2.1. Data Set
We analyzed data from eight patients with insulin pump therapy obtained from a pilot study performed at the Hospital Clinic of Barcelona. We use data of 30 weeks, approximately, recollected in different periods between 2020 and 2022. The demographic characteristics of patients are presented in
Table 1. All patients provided written informed consent to participate in this study.
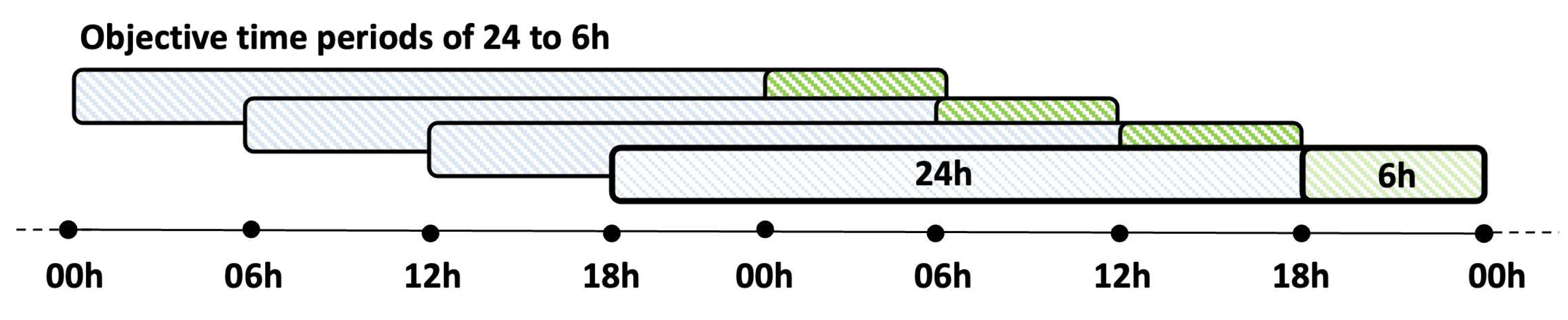
The recruited patients wore different sensors, including the Dexcom G6, the MiniMed 640G, and the FreeStyle Libre. The first two sensor models stored their measurements every 5 min, while the third model stored its measurements every 15 min. First, CGM measurements were preprocessed. Then, 24 h periods starting at 0 h, 6 h, 12 h, and 18 h and their corresponding subsequent period of 6 h were obtained (
Figure 1). The measurements in each period are divided into the five previously mentioned glucose ranges.
The patients’ glucose profiles have unrecorded measurements. Data were linearly interpolated when the gaps of missing data were not greater than two consecutive hours. The missing data that was interpolated is actual missing data. Surely if smaller periods were interpolated or not interpolated at all the quality of the data would improve. In this procedure, the days that had more than 2 h of missing data in the same period of 6 h were eliminated. Finally, a day was considered valid if each of its four 6 h periods had at least 75% of the data.
Table 2 shows the total number of days analyzed, sensors, and valid periods of 24 h and consecutive 6 h periods for each patient.
2.2. CoDa
A composition is a vector
, with
D number of parts whose components are all strictly positive and of constant sum (which can be the unit, 100% (as is our case study), sum of the hours of the day (24 h) or some other constant sum defined by the researcher), according to the “scale invariance” property the chosen value for
k it is irrelevant for the analysis and is only useful for the interpretation of the results:
Historically, CoDa have been identified with closed data, with the simplex being the natural sample space for this data type, while the real Euclidean space is associated with unrestricted data. The basic principles of CoDa analysis that are of special interest in this study are as follows:
(1) scale invariance, which states that CoDa only contains relative information, implying that any change in the scale of the original data do not affect the structure of the composition;
(2) subcompositional coherence, which implies that the results obtained for a subset of parts of a composition, that is, a subcomposition, must be coherent with the results obtained with the complete composition; and
(3) permutation invariance, which indicates that the results do not depend on the order in which the parts appear in the composition [
14].
In this work, the compositional vector X is defined as a composition where each D-part corresponds to the percentage of time in each of the glucose ranges:
Hypoglycemia level 2 ,
Hypoglycemia level 1 (),
Target BG (),
Hyperglycemia level 1 (), and
Hyperglycemia level 2 ()
and is treated as the 5-part composition:
whose constant sum is 100%. Some of the parts of the composition would be zero if no measurements were found in some of the glucose ranges. For example, a composition (0, 0, 100, 0, 0) would mean 100% TIR, another example could be (0, 10, 80, 10, 0) where it would have 10% in hypo and hyper level 1 and 80% in TIR. As CoDa analysis is based on log-ratios of parts, treating zeros appropriately and analyzing incidence patterns is necessary [
20]. In the analyzed measurements, three types of patterns of zeros were identified: non-consecutive zeros, two consecutive zeros, and three consecutive zeros.
