
MBDM: Multinational Banknote Detecting Model for Assisting Visually Impaired People

Abstract
:1. Introduction
- -
- This study is the first on smartphone-based multinational banknote detection.
- -
- A novel MBDM was developed. The MBDM consists of 69 layers and has a four-step process for feature extraction and final detection. Its feature map configuration is particularly effective at detecting small objects such as coins.
- -
- The detection performance of the MBDM was improved using mosaic data augmentation to increase training data.
- -
- The self-constructed Dongguk Multinational Banknote database version 1 (DMB v1) and the MBDM developed in this study were made publicly available on GitHub [6] for fair evaluation by other researchers.
2. Related Works
3. Materials and Methods
3.1. Overall Procedure of Proposed Method
3.2. Mosaic Data Augmentation
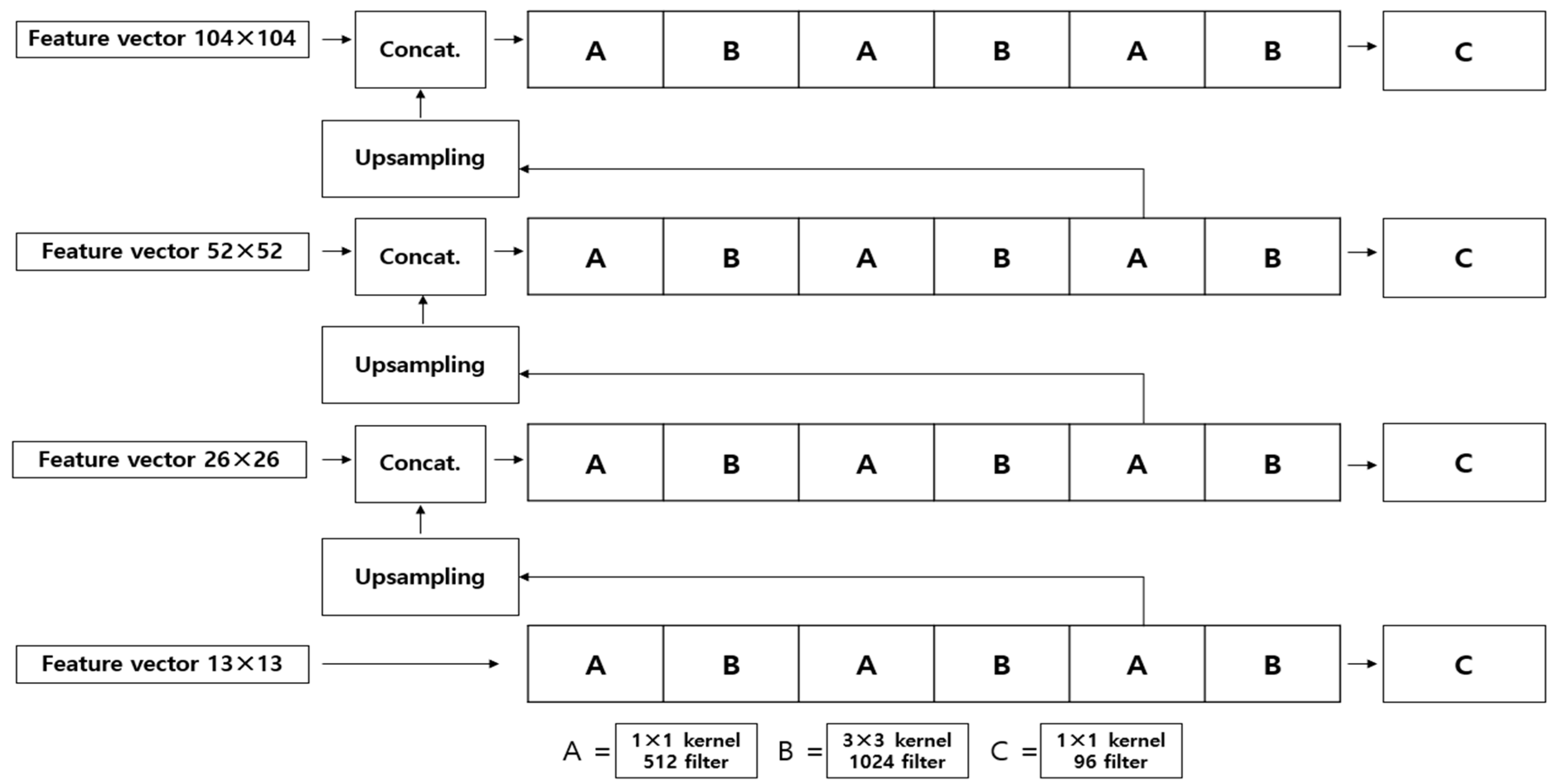
