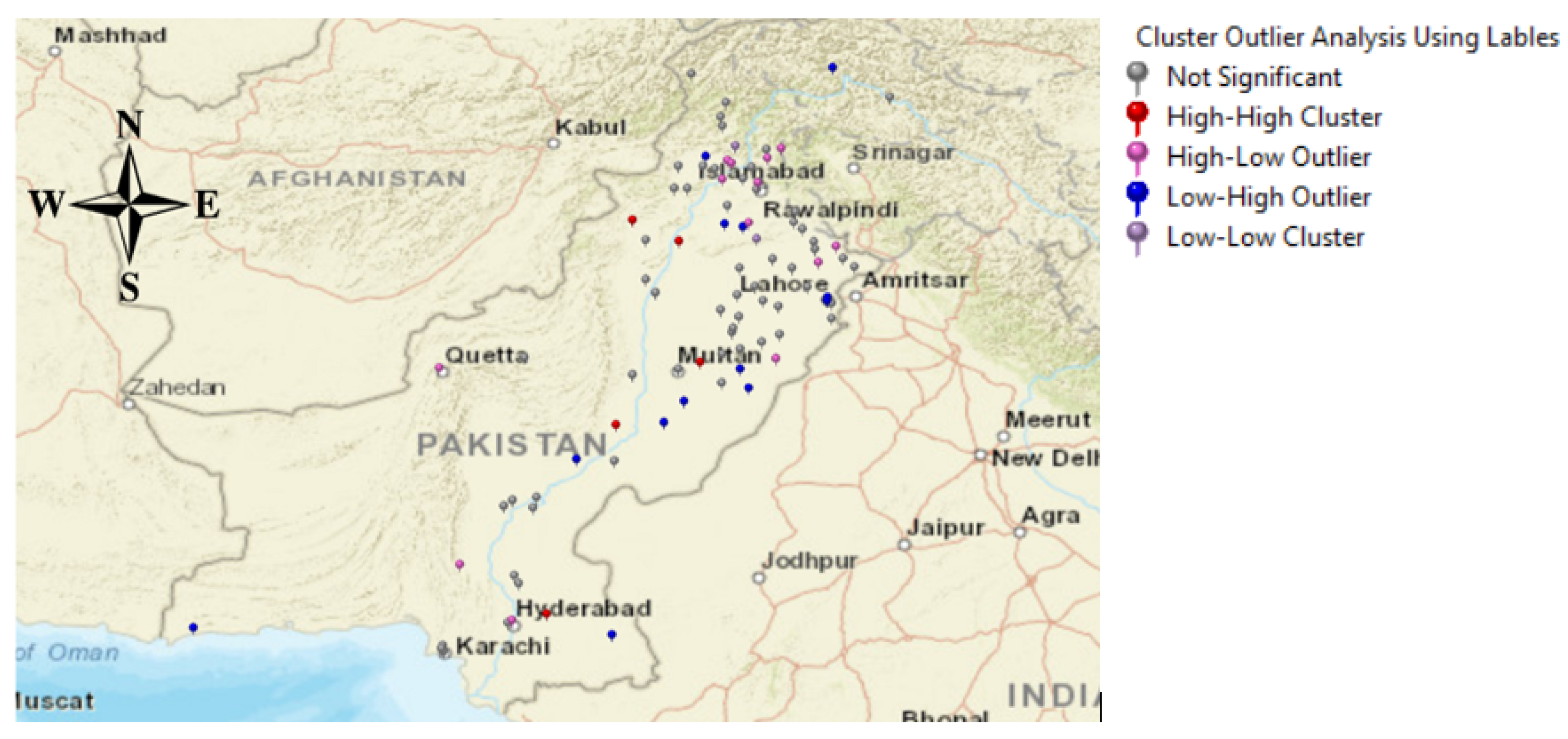
6. Spatial Data Analysis of Political Hate Speech
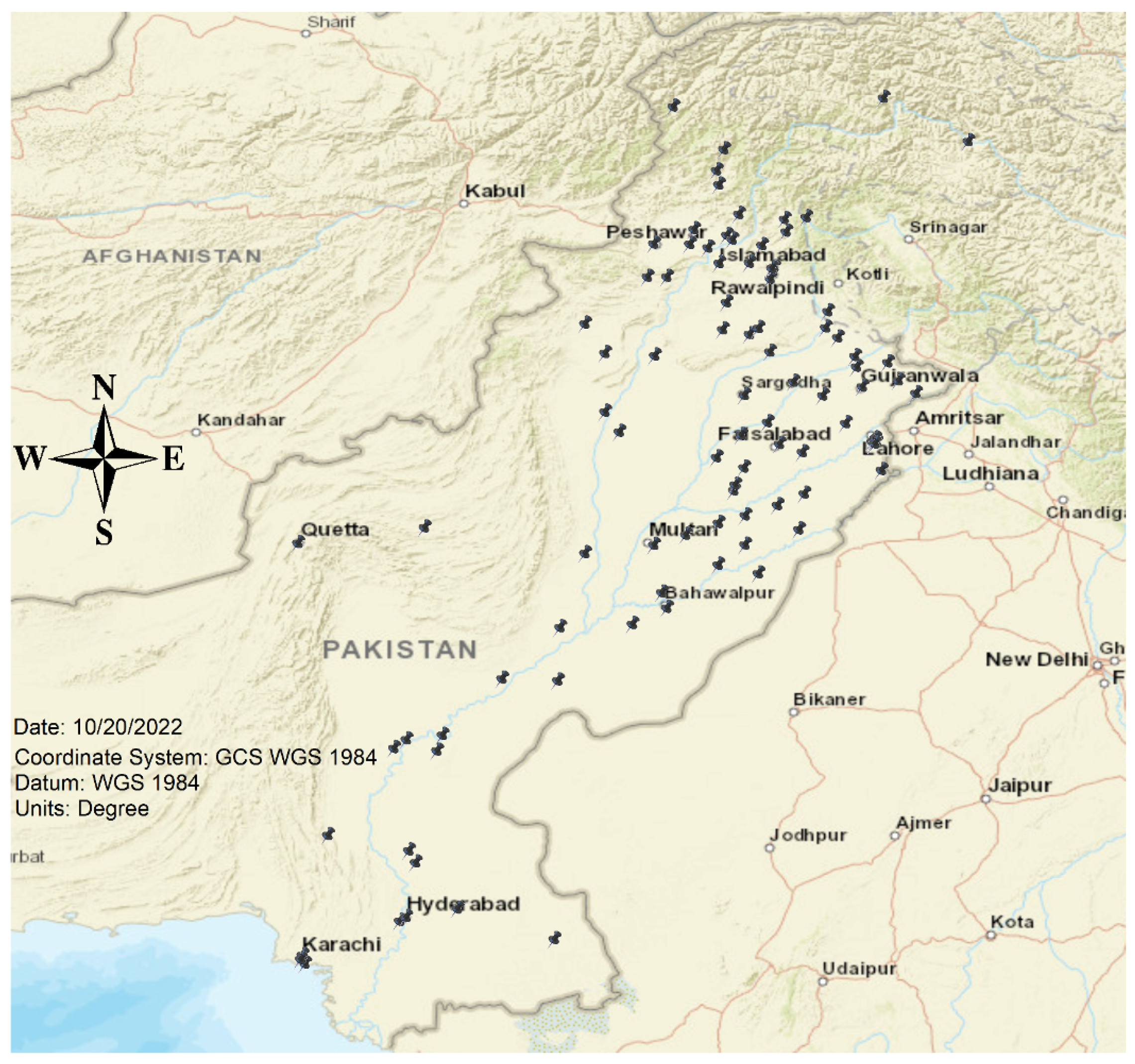
6.1. Geocoding
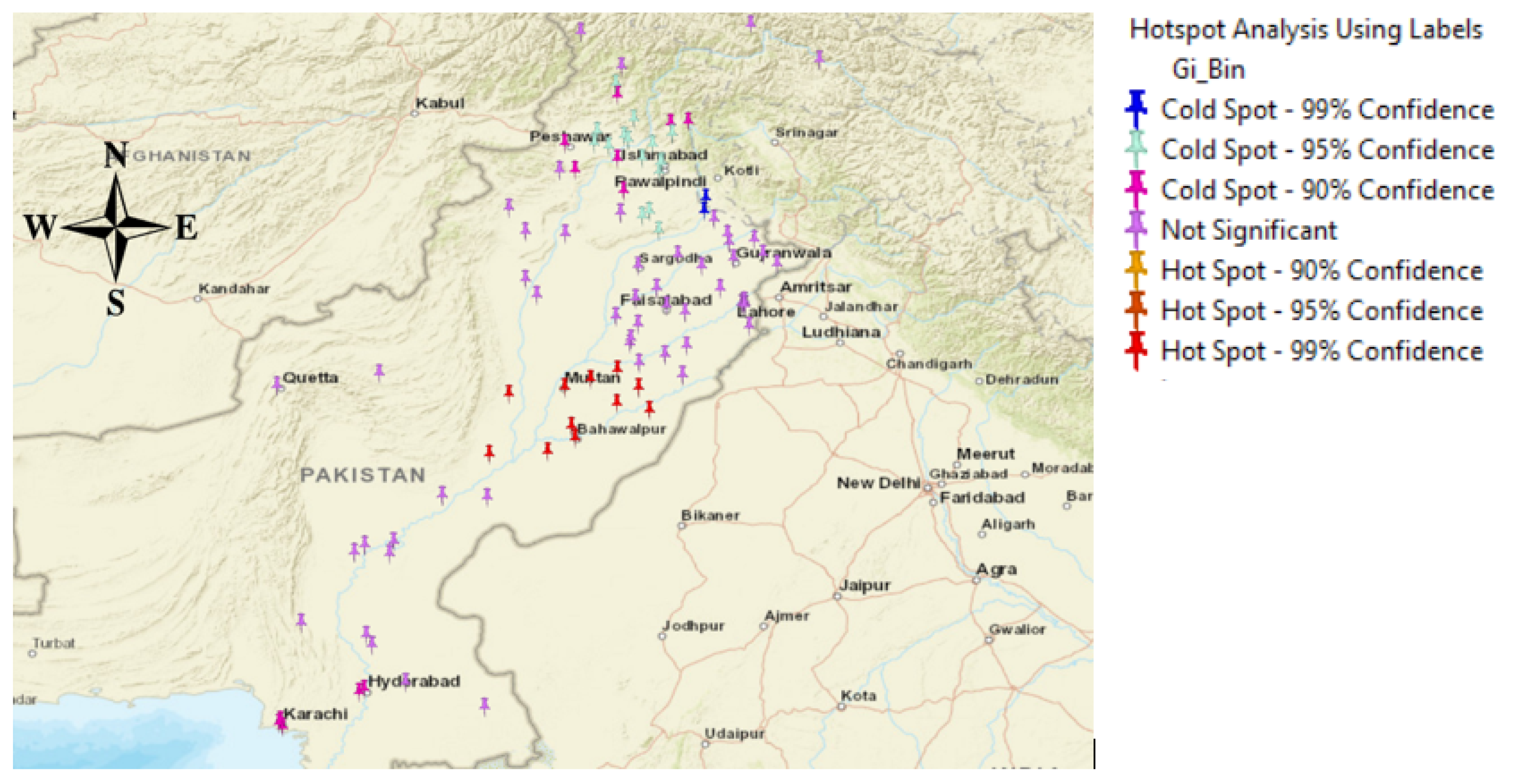
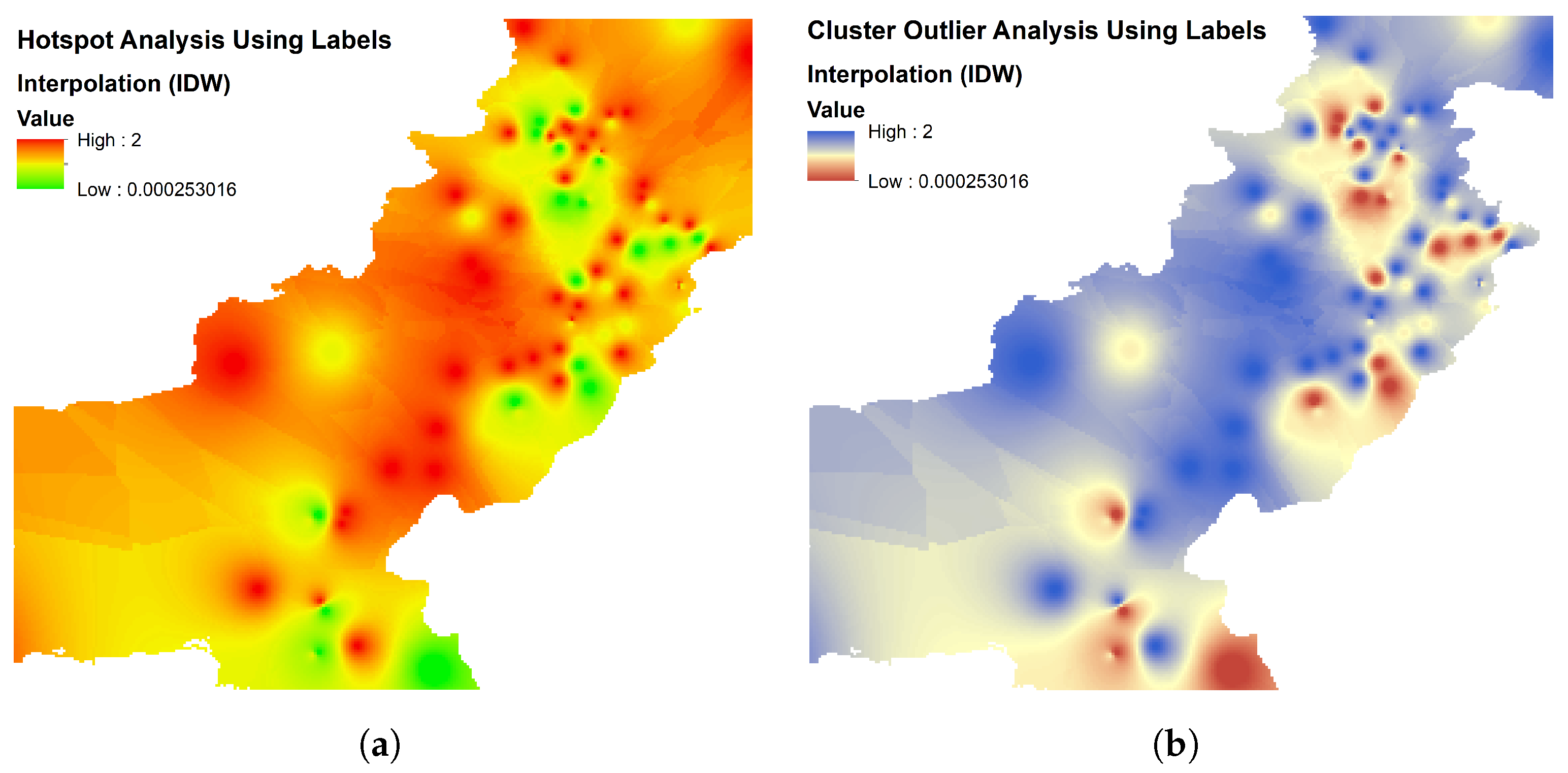
6.2. Hotspot Analysis
6.3. Cluster Analysis
6.4. Interpolation
