


LLE-NET: A Low-Light Image Enhancement Algorithm Based on Curve Estimation



Abstract
:1. Introduction
- A low-light image enhancement model(LLE-NET) based on curve estimation is proposed which estimates the control parameters of enhancement curves. LLE-NET eliminates the need for paired training data, mitigating the risk of overfitting and demonstrating strong generalization across diverse lighting conditions.
- Cubic curves and gamma correction are used in this enhancement method. If computing power permits, using a cubic enhancement curve can achieve fine results. If the computational burden is heavy, a method based on gamma correction for low-light image enhancement can be chosen.
- We conduct extensive experiments to validate the effectiveness of LLE-NET across a wide range of comparison methods and affirm its efficacy.
2. Related Work
2.1. Traditional Enhancement Methods
2.2. Learning-Based Methods
3. Proposed Method
3.1. Low-Light Enhancement Curve
- (1)
- The enhancement curve is required to be a continuously ascending function to maintain the contrast between adjacent pixels.
- (2)
- After normalizing the image, each enhanced pixel value should be confined within the range of [0, 1] to prevent overflow truncation.
- (3)
- The transformation function should aim for simplicity while remaining differentiable for efficient backpropagation.
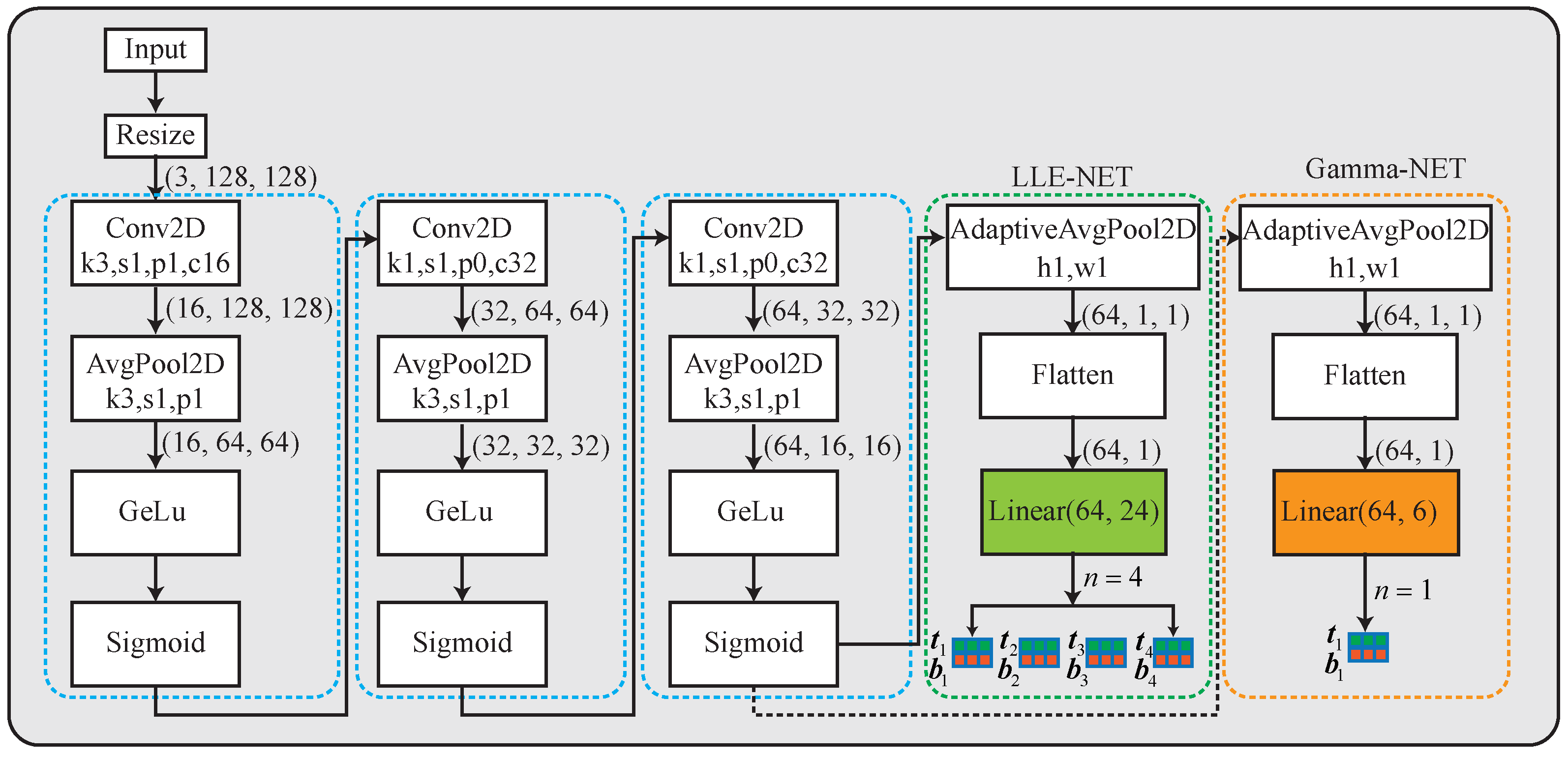
3.2. LLE-NET
3.3. Gamma-NET
3.4. Non-Reference Loss Function
4. Experiments
4.1. Implementation Details
4.2. Experimental Evaluation
4.3. Ablation Study
4.4. Effect of Parameter Setting
4.5. Effect of Training Data
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Moran, S.; Marza, P.; McDonagh, S.; Parisot, S.; Slabaugh, G. Deeplpf: Deep local parametric filters for image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12826–12835. [Google Scholar]
- Cai, J.; Gu, S.; Zhang, L. Learning a deep single image contrast enhancer from multi-exposure images. IEEE Trans. Image Process. 2018, 27, 2049–2062. [Google Scholar] [CrossRef] [PubMed]
- Yang, S.; Zhou, D.; Cao, J.; Guo, Y. LightingNet: An integrated learning method for low-light image enhancement. IEEE Trans. Comput. Imaging 2023, 9, 29–42. [Google Scholar] [CrossRef]
- Wu, W.; Weng, J.; Zhang, P.; Wang, X.; Yang, W.; Jiang, J. Uretinex-net: Retinex-based deep unfolding network for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5901–5910. [Google Scholar]
- Li, C.; Qu, X.; Gnanasambandam, A.; Elgendy, O.A.; Ma, J.; Chan, S.H. Photon-limited object detection using non-local feature matching and knowledge distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3976–3987. [Google Scholar]
- Wang, W.; Wang, X.; Yang, W.; Liu, J. Unsupervised face detection in the dark. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1250–1266. [Google Scholar] [CrossRef] [PubMed]
- Gao, H.; Guo, J.; Wang, G.; Zhang, Q. Cross-domain correlation distillation for unsupervised domain adaptation in nighttime semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9913–9923. [Google Scholar]
- Ye, J.; Fu, C.; Zheng, G.; Paudel, D.P.; Chen, G. Unsupervised domain adaptation for nighttime aerial tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8896–8905. [Google Scholar]
- Xin, Z.; Wang, Z.; Yu, Z.; Zheng, B. ULL-SLAM: Underwater low-light enhancement for the front-end of visual SLAM. Front. Mar. Sci. 2023, 10, 1133881. [Google Scholar] [CrossRef]
- Su, Y.; Wang, J.; Wang, X.; Hu, L.; Yao, Y.; Shou, W.; Li, D. Zero-reference deep learning for low-light image enhancement of underground utilities 3D reconstruction. Autom. Constr. 2023, 152, 104930. [Google Scholar] [CrossRef]