3.3. Architecture of MBDM
3.4. Mathematical Fundamentals of Bounding Box Detection by MBDM
4. Experiment Results and Analysis
4.1. Experimental Database and Setup
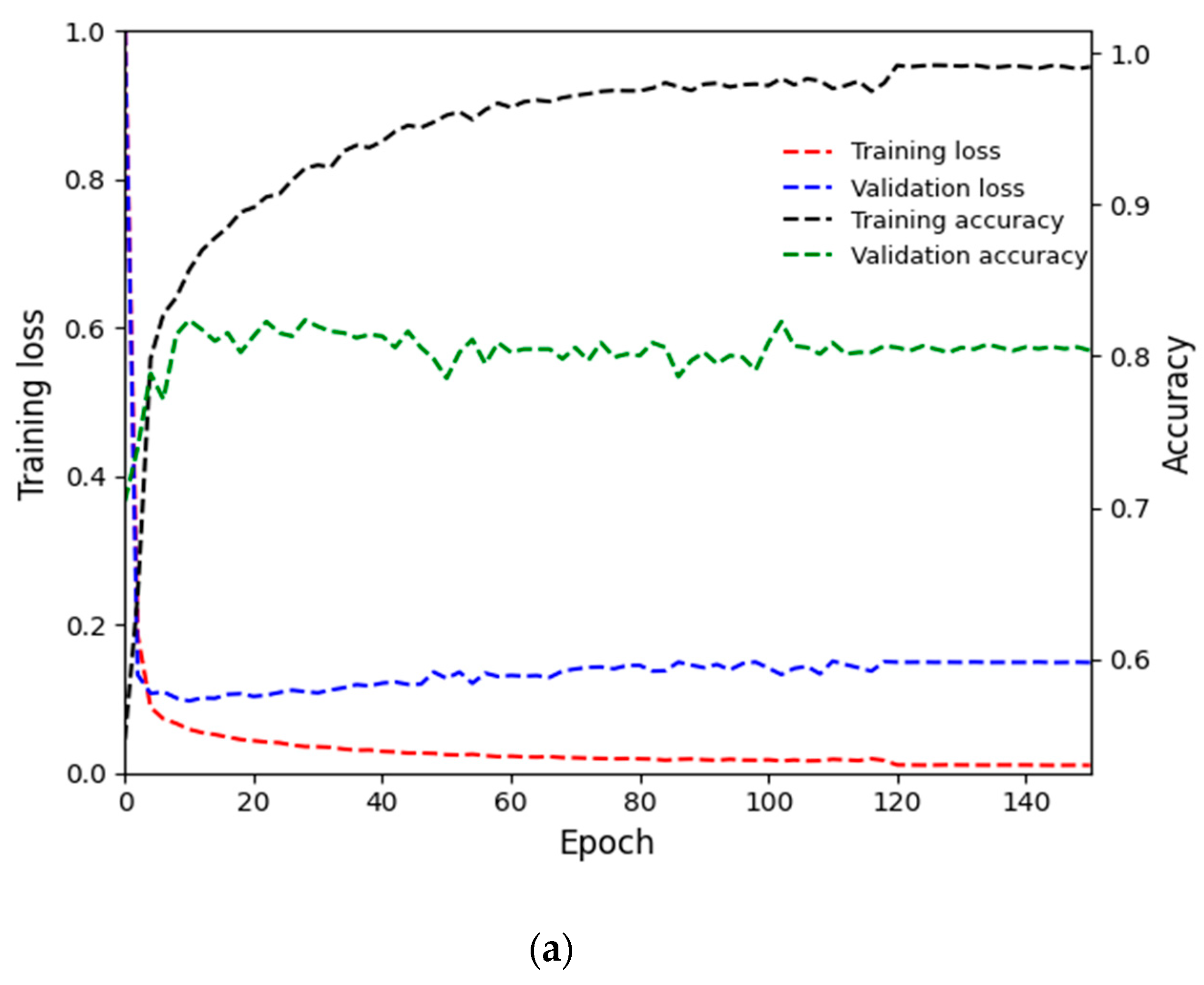
4.2. Training of Proposed Method
4.3. Testing of Proposed Method
4.3.1. Evaluation Metric
4.3.2. Ablation Studies
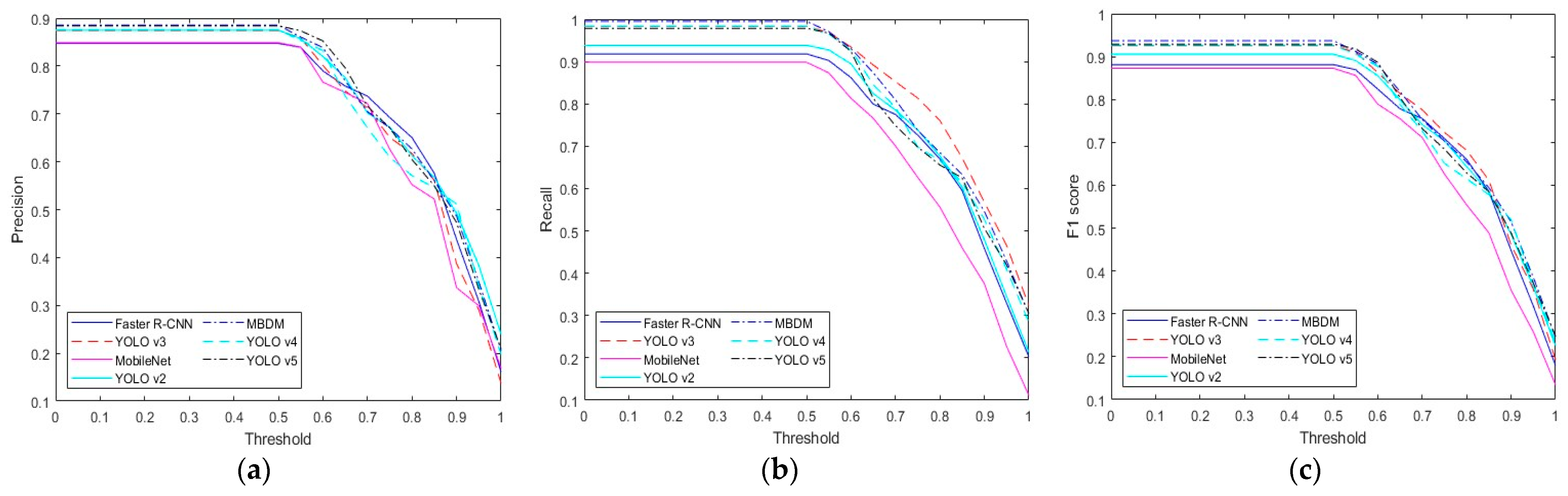
4.3.3. Comparisons with the State-of-the-Art Methods
4.3.4. Analysis
4.3.5. Comparisons of Inference Time and Model Complexity
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sanchez, G.A.R. A computer vision-based banknote recognition system for the blind with an accuracy of 98% on smartphone videos. J. Korea Soc. Comput. Inform. 2019, 24, 67–72. [Google Scholar]
- Sanchez, G.A.R.; Uh, Y.J.; Lim, K.; Byun, H. Fast banknote recognition for the blind on real-life mobile videos. In Proceedings of the Korean Society of Computer Information Conference, Jeju Island, Republic of Korea, 24–26 June 2015; pp. 835–837. [Google Scholar]
- Hasanuzzaman, F.M.; Yang, X.; Tian, Y. Robust and effective component-based banknote recognition by SURF features. In Proceedings of the 2011 20th Annual Wireless and Optical Communications Conference (WOCC), Newark, NJ, USA, 15–16 April 2011; pp. 1–6. [Google Scholar]
- Dunai, L.D.; Pérez, M.C.; Peris-Fajarnés, G.; Lengua, I.L. Euro Banknote Recognition System for Blind People. Sensors 2017, 17, 184. [Google Scholar] [CrossRef] [Green Version]
- Park, C.; Cho, S.W.; Baek, N.R.; Choi, J.; Park, K.R. Deep Feature-Based Three-Stage Detection of Banknotes and Coins for Assisting Visually Impaired People. IEEE Access 2020, 8, 184598–184613. [Google Scholar] [CrossRef]
- MBDM with Algorithms. Available online: https://github.com/channygrad/MBDM/tree/main/MBDM (accessed on 3 March 2023).
