
Transfer Learning with ResNet3D-101 for Global Prediction of High Aerosol Concentrations

 ,
,  , , and
, , and
Abstract
:1. Introduction
Literature Review and Related Work
2. Data and Methodology
Pre-Training Process
- The distance domain criterion (ddc) (the machine learning (ML) model is capable of generating adequate data if metrics for the predicted data, in comparison with the original data, are equal or better than an average difference between randomly selected output data from the database).
- The time domain criterion (dtc) (the ML model is capable of finding patterns in the time domain if metrics for predicted data, in comparison with the original data, are equal or better than an average difference of two adjacent output data from the database).
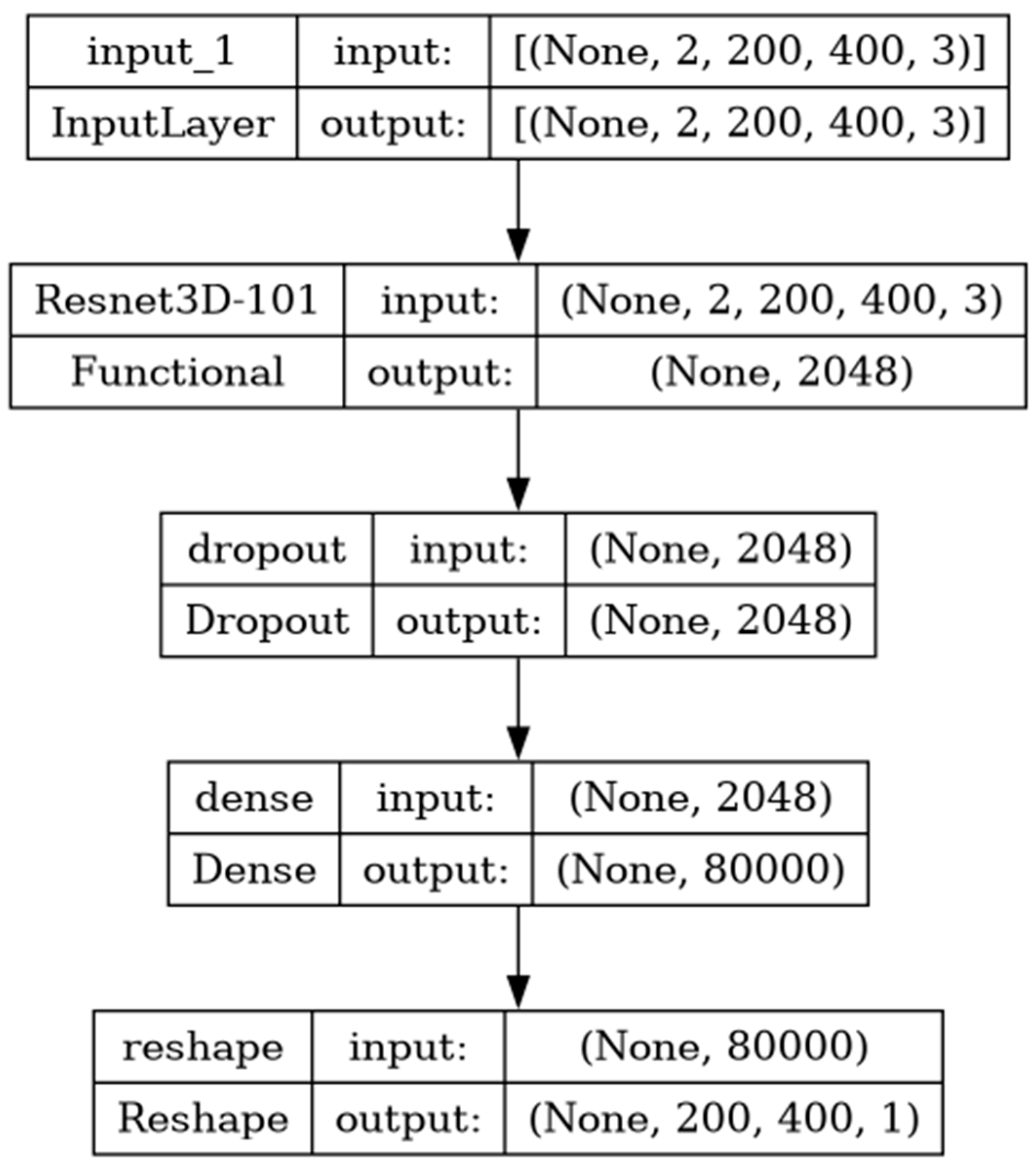
3. Transfer Learning Model
4. Results and Discussion
4.1. Grid Search
4.2. Effect of Batch Size
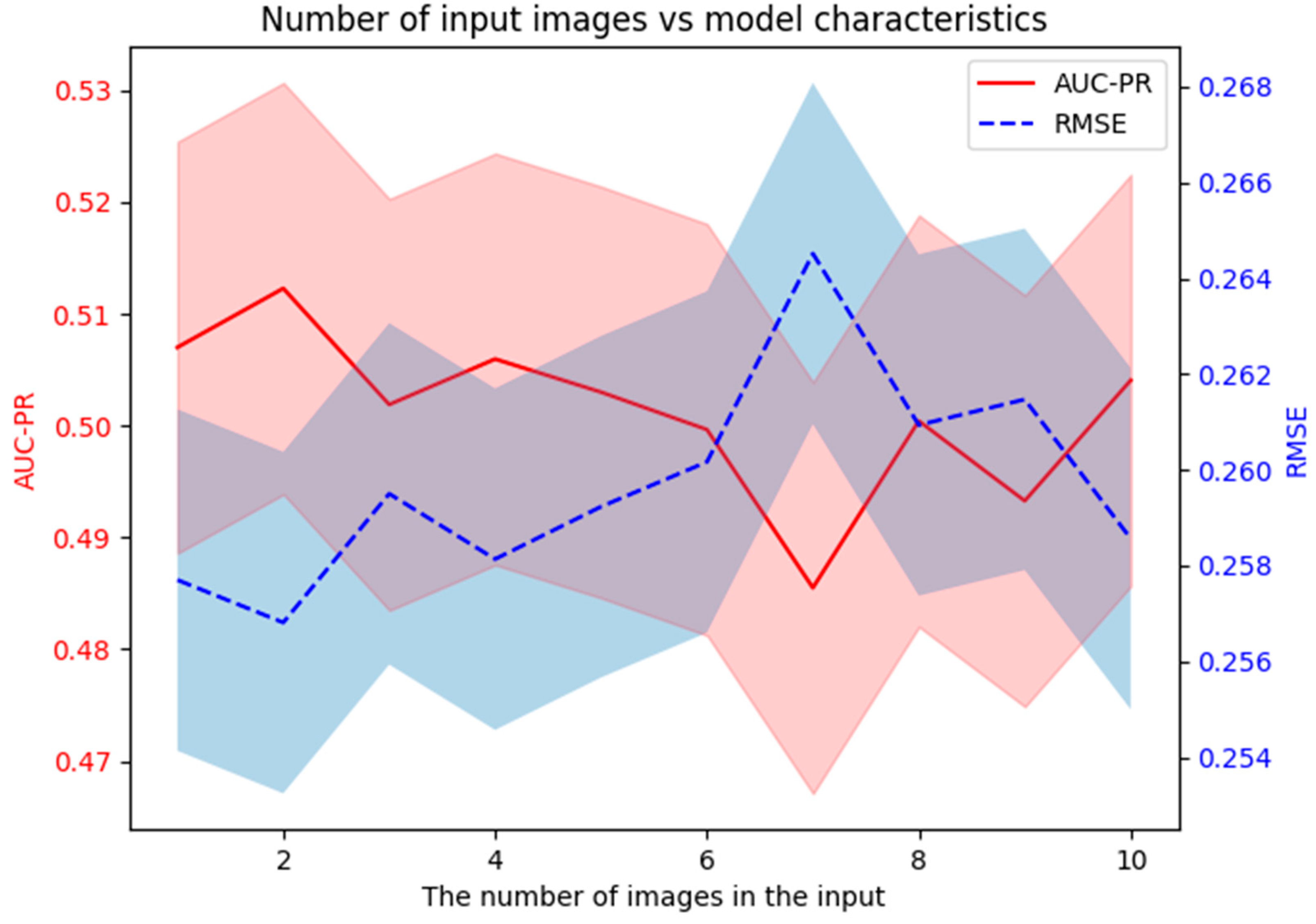
4.3. Influence of Input Length
4.4. Classification Threshold
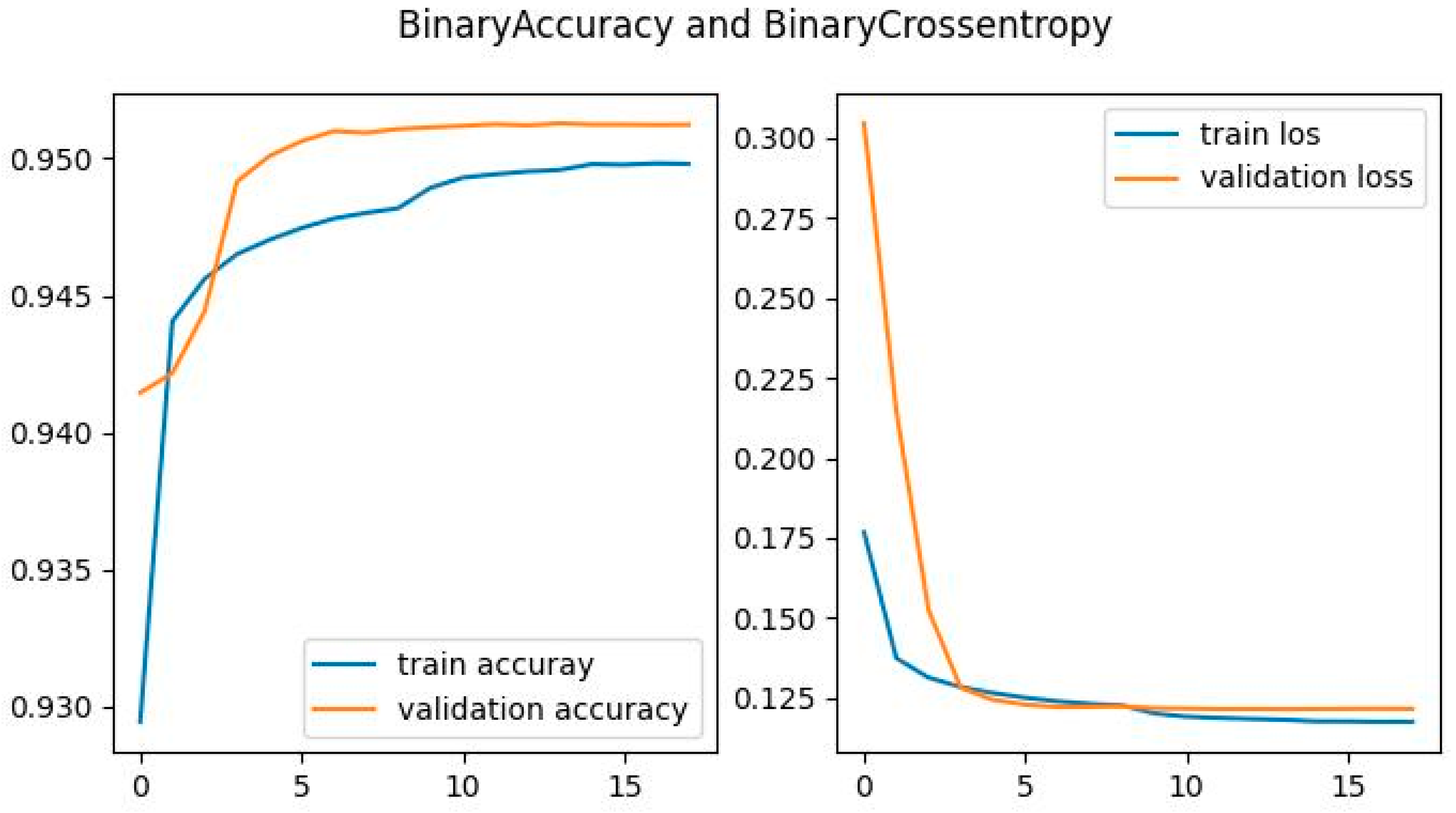
