1. Introduction
In randomized clinical trials, often multiple outcome measures are selected to assess the effect of a treatment on two groups of subjects. In clinical areas, such as cardiology, oncology, psychology, and infectious disease, the combination of several clinical meaningful outcome measures is very common [
1,
2,
3,
4]. The standard method of analysis for multivariate survival outcomes is a time-to-first event analysis, which uses only the first event per subject [
5]. However, this approach has been criticized, since it ignores subsequent events and the clinical relevance of the events. To remediate the shortcomings of the time-to-first event analysis, a new class of non-parametric methods has been proposed that allows for the analysis of multiple events per subject and allows for prioritizing the events by clinical relevance [
6,
7,
8]. These methods are a generalization to multivariate prioritized outcomes of the classical univariate Mann–Whitney [
9] and Gehan–Wilcoxon test [
10,
11]. Similar to the univariate outcome statistic, the generalized statistics compare the outcome per pair of subjects and hence are named generalized pairwise comparisons (GPC) statistics [
7], while others use the term win statistics [
12].
GPC is based on a prioritization of a number of
k outcome measures, usually according to a decreasing level of clinical relevance. For each outcome measure, every subject is compared to every other subject in a pairwise manner. Per pair and per outcome, a score,
, is assigned, which is chosen to reflect whether subject
i or subject
j has the more favorable outcome
k. The concept of more favorable can involve censoring, missing data, and can include a threshold of clinical relevance [
7,
13]. The score
that is most often used is the score proposed by Gehan [
10] for censored observations:
The scores can be computed separately for each outcome measure
k, and the score
for a pair in the prioritized GPC is the first non-zero score
, where the first is defined by the prespecified priority list of outcomes. It is quite possible that for many pairs of subjects, the overall comparison will remain 0. It is also possible to have non-transitive comparisons, such as three patients where
,
, and
[
13]. Alternatively, if prioritization of the outcome measures is not feasible or appropriate, a non-prioritized GPC sums the scores
over all outcome measures [
13,
14]. Additionally, the scores of the pairs that are uninformative due to censored observations, and thus cannot be compared, can be corrected by estimating the chance of a favorable outcome using Kaplan–Meier estimates [
15,
16,
17,
18]. The Kaplan–Meier corrected score matrix will consist of scores
. The score matrix resulting from the pairwise comparisons is a skew-symmetric
matrix, with entries in the set
for the prioritized GPC without the censoring corrections and entries in
otherwise. Although scores in a non-prioritized GPC can be
per pair, most GPC statistics will adjust the scoring by dividing by
k outcomes. Because of the summing, this adjustment can be performed at the level of the scores or after summing all scores. In the former, scores will be
, while in the latter, scores will be
.
Inferential tests and confidence intervals for GPC are then constructed from the scoring matrix, utilizing statistics such as the Finkelstein–Schoenfeld statistic [
6], the net treatment benefit [
7], the win ratio [
8] and win odds [
19]. Suppose there are
N subjects in a two-arm trial, with
m subjects in the experimental group from a distribution
and
n subjects in the control group from a distribution
. Moreover, let the indicator
for subjects in the experimental group, and
for patients in the control group. The Finkelstein–Schoenfeld statistic [
6] is then the sum of the scores for the experimental group. If
, the Finkelstein–Schoenfeld statistic is:
which can be interpreted as the difference between the favorable outcomes in the experimental arm,
with
, and the favorable outcomes in the control arm,
with
. If the score entries are restricted to
,
and
merely count the number of wins per treatment arm, and
.
It is easy to show (
Appendix A) that
. The variance suggested by Finkelstein and Schoenfeld [
6] is based on a permutation test
following [
10,
11,
20]. Although Finkelstein and Schoenfeld presented the formula for
, they did not give expectations and variances for
and
separately. For many of the GPC models considered below, those separate variances are needed.
The permutation test assumes exchangeability between observations and tests the null hypothesis:
. Gehan [
10], Gilbert [
11] and Mantel [
20] derived a closed-form expression of the mean and variance of the exact null distribution, which means that no re-sampling permutation is actually required. Consequently, the asymptotic null distribution of the test statistic
is shown to be standard normal [
10,
11], and the
p-values computed from this null distribution are valid, even for very small sample sizes of only 10 observations [
10]. Alternatively, inference can be based on the proportion of re-sampling permutation samples with a test statistic greater than or equal to the observed statistic. Even though the permutation test is formulated under the
null hypothesis, the test statistic is only consistent under alternatives of the form
[
10,
11]. The permutation test is thus not consistent against all alternatives of the form
[
21,
22].
Other GPC statistics include the net treatment benefit (NTB) [
7], which is a U-statistic [
23] transformation of the Finkelstein–Schoenfeld statistic, by dividing it by the total number of pairs possible between the two treatment arms,
. It has been shown that the NTB and its transformations are unbiased and efficient estimators for univariate and uncensored observations [
24]. The win ratio (WR) is defined as the ratio of the number of times a subject has a favorable outcome in the treatment arm and in the control arm,
[
8]. Finally, the win odds adds half of the number of tied outcomes (
) to both the numerator and denominator,
[
25]. Since the win odds (
) is a transformation of the net treatment benefit,
, any test proposed for the net treatment benefit or Finkelstein–Schoenfeld statistic can also be applied to the win odds, and we will not focus further on the win odds.
For the inference of the GPC statistics, also re-sampling bootstrap [
8], re-sampling re-randomization [
7] or U-statistic asymptotic methods have been proposed [
14,
26,
27]. The asymptotic properties are used in two different ways:
For larger trials, the asymptotic formulas may be satisfactory, but the re-sampling methods require a large number of replications to be accurate. In contrast, the permutation test (
2) presented by Finkelstein and Schoenfeld [
6] avoids the first step in the use of asymptotic properties and the associated error. This would be important in smaller clinical trials, such as in rare disease trials. Moreover, as the permutation test is an exact test in finite sampling, it is more accurate than the re-sampling methods and less time-consuming.
