

PGA: A New Hybrid PSO and GA Method for Task Scheduling with Deadline Constraints in Distributed Computing


Abstract
:1. Introduction
- We formulate the task scheduling problem with deadline constraints into a binary nonlinear programming model (BNLP) for distributed computing systems. There are two optimization objectives of BNLP. The major optimization objective is maximizing the number of tasks with deadline satisfaction, which is one of the metrics quantifying user satisfaction. The minor one is maximizing the overall resource utilization, which is a widely used quantitative metric for resource efficiency.
- We design a hybrid heuristic method for solving the task scheduling problem named PGA. In the PGA, each chromosome represents one solution mapping tasks onto computing units, and the fitness function is the objective of formulated BNLP. In the evolution process of the GA, the PGA adds two crossover operations to speed up the evolutionary rate, inspired by PSO, which crosses the current chromosome with its own historical best chromosome and the global best chromosome, respectively, for each individual.
- To evaluate the performance of the PGA, we conduct extensive simulated experiments, where the system parameters are set referring to related works. Experiment results confirm the performance superiority of the PGA in both user satisfaction and resource efficiency, compared with seven heuristic/meta-heuristic/hybrid heuristic task scheduling methods proposed recently.
2. Problem Formulation
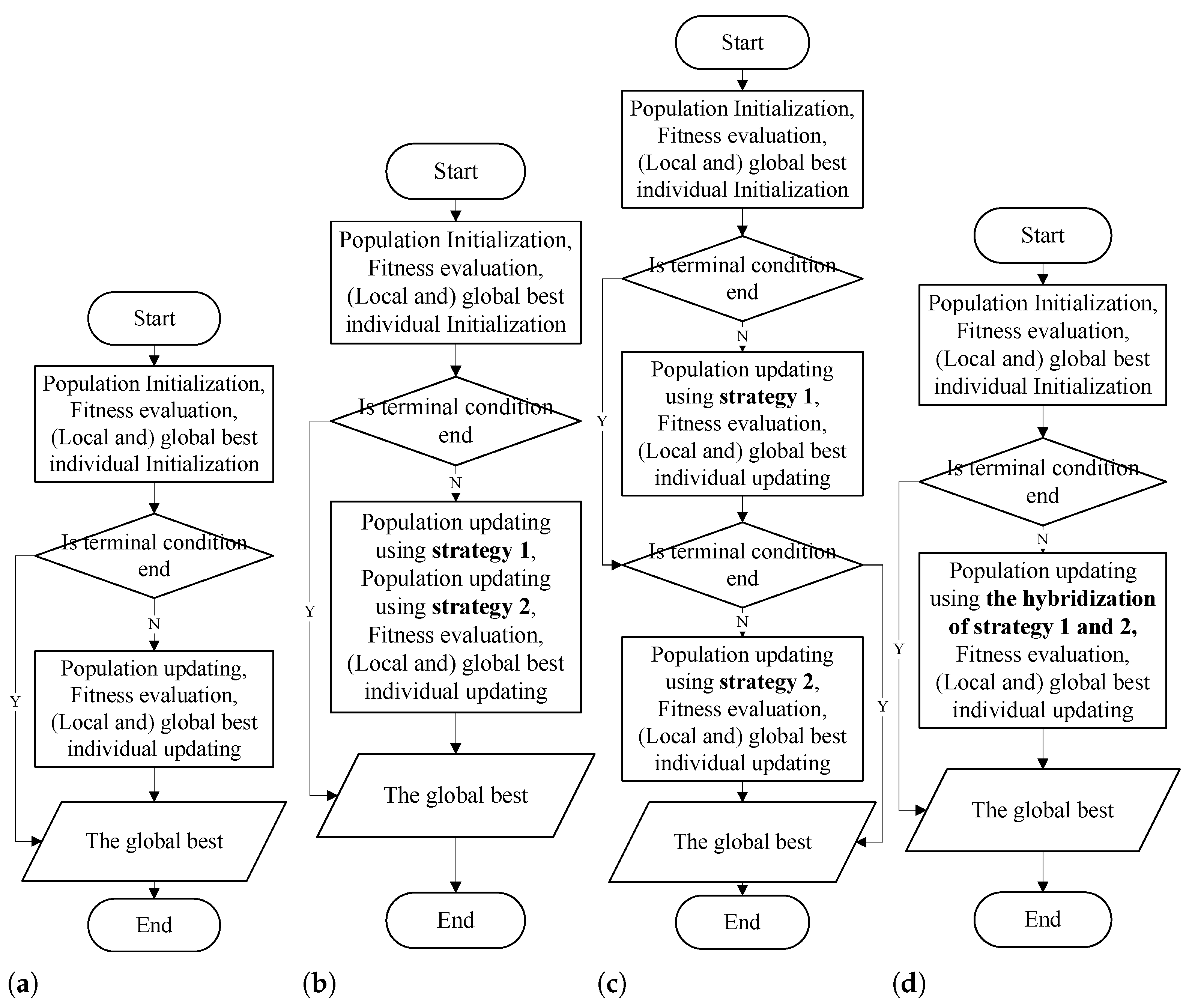
3. PGA: The Hybrid Heuristic Scheduling Method
| Algorithm 1 PGA: the hybrid heuristic scheduling method |
| Require: The information of tasks and computing servers, the parameters of GA; |
| Ensure: the solution of task scheduling; |
|
3.1. The Encoding or Decoding Method
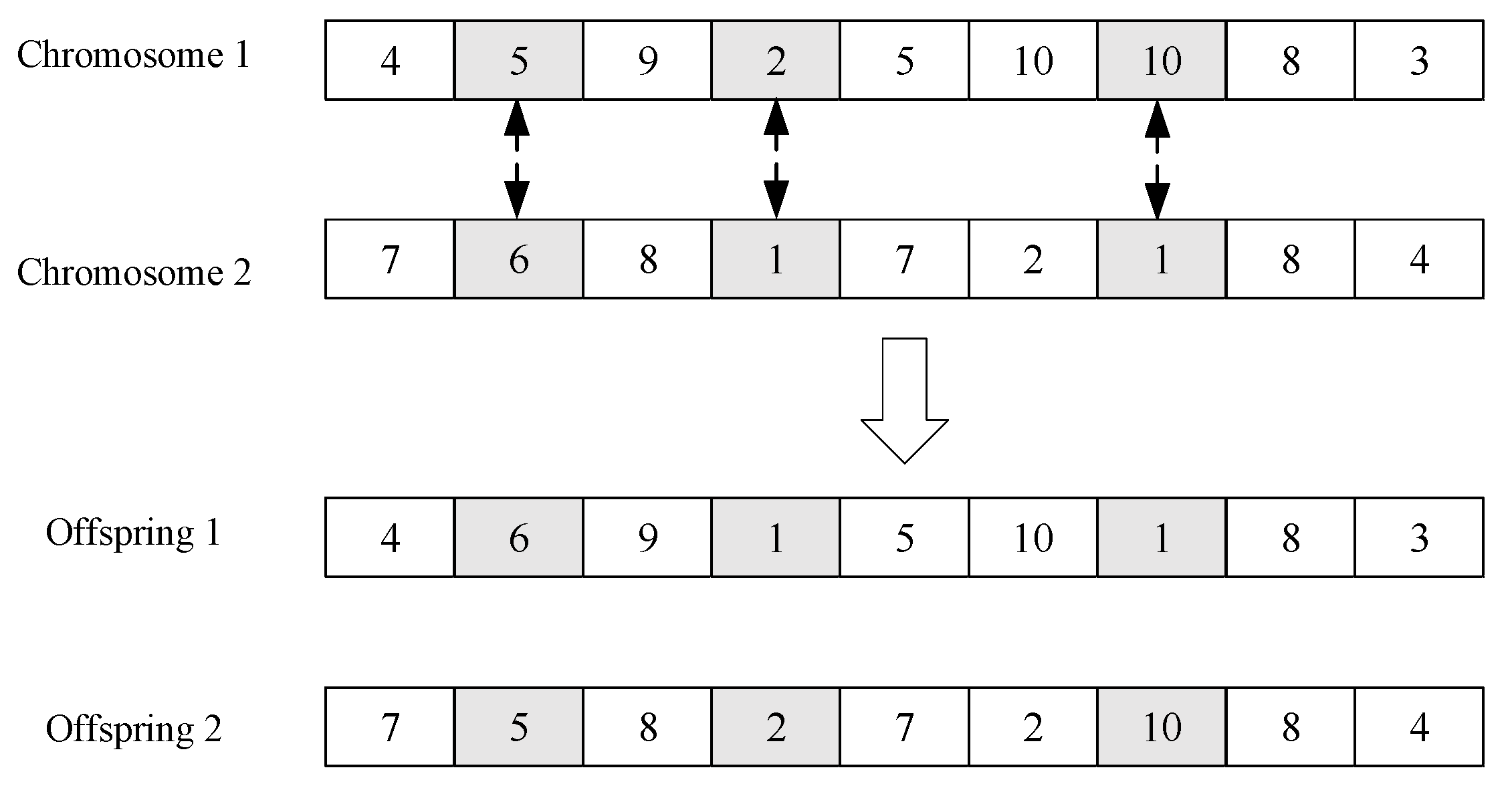
3.2. The Crossover Operator
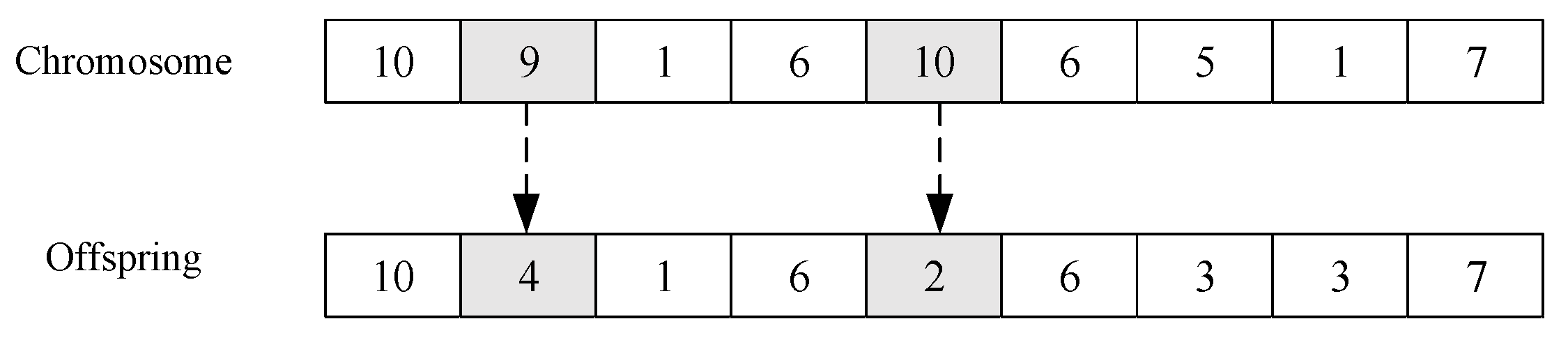
3.3. The Mutation Operator
3.4. The Selection Operator
3.5. Time Complexity Analysis
4. Performance Evaluation
4.1. Experiment Environment
- HC
- GA
- The basic idea of [26], which exploits the principle of a Genetic Algorithm (GA) for scheduling tasks.
- GAHC
- The method used by Hussain and Al-Turjman [20] uses the idea of HC to improve the quality of each chromosome at the beginning of each evolution for the GA. Instead of the selection operator of a GA, GAHC replaces the chromosome with its offspring with better fitness after each of the crossover and mutation operators.
- PSO
- Particle swarm optimization (PSO) is also one of the most popular approaches for the task scheduling problem, e.g., [27].
