1. Introduction
For a studied process, forecasting as a procedure consists of four consecutive stages: modeling (model design), learning (estimation of model characteristics), testing (of the “learned” model) and prediction of future development.
Forecasting is based on retrospective data analysis with its subsequent extrapolation to future periods. Consider the state of a studied process at moment , and suppose that the problem is to forecast further evolution of the process on a time interval . Then, it is necessary to operate existing data on its past dynamics on a time interval , where (the so-called retrospective data). Generally, retrospective data and the time interval are divided into two groups, namely data serving for the estimation of the model’s characteristics (on a time interval ) and model testing (on a time interval ).
There exist at least three forecasting techniques differing in the objectification degree of constructed forecasts. The
first technique, referred to as
scenario forecasting [
1], proceeds from the scenario approach whose objectification is replaced by the opinion of an expert group. Actually, it implements only the stages of modeling and prediction: learning and testing are eliminated owing to the opinion of experts, who choose an appropriate mathematical model of a studied process and form value sets (scenarios) of the model parameters. Then, the model with the scenario parameter values generates forecasting trajectories. As a matter of fact, such a forecasting technique is most widespread in demographic prediction [
2,
3,
4]. Note that real retrospective data about a studied process are not utilized. They are indirectly reflected by the knowledge and experience of invited experts.
The
second technique of forecasting explicitly involves real data for model learning and testing. The framework of mathematical statistics provides numerous estimation methods for model parameters; see [
5,
6,
7,
8]. Here, a major assumption is that the model possesses deterministic parameters, the values of which are defined using sets of real retrospective data. The latter are treated as a stochastic object with certain properties (a sample from a universe, normal distribution,
etc.). In this case, one may assign different probabilistic characteristics (variances, confidence intervals, and so on) to the derived estimates of model parameters.
Sometimes, these characteristics assist in constructing the probabilistic characteristics of forecasting trajectories. The described technique will be termed
probabilistic forecasting (PF) [
9,
10,
11,
12,
13,
14]. We emphasize that the above hypotheses regarding the stochastic properties of real datasets are almost impossible to verify, especially under small data arrays. It follows for the low efficiency of forecasts [
15,
16].
Finally, the third technique of forecasting proposed in this paper stems from the randomized model (RM) of a studied process, where model parameters are supposed random. Hence, we characterize RMs using the probability density functions (PDFs) of their parameters. At the learning stage, the PDFs of the model parameters are estimated on the basis of real retrospective data.
A randomized model generates an ensemble of forecasting trajectories, where each trajectory corresponds to a set of random realizations of parameters with the derived estimates of the PDFs. Computer simulation of such models employs the Monte Carlo method. Below, this technique will be called randomized forecasting (RF).
As opposed to existing methods [
17,
18,
19], the proposed method of randomized forecasting is based on entropy-optimal estimations of PDFs for real datasets. The structure of the randomized dynamic model, used in this method, is based on ordinary differential equations.
The developed method serves for obtaining randomized predictions of the World population dynamics. Modeling the World population variations in time and space forms a major problem of demographic analysis [
20,
21,
22].
Throughout the paper, we describe the above mentioned dynamics by the exponential model incorporating several parameters associated with fertility and mortality rates, as well as its change in time. In the randomized setting, they are assumed random, whereas World population is measured with random errors. To find the corresponding PDFs, the method involves the retrospective population data provided by the UN (see UNdata service at
https://data.un.org/). In addition, we perform the comparative analysis of the PF- and RF-based approaches.
2. Randomized Model: Linear Differential Form
Consider a dynamic object having an input and an output . The components of the input and output vectors can be observed (measured) on a time interval .
The relationship between the input and output of the object is described by the linear nonautonomous system of ordinary differential equations:
where
;
;
and
denote matrices of appropriate dimensions.
The object’s output is observed with inevitable disturbances modeled by a vector noise
. Therefore, the observed output of the model acquires the form:
where
.
Equations (1) and (2) define a
linear dynamical randomized model (LDRM) if:
the matrix
A is a random matrix (with independent random elements or elements with independent random components) of the interval type:
where
mean given matrices;
there exists a probability density function (PDF) ;
the vector
is a random vector (
i.e., contains independent random components) of the interval type:
there exists a probability density function (PDF) ;
the matrix B possesses fixed known elements.
Under the stated conditions, the LDRM generates an ensemble of random trajectories on the time interval .
Let us rewrite the LDRM (2) in the input-output representation using the notion of matrix exponent [
23]:
The input and output are measured at discrete moments with step
h. Hence, on the time interval
, we have:
here
and
indicates the integer part of •.
The LDRM output Equation (3) observed at discrete moments has the following form:
Let us denote
. They are random vectors with independent and interval components. Now, we introduce the block-vector
. As we assume that these vectors and their components are independent, then the joint PDF is:
The domain of this function is:
Here, gives a sequence of n-dimensional independent random vectors of the interval type, associated with corresponding PDFs.
As soon as the matrix A and the noise vector are random and characterized by the PDFs and , respectively, so the observed output of the LDRM represents an ensemble of random trajectories .