- Domínguez, A.R.; Alvarez, C.L.; Corrochano, E.B. Automated banknote identification method for the visually impaired. In Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications, Proceedings of the 19th Iberoamerican Congress, CIARP 2014, Puerto Vallarta, Mexico, 2–5 November 2014; Springer: Cham, Switzerland, 2014; pp. 572–579. [Google Scholar]
- Grijalva, F.; Rodriguez, J.C.; Larco, J.; Orozco, L. Smartphone recognition of the U.S. banknotes’ denomination, for visually impaired people. In Proceedings of the 2010 IEEE ANDESCON, Bogota, Colombia, 15–17 September 2010; pp. 1–6. [Google Scholar]
- Cunningham, P.; Delany, S.J. K-nearest neighbour classifiers. arXiv 2020, arXiv:2004.04523. [Google Scholar]
- Swain, P.H.; Hauska, H. The decision tree classifier: Design and potential. IEEE Trans. Geosci. Electron. 1977, 15, 142–147. [Google Scholar] [CrossRef] [Green Version]
- Sufri, N.A.J.; Rahmad, N.A.; As’ari, M.A.; Zakaria, N.A.; Jamaludin, M.N.; Ismail, L.H.; Mahmood, N.H. Image based ringgit banknote recognition for visually impaired. J. Telecomm. Electronic Comput. Eng. 2017, 9, 103–111. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Mittal, S.; Mittal, S. Indian banknote recognition using convolutional neural network. In Proceedings of the 2018 3rd International Conference On Internet of Things: Smart Innovation and Usages (IoT-SIU), Bhimtal, India, 23–24 February 2018. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1106–1114. [Google Scholar]
- Imad, M.; Ullah, F.; Hassan, M.A.; Naimullah, M.A. Pakistani Currency Recognition to Assist Blind Person Based on Convolutional Neural Network. J. Comput. Sci. Technol. Stud. 2020, 2, 12–19. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Joshi, R.C.; Yadav, S.; Dutta, M.K. YOLO-v3 Based Currency Detection and Recognition System for Visually Impaired Persons. In Proceedings of the 2020 International Conference on Contemporary Computing and Applications (IC3A), Lucknow, India, 5–7 February 2020; pp. 280–285. [Google Scholar]
- Mahmood, R.R.; Younus, M.D.; Khalaf, E.A. Currency Detection for Visually Impaired Iraqi Banknote as a Study Case. Turkish J. Comput. Math. Educ. 2021, 12, 2940–2948. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Pérez, D.G.; Corrochano, E.B. Recognition system for Euro and Mexican banknotes based on deep learning with real scene images. Comput. Sist. 2018, 22, 1065–1076. [Google Scholar]
- Yang, B.; Li, Y.; Zheng, W.; Yin, Z.; Liu, M.; Yin, L.; Liu, C. Motion prediction for beating heart surgery with GRU. Biomed. Signal Process. Control 2023, 83, 104641. [Google Scholar] [CrossRef]
- Lai, X.; Yang, B.; Ma, B.; Liu, M.; Yin, Z.; Yin, L.; Zheng, W. An improved stereo matching algorithm based on joint similarity measure and adaptive weights. Appl. Sci. 2022, 13, 514. [Google Scholar] [CrossRef]
- Yang, B.; Xu, S.; Chen, H.; Zheng, W.; Liu, C. Reconstruct dynamic soft-tissue with stereo endoscope based on a single-layer network. IEEE Trans. Image Process. 2022, 31, 5828–5840. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Wang, L.; Zheng, W.; Yin, L.; Hu, R.; Yang, B. Endoscope image mosaic based on pyramid ORB. Biomed. Signal Process. Control 2022, 71 Pt B, 103261. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Samsung Galaxy Note 10. Available online: https://en.wikipedia.org/wiki/Samsung_Galaxy_Note_10 (accessed on 19 December 2022).