- PSO_M
- This is the work proposed by Hafsi et al. [28], which integrates the mutation operator into PSO. PSO_M adds the mutation operator for each particle at the end of each iteration of PSO.
- GA+PSO
- The method used in [29] exploits a GA and PSO in the first half and the second half of the evolution phase, respectively.
- GA_PSO
- The method proposed by Wang et al. [30] uses a GA and PSO in each iteration of the population evolution.
- User Satisfaction
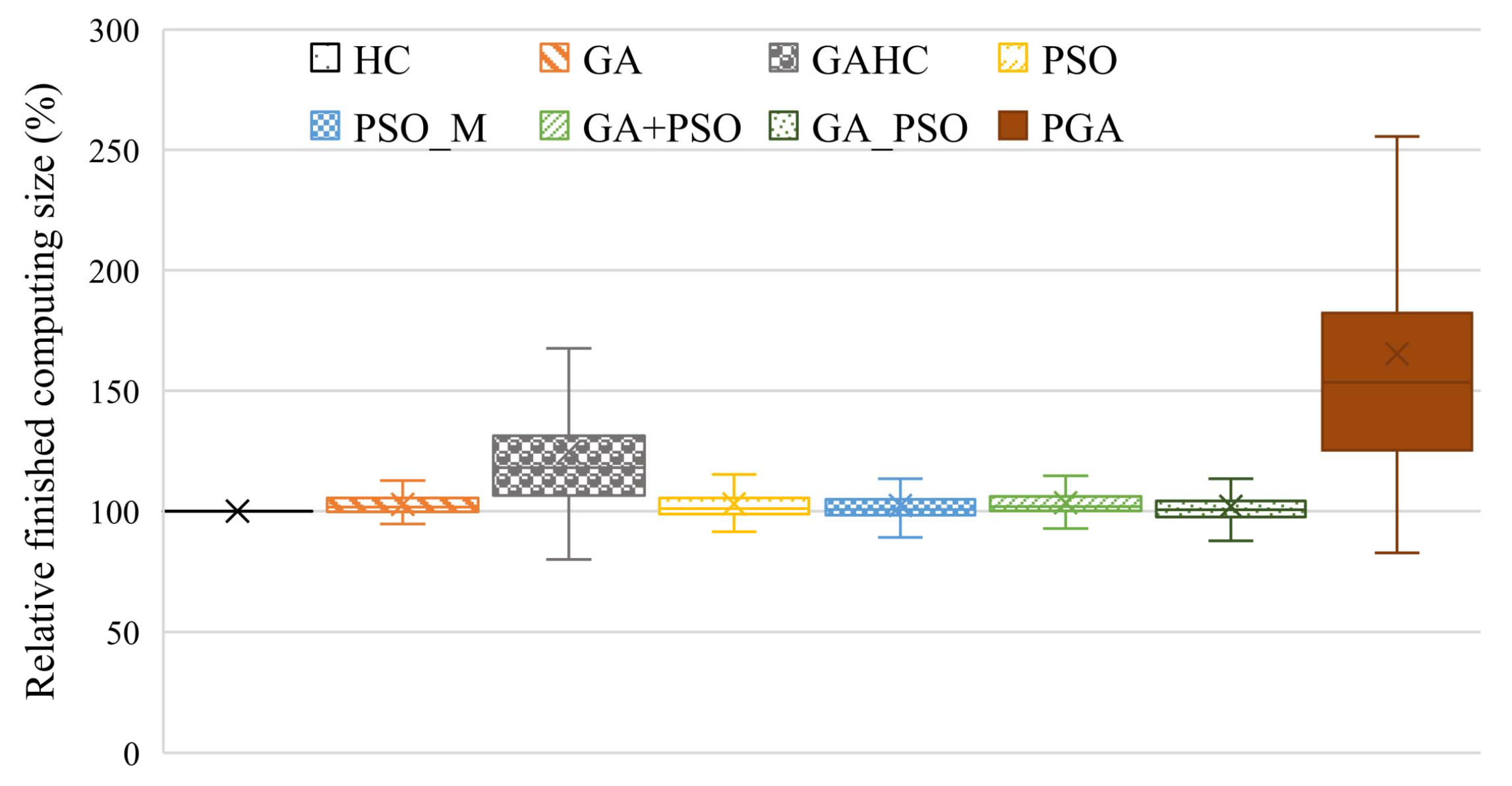
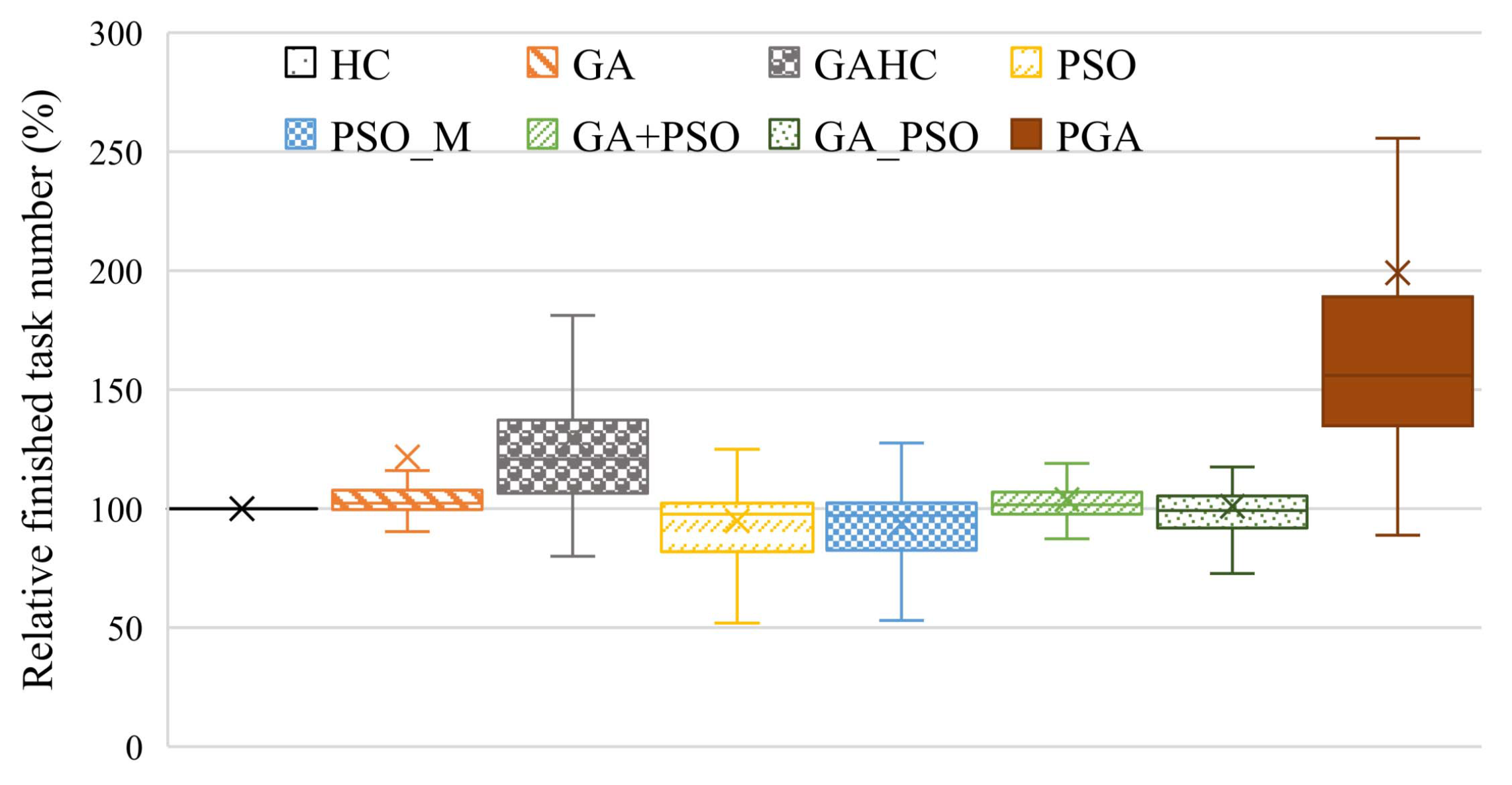