- Song, S.; Chen, W.; Liu, Q.; Hu, H.; Huang, T.; Zhu, Q. A novel deep learning network for accurate lane detection in low-light environments. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2022, 236, 424–438. [Google Scholar] [CrossRef]
- Tang, H.; Zhu, H.; Fei, L.; Wang, T.; Cao, Y.; Xie, C. Low-Illumination image enhancement based on deep learning techniques: A brief review. Photonics 2023, 10, 198. [Google Scholar] [CrossRef]
- Peng, B.; Zhang, X.; Lei, J.; Zhang, Z.; Ling, N.; Huang, Q. LVE-S2D: Low-light video enhancement from static to dynamic. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 8342–8352. [Google Scholar] [CrossRef]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-Light Image Enhancement via Illumination Map Estimation. IEEE Trans. Image Process. 2017, 26, 982–993. [Google Scholar] [CrossRef]
- Jobson, D.J.; Rahman, Z.u.; Woodell, G.A. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 1997, 6, 965–976. [Google Scholar] [CrossRef]
- Arici, T.; Dikbas, S.; Altunbasak, Y. A histogram modification framework and its application for image contrast enhancement. IEEE Trans. Image Process. 2009, 18, 1921–1935. [Google Scholar] [CrossRef] [PubMed]
- Kim, W. Low-light image enhancement: A comparative review and prospects. IEEE Access 2022, 10, 84535–84557. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Han, L.; Jiang, J.; Cheng, M.M.; Gu, J.; Loy, C.C. Low-light image and video enhancement using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 9396–9416. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Teng, B.; Yang, D.; Chen, Z.; Ma, H.; Li, G.; Ding, W. Learning a Single Convolutional Layer Model for Low Light Image Enhancement. IEEE Trans. Circuits Syst. Video Technol. 2023. [Google Scholar] [CrossRef]
- Lv, F.; Li, Y.; Lu, F. Attention guided low-light image enhancement with a large scale low-light simulation dataset. Int. J. Comput. Vis. 2021, 129, 2175–2193. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Loy, C.C. Learning to enhance low-light image via zero-reference deep curve estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4225–4238. [Google Scholar] [CrossRef] [PubMed]
- Wu, C.; Dong, J.; Tang, J. LUT-GCE: Lookup Table Global Curve Estimation for Fast Low-light Image Enhancement. arXiv 2023, arXiv:2306.07083. [Google Scholar]
- Dhal, K.G.; Das, A.; Ray, S.; Gálvez, J.; Das, S. Histogram equalization variants as optimization problems: A review. Arch. Comput. Methods Eng. 2021, 28, 1471–1496. [Google Scholar] [CrossRef]
- Ibrahim, H.; Kong, N.S.P. Brightness preserving dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 2007, 53, 1752–1758. [Google Scholar] [CrossRef]
- Chen, S.D.; Ramli, A.R. Preserving brightness in histogram equalization based contrast enhancement techniques. Digit. Signal Process. 2004, 14, 413–428. [Google Scholar] [CrossRef]
- Dhal, K.G.; Sen, M.; Das, S. Cuckoo search-based modified bi-histogram equalisation method to enhance the cancerous tissues in mammography images. Int. J. Med. Eng. Inform. 2018, 10, 164–187. [Google Scholar]
- Muniraj, M.; Dhandapani, V. Underwater image enhancement by modified color correction and adaptive Look-Up-Table with edge-preserving filter. Signal Process. Image Commun. 2023, 113, 116939. [Google Scholar] [CrossRef]
- Shi, Z.; Feng, Y.; Zhao, M.; Zhang, E.; He, L. Normalised gamma transformation-based contrast-limited adaptive histogram equalisation with colour correction for sand–dust image enhancement. IET Image Process. 2020, 14, 747–756. [Google Scholar] [CrossRef]
