1. Introduction
Multi-attribute decision making (MADM) [
1,
2] is sub branch of The Artificial Intelligent (AI) and is essential in current AI-decision making. Due to the ambiguity of the criteria, the convolution of the actual environment, and the discrete subjectivity, the decision makers (DMs) are frequently needed to offer estimation information with reference to a variety of criteria values.
1.1. A Brief Review on the Development of Fuzzy Sets
The concept of fuzzy sets (FSs) was put out by L.A. Zadeh in 1965 [
3]. It has been studied thoroughly by many experts. Another mathematician, Atanassov [
4,
5], modified FSs by adding the non-membership degree then introducing intuitionistic fuzzy sets (IFSs) in 1983. While fuzzy sets and intuitionistic fuzzy sets have gained popularity, people are more used to communicating their estimation information using linguistic term sets (LTSs) in reality. LTSs are capable of dealing with tough scenarios. Zadeh [
6] presented the framework for word-based computation (CW) and elaborated on several momentous LTS extension forms [
7,
8,
9] which have been developed and investigated. Regarding deep modelling of expert expressions, Gou et al. [
10,
11] presented the double hierarchy linguistic term sets (DHLTSs). The majority of DMs find it challenging to provide an accurate estimate of the attributes of projects during the project investment phase. Furthermore, for the majority of DMs, using qualitative estimates to project traits is more appropriate and pleasant. DHLTSs communicate complex linguistic expressions and can better convey qualitative information than the single linguistic term set does [
12]. When DMs estimate the project’s attribute information, they can provide the estimated value more quickly, which cuts down on the amount of time it takes to gather estimates. First and second hierarchy hesitant linguistic terms (DHHLTS), which may represent doubt and murkiness more freely, make up the system. For the double hierarchy of hesitant linguistic term (DHHLTE) components, we develop the score function and distance measure regarding the development of DHHLEs’ core function. Narukawa [
13] and Torra [
14] introduce the idea of hesitant fuzzy sets (HFSs) to manage these situations. With HFSs, a collection of attainable values may be used to control the degree to which an element is a member of a set. Researchers’ focus on hesitant fuzzy aggregations operators has recently increased. Recently, Zhu et al. [
15] maintains that dual hesitant fuzzy sets (DHFSs) are comprised of two functions: the membership function and the non-membership function. They have studied some of DHFSs’ essential features and functions.
1.2. A Brief Review on the Aggregation Operators
Wang et al. [
16] advanced aggregation operators according to dual hesitant fuzzy elements (DHFEs), including dual hesitant fuzzy weighted averaging (DHFWA), dual hesitant fuzzy ordered weighted geometrics (DHFOWG), dual hesitant fuzzy weighted geometrics (DHFWG), and then examined some pros and cons. Some aggregation operations using interval-valued dual hesitant fuzzy information were proposed by Ju et al. [
17]. There is a possibility that the aforementioned aggregate operators, which are not the only options for simulating the intersection and union of IVDHFEs, are all chosen according to the fundamental algebraic sum and algebraic product. Both the algebraic sum and algebraic product are suitable replacements for the Einstein operations, which include the Einstein product and sum. Additionally, it suggests that there is research being done on aggregation methods that combine a group of IFVs utilizing Einstein operations on HFSs or IFSs. In order to solve MADM difficulties, Zhao and Wei [
18] implemented the geometric operator and intuitionistic fuzzy Einstein hybrid averaging (IFEHA) operator. Wang and Liu [
19,
20] improved various geometric and arithmetic aggregation algorithms by combining intuitionistic fuzzy data with Einstein operations. Additionally, the Einstein operators were examined by Wang and Liu [
21,
22] in interval-valued intuitionistic fuzzy settings. In order to solve MADM difficulties, Zhang and Yu [
23] advanced various geometric Choquet aggregation operators. Einstein operations were used by Zhao et al. [
24] to progress a reluctant fuzzy correlated aggregation operator. Einstein operational laws have also been introduced for fuzzy soft Pythagorean numbers [
25] (PFSNs).
1.3. A Review on the New Version of Fuzzy Logic Systems
As fuzzy logic studies develop, we can anticipate more developments that will enhance the functionality and usefulness of fuzzy logic systems. Another variation of fuzzy logic systems called type-3 fuzzy logic systems [
26] has been put forth to deal with even more complicated ambiguity than type-2 fuzzy logic systems. The membership function, degree of membership, and even the values of the membership function themselves are unclear in type-3 fuzzy logic systems. Type-3 fuzzy logic systems can manage more complicated and unclear data than type-2 fuzzy logic systems due to the additional degree of ambiguity.
