A Multi-Objective Particle Swarm Optimization Algorithm Based on Gaussian Mutation and an Improved Learning Strategy


Abstract
:1. Introduction
2. Description of Multi-Objective Optimization Problems
3. An Introduction to the Multi-Objective Improved PSO
3.1. Main Aspects of the Standard PSO Algorithm
| Algorithm 1: Standard particle swarm optimization [20] |
| Step 1: Initialize a population of particles , such that each particle has a random position vector and a velocity vector . Set parameters and , the maximum number of generations , and the generation number . Step 2: Calculate the fitness of all the particles in . Step 3: Renew the positions and velocities of particles based on the following equations: Step 5: (Termination examination) If the termination criterion is satisfied, then output the global optimal position and the fitness value. Otherwise, let and return to Step 2. |
3.2. Main Aspects of the Multi-Objective Improved PSO Algorithm (MOIPSO)
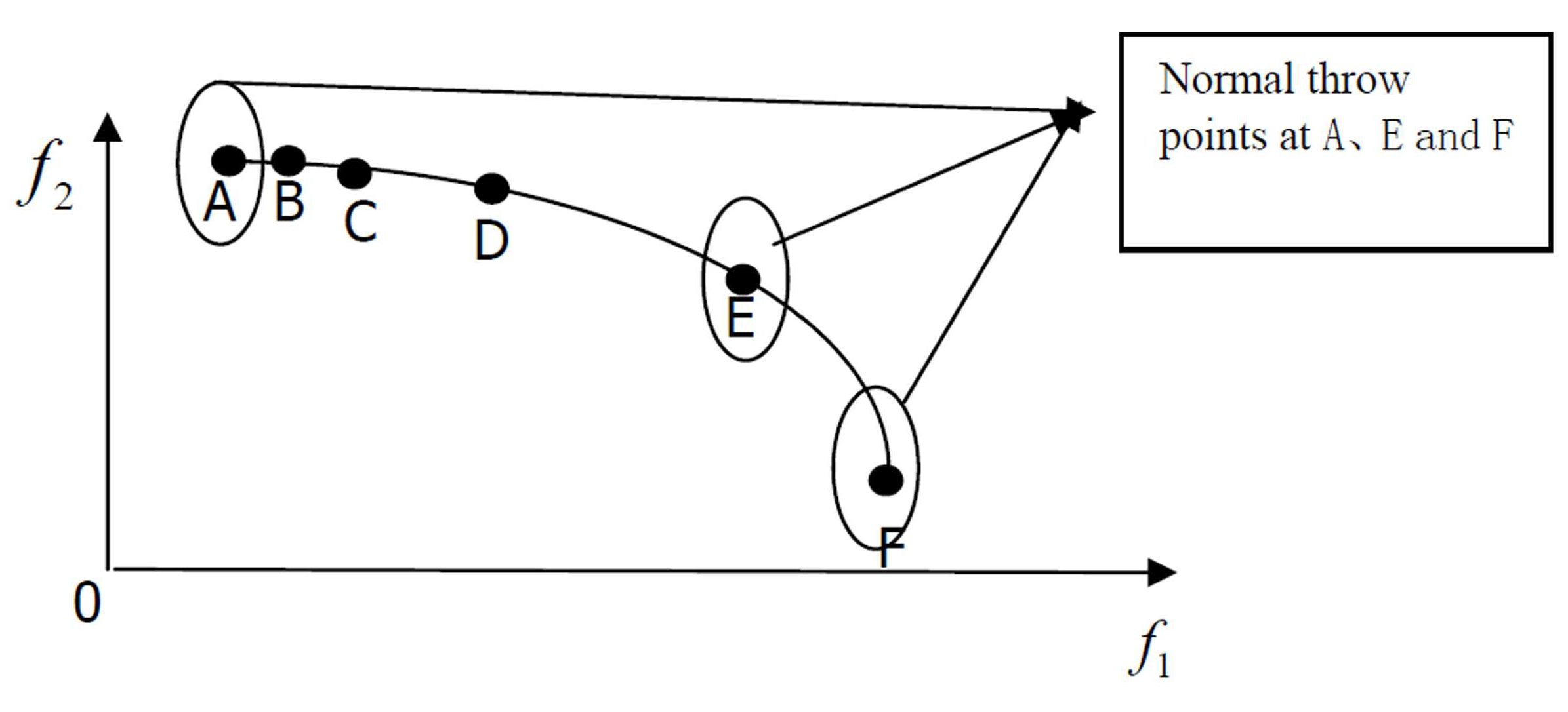
3.2.1. Elitist Archive and Crowding Entropy
3.2.2. Gaussian Mutation Strategy
3.2.3. Improved Learning Strategy
3.2.4. Update External Archive
3.2.5. Population Elitist Incremental Strategy
4. Overview of the MOIPSO Algorithm
5. Methods and Simulation Experiments
5.1. Test Problems
5.2. Performance Measures
5.2.1. Convergence Measure Indicator
5.2.2. Distribution Measure Indicator
5.3. Algorithm Comparison
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| MOIPSO | Multi-objective improved PSO algorithm |
| MOPs | Multi-objective optimization problems |
| MOEA | Multi-objective optimization evolutionary algorithm |
| GMPS | Gaussian mutation points set |
| TPS | Thickened point set |
| DW | Distribution width |
References
- Miettinen, K.M. Nonlinear Multi-Objective Optimization; Kluwer Academic Publishers: Boston, MA, USA, 1999. [Google Scholar]
- Deb, K. Multi-Objective Optimization Using Evolutionary Algorithms; John Wiley and Sons: Hoboken, NJ, USA, 2001. [Google Scholar]
- Fonseca, C.M.; Fleming, P.J. Genetic Algorithm for Multi-Objective Optimization: Formulation, Discussion and Generalization; Morgan Kaufmann Publishers: Burlington, MA, USA, 1993. [Google Scholar]
- Deb, K.; Pratap, A.; Agrawal, S.; Meyarivan, T. A fast and elitist multi-objective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Zitzler, E.; Thiele, L. Multi-objective evolutionary algorithms: A comparative case study and the strength pareto approach. IEEE Trans. Evol. Comput. 1999, 3, 257–271. [Google Scholar] [CrossRef]
- Knowles, J.D.; Corne, D.W. Approximating the nondominated front using the Pareto archived evolution strategy. IEEE Trans. Evol. Comput. 2000, 8, 149–172. [Google Scholar] [CrossRef]
- Coello, C.A.C.; Pultdo, G.T.; Lechuga, M.S. Handling multiple objectives with particle swarm optimization. IEEE Trans. Evol. Comput. 2004, 8, 256–279. [Google Scholar] [CrossRef]
- Sierra, M.R.; Coello, C.A.C. Improving PSO-Based Multi-Objective Optimization Using Crowding, Mutation and ε-Dominance; Springer: Berlin/Heidelberg, Germany, 2005; pp. 505–519. [Google Scholar]
- Reddy, M.J.; Kumar, D.N. An efficient multi-objective optimization algorithm based on swarm intelligence for engineering design. Eng. Optim. 2007, 39, 49–68. [Google Scholar] [CrossRef]
- Leong, W.F.; Yen, G.G. PSO-based multi-objective optimization with dynamic population size and adaptive local archives. IEEE Trans. Syst. Man Cybern. Part B 2008, 38, 1270–1293. [Google Scholar] [CrossRef] [PubMed]