While the permutation test, as derived by Gehan [
10], can be easily extended to the net treatment benefit and the win odds through their transformations, it is not obvious to extend it to the win ratio. Moreover, the permutation test determines the variability under the null hypotheses, making it unsuited for the determination of a confidence interval of the GPC statistics. Therefore, we re-derive the closed-form expression of the expectation and the variance of the permutation distribution using graph theory notation on the skew-symmetric score matrix, which allows extension of these results to a two-sample bootstrap distribution and to the win ratio. Additionally, we generalize the expression to allow scores in the
field, generalizing the application to non-prioritized GPC algorithms and censoring correcting scores. It will be shown that the algorithm complexity of our expressions is
in both time and space, and thus, the exact permutation and bootstrap method will be both faster and more accurate than re-sampling permutation and bootstrap tests.
This paper is organized as follows. In
Section 2, the graphical model is presented that will be used the derive the expected values and variances of the GPC statistic under the permutation and bootstrap distribution. The exact permutation formulas for the mean and variance are derived in
Section 3, while the exact bootstrap formulas follow in
Section 4. The time complexity of the exact methods is evaluated in
Section 5. Throughout the development of the theory, a small example is used to demonstrate the new methodologies. Additionally, a simulation shows the type I error and the 95% confidence interval coverage in
Section 6, and the methodology is demonstrated in an example in
Section 7. Both R® and SAS code for the exact permutation, and bootstrap tests are presented in the
Supplementary Material as well as full detailed derivations and an extensive test of the algorithm.
2. Graphical Model
Any pairwise comparison analysis of an outcome measure in
subjects, that allows for non-prioritized analyses and censoring corrected scores to denote the more favorable outcome, will result in a skew-symmetry
score matrix
U with entries in the
field. This will be the case when evaluating both a single outcome measure, by use of the Mann–Whitney test, or the Gehan–Wilcoxon test, and when evaluating multiple outcomes, by a GPC analysis. In the remainder of this manuscript, we consider that the score matrix
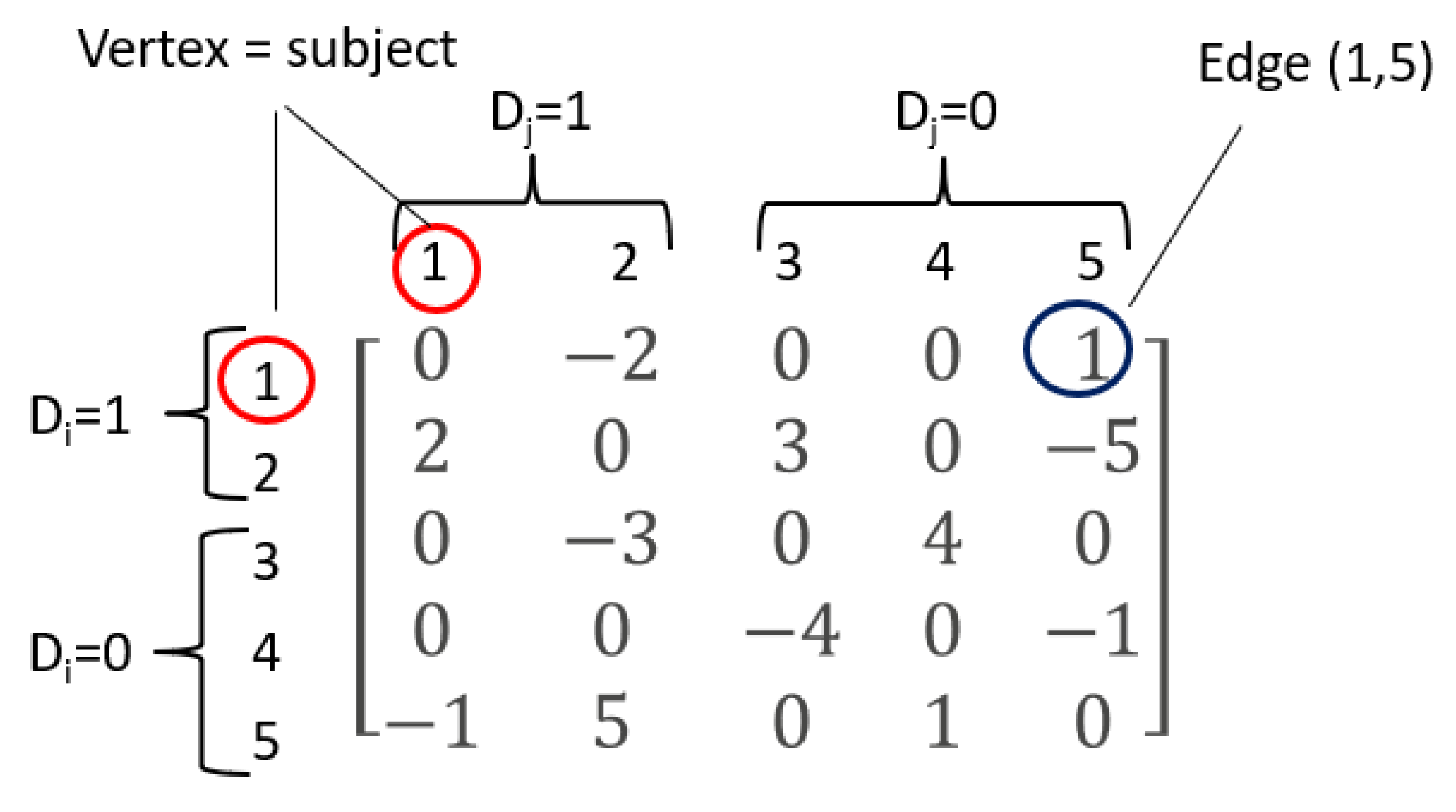
U has been produced by some further unspecified mechanism; the only restriction is the skewness and symmetry. A small example (
Figure 1) illustrates such a
U matrix.
