Comparative Analysis of Machine Learning Models for Prediction of Remaining Service Life of Flexible Pavement

 ,
,  , ,
, ,  ,
,  and
and
Abstract
:1. Introduction
2. Literature Review
- First category: Models that predict the RSL based on the response (stress and strain) of pavement to the applied loads.
- Second category: Models that predict the RSL based on pavement quality indices.
- Third category: Models that predict the RSL based on the results of pavement non-destructive tests.
3. Methodology
3.1. Pavement Condition Index (PCI)
3.2. Remaining Service Life (RSL)
- The remaining time to reach a level of distress when the pavement needs to be rehabilitated or reconstructed. For example, the Minnesota Department of Transportation (MnDOT) defines the RSL as the time until the next major rehabilitation.
- The time until pavement conditions reach a specific condition index limit. For example, the Michigan Department of Transportation (MDOT) defines the RSL based on the Michigan Ride Quality Index, assuming an RSL of zero when the said index is 50.
3.3. Machine Learning Techniques
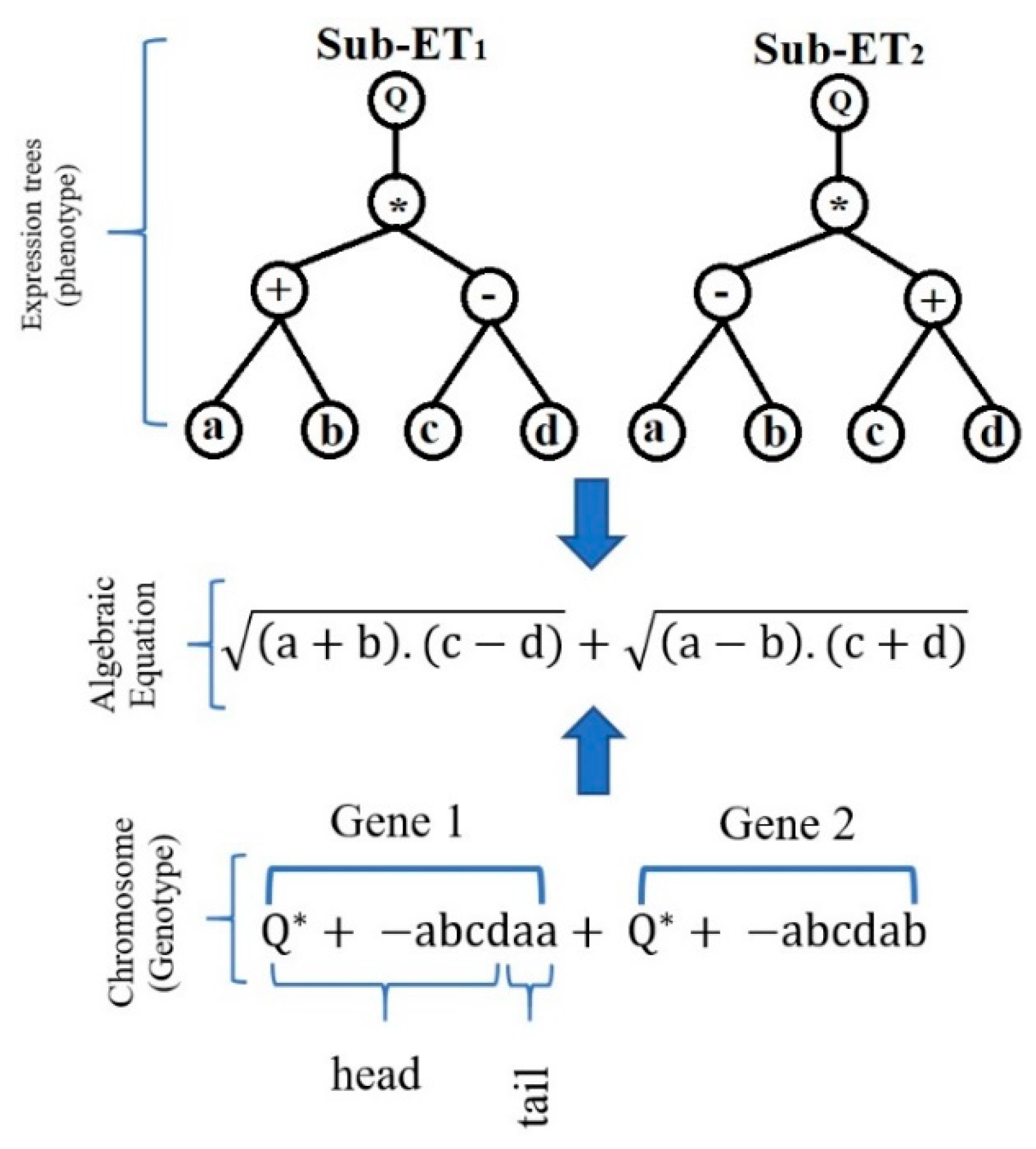
3.3.1. Gene Expression Programming (GEP)
3.3.2. Support Vector Regression (SVR)
- : this parameter supervises the width of the -insensitive zone, used to fit the training data. The value can affect the number of support vectors used to build the regression function. For the bigger , estimates are more ‘flat’, and the fewer support vectors are chosen.