- NVIDIA GeForce GTX 1070. Available online: https://www.nvidia.com/en-in/geforce/products/10series/geforce-gtx-1070/ (accessed on 26 March 2022).
- Pytorch. Available online: https://pytorch.org/docs/stable/index.html (accessed on 26 March 2022).
- Python. Available online: https://docs.python.org/3.7/whatsnew/changelog.html#python-3-7-0-alpha-1 (accessed on 26 March 2022).
- CUDA. Available online: https://en.wikipedia.org/wiki/CUDA (accessed on 26 March 2022).
- CUDNN. Available online: https://developer.nvidia.com/cudnn (accessed on 26 March 2022).
- Precision and Recall. Available online: https://en.wikipedia.org/wiki/Precision_and_recall (accessed on 29 January 2022).
- Parihar, A.S.; Singh, S. A study on Retinex based method for image enhancement. In Proceedings of the 2018 2nd International Conference on Inventive Systems and Control (ICISC), Coimbatore, India, 19–20 January 2018; pp. 619–624. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- YOLO v5. Available online: https://pytorch.org/hub/ultralytics_yolov5/ (accessed on 28 February 2023).
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Student’s T-Test. Available online: https://en.wikipedia.org/wiki/Student%27s_t-test (accessed on 27 December 2020).
- Cohen, J. A power primer. Psychol. Bull. 1992, 112, 155. [Google Scholar] [CrossRef]
- Jetson TX2 Module. Available online: https://developer.nvidia.com/embedded/jetson-tx2 (accessed on 22 April 2022).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Methods | Advantages | Disadvantages | |
|---|---|---|---|---|
| Single-national banknote detection | Handcrafted feature-based | SURF-based [1,2,3,4], FRS transform [7], PCA [8], KNN + DTC [11] |
| Detection performance is poor in images with complex backgrounds, and limited scale invariance performance |
| Deep feature-based | MobileNet [13], AlexNet, SVM, and HOG [15], Faster R-CNN + three step postprocessing [5], YOLO-v3 + data augmentation [19,20], Shallow CNN [22] |
| Did not perform multinational banknote detection of various nationalities | |
| Multinational banknote detection | Deep feature-based | MBDM (proposed method) | In a multinational banknote environment acquired from various conditions and backgrounds, not only bills but also small-sized coins are detected with high accuracy | Higher computational cost than MobileNet, YOLO-based methods |
| Layer Number | Number of Iterations | Layer Type | Number of Filters | Filter Size | Output |
|---|---|---|---|---|---|
| 0 | Input_layers | 0 | 0 | ||
| 1 | Conv. | 32 | 3 × 3 | 512 × 512 | |
| 2 | Conv. | 64 | 3 × 3/2 | 256 × 256 | |
| 3 | ×1 | Conv. | 32 | 1 × 1 | |
| 4 | Conv. | 64 | 3 × 3 | ||
| 5 | Residual | 256 × 256 | |||
| 6 | Conv. | 128 | 3 × 3/2 | 128 × 128 | |
| 7 | ×2 | Conv. | 64 | 1 × 1 | |
| 8 | Conv. | 128 | 3 × 3 | ||
| 9 | Residual | 128 × 128 | |||