- The satisfaction strongly affects the income and reputation of operating a distributed system [31], which usually is quantified by the completion rates of tasks. In this paper, we use the following two metrics for the quantification of the satisfaction, the number (N) and the computing size () of tasks with deadlines met, where the computing size of a task is the number of computing resources required by the task.
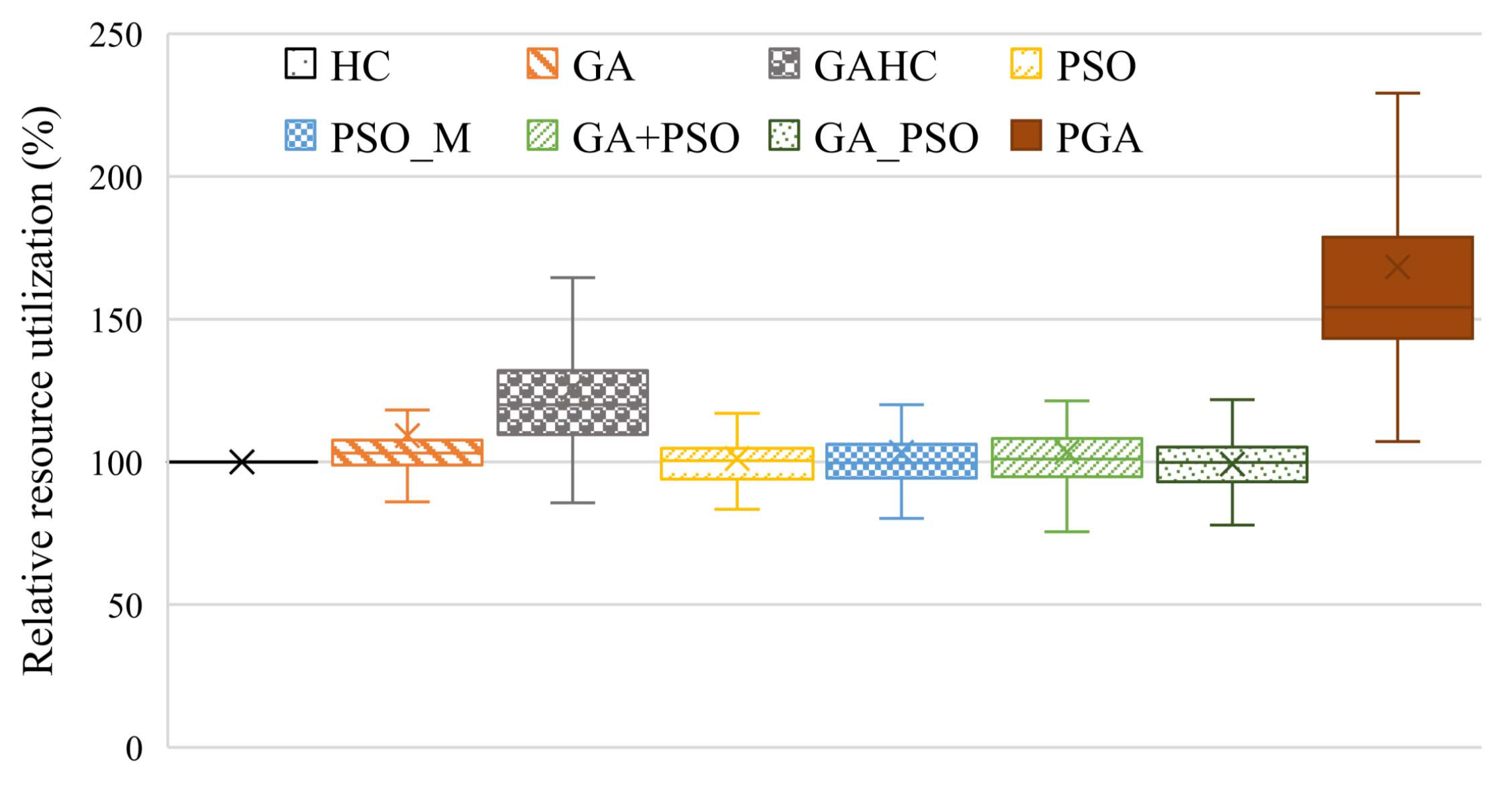
- Resource Efficiency
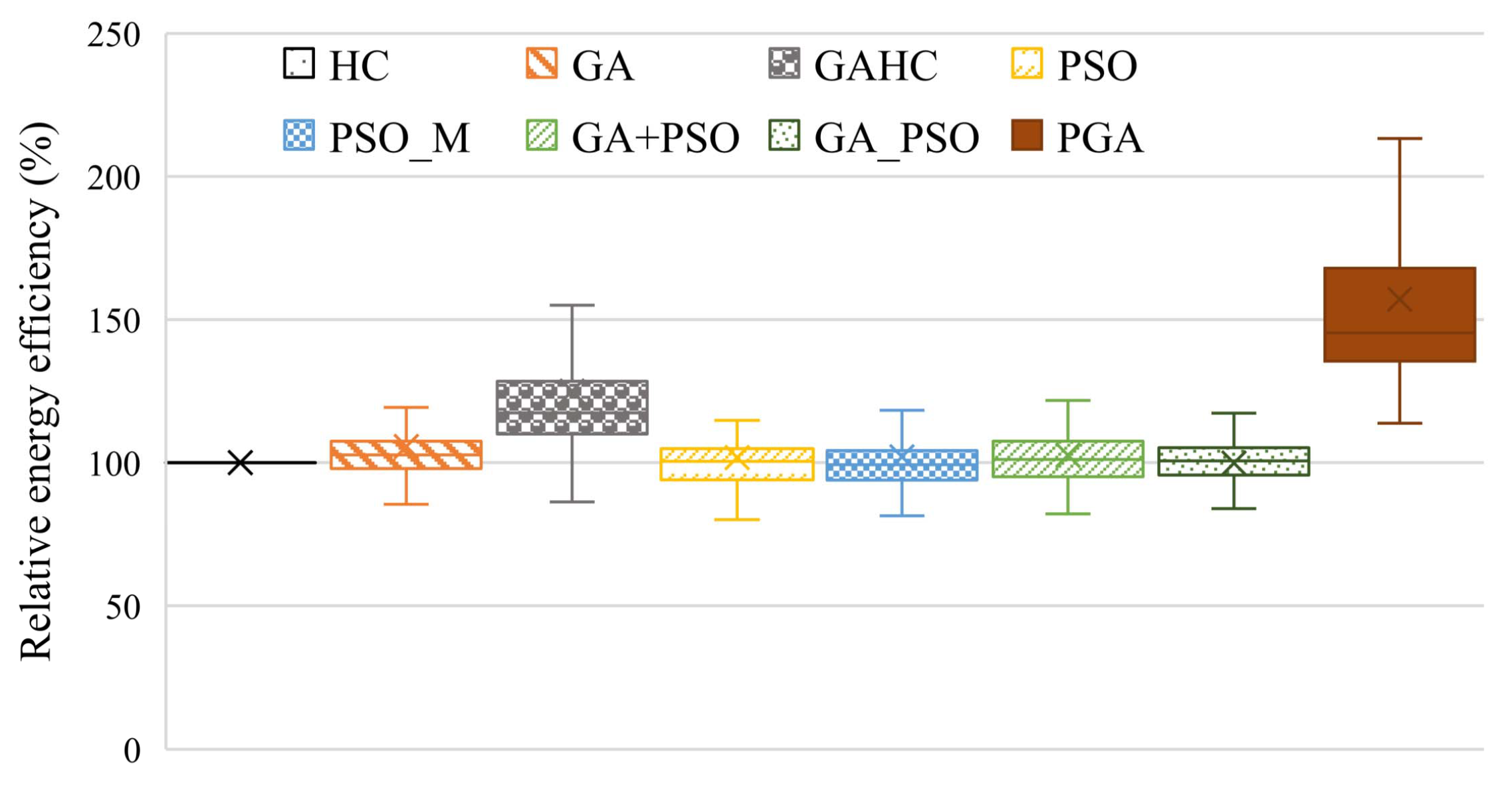
- In general, the task load finished by consuming per unit of resources can be applied to quantifying the resource efficiency in distributed systems. Two metrics are used in our experiments for evaluating the resource efficiency, which is the overall resource utilization (U) and energy efficiency (). Energy efficiency is the processed computing size per unit of energy, which is the ratio of processed computing size to the consumed energy.
- Processing Efficiency
- The processing efficiency can reflect the speed-up of the distributed processing system. In this paper, the processing efficiency is quantified by dividing the processed computing size by the makespan of processed tasks, i.e., the processing speed, which is calculated by .