The detection limits
matrix used in zero imputation was obtained considering 5- and 15-min fractions, as in Biagi and colleagues [
12], depending on the position of the zero in the compositions. For the sensors that save the measurements every 5 min, one day has 1440/5 = 288 measurement recordings, then the
is calculated as
= 5/1440 = 1/288 = 0.0035; following the same procedure for the sensors that store the samples every 15 min, 1440/15 = 96 measurements, then the
= 15/1440 = 1/96 = 0.0104. Measured values below the thresholds defined in the
matrix cannot be distinguished from a blank signal with a specified confidence level. We considered that the further the zero is from the non-zero value, the smaller this value must be in the
matrix, as presented in
Table A5 of
Appendix A. In none of the periods, the glucose range was found to be always zero for any patient. Therefore, we consider these zeros to be rounded zeros of continuous data, not essential ones.
The replacement of zeros in the vector of times at each of the glucose ranges is performed following Biagi and colleagues [
12] using the robust expectation-maximization (lrEM) [
20,
21]. This model-based function imputes left-censored data (e.g., values below the
, rounded zeros) by representing CoDa coordinates incorporating the relative covariance structure information. When the matrix of zero patterns has a whole column of zeros, the multiplicative replacement method (multRepl) [
20,
22] was considered. This method preserves the covariance structure and is consistent with the properties of CoDa; it consists of multiplicatively imputing the null values with a small preset value. The modification in the values that are not zero is multiplicative; it is consistent with the basic operations in the simplex and the structure of the compositions [
23,
24].
Figure 2 describes the methodology for this work, first for proper preprocessing of BG measurements, then for the validation of the model, and finally, the update of the probabilistic prediction model if it has already been previously validated.
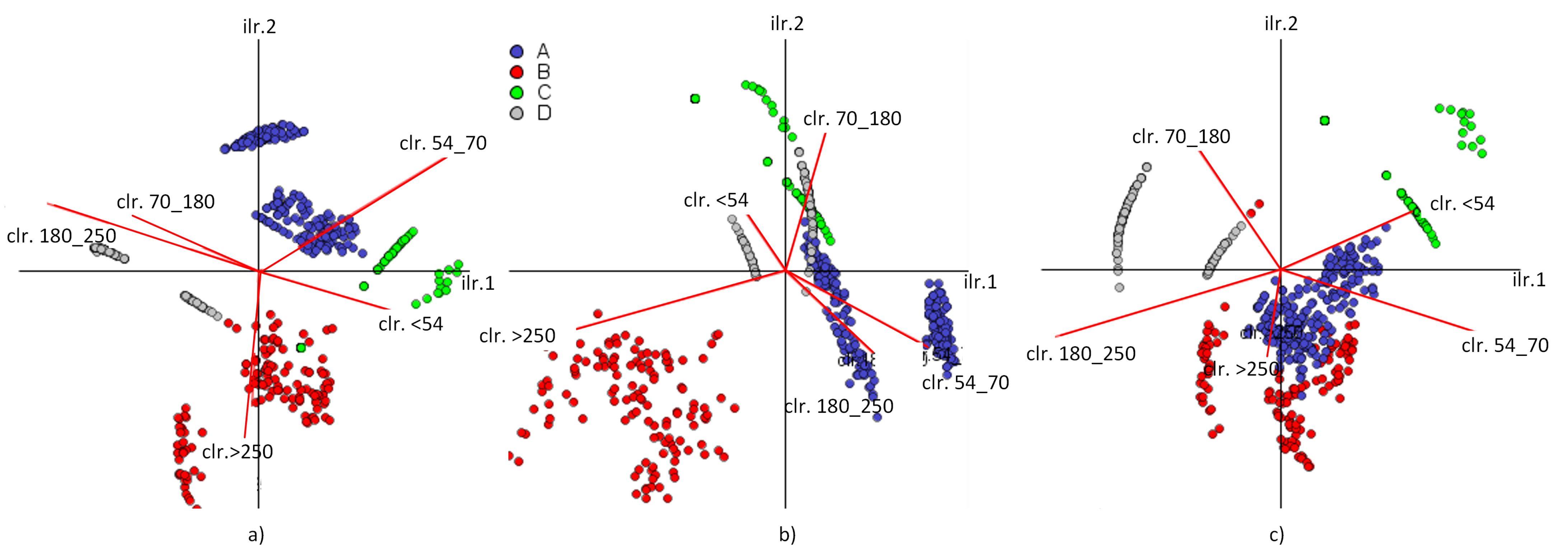
2.2.1. Log-Ratio Coordinates
CoDa can be translated into real space via clr-scores and olr-coordinates, in which, traditional statistical methods can be applied [
14], and are calculated using Equations (
3) and (
4) [
25], where
g is the geometric mean (Equation (
5)),
r and
s are the number of parts in the i-th row of S (sign matrix of the sequential binary partition (SBP)) coded by +1 (positive) and −1 (negative), which will be in the numerator and denominator of the corresponding log-ratio, respectively. Egozcue and Pawlowsky-Glahn [
26] defined the SBP as a hierarchical grouping of parts of the original compositional vector, starting with the complete composition as a group and ending with each part in a single group. If
D is the number of parts in the original composition, then the number of steps in the partition is
. In this study, we considered the SBP presented in
Table 3, which was established according to Biagi and colleagues [
12].