Since all GPC statistics can be constructed from
and
, it is our aim to compute the expectations and the variances of
and
as well as their covariance for both the permutation as the bootstrap distribution. These mean and (co)variances are computed over all possible permutations of the treatment arms or all possible bootstrap samples. For the net treatment benefit (
),
For the win ratio
, it is known that the logarithm of the win ratio is approximately normal distributed [
24,
26]. Its variance can then be approximated using the delta method:
In order to derive the expectations, variances, and covariance for the
and
, it will be convenient to think of the score matrix
U as the adjacency matrix of a directed graph
[
28] with
N vertices, where a vertex represents a subject. A pair of subjects or vertices can be joined by an edge
. Since we are interested in the favorable outcomes, an edge
is defined when
. When
and
, such an edge is called a treatment edge and when
and
, it is called a control edge. The value
is called the weight of the edge, and it is denoted by
. Note that the score of the comparison of subject
i with subject
j is exactly the opposite of the score of the comparison of subject
j with subject
i. Hence, the edge
is an ordered pair of distinct vertices, where the head of
e is vertex
j and the tail is vertex
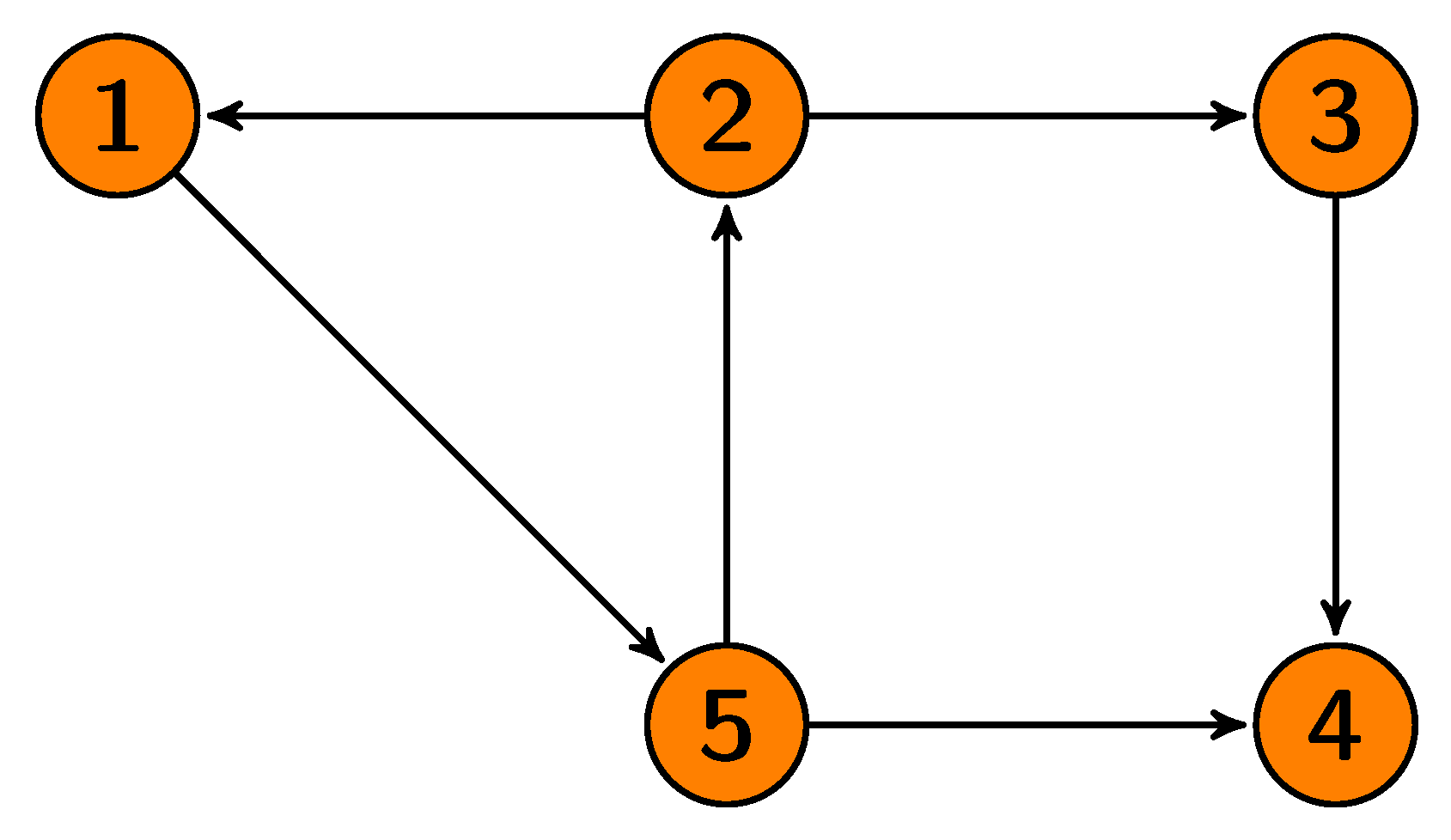
i. In a pictorial representation, the edge
is represented by an arrow going from vertex
i to vertex
j (
Figure 2). Let then
E denote the total number of edges of
. In our small example (
Figure 1 and
Figure 2),
.
Using the graph theory notation, the number of wins for the treatment,
, and control arm,
, can be redefined as follows. For a subject or vertex
v, let
denote the number of times that the vertex
v appears in the sample. In a permutation sample, each subject can only appear once and
for all samples. In a bootstrap sample, subjects can appear more than once and
can be zero or higher. To count the number of wins for the treatment arm, the value
is defined as the number of times that edge
e is a treatment edge in the sample, and similarly, the value
is the number of times that edge
e is a control edge. If the treatment edge
e has subjects
, the number of times this edge appears in the sample is then
. For example, suppose that in a bootstrap sample of the five subjects in our small example (
Figure 1), subjects 1 and 2 appear twice, subject 3 appears once, and subjects 4 and 5 do not appear at all; then,
,
, and
. Furthermore, the pair or treatment edge (2,1) will appear
times, the treatment edge
times and all other treatments edges
times. The vectors
T and
C are the
column vectors composed of the various
and
and the vector
W is the column vector of the weights
.
and
are then redefined as:
Vector of edges = {(1,5),(2,1),(2,3),(3,4),(5,2),(5,4)};
Vector = {1,2,3,4,5,1};
Vector = {1,0,1,0,0,0} and ;
Vector = {0,0,0,0,1,0} and .
The development of the expectations and variances of and , and their covariance for the permutation and the bootstrap distribution, then follow the same general pattern.
The expectation of
is derived by:
and similarly,
.