- Liu, R.; Ma, L.; Zhang, J.; Fan, X.; Luo, Z. Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10561–10570. [Google Scholar]
- Bao, S.; Ma, S.; Yang, C. Multi-scale retinex-based contrast enhancement method for preserving the naturalness of color image. Opt. Rev. 2020, 27, 475–485. [Google Scholar] [CrossRef]
- Zhang, W.; Dong, L.; Pan, X.; Zhou, J.; Qin, L.; Xu, W. Single Image Defogging Based on Multi-Channel Convolutional MSRCR. IEEE Access 2019, 7, 72492–72504. [Google Scholar] [CrossRef]
- Tian, F.; Wang, M.; Liu, X. Low-Light mine image enhancement algorithm based on improved Retinex. Appl. Sci. 2024, 14, 2213. [Google Scholar] [CrossRef]
- Lv, F.; Lu, F.; Wu, J.; Lim, C. MBLLEN: Low-Light Image/Video Enhancement Using CNNs. In BMVC; Northumbria University: Newcastle upon Tyne, UK, 2018; Volume 220, p. 4. [Google Scholar]
- Chen, C.; Chen, Q.; Xu, J.; Koltun, V. Learning to see in the dark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3291–3300. [Google Scholar]
- Chen, W.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. In British Machine Vision Conference; British Machine Vision Association: Glasgow, UK, 2018. [Google Scholar]
- Zhang, Y.; Guo, X.; Ma, J.; Liu, W.; Zhang, J. Beyond brightening low-light images. Int. J. Comput. Vis. 2021, 129, 1013–1037. [Google Scholar] [CrossRef]
- Ma, L.; Ma, T.; Liu, R.; Fan, X.; Luo, Z. Toward fast, flexible, and robust low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5637–5646. [Google Scholar]
- Hui, Y.; Wang, J.; Shi, Y.; Li, B. Low-light Image Enhancement Algorithm Based on Exposure Prediction and Hybrid Feature Weighted Fusion Strategy. Proc. J. Phys. Conf. Ser. 2022, 2281, 012017. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. Enlightengan: Deep light enhancement without paired supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef] [PubMed]
- Hui, Y.; Jue, W.; Li, B.; Shi, Y. Low light image enhancement algorithm based on improved multi-objective grey wolf optimization with detail feature enhancement. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 101666. [Google Scholar] [CrossRef]
- Zhu, A.; Zhang, L.; Shen, Y.; Ma, Y.; Zhao, S.; Zhou, Y. Zero-shot restoration of underexposed images via robust retinex decomposition. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Chen, L.; Chu, X.; Zhang, X.; Sun, J. Simple baselines for image restoration. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2022; pp. 17–33. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Mertens, T.; Kautz, J.; Van Reeth, F. Exposure fusion: A simple and practical alternative to high dynamic range photography. In Computer Graphics Forum; Wiley Online Library: Oxford, UK, 2009; Volume 28, pp. 161–171. [Google Scholar]
- Lee, C.; Lee, C.; Kim, C.S. Contrast enhancement based on layered difference representation of 2D histograms. IEEE Trans. Image Process. 2013, 22, 5372–5384. [Google Scholar] [CrossRef] [PubMed]
- Ma, K.; Zeng, K.; Wang, Z. Perceptual quality assessment for multi-exposure image fusion. IEEE Trans. Image Process. 2015, 24, 3345–3356. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Zheng, J.; Hu, H.M.; Li, B. Naturalness Preserved Enhancement Algorithm for Non-Uniform Illumination Images. IEEE Trans. Image Process. 2013, 22, 3538–3548. [Google Scholar] [CrossRef]
- Vonikakis, V. Busting Image Enhancement and Tonemapping Algorithms. Available online: https://sites.google.com/site/vonikakis/datasets (accessed on 1 January 2021).
