
An Enhanced Simulation-Based Multi-Objective Optimization Approach with Knowledge Discovery for Reconfigurable Manufacturing Systems

 , , ,
, , ,
Abstract
:1. Introduction
- For an MPFL-RMS, a customized NSGA-II is proposed with an encoding and decoding strategy specifically designed to optimize system configuration subjected to scalable capacities and fluctuating production volumes by simultaneously addressing the task assignments to WSs and the buffer allocation problem for maximum throughput (THP) and minimum total buffer capacity (TBC). With this contribution, this study does not aim to compare the performance of the customized NSGA-II with other optimization methods or algorithms but to extend the performance of the NSGA-II and to show the benefits gained by customizing the genetic representation.
- To overcome inaccurate results and to cope with the dynamic and stochastic behavior of an RMS (e.g., resource failures, variability of task times, and inter-station buffers) while simultaneously dealing with multiple objectives, the customized NSGA-II is incorporated with DES to render an SMO approach that takes the dynamic nature of the RMS into account.
- This study enhances the proposed SMO approach with a data mining methodology for a post-optimal analysis on multi-dimensional and multi-objective optimization datasets by employing a novel flexible pattern mining algorithm in an industrial R&D RMS application. Knowledge is extracted and represented as decision rules to discover the underlying patterns that constitute the preferred solutions for a scalable RMS under different production volumes. This contribution exploits the multi-objectiveness nature of the approach to analyze the trade-off solutions found in the Pareto front and gain knowledge from it.
2. Frame of Reference
2.1. Reconfigurable Manufacturing System Challenges and Related Work
2.1.1. Single-Part Flow Lines
2.1.2. Multi-Part Flow Lines
2.2. Simulation-Based Multi-Objective Optimization and Multi-Criteria Decision Making
2.3. Knowledge Discovery and Flexible Pattern Mining
2.4. Concluding Remarks
3. A MOO Problem Formulation for RMS
- An MPFL-RMS that consists of one or several WSs manufactures several products under different production volumes.
- Resources within the RMS are subjected to maintenance, breakdown, setup times, and variability of the task times.
- All resources within a WS are identical and perform the same sequence of tasks.
- There are reserved places for adding or relocating resources in the WSs.
- There are inter-station buffers with variable capacity.
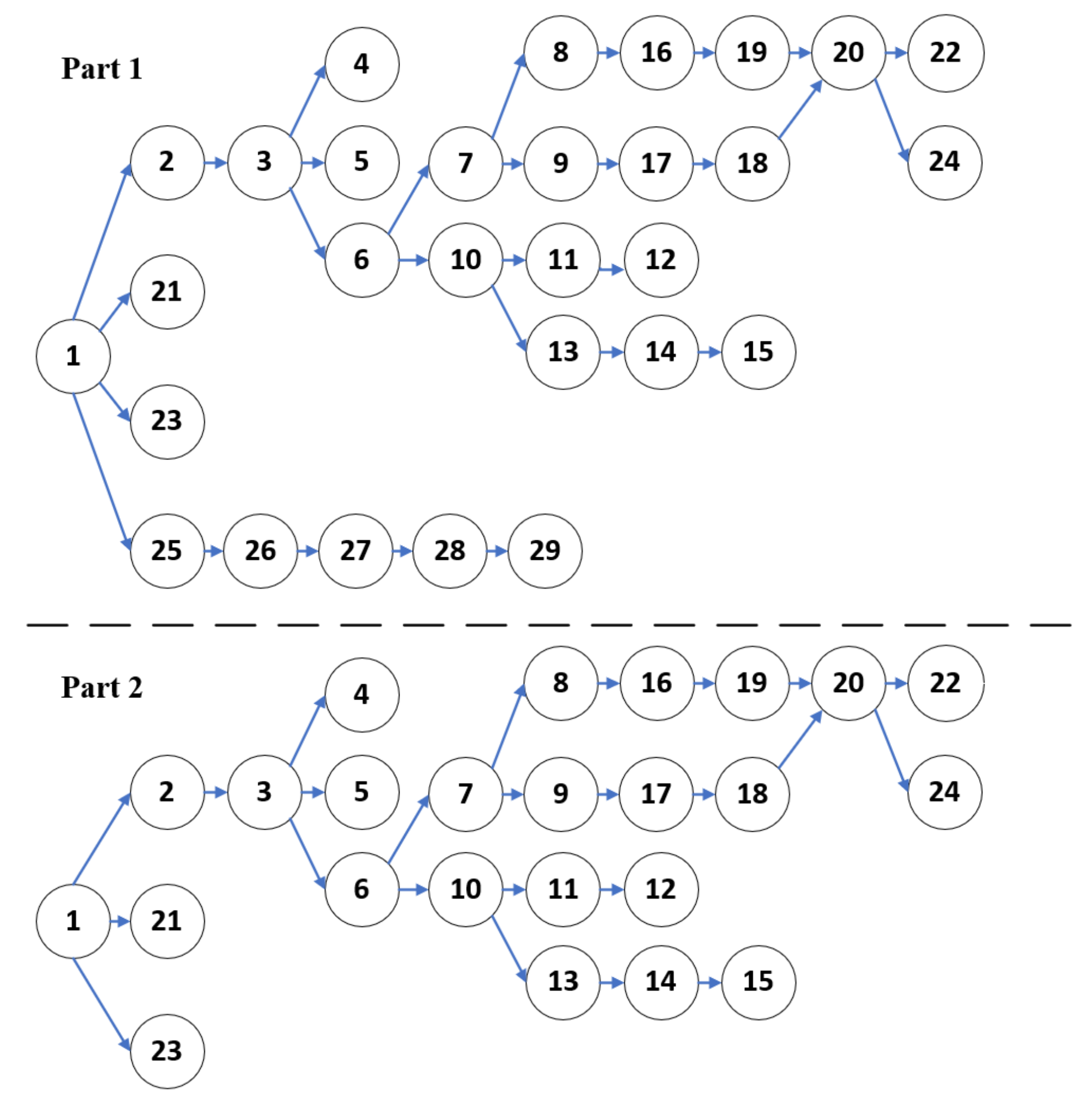
- Tasks are subjected to precedence relationship and technological requirements that ensure a feasibility sequence is performed in specific WSs.