1.4. A Review on the Three-Way Decisions
To address MADM issues involving hesitant interval-valued fuzzy information, Wei and Zhao [
27] advanced several induced hesitant interval-valued fuzzy Einstein aggregation operations. According to the Einstein operations, Zhao et al. [
24] identified numerous hesitant triangular fuzzy aggregation operators. Conventional MADM decisions only allow for scheme ranking; they do not enable decision makers to categorize schemes. The three-way decision [
28,
29] (TWDs) technique overcomes this restriction since it is consistent with how individuals normally organize their thoughts. Ever since Yao’s suggestion, TWDs have only been used in decision theory study [
30,
31,
32]. By applying the Bayesian procedure, it is likely that the elements are split into three distinct areas [
33,
34]. It is intended for DMs to accept, reject, or postpone making a judgement when an element is separated into a positive, negative, or boundary region, respectively. TWDs work in conjunction with human decision-making processes; it has been used in many domains, such as medical care [
35,
36], business decisions [
37], and employment resumes [
38]. There are many dispersed types of fuzzy sets, such as [
39] the triangular fuzzy number [
40] and dual hesitant fuzzy set. Liang et al. [
41,
42] have used the procedure of TWDs to more accurately deliberate loss functions (LFs) in the model. DHLTSs provide a new technique for conveying estimate information in TWDs. When DMs estimate the project’s criteria information, they can commit the estimated value by DHLTSs, which saves time. DMs must make choices quickly. DHLTSs allow DMs to make more efficient judgments, proving that they are acceptable and efficient tools for DMs. Jia et al. [
43] developed unique LF calculation techniques based on a multi-criteria environment. Nonetheless, DMs often estimate loss functions in practice depending on what they know and have done in the past, and this work uses this strategy to conduct research. Many academics have examined the calculation of conditional probability as another important aspect of TWDs. The entropy measure method was used to compute the criterion weights, and then weighted aggregation was used to compute the conditional probability. Liang et al. [
44], using the maximizing deviation technique, first computed the criterion weights [
45]. Then, they used the grey relational analysis (GRA) method to compute the conditional probability [
46]. Using third-generation prospect theory to calculate the conditional probability, Wang et al. [
47] modified two MADM approaches. We develop the double hierarchy linguistic decision-theoretic rough set (DHLDTRS) model in response to Lin et al. [
48], and we compute the conditional probability by using the TOPSIS method. In turn, states A and Ac of the TWDs correlate to the relative positive ideal solution (RPIS) and the relative negative ideal solution (RNIS), respectively.
1.5. A Review on the TOPSIS Method
The TOPSIS method [
49,
50] is a popular MCDM method that can handle both quantitative and qualitative data and is reasonably easy to use. It is frequently applied to issues where there are few options or requirements. Additionally, popular MCDM techniques that can manage both numeric and qualitative data are the WSM [
51] and WPM [
52] methods, respectively. These techniques are frequently employed for issues where the parameters are distinct from one another. A comparatively novel MCDM technique called PROMETHEE [
53] uses all potential paired scores to create a comprehensive evaluation of all options. This is helpful for issues where there are few options or requirements. A decision could be made using both positive and negative criteria. The decision matrix can have as many criteria as you desire, resulting in an easy and effective technique for assessing many choices and factors. With easy translation from emotional to quantifiable criteria, the result is quantifiable, and a number rating of the different options is given. Distances can be used with this approach. The choice with the lowest distance from the best option and the largest distance from the worst option is selected by TOPSIS.
1.6. Motivation of the Study
It can be concluded from the research analysis above that there has been no in-depth use of the reluctant double hierarchy hesitant linguistic term set or the Einstein aggregation operators for DHHLTSs.
- a.
Extending the Einstein operations to aggregate double hierarchy hesitation fuzzy information.
- b.
Artificial intelligence based three-way decision-making problem with double hierarchy hesitant linguistic terms estimate information.
- c.
Develop artificial intelligence based three-way decision making for S-box analysis in image encryption [
54,
55].
- d.
There are many methods in Artificial intelligence by which to find unknown experts and criteria weights to obtain unknown expert weights. When criterion are found, we must employ entropy methods.
- e.
Using the popular technique for multi-criteria decision making is the TOPSIS technique. Based on a collection of parameters, the TOPSIS technique is used to select the best S-box for image encryption.
