1. Introduction
Risk analysis in insurance data refers to the process of evaluating and estimating the likelihood of future events that may have an impact on the insurance industry or a specific insurance policy. The goal of risk analysis is to identify potential risks, assess their likelihood and impact, and develop strategies to manage or mitigate those risks. This process involves collecting, analyzing, and interpreting data regarding various factors, such as demographic information, insurance claims history, and economic indicators, to determine the level of risk associated with a particular policy or portfolio of policies. The result of risk analysis is used by insurance companies to set premiums, make underwriting decisions, and develop strategies to manage potential losses.
The claim-size random variable (CSRV) and the claim-count random variable (CCRV) are the two independent random variables (RVs) employed in each property/casualty claim procedure. The aggregate-loss RV (ALRV), which represents the total claim amount produced by the fundamental claim method, can be generated by combining the first two basic claim RVs.
The CSRV is a variable that represents the size or amount of a claim that an insurer may face. For example, if a policyholder files a claim for a car accident, the CSRV variable would represent the amount of money that the insurer would need to pay out to cover the damages. The distribution of claim sizes can vary depending on the type of insurance policy and the risk profile of the policyholders. The CCRV is a variable that represents the number of claims that an insurer may face. For example, if an insurance company offers homeowner’s insurance, the CCRV would represent the number of claims filed by policyholders in a given period of time. The distribution of claim counts can also vary depending on the type of insurance policy and the risk profile of the policyholders. The CCRV and CSRV and key/main risk indicators are essential concepts in the insurance industry, helping insurers to effectively measure and manage risk. By understanding these concepts and using them in practice, insurers can ensure their financial stability and ability to pay claims, even in the face of unexpected events and changing risk profiles.
The generalized odd log-logistic Burr XII (GOLLBrXII) distribution, a unique distribution of claim-size variables, is examined for risk analysis in this paper. Several actuaries have employed a broad variety of parametric families of continuous distributions to model the property and casualty insurance claim size. The degree of risk exposure is typically expressed as one number, or at the very least a limited group of numbers. These risk exposure levels, which are definitely functions of a certain model, are usually referred to as key/main risk indicators (KRKIs) (see Hogg and Klugman [
1] for more details). These KRKIs provide the actuaries and the risk managers with significant knowledge regarding the level of a company’s exposure to particular risks. In the actuarial analysis and the literature, there are several KRKIs that may be considered and researched, including value-at-risk (VRk), tailed-value-at-risk (TVRk) (also known as conditional tail expectation), conditional-value-at-risk, tailed-variance (TV), and tailed-mean-variance (TMV), among others.
The quantile of the probability distribution of the aggregate losses RV can be considered as the VRk. The VRk indicator may be used to express the likelihood of a negative outcome at a certain level, this level can be considered to be the probability/confidence. Actuaries and risk managers commonly concentrate on this estimate. This indicator is typically used to estimate how much money will be required to handle such potential undesirable consequences. Actuaries, regulators, investors, and rating agencies all place a premium on an insurance company’s capacity to manage such situations. Certain KRI variables, including VRk, TVRk, TV, and TMV, are suggested in this work for the left-skewed insurance claims data under the GOLLBrXII distribution (see Artzner, [
2]). Based on the t-Hill technique, an upper order statistic modification of the t-estimator, one of the best methods for heavy-tailed distributions exists (Figueiredo et al. [
3]). Burr [
4], who developed a system of densities equivalent to that of Pearson, uses twelve different varieties of cumulative distribution functions (CDFs) to produce a variety of density shapes; for more details see Burr [
4], Burr [
5], Burr [
6], Burr and Cislak [
7], and Rodriguez [
8]. One of these variants, the Burr type XII distribution, has received particular attention. The three-parameter BrXII distribution’s CDF and probability density function (PDF) are provided by
and
respectively, where both
and
are shape parameters and
is the scale parameter. See Tadikamalla [
9] for further information on the BrXII model and its connections to other similar models. For an arbitrary baseline CDF
, the CDF of the GOLL-G family is written as
where both
and
are shape parameters. For
, we obtain the OLL-G family. For
, we obtain the proportional reversed hazard rate G (PRHR-G) family (Gupta and Gupta [
10]). The CDF of the GOLLBrXII due to Cordeiro et al. [
11] is given by
where
and
The PDF corresponding to (4) is given by
Table 1 provides some sub-models of the GOLLBrXII model.
Figure 1 shows some PDF graphs for some selected parameters values.