3. Entropy-Robust Estimation
The first stage of the randomized forecasting (RF) is an estimation of the PDFs of the RMs’ parameters and of the measurement noises. It is a classical problem of the Bayesian approach, and there exists the classical maximum likelihood method (or maximum relation of likelihood; see [
6]) for its solving.
Let us recall the definition of the function of the relation of likelihood (FRL) in the terms of
Section 2. The
a priori PDFs
and the
a posteriori PDFs
are the basic notations of the FRL. The FRL takes the form:
If the PDFs in these expressions are restored as functions of the parameters, then maximization of these functions gives “optimal” estimations. The principle of maximization of the FRL takes the form:
As a declaration, this principle is fine. However, how is it possible to restore the PDFs and (also and )? The problem of the restoration of the PDFs remains outside of the FRL.
Let us consider the
functional of the likelihood relation (FuRL) in the following form:
From Equation (12), we can see that the FuRL is the mathematical expectation of the FRL. On the other side, the FuRL is the opposite generalized information Boltzmann entropy (Kullback–Leibler distance) [
24,
25], that is:
According to [
26], maximization of entropy functions gives the best robust solution under high uncertainty. This idea with the addition of real data balance conditions forms the basis of the
entropy-robust estimation method [
27].
The
entropy-robust estimation can be reformulated as a problem of functional nonlinear programming [
28,
29]:
subject to the constraints imposed on:
- -
the class of (normalized) PDFs:
- -
the balance between the first moment vector of the observed output
in the LDRM Equation (7) and the real data vector
:
where:
entropy-robust estimation uses the first moment vector of the output LDRM. It is possible to use moments of higher order. This depends on measurable real data. If they represent the k-moment, then the balance condition can be formulated in the following form:
where
is a vector of
k-moment components. In this case, we will have
entropy-robust estimation.
The problem Equations (14)–(17) are related to the Lyapunov problem [
28,
29] where the goal functional and constraints are of an integral type. Here, we will use the necessary condition of equality to zero of the integral equation:
where the function
is continuous and is equal to zero on the boundary of the set
X (the class
); the function
is differentiable (the class
). Then, this equality will be valid
for any function with the mentioned properties if:
Now, we return to the problem Equations (14)–(17) and introduce the Lagrange functional:
where:
Sign denotes a scalar product.
As the solution of the problem Equations (14)–(17) is searched in the class of differentiable functions, then the Gato derivation can be used for determination of the variation of Lagrange functional Equation (21).
Let us denote the solution of the problem Equations (14)–(17) as
and
. Furthermore, introduce the functions
and two scalar variables
to present the functions
in the following form:
Functions
, as a solutions of the problem Equations (14)–(17), are fixed. The optimality conditions for the problem Equations (14)–(17) take the form:
The application of these conditions leads to the following systems of integral equations:
According to Equations (
19) and (
20), we obtain the following equations, which are necessary optimality conditions (necessary conditions of Lagrangian-stationarity) for the problem Equations (14)–(17):
The solution of the problem Equations (14)–(17) takes the form:
where:
The vectors of Lagrange multipliers are determined from the following equations:
Calculation of the vectors
is turned into a search for the global minimum of the residual function:
A global optimization algorithm is based on the simple Monte Carlo trials proposed in [
30]. However, as soon as the
metric is a convex function, one of the traditional gradient-based local optimization methods can be used for its solving.
4. Randomized Forecast Implementation
We comprehend a randomized forecast as an ensemble of trajectories on a forecasting interval , which has to be generated using the model Equations (6) and (7) with the random matrix A and noise described by the PDFs and , respectively; see formulas Equations (27) and (28). The matrices A and the vector noise belong to the parallelepipeds from Equation (3) and Ξ from Equation (4), respectively.
Let us study the generation problem of random matrices with the PDF Equation (27). First, we transform a matrix into a vector through concatenation of its rows. This procedure yields a vector
of length
. Additionally, the domain of random matrices becomes an
m-dimensional parallelepiped:
where the vectors
and
result from the row concatenation of the matrices
and
, respectively.
Lets consider a transformation of a vector
into a vector
belonging to the
m-dimensional unit nonnegative cube
:
Therefore, the entropy-optimal PDF undergoes the following chain of transformations:
Therefore, it is necessary to generate random vectors
with PDFs
. The generation was implemented by the acceptance-rejection algorithm [
24].
5. Application of the RF Method for World Population Prediction
5.1. The World Population Prediction Problem
The state of an isolated population is characterized by its size
on a calendar time interval
. Population size varies under the impact of fertility and mortality processes, since World population is an isolated system. Within the framework of the linear population dynamics model, fertility and mortality are described by corresponding rates, whereas the flows of newborns and decedents appear proportional to population size, while fertility (b) and mortality (m) rates are considered as linear time-dependent parameters [
22].