1.7. Contribution of the Study
In the above analysis, there are no details about the double hierarchy hesitant linguistic term and the Einstein aggregation operations for the double hierarchy hesitant linguistic term; the main objectives of this article are listed below:
- a.
Establish the basic concepts of DHHLTSs and introduce the Einstein operational rules of DHHLEs.
- b.
Develop the score function, Einstein operational laws and Einstein aggregation operators for the double hierarchy hesitant linguistic term.
- c.
Discuss the TOPSIS method for calculating conditional probability and a novel DHHLDTRS model using Einstein aggregation operations and their further expected losses and score functions.
- d.
Develop the TWDs for the double hierarchy hesitant linguistic term.
- e.
Use the process of TWDs for the s-box analysis for image encryption.
2. Preliminaries
The preliminaries section provides basic terminology and concepts for the remaining paper. This section will cover fundamental concepts of DHLTSs. First, we will define the DHLTS and their properties.
Double Hierarchy Hesitant Linguistic Term Sets
In this subsection, first we define DHLTSs
Consider a DHHLTS P defined [
13,
14] by
where the first hierarchy hesitant linguistic term (FHHLT) is
with
and
as the lower bounds and the upper bounds of the term set, respectively, the second hierarchy hesitant linguistic term (SHHLT) is
with
and
as the lower and upper bound of the term set, respectively, and k = 1, 2, 3,…,#P is the number of elements in P.
Consider
as a continuous DHHLTS. Between the numerical value and the subscript,
, there are two transformed functions.
and
of the DHHLT
are given as follows;
where
denote the integer component of the number
According to (2) and (3) the transformed functions
and
between the DHHLT
and the numerical value
can be created as follow;
3. The Einstein Operation Law of DHHLTs
Let us consider two DHHLTSs: and The Einstein operation for these two DHHLTS can be defined as follows:
- (i)
- (ii)
- (iii)
- (iv)
The score function for DHHLE can be defined as DHHLE
. Then, the score function is denoted by
where the score function of
.
If the score function values are same for two DHHLE, then the defined accuracy function can be defined as and for the two DHHLTSs. Then,
- (1)
If , then
- (2)
If , then
- (3)
If , then
Consider that
is a collection of DHHLEs and
is the associated weight vector. Then, the DHHLEWA can be defines as follows:
Consider that
is a collection of DHHLEs and
is an aggregation associated weight vector. The DHHLEWG can be defined as follows:
Let us consider
as a collection of DHHLEs,
as the largest of them, and
as the aggregation associated weight vector with
. Then, the DHHLEOWA can be defined as follows:
Consider that
is a collection of DHHLEs,
is the largest of them,
is the weight vector for the aggregate associated with
and
. Then, the DHHLEOWG can be defined as follows:
Consider that is a collection of DHHLEs, is the largest of them, is the weight vector for the aggregate associated with , and t is the balancing coefficient. The double hierarchy hesitant hybrid aggregation operators can be defined as follows:
The DHHLHA operator can be defined as follows:
The DHHLHG can be defined as follows:
Theorem 1. The DHHLEWA operations according to the above operational laws;
then the DHHLEWA can be defined as follows: Proof. Using mathematical induction.
This is the complete proof. □
Specifically, if
then the DHHEWA becomes
Theorem 2 . Consider is a set of DHHLEs with the following properties:
Idempotency: if = P, Then DHHEWA
Proof. We are to prove that = P, so let , if k = 1
Then DHHLEWA
Boundedness: Consider if is DHHLE, then
DHHEWA . □
Proof. Consider
,
; if
, then
is a decreasing function. Since
, then
, then
Consider that
is the weight vector of
, so we have
This is the complete proof. □
Let us consider that and are three DHHLTSs. Then:
- (i)
- (ii)
- (iii)
- (iv)
4. TOPSIS Method for Calculating Conditional Probability
The TWDs consist of two components: LFs and conditional probability. First, we defined the DHHLT information system for conditional probability computation. Consider that
is a conditional criteria set of the DHHLT information system.
, where
denotes a domain of criteria, and
is a set of feasible elements. Then,
represents a function in such a way that
is with each,
,
. The estimation of the elements
with
is expressed by
Assuming that the DM provided a complimentary decision matrix for each criteria,
where
is the degree to which the criteria
is preferred over the criteria
, represented as a DHHLT and
. The weight vector
can be computed by using the following formula:
Now we use Equation (14) to calculate the entropy of decision matrices:
Now we use this equation to calculate the weight of each decision maker:
Next, we find the DHHLT information system’s RPIS (
and RNIS
,
The RPIS
and the grey relational coefficient (GRC) between
,
The RNIS
and the grey relational coefficient (GRC) between
,
The relative relational degree (RRG)
can be calculated as:
Here, we considered RRD as equal to the conditional probability.
where,
,
represents the RRD of project
.