- C: this parameter specifies the trade-off between the complexity of the model and the grade to which deviations larger than are bearable in optimization formulation.
- : this parameter determines the relation between error minimization and smoothness of the estimated function.
3.3.3. Fruit Fly Optimization Algorithm (FOA)
3.4. Case Study
4. Results and Discussion
- Blue contoursIt shows the Pearson correlation coefficient.
- Orange contoursIt indicates the RMS error that is proportional to the distance from a green spot on the horizontal axis called observed.
- Black contoursIt indicates the standard deviation proportional to the radial distance from the center.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Acronyms
| Abbreviation | Description |
| RSL | Remaining Service Life |
| PCI | Pavement Condition Index |
| FWD | Falling Weight Deflectometer |
| GPR | Ground Penetrating Radar |
| SVR | Support Vector Regression |
| SVR-FOA | Support Vector Regression Optimized by Fruit Fly Optimization Algorithm |
| GEP | Gene Expression Programming |
| CC | Correlation Coefficient |
| NSE | Nash–Sutcliffe Efficiency |
| SI | Scattered Index |
| WI | Willmott’s Index of agreement |
| PMSs | Pavement Management Systems |
| MR&R | Maintenance, Rehabilitation, and Reconstruction |
| IRI | International Roughness Index |
| PSI | Present Serviceability Index |
| PSR | Present Serviceability Ratio |
| ANN | Artificial Neural Network |
| SVM | Support Vector Machine |
| RBF | Radial Basis Function |
| GEP | Gene Expression Programming |
| RT | Regression Tree |
| RF | Random Forest |
| GP | Genetic Programming |
| AMS | Assessment Management System |
| DV | Deduct Value |
| CDV | Corrected Deduct Value |
| TDV | Sum of DVs |
| MnDOT | Minnesota Department of Transportation |
| MDOT | Michigan Department of Transportation |
| HWD | Heavy Falling Weight Deflectometer |
| GA | Genetic Algorithm |
| ETs | Expression Trees |
| ORF | Open Reading Frame |
| RRSE | Root Relative Squared Error |
| RSE | Relative Square Error |
| RMSE | Root Mean Square Error |
| MSE | Mean Square Error |
| SVM | Support Vector Machine |
| SRM | Structural Risk Minimization |
| ERM | Empirical Risk Minimization |
| FOA | Fruit Fly Optimization Algorithm |
References
- Ziari, H.; Maghrebi, M.; Ayoubinejad, J.; Waller, S.T. Prediction of pavement performance: Application of support vector regression with different kernels. Transp. Res. Rec. 2016, 2589, 135–145. [Google Scholar] [CrossRef]
- Ismail, N.; Ismail, A.; Atiq, R. An overview of expert systems in pavement management. Eur. J. Sci. Res. 2009, 30, 99–111. [Google Scholar]
- Marcelino, P.; de Lurdes Antunes, M.; Fortunato, E.; Gomes, M.C. Machine learning approach for pavement performance prediction. Int. J. Pavement Eng. 2019, 12, 1–14. [Google Scholar] [CrossRef]
- Butt, A.A.; Shahin, M.Y.; Feighan, K.J.; Carpenter, S.H. Pavement Performance Prediction Model Using the Markov Process; Transportation Research Board: New York, NY, USA, 1987. [Google Scholar]
- Bianchini, A.P. Bandini, Prediction of pavement performance through neuro-fuzzy reasoning. Comput. Aided Civ. Infrastruct. Eng. 2010, 25, 39–54. [Google Scholar] [CrossRef]
- Broten, M. Local Agency Pavement Management Application Guide; Wiley: New York, NY, USA, 1997. [Google Scholar]
- Prozzi, J.A. Modeling Pavement Performance by Combining Field and Experimental Data; University of California: Oakland, CA, USA, 2001. [Google Scholar]