7. Results and Discussions
7.1. Hyperparameters
7.2. Model Training and Validation
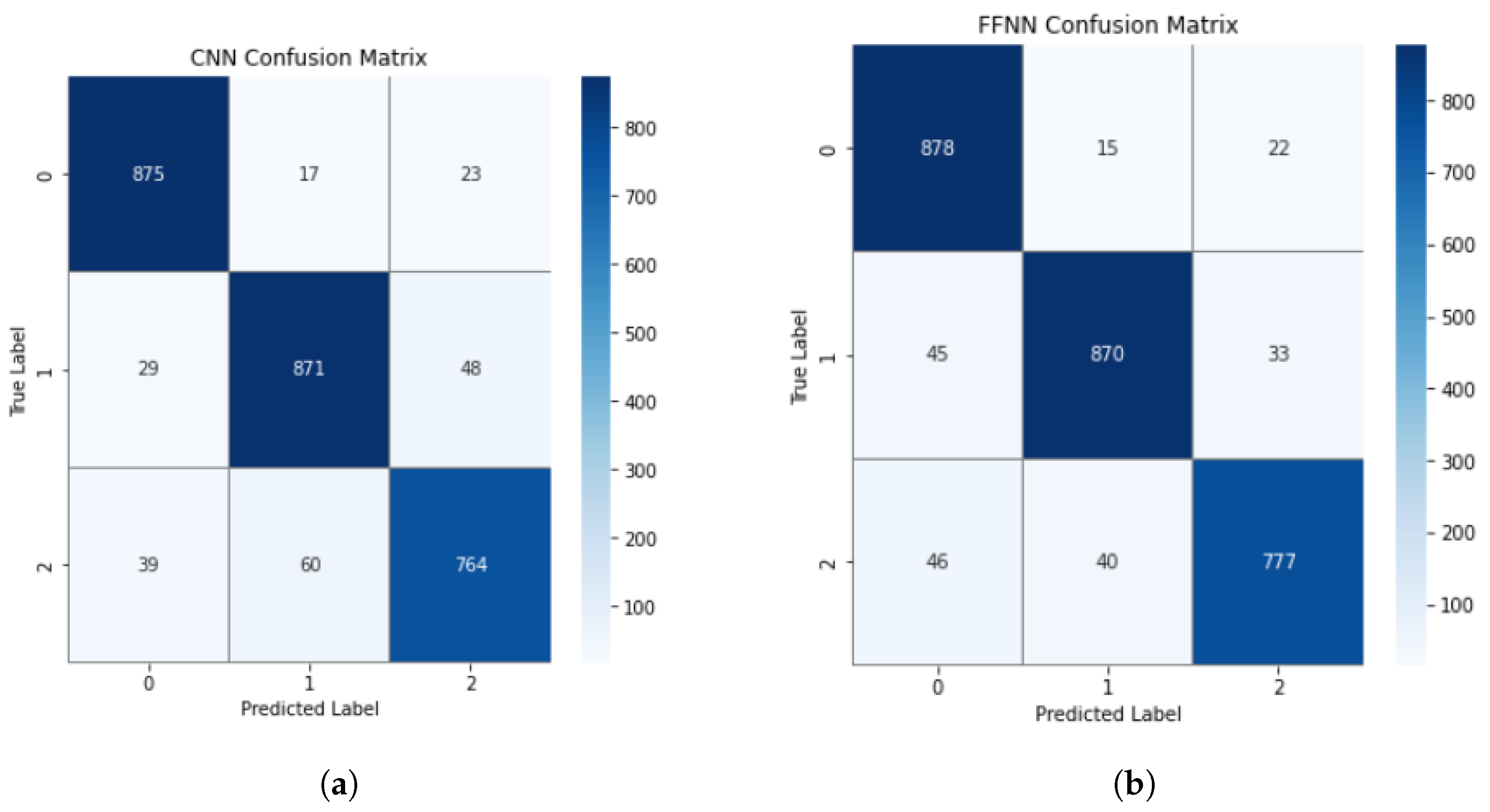
7.3. Accuracy
8. Conclusions and Future Directions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gitari, N.D.; Zuping, Z.; Damien, H.; Long, J. A lexicon-based approach for hate speech detection. Int. J. Multimed. Ubiquitous Eng. 2015, 10, 215–230. [Google Scholar] [CrossRef]
- Aslam, S. Twitter by the Numbers: Stats, Demographics & Fun Facts. 2022. Available online: https://www.omnicoreagency.com/twitter-statistics/ (accessed on 8 June 2022).