| Notations | Definition |
| Indices: | |
| i, r | task index |
| j | WS index |
| m | resources index |
| v | variant index |
| Parameters: | |
| NS | number of WS |
| NV | number of variants |
| NTv | number of tasks for variant v (v = 1, …, NV) |
| TNM | total number of resources in RMS |
| NMWSmax | maximum number of resources per WS |
| NMWSmin | minimum number of resources per WS |
| NB | number of buffers (NS − 1) |
| Bmin | minimum safety buffer |
| Bmax | maximum buffer capacity |
| Bunit | buffer incremental unit |
| PRirv | precedence relationships for variant v; 1 if task i is the predecessor of task r; otherwise 0 |
| TRjiv | technological requirement for variant v; 1 if task i can be assigned to WS j; otherwise 0 |
| THP | throughput per hour |
| TBC | total buffer capacity |
| Decision variables: | |
| xijv | 1 if task i is assigned to WS j for variant v; 0 otherwise |
| ymj | 1 if resource m is assigned to to WS j; 0 otherwise |
| Bj | in-between buffer capacity for WS j and j + 1 |
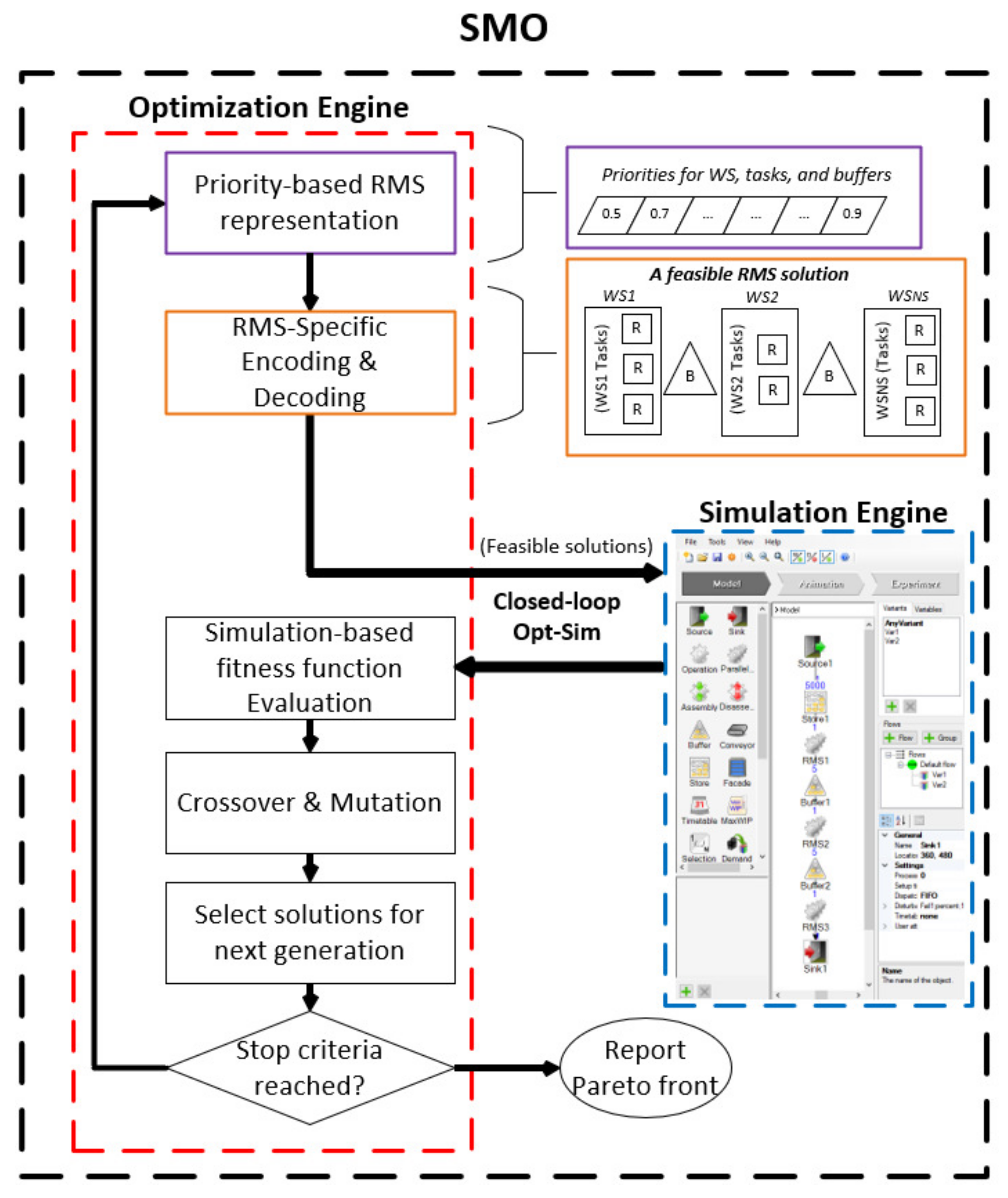
4. A Simulation-Based Multi-Objective Optimization Approach
4.1. SMO-NSGA-II for RMS
| Algorithm 1: SMO-NSGA-II |
2 Using Section 4.1.1 3 While g ≤ Gmax 4 Using the proposed encoding and decoding mechanisms in Section 4.1.2 to ensure a population of RMS feasible solutions 5 Using the simulation component in Section 4.1.3, evaluate the fitness function for each solution 6 Rank the solutions using the fast non-dominated sorting mechanism 7 Calculate the crowding distance of each solution in each individual front 8 Select parents for crossover using tournament selection 9 Using crossover and mutation operators in Section 4.1.4, generate a new set of offspring 10 Using the elitism mechanism to preserve the best individuals 11 Increment g 12 End 13 Output: The Pareto-optimal solutions for RMS |
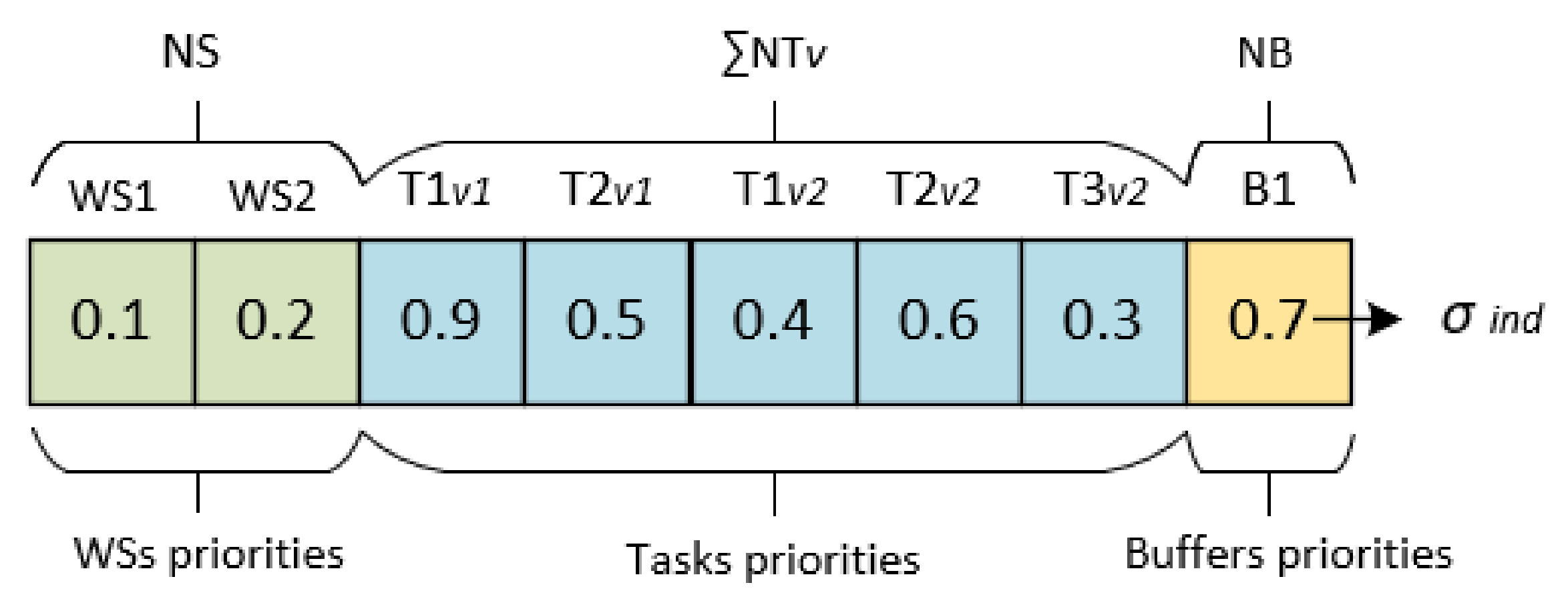
4.1.1. Solution Representation
4.1.2. Encoding and Decoding
| Algorithm 2: Encoding |
in descending order in ascending order in terms of their flexibility (based on ) and priority (based on ) in ascending and descending orders, respectively in descending order 24 While the total number of in-between buffers capacity in ascending order 29 While the total number of in-between buffers capacity to the sorted in-between buffers in line 28 31 End 32 End 33 End 34 End 35 Output: number of resources per WS, vectors of sorted tasks based on flexibility and priority per variant, in-between buffers capacity |
| Algorithm 3: Decoding |
| , vectors of sorted tasks based on flexibility and priority per variant 4 task = set the selected task as the ith index in the sorted tasks vector for variant v matrix by to 9 End 10 End 11 Calculate the total task time per variant per WS 12 Output: A feasible solution for RMS includes the number of resources per WS (encoding), assignment of tasks to WSs (decoding), the total task time per variant per WS (decoding), and in-between buffers capacity (encoding) |
4.1.3. SMO-Based Fitness Function Evaluation of the RMS Solution