5.1.1. Randomized population model
World population evolves according to the following differential equation that has an analytical solution:
Real measurements of the population size dynamics modeled by Equation (34) take place at discrete moments. Hence, the population size at discrete moments
(where
h specifies a given increment) is defined by the expression:
with parameters
r and
, which describe the result of the difference between fertility and mortality flows.
World population is measured in billions of people. Fertility and mortality processes aggregate many factors, including measurement errors, whose quantitative analysis is impossible or complicated. On the other hand, the mass nature of fertility and mortality processes admits their modeling based on the probabilistic approach.
Thus, the resultant flow rate and its changing in time are supposed to be random variables with a joint probability density function
defined on the rectangle:
Generally, measurement errors are modeled by an additive noise
of the interval type:
where
I indicates a time interval of such measurements. By assumption, the PDFs
are specified on the intervals
from Equation (37). Due to the independence of the set of random variables
, their joint PDF has the form:
Therefore, the
randomized model of World population dynamics can be described by:
where the function
meets Equality (35).
5.1.2. Real and forecasting data
The entropy-optimal RM is tested via the measurements of the World population dynamics during the period from 1995–2015 and the values
for this period (according to the UN forecast announced in 1985) (
http://www.irbis.vegu.ru/repos/1002/Html/27.htm; see
Table 2).
The World population prediction till 2050 using the UN data is illustrated by
Table 3 (
http://data.un.org/; [
31]). United Nations’ projections both for the testing interval and the forecasting interval were made in accordance with the commonly-used cohort-component method, based on age-specific estimates of the components of population change (fertility, mortality and international migration) [
32,
33]. We will compare this prediction with its randomized analog.
World population is measured in billions of people. In the sequel, the subscript indicates the measured data of the population.
To summarize, the RM has the following forms on corresponding time intervals:
on the estimation interval
(see
Table 1):
on the testing interval
(see
Table 2):
on the forecasting interval
(see
Table 3):
where
r and
are random parameters with the entropy-optimal PDFs
and
is a vector of random noise with entropy-optimal PDF
.
5.1.3. The entropy-optimal PDFs of the parameters and noise
According to the general entropy-robust estimation procedure of PDFs (see
Section 2), we have:
the PDF of the parameters
r and
in the form:
the PDF of the noise in the form:
where:
To calculate the Lagrange multipliers, we will solve the system of balance equations (see Equations (16) and (17):
Then, Equation (47) can be rewritten as:
where:
We endeavor to solve these equations through minimizing the residual function:
5.2. The Results of Computer Experiment
5.2.1. General conditions
We have performed calculations for the stages of estimation, testing and prediction with the following ranges for the model parameters, which include the possibility for both positive and negative trends of World population growth:
and identically the range for the measurement noises:
Under the above ranges of the model parameters and measurement noises, the computer experiment has constructed the entropy-optimal PDFs and generated the ensembles of corresponding random trajectories for RM testing and randomized forecasting.
5.2.2. Estimation
On the estimation interval, we employ the data from
Table 1. The residual function
Equation (51) is a function of eight variables, and it contains integral component Equations (45)–(49) to be estimated only numerically. For this, we have selected the so-called tiled method of two-dimensional integral estimation, which represents a combination of several quadrature formulas [
34].
The idea of the tiled method consists of: (1) partitioning the whole domain of integration into a set of smaller-area subdomains having the rectangular or trapezoidal shape; and (2) applying appropriate quadrature formulas on each subdomain. The described method is implemented in MATLAB by the function quad2d.
Minimization of the residual function
(51) runs by the nonlinear trusted region method implemented by the function
lsqnonlin from the package
Optimization Toolbox. The function
lsqnonlin has been optimized [
35] for nonlinear least-squares problems.
The function
lsqnonlin have several user-defined options for stopping criteria, such as function evaluation tolerance (
), step size tolerance (
) and maximum number of iterations (500).
Table 4 presents the calculated Lagrange multipliers for the above ranges.