- Shahnazari, H.; Tutunchian, M.A.; Mashayekhi, M.; Amini, A.A. Application of soft computing for prediction of pavement condition index. J. Transp. Eng. 2012, 138, 1495–1506. [Google Scholar] [CrossRef]
- Ziari, H.; Sobhani, J.; Ayoubinejad, J.; Hartmann, T. Prediction of IRI in short and long terms for flexible pavements: ANN and GMDH methods. Int. J. Pavement Eng. 2016, 17, 776–788. [Google Scholar] [CrossRef] [Green Version]
- Mazari, M.D.D. Rodriguez, Prediction of pavement roughness using a hybrid gene expression programming-neural network technique. J. Traffic Transp. Eng. (Engl. Ed.) 2016, 3, 448–455. [Google Scholar] [CrossRef] [Green Version]
- Kargah-Ostadi, N.S.M. Stoffels, Framework for development and comprehensive comparison of empirical pavement performance models. J. Transp. Eng. 2015, 141, 04015012. [Google Scholar] [CrossRef]
- Kargah-Ostadi, N.; Stoffels, S.M.; Tabatabaee, N. Network-level pavement roughness prediction model for rehabilitation recommendations. Transp. Res. Rec. 2010, 2155, 124–133. [Google Scholar] [CrossRef]
- Terzi, S. Modeling the pavement present serviceability index of flexible highway pavements using data mining. J. Appl. Sci. 2006, 6, 193–197. [Google Scholar]
- Karballaeezadeh, N.; Mohammadzadeh, S.D.; Shamshirband, S.; Hajikhodaverdikhan, P.; Mosavi, A.; Chau, K.-W. Prediction of remaining service life of pavement using an optimized support vector machine (case study of Semnan–Firuzkuh road). Eng. Appl. Comput. Fluid Mech. 2019, 13, 188–198. [Google Scholar] [CrossRef]
- Ke-zhen, Y.; Liao, H.; Yin, H.; Huang, L. Predicting the pavement serviceability ratio of flexible pavement with support vector machines. In Road Pavement and Material Characterization, Modeling, and Maintenance; American Society of Civil Engineers: New York, NY, USA, 2011; pp. 24–32. [Google Scholar]
- Inkoom, S.; Sobanjo, J.; Barbu, A.; Niu, X. Prediction of the crack condition of highway pavements using machine learning models. Struct. Infrastruct. Eng. 2019, 15, 940–953. [Google Scholar] [CrossRef]
- Fathi, A.; Mazari, M.; Saghafi, M.; Hosseini, A.; Kumar, S. Parametric Study of Pavement Deterioration Using Machine Learning Algorithms. In Airfield and Highway Pavements 2019: Innovation and Sustainability in Highway and Airfield Pavement Technology; American Society of Civil Engineers Reston: Reston, VA, USA, 2019; pp. 31–41. [Google Scholar]
- Soncim, S.P.; de Oliveira, I.C.S.; Santos, F.B. Development of fuzzy models for asphalt pavement performance. Acta Sci. Technol. 2019, 41, e35626. [Google Scholar] [CrossRef]
- Arhin, S.A.; Williams, L.N.; Ribbiso, A.; Anderson, M.F. Predicting pavement condition index using international roughness index in a dense urban area. J. Civ. Eng. Res. 2015, 5, 10–17. [Google Scholar]
- Mfinanga, D.A. Sampling procedure for pavement condition evaluation of local collectors and access roads. Tanzan. J. Eng. Technol. 2007, 1, 99–109. [Google Scholar]
- Wahyudi, W.; Sandra, P.A.; Mulyono, A.T. Analysis of Pavement Condition Index (PCI) and Solution Alternative of Pavement Damage Handling Due to Freight Transportation Overloading (Case Study: National Road Section West Sumatra Border-Jambi City). In Proceedings of the Eastern Asia Society for Transportation Studies, Lalkatta, India, 2013. [Google Scholar]
- ASTM. ASTM D6433-07 Standard Practice for Roads and Parking Lots Pavement Condition Index Surveys; ASTM International: West Conshohocken, PA, USA, 2009. [Google Scholar]