4.2. Experiment Results
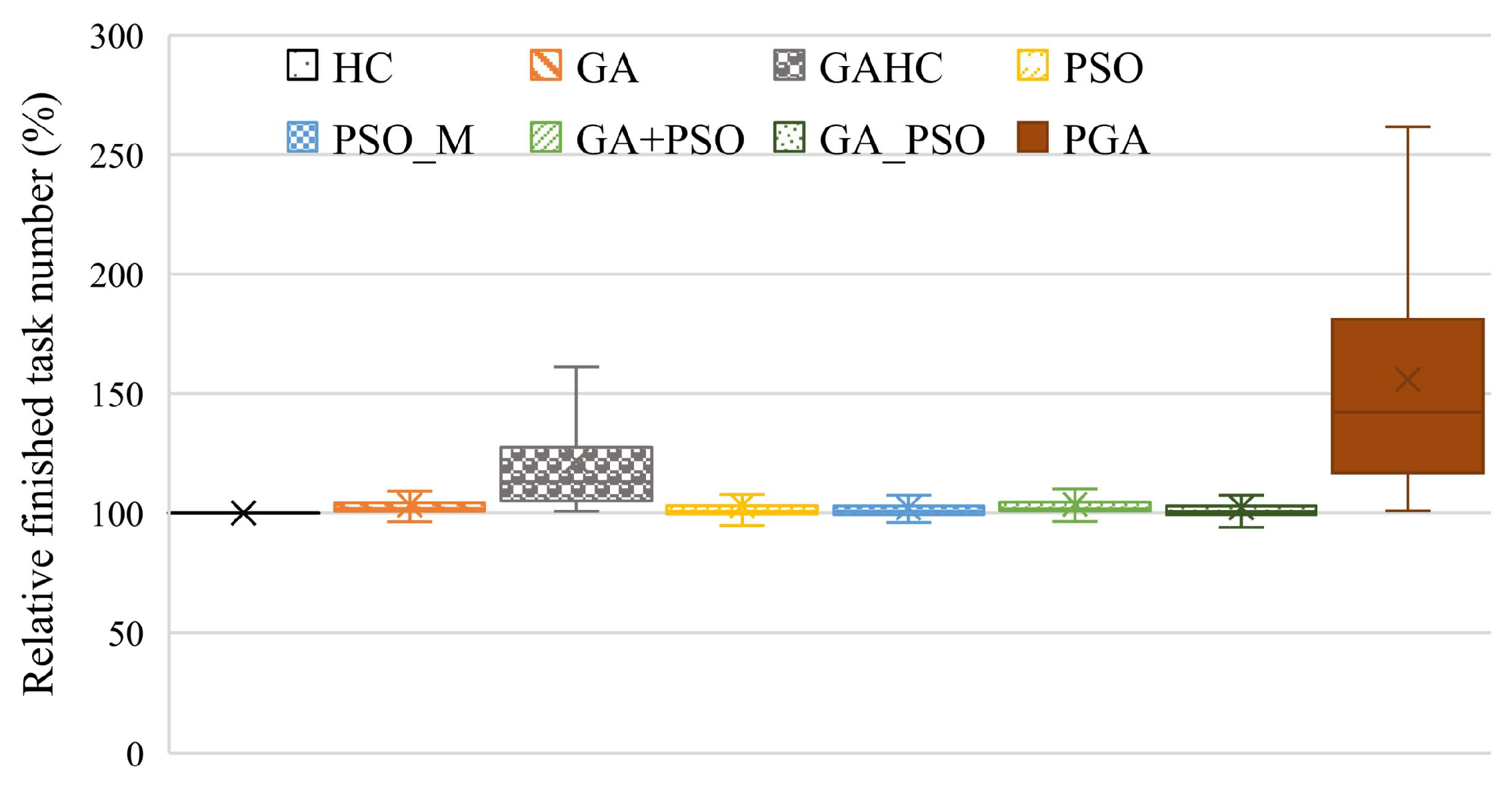
4.2.1. User Satisfaction
4.2.2. Resource Efficiency
4.2.3. Processing Efficiency
5. Related Works
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ACO | Ant Colony Optimization |
| BNLP | Binary non-linear programming |
| BoT | Bag-of-tasks |
| CSO | Cat Swarm Optimization |
| EFO | Electric Fish Optimization |
| EOA | Earthworm Optimization Algorithm |
| GA | Genetic algorithm |
| GAHC | GA with hill climbing |
| HC | Hill climbing |
| MINLP | Mixed-integer non-linear programming |
| MI | Million instructions |
| MIPS | Million instructions per second |
| OBL | Opposition-based learning |
| PGA | Hybrid GA and PSO |
| PSO | Particle swarm optimization |
| PSO_M | PSO with mutation operator |
| SSO | Simplified Swarm Optimization |
| WOA | Whale optimization algorithm |
References
- Jamil, B.; Ijaz, H.; Shojafar, M.; Munir, K.; Buyya, R. Resource Allocation and Task Scheduling in Fog Computing and Internet of Everything Environments: A Taxonomy, Review, and Future Directions. ACM Comput. Surv. 2022, 54, 1–38. [Google Scholar] [CrossRef]
- Dai, H.; Wu, J.; Wang, Y.; Xu, C. Towards scalable and efficient Deep-RL in edge computing: A game-based partition approach. J. Parallel Distrib. Comput. 2022, 168, 108–119. [Google Scholar] [CrossRef]
- Sang, Y.; Cheng, J.; Wang, B.; Chen, M. A three-stage heuristic task scheduling for optimizing the service level agreement satisfaction in device-edge-cloud cooperative computing. PeerJ Comput. Sci. 2022, 8, e851. [Google Scholar] [CrossRef]
- Peng, J.; Li, K.; Chen, J.; Li, K. HEA-PAS: A hybrid energy allocation strategy for parallel applications scheduling on heterogeneous computing systems. J. Syst. Archit. 2022, 122, 102329. [Google Scholar] [CrossRef]
- Ghafari, R.; Kabutarkhani, F.H.; Mansouri, N. Task scheduling algorithms for energy optimization in cloud environment: A comprehensive review. Clust. Comput. 2022, 25, 1035–1093. [Google Scholar] [CrossRef]
- Du, J.; Leung, J.Y.T. Complexity of Scheduling Parallel Task Systems. SIAM J. Discret. Math. 1989, 2, 473–487. [Google Scholar] [CrossRef]
- Martí, R.; Reinelt, G. Heuristic Methods. In Exact and Heuristic Methods in Combinatorial Optimization: A Study on the Linear Ordering and the Maximum Diversity Problem; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar] [CrossRef]
- Durasević, M.; Jakobović, D. Heuristic and metaheuristic methods for the parallel unrelated machines scheduling problem: A survey. Artif. Intell. Rev. 2022, 56, 3181–3289. [Google Scholar] [CrossRef]
- Vinod Chandra, S.S.; Anand, H.S. Nature inspired meta heuristic algorithms for optimization problems. Computing 2022, 104, 251–269. [Google Scholar] [CrossRef]
- Abualigah, L.; Elaziz, M.A.; Khasawneh, A.M.; Alshinwan, M.; Ibrahim, R.A.; Al-Qaness, M.A.A.; Mirjalili, S.; Sumari, P.; Gandomi, A.H. Meta-heuristic optimization algorithms for solving real-world mechanical engineering design problems: A comprehensive survey, applications, comparative analysis, and results. Neural Comput. Appl. 2022, 34, 4081–4110. [Google Scholar] [CrossRef]
- Abo-Alsabeh, R.R.; Salhi, A. The Genetic Algorithm: A study survey. Iraqi J. Sci. 2022, 63, 1215–1231. [Google Scholar] [CrossRef]
- Shami, T.M.; El-Saleh, A.A.; Alswaitti, M.; Al-Tashi, Q.; Summakieh, M.A.; Mirjalili, S. Particle Swarm Optimization: A Comprehensive Survey. IEEE Access 2022, 10, 10031–10061. [Google Scholar] [CrossRef]
- Abohamama, A.S.; El-Ghamry, A.; Hamouda, E. Real-Time Task Scheduling Algorithm for IoT-Based Applications in the Cloud–Fog Environment. J. Netw. Syst. Manag. 2022, 30, 54. [Google Scholar] [CrossRef]
- Pinedo, M.L. Scheduling: Theory, Algorithms, and Systems; Springer: Berlin/Heidelberg, Germany, 2016; Chapter 2; pp. 13–32. [Google Scholar]
- lpsolve: Mixed Integer Linear Programming (MILP) Solver. 2021. Available online: https://sourceforge.net/projects/lpsolve/ (accessed on 20 March 2023).