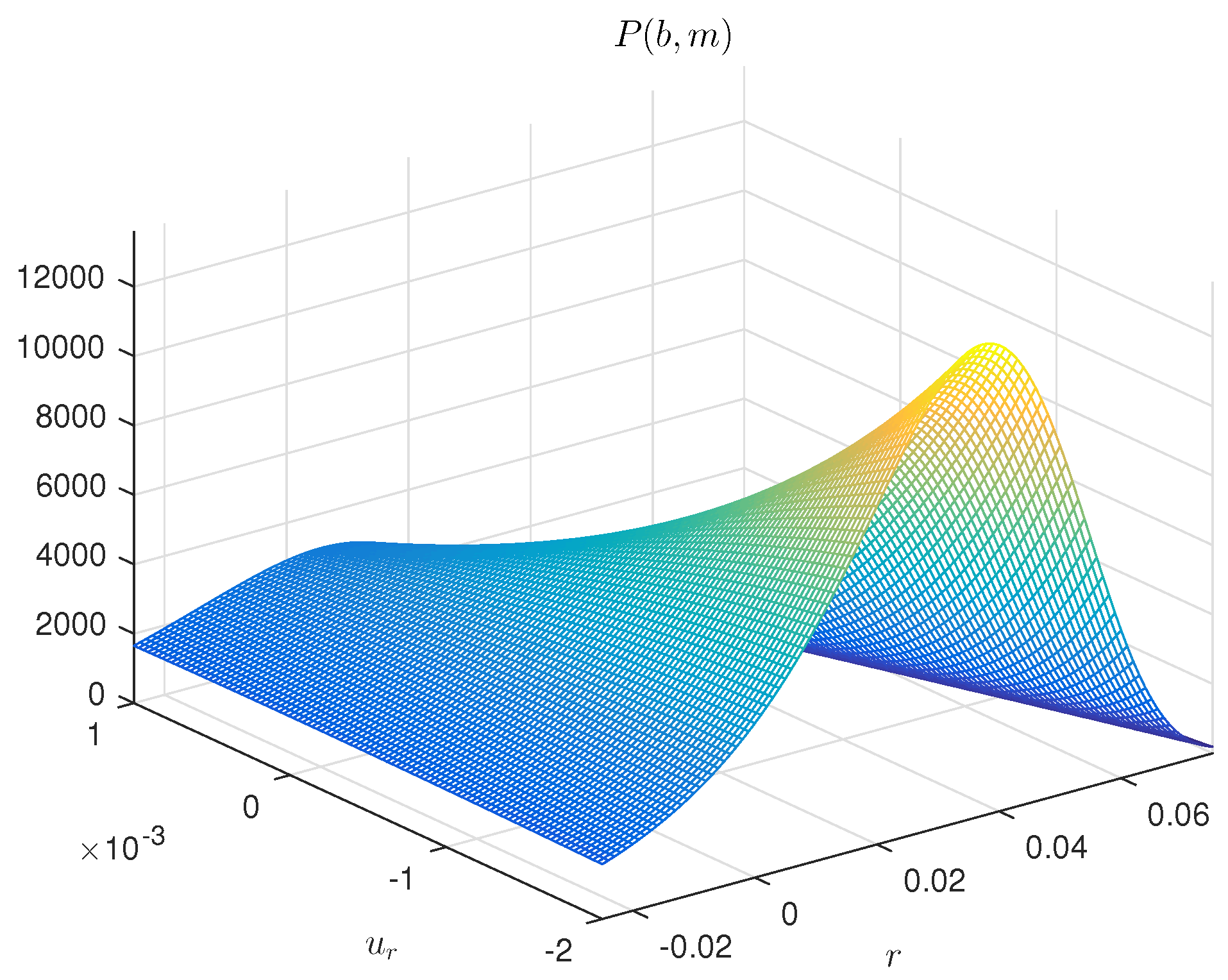
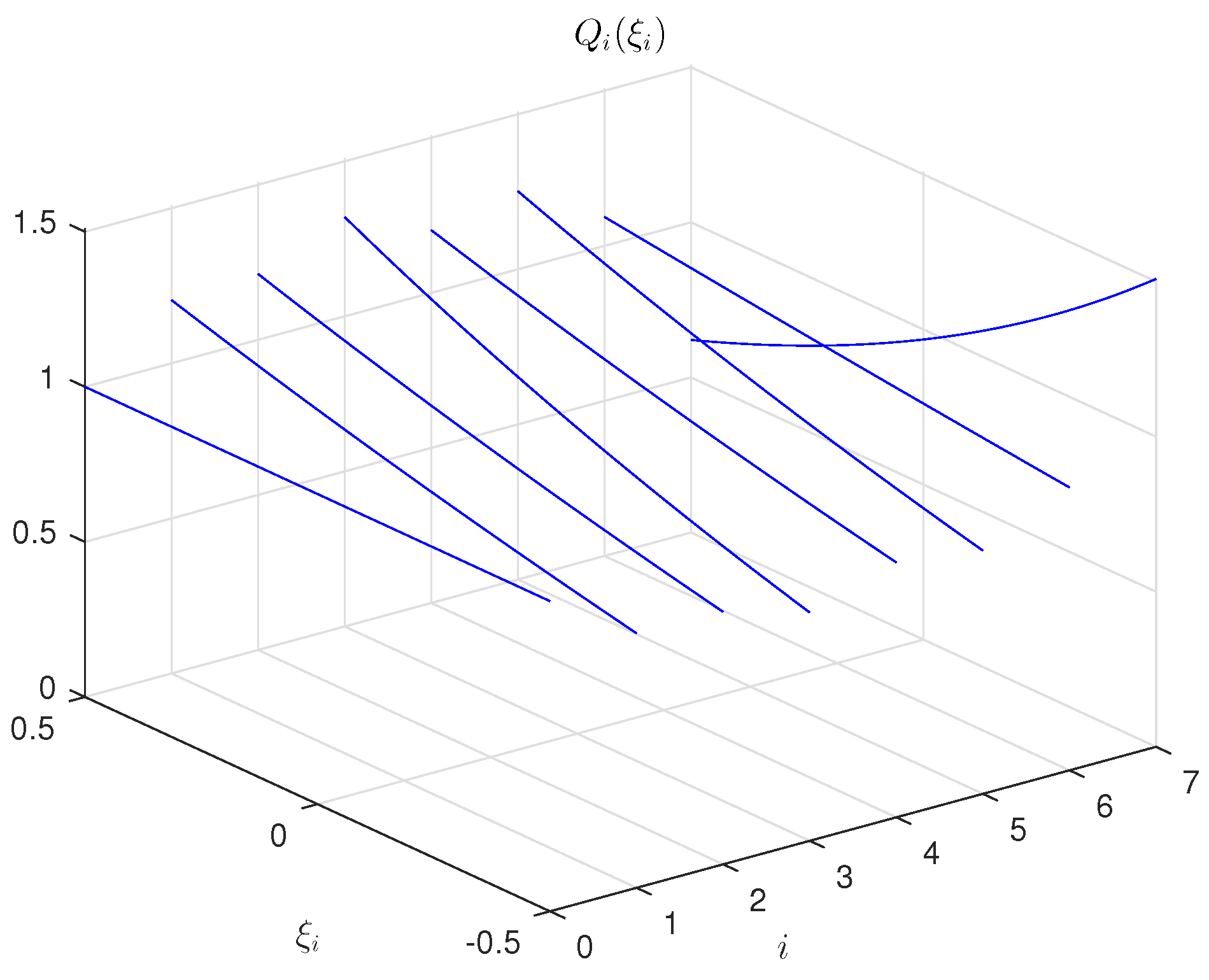
Figure 1 and
Figure 2 demonstrate the entropy-optimal PDFs for the parameters of Model (35) and noise components. The functions
and
represent an entropy-optimal distribution of random variables at the corresponding intervals and will be used for making randomized predictions.
5.2.3. Testing
Testing of the model has been made using the data from
Table 2. The population size has been evaluated by the Formula (41), where
are the random variables with the PDF
and
are the random noises with the PDFs
(see
Figure 1 and
Figure 2).