- Marcelino, P.; Antunes, M.d.L.; Fortunato, E. Comprehensive performance indicators for road pavement condition assessment. Struct. Infrastruct. Eng. 2018, 14, 1433–1445. [Google Scholar] [CrossRef]
- Bryce, J.; Boadi, R.; Groeger, J. Relating Pavement Condition Index and Present Serviceability Rating for Asphalt-Surfaced Pavements. Transp. Res. Rec. 2019, 2673, 48–59. [Google Scholar] [CrossRef]
- Luo, Z.; Chou, E.Y. Pavement condition prediction using clusterwise regression. Transp. Res. Rec. 2006, 1974, 70–77. [Google Scholar] [CrossRef]
- Das, A.; Pandey, B. Mechanistic-empirical design of bituminous roads: An Indian perspective. J. Transp. Eng. 1999, 125, 463–471. [Google Scholar] [CrossRef]
- Hossain, M.; Wu, Z. Estimation of Asphalt Pavement Life; 2002. [Google Scholar]
- Park, H.M.; Kim, Y.R. Prediction of remaining life of asphalt pavement using fwd multiload level deflections. Transp. Res. Rec. 2003, 1860, 48–56. [Google Scholar] [CrossRef]
- Smith, R.E. Structuring a microcomputer based pavement management system for local agencies. Diss. Abstr. Int. Part B Sci. Eng. 1987, 47, 320–329. [Google Scholar]
- Al-Suleiman, T.I.; Shiyab, A.M. Prediction of pavement remaining service life using roughness data—Case study in Dubai. Int. J. Pavement Eng. 2003, 4, 121–129. [Google Scholar] [CrossRef]
- Setyawan, A.; Nainggolan, J.; Budiarto, A. Predicting the remaining service life of road using pavement condition index. Procedia Eng. 2015, 125, 417–423. [Google Scholar] [CrossRef] [Green Version]
- Saleh, M. A mechanistic empirical approach for the evaluation of the structural capacity and remaining service life of flexible pavements at the network level. Can. J. Civ. Eng. 2016, 43, 749–758. [Google Scholar] [CrossRef]
- Huang, Y.H. Pavement Analysis and Design; Pearson: New York, NY, USA, 1993. [Google Scholar]
- Shahin, M.Y. Pavement Management for Airports, Roads, and Parking Lots; Springer: New York, NY, USA, 2005; Volume 501. [Google Scholar]
- Abdel-Khalek, A.; Elseifi, M.A.; Codjoe, J.; Fillastre, C. Estimating Service Life of In Situ Flexible Pavements in Louisiana Using Pavement Management System Data. In Proceedings of the Construction Research Congress 2018, New Orleans, LA, USA, 2–4 April 2018. [Google Scholar]
- Kumar, R.; Matias de Oliveira, J.L.; Schultz, A.; Marasteanu, M. Remaining Service Life Asset Measure, Phase 1; Minnesota Department of Transportation, Springer: Manhattan/New York, NY, USA, 2018. [Google Scholar]
- ASTM. Standard Test Method for Deflections with a Falling-Weight-Type Impulse Load Device; ASTM: West Conshohocken, PA, USA, 2009. [Google Scholar]
- Drenth, K. ELMOD 6: The design and structural evaluation package for road, airport and industrial pavements. In Proceedings of the 8th International Conference on Concrete Block Paving, San Francisco, CA, USA, 6–8 November 2006. [Google Scholar]
- ASTM. Standard Guide for Using the Surface Ground Penetrating Radar Method for Subsurface Investigation; ASTM: West Conshohocken, PA, USA, 2011. [Google Scholar]
- Benedetto, A.; Tosti, F.; Ciampoli, L.B.; D’Amico, F. An overview of ground-penetrating radar signal processing techniques for road inspections. Signal Process. 2017, 132, 201–209. [Google Scholar] [CrossRef]
- Salvi, R.; Ramdasi, A.; Kolekar, Y.A.; Bhandarkar, L.V. Use of Ground-Penetrating Radar (GPR) as an Effective Tool in Assessing Pavements—A Review. In Geotechnics for Transportation Infrastructure; Springer: Manhattan/New York, NY, USA, 2019; Volume 95, p. 85. [Google Scholar]