| 10 | Conv. | 256 | 3 × 3/2 | 64 × 64 | |
| 11 | ×8 | Conv. | 128 | 1 × 1 | |
| 12 | Conv. | 256 | 3 × 3 | ||
| 13 | Residual | 64 × 64 | |||
| 14 | Conv. | 512 | 3 × 3/2 | 32×32 | |
| 15 | ×8 | Conv. | 256 | 1 × 1 | |
| 16 | Conv. | 512 | 3 × 3 | ||
| 17 | Residual | 32 × 32 | |||
| 18 | Conv. | 1024 | 3 × 3/2 | 16 × 16 | |
| 19 | ×8 | Conv. | 512 | 1 × 1 | |
| 20 | Conv. | 1024 | 3 × 3 | ||
| 21 | Residual | 16 × 16 | |||
| 22 | Conv. | 2048 | 3 × 3/2 | 8 × 8 | |
| 23 | ×4 | Conv. | 1024 | 1 × 1 | |
| 24 | Conv. | 2048 | 3 × 3 | ||
| 25 | Residual | 8 × 8 | |||
| 26 | Average pooling | Global | |||
| 27 | Connected | 1000 | |||
| 28 | Independent logistic classifier | ||||
| Type of Banknote | Denomination | Number of Images | Training | Testing |
|---|---|---|---|---|
| USD | 1 Dollar | 660 | 330 | 330 |
| 5 Dollar | 670 | 335 | 335 | |
| 10 Dollar | 660 | 330 | 330 | |
| 20 Dollar | 670 | 335 | 335 | |
| 50 Dollar | 660 | 330 | 330 | |
| 100 Dollar | 680 | 340 | 340 | |
| EUR | 5 Euro | 800 | 400 | 400 |
| 10 Euro | 800 | 400 | 400 | |
| 20 Euro | 800 | 400 | 400 | |
| 50 Euro | 800 | 400 | 400 | |
| 100 Euro | 800 | 400 | 400 | |
| KRW | 10 Won | 800 | 400 | 400 |
| 50 Won | 800 | 400 | 400 | |
| 100 Won | 800 | 400 | 400 | |
| 500 Won | 800 | 400 | 400 | |
| 1000 Won | 820 | 410 | 410 | |
| 5000 Won | 820 | 410 | 410 | |
| 10,000 Won | 820 | 410 | 410 | |
| 50,000 Won | 820 | 410 | 410 | |
| JOD | 1 piastres | 700 | 350 | 350 |
| 5 piastres | 900 | 450 | 450 | |
| 10 piastres | 240 | 120 | 120 | |
| 0.25 dinar | 580 | 290 | 290 | |
| 0.5 dinar | 480 | 240 | 240 | |
| 1 dinar | 1460 | 730 | 730 | |
| 5 dinar | 580 | 290 | 290 | |
| 10 dinar | 700 | 350 | 350 | |
| 20 dinar | 900 | 450 | 450 | |
| Total | 21,020 | 10,510 | 10,510 | |
| Method | Precision | Recall | F1 Score |
|---|---|---|---|
| With Retinex | 0.8053 | 0.8737 | 0.8381 |
| Without Retinex (proposed method) | 0.8396 | 0.9334 | 0.8840 |
| Method | Precision | Recall | F1 Score |
|---|---|---|---|
| With grouped convolution | 0.8294 | 0.9255 | 0.8748 |
| Without grouped convolution (proposed method) | 0.8396 | 0.9334 | 0.8840 |
| Method | Precision | Recall | F1 Score | |
|---|---|---|---|---|
| Without mosaic augmentation | 0.8242 | 0.9263 | 0.8723 | |
| With mosaic augmentation using | two images | 0.8173 | 0.9097 | 0.8610 |
| four images | 0.8396 | 0.9334 | 0.8840 | |
| six images | 0.8166 | 0.8885 | 0.8510 | |
| Method | Precision | Recall | F1 Score | |
|---|---|---|---|---|
| Without mosaic augmentation | MBDM (deeper layers) | 0.8150 | 0.9424 | 0.8741 |
| MBDM (normal layers) | 0.8242 | 0.9263 | 0.8723 | |
| With mosaic augmentation (four images) | MBDM (deeper layers) | 0.8359 | 0.9255 | 0.8784 |
| MBDM (normal layers) | 0.8396 | 0.9334 | 0.8840 | |
| Methods | Precision | Recall | F1 Score | |
|---|---|---|---|---|