5. A Novel DHHLDTRS Model Base on Einstein Aggregation Operators
The first hierarchy hesitant linguistic term set and the second hierarchy hesitant linguistic term set, which may communicate doubt and fuzziness more flexibly, are the foundation of DHHLSs. DHHLEs are a more acceptable form of expression than singular actual or singular linguistic terms. We define the loss function in TWDs with DHHLEs in this section. A new DTRS model is then suggested using DHHLT information. There are three actions and two states that make up the innovative DTRS model.
,
is the collection of states that represent an element in Z, not in Z with three actions.
are employed to classify element
.
denotes
,
denotes
, and
denotes
, where POS(A), BND(A), and NEG(A) represents the positive, the boundary, and the negative, region of Z, respectively. The states explain an element’s entire position, while the actions convey our opinions. The loss function matrix is then built in the DHHLT environment.
Table 1 shows the outcome.
Where k = 1, 2, 3, …, #P denotes the number of elements in P;
,
, and
denotes loss degrees with DHHLEs created by performing identical actions as
and
to x given state Z, respectively, and
,
and
loss degrees with DHHLEs are created by doing the identical actions as x given state
. As in case
, a suitable connection may be defined as follows based on the semantics of DTRS and the properties of DHHLEs:
While these two loss degrees are bigger than the loss degrees of correct judgement, the loss degrees of false judgement are more than the loss degrees of postponing choice. The conditional probability is a key component of the references’ [
33,
34] Bayesian decision technique.
, represents the conditional probability of element
belonging to Z, and
represents the conditional probability of element
, belonging to
. They are all real numbers that satisfy
. Then, given element
, the corresponding actions of expected losses
can be calculated as follows:
The DHHLEWA operator may compute the expected losses.
The minimum loss decision rules can be inferred from the results in references [
30,
31,
32] as follows.
If , and , decide ;
If , and , decide ; and
If , and , decide .
According to the positive rule (P), we should accept, that is, . According to the boundary rule (B), we should postpone the choice, that is, . According to the negative rule , we should reject, that is, .
The TWDs Procedure
We suggest a unique approach of TWDs in the context of DHHLT in light of the aforementioned findings. According to
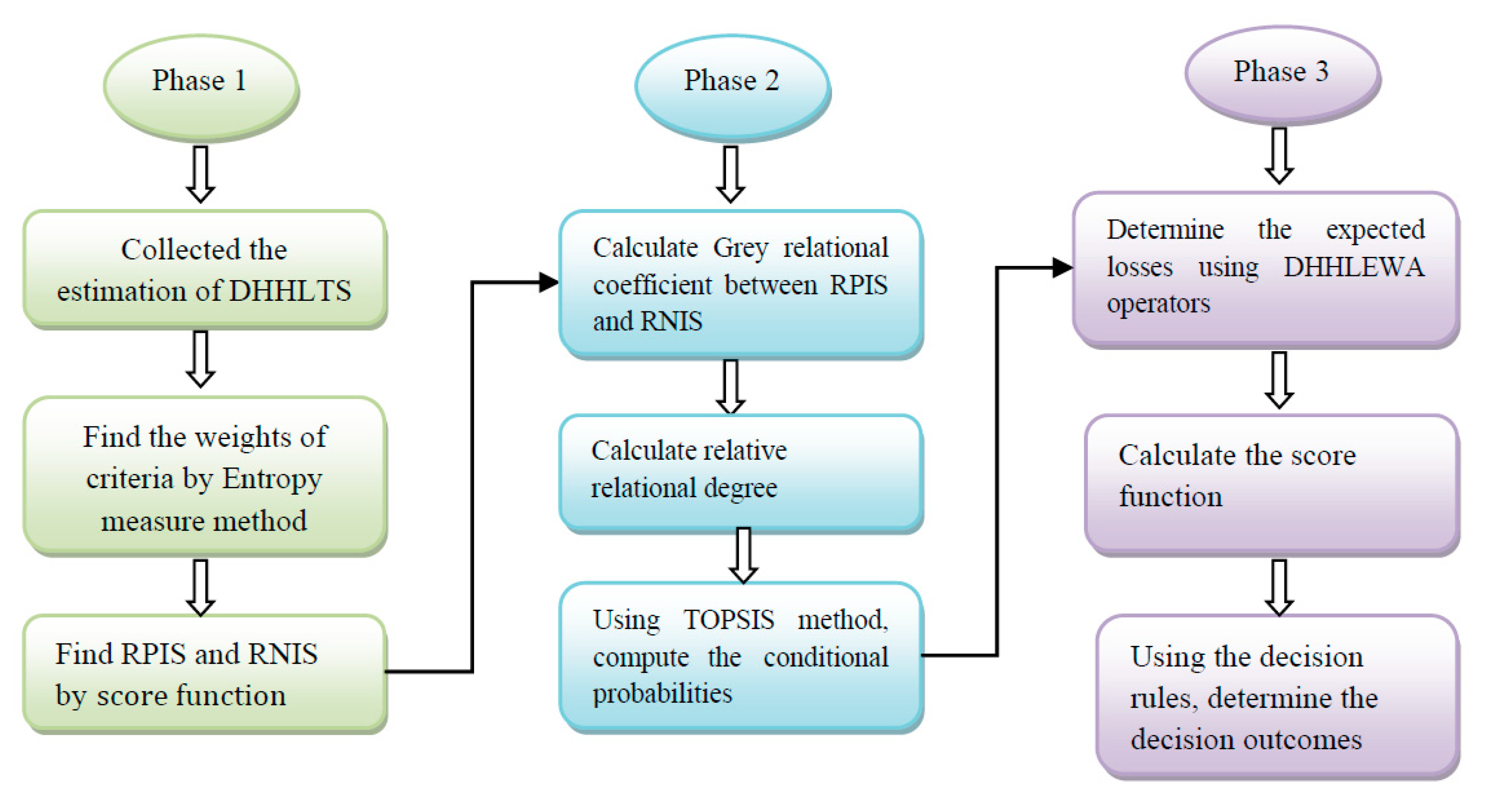
Figure 1, the three-way decision method consists of six phases.