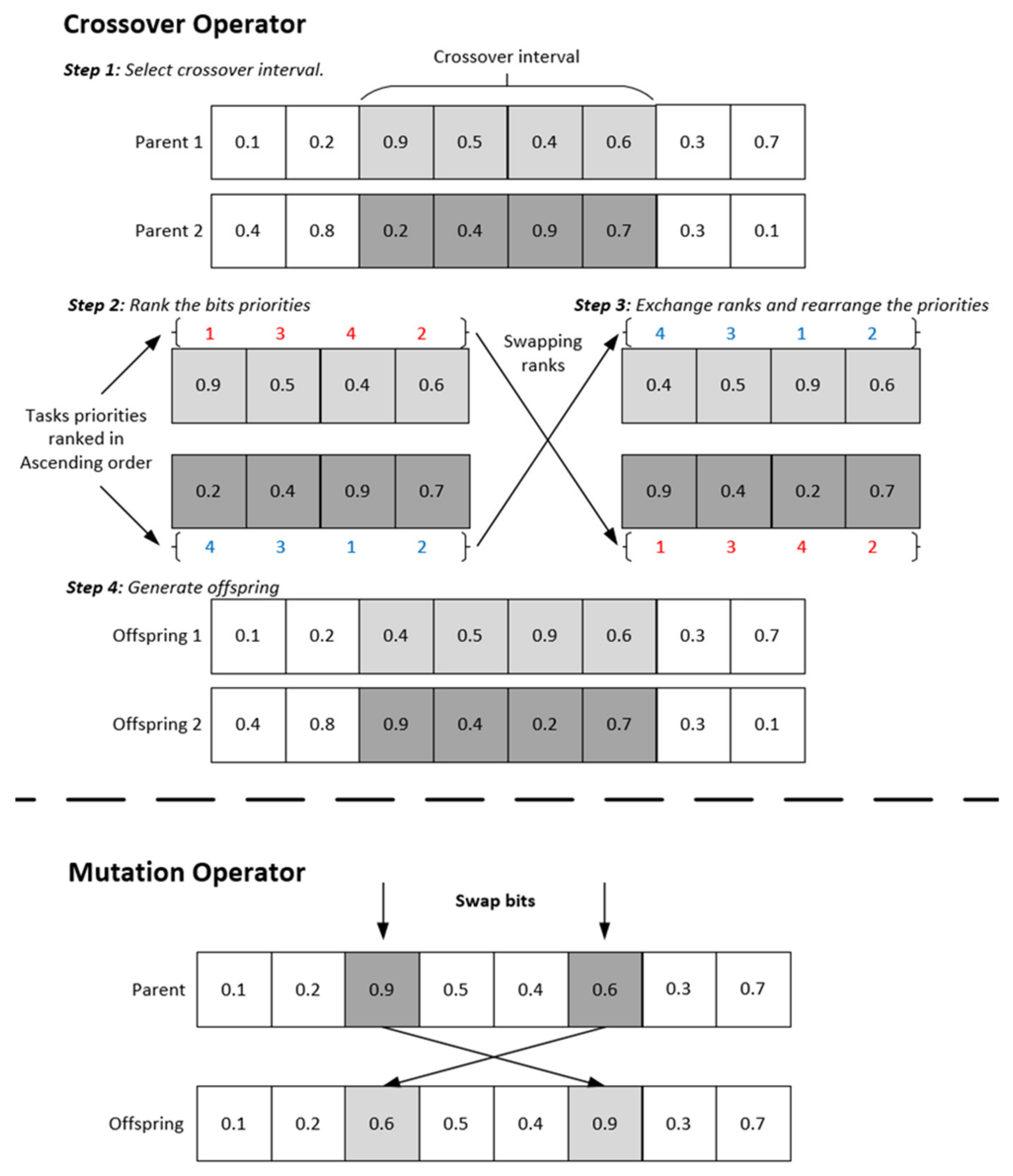
4.1.4. Genetic Operators (Crossover/Mutation)
5. An Application Case with Multiple Instances
6. Experimental Results and Knowledge Discovery
6.1. Approach Comparison
6.2. Knowledge Discovery from SMO
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Diaz, C.A.B.; Aslam, T.; Ng, A.H.C. Optimizing Reconfigurable Manufacturing Systems for Fluctuating Production Volumes: A Simulation-Based Multi-Objective Approach. IEEE Access 2021, 9, 144195–144210. [Google Scholar] [CrossRef]
- Dou, J.; Li, J.; Xia, D.; Zhao, X. A Multi-Objective Particle Swarm Optimisation for Integrated Configuration Design and Scheduling in Reconfigurable Manufacturing System. Int. J. Prod. Res. 2020, 59, 3975–3995. [Google Scholar] [CrossRef]
- Koren, Y.; Wang, W.; Gu, X. Value Creation through Design for Scalability of Reconfigurable Manufacturing Systems. Int. J. Prod. Res. 2017, 55, 1227–1242. [Google Scholar] [CrossRef]
- Koren, Y.; Heisel, U.; Jovane, F.; Moriwaki, T.; Pritschow, G.; Ulsoy, G.; van Brussel, H. Reconfigurable Manufacturing Systems. CIRP Ann. 1999, 48, 527–540. [Google Scholar] [CrossRef]
- Diaz, C.A.B.; Aslam, T.; Ng, A.H.C.; Flores-Garcia, E.; Wiktorsson, M. Simulation-Based Multi-Objective Optimization for Reconfigurable Manufacturing System Configurations Analysis. In Proceedings of the 2020 Winter Simulation Conference, Orlando, FL, USA, 14–18 December 2020; pp. 1527–1538. [Google Scholar] [CrossRef]
- Koren, Y.; Gu, X.; Guo, W. Reconfigurable Manufacturing Systems: Principles, Design, and Future Trends. Front. Mech. Eng. 2018, 13, 121–136. [Google Scholar] [CrossRef] [Green Version]
- Fan, J.; Zhang, C.; Liu, Q.; Shen, W.; Gao, L. An Improved Genetic Algorithm for Flexible Job Shop Scheduling Problem Considering Reconfigurable Machine Tools with Limited Auxiliary Modules. J. Manuf. Syst. 2022, 62, 650–667. [Google Scholar] [CrossRef]
- Bortolini, M.; Galizia, F.G.; Mora, C. Reconfigurable Manufacturing Systems: Literature Review and Research Trend. J. Manuf. Syst. 2018, 49, 93–106. [Google Scholar] [CrossRef]
- Yelles-Chaouche, A.R.; Gurevsky, E.; Brahimi, N.; Dolgui, A. Reconfigurable Manufacturing Systems from an Optimisation Perspective: A Focused Review of Literature. Int. J. Prod. Res. 2020, 59, 6400–6418. [Google Scholar] [CrossRef]
- Koren, Y.; Gu, X.; Guo, W. Choosing the System Configuration for High-Volume Manufacturing. Int. J. Prod. Res. 2018, 56, 476–490. [Google Scholar] [CrossRef]
- Dou, J.; Dai, X.; Meng, Z. Optimisation for Multi-Part Flow-Line Configuration of Reconfigurable Manufacturing System Using GA. Int. J. Prod. Res. 2010, 48, 4071–4100. [Google Scholar] [CrossRef]
- Goyal, K.K.; Jain, P.K.; Jain, M. Optimal Configuration Selection for Reconfigurable Manufacturing System Using NSGA II and TOPSIS. Int. J. Prod. Res. 2012, 50, 4175–4191. [Google Scholar] [CrossRef]
- Pehrsson, L.; Frantzén, M.; Aslam, T.; Ng, A.H.C. Aggregated Line Modeling for Simulation and Optimization of Manufacturing Systems. In Proceedings of the 2015 Winter Simulation Conference, Huntington Beach, CA, USA, 6 December 2015; pp. 3632–3643. [Google Scholar]