Based on
Figure 1, it can be seen that the PDF of the new model can be “right skewed heavy tail”, “right skewed heavy tail with one peak”, “right skewed”, and have bimodal density with different shapes. The hazard rate function (HRF) for the GOLLBrXII model can be obtained from
. This paper focuses on several estimation methods.
The rest of the paper is organized as follows: The literature review is given in
Section 2.
Section 3 presents some new properties. The main risk indicators are given in
Section 4. Methods of estimation are provided in
Section 5.
Section 6 presents simulation studies for comparing methods.
Section 7 offers data analysis for comparing classical methods and data analysis for comparing models. Risk analysis under insurance claims data utilizing different estimation methods is provided in
Section 8. Finally,
Section 9 presents some concluding remarks and discussions.
2. Literature Review and Motivation
In this section, a comprehensive literature review is provided to help readers to develop an overall idea about the history of the research problem. This section will include several basic aspects, including those related to the new probability distribution, and others related to applications, including those related to the treatment of actuarial risks and how to evaluate and analyze them.
The BrXII distribution, often known as the Burr distribution, is a continuous probability distribution for a non-negative random variable (NNRV) used in probability theory, statistics, and econometrics; it is one of several alternative distributions referred to as the generalized Burr XII distribution, exponentiated Burr distribution, among others (see Burr [
4], Burr [
5], Burr [
6], Burr and Cislak [
7], and Rodriguez [
8]). The BrXII distribution has attracted the attention of many researchers in the last two decades, so it has been used in many mathematical and statistical modeling operations, and many researchers have made many generalizations to it, including: the beta BrXII (B BrXII) model was proposed and investigated by Paranaíba et al. [
12]. The Kumaraswamy BrXII (KumBrXII) model was put forward and researched by Paranaíba et al. [
13]. Yousof et al. [
14] created a regression model based on a new family of Burr-Hatke G (BH-G) models. Validation of the BrXII inverse Rayleigh model was conducted by Goual and Yousof [
15]. A novel two-parameter BrXII distribution with some copulas, properties, different methods, and modeling acute bone cancer dataset was proposed by Mansour et al. [
16]. Elsayed and Yousof [
17] developed the generalized Poisson Burr XII (GP BrXII) distribution with four applications by extending the BrXII model. The double BrXII model with censored and uncensored distributional validation utilizing a novel Rao-Robson-Nikulin test was introduced by Ibrahim et al. [
18]. Finally, a Bagdonavicius-Nikulin goodness-of-fit test was performed for the compound Topp Leone BrXII model by Khalil et al. [
19], among others.
In the actuarial analysis, many works have employed the standard Pareto and standard lognormal distributions to model insurance payments data, and more specifically, massive insurance claim payment data. The extended Pareto has been employed by several academics, including Resnick [
20] and Beirlant et al. [
21]. The standard Pareto model does not provide a satisfactory match for many actuarial applications when the frequency distributions are hump-shaped because of its monotonically declining density type. In these situations, the standard lognormal is routinely employed to model these datasets, but the lognormal is not suitable for some cases and the Pareto model encompassing more claim payments data. It is clear that left-skewed payment data cannot be explained by the lognormal distribution or the Pareto distribution. To address this flaw in the outdated conventional models, we provide the GOLLBrXII distribution for the negative-skewed insurance claim payments datasets.
In the statistical and actuarial literature, there is a dearth of works that have used probability distributions in the field of processing and analyzing actuarial risks. We mention some of these works, especially the recent ones; for example, see Figueiredo et al. [
3], Shrahili et al. [
22], and Mohamed et al. ([
23,
24]). Hence, this important aspect of actuarial science requires a lot of effort to employ probability distributions in the field of actuarial science and to treat, evaluate, and forecast risks.
Although there are numerous established methods for estimation and statistical inference in the statistical literature, we concentrate on the four methods listed above due to their widespread use, effectiveness, and suitability, particularly when combined with the Burr distribution and any derived extensions. These four methods have attracted the attention of many researchers in the last decade. Researchers have used them in statistical modeling and applications in real data. For more details, see Mansour et al. [
16] and Ibrahim et al. [
18]. We do not mean to imply that these methods do not have failures, or that they do not have defects, but, in any case, we have made every effort to choose the most famous and classic methods with capabilities that are characterized by efficiency and statistical consistency.