Phase 1: We define the components of hierarchy hesitant linguistic term information systems, based on the practical situation. DHHLTIS , element and criteria included. Then, we obtained the DHHLTIS outcomes and the DM’s loss function.
Phase 2: By using the entropy measure method, we determine the criterion weights. As determined by using Formula (14), the weight of criteria represents the significance of these criteria in the estimate system.
Phase 3: Determine the RPIS and the RNIS by using the score function as determined by using Formula (6).
Phase 4: Determine the conditional probability by using the TOPSIS method, indicated by and as determined by using Formulas (16)–(19).
Phase 5: Each action’s expected loss can be aggregated using Formulas (22)–(24) in accordance with Einstein’s aggregation operators. It is therefore possible to determine the score function of expected losses.
Phase 6: Finally, according to the decision rules, deduce the decision outcomes.
6. Problem Statement
The block ciphers are an essential role in the field of cryptography. The action of a cipher calculates the toughness of the algorithm, which is answerable for executing agitation in the encryption process. An S-box, the only nonlinear element made up of several block ciphers, is used to achieve this performance. In the field of encryption, the improvement of S-boxes’ algebraic and statistical properties has attracted a lot of attention. Let us consider S-boxes for security purposes, and to select the best S-box among RP, AES, APA, G, LJ, and S8 as displayed in
Table 2. We consider some of their characteristics as criteria:
Correlation analysis is a popular method for assessing the statistical characteristics of an S-box. The correlation analysis determines the relationship between the input and output. To verify that the S-box has excellent statistical properties, we aim to reduce the correlation between the input and output.
= Entropy analysis is an essential method in encryption for determining the strength of an S-box. Entropy is a measure of the variability or volatility of an S-output box’s values given its input values. The greater the entropy, the more difficult it is for an attacker to anticipate the S-box output values.
= Contrast analysis is a technique for assessing the integrity of an S-box in terms of resilience to differential cryptanalysis. Differential cryptanalysis is a frequent form of assault on cryptography systems, and a powerful S-box is one that is immune to such attacks.
= Homogeneity analysis is a technique for assessing the probabilistic characteristics of S-boxes in encryption methods. It quantifies how well the S-box transfers input values to output values. A decent S-box should be homogeneous, which means that its output numbers should be equally dispersed across its input range.