- Djuric, N.; Zhou, J.; Morris, R.; Grbovic, M.; Radosavljevic, V.; Bhamidipati, N. Hate speech detection with comment embeddings. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 29–30. [Google Scholar]
- Saeed, H.H.; Ashraf, M.H.; Kamiran, F.; Karim, A.; Calders, T. Roman Urdu toxic comment classification. Lang. Resour. Eval. 2021, 55, 971–996. [Google Scholar] [CrossRef]
- Naqvi, R.A.; Khan, M.A.; Malik, N.; Saqib, S.; Alyas, T.; Hussain, D. Roman Urdu news headline classification empowered with machine learning. Comput. Mater. Contin. 2020, 65, 1221–1236. [Google Scholar]
- Mehmood, F.; Ghani, M.U.; Ibrahim, M.A.; Shahzadi, R.; Mahmood, W.; Asim, M.N. A precisely xtreme-multi channel hybrid approach for roman urdu sentiment analysis. IEEE Access 2020, 8, 192740–192759. [Google Scholar] [CrossRef]
- Jiang, M.; Liang, Y.; Feng, X.; Fan, X.; Pei, Z.; Xue, Y.; Guan, R. Text classification based on deep belief network and softmax regression. Neural Comput. Appl. 2018, 29, 61–70. [Google Scholar] [CrossRef]
- Dulac-Arnold, G.; Denoyer, L.; Gallinari, P. Text classification: A sequential reading approach. In Proceedings of the European Conference on Information Retrieval, Stavanger, Norway, 10–14 April 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 411–423. [Google Scholar]
- Bollen, J.; Gonçalves, B.; Ruan, G.; Mao, H. Happiness is assortative in online social networks. Artif. life 2011, 17, 237–251. [Google Scholar] [CrossRef] [PubMed]
- Khan, M.M.; Shahzad, K.; Malik, M.K. Hate speech detection in roman urdu. ACM Trans. Asian Low-Resour. Lang. Inf. Process. (TALLIP) 2021, 20, 1–19. [Google Scholar] [CrossRef]
- Rizwan, H.; Shakeel, M.H.; Karim, A. Hate-speech and offensive language detection in roman Urdu. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 2512–2522. [Google Scholar]
- Martins, R.; Gomes, M.; Almeida, J.J.; Novais, P.; Henriques, P. Hate speech classification in social media using emotional analysis. In Proceedings of the 2018 7th Brazilian Conference on Intelligent Systems (BRACIS), Sao Paulo, Brazil, 22–25 October 2018; pp. 61–66. [Google Scholar]
- Bilal, M.; Israr, H.; Shahid, M.; Khan, A. Sentiment classification of Roman-Urdu opinions using Naïve Bayesian, Decision Tree and KNN classification techniques. J. King Saud Univ.-Comput. Inf. Sci. 2016, 28, 330–344. [Google Scholar] [CrossRef]
- Alam, M.; Hussain, S.U. Roman-Urdu-Parl: Roman-Urdu and Urdu Parallel Corpus for Urdu Language Understanding. Trans. Asian Low-Resour. Lang. Inf. Process. 2022, 21, 1–20. [Google Scholar] [CrossRef]
- Younas, A.; Nasim, R.; Ali, S.; Wang, G.; Qi, F. Sentiment Analysis of Code-Mixed Roman Urdu-English Social Media Text using Deep Learning Approaches. In Proceedings of the 2020 IEEE 23rd International Conference on Computational Science and Engineering (CSE), Guangzhou, China, 29 December 2020–1 January 2021; pp. 66–71. [Google Scholar]
- Wasswa, H.W. The Role of Social Media in the 2013 Presidential Election Campaigns in Kenya. Ph.D. Thesis, University of Nairobi, Nairobi, Kenya, 2013. [Google Scholar]
- Mukund, S.; Srihari, R.K. Analyzing Urdu social media for sentiments using transfer learning with controlled translations. In Proceedings of the Second Workshop on Language in Social Media, Montreal, QC, Canada, 7 June 2012; pp. 1–8. [Google Scholar]
- Tehreem, T. Sentiment analysis for youtube comments in roman urdu. arXiv 2021, arXiv:2102.10075. [Google Scholar]
- Aimal, M.; Bakhtyar, M.; Baber, J.; Lakho, S.; Mohammad, U.; Ahmed, W.; Karim, J. Identifying negativity factors from social media text corpus using sentiment analysis method. arXiv 2021, arXiv:2107.02175. [Google Scholar]
- Habiba, R.; Awais, D.M.; Shoaib, D.M. A Technique to Calculate National Happiness Index by Analyzing Roman Urdu Messages Posted on Social Media. ACM Trans. Asian Low-Resour. Lang. Inf. Process. (TALLIP) 2020, 19, 1–16. [Google Scholar] [CrossRef]
- Hussain, A.; Arshad, M.U. An Attention Based Neural Network for Code Switching Detection: English & Roman Urdu. arXiv 2021, arXiv:2103.02252. [Google Scholar]
- Sadia, H.; Ullah, M.; Hussain, T.; Gul, N.; Hussain, M.F.; ul Haq, N.; Bakar, A. An efficient way of finding polarity of roman urdu reviews by using Boolean rules. Scalable Comput. Pract. Exp. 2020, 21, 277–289. [Google Scholar] [CrossRef]
- Rana, T.A.; Shahzadi, K.; Rana, T.; Arshad, A.; Tubishat, M. An Unsupervised Approach for Sentiment Analysis on Social Media Short Text Classification in Roman Urdu. Trans. Asian Low-Resour. Lang. Inf. Process. 2021, 21, 1–16. [Google Scholar] [CrossRef]
- Akhter, M.P.; Jiangbin, Z.; Naqvi, I.R.; Abdelmajeed, M.; Sadiq, M.T. Automatic detection of offensive language for urdu and roman urdu. IEEE Access 2020, 8, 91213–91226. [Google Scholar] [CrossRef]