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Blau, Y.; Michaeli, T. The perception-distortion tradeoff. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6228–6237. [Google Scholar]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “Completely Blind” Image Quality Analyzer. IEEE Signal Process. Lett. 2013, 20, 209–212. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Parameters (K) ↓ | GFLOPs ↓ | Time (s) ↓ |
|---|---|---|---|
| RetinexNet [35] | 555 | 587 | - |
| MBLLEN [33] | 450 | 301 | 21.9512 |
| EnlightenGAN [40] | 8000 | 273 | 16.1921 |
| RUAS [29] | 3.4 | 3.5 | 5.5745 |
| Zero-DCE [21] | 79 | 85 | 3.3182 |
| SCI medium [37] | 5.877 | 188 | 4.0959 |
| LLE-NET (ours) | 76 | 0.7515 | 2.9972 |
| Gamma-Net (ours) | 75 | 0.7517 | 2.8852 |
| Dataset | Method | PSNR ↑ | SSIM ↑ | MAE ↓ | LPIPS ↓ |
|---|---|---|---|---|---|
| DICM | MBLLEN | 18.2286 | 0.7271 | 1520.6005 | 0.1981 |
| RUAS | 10.7435 | 0.6088 | 6945.4501 | 0.3509 | |
| EnlightenGAN | 13.2887 | 0.6082 | 3434.5043 | 0.2353 | |
| Zero-DCE | 14.5836 | 0.6391 | 2500.3813 | 0.2292 | |
| SCI-medium | 9.4584 | 0.5115 | 8606.4664 | 0.4096 | |
| LLE-NET | 18.7514 | 0.7180 | 946.5415 | 0.2251 | |
| Gamma-Net | 14.1608 | 0.6352 | 2684.1659 | 0.2535 | |
| LIME | MBLLEN | 14.3632 | 0.5512 | 3060.0568 | 0.2800 |
| RUAS | 12.7033 | 0.5522 | 4184.1014 | 0.2390 | |
| EnlightenGAN | 10.4526 | 0.3762 | 6373.8652 | 0.3260 | |
| Zero-DCE | 12.7292 | 0.4673 | 3716.9237 | 0.3205 | |
| SCI-medium | 10.1090 | 0.3750 | 7311.8408 | 0.3533 | |
| LLE-NET | 16.6399 | 0.5587 | 1462.218 | 0.3071 | |
| Gamma-Net | 13.4485 | 0.5057 | 3055.1416 | 0.2880 | |
| MEF | MBLLEN | 16.1754 | 0.5963 | 1855.8897 | 0.2510 |
| RUAS | 12.0177 | 0.5755 | 4624.5877 | 0.2633 | |
| EnlightenGAN | 12.6525 | 0.4397 | 3934.1041 | 0.2906 | |
| Zero-DCE | 13.6976 | 0.4444 | 3034.4384 | 0.2999 | |
| SCI-medium | 10.2258 | 0.3960 | 6835.2636 | 0.3595 | |
| LLE-NET | 17.5471 | 0.5581 | 1225.4604 | 0.2759 | |
| Gamma-Net | 14.0117 | 0.4812 | 2702.0425 | 0.2818 | |
| NPE | MBLLEN | 19.5104 | 0.7448 | 1052.0196 | 0.1556 |
| RUAS | 10.3375 | 0.6025 | 6571.6485 | 0.3412 | |
| EnlightenGAN | 12.6337 | 0.6552 | 3783.2525 | 0.1888 | |
| Zero-DCE | 13.8611 | 0.6519 | 2817.4149 | 0.1813 | |
| SCI-medium | 9.0282 | 0.5091 | 8514.8493 | 0.3855 | |
| LLE-NET | 17.7302 | 0.7360 | 1128.3872 | 0.1813 | |
| Gamma-Net | 14.1781 | 0.545 | 2575.9487 | 0.3921 | |