- Cao, Y.; Labuz, J.F.; Dai, S.; Pantelis, J. Implementation of Ground Penetrating Radar; Springer: Manhattan/New York, NY, USA, 2007. [Google Scholar]
- Designation, A.S. D4748-87 Standard Test Method for Determining the Thickness of Bound Pavement Layers Using Short-Pulse Radar; American Society for Testing and Materials: Philadelphia, PA, USA, 1987. [Google Scholar]
- Ferreira, C. Gene Expression Programming in Problem Solving, in Soft Computing and Industry; Springer: Manhattan/New York, NY, USA, 2002; pp. 635–653. [Google Scholar]
- Ferreira, C. Gene Expression Programming: A New Adaptive Algorithm for Solving Problems. arXiv 2001, arXiv:cs/0102027. [Google Scholar]
- Suykens, J.A.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Cherkassky, V.; Ma, Y. Practical selection of SVM parameters and noise estimation for SVM regression. Neural Netw. 2004, 17, 113–126. [Google Scholar] [CrossRef] [Green Version]
- Pan, W.-T. A new fruit fly optimization algorithm: Taking the financial distress model as an example. Knowl. Based Syst. 2012, 26, 69–74. [Google Scholar] [CrossRef]
- Ebtehaj, I.; Bonakdari, H.; Zaji, A.H.; Azimi, H.; Sharifi, A. Gene expression programming to predict the discharge coefficient in rectangular side weirs. Appl. Soft Comput. 2015, 35, 618–628. [Google Scholar] [CrossRef]
- Yassin, M.A.; Alazba, A.; Mattar, M.A. Artificial neural networks versus gene expression programming for estimating reference evapotranspiration in arid climate. Agric. Water Manag. 2016, 163, 110–124. [Google Scholar] [CrossRef]
- Lopes, H.S.; Weinert, W.R. EGIPSYS: An enhanced gene expression programming approach for symbolic regression problems. Int. J. Appl. Math. Comput. Sci. 2004, 14, 375–384. [Google Scholar]
- Faradonbeh, R.S.; Salimi, A.; Monjezi, M.; Ebrahimabadi, A.; Moormann, C. Roadheader performance prediction using genetic programming (GP) and gene expression programming (GEP) techniques. Environ. Earth Sci. 2017, 76, 584. [Google Scholar] [CrossRef]
- Ferreira, C. Gene Expression Programming: Mathematical Modeling by An Artificial Intelligence; Springer: Manhattan/New York, NY, USA, 2006; Volume 21. [Google Scholar]
- Choubin, B.; Moradi, E.; Golshan, M.; Adamowski, J.; Sajedi-Hosseini, F.; Mosavi, A. An Ensemble prediction of flood susceptibility using multivariate discriminant analysis, classification and regression trees, and support vector machines. Sci. Total Environ. 2019, 651, 2087–2096. [Google Scholar] [CrossRef]
- Dehghani, M.; Riahi-Madvar, H.; Hooshyaripor, F.; Mosavi, A.; Shamshirband, S.; Zavadskas, E.K.; Chau, K.-W. Prediction of hydropower generation using grey wolf optimization adaptive neuro-fuzzy inference system. Energies 2019, 12, 289. [Google Scholar] [CrossRef] [Green Version]
- Dibike, Y.B.; Velickov, S.; Solomatine, D. Support vector machines: Review and applications in civil engineering. In Proceedings of the 2nd Joint Workshop on Application of AI in Civil Engineering, Cottbus, Germany, 20 March 2000. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Cheng, K.; Lu, Z.; Wei, Y.; Shi, Y.; Zhou, Y. Mixed kernel function support vector regression for global sensitivity analysis. Mech. Syst. Signal Process. 2017, 96, 201–214. [Google Scholar] [CrossRef]
- Cherkassky, V.; Mulier, F.M. Learning from Data: Concepts, Theory, and Methods; John Wiley & Sons: New York, NY, USA, 2007. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin, Germany, 2013. [Google Scholar]