- Mourtzis, D. Simulation in the Design and Operation of Manufacturing Systems: State of the Art and New Trends. Int. J. Prod. Res. 2020, 58, 1927–1949. [Google Scholar] [CrossRef]
- Petroodi, S.E.H.; Eynaud, A.B.D.; Klement, N.; Tavakkoli-Moghaddam, R. Simulation-Based Optimization Approach with Scenario-Based Product Sequence in a Reconfigurable Manufacturing System (RMS): A Case Study. IFAC-PapersOnLine 2019, 52, 2638–2643. [Google Scholar] [CrossRef]
- Juan, A.A.; Faulin, J.; Grasman, S.E.; Rabe, M.; Figueira, G. A Review of Simheuristics: Extending Metaheuristics to Deal with Stochastic Combinatorial Optimization Problems. Oper. Res. Perspect. 2015, 2, 62–72. [Google Scholar] [CrossRef] [Green Version]
- Niño-Pérez, E.; Méndez-Vázquez, Y.M.; Arias-González, D.E.; Cabrera-Ríos, M. A Simulation–Optimization Strategy to Deal Simultaneously with Tens of Decision Variables and Multiple Performance Measures in Manufacturing. J. Simul. 2018, 12, 258–270. [Google Scholar] [CrossRef]
- Xu, J.; Huang, E.; Hsieh, L.; Lee, L.H.; Jia, Q.S.; Chen, C.H. Simulation Optimization in the Era of Industrial 4.0 and the Industrial Internet. J. Simul. 2016, 10, 310–320. [Google Scholar] [CrossRef]
- Barrera Diaz, C.A.; Fathi, M.; Aslam, T.; Ng, A.H.C. Optimizing Reconfigurable Manufacturing Systems: A Simulation-Based Multi-Objective Optimization Approach. Procedia CIRP 2021, 104, 1837–1842. [Google Scholar] [CrossRef]
- Bensmaine, A.; Dahane, M.; Benyoucef, L. A Simulation-Based Genetic Algorithm Approach for Process Plans Selection in Uncertain Reconfigurable Environment. IFAC Proc. Vol. 2013, 46, 1961–1966. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A Fast and Elitist Multi-objective Genetic Algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Michalos, G.; Makris, S.; Mourtzis, D. An Intelligent Search Algorithm-Based Method to Derive Assembly Line Design Alternatives. Int. J. Comput. Integr. Manuf. 2012, 25, 211–229. [Google Scholar] [CrossRef]
- Renzi, C.; Leali, F.; Cavazzuti, M.; Andrisano, A.O. A Review on Artificial Intelligence Applications to the Optimal Design of Dedicated and Reconfigurable Manufacturing Systems. Int. J. Adv. Manuf. Technol. 2014, 72, 403–418. [Google Scholar] [CrossRef]
- Delorme, X.; Malyutin, S.; Dolgui, A. A Multi-Objective Approach for Design of Reconfigurable Transfer Lines. IFAC-PapersOnLine 2016, 49, 509–514. [Google Scholar] [CrossRef]
- Bandaru, S.; Ng, A.H.C.; Deb, K. Data Mining Methods for Knowledge Discovery in Multi-Objective Optimization: Part A—Survey. Expert Syst. Appl. 2017, 70, 139–159. [Google Scholar] [CrossRef] [Green Version]
- Koren, Y.; Hu, S.J.; Weber, T.W. Impact of Manufacturing System Configuration on Performance. CIRP Ann. 1998, 47, 369–372. [Google Scholar] [CrossRef]
- ElMaraghy, H.A. Reconfigurable Process Plans for Responsive Manufacturing Systems. In Digital Enterprise Technology: Perspectives and Future Challenges; Springer: Berlin/Heidelberg, Germany, 2007; pp. 35–44. [Google Scholar]