= Energy analysis: A side-channel technique called energy analysis can be used to crack encryption protocols. This kind of assault includes monitoring a device’s radio emissions or battery usage as it performs cryptography processes. An intruder could learn the encryption secret or other confidential data by examining these readings. The formulas for calculating the criteria of S-boxes are displayed in
Table 3.
Phase 1: We define the essential components of a linguistic term hierarchy information system, DHHLTIS , and after that, we may get and .
Phase 2: We determine the weight of criteria by entropy measure method.
. They are displayed in
Table 4.
Phase 3: The criteria – are benefit criteria. Through the score function we can find the and as follows:
, and
.
Phase 4: Using the TOPSIS method, we calculate the conditional probability. The outcomes are displayed in
Table 6.
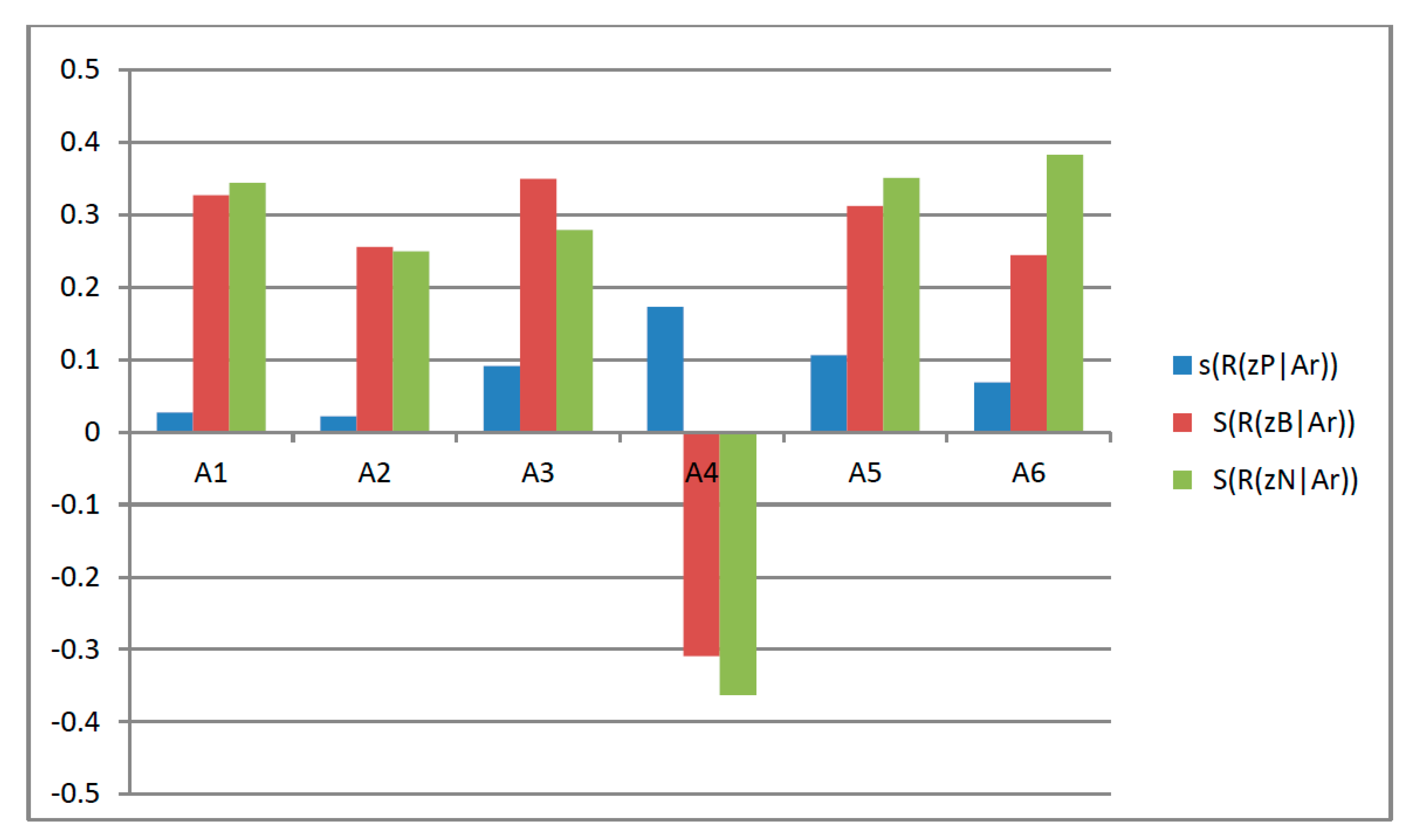
Phase 5: Each action’s expected loss can be aggregated using Formulas (22)–(24) in accordance with Einstein’s aggregation operators. It is therefore possible to determine the score function of expected losses. They are displayed in
Table 7.