4. Main Risk Indicators
Actuaries use probability distributions to model and quantify the likelihood of different outcomes and to determine the expected values of future losses. A probability distribution is a function that describes the likelihood of different outcomes for a RV. Actuaries use various types of probability distributions, such as normal, Poisson, exponential, and log-normal, to model different types of risks, such as mortality, morbidity, and property damage. The choice of distribution depends on the nature of the risk being modeled and the data available to support the modeling. Actuaries use probability distributions to calculate the expected values of future losses, which can be used to set insurance premiums, design insurance products, and evaluate investment strategies. Actuaries also use simulation techniques to test their models and to evaluate the impact of various scenarios on the financial outcomes of insurance policies and investments. In this section, we will review a group of important actuarial indicators that are commonly used in evaluating actuarial risks and analyzing the maximum expected losses from the point of view of insurance and reinsurance companies. The new probability distribution is also added according to these actuarial indicators.
4.1. VRk Indicator
Definition 1. Let denote a loss random variable (LRV). The VRk of at the level, say VRk or , is the quantile (or percentile) of the distribution of .
Then, based on Definition 1, we can simply write for the GOLLBrXII distribution.
where
refers to the quantile function of the new model.
4.2. TVRk Risk Indicator
Definition 2. Let denote a LRV. The TVRk of at the confidence level is the expected loss given that the loss exceeds the of the distribution of , namelywhere refers to the significant level.
Thus, the quantity
is an average of all
values above the confidence level
, which provides more information about the tail of the GOLLBrXII distribution. Finally,
can also be obtained from
where
is the mean excess loss function (MELF) evaluated at the
quantile. Therefore,
is larger than its corresponding
by the amount of average excess of all losses that exceed the MELF value. In the insurance literature,
has been independently developed and it is also called the conditional tail expectation. It is also called the tail conditional expectation (TCE) or expected shortfall (ES) (Tasche [
26]; Acerbi and Tasche [
27]).
4.3. TV Risk Indicator
Definition 3. Let denote a LRV. The TV risk indicator (TV ()) can be expressed as
Then, for the GOLLBrXII model, we have
4.4. TMV Risk Indicator
Definition 4. Let denote a LRV. Then, the TMV can be derived as
Then, for any LRV, , , for the and for the .
8. Risk Analysis under Insurance Claims Data Utilizing Different Estimation Methods
Actuaries have recently used continuous distributions, especially ones with broad tails, to reflect actual insurance data. Engineering, risk management, dependability, and the actuarial sciences are just a few of the application areas where real data has been simulated using continuous heavy-tailed probability distributions. The skewness of insurance datasets can be either left, right, or right with exceptionally large tails. In this paper, we show how the flexible continuous heavy-tailed GOLLBrXII distribution can be used to represent left-skewed insurance claims data.
Utilizing insurance claims data is challenging despite its huge value. The largest issue is evaluating its quality and counting the number of incomplete or missing observations (see Stein et al. [
30] and Lane [
31]). For further details, see Ibragimov and Prokhorov [
32], Cooray and Ananda [
33], Hogg and Klugman [
1], and Lane [
31]. Real datasets for insurance payments are commonly heavy or right tailed, and they are generally positive. In this section, using a U.K. Motor Non-Comprehensive account as a concrete example, we look at the insurance claims payment triangle. Convenience led us to pick the genesis era from 2007 to 2013 (see Charpentier [
34], Shrahili et al. [
22], Mohamed et al. [
23,
24]).
The claims data are presented in the insurance claims payment data frame in the same way that a database would typically store it. The first column contains the development year, the incremental payments, and the origin year, which spans from 2007 to 2013. It is vital to remember that a probability-based distribution was initially used to examine these data on insurance claims. The insurance premium is the sum of money an individual or business pays to purchase an insurance policy. For the coverage of life, an automobile, a house, and health insurance, premiums are paid. Once the premium is earned, the insurance company is paid. It also entails a liability because the insurer is obligated to provide coverage for any claims brought up in relation to the policy. The policy may be cancelled if either the individual or the business fails to pay the premium. In this work, we focus our work on the insurance claims side, which is what was from the data. Perhaps we will find the opportunity in the future to carry out a balanced study examining the claims and the premiums.