- Yen, G.G.; Leong, W.F. Dynamic multiple swarms in multi-objective particle swarm optimization. IEEE Trans. Syst. Man Cybern. Part B 2009, 39, 890–911. [Google Scholar] [CrossRef]
- Chen, D.B.; Zou, F.; Wang, J.T. A multi-objective endocrine PSO algorithm and application. Appl. Soft Comput. 2011, 11, 4508–4520. [Google Scholar] [CrossRef]
- Lin, Q.; Li, J.; Du, Z.; Chen, J.; Ming, Z. A novel multi-objective particle swarm optimization with multiple search strategies. Eur. J. Oper. Res. 2015, 247, 732–744. [Google Scholar] [CrossRef]
- Meza, J.; Espitia, H.; Montenegro, C.; Giménez, E.; González-Crespo, R. Movpso: Vortex multi-objective particle swarm optimization. Appl. Soft Comput. 2017, 52, 1042–1057. [Google Scholar] [CrossRef]
- Hu, W.; Yen, G.G. Adaptive multi-objective particle swarm optimization based on parallel cell coordinate system. IEEE Trans. Evol. Comput. 2015, 19, 1–18. [Google Scholar]
- Knight, J.T.; Singer, D.J.; Collette, M.D. Testing of a spreading mechanism to promote diversity in multi-objective particle swarm optimization. IEEE Trans. Evol. Comput. 2015, 16, 279–302. [Google Scholar] [CrossRef]
- Cheng, T.; Chen, M.; Fleming, P.J.; Yang, Z.; Gan, S. A novel hybrid teaching learning based multi-objective particle swarm optimization. Neurocomputing 2017, 222, 11–25. [Google Scholar] [CrossRef]
- Coello, C.A.C. Evolutionary multi-objective optimization: A historical view of the field. IEEE Comput. Intell. Mag. 2006, 1, 28–36. [Google Scholar] [CrossRef]
- Zitzler, E. Evolutionary Algorithm for Multiobjective Optimization: Methods and Application; Swiss Federal Institute of Technology: Zurich, Switzerland, 1999. [Google Scholar]
- Kennedy, J.; Eberhart, R.C. Particle Swarm Optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Wang, Y.N.; Wu, L.H.; Yuan, X.F. Multi-objective self-adaptive differential evolution with elitist archive and crowding entropy-based diversity measure. Soft Comput. 2010, 14, 193–209. [Google Scholar] [CrossRef]
- Higashi, N.; Iba, H. Particle Swarm Optimization with Gaussian Mutation; IEEE: Piscataway, NJ, USA, 2013. [Google Scholar]
- Coelho, L.D.S.; Ayala, V.H.; Alotto, P. A Multiobjective Gaussian Particle Swarm Approach Applied to Electromagnetic Optimization. IEEE Trans. Mag. 2010, 46, 3289–3292. [Google Scholar] [CrossRef]
- Liang, H.M.; Zhang, K.; Yu, H.H. Multi-objective Gaussian particle swarm algorithm optimization based on niche sorting for actuator design. Adv. Mech. Eng. 2015, 7, 1–7. [Google Scholar] [CrossRef]
- Schaffer, J.D. Multiple objective optimization with vector evaluated genetic algorithm. In Proceedings of the 1st International Conference on Genetic Algorithm and Their Applications, Pittsburg, CA, USA, 24–26 July 1985; pp. 93–100. [Google Scholar]
- Kursawe, F. A varant of evolution strategies for vector optimization. In International Conference on Parallel Problem Solving from Nature; Springer: Berlin/Heidelberg, Germany, 1991; pp. 193–197. [Google Scholar]
- Fonseca, C.M.; Fleming, P.J. Multiobjective optimization and multiple constraint handling with evolutionary algorithms, Part II: Application example. IEEE Trans. Syst. Man Cybern. A 1998, 28, 38–47. [Google Scholar] [CrossRef]
- Zitzler, E.; Deb, K.; Thiele, L. Comparison of multi-objective evolutionary algorithms: Empirical results. Evol. Comput. 2000, 8, 173–195. [Google Scholar] [CrossRef]