2.2.2. Compositional Measurements
The geometric mean is a representative measure of the center of the CoDa set and identifies the components that better discriminate in the composition. Let
be a compositional data set of
. The compositional geometric mean (
) of the set
X is defined as:
where
represents the geometric mean represents the geometric mean of the k-th component of the data. The variation matrix shows the pairwise log-ratio variance for all parts of the composition. It allows the analysis of the data dispersion. This matrix is defined as
, and in its extended form, is equal to:
where
represents the expected variance of the log-ratio of parts
i and
j. This matrix is based on the contribution of variance for each pairwise log-ratio. However, the variation array is usually preferred in practice. This array is based on the variation matrix where the upper diagonal of the array contains the log-ratio variances and the lower diagonal contains the log-ratio means. That is, the way we show the results in
Table A2 of the
Appendix A, the
-th component of the upper diagonal is var
and the
-th component of the lower diagonal is
, where
i,
[
14].
In real space, the most widely used measure of dispersion is the trace of the covariance matrix associated with the ensemble. However, the interpretability of the direct covariance matrix of a CoDa set is lacking. As this measure is not compatible with CoDa, Pawlowsky-Glahn and Egozcue [
16] defined a measure of variability
equal to the trace of the covariance matrix of the clr-transformed data set:
2.3. Probabilistic Model of Transition
The probabilistic transition model proposed by Biagi et al. [
13] was implemented for 3, 4, and 5 clusters, where the categories from the previous 24 h period to the next 6 h period are counted. The procedure is as follows: suppose the categories are defined as A, B, C, D, and E. First find all the A categories, examine the period after these days and complete a matrix with the counts of each column, as described in