To generate an ensemble of random variables, the two-dimensional modification of the Ulam–von Neumann method has been used [
24]. The size of the generated sample is
100,000.
Each pair of the random values r and defines a separate exponential growth curve; moreover, for each point , a random value of the noise is added according to its PDF. As a result, the constructed trajectory of World population dynamics is not an exponential function.
The test procedure yields the probabilistic characteristics of the parameters
r,
and
ξ. It depends on the initial population size for the testing interval.
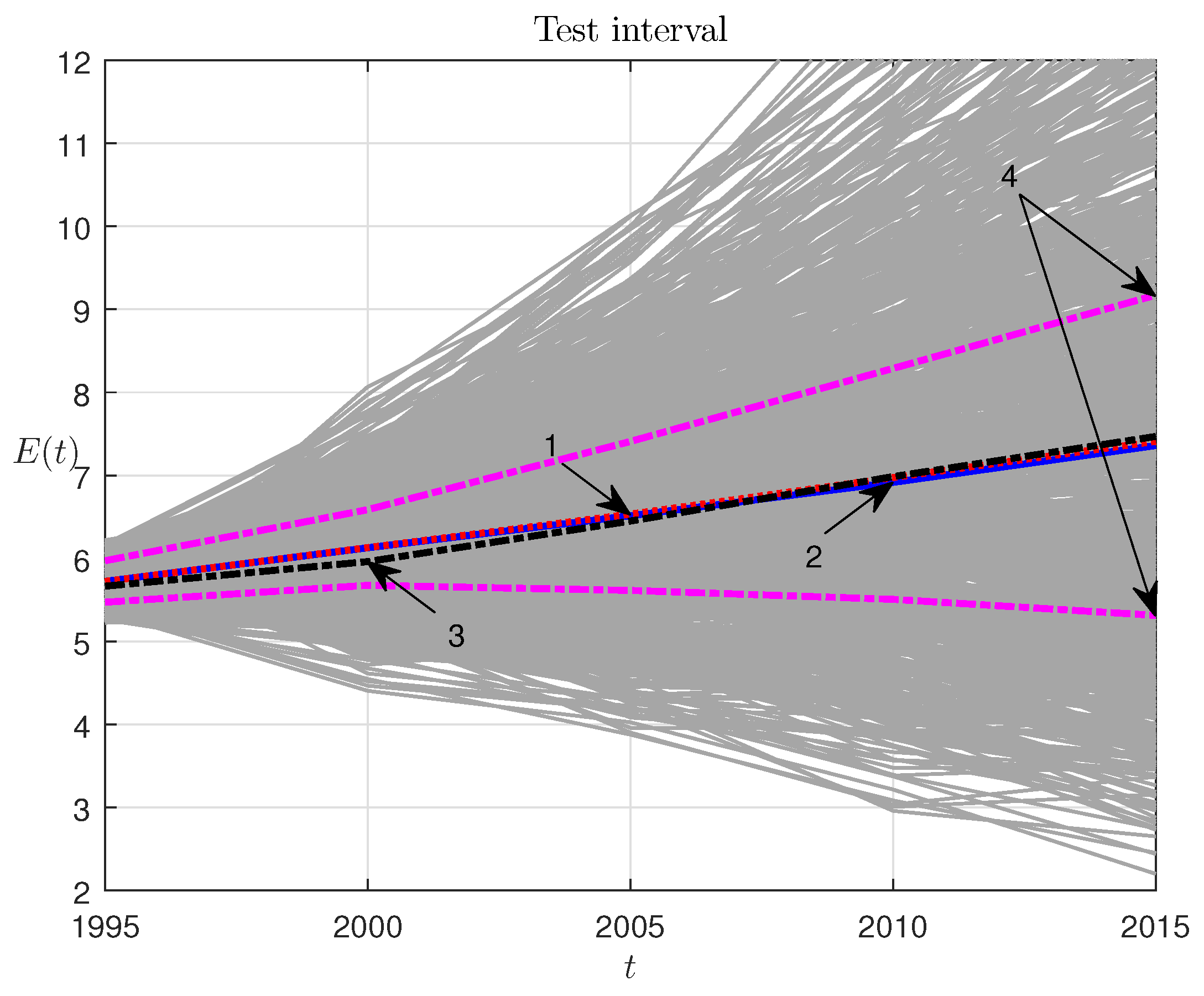