- Xiao, C.; Hao, K.; Ding, Y. An improved fruit fly optimization algorithm inspired from cell communication mechanism. Math. Probl. Eng. 2015, 2015, 492195. [Google Scholar] [CrossRef] [Green Version]
- Chu, D.; He, Q.; Mao, X. Rolling bearing fault diagnosis by a novel fruit fly optimization algorithm optimized support vector machine. J. Vibroengineering 2016, 18, 151–164. [Google Scholar]
- Yu, Y.; Li, Y.; Li, J.; Gu, X. Self-adaptive step fruit fly algorithm optimized support vector regression model for dynamic response prediction of magnetorheological elastomer base isolator. Neurocomputing 2016, 211, 41–52. [Google Scholar] [CrossRef] [Green Version]
- Cong, Y.; Wang, J.; Li, X. Traffic flow forecasting by a least squares support vector machine with a fruit fly optimization algorithm. Procedia Eng. 2016, 137, 59–68. [Google Scholar] [CrossRef] [Green Version]
- West, S.G.; Finch, J.F.; Curran, P.J. Structural Equation Models with Nonnormal Variables: Problems and Remedies; American Psychological Association: Washington, DC, USA, 1995. [Google Scholar]
- Joanes, D.; Gill, C. Comparing measures of sample skewness and kurtosis. J. R. Stat. Soc. Ser. D (Stat.) 1998, 47, 183–189. [Google Scholar] [CrossRef]
- George, D. SPSS for Windows Step by Step: A Simple Study Guide and Reference, 17.0 Update, 10/e; Pearson Education India: Kolkata, India, 2011. [Google Scholar]
- Mehr, A.D. An improved gene expression programming model for streamflow forecasting in intermittent streams. J. Hydrol. 2018, 563, 669–678. [Google Scholar] [CrossRef]
- Willmott, C.J.; Robeson, S.M.; Matsuura, K. A refined index of model performance. Int. J. Climatol. 2012, 32, 2088–2094. [Google Scholar] [CrossRef]
- Choubin, B.; Abdolshahnejad, M.; Moradi, E.; Querol, X.; Mosavi, A.; Shamshirband, S.; Ghamisi, P. Spatial hazard assessment of the PM10 using machine learning models in Barcelona, Spain. Sci. Total Environ. 2020, 701, 134474. [Google Scholar] [CrossRef]
- Shamshirband, S.; Hadipoor, M.; Baghban, A.; Mosavi, A.; Bukor, J.; Várkonyi-Kóczy, A.R. Developing an ANFIS-PSO Model to Predict Mercury Emissions in Combustion Flue Gases. Mathematics 2019, 7, 965. [Google Scholar] [CrossRef] [Green Version]
- Mohammadzadeh, D.; Kazemi, S.-F.; Mosavi, A.; Nasseralshariati, E. Prediction of Compression Index of Fine-Grained Soils Using a Gene Expression Programming Model. Infrastructures 2019, 4, 26. [Google Scholar] [CrossRef] [Green Version]
- Samadianfard, S.; Jarhan, S.; Salwana, E.; Mosavi, A.; Shamshirband, S. Support Vector Regression Integrated with Fruit Fly Optimization Algorithm for River Flow Forecasting in Lake Urmia Basin. Water 2019, 11, 1934. [Google Scholar] [CrossRef] [Green Version]
- Taylor, K.E. Summarizing multiple aspects of model performance in a single diagram. J. Geophys. Res. Atmos. 2001, 106, 7183–7192. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Model Inputs | Equation | Author |
|---|---|---|---|
| 1. Based on pavement responses | εt = Tensile strain at the bottom of the asphalt layer, E1 = Elastic modulus of asphalt, f1, f2, and f3 = Regression coefficients. | Huang (1993) | |
| εc = Compressive strain at the top of the subgrade, f4 and f5 = Regression coefficients. | Huang (1993) | ||
| εt = Tensile strain at the asphalt layer bottom, MR = Resilient modulus. | Das & Pandey (1999) | ||
| εr = Horizontal tensile strain at the bottom of the asphalt layer, EAC = Modulus of asphalt, a, b, and c = Constant coefficients of regression. | Hossain & Wu (2002) | ||