- Santosh, T.; Aravind, K. Hate speech detection in hindi-english code-mixed social media text. In Proceedings of the ACM India Joint International Conference on Data Science and Management of Data, Kolkata, India, 3–5 January 2019; pp. 310–313. [Google Scholar]
- Arshad, M.U.; Bashir, M.F.; Majeed, A.; Shahzad, W.; Beg, M.O. Corpus for emotion detection on roman urdu. In Proceedings of the 2019 22nd International Multitopic Conference (INMIC), Islamabad, Pakistan, 29–30 November 2019; pp. 1–6. [Google Scholar]
- Mahmood, Z.; Safder, I.; Nawab, R.M.A.; Bukhari, F.; Nawaz, R.; Alfakeeh, A.S.; Aljohani, N.R.; Hassan, S.U. Deep sentiments in roman urdu text using recurrent convolutional neural network model. Inf. Process. Manag. 2020, 57, 102233. [Google Scholar] [CrossRef]
- Mehmood, K.; Essam, D.; Shafi, K.; Malik, M.K. Discriminative feature spamming technique for roman urdu sentiment analysis. IEEE Access 2019, 7, 47991–48002. [Google Scholar] [CrossRef]
- Mukhtar, N.; Khan, M.A. Effective lexicon-based approach for Urdu sentiment analysis. Artif. Intell. Rev. 2020, 53, 2521–2548. [Google Scholar] [CrossRef]
- Majeed, A.; Mujtaba, H.; Beg, M.O. Emotion detection in roman urdu text using machine learning. In Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering Workshops, Virtual Event, Australia, 21–25 December 2020; pp. 125–130. [Google Scholar]
- Naqvi, U.; Majid, A.; Abbas, S.A. UTSA: Urdu text sentiment analysis using deep learning methods. IEEE Access 2021, 9, 114085–114094. [Google Scholar] [CrossRef]
- Chen, Y.; Zhou, Y.; Zhu, S.; Xu, H. Detecting offensive language in social media to protect adolescent online safety. In Proceedings of the 2012 International Conference on Privacy, Security, Risk and Trust and 2012 International Confernece on Social Computing, Amsterdam, The Netherlands, 3–5 September 2012; pp. 71–80. [Google Scholar]
- Xiang, G.; Fan, B.; Wang, L.; Hong, J.; Rose, C. Detecting offensive tweets via topical feature discovery over a large scale twitter corpus. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management, Maui, HI, USA, 29 October–2 November 2012; pp. 1980–1984. [Google Scholar]
- Dinakar, K.; Jones, B.; Havasi, C.; Lieberman, H.; Picard, R. Common sense reasoning for detection, prevention, and mitigation of cyberbullying. ACM Trans. Interact. Intell. Syst. (TiiS) 2012, 2, 1–30. [Google Scholar] [CrossRef]
- Warner, W.; Hirschberg, J. Detecting hate speech on the world wide web. In Proceedings of the Second Workshop on Language in Social Media, Montreal, QC, Canada, 7 June 2012; pp. 19–26. [Google Scholar]
- Wadhwa, P.; Bhatia, M. Tracking on-line radicalization using investigative data mining. In Proceedings of the 2013 National Conference on Communications (NCC), New Delhi, India, 15–17 February 2013; pp. 1–5. [Google Scholar]
- Kwok, I.; Wang, Y. Locate the hate: Detecting tweets against blacks. In Proceedings of the Twenty-Seventh AAAI Conference on Artificial Intelligence, Bellevue, WA, USA, 14–18 July 2013. [Google Scholar]
- Nahar, V.; Al-Maskari, S.; Li, X.; Pang, C. Semi-supervised learning for cyberbullying detection in social networks. In Proceedings of the Australasian Database Conference, Brisbane, QLD, Australia, 14–16 July 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 160–171. [Google Scholar]
- Burnap, P.; Williams, M.L. Hate speech, machine classification and statistical modelling of information flows on Twitter: Interpretation and communication for policy decision making. In Proceedings of the Internet, Policy & Politics, Oxford, UK, 26 September 2014. [Google Scholar]
- Agarwal, S.; Sureka, A. Using knn and svm based one-class classifier for detecting online radicalization on twitter. In Proceedings of the International Conference on Distributed Computing and Internet Technology, Bhubaneswar, India, 5–8 February 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 431–442. [Google Scholar]
- Waseem, Z.; Hovy, D. Hateful symbols or hateful people? predictive features for hate speech detection on twitter. In Proceedings of the NAACL Student Research Workshop, San Diego, CA, USA, 12–17 June 2016; pp. 88–93. [Google Scholar]
- Di Capua, M.; Di Nardo, E.; Petrosino, A. Unsupervised cyber bullying detection in social networks. In Proceedings of the 2016 23rd International conference on pattern recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 432–437. [Google Scholar]
- Park, J.H.; Fung, P. One-step and two-step classification for abusive language detection on twitter. arXiv 2017, arXiv:1706.01206. [Google Scholar]
- Chen, H.; McKeever, S.; Delany, S.J. Abusive Text Detection Using Neural Networks. In Proceedings of the AICS, Dublin, Ireland, 7–8 December 2017; pp. 258–260. [Google Scholar]
- Badjatiya, P.; Gupta, S.; Gupta, M.; Varma, V. Deep learning for hate speech detection in tweets. In Proceedings of the 6th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017; pp. 759–760. [Google Scholar]