Table 4. Then, with the closure operator defined in Equation (
8), the transition probabilities are calculated at different times of the day.
Table A3 of the
Appendix A shows a particular example of the model for P1.
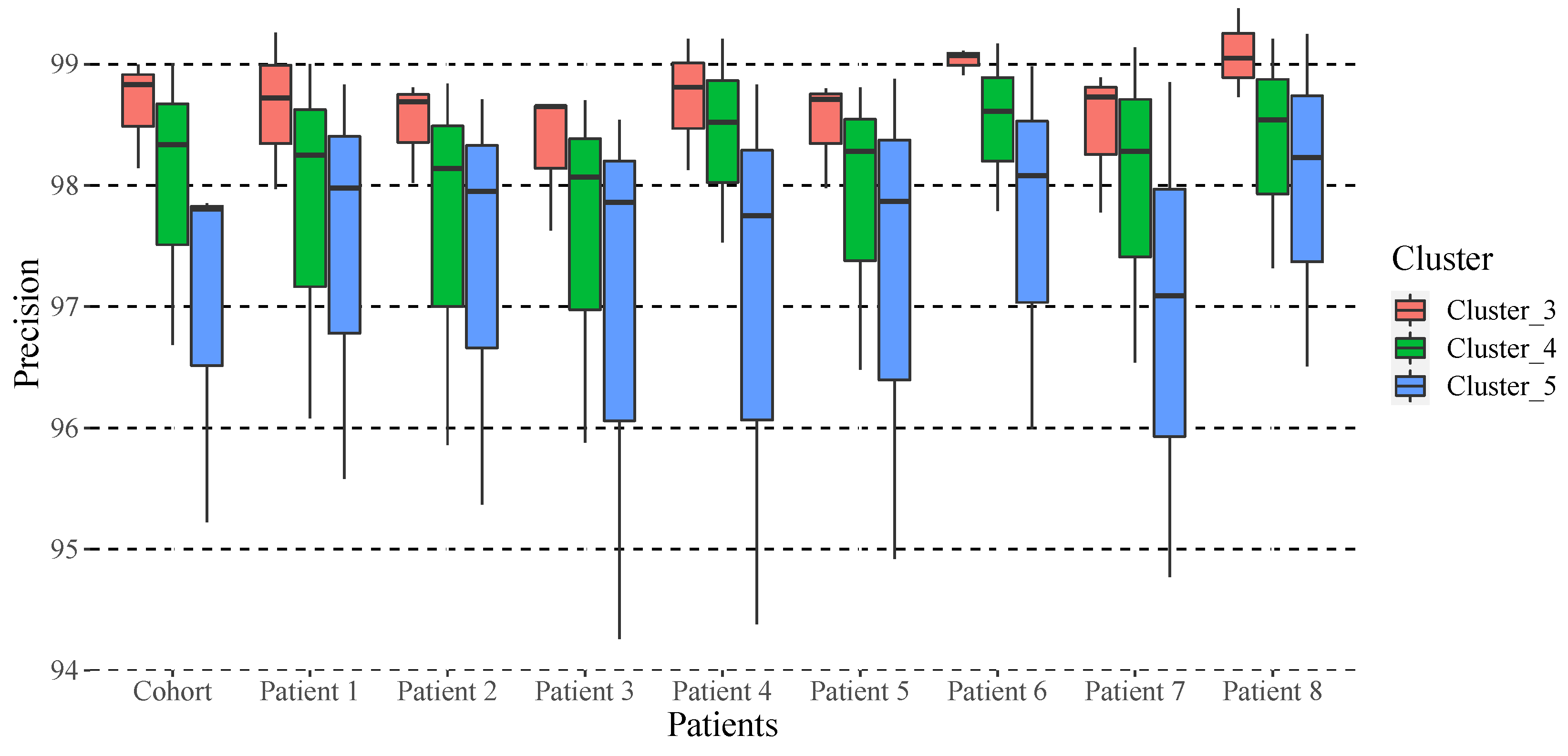
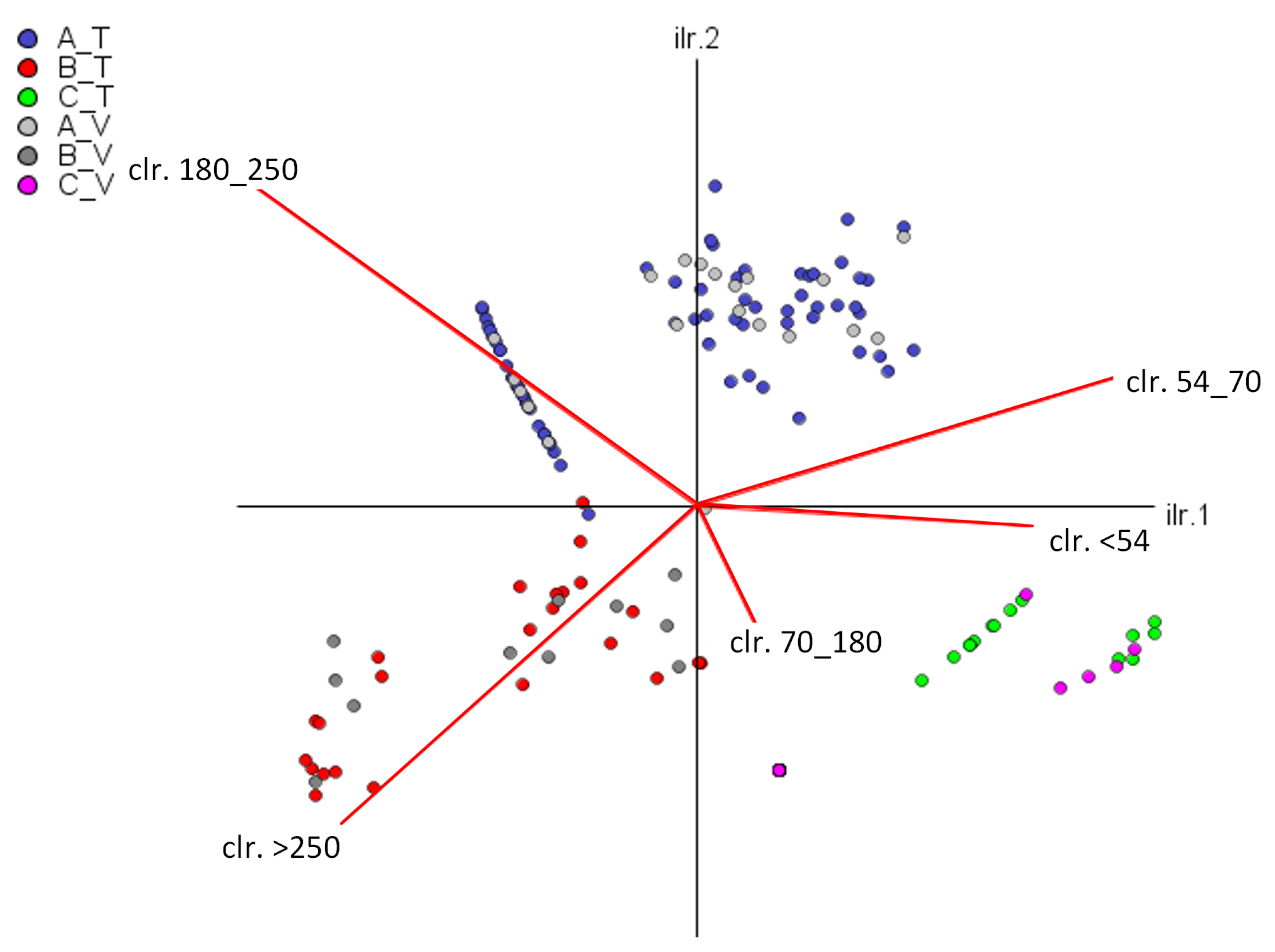
To validate this probabilistic transition model, clusters 3, 4, and 5 mentioned previously are analyzed. We consider 5-fold cross-validation, randomly selecting 75% of the data for training and the remaining 25% for validation. We employ linear discriminant analysis to assign groups to the validation data, following the methodology of Biagi et al. [
13]. Both the training and validation data of the model are CoDa vectors, whose constant sum is 100%. Therefore, a metric is needed to compare the training and validation results to obtain the accuracy of the model.
2.4. Accuracy Metric
We propose the calculation of an accuracy metric based on CoDa. The first step is to create the Training (
T) and Validation (
V) matrices (Equation (
9)), which contain the transition probabilities of the categories from one 24 h period to the next 6 h, where
D is the dimension of the vector. For this, the categories are counted, and the zero type counts are substituted.
In Martín-Fernández et al. [
27], count-type vectors are defined as categorical data in which the counts represent the number of elements located in each of several categories. This type of zeros is related to a sampling problem because the components may not be observed given the limited size of the sample. The count-zero multiplicative replacement is implemented in the R package “zCompositions” [
20], following what was established in Martín-Fernández et al. [
27], where the multiplicative replacement by rounded zero defined in Martín-Fernández and colleagues [
24] was adapted for the case of counting zeros. Although this method satisfies the condition that the imputed zero value does not depend on the
D parts of the composition, it is recommended only when the number of zeros in the data matrix is insignificant.