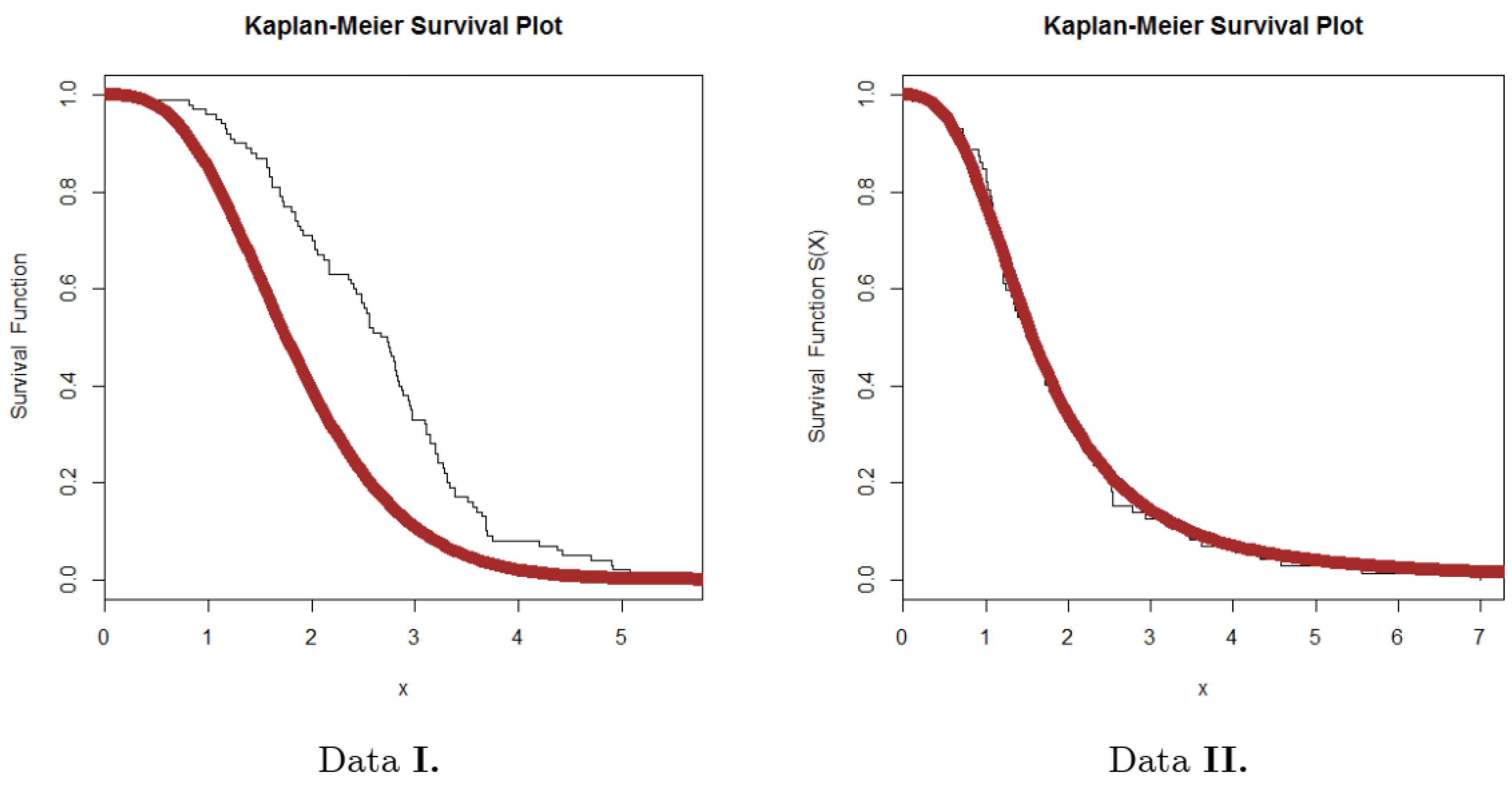
We start by examining the data on insurance claims statistics, but this time for data on insurance claims. It is possible to quantitatively, visually, or by combining the two, evaluate real-world data. Initial fits of theoretical distributions such as the normal, exponential, logistic, beta, uniform, lognormal, and Weibull are assessed using the numerical technique (see
Table 11), as well as other several graphical/statistical tools, such as the skewness-kurtosis graph (or the Cullen-Frey graph) (see
Figure 10).
The nonparametric density estimation (NKDE) method for examining the initial shape of the insurance claims density, the Q-Q graph for examining the “normality” of the current data, the TTT graph for examining the initial shape of the HRF, and the “box graph” for identifying the extreme claims are just a few of the additional graphical methods that are taken into consideration (see
Figure 11, bottom right graph). The top left graph of
Figure 11 shows the initial density as an asymmetric function with a left tail. No extreme values are shown from
Figure 11 (bottom right graph).
In addition, the bottom left graph of
Figure 11 shows that the HRF for the models that account for the observed data should be “monotonically increasing”. It is important to note that there are numerous risk indicators that can be used and employed in the assessment and analysis of actuarial risks. Additionally, there is room for the introduction of new risk indicators that might perform better in some theoretical and practical respects than the established ones. We think that there is still a lot of work to be done in the area of actuarial statistical programming in order to develop more specialized actuarial packages that might make the work of insurance and reinsurance businesses easier.