Figure 3 shows the ensemble of the model-based trajectories for the parameter range from Equation (52) and the noise range from Equation (53), with a data-based selection of the initial point:
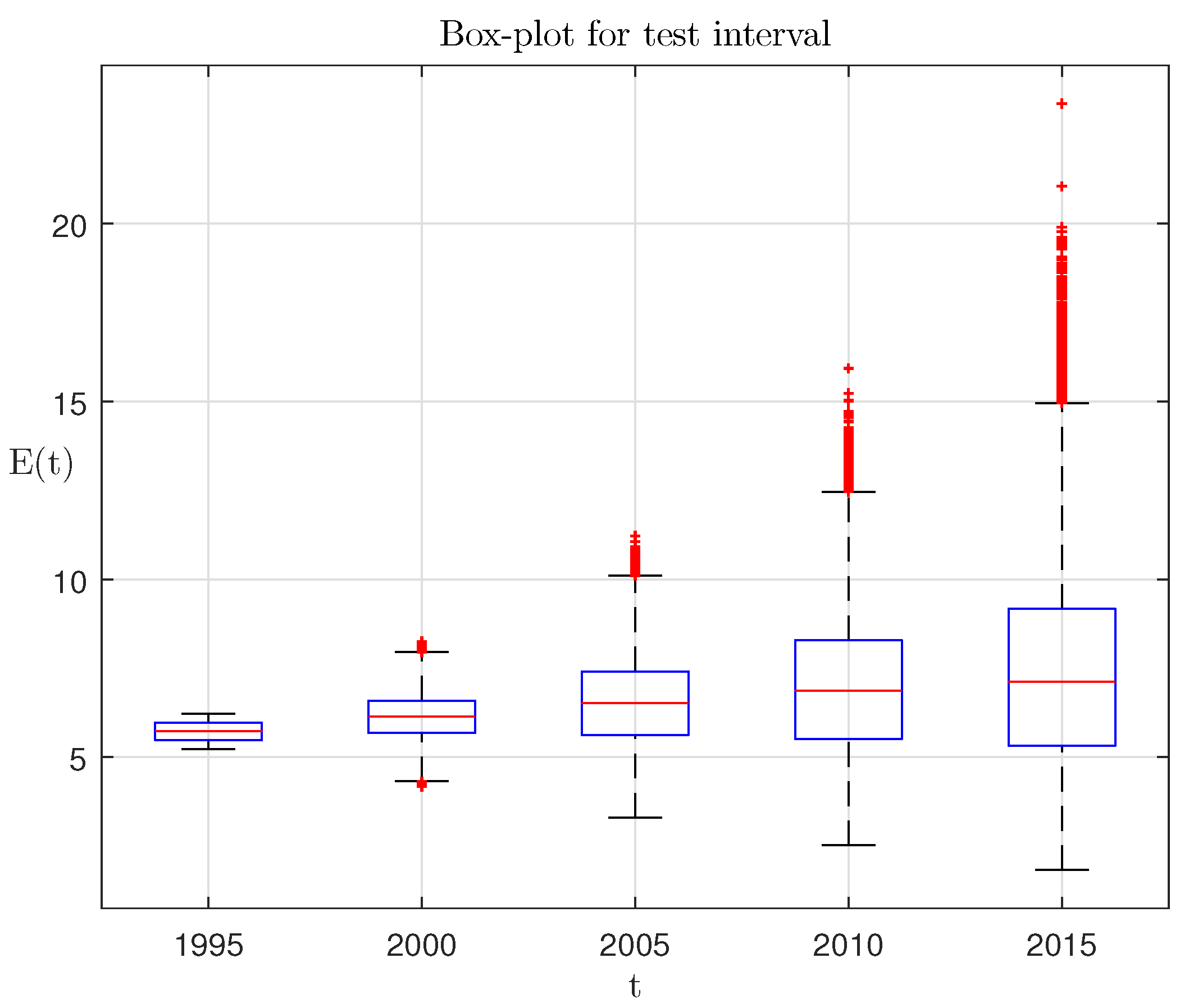
Figure 3 has the following notation: 1, the ensemble-average trajectories of population dynamics; 2, real population dynamics on the testing interval; 3, population dynamics on the testing interval according to the UN forecast of the year 1998; 4, the boundaries of the first and the third quartiles. The same model-generated ensemble for testing interval can be presented as a box plot with median mark and interquartile ranges; see
Figure 4.