- Van Veldhuizen, D.A.; Lamont, G.B. Evolutionary computation and convergence to a Pareto front. In Late Breaking Papers at the Genetic Programming 1998 Conference; Standford University: Stanford, CA, USA, 1998; pp. 221–228. [Google Scholar]
- Saraswat, A.; Saini, A. Multi-objective optimal reactive power dispatch considering voltage stability in power systems using HFMOEA. Eng. Appl. Artif. Intell. 2013, 26, 390–404. [Google Scholar] [CrossRef]
- Ding, S.X.; Chen, C.; Xin, B.; Psrdalos, P. A bi-objective load balancing model in a distributed simulation system using NSGA-II and MOPSO approaches. Appl. Soft Comput. 2018, 63, 249–267. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Function | Objective Functions | D | Variable Bounds | Characteristics of the Pareto Front |
|---|---|---|---|---|
| SCH | 1 | Convex | ||
| FON | 3 | Nonconvex | ||
| KUR | 3 | Disconnect | ||
| ZDT1 | 30 | Convex | ||
| ZDT2 | 30 | Nonconvex | ||
| ZDT3 | 30 | Convex disconnect | ||
| ZDT4 | 10 | Nonconvex | ||
| ZDT6 | 10 | Nonconvex |
| Function | Statistic | MOPSO | NSGA-II | MOIPSO |
|---|---|---|---|---|
| SCH | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| FON | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| KUR | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT1 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT2 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT3 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | 1.50 | |||
| ZDT4 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT6 | Best | |||
| Worst | ||||
| Mean | ||||
| Std |
| Function | Statistic | MOPSO | NSGA-II | MOIPSO |
|---|---|---|---|---|
| SCH | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| FON | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| KUR | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT1 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT2 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT3 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT4 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT6 | Best | |||
| Worst | ||||
| Mean | ||||
| Std |
| Function | Statistic | MOPSO | NSGA-II | MOIPSO |
|---|---|---|---|---|
| SCH | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| FON | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| KUR | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT1 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT2 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT3 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT4 | Best | |||
| Worst | ||||
| Mean | ||||
| Std | ||||
| ZDT6 | Best | |||
| Worst | ||||
| Mean | ||||
| Std |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Gao, Y. A Multi-Objective Particle Swarm Optimization Algorithm Based on Gaussian Mutation and an Improved Learning Strategy. Mathematics 2019, 7, 148. https://doi.org/10.3390/math7020148
Sun Y, Gao Y. A Multi-Objective Particle Swarm Optimization Algorithm Based on Gaussian Mutation and an Improved Learning Strategy. Mathematics. 2019; 7(2):148. https://doi.org/10.3390/math7020148
Chicago/Turabian StyleSun, Ying, and Yuelin Gao. 2019. "A Multi-Objective Particle Swarm Optimization Algorithm Based on Gaussian Mutation and an Improved Learning Strategy" Mathematics 7, no. 2: 148. https://doi.org/10.3390/math7020148
APA StyleSun, Y., & Gao, Y. (2019). A Multi-Objective Particle Swarm Optimization Algorithm Based on Gaussian Mutation and an Improved Learning Strategy. Mathematics, 7(2), 148. https://doi.org/10.3390/math7020148