The first row in
Figure 12 shows scattergrams for the data on insurance claims, while the second row shows the autocorrelation function (ACF) and partial autocorrelation function (partial ACF). We provide the ACF that may be used.
Figure 12 illustrates the distribution of hills and valleys on the surface with Lag = k = 1 in more detail (bottom left). Theoretical partial ACF with Lag = k = 1 is shown in
Figure 12 (the bottom right panel). According to the bottom right corner of
Figure 12, the initial lag value is statistically significant; however, none of the other partial autocorrelations for any other delays are. In order to potentially fit these data, an autoregressive (AR(1)) model is suggested.
The initial NKDE is an asymmetric function with a left tail, as shown in the top left panel of
Figure 12. On the other hand, the left tail form is present in the novel model’s density. As a result, it is advised to use the GOLLBrXII model to model the payouts for insurance claims. We present an application for risk assessment and analysis under VRk
, TVRk
, TV
, and TMV
measures for the insurance claims data. The risk analysis is conducted for some confidence levels
The five measures are analyzed and then estimated for the GOLLBrXII and Burr XII models. The Burr XII model is the better baseline model for this application.
Table 15 summarizes the estimated parameters for KRKIs for the GOLLBrXII and Burr XII models,
Table 16 reports the KRKIs for the GOLLBrXII model, and
Table 17 reports the KRKIs for the Burr XII model.
Table 18 provides the VRk range under the new model and the baseline model for all
values. Based on
Table 18, the new model is better for all
values. Insurance companies can rely on the new distribution in determining the minimum and maximum limits for the volume of insurance claims. This reluctance of claims, which was estimated in the light of historical data, could achieve some safety for insurance companies in avoiding the risks of an inability to pay insurance claims.
Specifically, and based on
Table 16 and
Table 17, we can highlight the following detailed results:
- I.
Under the MLEs: For the GOLLBrXII model, the quantity VRk ranges from 3313.4 to 17414.62; however, for the Burr XII model, the quantity VRk ranges from 3398.65 to 7369.73.
- II.
For the GOLLBrXII model, the quantity TVRk ranges from 6610.75 to 32,345.5; however, for the Burr XII model, the quantity TVRk ranges from 4701.5 to 8285.6.
- III.
For the GOLLBrXII model, the quantity TV ranges from 125,688,493.43 to 2,884,628,282.96; however, for the Burr XII model, the quantity TV ranges from 1,309,732.22 to 776,459.57.
- IV.
For the GOLLBrXII model, the quantity TMV ranges from 62,850,857.47 to 1,442,346,487.03; however, for the Burr XII model, the quantity TMV ranges from 659,567.64 to 396,515.42.
- V.
For the GOLLBrXII model, the quantity MELF ranges from 3297.36 to 14,930.9; however, for the Burr XII model, the quantity MELF ranges from 1302.88 to 915.91. However, the same comments can be addressed.
9. Concluding Remarks
The probability-based distributions could provide a reasonable explanation for the exposure to risk. Most often, one number, or at least a small collection of numbers, are used to indicate the level of risk exposure. We examine the actuarial risks using the five previously stated indicators in order to study and evaluate the risks that insurance firms may face in relation to the payment of insurance claims. Four estimation methods are used to calculate these five fundamental indicators. A novel distribution, known as the generalized odd log-logistic Burr type XII, is given and studied as a consequence, keeping this main goal in mind. Through Monte Carlo simulations, the performance of each estimating method is examined. For comparing traditional methodologies, two actual data applications are shown. For comparing the new model with other competing models and demonstrating the significance of the suggested model using the maximum likelihood technique, two actual data applications are offered. The four approaches indicated above and five actuarial indicators based on bimodal insurance claims payment data are used to analyze and evaluate the actuarial risks. The following results can also be shown for most values of :
- I.
for the GOLLBrXII model VRk for the Burr XII model
- II.
for the GOLLBrXII model TVRk for the Burr XII model.
- III.
for the GOLLBrXII model TV for the Burr XII model.
- IV.
for the GOLLBrXII model TMV for the Burr XII model.
- V.
- VI.
- VII.
- VIII.
- IX.
The generalized odd log-logistic Burr XII model can also be employed for the stress-strength models and multicomponent stress-strength models. It is worth noting that there are many risk indicators that can be used and employed in the evaluation and analysis of actuarial risks, and the door is open to presenting more new risk indicators that may outperform the well-known indicators in some theoretical and applied aspects. We believe that the field of actuarial statistical programming still needs a lot of efforts to provide more specialized actuarial packages that may facilitate the work of insurance and reinsurance companies.



 ,
, _Masoom_Ali.png)














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}