- Wiegand, M.; Ruppenhofer, J.; Schmidt, A.; Greenberg, C. Inducing a lexicon of abusive words–a feature-based approach. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Long Papers. Association for Computational Linguistics: Cedarville, OH, USA, 2019; Volume 1, pp. 1046–1056. [Google Scholar]
- Pawar, R.; Agrawal, Y.; Joshi, A.; Gorrepati, R.; Raje, R.R. Cyberbullying detection system with multiple server configurations. In Proceedings of the 2018 IEEE International Conference on Electro/Information Technology (EIT), Rochester, MI, USA, 3–5 May 2018; pp. 90–95. [Google Scholar]
- Watanabe, H.; Bouazizi, M.; Ohtsuki, T. Hate speech on twitter: A pragmatic approach to collect hateful and offensive expressions and perform hate speech detection. IEEE Access 2018, 6, 13825–13835. [Google Scholar] [CrossRef]
- Malmasi, S.; Zampieri, M. Challenges in discriminating profanity from hate speech. J. Exp. Theor. Artif. Intell. 2018, 30, 187–202. [Google Scholar] [CrossRef]
- Pitsilis, G.K.; Ramampiaro, H.; Langseth, H. Effective hate-speech detection in Twitter data using recurrent neural networks. Appl. Intell. 2018, 48, 4730–4742. [Google Scholar] [CrossRef] [Green Version]
- Fernandez, M.; Alani, H. Contextual semantics for radicalisation detection on Twitter. In Proceedings of the Semantic Web for Social Good Workshop (SW4SG) at International Semantic Web Conference 2018, Monterey, CA, USA, 9 October 2018. [Google Scholar]
- Ousidhoum, N.; Lin, Z.; Zhang, H.; Song, Y.; Yeung, D.Y. Multilingual and multi-aspect hate speech analysis. arXiv 2019, arXiv:1908.11049. [Google Scholar]
- Zhang, Z.; Luo, L. Hate speech detection: A solved problem? the challenging case of long tail on twitter. Semant. Web 2019, 10, 925–945. [Google Scholar] [CrossRef]
- Kaur, A.; Gupta, V. N-gram based approach for opinion mining of Punjabi text. In Proceedings of the International Workshop on Multi-Disciplinary Trends in Artificial Intelligence, Bangalore, India, 8–10 December 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 81–88. [Google Scholar]
- Ashari, A.; Paryudi, I.; Tjoa, A.M. Performance comparison between Naïve Bayes, decision tree and k-nearest neighbor in searching alternative design in an energy simulation tool. Int. J. Adv. Comput. Sci. Appl. (IJACSA) 2013, 4, 33–39. [Google Scholar] [CrossRef]
- Syed, A.Z.; Aslam, M.; Martinez-Enriquez, A.M. Lexicon based sentiment analysis of Urdu text using SentiUnits. In Proceedings of the Mexican International Conference on Artificial Intelligence, Pachuca, Mexico, 8–13 November 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 32–43. [Google Scholar]
- Ghulam, H.; Zeng, F.; Li, W.; Xiao, Y. Deep learning-based sentiment analysis for roman urdu text. Procedia Comput. Sci. 2019, 147, 131–135. [Google Scholar] [CrossRef]
- Khan, L.; Amjad, A.; Afaq, K.M.; Chang, H.T. Deep sentiment analysis using CNN-LSTM architecture of English and Roman Urdu text shared in social media. Appl. Sci. 2022, 12, 2694. [Google Scholar] [CrossRef]
- Sharf, Z.; Rahman, S.U. Lexical normalization of roman Urdu text. Int. J. Comput. Sci. Netw. Secur. 2017, 17, 213–221. [Google Scholar]
- Sharf, Z.; Mansoor, H.A. Opinion mining in roman urdu using baseline classifiers. Int. J. Comput. Sci. Netw. Secur. 2018, 18, 156–164. [Google Scholar]
- Sharjeel, M.; Nawab, R.M.A.; Rayson, P. COUNTER: Corpus of Urdu news text reuse. Lang. Resour. Eval. 2017, 51, 777–803. [Google Scholar] [CrossRef]
- Dzakiyullah, N.R.; Hussin, B.; Saleh, C.; Handani, A.M. Comparison neural network and support vector machine for production quantity prediction. Adv. Sci. Lett. 2014, 20, 2129–2133. [Google Scholar] [CrossRef]
- Bose, R.; Aithal, P.; Roy, S. Sentiment analysis on the basis of tweeter comments of application of drugs by customary language toolkit and textblob opinions of distinct countries. Int. J. 2020, 8, 3684–3696. [Google Scholar]
- Suri, N.; Verma, T. Multilingual Sentimental Analysis on Twitter Dataset: A Review. Int. J. Adv. Comput. Sci. Appl. 2017, 10, 2789–2799. [Google Scholar]
- Jebaseel, A.; Kirubakaran, D.E. M-learning sentiment analysis with data mining techniques. Int. J. Comput. Sci. Telecommun. 2012, 3, 45–48. [Google Scholar]
- Gamallo, P.; Garcia, M. Citius: A Naive-Bayes Strategy for Sentiment Analysis on English Tweets. In Proceedings of the Semeval@Coling, Dublin, Ireland, 23–24 August 2014; pp. 171–175. [Google Scholar]
- Peña, A.; Mesias, J.; Patiño, A.; Carvalho, J.V.; Gomez, G.; Ibarra, K.; Bedoya, S. PANAS-TDL: A psychrometric deep learning model for characterizing sentiments of tourists against the COVID-19 pandemic on Twitter. In Advances in Tourism, Technology and Systems: Selected Papers from ICOTTS20; Springer: Berlin/Heidelberg, Germany, 2021; Volume 2, pp. 162–176. [Google Scholar]