The variance is derived by
The variance of the GPC statistics thus requires two counting steps. In the first step, the expected values , and the expected value of an ordered pair of edges , not necessarily distinct, , , , and are computed using elementary calculations involving binomial coefficients. These calculations differ between edge pairs, depending on the trial arm assignments and the geometric relationship of the edges. Note that because the variance matrix is symmetric, we do not explicitly need the individual terms . In the second step, the number of times that each of these geometric configurations of edges is present in the data set is counted.
3. The Permutation Distribution
In this section, it is shown that our derivation of the graph theory concepts lead to the exact same permutation test as proposed by Gehan [
10], Gilbert [
11], Mantel [
20] and Finkelstein and Schoenfeld [
6]. It allows, however, to develop a permutation test for the win ratio, and it can be extended to a bootstrap test.
In a permutation test, subjects are randomly re-sampled to the treatment groups without replacement. If all possible permutations of m treatment assignments and n control assignments are considered, the and in each of these permutation samples will lead to their permutation distribution. The expectations, variances, and covariance of this permutation distribution of and can be calculated explicitly. An edge will thus always join the same subjects, but whether or not this edge contributes to the treatment wins or control wins depends on the treatment assignment in the permutation sample.
These provide the second half of the Equation (
7). For our small example (
Figure 1), the expectations of
and
equal
.
Note that and that, due to the symmetry of the U-matrix, the column sums of (or entries with are equal to the row sums of .
Finally, the variance of the Finkelstein–Schoenfeld statistic, the net treatment benefit and win ratio statistic can be calculated from (
3)–(
6). For the Finkelstein–Schoenfeld statistic (and the net treatment benefit), the exact permutation variance simplifies to simple row sums of
(
Figure 3):
It is easy to see that this is equal to (
2), as proposed by Gehan [
10], Gilbert [
11], Mantel [
20] and Finkelstein and Schoenfeld [
6].
For our small example (
Figure 1), it is possible to take every permutation sample, calculate the win difference for each sample and determine the variance of the win differences. If we do this, the variance coincides with what is calculated using the exact permutation formulas (see
Supplementary Material S2, Section S1.1):
4. The Bootstrap Distribution
Using a similar approach, we can now also develop a closed-form formula for the bootstrap distribution for both the net treatment benefit and the win ratio rather than the originally proposed re-sampling bootstrap test [
8] for testing the hypothesis
or
or for the confidence interval construction.
In a bootstrap, subjects are randomly re-sampled with replacement within their treatment group. If all possible bootstrap samples, in total, are considered, the number of treatment wins, and control wins, , in each of these samples will lead to their bootstrap distribution. The expectations, variances, and covariance of this bootstrap distribution of and can also be calculated explicitly, following a similar reasoning as in the permutation. This method will be more accurate than actually re-sampling via bootstrap, since the randomization error is eliminated.
Since the bootstrap uses the same observed information as the permutation, the graph
described in
Section 2 remains useful. The edges and vertices remain the same as previously. However, since an edge
e can now be repeated in a sample, be present once, or not be present at all, the number of times an edge contributes to a win in
T or
C can now be between 0 and
n, respectively,
m. Additionally, since subjects or vertices remain in their treatment arm over the bootstrap samples, edges joining vertices within the same treatment arm (
) will never be a win in any bootstrap sample, and they will also not contribute to the variance. In other words, the variance of wins in a bootstrap sample does not depend on the within-arm comparisons. This is in contrast to the permutation variance, where within-arm comparisons contribute to the final variance.
There are thus ordered pairs of edges corresponding to wins and contributing to the variance. Let the indicator when and , and when and . An edge corresponding to a treatment win ( for and for ) or a control win ( for and for ) in the observed data will be called a treatment edge or a control edge.