Phase 6: According to decision rules
–
, it is possible to determine the outcomes of each element’s decision. As seen in
Figure 2,
, and
. Thus the
can be selected and
should be rejected.
7. Discussion and Comparison
We now contrast our suggested method with the GRA method and talk about its limitations and advantages.
7.1. Using the GRA Method for TWDs
By using the GRA method to calculate the conditional probability and weight of criteria, RPIS and RNIS are the same using the TOPSIS method and the GRA method.
Table 8 displays the conditional probability.
The weight, the PIS and the NIS are the same using both methods (GRA and TOPSIS). The conditional probability in the results change when we put different values of
in interval [0, 1]. When we put the values of
i.e., {0.9, 0.5, 0.1, 0.05}, then we get the results as
and
,
and
,
and
and
and
respectively. We conclude that decreasing the values of
produce decisions with almost the same outcomes as our suggested method. If
, results are shown in
Table 8. The following choice is made as an outcome of using the minimum-cost decision rules:
and
.
Table 9 shows that the GRA method gives the same decision outcomes as our suggested method (TOPSIS).
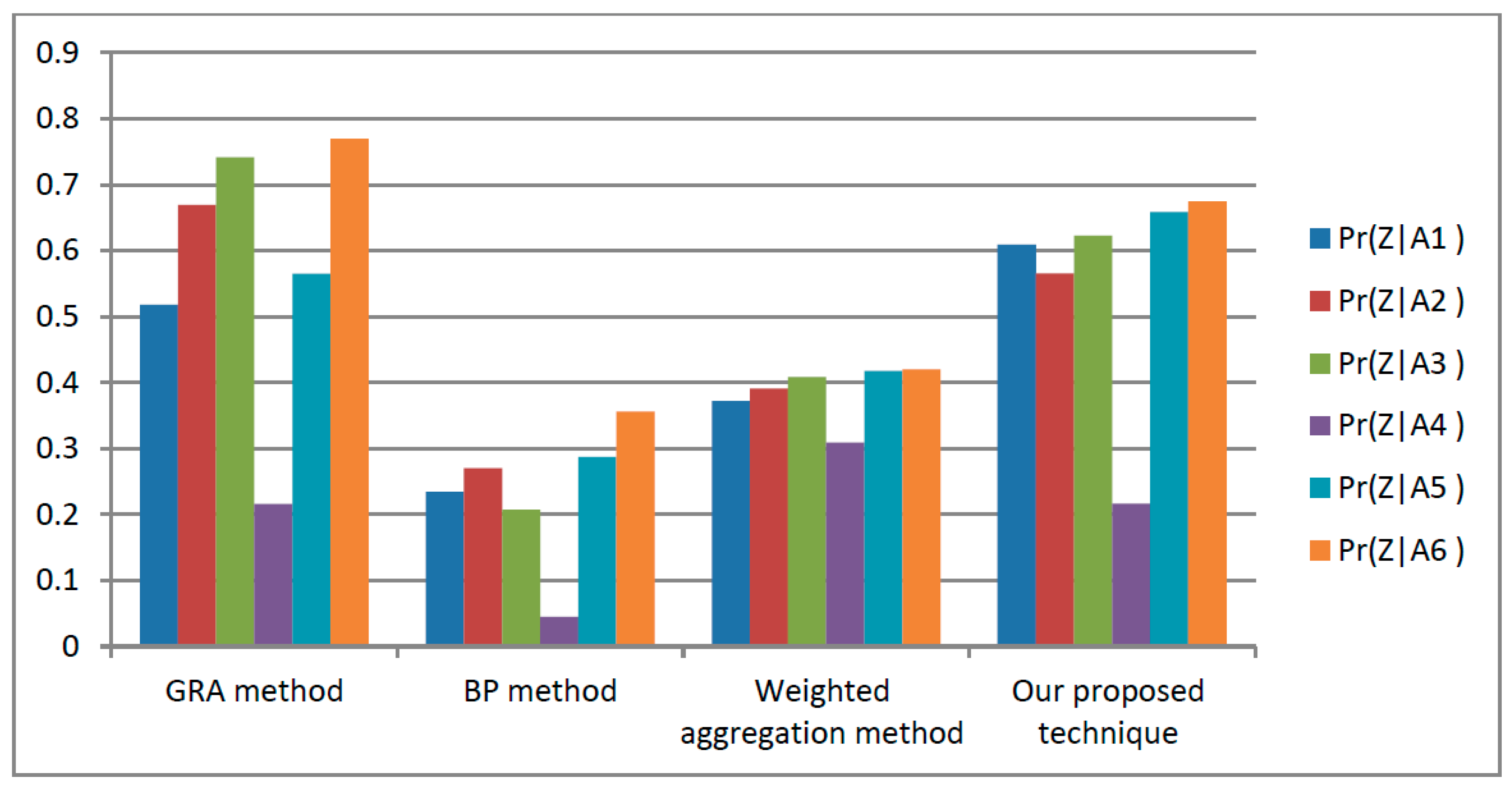
7.2. MADM Methods Are Used to Computed the Conditional Probability
One of the essential components of TWDs is conditional probability, which may also serve as the foundation for scheme ordering. We calculate the conditional probability by the GRA method, the BP method, the weighted aggregation method, and the ideal solutions (see
Figure 3). The same weights for all above methods in
Table 10 displays the results of the conditional probability. From
Table 11, we learn that our suggested method and the other MADM method’s ranking of conditional probability elements are mostly the same. The S-box
is selected as the best S-box in image encryption according to the above ranking outcomes of all methods.