- Jing, L.P.; Huang, H.K.; Shi, H.B. Improved feature selection approach TFIDF in text mining. In Proceedings of the International Conference on Machine Learning and Cybernetics, Beijing, China, 4–5 November 2002; Volume 2, pp. 944–946. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 1–9. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef] [Green Version]
- Zell, A. Simulation Neuronaler Netze; Addison-Wesley: Bonn, Germany, 1994; Volume 1. [Google Scholar]
- Johnson, R.; Zhang, T. Effective use of word order for text categorization with convolutional neural networks. arXiv 2014, arXiv:1412.1058. [Google Scholar]
- Chakravorty, S. Identifying crime clusters: The spatial principles. Middle States Geogr. 1995, 28, 53–58. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Corpus | Language | Frequency | Type |
|---|---|---|---|---|
| [6] | DSL RU Sentiments | Roman Urdu | 3241 | Sentiments |
| [16] | RUT | Roman Urdu | 72,000 | Comments |
| [3] | HS-RU-20 | Roman Urdu | 5000 | Tweets |
| [11] | RUHSOLD | Roman Urdu | 10,012 | Tweets |
| [13] | No Corpus Name | Roman Urdu | 300 | Opinions |
| [15] | MultiSenti | RU and English | 20,735 | Tweets |
| [17] | UCSA | Urdu | 9601 | Reviews |
| [18] | No Corpus Name | Roman Urdu | 14,131 | YouTube Comments |
| [19] | No Corpus Name | English | 2577 | Tweets |
| [20] | No Corpus Name | Roman Urdu | 1000 | Tweets |
| [21] | Aryan Urdu | English and RU | _ | _ |
| [22] | No Corpus Name | Roman Urdu | 454 | Reviews |
| [23] | UCI RUSA-19 | Roman Urdu | 20,229, 10,016 | Sentences |
| [24] | UOD | Urdu RU | 2171 | YouTube Comments |
| [25] | TRAC-1 HS HOT | Hindi-English | 12,000, 11,623 | Sentences |
| [26] | RUED | Roman Urdu | 20,000 | Sentences |
| [27] | RUSA-19 | Roman Urdu | 10,021 | Sentences |
| [28] | Roman Urdu (RU) | Roman Urdu | 11,000 | Reviews |
| [29] | No Corpus Name | Urdu | 6025 | Sentences |
| [30] | No Corpus Name | Roman Urdu | 18,000 | Sentences |
| [12] | Existing Dataset | English | 24,782 | Tweets |
| [31] | No Corpus Name | Urdu | 6000 | Sentences |
| Ref. | YouTube | Yahoo | Formspring | Wikipedia | Slashdot | ||
|---|---|---|---|---|---|---|---|
| [3] | ✓ | ||||||
| [32] | ✓ | ||||||
| [33] | ✓ | ||||||
| [34] | ✓ | ||||||
| [35] | ✓ | ||||||
| [36] | ✓ | ||||||
| [37] | ✓ | ||||||
| [38] | ✓ | ||||||
| [39] | ✓ | ||||||
| [40] | ✓ | ||||||
| [41] | ✓ | ||||||
| [42] | ✓ | ✓ | ✓ | ||||
| [43] | ✓ | ||||||
| [44] | ✓ | ✓ | |||||
| [45] | ✓ | ||||||
| [46] | ✓ | ✓ | |||||
| [47] | ✓ | ||||||
| [48] | ✓ | ||||||
| [49] | ✓ | ||||||
| [50] | ✓ | ||||||
| [51] | ✓ | ||||||
| [52] | ✓ | ||||||
| [53] | ✓ |
| Ref. | Strengths | Weaknesses |
|---|---|---|
| [56] | Classification of Urdu sentences on document-level, lexicon-based sentiment analysis | No method to tackle implicit negation Noun phrases not considered |
| [57] | Utilized long short-term memory (LSTM) for polarity detection in Roman Urdu | No validation of data collection process, no data preprocessing method declared Methods were not transparent |
| [58] | 806 Roman Urdu sentences collection, feature construction, and application on different multilingual classifiers | Limited dataset No structure of the dataset |
| [59] | Lexicon- and rule-based methods used to construct an RU classification algorithm, ML, and phonetic techniques used | Limited categorization of the dataset No normalizing of the dataset |
| [60] | 15,000 roman Urdu sentences collected | The dataset contained biographies and was not general |
| [31] | 22,000 sentences of RU were collected; supervised and unsupervised methods were used | Ambiguous combination of classifiers |
| [61] | 1200 text documents of Urdu news were collected; performed a linguistic analysis | No character-level features used Needs evaluation on state-of-the-art semantic techniques |
| [62] | Existing values collated to different techniques | No dataset mentioned No classification methods mentioned |
| [63] | A massive dataset of 5 sentiments; use of lexical classifying techniques | Confusing representation of the dataset Lack of credible results |
| [64] | 1000 reviews collected and various frameworks compared, i.e., Hadoop MapReduce | Limited dataset; classifiers were not general and were overfitting on the given dataset |
| Representation | Decomposition |
|---|---|
| Word | Bhagora |
| Character | B+h+a+g+o+r+a |
| Character 2-gram | Bh+ha+ag+go+or+ra |
| Character 3-gram | Bha+hag+ago+gor+ora |
| Labels | Full Form | #tweets | #Words |
|---|---|---|---|
| PO | Politically offensive | 3028 | 273,379 |
| PM | Politically medium | 1190 | 80,322 |
| N | Neutral | 784 | 46,553 |
| Classes | Guidelines |
|---|---|
| A tweet or phrase belonged to the “political hate speech” class if it met any or all of the following parameters: | |