One could also consider bootstrap sampling from the entire population to test the same null hypothesis of the permutation test,
. The formulas of the one-sample bootstrap are similar in spirit to those given here, and they are detailed in the
Supplementary Material S1, Section S6.
Using elementary sums of multinomial coefficients, the expectations of
and
are shown to be
and similarly,
(
Supplementary Material S1, Section S5.1). Consequently, the expectation of the win difference
and the approximation of the expectation for the win ratio
.
The variance of
is obtained similarly by replacing all treatment with control parameters and defining
as the row (
) and column (
) sums of
for vertex
v and
as the row (
) and column (
) sums of
for
vertex
v. The covariance equals (
Supplementary Material S1 Section S5.3):
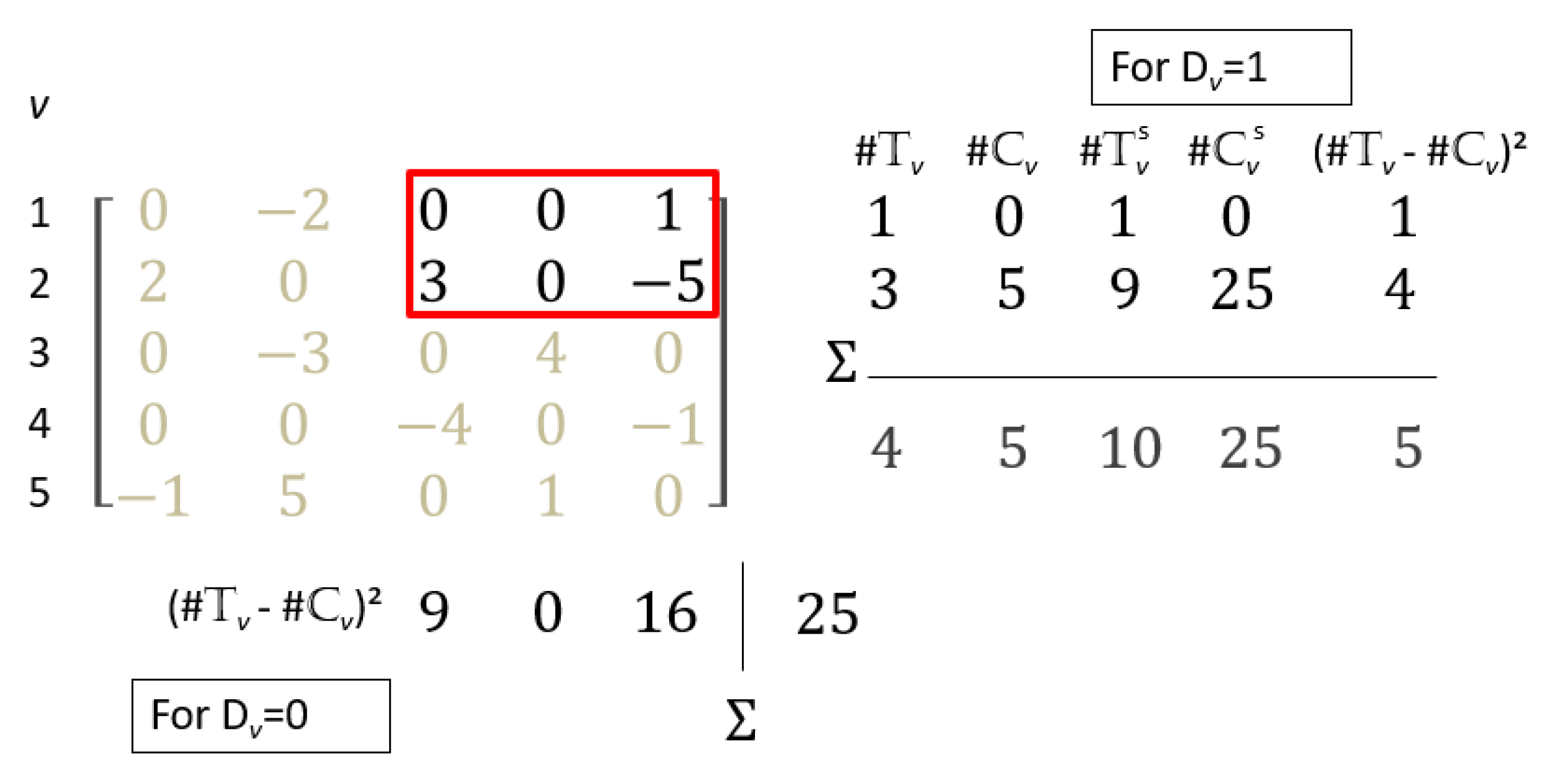
Finally, the variance of the Finkelstein–Schoenfeld statistic, the net treatment benefit and win ratio statistic can be calculated from (
3)–(
6). For the Finkelstein–Schoenfeld statistic and the net treatment benefit, the exact bootstrap variance simplifies to row and column sums of
and
counts (
Figure 4).
For our small example (
Figure 1), it is possible to take every bootstrap sample, calculate the win difference for each sample and determine the variance of the win differences. If we do this, the variance coincides with what is calculated using the exact bootstrap formulas (see
Supplementary Material S2, Section S2.1):
5. Complexity
In any GPC analysis, a bounded number of computations for each pair of patients is performed to obtain the score matrix U, and the number of pairs is . The complexity of computing U is therefore . It is conceivable that one could reduce the complexity for special cases of GPC, however, our analysis works for arbitrary skew matrices, and in such cases, every pair of patients must be examined at least once.
For the variance of a GPC statistic, one could in principle consider all possible permutations or bootstrap samples, compute the numbers of treatment and control wins for each sample, and then compute the mean and variances. Such a computation would be exponential in
N and hence completely unsatisfactory for a real example. We have performed such computations in some very small examples as a test of our algorithm (
Supplementary Material S2).
For a specific vertex v, in order to compute the various vertex-dependent terms in the variance formulas, (, , , , , , , and ), each other vertex must be examined once. Thus, the complexity of the computation at each vertex is , and computing at all vertices is thus . The total number of edges and the wins and are computed from these numbers in an additional steps, and the final computations are . Accordingly, the time complexity of both the permutation and bootstrap algorithms is .
The exact computations will be faster than evaluating a large number of any permutation or bootstrap re-sampling, because evaluating only one sample is already .
6. Simulations
Similarly as for the Finkelstein-Schoenfeld test, inference for the permutation and bootstrap test is based on the standard normal assumption for the net treatment benefit and lognormal assumption for the win ratio of the asymptotic distribution of the permutation and bootstrap test statistic. While both the permutation and the bootstrap serve for hypothesis testing, albeit testing slightly different null hypotheses (see Introduction), only the bootstrap is additionally useful for confidence interval construction. As the permutation is estimating the variance under the null hypothesis, it is expected that the estimation bias of the variance under the alternative hypothesis will increase with increasing effect size. Since the bootstrap is estimating the variance under the alternative hypothesis, the bootstrap asymptotic distribution may be more likely to deviate from normality close to the boundary of potential values, which is 1 (or −1) for the NTB. Therefore, we will additionally evaluate an inverse hyperbolic tangent transformation of the test statistic, which limits the confidence interval within the boundaries of the NTB and under which the normality assumption may hold for smaller sample sizes [
29].
By means of a simulation study, the appropriateness of the normality assumption is evaluated by means of the nominal type I error and the confidence interval coverage for small samples. The simulated samples contain 5, 10, 15, 20, 25, 30, 40, 50 or 75 observations from a normal distribution for the experimental arm and an equal number of observations from a distribution with for the control arm. These correspond to a net treatment benefit of 0, 0.2, 0.5 and 0.8. Each simulation is repeated 10,000 times.