4.5. Obtained Results
5. Conclusions and Future Research
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bichri, H.; Chergui, A.; Hain, M. Image Classification with Transfer Learning Using a Custom Dataset: Comparative Study. Procedia Comput. Sci. 2023, 220, 48–54. [Google Scholar] [CrossRef]
- Nikezić, D.P.; Ramadani, U.R.; Radivojević, D.S.; Lazović, I.M.; Mirkov, N.S. Deep Learning Model for Global Spatio-Temporal Image Prediction. Mathematics 2022, 10, 3392. [Google Scholar] [CrossRef]
- Radivojević, D.S.; Lazović, I.M.; Mirkov, N.S.; Ramadani, U.R.; Nikezić, D.P. A Comparative Evaluation of Self-Attention Mechanism with ConvLSTM Model for Global Aerosol Time Series Forecasting. Mathematics 2023, 11, 1744. [Google Scholar] [CrossRef]
- Brennan, J.; Kaufman, Y.; Koren, I.; Li, R.R. Aerosol-Cloud Interaction-Misclassification of MODIS Clouds in Heavy Aerosol. IEEE Trans. Geosci. Remote Sens. 2005, 43, 911. [Google Scholar] [CrossRef]
- Aerosol Optical Thickness (AOT). Available online: https://discover.data.vic.gov.au/dataset/aerosol-optical-thickness-aot (accessed on 19 January 2024).
- Keras Applications. Available online: https://keras.io/api/applications/ (accessed on 27 January 2024).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Bello, I.; Fedus, W.; Du, X.; Cubuk, E.D.; Srinivas, A.; Lin, T.Y.; Shlens, J.; Zoph, B. Revisiting ResNets: Improved Training and Scaling Strategies. Adv. Neural Inf. Process. Syst. 2021, 34, 22614–22627. [Google Scholar] [CrossRef]
- Du, X.; Li, Y.; Cui, Y.; Qian, R.; Li, J.; Bello, I. Revisiting 3D ResNets for Video Recognition. arXiv 2021, arXiv:2109.01696. [Google Scholar]
- Hara, K.; Kataoka, H.; Satoh, Y. Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshop (ICCVW), Venice, Italy, 22–29 October 2017; pp. 3154–3160. [Google Scholar]
- Bao, W.; Ma, Z.; Liang, D.; Yang, X.; Niu, T. Pose ResNet: 3D Human Pose Estimation Based on Self-Supervision. Sensors 2023, 23, 3057. [Google Scholar] [CrossRef] [PubMed]
- Hara, K.; Kataoka, H.; Satoh, Y. Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet? In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6546–6555. [Google Scholar]
- Merino, I.; Azpiazu, J.; Remazeilles, A.; Sierra, B. 3D Convolutional Neural Networks Initialized from Pretrained 2D Convolutional Neural Networks for Classification of Industrial Parts. Sensors 2021, 21, 1078. [Google Scholar] [CrossRef] [PubMed]
- Yue-Hei Ng, J.; McCloskey, K.; Cui, J.; Meijer, V.R.; Brand, E.; Sarna, A.; Goyal, N.; Van Arsdale, C.; Geraedts, S. OpenContrails: Benchmarking Contrail Detection on GOES-16 ABI. arXiv 2023, arXiv:2304.02122. [Google Scholar]
- Ebrahimi, A.; Luo, S.; Chiong, R. Introducing Transfer Learning to 3D ResNet-18 for Alzheimer’s Disease Detection on MRI Images. In Proceedings of the 2020 35th International Conference on Image and Vision Computing New Zealand (IVCNZ), Wellington, New Zealand, 25–27 November 2020. [Google Scholar]
- ZFTurbo/Classification_Models_3D. Available online: https://github.com/ZFTurbo/classification_models_3D (accessed on 27 January 2024).