- Koren, Y. The Rapid Responsiveness of RMS. Int. J. Prod. Res. 2013, 51, 6817–6827. [Google Scholar] [CrossRef]
- Wang, W.; Koren, Y. Scalability Planning for Reconfigurable Manufacturing Systems. J. Manuf. Syst. 2012, 31, 83–91. [Google Scholar] [CrossRef]
- Shabaka, A.I.; Elmaraghy, H.A. A Model for Generating Optimal Process Plans in RMS. Int. J. Comput. Integr. Manuf. 2008, 21, 180–194. [Google Scholar] [CrossRef]
- Dou, J.P.; Dai, X.; Meng, Z. Precedence Graph-Oriented Approach to Optimise Single-Product Flow-Line Configurations of Reconfigurable Manufacturing System. Int. J. Comput. Integr. Manuf. 2009, 22, 923–940. [Google Scholar] [CrossRef]
- Dou, J.; Dai, X.; Meng, Z. A GA-Based Approach for Optimizing Single-Part Flow-Line Configurations of RMS. J. Intell. Manuf. 2011, 22, 301–317. [Google Scholar] [CrossRef]
- Moghaddam, S.K.; Houshmand, M.; Fatahi Valilai, O. Configuration Design in Scalable Reconfigurable Manufacturing Systems (RMS); a Case of Single-Product Flow Line (SPFL). Int. J. Prod. Res. 2018, 56, 3932–3954. [Google Scholar] [CrossRef]
- Deif, A.M.; ElMaraghy, W. Investigating Optimal Capacity Scalability Scheduling in a Reconfigurable Manufacturing System. Int. J. Adv. Manuf. Technol. 2007, 32, 557–562. [Google Scholar] [CrossRef] [Green Version]
- Borisovsky, P.A.; Delorme, X.; Dolgui, A. Genetic Algorithm for Balancing Reconfigurable Machining Lines. Comput. Ind. Eng. 2013, 66, 541–547. [Google Scholar] [CrossRef]
- Makssoud, F.; Battaïa, O.; Dolgui, A. Reconfiguration of Machining Transfer Lines. In Service Orientation in Holonic and Multi Agent Manufacturing and Robotics; Spring: Berlin/Heidelberg, Germany, 2013; pp. 339–353. [Google Scholar]
- Goyal, K.K.; Jain, P.K. Design of Reconfigurable Flow Lines Using MOPSO and Maximum Deviation Theory. Int. J. Adv. Manuf. Technol. 2016, 84, 1587–1600. [Google Scholar] [CrossRef]
- Khezri, A.; Benderbal, H.H.; Benyoucef, L. Towards a Sustainable Reconfigurable Manufacturing System (SRMS): Multi-Objective Based Approaches for Process Plan Generation Problem. Int. J. Prod. Res. 2020, 1–26. [Google Scholar] [CrossRef]
- Touzout, F.A.; Benyoucef, L. Multi-Objective Sustainable Process Plan Generation in a Reconfigurable Manufacturing Environment: Exact and Adapted Evolutionary Approaches. Int. J. Prod. Res. 2018, 57, 2531–2547. [Google Scholar] [CrossRef]
- Touzout, F.A.; Benyoucef, L. Multi-Objective Multi-Unit Process Plan Generation in a Reconfigurable Manufacturing Environment: A Comparative Study of Three Hybrid Metaheuristics. Int. J. Prod. Res. 2019, 57, 7520–7535. [Google Scholar] [CrossRef]
- Youssef, A.M.A.; ElMaraghy, H.A. Availability Consideration in the Optimal Selection of Multiple-Aspect RMS Configurations. Int. J. Prod. Res. 2008, 46, 5849–5882. [Google Scholar] [CrossRef]
- Saxena, L.K.; Jain, P.K. A Model and Optimisation Approach for Reconfigurable Manufacturing System Configuration Design. Int. J. Prod. Res. 2012, 50, 3359–3381. [Google Scholar] [CrossRef]