The accuracy is a difference measure between the training data (expected), and the validation data (observed) for each k model created. The higher the accuracy, the more similar the probability vectors between the transitions from one period to another; therefore, it would also suggest the most appropriate number of groups for each patient. From the analysis of the distances and the norms of the
T and
V vectors that are detailed below, the accuracy metric is defined as Equation (
10).
To implement this Equation (
10), mathematical operators defined for CoDa were considered. The
T or
V matrix vectors where no transitions were found from one period to another were treated as null or empty
. Then, the difference perturbation operator introduced by Martín-Fernández and their colleagues [
9] is applied as:
Applying Equation (
11) to the previously defined matrices
T and
V leads to Equation (
12). The perturbation difference operation is analogous to subtraction in Euclidean space. Therefore, the process is performed row-wise.
The difference perturbation operation also includes the closure operator
, as defined in Equation (
8). This is a technique to simplify the use of closed-form compositions, that is, positive vectors whose parts add up to a constant positive k (in our case,
, percentage type data). In this context, the triangular inequality theorem of Euclidean geometry is applied, which has been generalized to normed vector spaces, obtaining:
where the Aitchison norm
of a composition can be calculated as the Euclidean norm
of the clr-scores [
25].
Rearranging Equation (
13), we obtain:
The Aitchison distance [
28] between two compositions is known as
(Equation (
18)), which is the norm of the difference perturbation operation of these compositions; therefore, in the numerator of Equation (
17), the Aitchison distance of the composition created between the components of the training vector and those of the validation vector is calculated.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