| Faster R-CNN [5] | Coin | 0.7576 | 0.8210 | 0.7880 |
| Bill | 0.8410 | 0.9114 | 0.8748 | |
| Coin and bill | 0.7993 | 0.8662 | 0.8314 | |
| YOLO v3 [19,20] | Coin | 0.7351 | 0.8272 | 0.7783 |
| Bill | 0.8629 | 0.9710 | 0.9137 | |
| Coin and bill | 0.7990 | 0.8991 | 0.8460 | |
| MobileNet [13] | Coin | 0.7472 | 0.7911 | 0.7685 |
| Bill | 0.8376 | 0.8867 | 0.8614 | |
| Coin and bill | 0.7924 | 0.8389 | 0.8150 | |
| YOLO v2 [21] | Coin | 0.7371 | 0.7906 | 0.7630 |
| Bill | 0.8653 | 0.9282 | 0.8956 | |
| Coin and bill | 0.8012 | 0.8594 | 0.8293 | |
| YOLO v4 [27] | Coin | 0.7763 | 0.8657 | 0.8186 |
| Bill | 0.8713 | 0.9715 | 0.9187 | |
| Coin and bill | 0.8238 | 0.9186 | 0.8686 | |
| YOLO v5 [37] | Coin | 0.7771 | 0.8608 | 0.8168 |
| Bill | 0.8731 | 0.9672 | 0.9178 | |
| Coin and bill | 0.8251 | 0.914 | 0.8673 | |
| MBDM (proposed method) | Coin | 0.7747 | 0.8707 | 0.8200 |
| Bill | 0.8737 | 0.9819 | 0.9246 | |
| Coin and bill | 0.8396 | 0.9334 | 0.8840 | |
| Methods | Precision | Recall | F1 Score |
|---|---|---|---|
| Faster R-CNN [5] | 0.8465 | 0.9173 | 0.8805 |
| YOLO v3 [19,20] | 0.8752 | 0.9848 | 0.9268 |
| MobileNet [13] | 0.8196 | 0.8676 | 0.8429 |
| YOLO v2 [21] | 0.8752 | 0.9388 | 0.9059 |
| YOLO v4 [27] | 0.8804 | 0.9745 | 0.9251 |
| YOLO v5 [37] | 0.8795 | 0.9815 | 0.9277 |
| MBDM (proposed method) | 0.8861 | 0.9957 | 0.9377 |
| Methods | Precision | Recall | F1 Score |
|---|---|---|---|
| Faster R-CNN [5] | 0.8472 | 0.9181 | 0.8812 |
| YOLO v3 [19,20] | 0.8739 | 0.9834 | 0.9254 |
| MobileNet [13] | 0.8486 | 0.8983 | 0.8727 |
| YOLO v2 [21] | 0.8747 | 0.9383 | 0.9054 |
| YOLO v4 [27] | 0.8756 | 0.9839 | 0.9266 |
| YOLO v5 [37] | 0.8841 | 0.9785 | 0.9289 |
| MBDM (proposed method) | 0.8855 | 0.9952 | 0.9372 |
| Methods | Precision | Recall | F1 Score | |
|---|---|---|---|---|
| Faster R-CNN [5] | Coin | 0.7600 | 0.8236 | 0.7905 |
| Bill | 0.8356 | 0.9055 | 0.8691 | |
| Coin and bill | 0.7978 | 0.8646 | 0.8298 | |
| YOLO v3 [19,20] | Coin | 0.7258 | 0.8167 | 0.7686 |
| Bill | 0.8520 | 0.9587 | 0.9022 | |
| Coin and bill | 0.7889 | 0.8877 | 0.8354 | |
| MobileNet [13] | Coin | 0.7392 | 0.7826 | 0.7603 |
| Bill | 0.8286 | 0.8772 | 0.8522 | |
| Coin and bill | 0.7839 | 0.8299 | 0.8062 | |
| YOLO v2 [21] | Coin | 0.7262 | 0.7789 | 0.7516 |
| Bill | 0.8524 | 0.9143 | 0.8823 | |
| Coin and bill | 0.7893 | 0.8466 | 0.8169 | |
| YOLO v4 [27] | Coin | 0.7573 | 0.8632 | 0.8068 |
| Bill | 0.8489 | 0.9676 | 0.9043 | |
| Coin and bill | 0.8031 | 0.9154 | 0.8556 | |
| YOLO v5 [37] | Coin | 0.7625 | 0.8496 | 0.8037 |
| Bill | 0.8563 | 0.9542 | 0.9026 | |
| Coin and bill | 0.8094 | 0.9019 | 0.8532 | |
| MBDM (proposed method) | Coin | 0.7681 | 0.8632 | 0.8129 |
| Bill | 0.8661 | 0.9734 | 0.9166 | |
| Coin and bill | 0.8171 | 0.9183 | 0.8647 | |
| Methods | Precision | Recall | F1 Score | |
|---|---|---|---|---|