- Moghaddam, S.K.; Houshmand, M.; Saitou, K.; Fatahi Valilai, O. Configuration Design of Scalable Reconfigurable Manufacturing Systems for Part Family. Int. J. Prod. Res. 2020, 58, 2974–2996. [Google Scholar] [CrossRef]
- Bensmaine, A.; Dahane, M.; Benyoucef, L. A Non-Dominated Sorting Genetic Algorithm Based Approach for Optimal Machines Selection in Reconfigurable Manufacturing Environment. Comput. Ind. Eng. 2013, 66, 519–524. [Google Scholar] [CrossRef]
- Bensmaine, A.; Dahane, M.; Benyoucef, L. A New Heuristic for Integrated Process Planning and Scheduling in Reconfigurable Manufacturing Systems. Int. J. Prod. Res. 2014, 52, 3583–3594. [Google Scholar] [CrossRef]
- Musharavati, F.; Hamouda, A.S.M. Enhanced Simulated-Annealing-Based Algorithms and Their Applications to Process Planning in Reconfigurable Manufacturing Systems. Adv. Eng. Softw. 2012, 45, 80–90. [Google Scholar] [CrossRef]
- Chaube, A.; Benyoucef, L.; Tiwari, M.K. An Adapted NSGA-2 Algorithm Based Dynamic Process Plan Generation for a Reconfigurable Manufacturing System. J. Intell. Manuf. 2012, 23, 1141–1155. [Google Scholar] [CrossRef]
- Dou, J.; Li, J.; Su, C. Bi-Objective Optimization of Integrating Configuration Generation and Scheduling for Reconfigurable Flow Lines Using NSGA-II. Int. J. Adv. Manuf. Technol. 2016, 86, 1945–1962. [Google Scholar] [CrossRef]
- Miettinen, K.; Hakanen, J.; Podkopaev, D. Interactive Nonlinear Multi-objective Optimization Methods. Int. Ser. Oper. Res. Manag. Sci. 2016, 233, 927–976. [Google Scholar] [CrossRef]
- Qu, S.; Shu, L.; Yao, J. Optimal Pricing and Service Level in Supply Chain Considering Misreport Behavior and Fairness Concern. Comput. Ind. Eng. 2022, 174, 108759. [Google Scholar] [CrossRef]
- Deb, K. Multi-Objective Optimization. In Search Methodologies; Springer: Boston, MA, USA, 2014; pp. 403–449. [Google Scholar] [CrossRef]
- Jian, N.; Henderson, S.G. An Introduction to Simulation Optimization. In Proceedings of the 2015 Winter Simulation Conference, Huntington Beach, CA, USA, 6–9 December 2015; pp. 1780–1794. [Google Scholar] [CrossRef]
- Carson, Y.; Maria, A. Simulation Optimization: Methods and Applications. In Proceedings of the 29th Conference on Winter Simulation, Atlanta, GE, USA, 7–10 December 1997; pp. 118–126. [Google Scholar]
- Qu, S.; Xu, L.; Mangla, S.K.; Chan, F.T.S.; Zhu, J.; Arisian, S. Matchmaking in Reward-Based Crowdfunding Platforms: A Hybrid Machine Learning Approach. Int. J. Prod. Res. 2022, 60, 7551–7571. [Google Scholar] [CrossRef]
- Bandaru, S.; Ng, A.H.C.; Deb, K. Data Mining Methods for Knowledge Discovery in Multi-Objective Optimization: Part B—New Developments and Applications. Expert Syst. Appl. 2017, 70, 119–138. [Google Scholar] [CrossRef] [Green Version]
- Agrawal, R.; Srikant, R. Fast Algorithms for Mining Association Rules in Large Databases. In Proceedings of the 20th International Conference on Very Large Data Bases, San Francisco, CA, USA, 12–15 September 1994; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1994; pp. 487–499. [Google Scholar]