- MathWorks, I. Optimization Toolbox: Solve Linear, Quadratic, Conic, Integer, and Nonlinear Optimization Problems. 2022. Available online: https://ww2.mathworks.cn/en/products/optimization.html (accessed on 20 March 2023).
- Jong, K.A.D.; Spears, W.M. A formal analysis of the role of multi-point crossover in genetic algorithms. Ann. Math. Artif. Intell. 1992, 5, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Nabi, S.; Ahmed, M. OG-RADL: Overall performance-based resource-aware dynamic load-balancer for deadline constrained Cloud tasks. J. Supercomput. 2021, 77, 7476–7508. [Google Scholar] [CrossRef]
- Nabi, S.; Ahmed, M. PSO-RDAL: Particle swarm optimization-based resource- and deadline-aware dynamic load balancer for deadline constrained cloud tasks. J. Supercomput. 2022, 78, 4624–4654. [Google Scholar] [CrossRef]
- Hussain, A.A.; Al-Turjman, F. Hybrid Genetic Algorithm for IOMT-Cloud Task Scheduling. Wirel. Commun. Mob. Comput. 2022, 2022, 6604286. [Google Scholar] [CrossRef]
- Barroso, L.A.; Hölzle, U. The Case for Energy-Proportional Computing. Computer 2007, 40, 33–37. [Google Scholar] [CrossRef]
- Baliga, J.; Ayre, R.W.A.; Hinton, K.; Tucker, R.S. Green Cloud Computing: Balancing Energy in Processing, Storage, and Transport. Proc. IEEE 2011, 99, 149–167. [Google Scholar] [CrossRef]
- Tian, W.; He, M.; Guo, W.; Huang, W.; Shi, X.; Shang, M.; Toosi, A.N.; Buyya, R. On minimizing total energy consumption in the scheduling of virtual machine reservations. J. Netw. Comput. Appl. 2018, 113, 64–74. [Google Scholar] [CrossRef]
- Aghdashi, A.; Mirtaheri, S.L. Novel dynamic load balancing algorithm for cloud-based big data analytics. J. Supercomput. 2022, 78, 4131–4156. [Google Scholar] [CrossRef]
- Athmani, M.E.; Arbaoui, T.; Mimene, Y.; Yalaoui, F. Efficient Heuristics and Metaheuristics for the Unrelated Parallel Machine Scheduling Problem with Release Dates and Setup Times. In Proceedings of the Genetic and Evolutionary Computation Conference (GECCO’22), New York, NY, USA, 9–13 July 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 177–185. [Google Scholar] [CrossRef]
- Pradhan, R.; Satapathy, S.C. Energy Aware Genetic Algorithm for Independent Task Scheduling in Heterogeneous Multi-Cloud Environment. J. Sci. Ind. Res. 2022, 81, 776–784. [Google Scholar] [CrossRef]
- Teraiya, J.; Shah, A. Optimized scheduling algorithm for soft Real-Time System using particle swarm optimization technique. Evol. Intell. 2022, 15, 1935–1945. [Google Scholar] [CrossRef]
- Hafsi, H.; Gharsellaoui, H.; Bouamama, S. Genetically-modified Multi-objective Particle Swarm Optimization approach for high-performance computing workflow scheduling. Appl. Soft Comput. 2022, 122, 108791. [Google Scholar] [CrossRef]
- Nwogbaga, N.E.; Latip, R.; Affendey, L.S.; Rahiman, A.R.A. Attribute reduction based scheduling algorithm with enhanced hybrid genetic algorithm and particle swarm optimization for optimal device selection. J. Cloud Comput. 2022, 11, 15. [Google Scholar] [CrossRef]
- Wang, B.; Wu, P.; Arefzaeh, M. A new method for task scheduling in fog-based medical healthcare systems using a hybrid nature-inspired algorithm. Concurr. Comput. Pract. Exp. 2022, 34, e7155. [Google Scholar] [CrossRef]
- Wang, B.; Cheng, J.; Cao, J.; Wang, C.; Huang, W. Integer particle swarm optimization based task scheduling for device-edge-cloud cooperative computing to improve SLA satisfaction. PeerJ Comput. Sci. 2022, 8, e893. [Google Scholar] [CrossRef]
- Wang, B.; Wang, C.; Huang, W.; Song, Y.; Qin, X. Security-aware task scheduling with deadline constraints on heterogeneous hybrid clouds. J. Parallel Distrib. Comput. 2021, 153, 15–28. [Google Scholar] [CrossRef]
- Ma, Z.; Zhang, S.; Chen, Z.; Han, T.; Qian, Z.; Xiao, M.; Chen, N.; Wu, J.; Lu, S. Towards Revenue-Driven Multi-User Online Task Offloading in Edge Computing. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 1185–1198. [Google Scholar] [CrossRef]
- Mangalampalli, S.; Swain, S.K.; Mangalampalli, V.K. Multi Objective Task Scheduling in Cloud Computing Using Cat Swarm Optimization Algorithm. Arab. J. Sci. Eng. 2022, 47, 1821–1830. [Google Scholar] [CrossRef]