| εt = Tensile strain at the asphalt layer bottom, K and c = Regression coefficients. | Park & Kim (2003) | ||
| 2. Based on pavement quality indices | IRI = International roughness index, a = Initial IRI (where age is zero), b = Curvature of performance line. | Al-suleiman & Shiyab (2003) | |
| PCI = Pavement Condition Index. | Setyawan et al. (2015) | ||
| 3. Based on the result of the non-destructive test | = Pavement surface curvature, and = Material constants. | Saleh (2016) | |
| AUPP = Area under pavement profile, and = Material constants. | Saleh (2016) |
| Rating Scale | 0–10 | 10–25 | 25–40 | 40–55 | 55–70 | 70–85 | 85–100 |
|---|---|---|---|---|---|---|---|
| Description | Failed | Serious | Very Poor | Poor | Fair | Satisfactory | Good |
| Parameter | Value |
|---|---|
| Tension (kPa) | 600–900 |
| Number of geophones | 9 |
| Geophone distance from center of laoding plate (cm) | 0, 20, 30, 45, 60, 90, 120, 150, and 180 |
| Number of weights falling | Four times |
| Loading plate radius (mm) | 150 |
| Parameter | Value |
|---|---|
| Antenna type | 1000 MHz |
| Record speed (km/hr) | 10 |
| Number of scanning (per meter) | 10 |
| Maximum pulse penetrating depth (ns) | 32 |
| Variable | Mean | Minimum | Maximum | Standard Deviation | Kurtosis | Skewness | Sig. in Kolmogorov–Smirnov Test | Correlation with RSL |
|---|---|---|---|---|---|---|---|---|
| PCI | 59.97 | 19.00 | 100.00 | 21.51 | −1.093 | 0.03 | 0.068 | 0.572 |
| RSL | 17.77 | 0.00 | 40.00 | 15.04 | −1.393 | 0.50 | 0.000 | 1 |
| Model | |||
|---|---|---|---|
| SVR | SVR-FOA | ||
| SVR parameter | C | 1.0000 | 1.0022 |
| 0.0100 | 0.2561 | ||
| 0.0010 | 0.0760 | ||
| Parameter | Quantity |
|---|---|
| Head size | 8 |
| Number of Genes | 3 |
| Chromosomes | 30 |
| Linking function | Addition (+) |
| One-point recombination rate | 0.3 |
| Two-point recombination rate | 0.3 |
| Inversion rate | 0.1 |
| Gene recombination rate | 0.1 |
| Mutation rate | 0.044 |
| Gene transposition rate | 0.1 |
| Used functions | +, −, ×, ÷, power |
| Parameter | GEP | SVR | SVR-FOA |
|---|---|---|---|
| CC | 0.874 | 0.865 | 0.879 |
| SI | 0.598 | 0.894 | 0.616 |
| NSE | 0.601 | 0.110 | 0.577 |
| WI | 0.807 | 0.369 | 0.786 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nabipour, N.; Karballaeezadeh, N.; Dineva, A.; Mosavi, A.; Mohammadzadeh S., D.; Shamshirband, S. Comparative Analysis of Machine Learning Models for Prediction of Remaining Service Life of Flexible Pavement. Mathematics 2019, 7, 1198. https://doi.org/10.3390/math7121198
Nabipour N, Karballaeezadeh N, Dineva A, Mosavi A, Mohammadzadeh S. D, Shamshirband S. Comparative Analysis of Machine Learning Models for Prediction of Remaining Service Life of Flexible Pavement. Mathematics. 2019; 7(12):1198. https://doi.org/10.3390/math7121198
Chicago/Turabian StyleNabipour, Narjes, Nader Karballaeezadeh, Adrienn Dineva, Amir Mosavi, Danial Mohammadzadeh S., and Shahaboddin Shamshirband. 2019. "Comparative Analysis of Machine Learning Models for Prediction of Remaining Service Life of Flexible Pavement" Mathematics 7, no. 12: 1198. https://doi.org/10.3390/math7121198
APA StyleNabipour, N., Karballaeezadeh, N., Dineva, A., Mosavi, A., Mohammadzadeh S., D., & Shamshirband, S. (2019). Comparative Analysis of Machine Learning Models for Prediction of Remaining Service Life of Flexible Pavement. Mathematics, 7(12), 1198. https://doi.org/10.3390/math7121198