- Kou, Z.; Xi, L. Binary Particle Swarm Optimization-Based Association Rule Mining for Discovering Relationships between Machine Capabilities and Product Features. Math. Probl. Eng. 2018, 2018, 2456010. [Google Scholar] [CrossRef] [Green Version]
- Tripathi, S.; Muhr, D.; Brunner, M.; Jodlbauer, H.; Dehmer, M.; Emmert-Streib, F. Ensuring the Robustness and Reliability of Data-Driven Knowledge Discovery Models in Production and Manufacturing. Front. Artif. Intell. 2021, 4, 22. [Google Scholar] [CrossRef]
- ElMaraghy, H.; Monostori, L.; Schuh, G.; ElMaraghy, W. Evolution and Future of Manufacturing Systems. CIRP Ann. 2021, 70, 635–658. [Google Scholar] [CrossRef]
- Algeddawy, T.; Elmaraghy, H. Manufacturing Systems Synthesis Using Knowledge Discovery. CIRP Ann. 2011, 60, 437–440. [Google Scholar] [CrossRef]
- Ng, A.H.C.; Bernedixen, J.; Moris, M.U.; Jägstam, M. Factory Flow Design and Analysis Using Internet-Enabled Simulation-Based Optimization and Automatic Model Generation. In Proceedings of the 2011 Winter Simulation Conference, Phoenix, AZ, USA, 11–14 December 2011; pp. 2181–2193. [Google Scholar]
- Lidberg, S.; Aslam, T.; Pehrsson, L.; Ng, A.H.C. Optimizing Real-World Factory Flows Using Aggregated Discrete Event Simulation Modelling: Creating Decision-Support through Simulation-Based Optimization and Knowledge-Extraction. Flex. Serv. Manuf. J. 2020, 32, 888–912. [Google Scholar] [CrossRef] [Green Version]
- Ng, A.H.C.; Bernedixen, J.; Syberfeldt, A. International Journal of Production Research A Comparative Study of Production Control Mechanisms Using Simulation-Based Multi-Objective Optimisation A Comparative Study of Production Control Mechanisms Using Simulation-Based Multi-Objective Optimisation. Int. J. Prod. Res. 2012, 50, 359–377. [Google Scholar] [CrossRef]
- Zitzler, E.; Thiele, L. Multi-objective Evolutionary Algorithms: A Comparative Case Study and the Strength Pareto Approach. IEEE Trans. Evol. Comput. 1999, 3, 257–271. [Google Scholar] [CrossRef] [Green Version]
- Smedberg, H.; Bandaru, S. Interactive Knowledge Discovery and Knowledge Visualization for Decision Support in Multi-Objective Optimization. Eur. J. Oper. Res. 2022, 306, 1311–1329. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
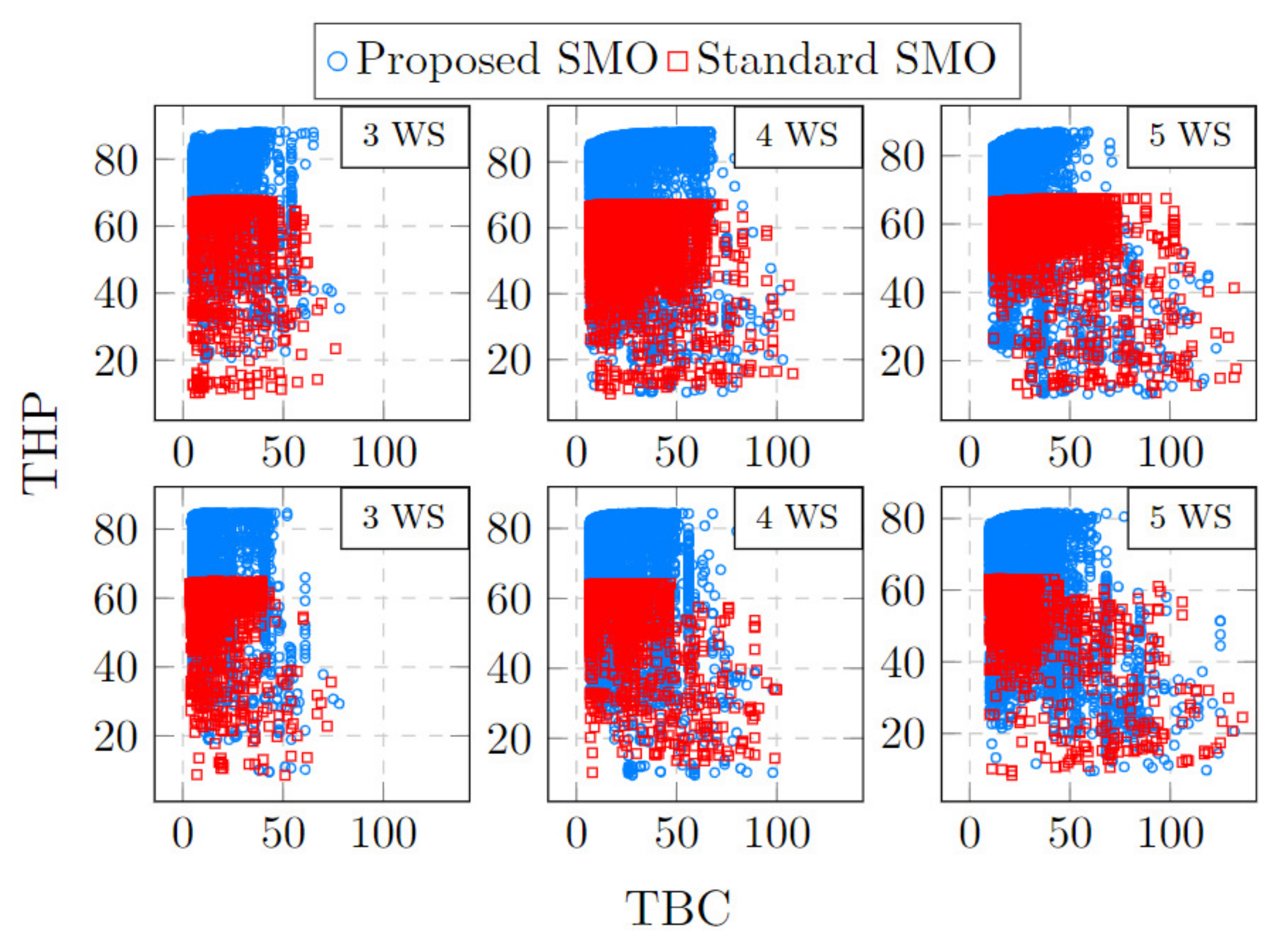{kind=link}
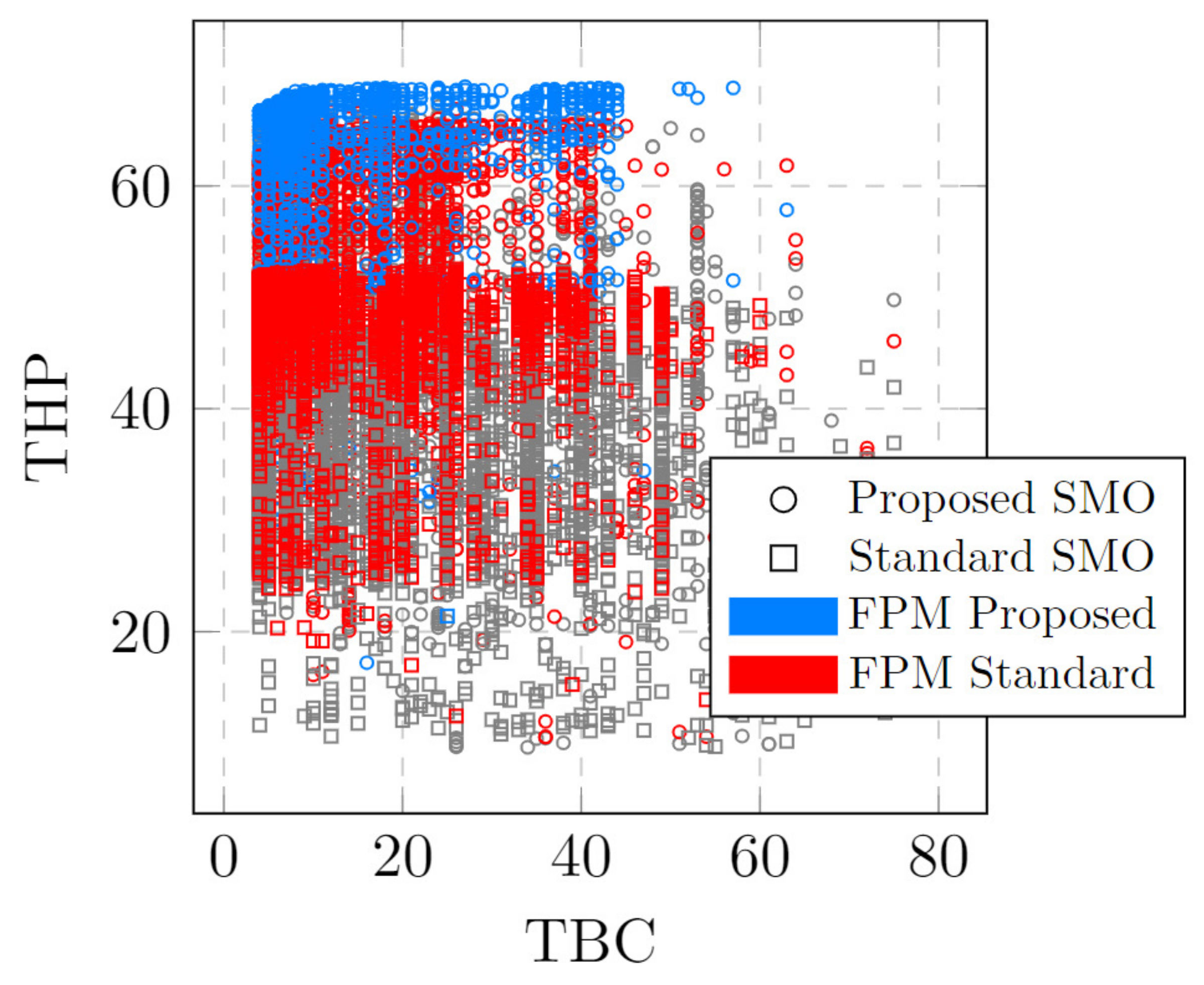{kind=link}
| NO | Proportion | THP | Bu1 | Bu2 | TBC |
|---|---|---|---|---|---|
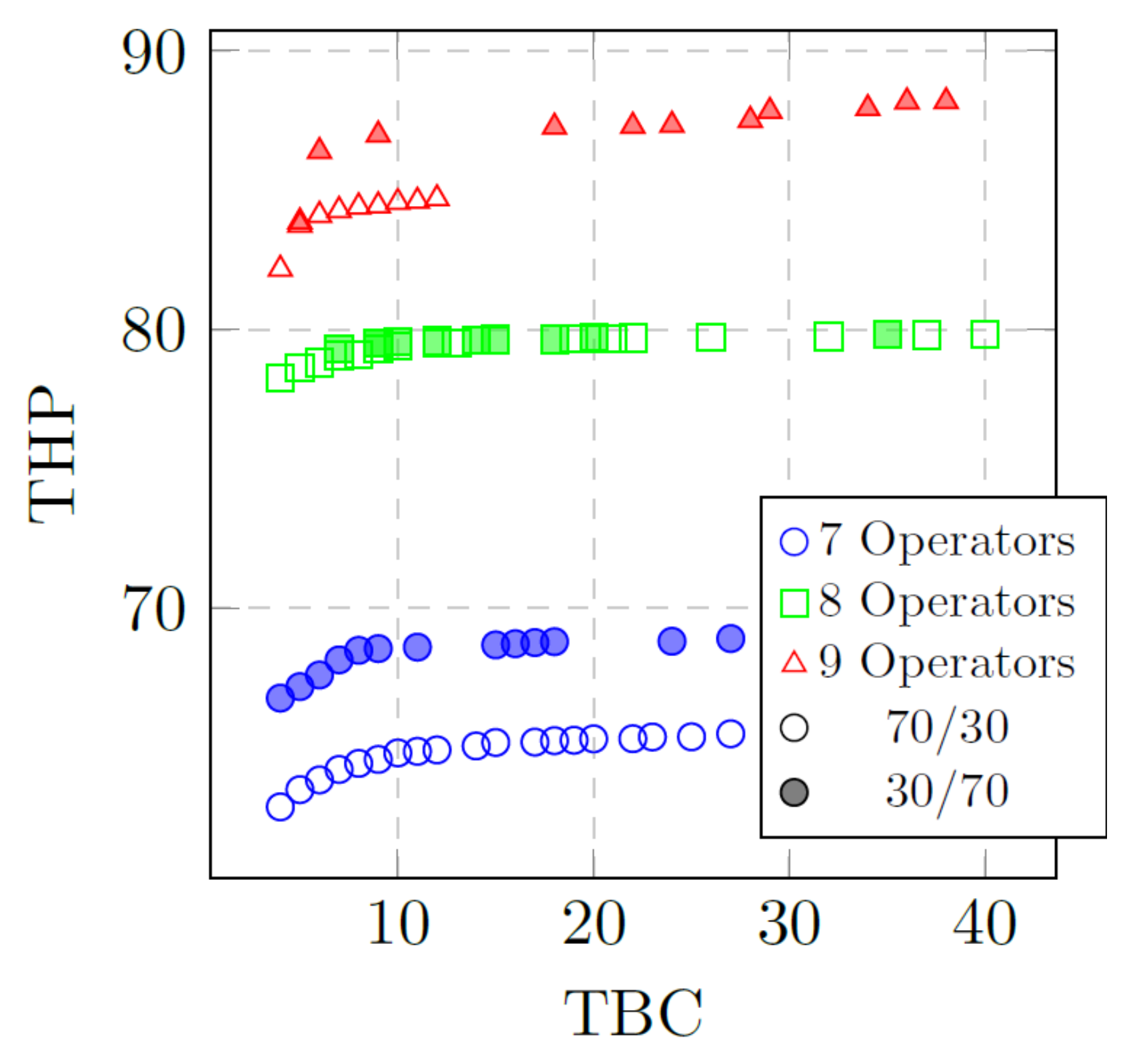
| 7 | 30/70 70/30 | 66.76–68.90 62.86–65.48 | 2–13 2–6 | 2–14 2–21 | 4–27 4–27 |
| 8 | 30/70 70/30 | 79.31–79.82 78.27–79.81 | 3–7 2–16 | 4–28 2–24 | 7–35 4–40 |
| 9 | 30/70 70/30 | 83.86–88.18 82.16–84.69 | 2–5 2–5 | 3–33 2–7 | 5–38 4–12 |
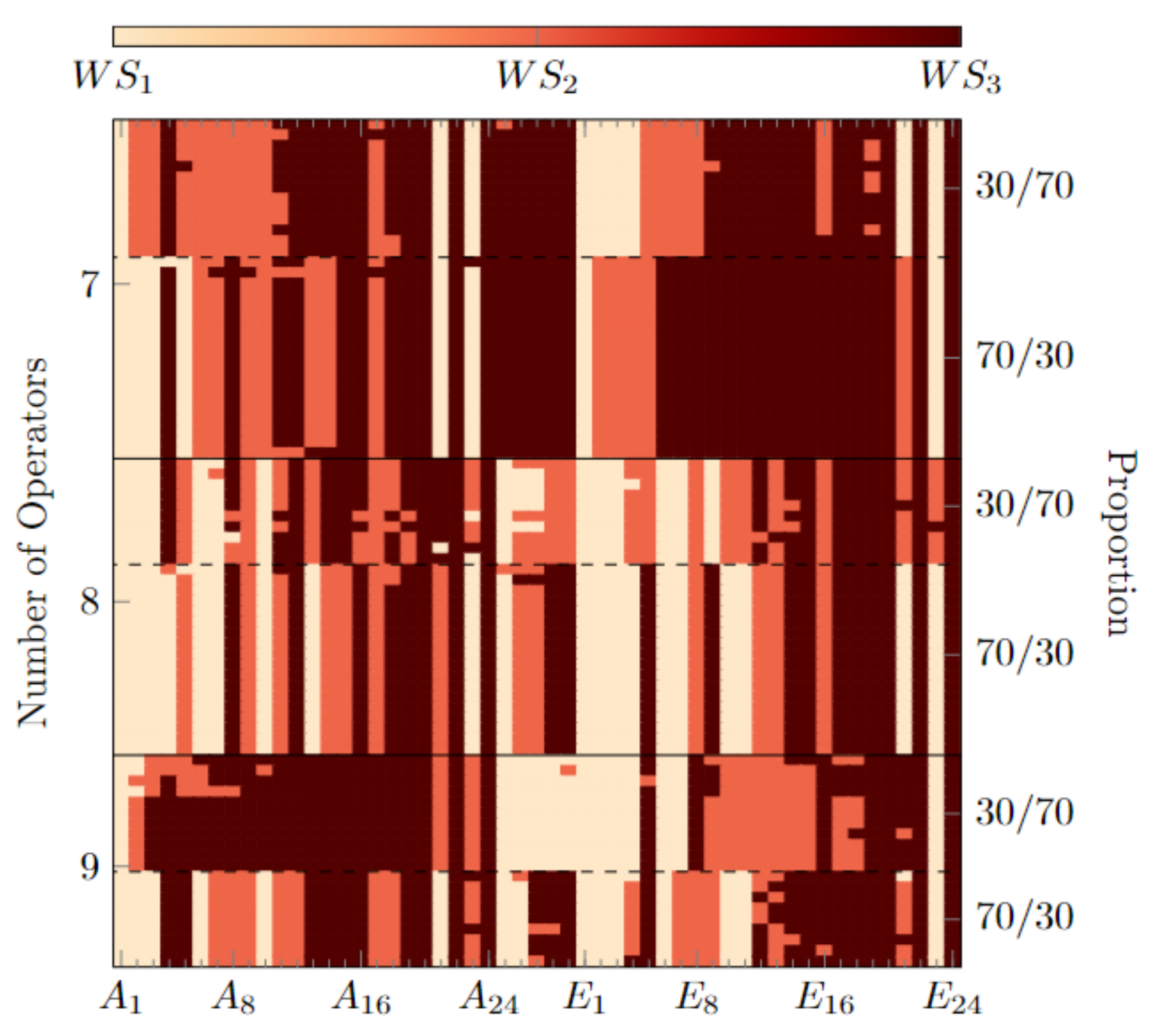
| NO | Proportion | WS1 | WS2 | WS3 | Tasks |
|---|---|---|---|---|---|
| 7 | 30/70 70/30 | 1 1 | 2 2 | 4 4 | 9/14–15/29–30 8/11–12/33–34 |
| 8 | 30/70 70/30 | 2 3 | 3 2 | 3 3 | 13–16/17–20/19–20 19–20/12–14/20–21 |
| 9 | 30/70 70/30 | 2 2 | 3 3 | 4 4 | 13–14/12–14/26–28 15–16/13–15/23–24 |
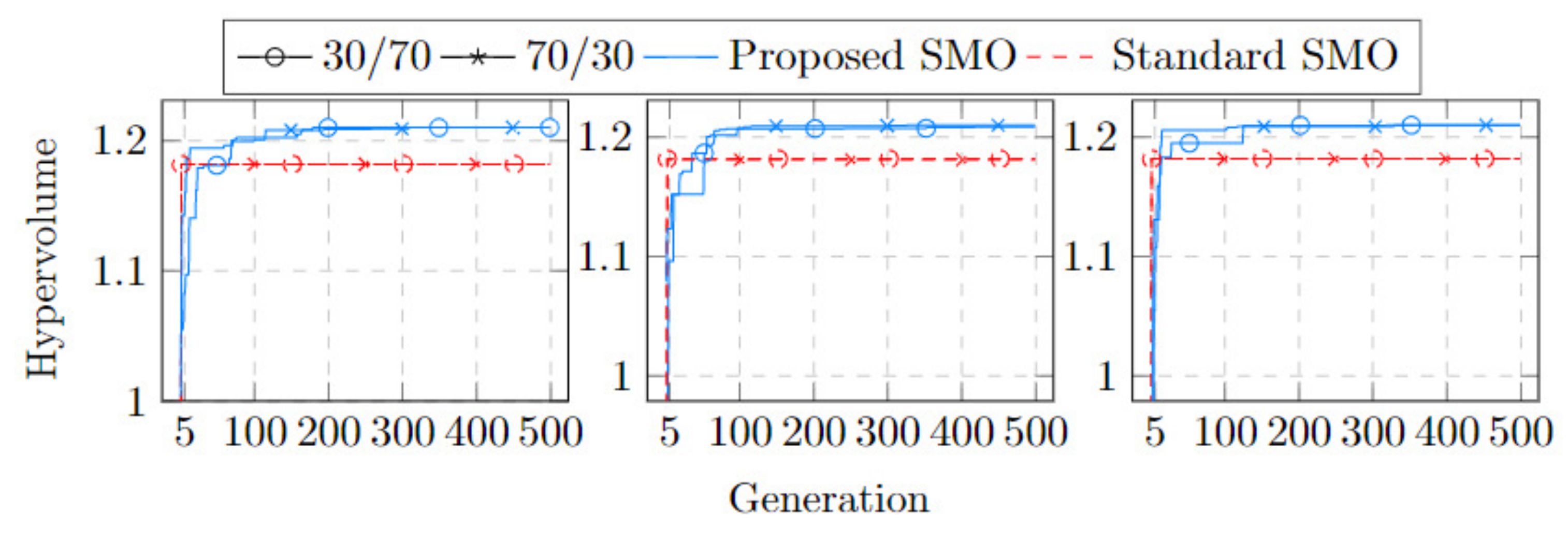
| NO | Proportion | Proposed SMO | Standard SMO |