Testing quality is assessed by the root-mean-square error of the average trajectory with respect to its real counterpart:
as well as by the relative error:
For instance, the UN forecast for the testing interval (
Table 2) has the following errors:
In our case, the deviation of the model-average trajectory from the real one (
Figure 3) appears to be appreciably smaller and demonstrates the following errors:
5.2.4. Prediction
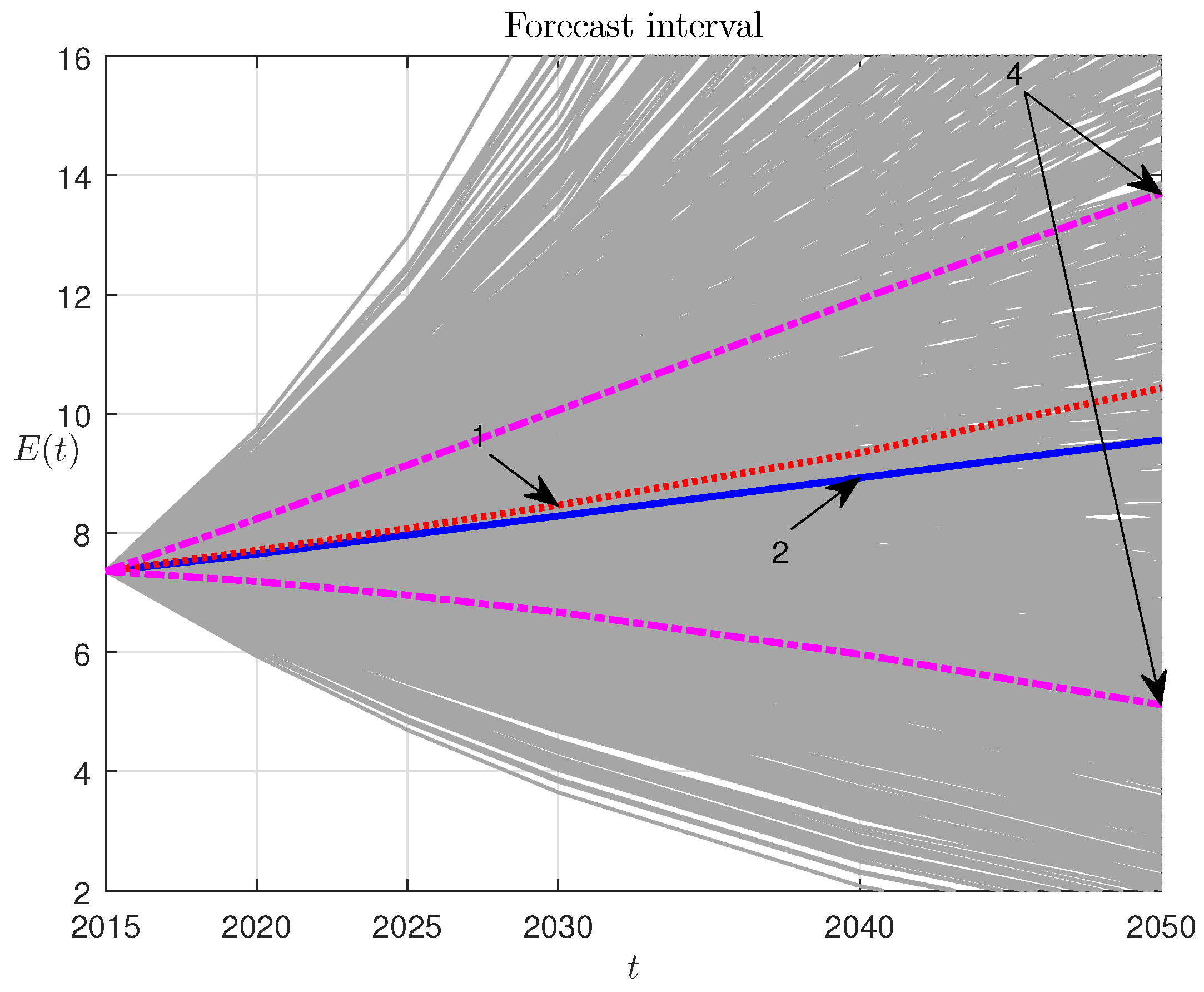
This simple RM has been applied to predict World population dynamics for the period from 2015–2050. The trajectory ensemble corresponding to the UN predictions (
Table 3) is illustrated by
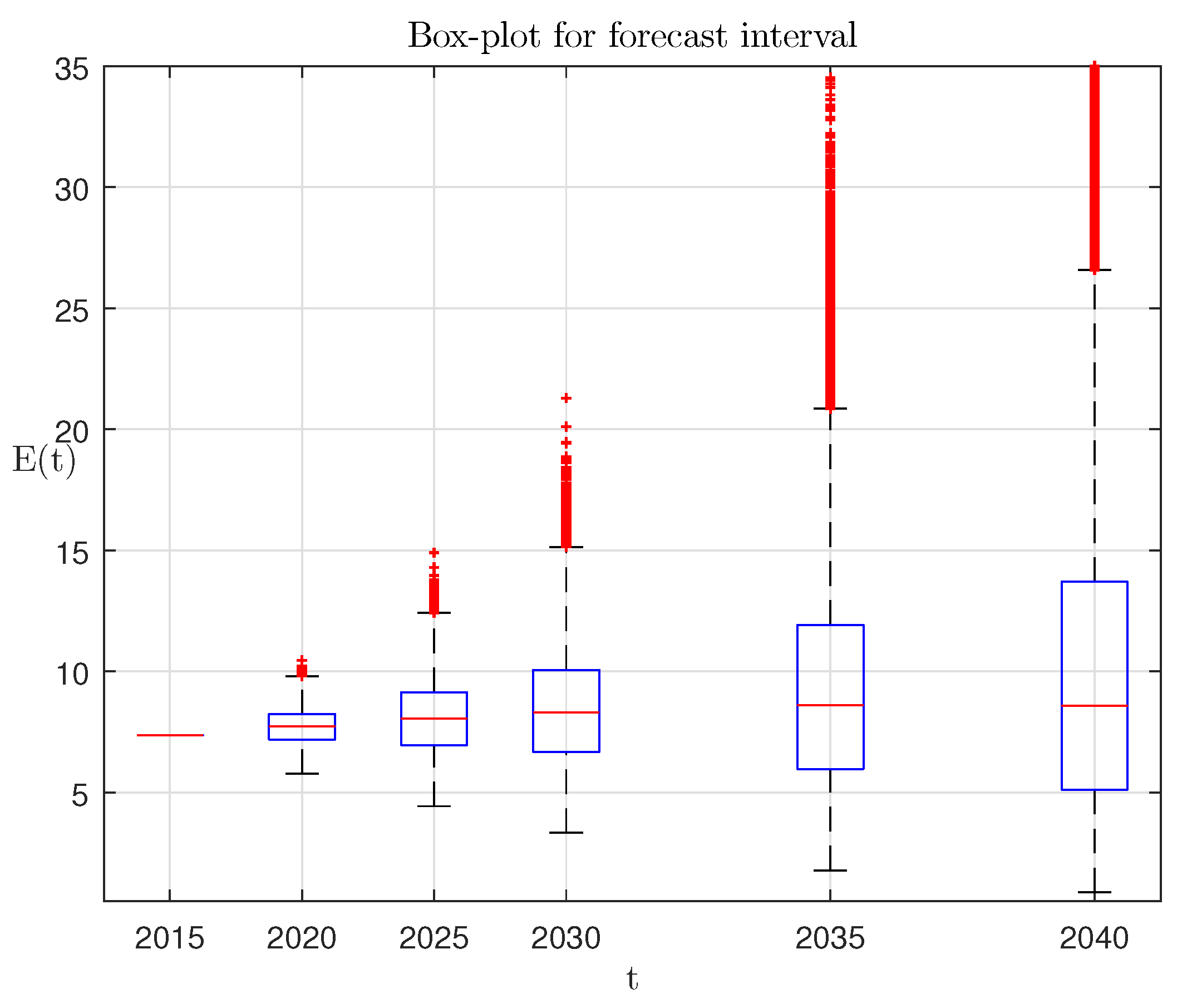
Figure 5: 1, the ensemble-average trajectory; 2, UN projection; 4, the boundaries of the interquartile range (IQR zone). The corresponding box-plot is presented in
Figure 6.
The presented results testify that the randomized forecasting as opposed to existent methods gives a set of probability characteristics of the World population prediction, which is calculated by using the ensemble of prognostic trajectories. The latter is generated by the randomized dynamic model with entropy-optimal PDFs of parameters. The randomized projection algorithm shows significantly closer to real data numerical results for testing interval, as well as stable projection that is higher, but close to the modern UN forecast for the future. According to our randomized model, 2026 will be the first eight billion year.
6. Conclusions
In this paper, we have suggested a randomized forecasting method that operates dynamic models described by linear ordinary differential equations with random parameters. Entropy-robust estimation has been developed for the probability density functions (PDFs) of model parameters and noisy measurements based on entropy maximization. It has been shown that the above PDFs belong to the exponential class. The randomized forecasting technique has been applied to randomized prediction of the World population dynamics. It has been demonstrated that randomized forecasting gives a set of probability characteristics of the World population dynamics.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}