- Otair, M.; Alhmoud, A.; Jia, H.; Altalhi, M.; Hussein, A.M.; Abualigah, L. Optimized task scheduling in cloud computing using improved multi-verse optimizer. Clust. Comput. 2022, 25, 4221–4232. [Google Scholar] [CrossRef]
- Chandrashekar, C.; Krishnadoss, P.; Kedalu Poornachary, V.; Ananthakrishnan, B.; Rangasamy, K. HWACOA Scheduler: Hybrid Weighted Ant Colony Optimization Algorithm for Task Scheduling in Cloud Computing. Appl. Sci. 2023, 13, 3433. [Google Scholar] [CrossRef]
- Yeh, W.C.; Zhu, W.; Yin, Y.; Huang, C.L. Cloud Computing Considering Both Energy and Time Solved by Two-Objective Simplified Swarm Optimization. Appl. Sci. 2023, 13, 2077. [Google Scholar] [CrossRef]
- Sharma, O.; Rathee, G.; Kerrache, C.A.; Herrera-Tapia, J. Two-Stage Optimal Task Scheduling for Smart Home Environment Using Fog Computing Infrastructures. Appl. Sci. 2023, 13, 2939. [Google Scholar] [CrossRef]
- Kumar, M.S.; Karri, G.R. EEOA: Cost and Energy Efficient Task Scheduling in a Cloud-Fog Framework. Sensors 2023, 23, 2445. [Google Scholar] [CrossRef]
- Cheikh, S.; Walker, J.J. Solving Task Scheduling Problem in the Cloud Using a Hybrid Particle Swarm Optimization Approach. Int. J. Appl. Metaheuristic Comput. 2022, 13, 1–25. [Google Scholar] [CrossRef]
- Chhabra, A.; Huang, K.; Bacanin, N.; Rashid, T.A. Optimizing bag-of-tasks scheduling on cloud data centers using hybrid swarm-intelligence meta-heuristic. J. Supercomput. 2022, 78, 9121–9183. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| T | The number of tasks |
| The ith task | |
| The computing resource amount required by | |
| The deadline required by | |
| The finish time of | |
| S | The number of computing servers |
| The jth server | |
| The number of cores equipped in | |
| The computing capacity of each core in | |
| The occupied time of for task executions | |
| The use time of kth core in | |
| The resource utilization of | |
| U | The overall resource utilization of the system |
| N | The number of tasks with deadline satisfactions |
| Parameter | Value |
|---|---|
| server number | 50 |
| core number of each server | [2, 64] |
| computing capacity of each core | [1000, 4000] MIPS |
| computing resource requirement of each task | [1000, 100,000] MI |
| deadline of each task | [1, 100] seconds |
| mutation probability | 0.1 |
| crossover probability | 0.5 |
| acceleration coefficients of PSO | 2.0 |
| (linearly decreased) inertia weight of PSO | [0.5, 1.2] |
| The Core Number | ||
|---|---|---|
| 110 | 175 | |
| 125 | 210 | |
| 210 | 300 | |
| 350 | 500 |
| Works | Used Algorithm | Hybrid |
|---|---|---|
| Wang et al. [32] | designed heuristic | no |
| Ma et al. [33] | designed heuristic | no |
| Mangalampalli et al. [34] | CSO | no |
| Otair et al. [35] | designed population optimization | no |
| Teraiya and Shah [27] | PSO | no |
| Chandrashekar et al. [36] | ACO | no |
| Yeh et al. [37] | SSO | no |
| Nwogbaga et al. [29] | GA and PSO | H2 |
| Sharma et al. [38] | PSO and ACO | H2 |
| Wang et al. [30] | GA and PSO | H1 |
| Kumar and Karri [39] | EOA and EFO | H1 |
| Cheikh and Bougara [40] | PSO and extremal optimization | H2 |
| Hussain and Al-Turjman [20] | GA and HC | H1 |
| Hafsi et al. [28] | PSO and the mutation operator of GA | H1 |
| Chhabra et al. [41] | OBL, PSO, and WOA | H1 + H2 |
| Ours | GA and PSO | H3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, K.; Song, Y.; Wang, B. PGA: A New Hybrid PSO and GA Method for Task Scheduling with Deadline Constraints in Distributed Computing. Mathematics 2023, 11, 1548. https://doi.org/10.3390/math11061548
Shao K, Song Y, Wang B. PGA: A New Hybrid PSO and GA Method for Task Scheduling with Deadline Constraints in Distributed Computing. Mathematics. 2023; 11(6):1548. https://doi.org/10.3390/math11061548
Chicago/Turabian StyleShao, Kaili, Ying Song, and Bo Wang. 2023. "PGA: A New Hybrid PSO and GA Method for Task Scheduling with Deadline Constraints in Distributed Computing" Mathematics 11, no. 6: 1548. https://doi.org/10.3390/math11061548
APA StyleShao, K., Song, Y., & Wang, B. (2023). PGA: A New Hybrid PSO and GA Method for Task Scheduling with Deadline Constraints in Distributed Computing. Mathematics, 11(6), 1548. https://doi.org/10.3390/math11061548