| VV | MBLLEN | 17.7058 | 0.7113 | 1177.6664 | 0.3196 |
| RUAS | 11.2388 | 0.6107 | 5559.8106 | 0.4134 | |
| EnlightenGAN | 11.5388 | 0.4948 | 4728.1429 | 0.5199 | |
| Zero-DCE | 13.8369 | 0.5316 | 2820.4735 | 0.4026 | |
| SCI-medium | 9.8914 | 0.4629 | 7278.1504 | 0.5279 | |
| LLE-NET | 18.1330 | 0.6238 | 1042.4784 | 0.3763 | |
| Gamma-Net | 13.6904 | 0.6814 | 2819.8596 | 0.1903 | |
| Average | MBLLEN | 17.19668 | 0.67404 | 1733.2466 | 0.24086 |
| RUAS | 11.40816 | 0.58994 | 5577.1196 | 0.32156 | |
| EnlightenGAN | 12.11326 | 0.51482 | 4450.7738 | 0.31212 | |
| Zero-DCE | 13.74168 | 0.54686 | 2977.9263 | 0.2867 | |
| SCI-medium | 9.98208 | 0.42828 | 7373.39696 | 0.40196 | |
| LLE-NET | 17.76032 | 0.63892 | 1161.0171 | 0.27314 | |
| Gamma-Net | 13.8979 | 0.5697 | 2767.43166 | 0.28114 |
| Method | Average | DICM | LIME | MEF | NPE | VV |
|---|---|---|---|---|---|---|
| MBLLEN | 3.84/4.43 | 3.75/4.20 | 3.63/4.50 | 3.91/4.73 | 3.43/4.54 | 4.48/4.18 |
| RUAS | 3.54/4.59 | 3.83/4.78 | 3.09/4.23 | 2.77/3.69 | 3.87/5.68 | 4.14/4.60 |
| EnlightenGAN | 3.34/3.90 | 3.11/3.48 | 2.83/3.66 | 2.45/3.22 | 2.96/4.11 | 5.35/5.01 |
| Zero-DCE | 2.94/3.60 | 3.08/3.60 | 3.00/3.95 | 2.43/3.28 | 2.86/3.93 | 3.33/3.22 |
| SCI-medium | 3.03/3.65 | 3.51/3.79 | 2.99/4.18 | 2.56/3.44 | 2.56/3.44 | 3.55/3.42 |
| LLE-NET | 3.15/3.80 | 3.19/3.75 | 3.00/3.95 | 2.88/3.52 | 3.09/4.39 | 3.61/3.39 |
| Gamma-Net | 3.11/3.73 | 3.17/3.69 | 3.19/3.99 | 2.76/3.38 | 3.52/3.32 | 2.96/4.25 |
| (40, 15, 5, 8) | (30, 15, 5, 8) | (40, 0, 5, 8) | (40, 15, 0, 8) | (40, 15, 5, 0) | |
|---|---|---|---|---|---|
| PI↓ | 2.9957 | 3.21121 | 3.1610 | 3.0962 | 3.0469 |
| NIQE↓ | 3.948 | 4.2345 | 4.2512 | 3.9505 | 3.9963 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, X.; Yu, J. LLE-NET: A Low-Light Image Enhancement Algorithm Based on Curve Estimation. Mathematics 2024, 12, 1228. https://doi.org/10.3390/math12081228
Cao X, Yu J. LLE-NET: A Low-Light Image Enhancement Algorithm Based on Curve Estimation. Mathematics. 2024; 12(8):1228. https://doi.org/10.3390/math12081228
Chicago/Turabian StyleCao, Xiujie, and Jingjun Yu. 2024. "LLE-NET: A Low-Light Image Enhancement Algorithm Based on Curve Estimation" Mathematics 12, no. 8: 1228. https://doi.org/10.3390/math12081228
APA StyleCao, X., & Yu, J. (2024). LLE-NET: A Low-Light Image Enhancement Algorithm Based on Curve Estimation. Mathematics, 12(8), 1228. https://doi.org/10.3390/math12081228