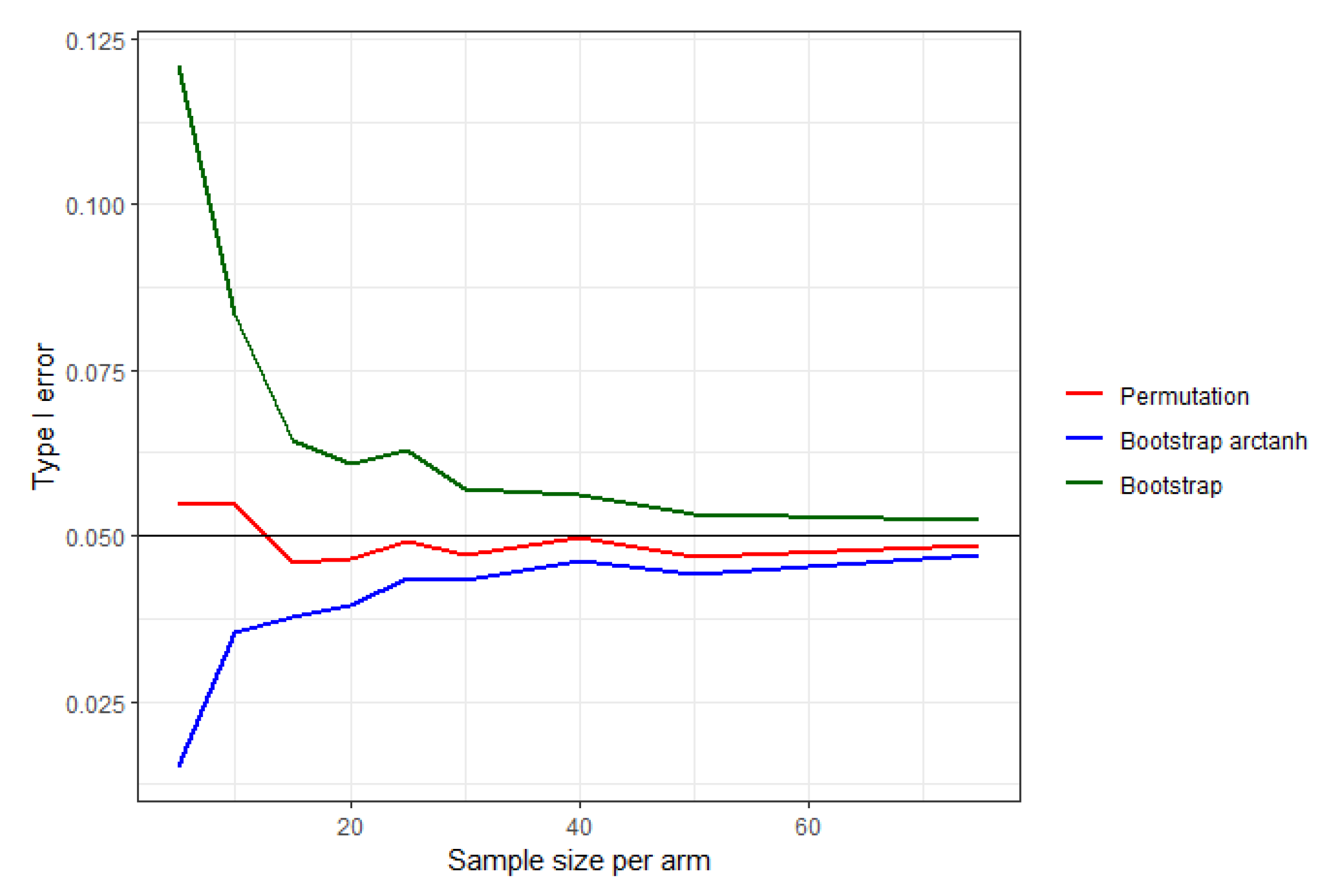
The permutation test controls the nominal alpha level well, even for very small sample sizes of five observations per treatment arm (
Figure 5). The bootstrap test and its inverse hyperbolic tangent transformation on the other hand require at least 30–40 observations per treatment arm.
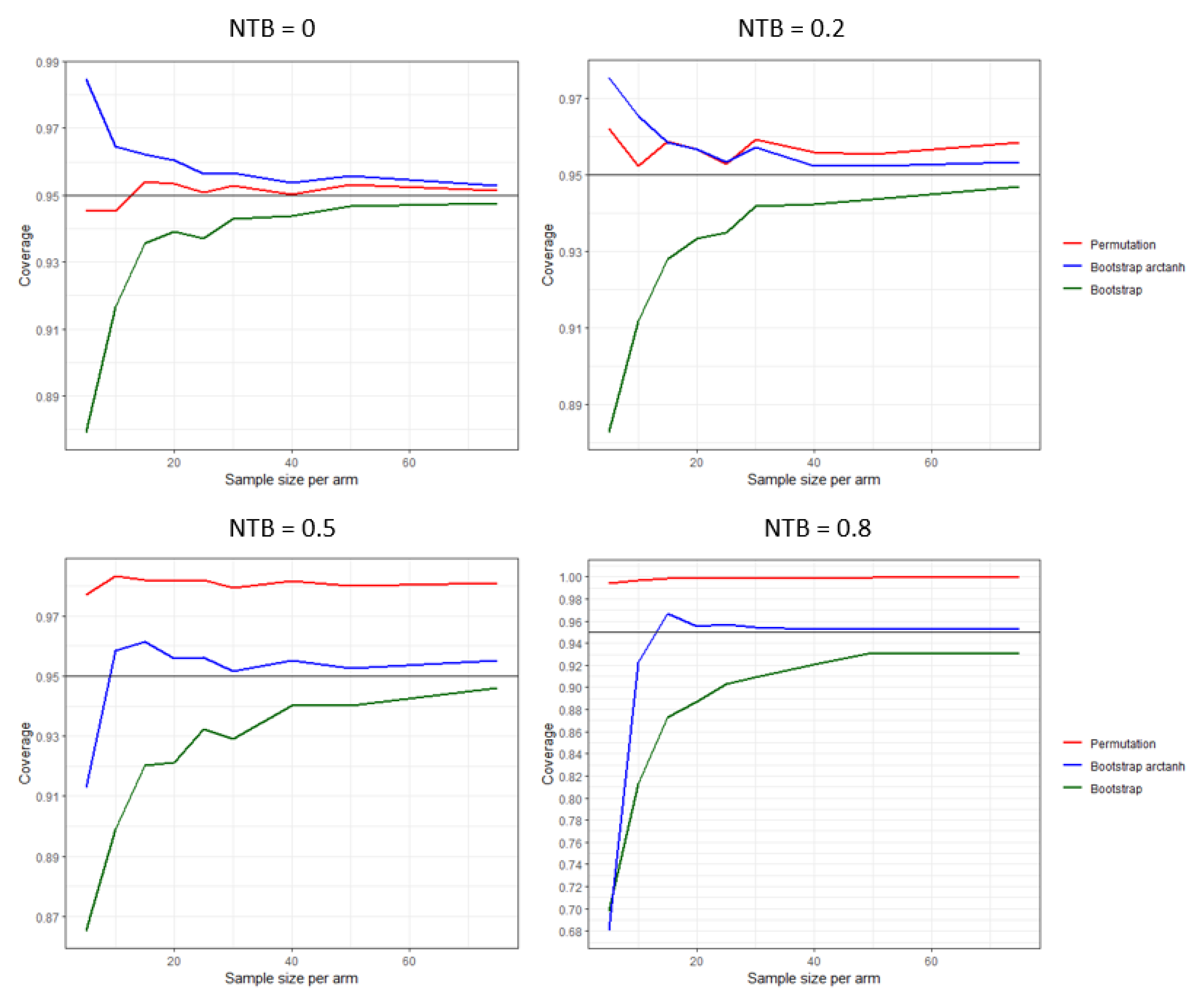
As anticipated, the confidence interval coverage based on the permutation distribution is good under the null hypothesis, but it increasingly deteriorates with increasing effect size (
Figure 6). The coverage for the transformed bootstrap is for all effect sizes better in range than the untransformed bootstrap, and depending on the effect size requires 20–30 observations per treatment arm.