| Faster R-CNN [5] | Coin | 0.7552 | 0.8184 | 0.7855 |
| Bill | 0.8349 | 0.9048 | 0.8684 | |
| Coin and bill | 0.7951 | 0.8616 | 0.8270 | |
| YOLO v3 [19,20] | Coin | 0.7228 | 0.8134 | 0.7654 |
| Bill | 0.8485 | 0.9548 | 0.8985 | |
| Coin and bill | 0.7857 | 0.8841 | 0.8320 | |
| MobileNet [13] | Coin | 0.7334 | 0.7765 | 0.7543 |
| Bill | 0.8221 | 0.8703 | 0.8455 | |
| Coin and bill | 0.7777 | 0.8234 | 0.7999 | |
| YOLO v2 [21] | Coin | 0.7334 | 0.7765 | 0.7543 |
| Bill | 0.8491 | 0.9108 | 0.8789 | |
| Coin and bill | 0.7862 | 0.8433 | 0.8138 | |
| YOLO v4 [27] | Coin | 0.7496 | 0.8405 | 0.7925 |
| Bill | 0.8410 | 0.9429 | 0.8890 | |
| Coin and bill | 0.7953 | 0.8917 | 0.8407 | |
| YOLO v5 [37] | Coin | 0.7274 | 0.8425 | 0.7807 |
| Bill | 0.8150 | 0.9439 | 0.8747 | |
| Coin and bill | 0.7712 | 0.8932 | 0.8277 | |
| MBDM (proposed method) | Coin | 0.7651 | 0.8598 | 0.8097 |
| Bill | 0.8627 | 0.9696 | 0.9131 | |
| Coin and bill | 0.8139 | 0.9147 | 0.8614 | |
| Environment | Inference Time per One Image (Unit: ms) | Processing Speed (Unit: frames/s) | |
|---|---|---|---|
| Desktop | Faster R-CNN [5] | 12.52 | 79.87 |
| YOLO v3 [19,20] | 9.81 | 101.94 | |
| MobileNet [13] | 7.59 | 131.75 | |
| YOLO v2 [21] | 10.38 | 96.34 | |
| YOLO v4 [27] | 10.11 | 98.91 | |
| YOLO v5 [37] | 9.96 | 100.4 | |
| MBDM (proposed method) | 11.32 | 88.34 | |
| Jetson embedded system | Faster R-CNN [5] | 63.25 | 15.81 |
| YOLO v3 [19,20] | 48.79 | 20.50 | |
| MobileNet [13] | 31.62 | 31.63 | |
| YOLO v2 [21] | 51.45 | 19.44 | |
| YOLO v4 [27] | 49.82 | 20.07 | |
| YOLO v5 [37] | 48.88 | 20.46 | |
| MBDM (proposed method) | 57.32 | 17.45 | |
| Method | # Parameters | GPU Memory Requirement (Unit: Gbyte) | #FLOPs |
|---|---|---|---|
| Faster R-CNN [5] | 65.2563 | 4.138 | 2.1592 |
| YOLO v3 [19,20] | 63.3524 | 2.285 | 1.7420 |
| MobileNet [13] | 13.1526 | 1.159 | 0.7492 |
| YOLO v2 [21] | 53.0006 | 2.293 | 1.6549 |
| YOLO v4 [27] | 64.1748 | 2.315 | 1.7951 |
| YOLO v5 [37] | 56.1049 | 1.951 | 1.5832 |
| MBDM (proposed method) | 68.2594 | 2.312 | 1.8472 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, C.; Park, K.R. MBDM: Multinational Banknote Detecting Model for Assisting Visually Impaired People. Mathematics 2023, 11, 1392. https://doi.org/10.3390/math11061392
Park C, Park KR. MBDM: Multinational Banknote Detecting Model for Assisting Visually Impaired People. Mathematics. 2023; 11(6):1392. https://doi.org/10.3390/math11061392
Chicago/Turabian StylePark, Chanhum, and Kang Ryoung Park. 2023. "MBDM: Multinational Banknote Detecting Model for Assisting Visually Impaired People" Mathematics 11, no. 6: 1392. https://doi.org/10.3390/math11061392
APA StylePark, C., & Park, K. R. (2023). MBDM: Multinational Banknote Detecting Model for Assisting Visually Impaired People. Mathematics, 11(6), 1392. https://doi.org/10.3390/math11061392