- Index of /archive/rgb/MODAL2_E_AER_OD. Available online: https://neo.gsfc.nasa.gov/archive/rgb/MODAL2_E_AER_OD/ (accessed on 18 November 2023).
- Hoffman, J.P.; Rahmes, T.F.; Wimmers, A.J.; Feltz, W.F. The Application of a Convolutional Neural Network for the Detection of Contrails in Satellite Imagery. Remote Sens. 2023, 15, 2854. [Google Scholar] [CrossRef]
- Radivojević, D. Introducing two evaluation criteria for the next data prediction using machine learning models. In Proceedings of the DSC Europe, Belgrade, Serbia, 20–24 November 2023. [Google Scholar] [CrossRef]
- Beleites, C.; Salzer, R.; Sergo, V. Validation of soft classification models using partial class memberships: An extended concept of sensitivity & co. applied to grading of astrocytoma tissues. Chemom. Intell. Lab. Syst. 2013, 122, 12–22. [Google Scholar] [CrossRef]
- Brier, G.W. Verification of forecasts expressed in terms of probability. Mon. Weather Rev. 1950, 78, 1–3. [Google Scholar] [CrossRef]
- Arfin, T.; Pillai, A.M.; Mathew, N.; Tirpude, A.; Bang, R.; Mondal, P. An overview of atmospheric aerosol and their effects on human health. Environ. Sci. Pollut. Res. 2023, 30, 125347–125369. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Distance-Domain Criterion ddc | Time-Domain Criterion dtc |
|---|---|---|
| RMSE | 0.29158 | 0.25895 |
| ACC | 0.91392 | 0.93171 |
| F1 | 0.64334 | 0.71851 |
| JS | 0.55719 | 0.62068 |
| AUC-PR | 0.36823 | 0.49563 |
| Batch Size | 1 | 2 | 4 | 8 | 16 | 32 | 64 |
| AUC-PR | 0.48306 | 0.49956 | 0.50189 | 0.50179 | 0.49798 | 0.49884 | 0.36113 |
| Metrics | Train | Validation | Test |
|---|---|---|---|
| RMSE | 0.22421 | 0.22535 | 0.24455 |
| ACC | 0.94863 | 0.94832 | 0.93929 |
| F1 | 0.78954 | 0.77734 | 0.75026 |
| JS | 0.69187 | 0.67932 | 0.65127 |
| AUC-PR | 0.62209 | 0.59820 | 0.55318 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nikezić, D.P.; Radivojević, D.S.; Lazović, I.M.; Mirkov, N.S.; Marković, Z.J. Transfer Learning with ResNet3D-101 for Global Prediction of High Aerosol Concentrations. Mathematics 2024, 12, 826. https://doi.org/10.3390/math12060826
Nikezić DP, Radivojević DS, Lazović IM, Mirkov NS, Marković ZJ. Transfer Learning with ResNet3D-101 for Global Prediction of High Aerosol Concentrations. Mathematics. 2024; 12(6):826. https://doi.org/10.3390/math12060826
Chicago/Turabian StyleNikezić, Dušan P., Dušan S. Radivojević, Ivan M. Lazović, Nikola S. Mirkov, and Zoran J. Marković. 2024. "Transfer Learning with ResNet3D-101 for Global Prediction of High Aerosol Concentrations" Mathematics 12, no. 6: 826. https://doi.org/10.3390/math12060826
APA StyleNikezić, D. P., Radivojević, D. S., Lazović, I. M., Mirkov, N. S., & Marković, Z. J. (2024). Transfer Learning with ResNet3D-101 for Global Prediction of High Aerosol Concentrations. Mathematics, 12(6), 826. https://doi.org/10.3390/math12060826