Further evaluation of the permutation and bootstrap Type I error control and confidence interval coverage, in comparison with other GPC methods for inference and with other type of data, is available in Verbeeck et al. [
30].
7. Illustration
The rare, genetic skin disease epidermolysis bullosa simplex (EBS) is characterized by the formation of blisters under low mechanical stress [
31]. An innovative immunomodulatory 1% diacerein cream was postulated to reduce the number of blisters compared to placebo and evaluated in a randomized, placebo-controlled, double-blind, two-period cross-over phase II/III trial in 16 pediatric patients [
32]. After daily treatment during 4 weeks and monitoring for an additional 3 months, patients crossed over to the opposite treatment after a washout period. In each treatment period, both the number of blisters in a treated body surface area were counted and the quality of life (QoL) was assessed. The primary endpoint, the proportion of patients with more than 40% reduction in blisters at week 4 compared to baseline, however, leads to inconclusive results [
32]. The primary analysis with the Barnard [
33] test requires separate analyses per treatment period, which showed that during the first treatment period, there was a treatment effect in favor of the diacerein cream (
p = 0.007) in contrast to the second treatment period (
p = 0.32). Wally et al. [
32] discuss reasons why the second period effect might be smaller.
Since the Barnard test is ignoring the cross-over design and the QoL, it only uses a fraction of the available information in the EBS trial. It is well known that the QoL of EBS patients is poor due to the hindrance of daily activities by the blisters [
32]. While the reduction in the number of blisters is important, the healing but not yet disappearance of a blister may affect positively the QoL outcome, which is relevant for both the patient and clinician. The ability to add the QoL outcome with the blister outcome is clinically very relevant and very straightforward with GPC. We will re-analyze the EBS trial with a GPC both when prioritizing and not prioritizing the outcomes. Although GPC variants exist for matched designs [
34], such as cross-over trials, under certain circumstances, which are applicable in the general GPC test, the matching can be ignored [
35]. This means that we can consider the contribution of each subject to both treatment periods as a contribution of two independent subjects. Hence, the re-analysis will include all available information in a single analysis, which evades difficulties in interpreting conflicting results from separate analyses per treatment period.
The GPC permutation hypothesis test of the binary 40% reduction in blisters outcome and the continuous change in QoL outcome separately does not show evidence of a treatment effect of diacerin on the reduction in blisters (
), while there is evidence for improvement in QoL (
) (
Table 1). In a prioritized GPC permutation test, where the blisters are evaluated first in the pairwise comparisons, there is evidence for a positive treatment effect of diacerin (
) (
Table 1). In addition, when evaluating all pairs for both outcomes in a non-prioritized GPC, the permutation test shows evidence for a positive treatment effect (
) (
Table 1). In addition, the confidence intervals around the net treatment benefit, obtained using the inverse hyperbolic tangent bootstrap, show that there is evidence for a treatment effect by diacerein, 59% (95% CI: 19–82%) with the prioritized GPC and 48% (95% CI:21–68%) for the non-prioritized GPC (
Table 1).
8. Discussion
Efficient closed-form formulas to compute the expectation and the variance of the permutation and bootstrap distribution of GPC statistics are developed using graph theory notation. These methodologies are shown to give the exact means and variances and are not subject to sampling errors, which do result from any randomized permutation or bootstrap test. Additionally, it is shown that the time complexity is
, which is faster than any randomization permutation or bootstrap test. Since in most of the applications of the GPC statistics, only the means and variances are used [
36,
37,
38,
39,
40,
41,
42,
43,
44,
45], the proposed exact methods eliminate the need for randomization tests. In order to construct a hypothesis test for the GPC statistics, any use of the means and variances would require the assumption of asymptotic normality. This normality assumption is either explicit or implicit in the various references. The normality assumption does seem satisfactory in simulations [
30], even for sample sizes as small as 10 observations for the null permutation distribution, which is in concordance with the results from Gehan [
10]. Slightly larger sample sizes are required for the null bootstrap distribution, which has been show to be normal for U-statistics [
46], such as the net treatment benefit. Further research is required to improve the small sample behavior of the exact bootstrap test, which may include an Edgeworth expansion [
29], alternative transformations [
47], small sample corrections [
48], wild bootstrap [
49] or fractional-random-weighted bootstrap methods [
50].
Even though the mean and variance for the null permutation distribution for absolute GPC statistics, such as the Finkelstein–Schoenfeld statistic and net treatment benefit, has been established in the literature [
6,
10,
11,
20], using the graph theory notation allows easy extension to the relative GPC statistic win ratio, allows extension to the bootstrap distribution with sampling within the treatment group and sampling over the entire population and allows the generalization to score entries in
, which result from non-prioritized GPC and censoring correcting algorithms. Because of the special structure of GPC, we are able to determine the expected value and variance from the bootstrap distribution without actually using the randomization. This is not a unique feature, since Efron has shown that in some other statistics, the exact values for the bootstrap distribution can be computed [
51] (Section 10.3). Our proposed approach means an improvement in both accuracy and speed for the win ratio bootstrap test [
40,
41,
42,
43,
44,
45].