|---|---|---|---|
| 7 | 30/70 | 1.066 × 100 | 3.277 × 10−1 |
| 70/30 | 1.055 × 100 | 3.516 × 10−1 | |
| 8 | 30/70 | 1.031 × 100 | 2.981 × 10−1 |
| 70/30 | 1.159 × 100 | 1927 × 10−1 | |
| 9 | 30/70 | 1.070 × 100 | 3.512 × 10−1 |
| 70/30 | 9.341 × 10−1 | 3.072 × 10−1 |
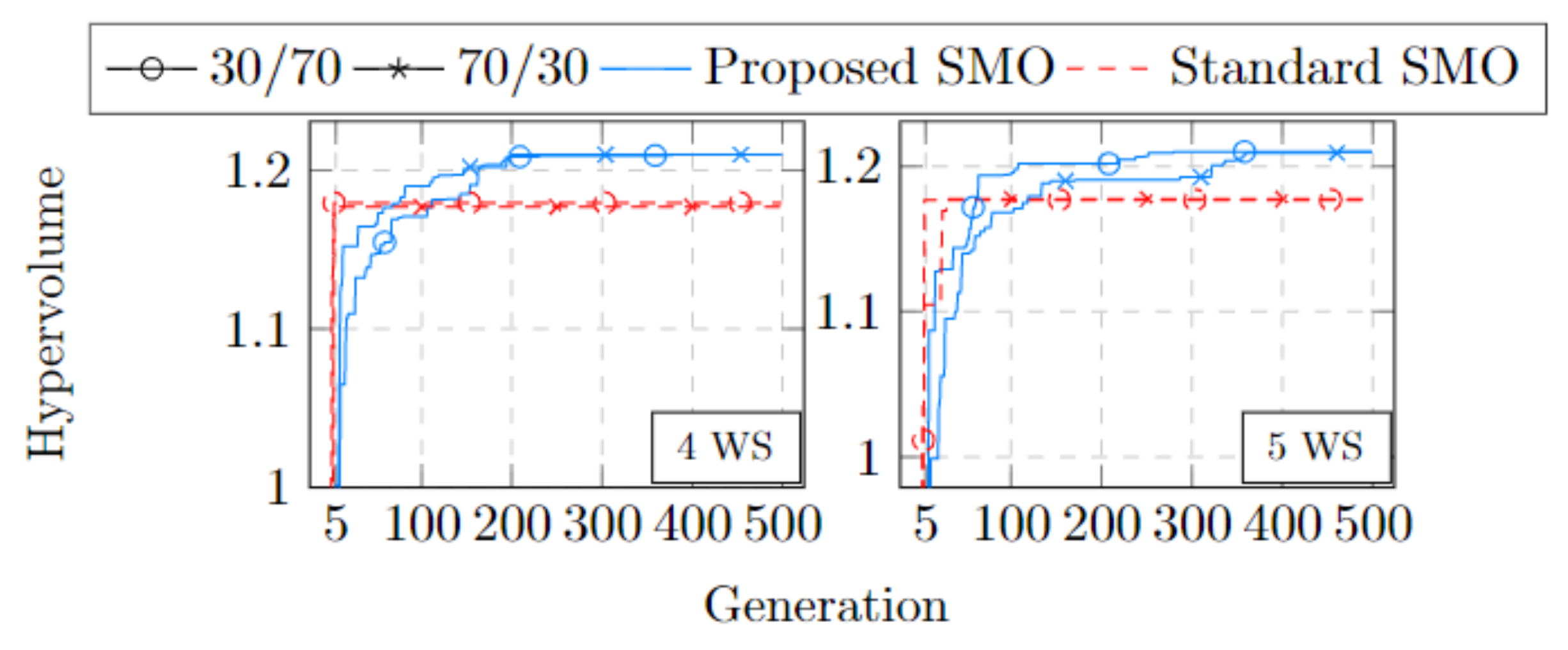
| WS | Proportion | Proposed SMO | Standard SMO |
|---|---|---|---|
| 4 | 30/70 | 1.103 × 100 | 2.233 × 10−1 |
| 70/30 | 1.021 × 100 | 2.422 × 10−1 | |
| 5 | 30/70 | 1.074 × 100 | 2.980 × 10−1 |
| 70/30 | 9.153 × 10−1 | 2.840 × 10−1 |
| Scenario NO Proportion | Rule-Interaction | Sig. | Unsig. |
|---|---|---|---|
| 7 | A10 = 2 ∧ E4 ≠ 3 ∧ E5 = 2 ∧ E6 ≠ 1 ∧ E23 = 1 | 100% | 10.49% |
| 8 | A10 = 1 ∧ A14 ≠ 1 ∧ A17 = 2 ∧ E7 = 1 ∧ E16 = 2 | 100% | 15.44% |
| 9 | A23 = 2 ∧ A26 = 1 ∧ E6 ≠ 1 ∧ E9 ≠ 1 ∧ E23 = 1 | 90.00% | 11.91% |
| 30/70 | A2 ≠ 3 ∧ A14 = 3 ∧ E3 = 1 ∧ E10 ≠ 1 ∧ E23 ≠ 3 | 97.06% | 29.98% |
| 70/30 | A3 = 1 ∧ E3 ≠ 3 ∧ E11 ≠ 2 ∧ E13 ≠ 1 ∧ E23 = 1 | 100% | 23.97% |
| Scenario NO Proportion | Rule-Interaction | Sig. | Unsig. |
|---|---|---|---|
| 7 | WS1 = 1 ∧ WS2 = 2 ∧ Bu1 < 7 ∧ Bu2 < 22 | 90.63% | 20.51% |
| 8 | WS3 = 3 ∧ WS1 ≠ 1 ∧ Bu1 < 17 ∧ Bu1 > 2 | 92.86% | 26.15% |
| 9 | WS2 = 3 ∧ WS3 = 4 ∧ Bu1 < 7 ∧ Bu2 < 34 | 100% | 24.80% |
| 30/70 | WS1 < 3 ∧ WS2 ≠ 1 ∧ Bu1 < 15 ∧ Bu2 > 2 | 94.12% | 71.01% |
| 70/30 | WS2 ≠ 1 ∧ WS3 > 2 ∧ Bu1 < 17 ∧ Bu2 < 25 | 100% | 83.81% |
| Scenario NO Proportion | Rule-Interaction | Sig. | Unsig. |
|---|---|---|---|
| 7 | A16 ≠ 1 ∧ A18 = 3 ∧ E5 ≠ 1 ∧ E19 ≠ 2 ∧ E21 = 2 | 92.86% | 16.48% |
| 8 | A5 ≠ 2 ∧ A11 = 2 ∧ A13 ≠ 2 ∧ A28 ≠ 2 ∧ E19 ≠ 2 | 90.48% | 23.00% |
| 9 | A4 = 3 ∧ A12 = 2 ∧ A18 ≠ 1 ∧ E4 ≠ 2 ∧ E19 ≠ 3 | 100% | 6.83% |
| 30/70 | A5 ≠ 3 ∧ E4 ≠ 3 ∧ E5 ≠ 1 ∧ E11 ≠ 2 ∧ E16 ≠ 1 | 96.00% | 15.57% |
| 70/30 | A13 ≠ 2 ∧ A16 = 2 ∧ A21 ≠ 1 ∧ A28 ≠ 1 ∧ E18 ≠ 1 | 91.30% | 29.21% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barrera-Diaz, C.A.; Nourmohammadi, A.; Smedberg, H.; Aslam, T.; Ng, A.H.C. An Enhanced Simulation-Based Multi-Objective Optimization Approach with Knowledge Discovery for Reconfigurable Manufacturing Systems. Mathematics 2023, 11, 1527. https://doi.org/10.3390/math11061527
Barrera-Diaz CA, Nourmohammadi A, Smedberg H, Aslam T, Ng AHC. An Enhanced Simulation-Based Multi-Objective Optimization Approach with Knowledge Discovery for Reconfigurable Manufacturing Systems. Mathematics. 2023; 11(6):1527. https://doi.org/10.3390/math11061527
Chicago/Turabian StyleBarrera-Diaz, Carlos Alberto, Amir Nourmohammadi, Henrik Smedberg, Tehseen Aslam, and Amos H. C. Ng. 2023. "An Enhanced Simulation-Based Multi-Objective Optimization Approach with Knowledge Discovery for Reconfigurable Manufacturing Systems" Mathematics 11, no. 6: 1527. https://doi.org/10.3390/math11061527
APA StyleBarrera-Diaz, C. A., Nourmohammadi, A., Smedberg, H., Aslam, T., & Ng, A. H. C. (2023). An Enhanced Simulation-Based Multi-Objective Optimization Approach with Knowledge Discovery for Reconfigurable Manufacturing Systems. Mathematics, 11(6), 1527. https://doi.org/10.3390/math11061527