7.3. Discussion on the Advantages and Limitations
One of the essential elements of the TWDs is the DTRS model, because the DTRS model can show the loss caused by various actions and select the appropriate action using minimum-loss decision rules. Conditional probability is an essential component of TWDs method. Using the entropy measure method, we estimate the weight of each criterion, take the RRD of the element, and—using the TOPSIS method—compute the conditional probability. To summarize the fundamental issue, linguistic terms match human expression habits more. DHHLTSs, as they differ from a single linguistic set, allow for a more versatile approach to representing qualitative information. The introduction of DHHLTSs provides a new method for communicating estimated data in TWDs. When DMs estimate the project’s criteria information, they can provide the estimate value using DHHLTSs more intuitively, which cuts down on decision-making time. The DHHLT environment is used to build the proposed model. The new research content consists of TWD models built upon the DHHLT information system. As a result, it has a high research value. The following list of our suggested method’s primary benefits is provided.
- (I)
The FHHLT and SHHLT that make up the DHHLE provide for more flexible expressions of the estimation of DMs throughout the TWD procedure.
- (II)
It is helpful to apply the TWD approach based on the DHHLEs when dealing with decision-making issues.
- (III)
The conditional probability was calculated by using the TOPSIS method.
However, the suggested method has certain limitations as well.
- (I)
This work does not examine the scenario of group decisions or take into account varied expert weights in order to simplify the computation.
- (II)
In the future, we will expand this concept to group choices and make it much more functional.
8. Conclusions
The artificial intelligence decision making is very important role in the Three Way artificial intelligence decision making double hierarchy hesitant linguistic term set. The weight of decision expert and criteria are calculated by using entropy methods with help of aggregation operators. The conditionally probability is central part of artificial intelligence based three way decision making. The conditional probability is measured by the extended TOPSIS method in the artificial intelligence-based three-way decision, and ranking is determined using the expected loose function. In this paper, we studied develop a new an Artificial Intelligence based three way decision model using double hierarchy hesitant linguistic term information. First, we defined some basic operational laws for DHHLEs according to Einstein operations and their properties. Then, we established some double hierarchy hesitant Einstein aggregation operators: the DHHLEWA operator, DHHLEWG operator, DHHLEOWA operator, DHHLEOWG operator, DHHLHA operator, DHHLHG operator, and some properties of double hierarchy hesitant Einstein aggregation operators. The weight of criteria was then calculated using the entropy measure method using double hierarchy hesitant linguistic term information. Then, using the score function, we determined the positive and negative ideals solutions. Then, we determined the GRC, the RRD by TOPSIS method, and RRD appraisement to conditional probability. According to the Einstein operational laws, we then determined the score function of expected losses. Finally, the TWD method is used to determine the selection of S-box in image encryption.
In future work, the proposed work can be extended to two-way decision-making problems, and the fractional fuzzy three-way decision can be developed for emergency decision problems. Furthermore, the linguistic three-way decision with fractional fuzzy sets can be defined for logistic provider selection. Additionally, the proposed models of three-way decision making under the double hierarchy linguistic variable can be applied to analyze the different types of S-boxes.











{kind=link}
{kind=link}
{kind=link}