In the case of a single outcome variable without censoring, the Mann–Whitney test [
9], the Finkelstein–Schoenfeld formula (
2) and the exact formula will all agree, because all are based on counting arguments using the exact permutation distribution of the trial arms. Similarly, in the case of a single outcome variable with censored observations, the Gehan–Wilcoxon test [
10], Finkelstein–Schoenfeld formula (
2) and the exact formula will agree. The exact computation of the bootstrap mean and variance is as easy as that for the permutation mean and variance used for the Mann–Whitney, Wilcoxon, or Gehan–Wilcoxon analyses. Accordingly, the bootstrap evaluation could be considered a practical alternative to the original permutation test-based analyses. It is important to note that for the GPC permutation and bootstrap test, the slightly different null hypotheses (see introduction) are subject to different assumptions. For example, when the observations in each treatment arm come from distributions with equal location but highly different variability, then we are under the null hypothesis for the bootstrap test but not for the permutation test [
52]. Although, both tests are only consistent against location shift alternatives [
21,
22].
In addition to randomization hypothesis tests for the GPC statistics, asymptotic tests have been proposed as well [
14,
26,
27]. In a direct comparison of the asymptotic tests and the exact methods for the net benefit and win ratio statistics under location shift models, with respect to type I error control, small sample bias and 95% confidence interval coverage, the exact methods are more accurate and at least as fast [
30]. Especially in sample sizes below 100–200 subjects, the exact permutation test clearly outperforms the asymptotic based tests.
Recently, a hypothesis test for the net treatment benefit has been suggested based on U-statistic decomposition [
52]. Interestingly, the variance estimator obtained from the second-order Hoeffding decomposition of the GPC statistics exactly equals the variance of the bootstrap distribution (
Appendix B).
Importantly, the application of the variance of the permutation and bootstrap distribution assumes that the score in a pair of subjects remains constant over all possible permutation and bootstrap samples. For example, in the GPC scoring algorithms that use Kaplan–Meier estimators within treatment arms to correct for censored observations [
15,
17], the score in a pair differs between permutation and bootstrap samples. It is therefore not recommended to use the exact permutation and bootstrap inference for these scoring algorithms. Similarly, in the inverse probability censoring weighting algorithms [
18,
53] and the algorithm using the joined Kaplan–Meier estimators over both treatment arms [
16], the score in a pair remains constant in all permutation samples but not in all bootstrap samples. Only the exact permutation inference is thus recommended for these scoring algorithms.










{kind=link}
{kind=link}
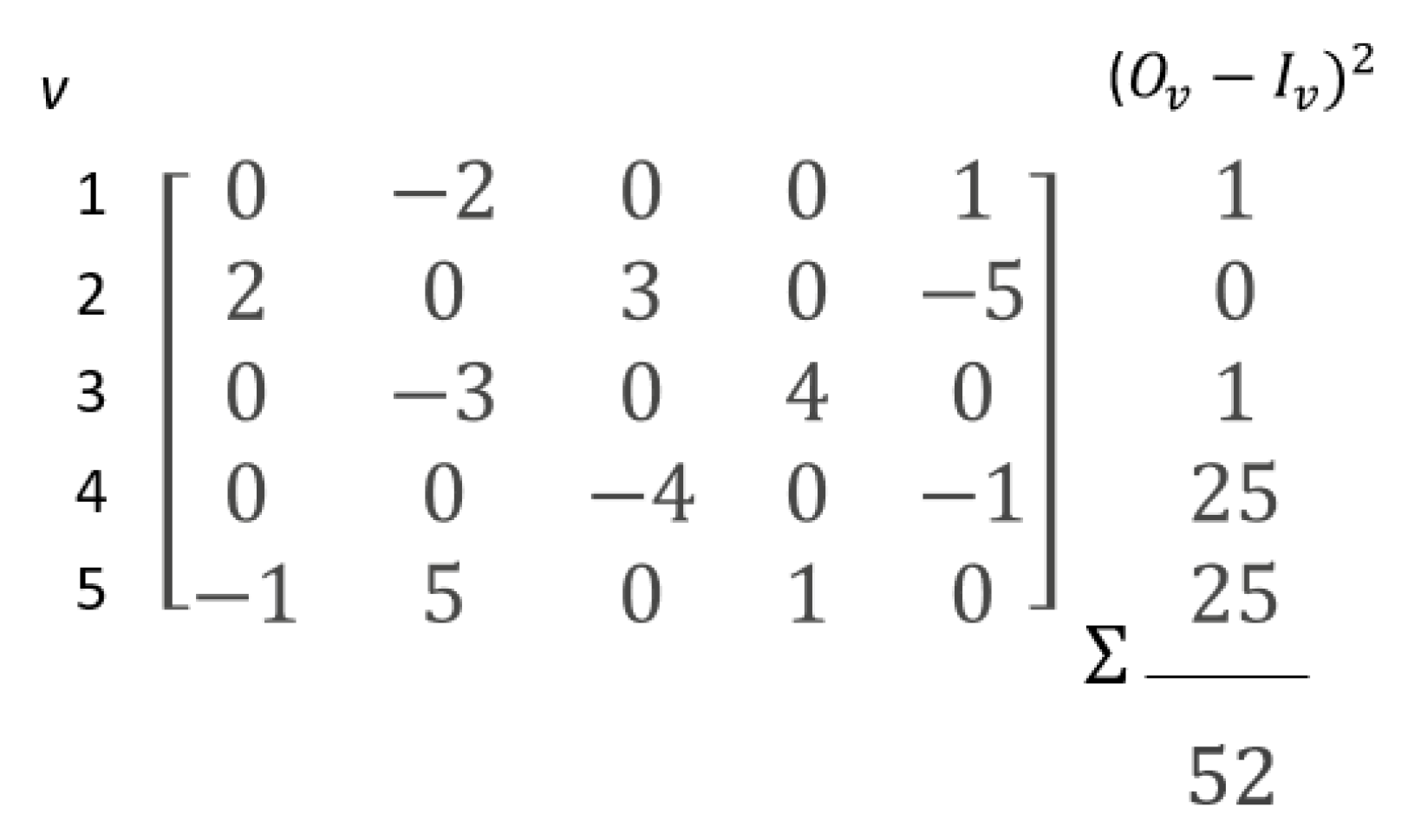{kind=link}
{kind=link}
{kind=link}
{kind=link}