| Political hate speech | If a tweet had a hate term about a political figure, political party, government or if it targeted the followers of a specific political party. For example, “Ap ka baap nawaz bhagora chor h” translated in English as “Your father Nawaz is a truant and thief”. Some other offensive terms could be “youthia” and “patwari” targeting the supporters of specific political parties. |
| Neutral | A tweet or phrase corresponded to the “neutral” class if it lacked any of the criteria mentioned for the political hate speech class, for example, “Wsa hi acha lgta ha mujha nawaz sharef” translated in English as “I just like nawaz sharef”. |
| Offensive | A tweet or phrase that belonged to the “political hate speech” class was further classified as “offensive”, if the tweet had abusive terms or symbols promoting hostility, igniting anger, or inciting harm to an individual political entity or a group of people that belonged to a political party or that supported a political profile. For example, “Bhounktey rahhooooo nawaz chor” translated in English as “Keep on barking nawaz thief”. |
| Medium/little offensive | A tweet or phrase that belonged to the “political hate speech” class was further classified as “sarcasm/little offensive”, if the tweet mocked and conveyed contempt against a political individual, political party, and supporter of a specific political profile yet if it did not contain explicit hate words. |
| For example, “Bilkul thek kaha ap nay nawaz Shareef nay boht investment ki h hmare adliya pay” translated in English as “You are right, Nawaz shareef has invested a lot in our judiciary system”. |
| Words | Frequency | Normalized |
|---|---|---|
| Kampain | 74 | Kmpn |
| Kampein | 65 | Kmpn |
| Kampain | 55 | Kmpn |
| Kanpay | 25 | Knpy |
| Kanpein | 15 | Knpn |
| Kanpen | 12 | Knpn |
| kanpien | 11 | knpn |
| Sr. | Layer | Type | Output Shape | Parameters | Activation |
|---|---|---|---|---|---|
| 1 | Input | Embedding | (None, 200, 50) | 689,950 | - |
| 2 | Hidden | Flatten | (None, 10,000) | 0 | - |
| 3 | Hidden | Dense | (None, 64) | 640,064 | ReLu |
| 4 | Hidden | Dense | (None, 32) | 2080 | ReLu |
| 5 | Output | Dense | (None, 3) | 99 | Softmax |
| Sr. | Layer | Type | Output Shape | Parameters | Activation |
|---|---|---|---|---|---|
| 1 | Input | Embedding | (None, 200, 50) | 689,950 | - |
| 2 | Hidden | Conv1D | (None, 196, 128) | 32,128 | Relu |
| 3 | Hidden | GlobalMaxPooling1D | (None, 128) | 0 | - |
| 4 | Hidden | Dense | (None, 10) | 1290 | Relu |
| 5 | Output | Dense | (None, 3) | 33 | Softmax |
| Technique | Classifier | Features | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|---|---|
| Bayes | Multinomial naïve Bayes | TF-IDF word2vec(CBOW) word2vec(CSG) fastText(CBOW) fastText(CSG) | 87 50 60 66 69 | 88 57 64 70 72 | 88 51 60 67 70 | 87 52 61 66 69 |
| SVM | Linear | TF-IDF word2vec(CBOW) word2vec(CSG) fastText(CBOW) fastText(CSG) | 89 62 70 74 75 | 90 70 75 76 77 | 90 73 70 74 76 | 90 73 70 74 77 |
| Random | Forest | TF-IDF word2vec(CBOW) word2vec(CSG) fastText(CBOW) fastText(CSG) | 91 88 91 91 93 | 92 89 92 89 92 | 91 89 92 91 93 | 91 89 92 91 93 |
| Regression | Gradient boosting | TF-IDF word2vec(CBOW) word2vec(CSG) fastText(CBOW) fastText(CSG) | 90 91 92 90 90 | 91 90 92 91 90 | 91 91 92 94 92 | 91 91 92 91 92 |
| XgBoost | TF-IDF word2vec(CBOW) word2vec(CSG) fastText(CBOW) fastText(CSG) | 84 70 77 82 89 | 86 74 80 84 90 | 85 70 78 83 91 | 85 70 78 83 91 | |
| Neural networks | Feed-forward neural network | word2vec(CBOW) word2vec(CSG) fastText(CBOW) fastText(CSG) | 65 72 85 93 | 71 77 86 90 | 65 72 91 92 | 65 72 89 93 |
| Convolutional neural network | word2vec(CBOW) word2vec(CSG) fastText(CBOW) fastText(CSG) | 70 89 85 92 | 75 91 88 92 | 71 90 89 91 | 71 89 89 92 |
| Classifier | MNB | LSVM | RF | GB | FFNN | CNN |
|---|---|---|---|---|---|---|
| Features | TF-IDF | TF-IDF | fastText(CSG) | W2V(CSG) | fastText(CSG) | fastText(CSG) |
| Time | 2 s | 6 s | 80 s | 60 s | 17 s | 20 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aziz, S.; Sarfraz, M.S.; Usman, M.; Aftab, M.U.; Rauf, H.T. Geo-Spatial Mapping of Hate Speech Prediction in Roman Urdu. Mathematics 2023, 11, 969. https://doi.org/10.3390/math11040969
Aziz S, Sarfraz MS, Usman M, Aftab MU, Rauf HT. Geo-Spatial Mapping of Hate Speech Prediction in Roman Urdu. Mathematics. 2023; 11(4):969. https://doi.org/10.3390/math11040969
Chicago/Turabian StyleAziz, Samia, Muhammad Shahzad Sarfraz, Muhammad Usman, Muhammad Umar Aftab, and Hafiz Tayyab Rauf. 2023. "Geo-Spatial Mapping of Hate Speech Prediction in Roman Urdu" Mathematics 11, no. 4: 969. https://doi.org/10.3390/math11040969
APA StyleAziz, S., Sarfraz, M. S., Usman, M., Aftab, M. U., & Rauf, H. T. (2023). Geo-Spatial Mapping of Hate Speech Prediction in Roman Urdu. Mathematics, 11(4), 969. https://doi.org/10.3390/math11040969